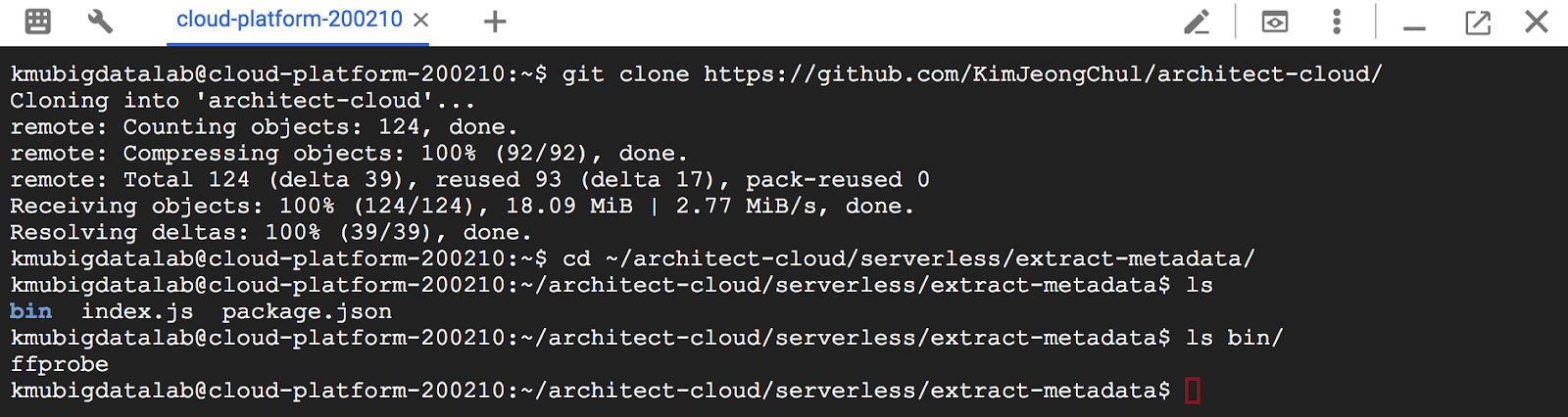
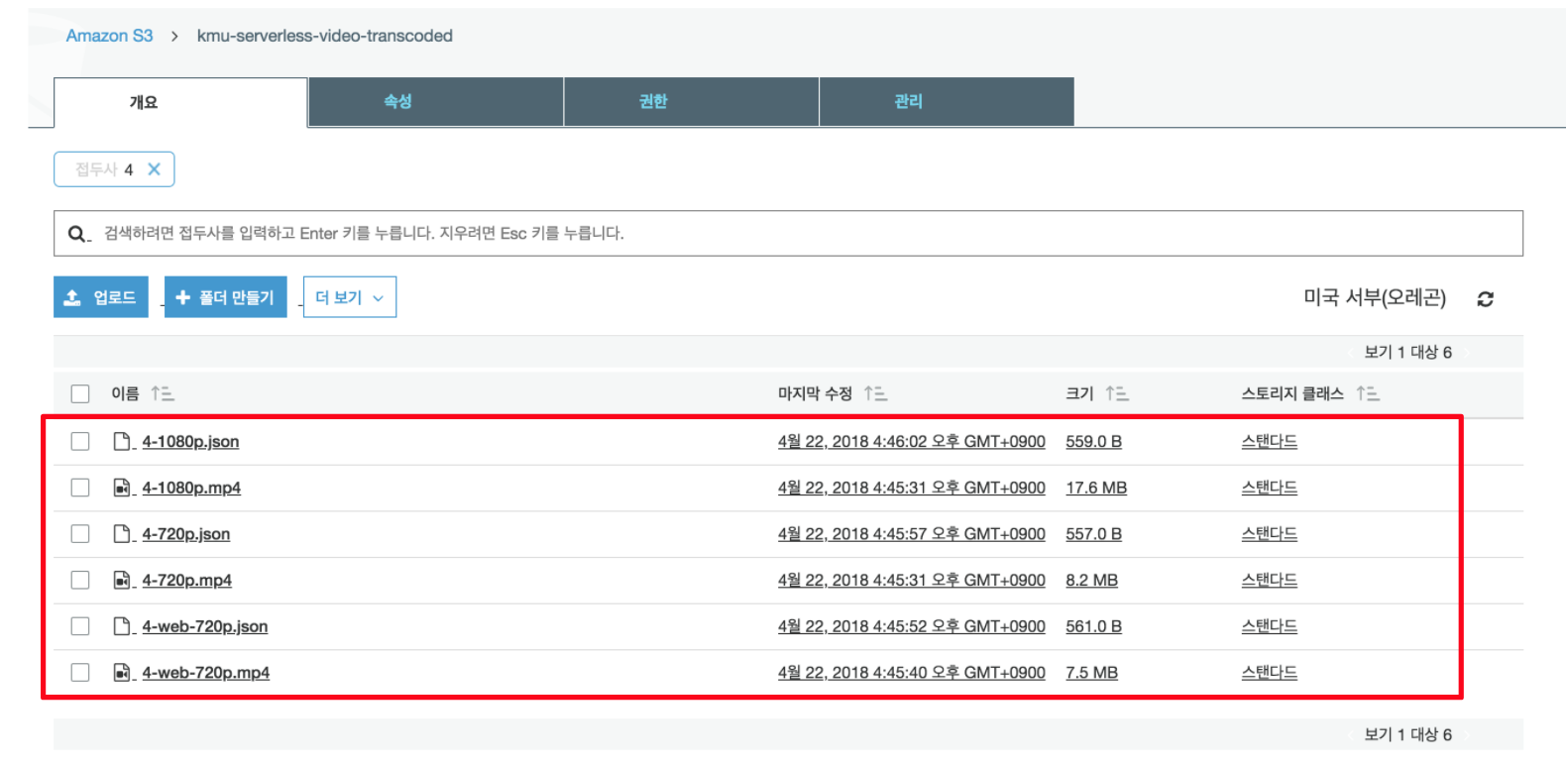
AWS Lambda Serverless 프로젝트 4 - 비디오 메타데이터 생성 - Lambda, SNS, S3 AWS Lambda Serverless 프로젝트 1 - AWS CLI, Lambda, S3, IAM AWS Lambda Serverless 프로젝트 2 - IAM, Lambda, Elastic Transcoder, NPM, S3, CloudWatch AWS Lambda Serverless 프로젝트 3 - SNS, Lambda, S3 세 번째 Lambda 함수는 비디오에 대한 메타 데이터가있는 JSON 파일을 만들어야합니다. 또한 메타 데이터 파일을 비디오 옆에 저장해야합니다. 이 람다 함수는 SNS를 통해 이전처럼 호출됩니다. 이 기능의 문제는 비디오를 분석하고 필요한 메타 데이터를 얻는 방법입니다. FFprobe를 얻는 방법에는 두 가지가 있습니다. 첫 번째 방법은 Amazon Linux를 사용하여 EC2의 사본을 작성하고 FFmpeg 소스 코드를 가져 와서 FFprobe를 빌드하는 것입니다. 그렇게하면 유틸리티의 정적 빌드를 만들어야합니다. 두 번째 방법은 신뢰할 수있는 소스 나 배포본에서 Linux 용 FFmpeg (예 : https://www.johnvansickle.com/ffmpeg/)의 정적 빌드를 찾는 것입니다. AWS Lambda에서 사용중인 Amazon Linux의 현재 버전은 항상 Lambda 문서의 Supported Versions 페이지에서 찾을 수 있습니다. 다음 코드는 세 번째 람다 함수의 구현을 보여줍니다. 'use strict'; (1) 명령을 실행하려면 FFprobe를 bin 디렉토리에 복사해야합니다. FFprobe에 올바른 권한 (chmod + x)이 있는지 확인하십시오. function saveFileToFilesystem(sourceBucket, sourceKey, callback){ (2) 읽기 스트림을 열려면 createReadStream 메소드에 파일의 경로가 필요합니다. 그런 다음이 스트림을 createWriteStream에 파이프하여 로컬 파일 시스템에 파일을 만드는 데 사용할 수 있습니다. (3) 그의 함수는 S3에서 로컬 파일 시스템 (saveFileToFilesystem)으로 객체를 복사하고, 파일에서 메타 데이터를 추출하고 (extractMetadata), S3의 새 파일에 메타 데이터를 저장합니다 (saveMetadataToS3). AWS 콘솔에서 세 번째 Lambda 함수를 만들고 추출 메타 데이터의 이름을 지정합니다. 이 함수의 역할을 lambda-s3-execution-role로 설정합니다. 만들어진 Lambda 함수를 제한 시간을 2 분으로 설정하고 메모리를 256MB로 설정하십시오. 모든 것이 작동 할 때 나중에 메모리 할당 및 시간 초과를 줄일 수 있습니다. GitHub에서 clone을 통해 index.js와 package.json과 ffprobe 실행 파일을 가져옵니다. bin 디렉토리에서 ffprobe의 실행 파일을 볼 수 있습니다. Lambda의 최대 배포 패키지 크기는 50MB이므로 너무 많은 불필요한 파일을 포함하면 배포가 실패할 수 있습니다. package.json을 편집하고 [ARN-LAMBDA-EXTRACT-METADATA-FUNCTION] 를 extract-metadata의 Lambda ARN을 변경합니다. 세 번째 Lambda 함수는 S3의 비디오를 로컬 파일 시스템의 /tmp 디렉토리에 복사하여 작동합니다. 그런 다음 FFprobe를 실행하고 필요한 정보를 수집합니다. 마지막으로 필요한 데이터가 포함 된 JSON 파일을 만들어 파일 옆에있는 버킷에 저장합니다. 람다는 최대 디스크 용량이 512MB이므로 비디오가 더 커질 경우이 기능이 작동하지 않습니다. deploying을 실시합니다. $ chmod +x bin/ffrpobe Lambda 콘솔에서 extract-metadata 함수가 배포된 것을 확인할 수 있습니다. File Permissions Lambda에서 실행하고자하는 스크립트 나 프로그램은 올바른 (실행 가능한) 파일 권한이 있어야합니다. 안타깝게도 Lambda에서는 파일 권한을 직접 변경할 수 없으므로 기능을 배포하기 전에 컴퓨터에서 완료해야합니다. Linux 또는 Mac을 사용하는 경우 쉽습니다. 터미널 명령 행에서 chmod + x bin / ffprobe를 실행합니다. (람다 함수의 디렉토리에 있어야합니다). 그런 다음 함수를 배포하면 FFprobe가 작동합니다. Windows의 경우 chmod 명령과 함께 제공되지 않기 때문에 처리가 까다 롭습니다. 이 문제를 해결할 수있는 한 가지 방법은 AWS에서 Amazon Linux 시스템을 회전하고 FFprobe를 복사하고 권한을 변경 한 다음 파일을 다시 복사하는 것입니다. 세 번째 Lambda 함수는 SNS 주제에 가입해야합니다. 두 번째 람다 함수에서했던 것처럼 새로운 구독을 만듭니다. 2. “구독 생성" 버튼을 클릭합니다. 3. AWS Lambda를 선택합니다. 엔드포인트 드롭 다운에서extract-metadata 람다 함수를 선택하고, “구독 생성” 버튼을 클릭합니다. 이제 전체 프로세스를 끝까지 실행할 준비가 되었습니다. serverless-video-uploaded 버킷에 비디오를 업로드합니다. serverless-video-transcoded 버킷에 JSON 파일이 생성되는 것을 확인할 수 있습니다. 지금까지 IAM 사용자 및 역할 S3의 저장소 및 이벤트 알림 탄성 트랜스 코더의 구성 및 사용법 커스텀 람다 함수의 구현 npm을 사용한 테스트 및 배포 SNS 및 여러 구독자 워크 플로 를 살펴보았습니다.Lambda 세 번째 함수 생성 그리고 FFprobe
FFmpeg는 비디오 및 오디오를 기록하고 변환하는 명령 행 유틸리티입니다. 미디어 정보를 추출하는 데 사용할 수있는 우수한 FFprobe를 비롯한 여러 구성 요소가 있습니다. FFprobe를 사용하여 메타 데이터를 추출한 다음 파일에 저장합니다. 이 섹션은 다른 섹션보다 약간 더 고급이지만 선택 사항입니다. 작업을 통해 많은 것을 배울 수 있지만 다른 장에서 수행하는 작업에 영향을주지 않고 건너 뛸 수 있습니다.
var AWS = require('aws-sdk');
var exec = require('child_process').exec;
var fs = require('fs');
process.env['PATH'] = process.env['PATH'] + ':' + process.env['LAMBDA_TASK_ROOT'];
var s3 = new AWS.S3();
function saveMetadataToS3(body, bucket, key, callback){
console.log('Saving metadata to s3');
s3.putObject({
Bucket: bucket,
Key: key,
Body: body
}, function(error, data){
if (error){
callback(error);
}
});
}
function extractMetadata(sourceBucket, sourceKey, localFilename, callback){
console.log('Extracting metadata');
var cmd = 'bin/ffprobe -v quiet -print_format json -show_format "/tmp/' + localFilename + '"'; (1)
exec(cmd, function(error, stdout, stderr){
if (error === null){
var metadataKey = sourceKey.split('.')[0] + '.json';
saveMetadataToS3(stdout, sourceBucket, metadataKey, callback);
} else {
console.log(stderr);
callback(error);
}
});
}
console.log('Saving to filesystem');
var localFilename = sourceKey.split('/').pop();
var file = fs.createWriteStream('/tmp/' + localFilename);
var stream = s3.getObject({Bucket: sourceBucket, Key: sourceKey}).createReadStream().pipe(file); (2)
stream.on('error', function(error){
callback(error);
});
//This will become easier with async waterfall
stream.on('close', function(){
extractMetadata(sourceBucket, sourceKey, localFilename, callback);
});
}
exports.handler = function(event, context, callback){
var message = JSON.parse(event.Records[0].Sns.Message);
var sourceBucket = message.Records[0].s3.bucket.name;
var sourceKey = decodeURIComponent(message.Records[0].s3.object.key.replace(/\+/g, ' '));
saveFileToFilesystem(sourceBucket, sourceKey, callback); (3)
};
코드의 함수에 많은 콜백이 있음을 알 수 있습니다. 기본적으로 순차적 인 작업을 수행하는 함수에 수많은 콜백을 가짐으로써 읽고 이해하기가 더 어려워집니다.$ git clone https://github.com/KimJeongChul/architect-cloud/
$ cd ~/architect-cloud/serverless/extract-metadata/
$ ls
$ npm run predeploy
$ npm run deploySNS
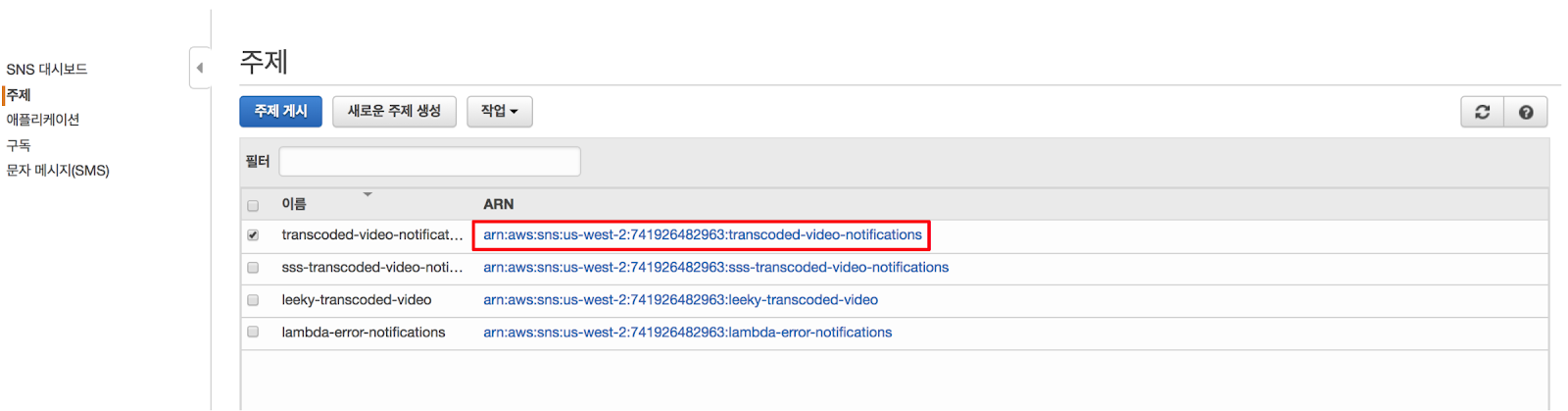
1. AWS 콘솔에서 SNS를 클릭하고 주제를 선택한 다음 항목의 ARN (transcoded-video-notifications)을 클릭합니다.S3에서 3 번째 Lambda 테스트
Jeongchul Kim