Web-Crawler BeautifulSoup Python 특정 사이트의 본문 내용을 가져오는 웹 크롤러를 Python과 Python 라이브러리인 Beauitful Soup을 이용해보겠습니다. https://www.crummy.com/software/BeautifulSoup/ $ sudo pip install beautifulsoup4 $ sudo pip3 install beautifulsoup4 $ pip install urllib $ pip install lxml $ pip install konlpy $ pip install JPype1 Python Code는 다음과 같습니다. Beautiful 객체를 생성하여 lxml 방식으로 Parsing 파싱을 했고, 한글 내용을 가져오기 위해 from_encoding을 utf-8 방식으로 인코딩하였습니다. """ python3 Mac OS X urllib : sudo pip3 install urllib lxml : sudo pip3 install lxml """ from bs4 import BeautifulSoup import urllib.request # OUTPUT File OUTPUT_FILE_NAME = 'output.txt' # Crawling URL CRAWLING_URL = 'http://thezam.co.kr/product/detail.html?product_no=2948&cate_no=1&display_group=2' # Crawling Function def get_text(CRAWLING_URL): # 지정된 URL을 오픈하여 requset 정보를 가져옵니다 source_code_from_URL = urllib.request.urlopen(CRAWLING_URL) # lxml parsor 를 이용합니다 soup = BeautifulSoup(source_code_from_URL, 'lxml', from_encoding='utf-8') text = '' # 더 잠 사이트에서 p 태그를 가져옵니다 for item in soup.find_all('p',align="center"): text = text + str(item.find_all(text=True))+' ' return text # Main Function def main(): # 파일을 쓰기 모드로 open open_output_file = open(OUTPUT_FILE_NAME, 'w') # get_text function 호출, crawling 해서 가져온 문자열 result_text = get_text(CRAWLING_URL) # 파일에 write open_output_file.write(result_text) # 파일을 닫는다 open_output_file.close() if __name__ == '__main__': main() Python 파일을 실행해 보겠습니다. $ python3 Crawling.py $ cat output.txt 가져온 본문 내용에는 \n과 \r 등의 특수 문자가 담겨 있습니다. 필요없는 문자를 제거하기 위해 다음의 처리 코드를 이용합니다. Python 코드 입니다. """ Text clean up """ import re # input file INPUT_FILE_NAME = "output.txt" # output file OUTPUT_FILE_NAME = "output_cleand.txt" # Cleaning Function def clean_text(text): cleaned_text = re.sub('[a-zA-Z0-9]', '', text) # 영어 대소문자와 숫자를 제거 cleaned_text = re.sub('[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]', '', cleaned_text) # 특수문자를 제거하는 코드 return cleaned_text # Main Function def main(): # 읽기 모드로 파일을 읽는다. read_file = open(INPUT_FILE_NAME, 'r') # 쓰기 모드로 파일을 읽는다. write_file = open(OUTPUT_FILE_NAME, 'w') # 파일을 읽어와 저장한다. text = read_file.read() # clean_text function 호출 후 대소문자와 숫자와 특수문자 제거된 문자열을 저장 text = clean_text(text) # 파일에 쓴다. write_file.write(text) # 파일을 닫는다. read_file.close() write_file.close() if __name__ == "__main__": main() 실행은 다음과 같습니다. $ python3 Cleaner.py $ cat output_cleand.txt 크롤링해 저장한 텍스트 파일의 내용을 단어 사용 빈도를 계산하는 python 코드를 이용해 보겠습니다. Python 코드 """ 형태소 분석기 : 명사 추출 및 빈도수 체크 python [모듈이름 [텍스트파일명.txt] [결과파일명.txt] konlpy.tag : http://konlpy.org/ko/latest/ $ pip install konlpy $ pip install JPype1 $ pip3 install konlpy """ import sys from konlpy.tag import Twitter from collections import Counter # 명사로 분리하고 갯수를 세어 반환한다. def get_tags(text, ntags=50): spliter = Twitter() nouns = spliter.nouns(text) # 명사로 분리한다 count = Counter(nouns) # 명사를 카운팅한다. return_list = [] for n, c in count.most_common(ntags): temp = {'tag': n, 'count': c} return_list.append(temp) return return_list def main(argv): # 입력되는 명령어 parmeter 유효성 검사 if len(argv) != 4: print('python [모듈 이름 [텍스트 파일명.txt] [단어 개수] [결과파일명.txt]') return text_file_name = argv[1] noun_count = int(argv[2]) output_file_name = argv[3] # 파일을 읽기 모드로 오픈 open_text_file = open(text_file_name, 'r') # 파일에서 읽어온다. text = open_text_file.read() # get_tags function 호출 tags = get_tags(text, noun_count) # 파일을 닫는다 open_text_file.close() # 파일을 쓰기 모드로 오픈 open_output_file = open(output_file_name, 'w') for tag in tags: noun = tag['tag'] count = tag['count'] open_output_file.write('{} {}\n'.format(noun, count)) # 파일을 닫는다 open_output_file.close() if __name__ == '__main__' : main(sys.argv) 실행은 다음과 같습니다. $ python3 CheckTF-IDF.py output_cleand.txt 25 output_tf_idf.txt $ cat output_tf_idf.txt 이상 포스팅을 마치겠습니다.Web-Crawler
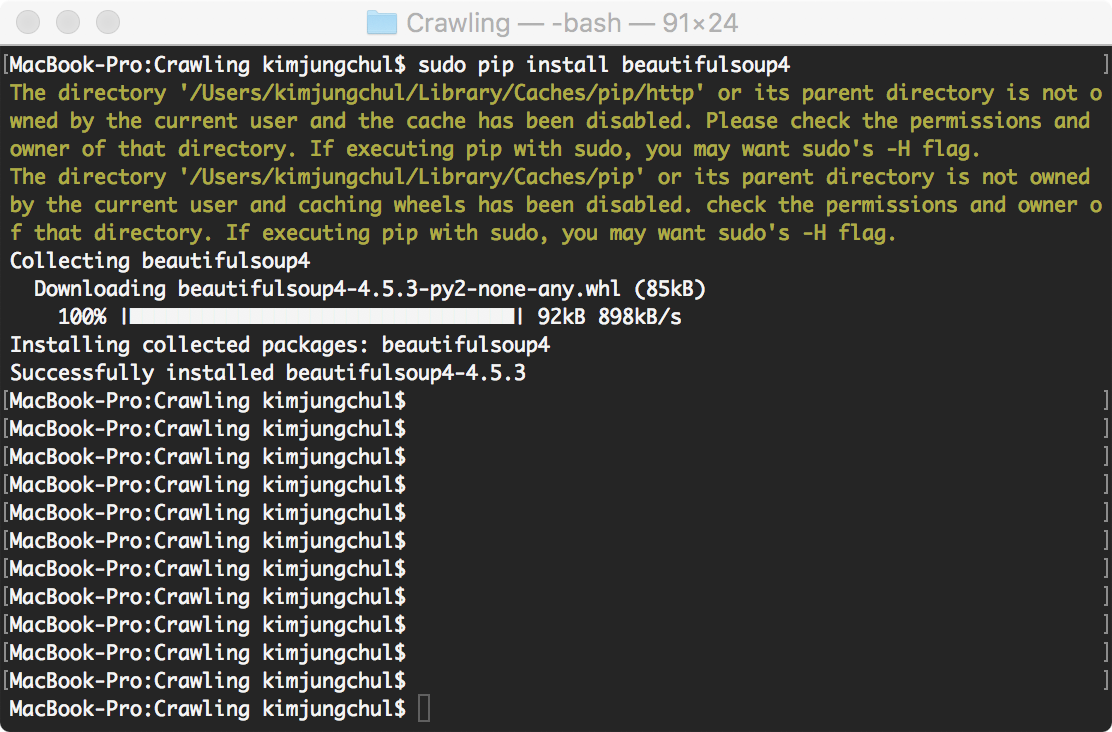
BeautifulSoup Install
필요한 Library
Python Code






'Computer Language' 카테고리의 다른 글
| Mac OS X Python 3 MySQL 연동 (0) | 2017.02.06 |
|---|---|
| Python 3 기본 문법 (0) | 2017.02.04 |
| NodeJs - 모듈(http) (0) | 2016.02.23 |
| NodeJs - 모듈(FileSystem, Event, Network) (0) | 2016.02.23 |
| NodeJs (0) | 2016.02.23 |