IBM Research Report An Updated Performance Comparison of Virtual Machines and Linux Containers Wes Felter, Alexandre Ferreira, Ram Rajamony, Juan Rubio IBM Research, Austin, TX {wmf, apferrei, rajamony, rubioj}@us.ibm.com http://blog.pierreroudier.net/wp-content/uploads/2015/08/rc25482.pdf Cloud computing makes extensive use of virtual machines (VMs) because they permit workloads to be isolated from one another and for the resource usage to be somewhat controlled. However, the extra levels of abstraction involved in virtualization reduce workload performance, which is passed on to customers as worse price/performance. Newer advances in container-based virtualization simplifies the deployment of applications while continuing to permit control of the resources allocated to different applications. 클라우드 컴퓨팅은 작업 부하를 서로 격리하고 리소스 사용을 통제하기 때문에 VM (가상 컴퓨터)을 광범위하게 사용합니다. 그러나 가상화와 관련된 추가 수준의 추상화는 작업 부하 성능을 감소시키므로 고객에게 더 낮은 가격 / 성능으로 전달됩니다. 컨테이너 기반 가상화의 새로운 발전은 여러 응용 프로그램에 할당된 자원을 계속 제어하면서 응용 프로그램 배포를 단순화합니다. In this paper, we explore the performance of traditional virtual machine deployments, and contrast them with the use of Linux containers. We use a suite of workloads that stress CPU, memory, storage, and networking resources. We use KVM as a representative hypervisor and Docker as a container manager. Our results show that containers result in equal or better performance than VMs in almost all cases. Both VMs and containers require tuning to support I/O-intensive applications. We also discuss the implications of our performance results for future cloud architectures. 본 논문에서는 전통적인 가상 머신 배포의 성능을 조사하고 Linux 컨테이너 사용과 대조합니다. 우리는 CPU, 메모리, 스토리지 및 네트워킹 리소스를 강조하는 일련의 작업 부하를 사용합니다. 우리는 KVM을 대표적인 하이퍼바이저로 사용하고 Docker를 컨테이너 관리자로 사용합니다. 우리의 결과는 컨테이너가 거의 모든 경우에 VM보다 동등하거나 더 우수한 성능을 보여 주었다. VM과 컨테이너 모두 I/O 집약적 인 응용 프로그램을 지원하도록 튜닝해야합니다. 또한 미래의 클라우드 아키텍처에 대한 우리의 성과 결과가 의미하는 바를 논의한다. Virtual machines are used extensively in cloud computing. In particular, the state-of-the-art in Infrastructure as a Service (IaaS) is largely synonymous with virtual machines. Cloud platforms like Amazon EC2 make VMs available to customers and also run services like databases inside VMs. Many Platform as a Service (PaaS) and Software as a Service (SaaS) providers are built on IaaS with all their workloads running inside VMs. Since virtually all cloud workloads are currently running in VMs, VM performance is a crucial component of overall cloud performance. Once a hypervisor has added overhead, no higher layer can remove it. Such overheads then become a pervasive tax on cloud workload performance. There have been many studies showing how VM execution compares to native execution [30, 33] and such studies have been a motivating factor in generally improving the quality of VM technology [25, 31]. 가상 머신은 클라우드 컴퓨팅에서 광범위하게 사용됩니다. 특히 IaaS (Infrastructure as a Service)의 최첨단 기술은 가상 시스템과 거의 동의어입니다. Amazon EC2와 같은 클라우드 플랫폼은 고객이 VM을 사용할 수 있게 하며, VM 내부의 데이터베이스와 같은 서비스도 실행합니다. SaaS (Servive as PaaS) 및 SaaS (Software as a Service) 공급자는 IaaS를 기반으로하며 모든 작업 부하가 VM 내부에서 실행됩니다. 거의 모든 클라우드 작업 부하가 현재 VM에서 실행 중이므로 VM 성능은 전반적인 클라우드 성능의 중요한 구성 요소입니다. 하이퍼 바이저가 오버 헤드를 추가하면 상위 계층에서 오버 헤드를 제거 할 수 없습니다. 그런 오버 헤드는 클라우드 작업 부하 성능에 대한 과도한 세금이됩니다. VM 실행이 원래 실행과 비교되는 방법을 보여주는 많은 연구가 있었고 [30, 33] 이러한 연구는 VM 기술의 품질을 전반적으로 향상시키는 동기 부여 요소였습니다 [25, 31]. Container-based virtualization presents an interesting alternative to virtual machines in the cloud [46]. Virtual Private Server providers, which may be viewed as a precursor to cloud computing, have used containers for over a decade but many of them switched to VMs to provide more consistent performance. Although the concepts underlying containers such as namespaces are well understood [34], container technology languished until the desire for rapid deployment led PaaS providers to adopt and standardize it, leading to a renaissance in the use of containers to provide isolation and resource control. Linux is the preferred operating system for the cloud due to its zero price, large ecosystem, good hardware support, good performance, and reliability. The kernel namespaces feature needed to implement containers in Linux has only become mature in the last few years since it was first discussed [17]. Within the last two years, Docker [45] has emerged as a standard runtime, image format, and build system for Linux containers. 컨테이너 기반 가상화는 클라우드의 가상 시스템에 대한 흥미로운 대안을 제시합니다 [46]. 클라우드 컴퓨팅의 선구자로 볼 수있는 Virtual Private Server 제공 업체는 10 년 이상 컨테이너를 사용해 왔지만 그 중 많은 업체가보다 일관된 성능을 제공하기 위해 VM으로 전환했습니다. 컨테이너와 같은 네임 스페이스와 같은 개념이 잘 이해되고 있지만 컨테이너 기술은 신속한 배포를 원할 때까지 PaaS 공급자가이를 채택하고 표준화 할 때까지 어려움을 겪었습니다. 컨테이너를 사용하여 격리 및 리소스 제어를 제공하는 르네상스가 되었습니다. Linux는 제로 가격, 대규모 에코 시스템, 우수한 하드웨어 지원, 우수한 성능 및 안정성으로 인해 클라우드에 선호되는 운영 체제입니다. 리눅스에서 컨테이너를 구현하는 데 필요한 커널 네임 스페이스 기능은 처음 논의 된 이래로 지난 몇 년 동안만 성숙 해졌다. 지난 2 년 동안 Docker [45]는 Linux 컨테이너 용 표준 런타임, 이미지 형식 및 빌드 시스템으로 등장했습니다. This paper looks at two different ways of achieving resource control today, viz., containers and virtual machines and compares the performance of a set of workloads in both environments to that of natively executing the workload on hardware. In addition to a set of benchmarks that stress different aspects such as compute, memory bandwidth, memory latency, network bandwidth, and I/O bandwidth, we also explore the performance of two real applications, viz., Redis and MySQL on the different environments. 이 논문에서는 오늘날 컨테이너, 가상 머신 등 리소스 제어를 달성하는 두 가지 방법을 살펴보고 두 환경의 작업 부하 집합의 성능을 하드웨어의 작업 부하를 기본적으로 실행하는 것과 비교합니다. 컴퓨팅, 메모리 대역폭, 메모리 대기 시간, 네트워크 대역폭 및 I / O 대역폭과 같은 다양한 측면을 강조하는 일련의 벤치 마크 외에도 두 가지 실제 응용 프로그램, 즉 다양한 환경에서 Redis 및 MySQL의 성능을 탐색합니다. Our goal is to isolate and understand the overhead introduced by virtual machines (specifically KVM) and containers (specifically Docker) relative to non-virtualized Linux. We expect other hypervisors such as Xen, VMware ESX, and Microsoft Hyper-V to provide similar performance to KVM given that they use the same hardware acceleration features. Likewise, other container tools should have equal performance to Docker when they use the same mechanisms. We do not evaluate the case of containers running inside VMs or VMs running inside containers because we consider such double virtualization to be redundant (at least from a performance perspective). The fact that Linux can host both VMs and containers creates the opportunity for an apples-to-apples comparison between the two technologies with fewer confounding variables than many previous comparisons. 우리의 목표는 가상화되지 않은 Linux에 비해 가상 시스템 (특히 KVM)과 컨테이너 (특히 Docker)가 도입 한 오버 헤드를 격리하고 이해하는 것입니다. Xen, VMware ESX 및 Microsoft Hyper-V와 같은 다른 하이퍼바이저는 동일한 하드웨어 가속 기능을 사용한다는 점에서 KVM과 비슷한 성능을 제공 할 것으로 기대합니다. 마찬가지로, 다른 컨테이너 도구도 Docker와 동일한 메커니즘을 사용할 때 Docker와 동일한 성능을 가져야합니다. 컨테이너 내부에서 실행되는 VM 또는 VM 내부에서 실행되는 컨테이너의 경우를 평가하지는 않습니다. 이중 가상화가 중복되는 것으로 간주하기 때문입니다 (적어도 성능 관점에서 볼 때). Linux가 VM과 컨테이너를 둘 다 호스트 할 수 있다는 사실은 이전의 여러 비교보다 혼동이 적은 변수로 두 기술 간의 apples-to-apples비교를 할 수있는 기회를 제공합니다. We make the following contributions: • We provide an up-to-date comparison of native, container, and virtual machine environments using recent hardware and software across a cross-section of interesting benchmarks and workloads that are relevant to the cloud. • We identify the primary performance impact of current virtualization options for HPC and server workloads. • We elaborate on a number of non-obvious practical issues that affect virtualization performance. • We show that containers are viable even at the scale of an entire server with minimal performance impact. 우리는 다음과 같은 공헌을합니다 : • 클라우드와 관련된 흥미로운 벤치 마크 및 워크로드의 교차 섹션에서 최신 하드웨어 및 소프트웨어를 사용하여 기본, 컨테이너 및 가상 시스템 환경의 최신 비교를 제공합니다. • HPC 및 서버 작업 부하에 대한 현재 가상화 옵션의 주요 성능 영향을 확인합니다. • 가상화 성능에 영향을 미치는 명확하지 않은 실제 문제에 대해 자세히 설명합니다. • 성능상의 영향을 최소화하면서 전체 서버 규모에서도 컨테이너가 실행 가능함을 보여줍니다. The rest of the paper is organized as follows. Section II describes Docker and KVM, providing necessary background to understanding the remainder of the paper. Section III describes and evaluates different workloads on the three environments. We review related work in Section IV, and finally, Section V concludes the paper. 논문의 나머지 부분은 다음과 같이 구성됩니다. 섹션 II는 Docker 및 KVM에 대해 설명하며 나머지 문서를 이해하는 데 필요한 배경 지식을 제공합니다. 섹션 III에서는 세 가지 환경에서 서로 다른 작업 부하를 설명하고 평가합니다. 우리는 IV 절의 관련 연구를 검토하고 마지막으로 V 절을 결론 짓는다. Unix traditionally does not strongly implement the principle of least privilege, viz., “Every program and every user of the system should operate using the least set of privileges necessary to complete the job.” and the least common mechanism principle, viz., “Every shared mechanism ... represents a potential information path between users and must be designed with great care to be sure it does not unintentionally compromise security.” [42]. Most objects in Unix, including the filesystem, processes, and the network stack are globally visible to all users. 유닉스는 전통적으로 최소한의 권한 원칙, 즉 "모든 프로그램과 모든 사용자는 작업을 완료하는 데 필요한 최소한의 권한을 사용하여 작동해야합니다."라는 원칙과 최소 공통 메커니즘 원리, 즉 " 모든 공유 메커니즘은 사용자 간의 잠재적 인 정보 경로를 나타내며 실수로 보안을 손상시키지 않도록주의 깊게 설계해야합니다. "[42] 파일 시스템, 프로세스 및 네트워크 스택을 포함하여 Unix의 대부분의 객체는 모든 사용자가 전체적으로 볼 수 있습니다. A problem caused by Unix’s shared global filesystem is the lack of configuration isolation. Multiple applications can have conflicting requirements for system-wide configuration settings. Shared library dependencies can be especially problematic since modern applications use many libraries and often different applications require different versions of the same library. When installing multiple applications on one operating system the cost of system administration can exceed the cost of the software itself. Unix의 공유 전역 파일 시스템으로 인해 생기는 문제는 구성 격리가 부족하다는 것입니다. 여러 응용 프로그램은 시스템 전체 구성 설정에 대한 요구 사항을 충족시킬 수 있습니다. 공유 라이브러리 의존성은 현대 응용 프로그램이 많은 라이브러리를 사용하고 종종 다른 응용 프로그램이 동일한 라이브러리의 다른 버전을 요구하기 때문에 특히 문제가 될 수 있습니다. 하나의 운영 체제에 여러 응용 프로그램을 설치하는 경우 시스템 관리 비용이 소프트웨어 자체의 비용을 초과 할 수 있습니다. These weaknesses in common server operating systems have led administrators and developers to simplify deployment by installing each application on a separate OS copy, either on a dedicated server or in a virtual machine. Such isolation reverses the status quo compared to a shared server with explicit action required for sharing any code, data, or configuration between applications. 이러한 일반적인 서버 운영 체제의 약점은 관리자와 개발자가 각 응용 프로그램을 전용 서버 또는 가상 컴퓨터의 별도 OS 복사본에 설치하여 배포를 단순화하도록 유도했습니다. 이러한 분리는 응용 프로그램 간에 코드, 데이터 또는 구성을 공유하는 데 필요한 명시적인 조치가있는 공유 서버와 비교하여 현상 유지를 취소합니다. Irrespective of the environment, customers want to get the performance they are paying for. Unlike enterprise consolidation scenarios where the infrastructure and workload are owned by the same company, in IaaS and PaaS there is an arms length relationship between the provider and the customer.This makes it difficult to resolve performance anomalies, so *aaS providers usually provision fixed units of capacity (CPU cores and RAM) with no oversubscription. A virtualization system needs to enforce such resource isolation to be suitable for cloud infrastructure use. 환경에 관계없이 고객은 지불하는 성능을 원합니다. 동일한 회사에서 인프라와 작업 부하를 소유하는 엔터프라이즈 통합 시나리오와 달리 IaaS와 PaaS에서는 공급자와 고객 간에 무기 길이 관계가 있습니다. 이로 인해 성능 이상을 해결하기가 어려워 지므로 일반적으로 고정 된 단위 초과 수용이없는 용량 (CPU 코어 및 RAM) 가상화 시스템은 클라우드 인프라 사용에 적합하도록 이러한 자원 격리를 시행해야합니다. Kernel Virtual Machine (KVM) [25] is a feature of Linux that allows Linux to act as a type 1 hypervisor [36], running an unmodified guest operating system (OS) inside a Linux process. KVM uses hardware virtualization features in recent processors to reduce complexity and overhead; for example, Intel VT-x hardware eliminates the need for complex ring compression schemes that were pioneered by earlier hypervisors like Xen [9] and VMware [8]. KVM supports both emulated I/O devices through QEMU [16] and paravirtual I/O devices using virtio [40]. The combination of hardware acceleration and paravirtual I/O is designed to reduce virtualization overhead to very low levels [31]. KVM supports live migration, allowing physical servers or even whole data centers to be evacuated for maintenance without disrupting the guest OS [14]. KVM is also easy to use via management tools such as libvirt [18]. KVM (Kernel Virtual Machine) [25]은 Linux가 유형 1 하이퍼 바이저 역할을하면서 Linux 프로세스 내에서 수정되지 않은 게스트 운영 체제 (OS)를 실행하는 Linux 기능입니다. KVM은 최근 프로세서에서 하드웨어 가상화 기능을 사용하여 복잡성과 오버 헤드를 줄입니다. 예를 들어 Intel VT-x 하드웨어를 사용하면 Xen [9] 및 VMware [8]와 같은 이전 하이퍼바이저에서 개척 된 복잡한 링 압축 스키마가 필요하지 않습니다. KVM은 QEMU [16] 및 virtio [40]를 사용하는 반 가상화 I / O 장치를 통해 에뮬레이트된 I/O 장치를 지원합니다. 하드웨어 가속과 반 가상화 I / O의 결합은 가상화 오버 헤드를 매우 낮게 줄이기 위해 고안되었습니다 [31]. KVM은 라이브 마이그레이션을 지원하므로 게스트 OS를 중단시키지 않고 유지 보수를 위해 물리적 서버 또는 전체 데이터 센터까지 대피시킬 수 있습니다 [14]. KVM은 libvirt [18]와 같은 관리 도구를 통해 쉽게 사용할 수 있습니다. Because a VM has a static number of virtual CPUs (vCPUs) and a fixed amount of RAM,its resource consumption is naturally bounded. A vCPU cannot use more than one real CPU worth of cycles and each page of vRAM maps to at most one page of physical RAM (plus the nested page table). KVM can resize VMs while running by “hot plugging” and “ballooning” vCPUs and vRAM,although this requires support from the guest operating system and is rarely used in the cloud. VM은 고정 된 수의 가상 CPU (vCPU)와 고정 된 RAM을 가지고 있기 때문에 자원 소비는 자연스럽게 제한됩니다. vCPU는 두 개 이상의 실제 CPU를 사용할 수 없으며 vRAM의 각 페이지는 최대 한 페이지의 실제 RAM (중첩 된 페이지 테이블 포함)에 매핑됩니다. KVM은 게스트 운영 체제의 지원이 필요하고 클라우드에서 거의 사용되지 않지만 vCPU 및 vRAM의 "핫 플러깅 (hot plugging)"및 "ballooning"기능으로 VM의 크기를 조정할 수 있습니다. Because each VM is a process, all normal Linux resource management facilities such as scheduling and cgroups (described in more detail later) apply to VMs. This simplifies implementation and administration of the hypervisor but complicates resource management inside the guest OS. Operating systems generally assume that CPUs are always running and memory has relatively fixed access time, but under KVM vCPUs can be descheduled without notification and virtual RAM can be swapped out, causing performance anomalies that can be hard to debug. VMs also have two levels of allocation and scheduling: one in the hypervisor and one in the guest OS. Many cloud providers eliminate these problems by not overcommitting resources, pinning each vCPU to a physical CPU, and locking all virtual RAM into real RAM. (Unfortunately, OpenStack has not yet enabled vCPU pinning, leading to uneven performance compared to proprietary public clouds.) This essentially eliminates scheduling in the hypervisor. Such fixed resource allocation also simplifies billing. 각 VM은 프로세스이기 때문에 스케쥴링 및 cgroup (자세한 내용은 나중에 설명 함)과 같은 모든 일반 Linux 자원 관리 기능이 VM에 적용됩니다. 이것은 하이퍼 바이저의 구현 및 관리를 단순화하지만 게스트 OS 내부의 자원 관리를 복잡하게 만듭니다. 운영 체제는 일반적으로 CPU가 항상 실행 중이며 메모리가 상대적으로 고정 된 액세스 시간을 유지한다고 가정하지만 KVM에서는 vCPU를 알리지 않고 일정을 예약 할 수 없으며 가상 RAM을 스왑 아웃 할 수있어 성능 이상이 발생하여 디버깅하기가 어려울 수 있습니다. VM은 또한 하이퍼 바이저와 게스트 OS에 두 가지 수준의 할당과 스케줄링을 제공합니다. 많은 클라우드 제공 업체는 리소스를 과도하게 사용하지 않고 각 vCPU를 실제 CPU에 고정하고 모든 가상 RAM을 실제 RAM에 고정시키지 않으므로 이러한 문제를 해결합니다. (안타깝게도 OpenStack은 아직 vCPU 고정을 활성화하지 않았기 때문에 독점적 인 공중 클라우드에 비해 성능이 고르지 않습니다.) 이는 기본적으로 하이퍼 바이저의 스케줄링을 제거합니다. 그러한 고정 된 자원 할당은 또한 청구를 단순화한다. VMs naturally provide a certain level of isolation and security because of their narrow interface; the only way a VM can communicate with the outside world is through a limited number of hypercalls or emulated devices, both of which are controlled by the hypervisor. This is not a panacea, since a few hypervisor privilege escalation vulnerabilities have been discovered that could allow a guest OS to “break out” of its VM “sandbox”. VM은 좁은 인터페이스로 인해 자연스럽게 격리 수준과 보안 수준을 제공합니다. VM이 외부 세계와 통신 할 수있는 유일한 방법은 하이퍼 바이저에 의해 제어되는 제한된 수의 하이퍼 콜 또는 에뮬레이트 된 장치를 사용하는 것입니다. 이는 게스트 OS가 VM "샌드 박스"를 "탈옥"시킬 수있는 몇 가지 하이퍼 바이저 권한 에스컬레이션 취약점이 발견 되었기 때문에 만병 통치약이 아닙니다. While VMs excel at isolation, they add overhead when sharing data between guests or between the guest and hypervisor. Usually such sharing requires fairly expensive marshaling and hypercalls. In the cloud, VMs generally access storage through emulated block devices backed by image files; creating, updating, and deploying such disk images can be time-consuming and collections of disk images with mostly duplicate contents can waste storage space. VM은 고립 상태에서 뛰어나지 만 게스트간에 또는 게스트와 하이퍼 바이저간에 데이터를 공유 할 때 오버 헤드가 가중됩니다. 일반적으로 이러한 공유에는 상당히 비싼 마샬링과 초 점이 필요합니다. 클라우드에서 VM은 일반적으로 이미지 파일로 백업 된 에뮬레이트 된 블록 장치를 통해 스토리지에 액세스합니다. 이러한 디스크 이미지를 생성, 업데이트 및 배포하는 데 많은 시간이 걸릴 수 있으며 대부분이 중복 된 내용으로 디스크 이미지를 수집하면 저장 공간이 낭비 될 수 있습니다. Rather than running a full OS on virtual hardware, container-based virtualization modifies an existing OS to provide extra isolation. Generally this involves adding a container ID to every process and adding new access control checks to every system call. Thus containers can be viewed as another level of access control in addition to the user and group permission system. In practice, Linux uses a more complex implementation described below. 가상 하드웨어에서 전체 OS를 실행하는 대신 컨테이너 기반 가상화는 기존 OS를 수정하여 추가 격리를 제공합니다. 일반적으로 이것은 모든 프로세스에 컨테이너 ID를 추가하고 모든 시스템 호출에 새로운 액세스 제어 검사를 추가하는 것과 관련됩니다. 따라서 컨테이너는 사용자 및 그룹 권한 시스템 외에도 다른 수준의 액세스 제어로 볼 수 있습니다. 실제로 Linux는 아래에 설명 된보다 복잡한 구현을 사용합니다. Linux containers are a concept built on the kernel namespaces feature, originally motivated by difficulties in dealing with high performance computing clusters [17]. This feature, accessed by the clone() system call, allows creating separate instances of previously-global namespaces. Linux implements filesystem, PID, network, user, IPC, and hostname namespaces. For example, each filesystem namespace has its own root directory and mount table, similar to chroot() but more powerful. Linux 컨테이너는 원래 커널 네임 스페이스 기능을 기반으로하는 개념으로 원래는 고성능 컴퓨팅 클러스터를 다루는데 어려움이있었습니다. clone () 시스템 호출에 의해 액세스되는이 기능을 사용하면 이전의 전역 네임 스페이스에 대한 별도의 인스턴스를 만들 수 있습니다. Linux는 파일 시스템, PID, 네트워크, 사용자, IPC 및 호스트 이름 네임 스페이스를 구현합니다. 예를 들어, 각 파일 시스템 네임 스페이스는 chroot ()와 비슷하지만 더 강력한 자체 루트 디렉토리와 마운트 테이블을 가지고 있습니다. Namespaces can be used in many different ways, but the most common approach is to create an isolated container that has no visibility or access to objects outside the container. Processes running inside the container appear to be running on a normal Linux system although they are sharing the underlying kernel with processes located in other namespaces. Containers can nest hierarchically[19],although this capability has not been much explored. 네임 스페이스는 여러 가지 방법으로 사용할 수 있지만 가장 일반적인 방법은 컨테이너 외부의 개체에 대한 가시성이나 액세스 권한이없는 격리 된 컨테이너를 만드는 것입니다. 컨테이너 내부에서 실행되는 프로세스는 기본 커널을 다른 네임스페이스에 있는 프로세스와 공유하지만 일반 Linux 시스템에서 실행중인 것처럼 보입니다. 이 기능은별로 탐구되지 않았지만 컨테이너는 계층 적으로 중첩 될 수 있습니다 [19]. Unlike a VM which runs a full operating system, a container can contain as little as a single process. A container that behaves like a full OS and runs init, inetd, sshd, syslogd, cron, etc. is called a system container while one that only runs an application is called an application container. Both types are useful in different circumstances. Since an application container does not waste RAM on redundant management processes it generally consumes less RAM than an equivalent system container or VM. Application containers generally do not have separate IP addresses, which can be an advantage in environments of address scarcity. 전체 운영 체제를 실행하는 VM과 달리 컨테이너에는 단일 프로세스가 포함될 수 있습니다. 전체 OS처럼 동작하고 init, inetd, sshd, syslogd, cron 등을 실행하는 컨테이너를 시스템 컨테이너라고하고 응용 프로그램 만 실행하는 컨테이너를 응용 프로그램 컨테이너라고합니다. 두 유형 모두 다른 상황에서 유용합니다. 응용 프로그램 컨테이너는 중복 관리 프로세스에서 RAM을 낭비하지 않으므로 일반적으로 동등한 시스템 컨테이너 또는 VM보다 RAM을 덜 소모합니다. 응용 프로그램 컨테이너에는 일반적으로 별도의 IP 주소가 없으므로 주소가 부족한 환경에서 이점이 될 수 있습니다. If total isolation is not desired, it is easy to share some resources among containers. For example, bind mounts allow a directory to appear in multiple containers, possibly in different locations. This is implemented efficiently in the Linux VFS layer. Communication between containers or between a container and the host (which is really just a parent namespace) is as efficient as normal Linux IPC. 전체 격리가 필요하지 않은 경우 컨테이너간에 일부 리소스를 공유하기가 쉽습니다. 예를 들어 바인드 마운트를 사용하면 디렉토리가 여러 위치에 표시 될 수 있습니다. 이것은 Linux VFS 계층에서 효율적으로 구현됩니다. 콘테이너들 사이의 또는 컨테이너와 호스트 사이의 통신 (실제로는 부모 네임 스페이스)은 일반적인 리눅스 IPC만큼 효율적입니다. The Linux control groups (cgroups) subsystem is used to group processes and manage their aggregate resource consumption. It is commonly used to limit the memory and CPU consumption of containers. A container can be resized by simply changing the limits of its corresponding cgroup. Cgroups also provide a reliable way of terminating all processes inside a container. Because a containerized Linux system only has one kernel and the kernel has full visibility into the containers there is only one level of resource allocation and scheduling. Linux 제어 그룹 (cgroup) 하위 시스템은 프로세스를 그룹화하고 총 자원 소비를 관리하는 데 사용됩니다. 일반적으로 컨테이너의 메모리 및 CPU 사용을 제한하는 데 사용됩니다. 컨테이너는 해당 cgroup의 제한을 간단히 변경하여 크기를 조정할 수 있습니다. Cgroup은 또한 컨테이너 내부의 모든 프로세스를 종료 할 수있는 안정적인 방법을 제공합니다. 컨테이너 화 된 Linux 시스템에는 하나의 커널 만 있고 커널에는 컨테이너에 대한 완전한 가시성이 있기 때문에 한 수준의 자원 할당 및 스케줄링 만 있습니다. An unsolved aspect of container resource management is the fact that processes running inside a container are not aware of their resource limits [27]. For example, a process can see all the CPUs in the system even if it is only allowed to run on a subset of them; the same applies to memory. If an application attempts to automatically tune itself by allocating resources based on the total system resources available it may overallocate when running in a resource-constrained container. As containers mature, this limitation is likely to be addressed. 컨테이너 자원 관리의 미해결 측면은 컨테이너 내부에서 실행되는 프로세스가 자원 제한을 인식하지 못한다는 사실이다 [27]. 예를 들어 프로세스는 하위 집합에서만 실행되도록 허용 되더라도 시스템의 모든 CPU를 볼 수 있습니다. 동일하게 메모리에 적용됩니다. 응용 프로그램이 사용 가능한 전체 시스템 자원을 기반으로 자원을 할당하여 자동으로 조정하려고하면 자원이 제한된 컨테이너에서 실행될 때 전체적으로 할당 될 수 있습니다. 컨테이너가 성숙함에 따라 이러한 제한이 해결 될 가능성이 있습니다. Securing containers tends to be simpler than managing Unix permissions because the container cannot access what it cannot see and thus the potential for accidentally over-broad permissions is greatly reduced. When using user namespaces, the root user inside the container is not treated as root outside the container, adding additional security. The primary type of security vulnerability in containers is system calls that are not namespace-aware and thus can introduce accidental leakage between containers. Because the Linux system call API set is huge, the process of auditing every system call for namespace related bugs is still ongoing. Such bugs can be mitigated (at the cost of potential application incompatibility) by whitelisting system calls using seccomp [5]. 컨테이너 보안은 Unix 권한을 관리하는 것보다 쉽습니다. 왜냐하면 컨테이너가 볼 수없는 것을 액세스 할 수 없기 때문에 실수로 광범위하게 퍼미션을 줄 가능성이 크게 줄어들 기 때문입니다. 사용자 이름 공간을 사용할 때 컨테이너 안의 루트 사용자는 컨테이너 외부에서 루트로 취급되지 않으므로 추가적인 보안이 추가됩니다. 컨테이너의 주요 보안 취약점 유형은 네임 스페이스를 인식하지 못하기 때문에 컨테이너간에 실수로 누수가 발생할 수있는 시스템 호출입니다. 리눅스 시스템 호출 API 세트가 거대하기 때문에 네임 스페이스 관련 버그에 대한 모든 시스템 호출을 감사하는 프로세스는 여전히 진행 중이다. 이러한 버그는 seccomp [5]를 사용하여 허용 된 시스템 호출에 의해 완화 될 수 있습니다 (잠재적 응용 프로그램 비 호환성을 희생 시키십시오). Several management tools are available for Linux containers, including LXC [48], systemd-nspawn [35], lmctfy [49], Warden [2], and Docker [45]. (Some people refer to Linux containers as “LXC”, but this causes confusion because LXC is only one of many tools to manage containers). Due to its feature set and ease of use, Docker has rapidly become the standard management tool and image format for containers. A key feature of Docker not present in most other container tools is layered filesystem images, usually powered by AUFS (Another UnionFS) [12]. AUFS provides a layered stack of filesystems and allows reuse of these layers between containers reducing space usage and simplifying filesystem management. A single OS image can be used as a basis for many containers while allowing each container to have its own overlay of modified files (e.g., app binaries and configuration files). In many cases, Docker container images require less disk space and I/O than equivalent VM disk images. This leads to faster deployment in the cloud since images usually have to be copied over the network to local disk before the VM or container can start. LXC [48], systemd-nspawn [35], lmctfy [49], Warden [2] 및 Docker [45]를 비롯한 여러 가지 관리 도구가 Linux 컨테이너에서 사용 가능합니다. (어떤 사람들은 리눅스 컨테이너를 "LXC"라고 부르지 만, LXC는 컨테이너를 관리하는 많은 도구 중 하나이기 때문에 혼란을 야기합니다. Docker는 기능 세트 및 사용 편의성으로 인해 컨테이너의 표준 관리 도구 및 이미지 형식이되었습니다. 대부분의 다른 컨테이너 도구에없는 Docker의 핵심 기능은 일반적으로 AUFS (Another UnionFS) [12]에 의해 구동되는 레이어 화 된 파일 시스템 이미지입니다. AUFS는 계층화 된 파일 시스템 스택을 제공하며 컨테이너 사이에서 이러한 계층을 재사용 할 수 있으므로 공간 사용을 줄이고 파일 시스템 관리를 단순화합니다. 하나의 OS 이미지는 여러 컨테이너의 기초로 사용되는 한편 각 컨테이너는 수정 된 파일 (예 : 앱 바이너리 및 구성 파일)의 오버레이를 가질 수 있습니다. 많은 경우 Docker 컨테이너 이미지는 동등한 VM 디스크 이미지보다 적은 디스크 공간과 I / O를 필요로합니다. VM이나 컨테이너를 시작하기 전에 일반적으로 이미지를 네트워크를 통해 로컬 디스크에 복사해야하기 때문에 클라우드에서의 빠른 배포가 가능합니다. Although this paper focuses on steady-state performance, other measurements [39] have shown than containers can start much faster than VMs (less than 1 second compared to 11 seconds on our hardware) because unlike VMs, containers do not need to boot another copy of the operating system. In theory CRIU [1] can perform live migration of containers, but it may be faster to kill a container and start a new one. 이 문서가 정상 상태 성능에 초점을 맞추고 있지만, VM과 달리 컨테이너가 다른 복사본을 부팅 할 필요가 없기 때문에 컨테이너가 VM보다 훨씬 빠르게 시작할 수 있다는 점 (39 초는 하드웨어보다 11 초보다 1 초 미만입니다) 운영 체제의 이론적으로 CRIU [1]는 컨테이너의 실시간 마이그레이션을 수행 할 수 있지만 컨테이너를 죽이고 새 컨테이너를 시작하는 것이 더 빠를 수도 있습니다. Performance has numerous aspects. We focus on the issue of overhead compared to native, non-virtualized execution because it reduces the resources available for productive work. Thus we investigate scenarios where one or more hardware resources are fully utilized and we measure workload metrics like throughput and latency to determine the overhead of virtualization. 성과에는 여러 측면이 있습니다. 우리는 생산적인 작업에 필요한 리소스를 줄이기 때문에 가상화되지 않은 원시 실행에 비해 오버 헤드 문제에 중점을 둡니다. 따라서 하나 이상의 하드웨어 리소스를 완벽하게 활용하고 처리량 및 대기 시간과 같은 작업 부하 메트릭을 측정하여 가상화의 오버 헤드를 결정하는 시나리오를 조사합니다. All of our tests were performed on an IBM System x3650 M4 server with two 2.4-3.0 GHz Intel Sandy Bridge-EP Xeon E5-2665 processors for a total of 16 cores (plus HyperThreading) and 256 GB of RAM. The two processors/sockets are connected by QPI links making this a non-uniform memory access (NUMA) system. This is a mainstream server configuration that is very similar to those used by popular cloud providers. We used Ubuntu 13.10 (Saucy) 64-bit with Linux kernel 3.11.0, Docker 1.0, QEMU 1.5.0, and libvirt 1.1.1. For consistency, all Docker containers used an Ubuntu 13.10 base image and all VMs used the Ubuntu 13.10 cloud image. 우리의 모든 테스트는 총 16 코어 (HyperThreading 포함) 및 256GB RAM을위한 2 개의 2.4GHz ~ 3.0GHz Intel Sandy Bridge-EP Xeon E5-2665 프로세서가 장착 된 IBM System x3650 M4 서버에서 수행되었습니다. 두 개의 프로세서 / 소켓은 QPI 링크로 연결되어 NUMA (Non-Uniform Memory Access) 시스템을 구성합니다. 이는 널리 사용되는 클라우드 공급자가 사용하는 것과 매우 유사한 주류 서버 구성입니다. Linux 커널 3.11.0, Docker 1.0, QEMU 1.5.0 및 libvirt 1.1.1과 함께 Ubuntu 13.10 (Saucy) 64 비트를 사용했습니다. 일관성을 위해 모든 Docker 컨테이너는 Ubuntu 13.10 기본 이미지를 사용했으며 모든 VM은 Ubuntu 13.10 Cloud 이미지를 사용했습니다. Power management was disabled for the tests by using the performance cpufreq governor. Docker containers were not restricted by cgroups so they could consume the full resources of the system under test. Likewise, VMs were configured with 32 vCPUs and adequate RAM to hold the benchmark’s working set. In some tests we explore the difference between stock KVM (similar to a default OpenStack configuration) and a highly-tuned KVM configuration (similar to public clouds like EC2). We use microbenchmarks to individually measure CPU, memory, network, and storage overhead. We also measure two real server applications: Redis and MySQL. performance cpufreq governor를 사용하여 테스트를 위해 전원 관리가 비활성화되었습니다. Docker 컨테이너는 cgroup에 의해 제한되지 않으므로 테스트중인 시스템의 전체 리소스를 사용할 수 있습니다. 마찬가지로 VM은 벤치 마크 작업 세트를 보유하기 위해 32 개의 vCPU와 적절한 RAM으로 구성되었습니다. 일부 테스트에서는 주식 KVM (기본 OpenStack 구성과 유사)과 고도로 조정 된 KVM 구성 (EC2와 같은 공용 클라우드와 유사) 간의 차이점을 탐색합니다. 우리는 마이크로 벤치 마크를 사용하여 CPU, 메모리, 네트워크 및 스토리지 오버 헤드를 개별적으로 측정합니다. Redis와 MySQL의 두 가지 실제 서버 응용 프로그램도 측정합니다. Compression is a frequently used component of cloud workloads. PXZ [11] is a parallel lossless data compression utility that uses the LZMA algorithm. We use PXZ 4.999.9beta (build 20130528) to compress enwik9 [29], a 1 GB Wikipedia dump that is often used for compression benchmarking. To focus on compression rather than I/O we use 32 threads, the input file is cached in RAM, and the output is piped to /dev/null. We use compression level 2. 압축은 클라우드 작업 부하에서 자주 사용되는 구성 요소입니다. PXZ [11]은 LZMA 알고리즘을 사용하는 병렬 무손실 데이터 압축 유틸리티입니다. 압축 벤치마킹에 자주 사용되는 1GB Wikipedia 덤프 인 enwik9 [29]를 압축하기 위해 PXZ 4.999.9beta (빌드 20130528)를 사용합니다. I / O보다는 압축에 초점을 맞추기 위해 32 개의 스레드를 사용하고, 입력 파일은 RAM에 캐시되고 출력은 / dev / null로 파이프됩니다. 우리는 압축 수준 2를 사용합니다. Table I shows the throughput of PXZ under different configurations. As expected, native and Docker performance are very similar while KVM is 22% slower. We note that tuning KVM by vCPU pinning and exposing cache topology makes little difference to the performance. While further experimentation is required to pinpoint the source of KVM overhead, we suspect it is caused by the extra TLB pressure of nested paging. PXZ may benefit from using large pages. 표 1은 다른 구성에서의 PXZ 처리량을 보여줍니다. 예상대로 기본 및 Docker 성능은 KVM이 22 % 더 느린 반면 매우 유사합니다. vCPU 고정 및 캐시 토폴로지 노출로 KVM을 조정하면 성능에 약간의 차이가 있음을 알 수 있습니다. KVM 오버 헤드의 원인을 정확히 찾아내는 데 더 많은 실험이 필요하지만, 중첩 된 페이징의 추가 TLB 압력으로 인한 것으로 의심됩니다. PXZ는 큰 페이지를 사용하면 도움이 될 수 있습니다. Linpack solves a dense system of linear equations using an algorithm that carries out LU factorization with partial pivoting [21]. The vast majority of compute operations are spent in double-precision floating point multiplication of a scalar with a vector and adding the results to another vector. The benchmark is typically based on a linear algebra library that is heavily optimized for the specific machine architecture at hand. We use an optimized Linpack binary (version 11.1.2.005)[3] based on the Intel Math Kernel Library (MKL). The Intel MKL is highly adaptive and optimizes itself based on both the available floating point resources (e.g., what form of multimedia operations are available), as well as the cache topology of the system. By default, KVM does not expose topology information to VMs, so the guest OS believes it is running on a uniform 32-socket system with one core per socket. Linpack은 부분 피벗을 사용하여 LU 분해를 수행하는 알고리즘을 사용하여 선형 방정식의 조밀 한 시스템을 해결합니다 [21]. 대다수의 연산 연산은 스칼라와 벡터의 배정도 부동 소수점 곱셈에 사용되며 그 결과를 다른 벡터에 더합니다. 벤치 마크는 일반적으로 특정 기계 아키텍처에 집중적으로 최적화 된 선형 대수 라이브러리를 기반으로합니다. 인텔 수학 커널 라이브러리 (MKL)를 기반으로 최적화 된 Linpack 바이너리 (버전 11.1.2.005) [3]를 사용합니다. 인텔 MKL은 적응력이 뛰어나고 사용 가능한 부동 소수점 리소스 (예 : 사용 가능한 멀티미디어 작업 유형) 및 시스템의 캐시 토폴로지를 기반으로 최적화됩니다. 기본적으로 KVM은 토폴로지 정보를 VM에 노출시키지 않으므로 게스트 OS는 소켓 당 하나의 코어가있는 균일 한 32 소켓 시스템에서 실행되고 있다고 생각합니다. Table I shows the performance of Linpack on Linux, Docker, and KVM. Performance is almost identical on both Linux and Docker–this is not surprising given how little OS involvement there is during the execution. However, untuned KVM performance is markedly worse, showing the costs of abstracting/hiding hardware details from a workload that can take advantage of it. By being unable to detect the exact nature of the system, the execution employs a more general algorithm with consequent performance penalties. Tuning KVM to pin vCPUs to their corresponding CPUs and expose the underlying cache topology increases performance nearly to par with native. 표 1은 Linux, Docker 및 KVM에서 Linpack의 성능을 보여줍니다. 성능은 Linux와 Docker에서 거의 동일합니다. 이는 실행 중에 OS가 거의 관여하지 않는다는 점을 감안하면 놀라운 일이 아닙니다. 그러나 조정되지 않은 KVM 성능은 현저하게 악화되어 하드웨어 세부 정보를 활용할 수있는 작업 부하에서 하드웨어 세부 정보를 추상화하거나 숨기는 데 드는 비용을 보여줍니다. 시스템의 정확한 특성을 감지 할 수 없으므로 실행은 성능상의 불이익을 초래하는보다 일반적인 알고리즘을 사용합니다. vCPU를 해당 CPU에 고정시키고 기본 캐시 토폴로지를 공개하도록 KVM을 조정하면 성능이 네이티브와 거의 동일 해집니다. We expect such behavior to be the norm for other similarly tuned, adaptive executions, unless the system topology is faithfully carried forth into the virtualized environment. The STREAM benchmark is a simple synthetic benchmark program that measures sustainable memory bandwidth when performing simple operations on vectors [21]. Performance is dominated by the memory bandwidth of the system with the working set engineered to be significantly larger than the caches. The main determinants of performance are the bandwidth to main memory, and to a much lesser extent, the cost of handling TLB misses (which we further reduce using large pages). The memory access pattern is regular and the hardware prefetchers typically latch on to the access pattern and prefetch data before it is needed. Performance is therefore gated by memory bandwidth and not latency. The benchmark has four components: COPY, SCALE, ADD and TRIAD that are described in Table II. STREAM 벤치 마크는 벡터에 대한 간단한 조작을 수행 할 때 지속 가능한 메모리 대역폭을 측정하는 간단한 합성 벤치 마크 프로그램입니다 [21]. 성능은 캐시보다 훨씬 더 크게 설계된 작업 집합을 사용하여 시스템의 메모리 대역폭에 의해 좌우됩니다. 성능의 주된 결정 요인은 메인 메모리에 대한 대역폭과 TLB 미스 (대용량 페이지를 사용하여 더 줄일 수 있음)를 처리하는 데 드는 비용입니다. 메모리 액세스 패턴은 규칙적이며 하드웨어 프리 페처는 일반적으로 액세스 패턴에 래치하여 필요한 전에 데이터를 프리 페치합니다. 따라서 성능은 대기 시간이 아닌 메모리 대역폭에 의해 제어됩니다. 벤치 마크는 표 II에 설명 된 COPY, SCALE, ADD 및 TRIAD의 네 가지 구성 요소로 구성됩니다. Table I shows the performance of Stream across the three execution environments. All four components of Stream perform regular memory accesses where once a page table entry is installed in the TLB, all data within the page is accessed before moving on to the next page. Hardware TLB prefetching also works very well for this workload. As a consequence, performance on Linux, Docker, and KVM is almost identical, with the median data exhibiting a difference of only 1.4% across the three execution environments. 표 1은 세 실행 환경에서의 스트림 성능을 보여줍니다. Stream의 네 가지 구성 요소 모두 일반 메모리 액세스를 수행합니다. 페이지 테이블 항목이 TLB에 설치되면 페이지 내의 모든 데이터에 액세스하여 다음 페이지로 이동합니다. 하드웨어 TLB 프리 페칭도이 워크로드에서 매우 잘 작동합니다. 결과적으로 Linux, Docker 및 KVM의 성능은 거의 동일하며 중앙값 데이터는 3 가지 실행 환경에서 1.4 %의 차이 만 나타냅니다. The Stream benchmark stresses the memory subsystem in a regular manner, permitting hardware prefetchers to bring in data from memory before it is used in computation. In contrast, the RandomAccess benchmark [21] is specially designed to stress random memory performance. The benchmark initializes a large section of memory as its working set, that is orders of magnitude larger than the reach of the caches or the TLB. Random 8-byte words in this memory section are read, modified (through a simple XOR operation) and written back. The random locations are generated by using a linear feedback shift register requiring no memory operations. As a result, there is no dependency between successive operations permitting multiple independent operations to be in flight through the system. RandomAccess typifies the behavior of workloads with large working sets and minimal computation such as those with in-memory hash tables and in-memory databases. Stream 벤치 마크는 메모리 서브 시스템을 일반적인 방식으로 강조하여 하드웨어 프리 페처가 메모리에서 데이터를 가져 와서 계산에 사용하도록 허용합니다. 대조적으로 RandomAccess 벤치 마크 [21]는 임의의 메모리 성능을 강조하기 위해 특별히 고안되었습니다. 벤치 마크는 메모리의 큰 부분을 작업 집합으로 초기화합니다. 즉 캐시 또는 TLB의 도달 범위보다 큰 순서입니다. 이 메모리 섹션의 무작위 8 바이트 워드는 읽고 (간단한 XOR 연산을 통해) 수정되고 다시 쓰여집니다. 랜덤 위치는 메모리 동작을 필요로하지 않는 선형 피드백 시프트 레지스터를 사용함으로써 생성된다. 결과적으로 시스템을 통해 여러 개의 독립적 인 작업을 수행 할 수 있도록하는 연속적인 작업 간에는 종속성이 없습니다. RandomAccess는 메모리 크기가 큰 해시 테이블과 메모리 내 데이터베이스가있는 작업 집합과 계산량이 최소 인 작업 부하의 동작을 나타냅니다. As with Stream, RandomAccess uses large pages to reduce TLB miss overhead. Because of its random memory access pattern and a working set that is larger than the TLB reach, RandomAccess significantly exercises the hardware page table walker that handles TLB misses. As Table I shows, On our two-socket system, this has the same overheads for both virtualized and non-virtualized environments. Stream과 마찬가지로 RandomAccess는 대형 페이지를 사용하여 TLB 누락 오 v 헤드를 줄입니다. 랜덤 메모리 액세스 패턴과 TLB 도달 범위보다 큰 작업 집합으로 인해 RandomAccess는 TLB 누락을 처리하는 하드웨어 페이지 테이블 워커를 상당히 연습합니다. 표 1에서 볼 수 있듯이 2 소켓 시스템에서는 가상화 환경과 비 가상화 환경에 동일한 오버 헤드가 있습니다. We used the nuttcp tool [7] to measure network bandwidth between the system under test and an identical machine connected using a direct 10 Gbps Ethernet link between two Mellanox ConnectX-2 EN NICs. We applied standard network tuning for 10 Gbps networking such as enabling TCP window scaling and increasing socket buffer sizes. As shown in Figure 1, Docker attaches all containers on the host to a bridge and connects the bridge to the network via NAT. In our KVM configuration we use virtio and vhost to minimize virtualization overhead. 우리는 테스트중인 시스템과 2 대의 Mellanox ConnectX-2 EN NIC 사이에 직접 10Gbps 이더넷 링크를 사용하여 연결된 동일한 시스템 사이의 네트워크 대역폭을 측정하기 위해 nuttcp 도구 [7]를 사용했습니다. 우리는 TCP 창 스케일링을 활성화하고 소켓 버퍼 크기를 늘리는 것과 같은 10Gbps 네트워킹에 표준 네트워크 튜닝을 적용했습니다. 그림 1과 같이 Docker는 호스트의 모든 컨테이너를 브리지에 연결하고 NAT를 통해 브리지를 네트워크에 연결합니다. KVM 구성에서는 virtio 및 vhost를 사용하여 가상화 오버 헤드를 최소화합니다. We used nuttcp to measure the goodput of a unidirectional bulk data transfer over a single TCP connection with standard 1500-byte MTU. In the client-to-server case the system under test (SUT) acts as the transmitter and in the server-to-client case the SUT acts as the receiver; it is necessary to measure both directions since TCP has different code paths for send and receive. All three configurations reach 9.3 Gbps in both the transmit and receive direction, very close to the theoretical limit of 9.41 Gbps due to packet headers. Due to segmentation offload, bulk data transfer is very efficient even given the extra layers created by different forms of virtualization. The bottleneck in this test is the NIC, leaving other resources mostly idle. In such an I/O-bound scenario, we determine overhead by measuring the amount of CPU cycles required to transmit and receive data. Figure 2 shows system-wide CPU utilization for this test, measured using perf stat -a. Docker’s use of bridging and NAT noticeably increases the transmit path length; vhost-net is fairly efficient at transmitting but has high overhead on the receive side. Containers that do not use NAT have identical performance to native Linux. In real network-intensive workloads, we expect such CPU overhead to reduce overall performance. 우리는 표준 1500 바이트 MTU를 사용하는 단일 TCP 연결을 통해 단방향 대량 데이터 전송의 굿풋을 측정하기 위해 nuttcp를 사용했습니다. 클라이언트 대 서버의 경우, 시험중인 시스템 (SUT)은 송신기 역할을하고 서버 투 클라이언트 (server-to-client)의 경우 SUT는 수신기 역할을한다. TCP는 송신과 수신을 위해 서로 다른 코드 경로를 가지고 있으므로 양방향을 측정 할 필요가 있습니다. 3 가지 구성 모두 전송 및 수신 방향 모두에서 9.3Gbps에 도달하며 패킷 헤더로 인해 이론적 한계 인 9.41Gbps에 매우 가깝습니다. 세분화 오프로드로 인해 대량의 데이터 전송은 다른 가상화 형식으로 생성 된 추가 레이어가있는 경우에도 매우 효율적입니다. 이 테스트의 병목 현상은 NIC이므로 다른 리소스가 대부분 유휴 상태입니다. 이러한 I / O 제한 시나리오에서는 데이터를 전송하고 수신하는 데 필요한 CPU 사이클 양을 측정하여 오버 헤드를 결정합니다. 그림 2는이 테스트에 대한 시스템 전체의 CPU 사용률을 perf stat -a를 사용하여 측정 한 결과입니다. Docker가 브리징 및 NAT를 사용하면 전송 경로 길이가 현저히 증가합니다. vhost-net은 전송시 상당히 효율적이지만 수신 측에 높은 오버 헤드가 있습니다. NAT를 사용하지 않는 컨테이너는 기본 Linux와 동일한 성능을 발휘합니다. 실제 네트워크 집약적 인 워크로드에서는 전반적인 성능을 저하시키기 위해 이러한 CPU 오버 헤드가 예상됩니다. Historically, Xen and KVM have struggled to provide line-rate networking due to circuitous I/O paths that sent every packet through userspace. This has led to considerable research on complex network acceleration technologies like polling drivers or hypervisor bypass. Our results show that vhost, which allows the VM to communicate directly with the host kernel, solves the network throughput problem in a straightforward way. With more NICs, we expect this server could drive over 40 Gbps of network traffic without using any exotic techniques. 역사적으로 Xen과 KVM은 사용자 공간을 통해 모든 패킷을 전송하는 순환 I / O 경로로 인해 회선 속도의 네트워킹을 제공하기 위해 애 쓰고 있습니다. 이로 인해 폴링 드라이버 나 하이퍼 바이저 바이 패스와 같은 복잡한 네트워크 가속 기술에 대한 상당한 연구가 이루어졌습니다. 우리의 결과는 VM이 호스트 커널과 직접 통신 할 수있게 해주는 가상 호스트가 네트워크 처리량 문제를 직접적으로 해결한다는 것을 보여줍니다. NIC가 많을수록이 서버는 이국적인 기술을 사용하지 않고도 40Gbps 이상의 네트워크 트래픽을 유발할 수 있습니다. We used the netperf request-response benchmark to measure round-trip network latency using similar configurations as the nuttcp tests in the previous section. In this case the system under test was running the netperf server (netserver) and the other machine ran the netperf client. The client sends a 100- byte request, the server sends a 200-byte response, and the client waits for the response before sending another request. Thus only one transaction is in flight at a time. 우리는 netperf 요청 - 응답 벤치 마크를 사용하여 이전 섹션의 nuttcp 테스트와 유사한 구성을 사용하여 왕복 네트워크 대기 시간을 측정했습니다. 이 경우 테스트중인 시스템은 netperf 서버 (netserver)를 실행 중이며 다른 시스템은 netperf 클라이언트를 실행했습니다. 클라이언트는 100 바이트 요청을 보내고 서버는 200 바이트 응답을 보내고 클라이언트는 다른 요청을 보내기 전에 응답을 기다립니다. 따라서 한 번에 하나의 트랜잭션 만 실행됩니다. Figure 3 shows the measured transaction latency for both TCP and UDP variants of the benchmark. NAT, as used in Docker, doubles latency in this test. KVM adds 30µs of overhead to each transaction compared to the non-virtualized network stack, an increase of 80%. TCP and UDP have very similar latency because in both cases a transaction consists of a single packet in each direction. Unlike as in the throughput test, virtualization overhead cannot be amortized in this case. 그림 3은 벤치 마크의 TCP 및 UDP 변형에 대해 측정 된 트랜잭션 대기 시간을 보여줍니다. Docker에서 사용되는 NAT는이 테스트에서 대기 시간을 두 배로 늘립니다. KVM은 가상화되지 않은 네트워크 스택에 비해 각 트랜잭션에 30μs의 오버 헤드를 추가합니다 (80 % 증가). TCP와 UDP는 두 경우 모두 트랜잭션이 각 방향의 단일 패킷으로 구성되어 있기 때문에 지연 시간이 매우 유사합니다. 처리량 테스트에서와 달리 가상화 오버 헤드는이 경우 상각 할 수 없습니다. SAN-like block storage is commonly used in the cloud to provide high performance and strong consistency. To test the overhead of virtualizing block storage, we attached a 20 TB IBM FlashSystem 840 flash SSD to our test server using two 8 Gbps Fibre Channel links to a QLogic ISP2532- based dual-port HBA with dm_multipath used to combine the two links. We created an ext4 filesystem on it using default settings. In the native case the filesystem was mounted normally while in the Docker test it was mapped into the container using the -v option (avoiding AUFS overhead). In the VM case the block device was mapped into the VM using virtio and mounted inside the VM. These configurations are depicted in Figure 4. We used fio [13] 2.0.8 with the libaio backend in O DIRECT mode to run several tests against a 16 GB file stored on the SSD. USing O DIRECT allows accesses to bypass the OS caches. SAN과 같은 블록 스토리지는 일반적으로 고성능과 강력한 일관성을 제공하기 위해 클라우드에 사용됩니다. 블록 스토리지 가상화의 오버 헤드를 테스트하기 위해 두 개의 링크를 결합하는 데 사용되는 dm_multipath와 함께 QLogic ISP2532 기반 듀얼 포트 HBA에 2 개의 8Gbps 파이버 채널 링크를 사용하여 테스트 서버에 20TB IBM FlashSystem 840 플래시 SSD를 연결했습니다. 우리는 기본 설정을 사용하여 ext4 파일 시스템을 만들었습니다. 네이티브의 경우 파일 시스템은 Docker 테스트에서 -v 옵션 (AUFS 오버 헤드를 피함)을 사용하여 컨테이너에 매핑되는 동안 정상적으로 마운트되었습니다. VM의 경우 블록 장치는 virtio를 사용하여 VM에 매핑되고 VM 내부에 마운트되었습니다. 이 구성은 그림 4에 묘사되어 있습니다. 우리는 SSD에 저장된 16GB 파일에 대해 여러 테스트를 실행하기 위해 O 직접 모드의 libaio 백엔드에서 fio [13] 2.0.8을 사용했습니다. USING O DIRECT는 액세스가 OS 캐시를 우회하도록 허용합니다. Figure 5 shows sequential read and write performance averaged over 60 seconds using a typical 1 MB I/O size. Docker and KVM introduce negligible overhead in this case, although KVM has roughly four times the performance variance as the other cases. Similar to the network, the Fibre Channel HBA appears to be the bottleneck in this test. 그림 5는 일반적인 1MB I / O 크기를 사용하여 60 초 동안 평균화 된 순차 읽기 및 쓰기 성능을 보여줍니다. Docker와 KVM은이 경우 무시할 수있는 오버 헤드를 발생시키지만 KVM은 다른 경우와 비교하여 약 4 배의 성능 차이를 보입니다. 네트워크와 마찬가지로이 테스트에서는 Fibre Channel HBA가 병목 현상이있는 것으로 보입니다. Figure 6 shows the performance of random read, write and mixed (70% read, 30% write) workloads using a 4 kB block size and concurrency of 128, which we experimentally determined provides maximum performance for this particular SSD. As we would expect, Docker introduces no overhead compared to Linux, but KVM delivers only half as many IOPS because each I/O operation must go through QEMU. While the VM’s absolute performance is still quite high, it uses more CPU cycles per I/O operation, leaving less CPU available for application work. Figure 7 shows that KVM increases read latency by 2-3x, a crucial metric for some real workloads. 그림 6은 4kB 블록 크기와 128의 동시성을 사용하여 무작위 읽기, 쓰기 및 혼합 (70 % 읽기, 30 % 쓰기) 작업 부하의 성능을 보여 주며,이 특정 SSD에 대해 최대 성능을 제공합니다. 기대했던대로 Docker는 Linux에 비해 오버 헤드가 없지만 각 I / O 작업은 QEMU를 거쳐야하기 때문에 KVM은 절반의 IOPS 만 제공합니다. VM의 절대 성능은 여전히 높지만 I / O 작업 당 더 많은 CPU 사이클을 사용하므로 응용 프로그램 작업에 사용할 수있는 CPU가 적습니다. 그림 7은 KVM이 실제 레이턴시의 중요한 지표 인 읽기 대기 시간을 2-3 배 증가시키는 것을 보여줍니다. We also note that this hardware configuration ought to be able to exceed 1.5 GB/s in sequential I/O and 350,000 IOPS in random I/O, so even the native case has significant unrealized potential that we did not manage to exploit while the hardware was on loan to us. 또한이 하드웨어 구성은 순차 I / O에서 1.5GB / s를 초과 할 수 있어야하고 임의 I / O에서 350,000 IOPS를 초과 할 수 있어야합니다. 따라서 원시 사례의 경우에도 우리가 관리하지 못했던 현저한 잠재력이 있습니다. 우리 한테 대출 했어. Memory-based key-value storage is commonly used in the cloud for caching, storing session information, and as a convenient way to maintain hot unstructured data sets. Operations tend to be simple in nature, and require a network round-trip between the client and the server. This usage model makes the application generally sensitive to network latency. The challenge is compounded given the large number of concurrent clients, each sending very small network packets to a number of servers. As a result, the server spends a sizable amount of time in the networking stack. 메모리 기반 키 - 값 저장소는 일반적으로 캐싱, 세션 정보 저장 및 비정형 데이터를 유지하는 편리한 방법으로 클라우드에서 사용됩니다. 운영은 본질적으로 단순한 경향이 있으며 클라이언트와 서버간에 네트워크 왕복이 필요합니다. 이 사용 모델은 응용 프로그램을 일반적으로 네트워크 대기 시간에 민감하게 만듭니다. 각 클라이언트가 매우 작은 네트워크 패킷을 여러 서버에 보내는 많은 수의 동시 클라이언트가 있으면이 문제는 더욱 복잡해집니다. 결과적으로 서버는 네트워킹 스택에 상당한 시간을 소비합니다. There are several such servers, for our evaluations, we selected Redis [43] due to its high performance, rich API and widespread use among PaaS providers (e.g., Amazon Elasticache, Google Compute Engine). We obtained Redis 2.8.13 from the main GitHub repository, and built it in our Ubuntu 13.10 platform. The resulting binaries are then used in each of the deployment modes: native, Docker and KVM. To improve performance, and given that Redis is a single-threaded application, we affinitize the container or VM to a core close to the network interface. The test consists of a number of clients issuing requests to the server. A mix of 50% read and 50% writes was used. Each client maintains a persistent TCP connection to the server and can pipeline up to 10 concurrent requests over that connection. Thus the total number of requests in flight is 10 times the number of clients. Keys were 10 characters long, and values were generated to average 50 bytes. This dataset shape is representative of production Redis users as described by Steinberg et. al. [47]. For each run, the dataset is cleared and then a deterministic sequence of operations is issued, resulting in the gradual creation of 150 million keys. Memory consumption of the Redis server peaks at 11 GB during execution. 이러한 서버가 몇 가지 있습니다. 평가를 위해 고성능, 풍부한 API 및 PaaS 제공 업체 (예 : Amazon Elasticache, Google Compute Engine) 간의 광범위한 사용으로 인해 Redis [43]를 선택했습니다. 주요 GitHub 저장소에서 Redis 2.8.13을 얻었고 우분투 13.10 플랫폼에이를 구축했습니다. 생성 된 바이너리는 각 배포 모드 (native, Docker 및 KVM)에서 사용됩니다. Redis는 단일 스레드 응용 프로그램이므로 성능을 향상시키기 위해 컨테이너 또는 VM을 네트워크 인터페이스에 가까운 코어에 연결합니다. 이 테스트는 서버에 요청을 보내는 많은 클라이언트로 구성됩니다. 50 % 읽기 및 50 % 쓰기의 혼합이 사용되었습니다. 각 클라이언트는 서버에 대한 지속적인 TCP 연결을 유지하며 해당 연결을 통해 최대 10 개의 동시 요청을 파이프 라인 할 수 있습니다. 따라서 비행중인 총 요청 수는 클라이언트 수의 10 배입니다. 키 길이는 10 자였으며 값은 평균 50 바이트로 생성되었습니다. 이 데이터 세트 모양은 Steinberg 등이 설명한대로 Redis 사용자의 생산을 대표합니다. al. [47]. 각각의 실행에 대해 데이터 세트가 지워지고 결정적 순서의 작업이 실행되어 1 억 5 천만 개의 키가 점진적으로 생성됩니다. 실행 중 Redis 서버의 메모리 사용량은 11GB로 최고입니다. Figure 8 shows the throughput (in requests per second) with respect to the number of client connections for the different deployment models. Figure 9 shows the corresponding average latencies (in µs) for each of the experiments. In the native deployment, the networking subsystem is quite sufficient to handle the load. So, as we scale the number of client connections, the main factor that limits the throughput of a Redis server is saturation of the CPU – note that Redis is a single-threaded, event-based application. In our platform, that occurs quickly at around 110 k request per second. Adding more clients results in requests being queued and an increase in the average latency. 그림 8에서는 여러 배포 모델에 대한 클라이언트 연결 수와 관련하여 처리량 (초당 요청 수)을 보여줍니다. 그림 9는 각 실험에 대한 해당 평균 대기 시간 (μs)을 보여줍니다. 네이티브 배포에서 네트워킹 하위 시스템은로드를 처리하기에 충분합니다. 따라서 클라이언트 연결 수를 조정할 때 Redis 서버의 처리량을 제한하는 주요 요소는 CPU의 채도입니다. Redis는 단일 스레드 이벤트 기반 응용 프로그램입니다. 우리 플랫폼에서는 초당 약 110 k 요청시 빠르게 발생합니다. 클라이언트를 추가하면 대기중인 요청이 발생하고 평균 대기 시간이 늘어납니다. A Redis server puts a lot of pressure in the networking and memory subsystems. When using Docker with the host networking stack, we can see that both throughput and latency are virtually the same as the native case. The story is quite different when using Docker with NAT enabled as shown in Figure 1. In this case the latency introduced grows with the number of packets received over the network. Whereas it is comparable to native with 4 concurrent connections (51µs or 1.05x that of native), it quickly grows once the number of connections increases (to over 1.11x with 100 connections). Additionally, NAT consumes CPU cycles, thus preventing the Redis deployment from reaching the peak performance seen by deployments with native networking stacks. Redis 서버는 네트워킹 및 메모리 하위 시스템에 많은 압박을 가하고 있습니다. Docker를 호스트 네트워킹 스택과 함께 사용하면 처리량과 대기 시간이 원래의 경우와 거의 동일하다는 것을 알 수 있습니다. 이 이야기는 그림 1과 같이 NAT가 설정된 Docker를 사용할 때 상당히 다릅니다.이 경우 네트워크를 통해 수신 된 패킷의 수와 함께 도입되는 대기 시간이 커집니다. 4 개의 동시 연결 (기본의 51μs 또는 1.05x)을 통해 네이티브와 비교할 수있는 반면, 연결 수가 증가하면 빠르게 증가합니다 (100 연결의 경우 1.11x 이상). 또한 NAT는 CPU주기를 소비하므로 Redis 배포가 네이티브 네트워킹 스택을 사용한 배포에서 볼 수있는 최고 성능에 미치지 못합니다. Similarly, when running in KVM, Redis appears to be network-bound. KVM adds approximately 83µs of latency to every transaction. We see that the VM has lower throughput at low concurrency but asymptotically approaches native performance as concurrency increases. Beyond 100 connections, the throughput of both deployments are practically identical. This is can be explained by Little’s Law; because network latency is higher under KVM, Redis needs more concurrency to fully utilize the system. This might be a problem depending on the concurrency level expected from the end user in a cloud scenario. 마찬가지로 KVM에서 실행될 때 Redis는 네트워크 바운드로 표시됩니다. KVM은 모든 트랜잭션에 약 83μs의 대기 시간을 추가합니다. VM은 낮은 동시성에서 낮은 처리량을 가지지 만 동시성이 증가함에 따라 원시 성능에 점근 적으로 접근한다는 것을 알 수 있습니다. 연결이 100 회 이상인 경우 두 배포의 처리량이 실질적으로 동일합니다. 이것은 Little의 법칙에 의해 설명 될 수 있습니다. KVM에서는 네트워크 대기 시간이 더 길기 때문에 Redis는 시스템을 완전히 활용하려면 더 많은 동시성이 필요합니다. 이는 클라우드 시나리오에서 최종 사용자가 예상하는 동시성 수준에 따라 문제가 될 수 있습니다. MySQL is a popular relational database that is widely used in the cloud and typically stresses memory, IPC, filesystem, and networking subsystems. We ran the SysBench [6] oltp benchmark against a single instance of MySQL 5.5.37. MySQL was configured to use InnoDB as the backend store and a 3GB cache was enabled; this cache is sufficient to cache all reads during the benchmark runs. The oltp benchmark uses a database preloaded with 2 million records and executes a fixed set of read/write transactions choosing between five SELECT queries, two UPDATE queries, a DELETE query and an INSERT. The measurements provided by SysBench are statistics of transaction latency and throughput in transactions per seconds. The number of clients was varied until saturation and ten runs were used to produce each data point. Five different configurations were measured: MySQL running normally on Linux (native), MySQL under Docker using host networking and a volume (Docker net=host volume), using a volume but normal Docker networking (Docker NAT volume), storing the database within the container filesystem (Docker NAT AUFS) and MySQL running under KVM; these different configurations are summarized in Table III. Although MySQL accesses the fileystem, our configuration has enough cache that it performed almost no actual disk I/O, making different KVM storage options moot. MySQL은 클라우드에서 널리 사용되고 널리 메모리, IPC, 파일 시스템 및 네트워킹 서브 시스템을 강조하는 널리 사용되는 관계형 데이터베이스입니다. 우리는 MySQL 5.5.37의 단일 인스턴스에 대해 SysBench [6] oltp 벤치 마크를 실행했습니다. MySQL은 InnoDB를 백엔드 저장소로 사용하도록 구성되었으며 3GB 캐시가 활성화되었습니다. 이 캐시는 벤치 마크 실행 중에 모든 읽기를 캐시하기에 충분합니다. oltp 벤치 마크는 2 백만 레코드가 사전 로드 된 데이터베이스를 사용하고 5 개의 SELECT 쿼리, 2 개의 UPDATE 쿼리, DELETE 쿼리 및 INSERT 중에서 선택하는 읽기 / 쓰기 트랜잭션 고정 세트를 실행합니다. SysBench가 제공하는 측정 값은 초당 트랜잭션의 트랜잭션 대기 시간 및 처리량 통계입니다. 포화 상태가 될 때까지 클라이언트 수를 변경하고 각 데이터 포인트를 생성하기 위해 10 회의 실행을 사용했습니다. Linux에서 정상적으로 실행되는 MySQL (기본), 호스트 네트워킹을 사용하는 Docker 아래의 MySQL 및 볼륨 (Docker net = 호스트 볼륨), 볼륨을 사용하지만 일반적인 Docker 네트워킹 (Docker NAT 볼륨), 데이터베이스를 컨테이너 파일 시스템 (Docker NAT AUFS) 및 KVM에서 실행되는 MySQL; 이러한 다른 구성은 표 3에 요약되어 있습니다. MySQL이 파일 시스템에 액세스하더라도 우리의 구성에는 실제 디스크 입출력을 거의 수행하지 않은 충분한 캐시가있어 다른 KVM 스토리지 옵션을 사용할 필요가 없습니다. Figure 10 shows transaction throughput as a function of the number of users simulated by SysBench. The right Y axis shows the loss in throughput when compared to native. 그림 10은 SysBench가 시뮬레이션 한 사용자 수에 따라 트랜잭션 처리량을 보여줍니다. 오른쪽 Y 축은 원래와 비교했을 때 처리량 손실을 나타냅니다. The general shape of this curve is what we would expect: throughput increases with load until the machine is saturated, then levels off with a little loss due to contention when overloaded. Docker has similar performance to native, with the difference asymptotically approaching 2% at higher concurrency. KVM has much higher overhead, higher than 40% in all measured cases. AUFS introduces significant overhead which is not surprising since I/O is going through several layers, as seen by comparing the Docker NAT volume and Docker NAT AUFS results. The AUFS overhead demonstrates the difference between virtualizing above the filesystem, as Docker does, and virtualizing below the filesystem in the block layer, as KVM does. We tested different KVM storage protocols and found that they make no difference in performance for an in-cache workload like this test. NAT also introduces a little overhead but this workload is not network-intensive. KVM shows a interesting result where saturation was achieved in the network but not in the CPUs (Figure 11). The benchmark generates a lot of small packets, so even though the network bandwidth is small, the network stack is not able to sustain the number of packets per second needed. Since the benchmark uses synchronous requests, a increase in latency also reduces throughput at a given concurrency level. 이 커브의 일반적인 모양은 예상대로입니다. 처리량이 부하에 따라 포화 상태가 될 때까지 처리량이 증가한 다음 과부하되었을 때 경합으로 인해 약간의 손실로 수평이 떨어집니다. Docker는 네이티브와 비슷한 성능을 제공하며, 동시성이 높을수록 점차적으로 2 %에 근접합니다. KVM은 모든 측정 된 케이스에서 40 % 이상의 높은 오버 헤드를 가지고 있습니다. AUX는 Docker NAT 볼륨과 Docker NAT AUFS 결과를 비교하여 볼 때 I / O가 여러 계층을 거쳐야하기 때문에 상당한 오버 헤드가 발생합니다. AUFS 오버 헤드는 Docker가하는 것처럼 파일 시스템을 가상화하는 것과 KVM처럼 블록 계층의 파일 시스템을 가상화하는 것의 차이점을 보여줍니다. 우리는 다른 KVM 스토리지 프로토콜을 테스트 한 결과,이 테스트와 같이 캐시 내 작업 부하의 성능에 아무런 차이가 없다는 것을 발견했습니다. NAT는 약간의 오버 헤드를 가져 오지만이 워크로드는 네트워크를 많이 사용하지 않습니다. KVM은 포화가 네트워크에서는 달성되었지만 CPU에서는 달성되지 않은 흥미로운 결과를 보여줍니다 (그림 11). 벤치 마크는 많은 작은 패킷을 생성하므로 네트워크 대역폭이 작더라도 네트워크 스택은 필요한 초당 패킷 수를 유지할 수 없습니다. 벤치 마크에서는 동기식 요청을 사용하므로 대기 시간이 증가하면 주어진 동시성 수준에서 처리량도 감소합니다. Figure 12 shows latency as a function of the number of users simulated by SysBench. As expected the latency increases with load, but interestingly Docker increases the latency faster for moderate levels of load which explains the lower throughput at low concurrency levels. The expanded portion of the graph shows that native Linux is able to achieve higher peak CPU utilization and Docker is not able to achieve that same level, a difference of around 1.5%. This result shows that Docker has a small but measurable impact. 그림 12는 SysBench에 의해 시뮬레이션 된 사용자 수에 따라 대기 시간을 보여줍니다. 예상대로 대기 시간은 부하와 함께 증가하지만 흥미롭게도 Docker는 중간 수준의 부하에 대해 대기 시간을 빠르게 늘려 낮은 동시 처리 수준에서 낮은 처리량을 설명합니다. 그래프의 확대 부분은 기본 Linux가 더 높은 CPU 사용률을 달성 할 수 있고 Docker가 동일한 수준을 달성 할 수 없음을 보여 주며 약 1.5 %의 차이가 있습니다. 이 결과는 Docker가 작지만 측정 할 수있는 영향을 미친다는 것을 보여줍니다. Figure 11 plots throughput against CPU utilization. Comparing Figures 10 through Figure 12, we note that the lower throughput for the same concurrency for Docker and Docker with NAT does not create an equivalent increase in CPU consumption. The difference in throughput is minimal when the same amount of CPU is used. The latency otherwise is not the same with Docker being substantially higher for lower values of concurrency, we credit this behavior to mutex contention. Mutex contention also prevents MySQL from fully utilizing the CPU in all cases, but it is more pronounced in the Docker case since the transactions take longer. Figure 11 shows clearly that in the case of VM the limitation is not CPU but network but the overhead of KVM is apparent even at lower numbers of clients. 그림 11은 CPU 사용률에 대한 처리량을 보여줍니다. 그림 10에서 그림 12를 비교하면 NAT가있는 Docker와 Docker의 동일한 동시성에 대한 처리량이 더 낮 으면 CPU 사용량이 똑같이 증가하지 않는다는 것을 알 수 있습니다. 같은 양의 CPU가 사용될 때 처리량의 차이가 최소화됩니다. 그렇지 않으면 Docker가 더 낮은 동시성 값에 대해 더 높은 레이턴시를 가지지 않는다면, 우리는이 동작을 뮤텍스 경합에 대해 생각해 볼 것입니다. 뮤텍스 (mutex) 경합은 MySQL이 모든 경우에 CPU를 최대한 활용하는 것을 막아 주지만, 트랜잭션이 오래 걸리기 때문에 Docker 사건에서 더 두드러진다. 그림 11은 VM의 경우 제한이 CPU가 아니지만 네트워크이지만 KVM의 오버 헤드는 더 적은 수의 클라이언트에서도 분명하다는 것을 보여줍니다. The throughput-latency curves in Figure 13 make it easy to compare the alternatives given a target latency or throughput. One interesting aspect of this curve is the throughput reduction caused by higher context switching in several cases when more clients are introduced after saturation. Since there is more idle time in the Docker case a higher overhead does not impact throughput for the number of clients used in the benchmark. 그림 13의 처리량 대기 시간 곡선은 대상 대기 시간 또는 처리량을 고려하여 대안을 쉽게 비교할 수있게합니다. 이 곡선의 한 가지 흥미로운 점은 포화 상태에서 더 많은 클라이언트를 도입 할 때 컨텍스트 스위칭이 높아지는 경우에 발생하는 처리량 감소입니다. Docker의 경우 유휴 시간이 더 길기 때문에 벤치 마크에서 사용되는 클라이언트의 처리량에 영향을 미치지 않습니다. We see several general trends in these results. As we expect given their implementations, containers and VMs impose almost no overhead on CPU and memory usage; they only impact I/O and OS interaction. This overhead comes in the form of extra cycles for each I/O operation, so small I/Os suffer much more than large ones. This overhead increases I/O latency and reduces the CPU cycles available for useful work, limiting throughput. Unfortunately, real applications often cannot batch work into large I/Os. 우리는 이러한 결과에서 몇 가지 일반적인 추세를 보았습니다. 구현을 고려할 때 컨테이너와 VM은 CPU 및 메모리 사용에 거의 아무런 오버 헤드도 부과하지 않습니다. I / O 및 OS 상호 작용에만 영향을 미칩니다. 이 오버 헤드는 각 I / O 작업에 여분의 사이클 형태로 나타나므로 작은 I / O는 큰 것보다 훨씬 많은 고통을 겪습니다. 이 오버 헤드로 인해 I / O 대기 시간이 증가하고 유용한 작업에 사용할 수있는 CPU 사이클이 줄어 처리량이 제한됩니다. 불행하게도 실제 응용 프로그램은 대개 대량 I / O로 일괄 처리 할 수 없습니다. Docker adds several features such as layered images and NAT that make it easier to use than LXC-style raw containers, but these features come at a performance cost. Thus Docker using default settings may be no faster than KVM. Applications that are filesystem or disk intensive should bypass AUFS by using volumes. NAT overhead can be easily eliminated by using –net=host, but this gives up the benefits of network namespaces. Ultimately we believe that the model of one IP address per container as proposed by the Kubernetes project can provide flexibility and performance. Docker는 계층화 된 이미지 및 NAT와 같은 몇 가지 기능을 추가하여 LXC 스타일의 원시 컨테이너보다 사용하기 쉽지만 이러한 기능은 성능 비용이 들게됩니다. 따라서 기본 설정을 사용하는 Docker는 KVM보다 빠르지 않을 수 있습니다. 파일 시스템 또는 디스크 집중 응용 프로그램은 볼륨을 사용하여 AUFS를 우회해야합니다. NAT 오버 헤드는 -net = host를 사용하여 쉽게 제거 할 수 있지만 네트워크 네임 스페이스의 이점을 포기합니다. 궁극적으로 우리는 Kubernetes 프로젝트에서 제안한 컨테이너 당 하나의 IP 주소 모델이 유연성과 성능을 제공 할 수 있다고 믿습니다. While KVM can provide very good performance, its configurability is a weakness. Good CPU performance requires careful configuration of large pages, CPU model, vCPU pinning, and cache topology; these features are poorly documented and required trial and error to configure. We advise readers to avoid using qemu-kvm directly and instead use libvirt since it simplifies KVM configuration. Even on the latest version of Ubuntu we were unable to get vhost scsi to work, so there is still room for improvement. This complexity represents a barrier to entry for any aspiring cloud operator, whether public or private. 대형 페이지, CPU 모델, vCPU 고정 및 캐시 토폴로지의 신중한 구성이 필요합니다. 이러한 기능은 제대로 문서화되지 않았으므로 시행 착오를 거쳐 구성해야합니다. 독자들은 qemu-kvm을 직접 사용하지 말고 libvirt를 사용하여 KVM 구성을 단순화하므로 권장합니다. Ubuntu의 최신 버전에서도 vhost-scsi를 사용할 수 없었으므로 여전히 개선의 여지가 있습니다. 이러한 복잡성은 공개 또는 비공개 여부에 관계없이 모든 클라우드 운영자의 진입 장벽을 나타냅니다. The Multics [32] project set out to build utility computing infrastructure in the 1960s. Although Multics never saw widespread use and cloud computing couldn’t take off until the Internet became widespread, the project produced ideas like the end-to-end argument [41] and a set of security principles [42] that are still relevant today. Multics [32] 프로젝트는 1960 년대에 유틸리티 컴퓨팅 인프라를 구축하기 시작했습니다. Multics는 널리 사용 된 적이 없었고 인터넷이 널리 보급 될 때까지는 클라우드 컴퓨팅이 이륙 할 수 없었지만 프로젝트는 오늘날에도 여전히 관련이있는 엔드 투 엔드 (end-to-end) 논쟁 [41]과 일련의 보안 원칙 [42]과 같은 아이디어를 만들어 냈습니다. Virtual machines were introduced on IBM mainframes in the 1970s [20] and then reinvented on x86 by VMware [38] in the late 1990s. Xen [15] and KVM [25] brought VMs to the open source world in the 2000s. The overhead of virtual machines was initially high but has been steadily reduced over the years due to hardware and software optimizations [25, 31]. 가상 머신은 1970 년대에 IBM 메인 프레임에 소개되었고 [20], 1990 년 후반에 VMware [38]에 의해 x86으로 재발명되었습니다. Xen [15]과 KVM [25]은 VM을 2000 년대 오픈 소스 세계로 가져 왔습니다. 가상 머신의 오버 헤드는 처음에는 높았지만 하드웨어 및 소프트웨어 최적화로 인해 수년 동안 꾸준히 감소했습니다 [25, 31]. Operating system level virtualization also has a long history. In some sense the purpose of an operating system is to virtualize hardware resources so they may be shared, but Unix traditionally provides poor isolation due to global namespaces for the file system, processes, and the network. Capability based OSes [22] provided container-like isolation by virtue of not having any global namespaces to begin with, but they died out commercially in the 1980s. Plan 9 introduced per-process file system namespaces [34] and bind mounts that inspired the namespace mechanism that underpins Linux containers. 운영 체제 수준의 가상화 또한 오랜 역사를 가지고 있습니다. 어떤 의미에서는 운영 체제의 목적은 하드웨어 리소스를 가상화하여 공유되도록하는 것이지만 유닉스는 전통적으로 파일 시스템, 프로세스 및 네트워크에 대한 글로벌 네임 스페이스로 인해 격리를 제공하지 않습니다. Capability based OSes [22]는 세계적인 네임 스페이스가 없기 때문에 컨테이너와 같은 격리를 제공했지만 1980 년대 상업적으로 사라졌습니다. Plan 9는 프로세스 별 파일 시스템 네임 스페이스 [34]와 바인드 마운트를 도입하여 Linux 컨테이너를 뒷받침하는 네임 스페이스 메커니즘에 영감을주었습니다. The Unix chroot() feature has long been used to implement rudimentary “jails” and the BSD jails feature extends the concept. Solaris 10 introduced and heavily promoted Zones [37], a modern implementation of containers, in 2004. Cloud provider Joyent has offered IaaS based on Zones since 2008, although with no effect on the overall cloud market. 유닉스 chroot () 기능은 오랫동안 기초적인 "감옥"을 구현하는 데 사용되어 왔으며 BSD 감옥 기능은 개념을 확장합니다. Solaris 10은 2004 년에 컨테이너의 최신 구현 인 Zones [37]를 도입하고 크게 홍보했습니다. Joyent의 클라우드 공급자는 전반적인 클라우드 시장에 영향을 미치지 않더라도 2008 년부터 ZaS를 기반으로 IaaS를 제공했습니다. Linux containers have a long and winding history. The Linux-VServer [46] project was an initial implementation of “virtual private servers” in 2001 that was never merged into mainstream Linux but was used successfully in PlanetLab. The commercial product Virtuozzo and its open-source version OpenVZ [4] have been used extensively for Web hosting but were also not merged into Linux. Linux finally added native containerization starting in 2007 in the form of kernel namespaces and the LXC userspace tool to manage them. 리눅스 컨테이너는 길고 굴곡 진 역사가 있습니다. Linux-VServer [46] 프로젝트는 2001 년에 "가상 사설 서버 (virtual private server)"를 최초로 구현 한 것으로 주류 리눅스로 합병되지는 않았지만 PlanetLab에서 성공적으로 사용되었습니다. 버추 오조 (Virtuozzo) 상용 제품과 오픈 소스 버전 인 OpenVZ [4]는 웹 호스팅에 광범위하게 사용되었지만 리눅스에도 통합되지 않았다. Linux는 마침내 2007 년부터 커널 네임 스페이스 및 LXC 사용자 공간 도구의 형태로 네이티브 컨테이너 화를 추가하여이를 관리합니다. Platform as a service providers like Heroku introduced the idea of using containers to efficiently and repeatably deploy applications [28]. Rather than viewing a container as a virtual server, Heroku treats it more like a process with extra isolation. The resulting application containers have very little overhead, giving similar isolation as VMs but with resource sharing like normal processes. Google also pervasively adopted application containers in their internal infrastructure [19]. Heroku competitor DotCloud (now known as Docker Inc.) introduced Docker [45] as a standard image format and management system for these application containers. Heroku와 같은 서비스 제공 업체 인 플랫폼은 컨테이너를 사용하여 효율적이고 반복적으로 응용 프로그램을 배포하는 아이디어를 도입했습니다 [28]. Heroku는 컨테이너를 가상 서버로 보는 대신 추가 격리 된 프로세스로 처리합니다. 결과로 생성되는 애플리케이션 컨테이너는 오버 헤드가 거의 없으므로 VM과 유사한 격리를 제공하지만 일반적인 프로세스처럼 리소스를 공유합니다. Google은 또한 내부 인프라에서 애플리케이션 컨테이너를 광범위하게 채택했습니다 [19]. Heroku 경쟁 업체 인 DotCloud (현재 Docker Inc.)는 이러한 응용 프로그램 컨테이너의 표준 이미지 형식 및 관리 시스템으로 Docker [45]를 도입했습니다. There has been extensive performance evaluation of hypervisors, but mostly compared to other hypervisors or nonvirtualized execution. [23, 24, 31] 하이퍼 바이저에 대한 광범위한 성능 평가가 있었지만 대부분 다른 하이퍼 바이저 또는 비 가상화 된 실행과 비교되었습니다. [23,24,31] Past comparison of VMs vs. containers [30, 33, 44, 46, 50] mostly used older software like Xen and out-of-tree container patches. VM과 컨테이너 [30, 33, 44, 46, 50]의 과거 비교는 대부분 Xen 및 트리 외부 컨테이너 패치와 같은 구형 소프트웨어를 사용했습니다. Both VMs and containers are mature technology that have benefited from a decade of incremental hardware and software optimizations. In general, Docker equals or exceeds KVM performance in every case we tested. Our results show that both KVM and Docker introduce negligible overhead for CPU and memory performance (except in extreme cases). For I/O intensive workloads, both forms of virtualization should be used carefully. VM과 컨테이너는 모두 10 년 간의 점진적 하드웨어 및 소프트웨어 최적화의 이점을 얻은 성숙한 기술입니다. 일반적으로 Docker는 테스트 할 때마다 KVM 성능과 동일하거나 그 이상입니다. 우리의 결과는 KVM과 Docker가 CPU 및 메모리 성능에 대한 무시할 수없는 오버 헤드를 초래한다는 것을 보여줍니다 (극단적 인 경우 제외). I / O 집약적 인 작업 부하의 경우 두 가지 가상화 형식을 신중하게 사용해야합니다. We find that KVM performance has improved considerably since its creation. Workloads that used to be considered very challenging, like line-rate 10 Gbps networking, are now possible using only a single core using 2013-era hardware and software. Even using the fastest available forms of paravirtualization, KVM still adds some overhead to every I/O operation; this overhead ranges from significant when performing small I/Os to negligible when it is amortized over large I/Os. Thus, KVM is less suitable for workloads that are latency-sensitive or have high I/O rates. These overheads significantly impact the server applications we tested. 우리는 KVM 성능이 창안 이후로 상당히 향상되었음을 알게되었습니다. 라인 속도 10Gbps 네트워킹과 같이 매우 어려웠던 작업 부하는 이제 2013 년 하드웨어 및 소프트웨어를 사용하는 단일 코어 만 사용하여 가능합니다. 사용 가능한 가장 빠른 형태의 반 가상화를 사용하더라도 KVM은 모든 I / O 작업에 약간의 오버 헤드를 추가합니다. 이 오버 헤드는 작은 I / O를 수행 할 때 중요한 것부터 큰 I / O에 대해 상각 할 때 무시할 수있는 것까지 다양합니다. 따라서 KVM은 대기 시간에 민감하거나 I / O 속도가 높은 작업 부하에 적합하지 않습니다. 이러한 오버 헤드는 테스트 한 서버 응용 프로그램에 큰 영향을 미칩니다. Although containers themselves have almost no overhead, Docker is not without performance gotchas. Docker volumes have noticeably better performance than files stored in AUFS. Docker’s NAT also introduces overhead for workloads with high packet rates. These features represent a tradeoff between ease of management and performance and should be considered on a case-by-case basis. 컨테이너 자체에는 거의 오버 헤드가 없지만 Docker는 성능상의 문제가 없습니다. Docker 볼륨은 AUFS에 저장된 파일보다 눈에 띄게 나은 성능을 제공합니다. Docker의 NAT는 또한 높은 패킷 속도의 작업 부하에 대한 오버 헤드를 발생시킵니다. 이러한 기능은 관리의 용이성과 성능 간의 균형을 나타내며 사례별로 고려해야합니다. In some sense the comparison can only get worse for containers because they started with near-zero overhead and VMs have gotten faster over time. If containers are to be widely adopted they must provide advantages other than steady-state performance. We believe the combination of convenience, faster deployment, elasticity, and performance is likely to become compelling in the near future. 어떤 의미에서는 컨테이너가 0에 가까운 오버 헤드로 시작하고 시간이 지남에 따라 VM이 빨라 졌기 때문에 비교는 컨테이너에 대해서만 악화 될 수 있습니다. 컨테이너를 널리 채택하려는 경우 정상 상태 성능 이외의 이점을 제공해야합니다. 가까운 시일 내에 편의성, 신속한 배치, 탄력성 및 성능의 결합이 매력적으로 나타날 것입니다. Our results can give some guidance about how cloud infrastructure should be built. Conventional wisdom (to the extent such a thing exists in the young cloud ecosystem) says that IaaS is implemented using VMs and PaaS is implemented using containers. We see no technical reason why this must be the case, especially in cases where container-based IaaS can offer better performance or easier deployment. Containers can also eliminate the distinction between IaaS and “bare metal” non-virtualized servers [10, 26] since they offer the control and isolation of VMs with the performance of bare metal. Rather than maintaining different images for virtualized and non virtualized servers, the same Docker image could be efficiently deployed on anything from a fraction of a core to an entire machine. 우리의 결과는 클라우드 인프라 구축 방법에 대한 지침을 제공 할 수 있습니다. 기존의 지혜 (젊은 클라우드 생태계에 그러한 일이 존재하는 정도까지)는 IaaS가 VM을 사용하여 구현되고 PaaS가 컨테이너를 사용하여 구현된다고 말합니다. 특히 컨테이너 기반 IaaS가 더 나은 성능을 제공하거나보다 쉽게 배포 할 수있는 경우 기술적 이유가 없습니다. 또한 컨테이너는 IaaS와 "베어 메탈 (bare metal)"가상화되지 않은 서버 [10, 26] 사이의 구분을 제거 할 수 있습니다. 베어 메탈 성능으로 VM을 제어하고 격리하기 때문입니다. 가상화 및 비 가상화 서버에 대해 서로 다른 이미지를 유지하는 대신 동일한 Docker 이미지를 코어의 일부에서 전체 시스템에 효율적으로 배포 할 수 있습니다. We also question the practice of deploying containers inside VMs, since this imposes the performance overheads of VMs while giving no benefit compared to deploying containers directly on non-virtualized Linux. If one must use a VM, running it inside a container can create an extra layer of security since an attacker who can exploit QEMU would still be inside the container. 우리는 또한 VM 내부에 컨테이너를 배치하는 관행에 의문을 제기합니다. 이것은 VM의 성능 오버 헤드를 부과하는 동시에 가상화되지 않은 Linux에 직접 컨테이너를 배치하는 것과 비교할 때 이점이 없기 때문입니다. VM을 사용해야하는 경우 컨테이너 내부에서이를 실행하면 QEMU를 활용할 수있는 공격자가 여전히 컨테이너 내부에 있으므로 보안 계층이 추가로 생성 될 수 있습니다. Although today’s typical servers are NUMA, we believe that attempting to exploit NUMA in the cloud may be more effort than it is worth. Limiting each workload to a single socket greatly simplifies performance analysis and tuning. Given that cloud applications are generally designed to scale out and the number of cores per socket increases over time, the unit of scaling should probably be the socket rather than the server. This is also a case against bare metal, since a server running one container per socket may actually be faster than spreading the workload across sockets due to the reduced cross-traffic. 오늘날의 일반적인 서버는 NUMA이지만 클라우드에서 NUMA를 악용하려는 시도는 가치보다 많은 노력 일 수 있습니다. 각 작업 부하를 단일 소켓으로 제한함으로써 성능 분석 및 튜닝을 크게 단순화합니다. 클라우드 애플리케이션은 일반적으로 수평 확장을 위해 설계되었으며 소켓 당 코어 수가 시간이 지남에 따라 증가하므로 스케일링 단위는 서버가 아닌 소켓이어야합니다. 베어 메탈에 대한 경우이기도합니다. 소켓 당 하나의 컨테이너를 실행하는 서버가 교차 트래픽이 줄어들어 실제로 소켓을 통해 작업 부하가 분산되는 것보다 빠르기 때문입니다. 이 논문에서 우리는 하나의 VM 또는 전체 서버를 소비하는 컨테이너를 생성; 클라우드에서는 서버를 더 작은 단위로 나누는 것이 더 일반적입니다. 이로 인해 조사 대상에 포함되는 몇 가지 추가 항목이 있습니다. 동일한 서버에서 여러 작업 부하가 실행될 때의 성능 격리, 컨테이너 및 VM의 실시간 크기 조정, 확장 및 스케일 아웃 간의 절충, 실시간 마이그레이션과 재시작 사이의 절충입니다. The scripts to run the experiments from this paper are available at https://github.com/thewmf/kvm-docker-comparison.ABSTRACT
1. INTRODUCTION
2. BACKGROUND
A. Motivation and requirements for cloud virtualization
B. KVM
C. Linux containers
3. EVALUATION
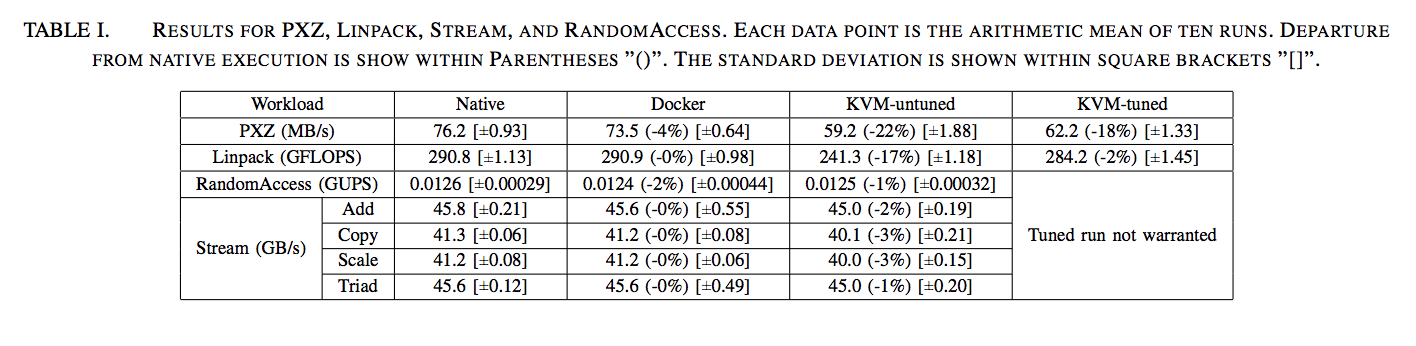
A. CPU-PXZ
B. HPC_Linpack
시스템 토폴로지가 가상화 된 환경으로 충실하게 이행되지 않는 한 이와 유사한 동작이 유사하게 조정되고 적용 가능한 실행에 대한 표준이 될 것으로 기대합니다.C. Memory bandwidth - Stream
D. Random Memory Access - Random Access
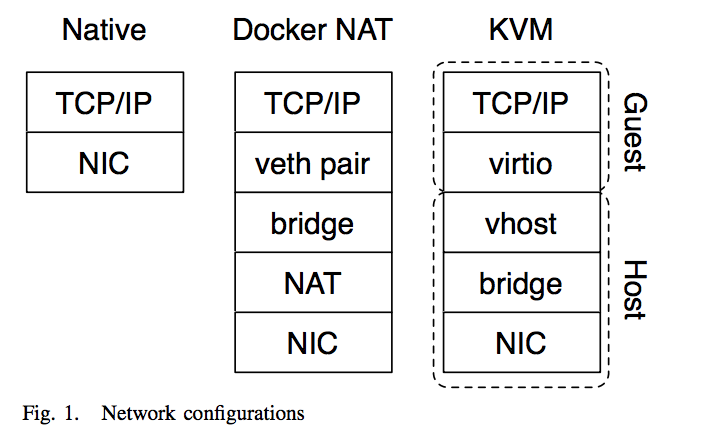
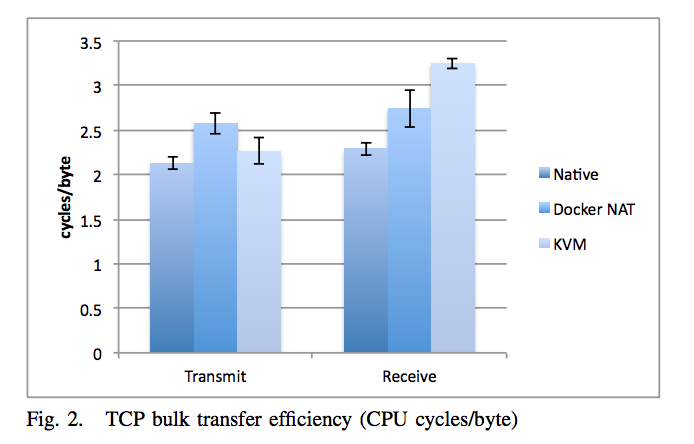
E. Network bandwidth - nuttcp
F. Network latency - netperf
G. Block I/O - fio
H. Redis
I. MySQL
J. Discussion
4. RELATED WORK
5. CONCLUSIONS AND FUTURE WORK
In this paper we created single VMs or containers that consumed a whole server; in the cloud it is more common to divide servers into smaller units. This leads to several additional topics worthy of investigation: performance isolation when multiple workloads run on the same server, live resizing of containers and VMs, tradeoffs between scale-up and scaleout, and tradeoffs between live migration and restarting. SOURCE CODE












'Docker' 카테고리의 다른 글
| Docker network 네트워크 (2) | 2019.07.26 |
|---|---|
| Docker run 명령어 in AWS EC2 (0) | 2018.11.21 |
| Docker AWS EC2 설치 (3) | 2018.11.20 |
| Google Cloud with Docker (0) | 2018.03.06 |
| Docker Tensorflow Jupyter Notebook (0) | 2017.06.15 |