
Jeongchul Kim
Genetic Algorithm 유전알고리즘 - 선택 변이 교차 본문
Genetic Algorithm 유전알고리즘 - 선택 변이 교차

Genetic Algorithm 유전알고리즘 - Introduction
Genetic Algorithm 유전알고리즘 염색체 유전자 적합도 함수
Parent Selection
Parent Selection은 다음 세대를 위한 자손(off-springs)을 만들기 위해 교미하고 재결합하는 부모를 선택하는 과정입니다. 좋은 부모가 개인을보다 훌륭하고 훌륭한 해결책으로 유도 할 때 학부모 선발은 GA의 수렴 속도에 매우 중요합니다.
그러나 극도로 딱 맞는 솔루션이 몇 세대 만에 전체 인구를 인수하지 못하도록 주의해야합니다. 솔루션이 솔루션 공간에서 서로 가까워 다양성이 손실 될 수 있습니다. 인구의 다양성을 유지하는 것은 GA의 성공을 위해 매우 중요합니다. 매우 적합한 솔루션으로 전체 인구를 감당하는 것은 조기 컨버전스로 알려져 있으며 GA에서 바람직하지 않은 조건입니다.
Fitness Proportionate Selection
가장 인기있는 부모 선택 방법 중 하나입니다. 이 모든 개인은 적합성에 비례하는 확률로 부모가 될 수 있습니다. 따라서, 개개인은 다음 세대로 그들의 특징을 교배하고 전파 할 기회가 더 많습니다. 따라서 그러한 선택 전략은 인구에 맞는 개인에게 선택 압력을 적용하여 시간이 지남에 따라 더 나은 개인을 발전시킵니다.
원형 바퀴를 고려합니다. 바퀴는 n 개의 파이로 나뉘며, n은 인구 중 개인의 수입니다. 각 개인은 적합도 값에 비례하는 원의 일부를 얻습니다.
적합성 비례 선택의 두 가지 구현이 가능합니다.
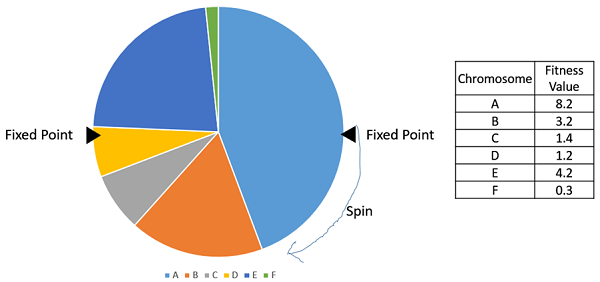
Roulette Wheel Selection
룰렛 휠 선택에서 원형 휠은 앞에서 설명한대로 분할됩니다. 그림과 같이 휠 원주에서 고정 점이 선택되고 휠이 회전됩니다. 고정 점 앞에 오는 휠의 영역이 부모로 선택됩니다. 두 번째 부모에게는 동일한 과정이 반복됩니다.

회전 할 때 휠체어에 더 큰 파이가있어서 고정 점 앞에 착륙 할 확률이 높아집니다. 따라서 개인을 선택할 확률은 적합성에 직접적으로 달려 있습니다.
우리는 다음 단계를 사용합니다.
- S를 계산 = finesses의 합계.
- 0과 S 사이의 난수 생성
- 모집단의 맨 위에서 시작하여 P <S까지 부분 합계 P에 피니시를 계속 추가합니다.
- P가 S를 초과하는 개인이 선택된 개인입니다.
Stochastic Universal Sampling(SUS)
Stochastic Universal Sampling은 룰렛 휠 선택과 매우 유사하지만 다음 그림과 같이 하나의 고정 점 대신에 고정 점이 여러 개 있습니다. 따라서 모든 부모는 휠 하나의 스핀만으로 선택됩니다. 또한 이러한 설정은 적합성이 높은 개인을 적어도 한 번 이상 선택하도록 권장합니다.
Tournament Selection
K-Way 토너먼트 선택에서 우리는 무작위로 K 명의 개인을 선택하고 이들 중 최고를 선택하여 부모가됩니다. 동일한 프로세스가 다음 상위를 선택하기 위해 반복됩니다. Tournament Selection은 부정적인 체력 값으로도 작동 할 수 있으므로 문학 분야에서 매우 인기가 있습니다.

Rank Selection
순위 선택은 또한 네거티브 적합도 값과 함께 작동하며 인구 집단의 개인이 매우 가까운 적합도 값을 가질 때 주로 사용됩니다 (이는 일반적으로 런 종료 시점에 발생합니다). 이것은 다음 그림에서와 같이 각 개인이 파이의 거의 같은 비중을 차지하도록합니다 (적합 비례 선택의 경우와 같음). 따라서 서로에 대해 얼마나 잘 맞는지 상관없이 각각의 개인은 부모의. 이는 결국 개개인에 대한 선택 압력을 상실하여 GA가 그러한 상황에서 부적절한 부모 선택을하도록합니다.
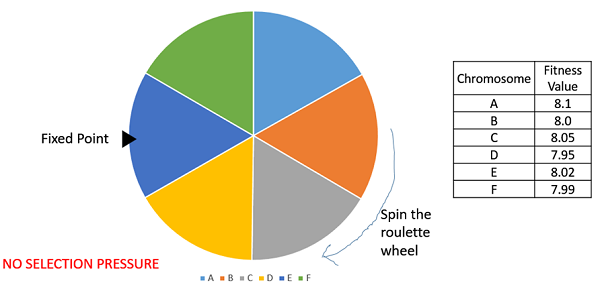
이 과정에서 우리는 부모를 선택하는 동안 적합도 값의 개념을 제거합니다. 그러나 인구의 모든 개인은 자신의 적합성에 따라 순위가 매겨집니다. 부모 선택은 각 개인의 순위에 따라 다르며 적응 정도에 따라 다릅니다. 높은 순위의 개인은 낮은 순위의 개인보다 선호됩니다.
Chromosome | Fitness Value | Rank |
A | 8.1 | 1 |
B | 8.0 | 4 |
C | 8.05 | 2 |
D | 7.95 | 6 |
E | 8.02 | 3 |
F | 7.99 | 5 |
Random Selection
교차는 생식 및 생물학적 교차와 유사합니다. 이 경우 하나 이상의 부모가 선택되고 부모의 유전 물질을 사용하여 하나 이상의 자손이 생성됩니다.
Crossover Operators
One Point Crossover
이 원 포인트 크로스 오버에서는 무작위로 교차 포인트가 선택되고 두 부모의 꼬리가 새로운 자손을 얻기 위해 바뀝니다.

Multi Point Crossover
멀티 포인트 크로스 오버는 새로운 자손 (off-spring)을 얻기 위해 번갈아가는 세그먼트가 교체된 원 포인트 크로스 오버 (one-point crossover)의 일반화입니다.

Uniform Crossover
획일적 인 크로스 오버에서, 우리는 염색체를 세그먼트로 나누지 않고 각 유전자를 개별적으로 취급합니다. 이 과정에서 우리는 본질적으로 각 염색체에 대해 동전을 뒤집어 봄에 포함 시킬지 여부를 결정합니다. 우리는 또한 동전을 한 부모에게 편향시킬 수 있으며, 그 부모로부터 그 자식에게 더 많은 유전 물질을 갖게 할 수 있습니다.

Whole Arithmetic Recombination
이것은 일반적으로 정수 표현에 사용되며 다음 수식을 사용하여 두 부모의 가중 평균을 취하여 작동합니다.
Child1 = α.x + (1-α).y
Child2 = α.x + (1-α).y
α = 0.5 인 경우 분명히 다음 그림과 같이 두 자식이 동일합니다.

Davis’ Order Crossover (OX1)
OX1은 비 순차적 순서에 관한 정보를 자손에 전송하려는 의도로 순열 기반 크로스 오버에 사용됩니다. 그것은 다음과 같이 작동합니다
- 부모에서 두 개의 임의 교차점을 만들고 첫 번째 부모에서 첫 번째 자손으로 세그먼트를 복사합니다.
- 이제 두 번째 부모의 두 번째 교차점에서 시작하여 두 번째 부모의 나머지 미사용 숫자를 첫 번째 자손에게 복사하고 목록을 둘러 쌉니다.
- 부모의 역할을 바꾸어 두 번째 자손를 위해 반복하십시오.
Introduction to Mutation
간단히 말해서, 돌연변이는 새로운 해법을 얻기 위해 염색체에서 작은 무작위적인 팅크라고 정의 할 수 있습니다. 그것은 유전 개체군에 다양성을 유지하고 도입하는데 사용되며 일반적으로 낮은 확률 - 오후로 적용됩니다. 확률이 매우 높으면 GA가 무작위 검색으로 축소됩니다.
돌연변이는 검색 공간의 "탐색"과 관련된 GA의 일부입니다. 크로스 오버가 아닌 동안 돌연변이가 GA의 수렴에 필수적이라는 것이 관찰되었습니다.
Mutation Operators
이 섹션에서는 가장 일반적으로 사용되는 돌연변이 연산자에 대해 설명합니다. 크로스 오버 연산자와 마찬가지로, 이것은 포괄적 인 목록이 아니며 GA 설계자는 이러한 접근 방식 또는 문제 별 변이 연산자를 더 유용하게 사용할 수 있습니다.
Bit Flip Mutation
binary encoded GAs.
이 비트 플립 변형에서 하나 이상의 임의의 비트를 선택하고 뒤집습니다. 바이너리 인코딩 된 GA에 사용됩니다.
Random Resetting
무작위 리셋은 정수 표현에 대한 비트 플립의 확장입니다. 이 경우 허용 된 값 집합의 무작위 값이 무작위로 선택된 유전자에 할당됩니다.
Swap Mutation
스왑 돌연변이에서는 무작위로 염색체상의 두 위치를 선택하고 값을 교환합니다. 이것은 순열 기반 인코딩에서 일반적입니다.
Scramble Mutation
스크램블 돌연변이는 순열 표현에도 널리 사용됩니다. 이것에서, 전체 염색체에서, 유전자의 부분 집합이 선택되고 그 값은 무작위로 뒤섞이거나 뒤섞이게됩니다.
Inversion Mutation
역전 돌연변이에서는 스크램블 돌연변이와 같은 유전자 서브 세트를 선택하지만, 서브 세트를 셔플하는 대신에 서브 세트의 전체 문자열을 뒤집을뿐입니다.
Survivor Selection
생존자 선택 정책에 따라 차용 할 개인과 다음 세대에 보관해야 할 개인이 결정됩니다. 개개인이 인구에서 쫓겨나지 않도록하면서 동시에 인구 다양성을 유지해야하는 것이 중요합니다.
일부 GAs는 엘리트주의를 채택합니다. 간단히 말하자면, 현재의 적자 인구가 항상 다음 세대로 전파된다는 의미입니다. 그러므로 어떤 상황에서도 현재 인구의 적자가 대체 될 수는 없습니다.
가장 쉬운 정책은 임의의 구성원을 모집단 밖으로 걷어차 기는 것이지만 그러한 접근법은 종종 수렴 문제가 있으므로 다음 전략이 널리 사용됩니다.
Age Based Selection
연령 기반 선택에서 우리는 적합도에 대한 개념이 없습니다. 그것은 각 개인이 제한된 세대를 위해서 인구에 허용된다는 전제에 기초를두고 있습니다. 그 이후에, 그 개인은 그 적합성이 아무리 좋더라도 인구에서 추방됩니다.
예를 들어, 다음 예에서 연령은 개인이 모집단에 있었던 세대 수입니다. 인구의 가장 오래된 구성원, 즉 P4와 P7이 인구에서 퇴장하고 나머지 구성원의 연령이 1 씩 증가합니다.

Fitness Based Selection
이 적합성에 근거한 선택에서, 아이들은 인구 중 가장 적합하지 않은 사람들을 대체하는 경향이 있습니다. 가장 적합하지 않은 개인의 선택은 앞서 설명한 선택 정책의 변형을 사용하여 수행 할 수 있습니다 (토너먼트 선택, 적합성 비례 선택 등).
예를 들어, 다음 이미지에서 어린이는 모집단의 가장 적합하지 않은 개체 P1 및 P10을 대체합니다. P1과 P9는 동일한 적합도 값을 갖기 때문에 어떤 개체를 모집단에서 제거할지 결정하는 것은 임의적이라는 점에 유의해야합니다.

Termination Condition
유전자 알고리즘의 종료 조건은 GA 실행이 언제 종료 될지를 결정하는 데 중요합니다. 초기에 GA는 몇 번의 반복 작업마다 더 나은 솔루션을 제공하면서 매우 빠르게 진행되지만, 이는 개선이 매우 적은 후반 단계에서 포화되는 경향이 있다는 것을 알게되었습니다. 우리는 대개 실행이 끝날 때 우리 솔루션이 최적에 가깝도록 종료 조건을 원합니다.
일반적으로 다음 종료 조건 중 하나를 유지합니다.
- X 반복에 대한 모집단의 개선이 없었던 경우.
- 우리가 절대 세대에 도달했을 때.
- 목적 함수 값이 미리 정의 된 특정 값에 도달했을 때.