OpenCL[3] Memory Object, Kernel Execution

OpenCL application execution scenario

OpenCL platform model
device 마다 global memory와 constant memory를 가지고 있습니다.
host와 device가 둘 다 접근할 수 있습니다. device에서는 host memory(main memory)에 바로 접근할 수 없습니다.

Memory Object
device의 global/constant memory에 공간을 할당하고 데이터를 저장하기 위해 필요합니다.
host program에서 memory object에 데이터를 읽고 쓸 수 있습니다.
- kernel 함수에서 memory object를 인자로 받을 수 있습니다.
- buffer object: 일반적인 배열(array)과 동일
- image object: 1~3 차원의 데이터를 처리하기 위한 특수 object, 텍스처(texture), 프레임 버퍼(frame buffer), 이미지

Create Buffer
buffer object 생성하기
cl_mem clCreateBuffer ( cl_context context, cl_mem_flags flags, size_t size, void *host_ptr, cl_int *errcode_ret)
flags: [Table 5.3] CL_MEM_READ_WRITE, CL_MEM_{WRITE, READ}_ONLY, CL_MEM_HOST_NO_ACCESS, CL_MEM_HO |
여러가지 flag를 줄 수 있습니다.
- CL_MEM_READ_WRITE, CL_MEM_READ_ONLY, CL_MEM_WRITE_ONLY
> kernel에서 이 buffer를 읽기만 하는지, 쓰기만 하는지, 둘 다 하는지 알려준다.
> runtime 시스템에서 최적화를 할 수 있도록 합니다.
- CL_MEM_COPY_HOST_PTR
> buffer object를 host_ptr이 가르키는 곳의 데이터로 초기화 합니다.
- 두 가지 이상의 flag는 bitwise OR(|)로 연결합니다.
다음의 코드는 float 값 10개를 저장할 buffer object를 생성합니다.
cl_context context;
cl_mem buffer;
cl_int err;
buffer = clCreateBuffer(context, 0, sizeof(float) * 10, NULL, &err); |
다음의 코드는 kernel에서 읽기(read)만 가능한 256 byte buffer object를 생성합니다.
cl_mem buffer;
cl_int err;
buffer = clCreateBuffer(context, CL_MEM_READ_ONLY, 256, NULL, &err); |
Command-queue
device에 command(kernel 실행, 데이터 전송, 동기화)를 보내기 위해 command-queue가 필요합니다.
host 프로그램이 command-queue에 command를 넣으면, OpenCL 프레임워크의 런타임 시스템에서 이것을 빼내어 실행합니다.

Write Buffer
cl_int clEnqueueWriteBuffer ( cl_command_queue command_queue, cl_mem buffer, cl_bool blocking_write, size_t offset, size_t size, const void *ptr, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event) |
동기화(blocking_write가 CL_TRUE)
- buffer 쓰기가 완료된 다음에 리턴
- 함수 호출이 끝난 다음 바로 ptr을 해제하거나 다른 용도로 사용해도 무방합니다.
비동기화(blocking_write가 CL_FALSE)
- command가 command_queue에 enqueue되자마자 리턴
- 완료 시점 파악을 위해 이벤트가 사용됩니다.
다음의 코드는 Main memory의 A, B 배열 데이터를 buffer에 씁니다.
cl_command_queue queue;
float *A, *B;
cl_mem bufA, bufB;
int N = 10000;
int i;
A = (float*)malloc(sizeof(float) * N);
B = (float*)malloc(sizeof(float) * N);
for(i = 0 ; i < N; i++) {
A[i] = rand() % 100;
B[i] = rand() % 100;
}
...
bufA = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float) * N, NULL, &err);
bufB = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float) * N, NULL, &err);
...
err = clEnqueueWriteBuffer(queue, bufA, CL_FALSE, 0, sizeof(float) * N, A, 0, NULL, NULL);
err = clEnqueueWriteBuffer(queue, bufB, CL_FALSE, 0, sizeof(float) * N, B, 0, NULL, NULL); |
Read Buffer
buffer에 쓰여진 데이터를 읽어옵니다.
cl_int clEnqueueReadBuffer ( cl_command_queue command_queue, cl_mem buffer, cl_bool blocking_read, size_t offset, size_t size, void *ptr, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event) |
다음의 코드는 buffer의 데이터를 main memory의 C 배열로 읽어와 출력합니다.
cl_command_queue queue;
float *C;
cl_mem bufC;
int N = 10000;
int i;
C = (float*)malloc(sizeof(float) * N);
bufC = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float) * N, NULL, &err);
err = clEnqueueReadBuffer(queue, bufC, CL_TRUE, 0, sizeof(float) * N, C, 0, NULL, NULL);
for(i = 0; i < N; i++)
printf("idx : %d , value : %f\n", i, C[i]); |
Copy Buffer
buffer에서 buffer로 복사합니다.
cl_int clEnqueueCopyBuffer ( cl_command_queue command_queue, cl_mem src_buffer, cl_mem dst_buffer, size_t src_offset, size_t dst_offset, size_t size, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event) |
kernel에서 buffer에 접근하는 코드는 다음과 같습니다.
__kernel void vec_add(__global float *A, __global float *B, __global float *C) {
int i = get_global_id(0);
C[i] = A[i] + B[i];
} |
Cautions : memory object
메모리 object는 추상적인 메모리 영역입니다.
- 특정 device의 메모리에 dedicated 된 것이 아닙니다.
- 실제로 device에서 사용될 때(해당 device의 command queue에 command를 넣어서 실행할 때) 비로소 global memory 에 할당되고 저장됩니다.
- 여러 device를 동시에 할당할 수 도 있습니다. 런타임 시스템에서 device사이의 consistency를 관리합니다.
- 똑같은 buffer를 여러 device에 할당하는 것은 성능이 좋지 않습니다.
Constant Memory : 4KB 이내의 공유할만한 데이터가 아닌 이상 사용할 일이 거의 없습니다.
Share memory in host and device
데이터를 복사하는 overhead가 엄청 큽니다.
Multi-core CPU
AMD APU(Accelerated Processing Unit)
- CPU와 GPU가 같은 칩에 장착됩니다.
- HSA(Heterogeneous System Architecture) 지원 : CPU와 GPU가 같은 가상 메모리 주소 공간을 공유하며, 캐시 일관성 지원
CPU + FPGA
- Intel에서 데이터 센터 대상의 서버용 프로세서 출시 계획
OpenCL 1.x
flags에 CL_MEM_USE_HOST_PTR 설정
- host_ptr이 가르키는 곳(host memory)을 버퍼로 사용할 수 있습니다.
- 불필요한 복사를 줄일 수 있습니다.
int N = 1000;
int i;
int *A = (int*)malloc(sizeof(int) * N);
for(i = 0; i < N; i++) A[i] = i;
buffer = clCreateBuffer(context, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR, sizeof(int) * N, A, &err); |
한계
- host와 device 사이에 동기화를 보장하지 않습니다. 주소 공간을 공유하는 것은 아닙니다. point 기반의 자료 구조(linked list, tree 등)를 공유하기 어렵습니다.
- clEnqueueMapBuffer : device에 write한 것을 device에 업데이트
- clEnqueueUnmapMemObject : host에서 write한 것을 device에 업데이트
OpenCL 2.X : SVM(Shared Virtural Memory)
3가지 종류의 SVM을 지원합니다.
device마다 지원하는 사항은 다르나, Coarse-grained buffer SVM은 필수로 있습니다.
OpenCL application execution scenario
OpenCL kernel function
SPMD(Single Program, Multiple Data)
같은 kernel 코드를 다른 데이터 아이템에 동시에 실행합니다. data parallelism을 활용합니다.
work-item
인덱스(index) 공간의 각 점마다 kernel 인스턴스(instance)가 하나씩 실행됩니다.
kernel 함수 안에서 OpenCL C의 built-in 함수(get_global_id 등)를 사용해 index 공간에서의 work-item의 id를 가져올 수 있습니다.
work-group
여러 work-item 들이 work-group 단위로 묶여 있습니다.
모든 work-group의 크기는 동일합니다.
하나의 work-group은 CU에서 실행됩니다.
- work-group 안의 여러 work-item 들이 CU안의 여러 PE에서 나뉘어 실행됩니다.
- 같은 work-group 안의 work-item들은 local memory를 공유합니다.
- work-group의 크기가 성능에 큰 영향을 미칩니다.

Set kernel arguments
buffer를 전달하거나, 값을 넘깁니다.
cl_int clSetKernelArg (cl_kernel kernel, cl_uint arg_index, size_t arg_size, const void *arg_value)
|
cl_mem buf;
cl_float f = 3.141569;
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &buf);
err = clSetKernelArg(kernel, 1, sizeof(cl_float), &A); |
cl_int clEnqueueNDRangeKernel ( cl_command_queue command_queue, cl_kernel kernel, cl_uint work_dim, const size_t *global_work_offset, const size_t *global_work_size, const size_t *local_work_size, cl_uint num_events_in_wait_list, const cl_event *event_wait_list, cl_event *event) |
work-group 크기에서 global_work_size[i]는 local_work_size[i]로 항상 나누어 떨어져야 합니다.
다음의 코드는 1차원 index 공간 생성합니다.
size_t global_size = 1024;
size_t local_size = 32;
clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &global_size, &local_size, 0, NULL, NULL); |
다음의 코드는 2차원 index 공간 생성합니다.
size_t global_size[2] = {256, 256};
size_t local_size[2] = {16, 16};
clEnqueueNDRangeKernel(queue, kernel, 2, NULL, global_size, local_size, 0, NULL, NULL);] |

Vector Add
크기가 N개인 int형 vector 3개를 생성합니다.
A와 B값을 초기화하고, GPU에서 계산을 하고, C를 가져와서 CPU에서 계산한 값과 비교합니다.
https://github.com/KimJeongChul/opencl/tree/master/project-3-vector-addition
kernel 함수 코드는 다음과 같습니다.
__kernel void vec_add(__global int *A, __global int *B, __global int *C) {
int i = get_global_id(0);
C[i] = A[i] + B[i];
} |
main 함수는 다음과 같습니다.
library를 가져오고 변수를 정의합니다. VECTOR_SIZE는 LOCAL_SIZE 약수로 나뉘어져야 합니다.
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <unistd.h>
#include <CL/cl.h>
#define VECTOR_SIZE 32768
#define LOCAL_SIZE 256 |
에러를 체크하고 시간을 가져오는 함수입니다.
#define CHECK_ERROR(err) \
if (err != CL_SUCCESS) { \
printf("[%s:%d] OpenCL error %d\n", __FILE__, __LINE__, err); \
exit(EXIT_FAILURE); \
}
double get_time() {
struct timeval tv;
gettimeofday(&tv, NULL);
return (double)tv.tv_sec + (double)1e-6 * tv.tv_usec;
} |
file에서 kernel 코드를 가져옵니다.
char *get_source_code(const char *file_name, size_t *len) {
char *source_code;
size_t length;
FILE *file = fopen(file_name, "r");
if (file == NULL) {
printf("[%s:%d] Failed to open %s\n", __FILE__, __LINE__, file_name);
exit(EXIT_FAILURE);
}
fseek(file, 0, SEEK_END);
length = (size_t)ftell(file);
rewind(file);
source_code = (char *)malloc(length + 1);
fread(source_code, length, 1, file);
source_code[length] = '\0';
fclose(file);
*len = length;
return source_code;
} |
main 함수는 다음과 같습니다.
int main() {
// OpenCl variables
cl_platform_id platform;
cl_device_id device;
cl_context context;
cl_command_queue queue;
cl_mem bufferA, bufferB, bufferC;
cl_program program;
char *kernel_source;
size_t kernel_source_size;
cl_kernel kernel;
cl_int err;
// Time variables
double start;
double end;
// Get platform
err = clGetPlatformIDs(1, &platform, NULL);
CHECK_ERROR(err);
// Get GPU device
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
CHECK_ERROR(err);
// Create context
context = clCreateContext(NULL, 1, &device, NULL, NULL, &err);
CHECK_ERROR(err);
// Get kernel code
kernel_source = get_source_code("kernel.cl", &kernel_source_size);
// Create program
program = clCreateProgramWithSource(context, 1, (const char**)&kernel_source,
&kernel_source_size, &err);
CHECK_ERROR(err);
// Build program
err = clBuildProgram(program, 1, &device, "", NULL, NULL);
if(err == CL_BUILD_PROGRAM_FAILURE) {
size_t log_size;
char *log;
// Get program build
err = clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
0, NULL, &log_size);
CHECK_ERROR(err);
// Get build log
log = (char*)malloc(log_size + 1);
err = clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
log_size, log, NULL);
CHECK_ERROR(err);
log[log_size] = '\0';
printf("Compiler error : \n%s\n", log);
free(log);
exit(0);
}
CHECK_ERROR(err);
// Create Vector A, B, C
int *A = (int*)malloc(sizeof(int) * VECTOR_SIZE);
int *B = (int*)malloc(sizeof(int) * VECTOR_SIZE);
int *C = (int*)malloc(sizeof(int) * VECTOR_SIZE);
// Initial Vector A, B
cl_ushort idx;
for(idx = 0; idx < VECTOR_SIZE; idx++) {
A[idx] = rand() % 100;
B[idx] = rand() % 100;
}
// Create kernel
kernel = clCreateKernel(program, "vec_add", &err);
CHECK_ERROR(err);
// Create Buffer
bufferA = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int) * VECTOR_SIZE, NULL, &err);
CHECK_ERROR(err);
bufferB = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(int) * VECTOR_SIZE, NULL, &err);
CHECK_ERROR(err);
bufferC = clCreateBuffer(context, CL_MEM_WRITE_ONLY, sizeof(int) * VECTOR_SIZE, NULL, &err);
CHECK_ERROR(err);
// Create command-queue
queue = clCreateCommandQueue(context, device, 0, &err);
CHECK_ERROR(err);
// Write Buffer
err = clEnqueueWriteBuffer(queue, bufferA, CL_FALSE, 0, sizeof(int) * VECTOR_SIZE, A, 0, NULL, NULL);
CHECK_ERROR(err);
err = clEnqueueWriteBuffer(queue, bufferB, CL_FALSE, 0, sizeof(int) * VECTOR_SIZE, B, 0, NULL, NULL);
CHECK_ERROR(err);
// Set Kernel arguments
start = get_time();
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufferA);
CHECK_ERROR(err);
err = clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufferB);
CHECK_ERROR(err);
err = clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufferC);
CHECK_ERROR(err);
end = get_time();
printf("Send Vector A, B to GPU : %f seconds elapsed\n", end - start);
start = get_time();
// Execute Kernel
size_t global_size = VECTOR_SIZE;
size_t local_size = LOCAL_SIZE;
clEnqueueNDRangeKernel(queue, kernel, 1, NULL, &global_size, &local_size, 0, NULL, NULL);
CHECK_ERROR(err);
end = get_time();
printf("Calculate C : %f seconds elapsed\n", end - start);
// Read Buffer
start = get_time();
err = clEnqueueReadBuffer(queue, bufferC, CL_TRUE, 0, sizeof(int) * VECTOR_SIZE, C, 0, NULL, NULL);
CHECK_ERROR(err);
end = get_time();
printf("Receive C from GPU : %f seconds elapsed\n", end - start);
// Evaluate Vector C
for(idx = 0; idx < VECTOR_SIZE; idx++) {
if(A[idx] + B[idx] != C[idx]) {
printf("Verification failed! A[%d] = %d, B[%d] = %d, C[%d] = %d\n", idx, A[idx], idx, B[idx], idx, C[idx]);
break;
}
}
if (idx == VECTOR_SIZE) {
printf("Verification success!\n");
}
// Release OpenCL object
clReleaseMemObject(bufferA);
clReleaseMemObject(bufferB);
clReleaseMemObject(bufferC);
free(A);
free(B);
free(C);
clReleaseKernel(kernel);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
return 0;
} |
컴파일을 하고 실행해 봅시다.
$ gcc -o vector main.c -lOpenCL
$ ./vector
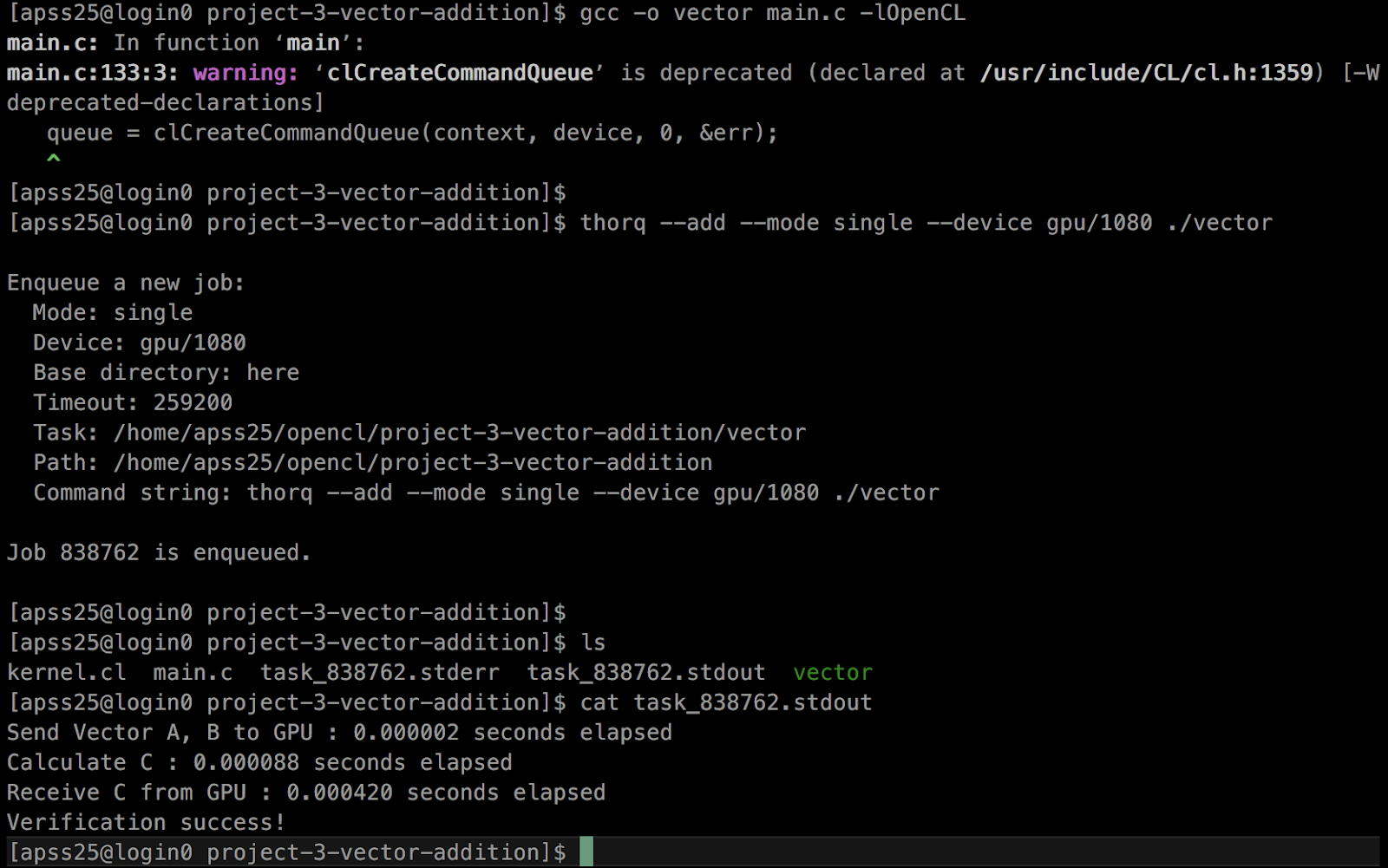
OpenCL Kernel Programming
OS가 없기 때문에 표준 C99 헤더 파일을 지원되지 않습니다.
함수 포인터와 재귀 함수가 지원되지 않습니다.
OpenCL C program
여러 함수(function) 정의가 나열되어 있습니다.
2 가지 종류의 함수가 있습니다. kernel 함수와 일반 함수
host 프로그램에서는 kernel 함수만 호출 가능합니다.
Declare Kernel
Function qualifier
- __kernel 또는 kernel이 붙습니다.
- OpenCL C의 예약어로 kernel 선언 이외에 사용할 수 없습니다.
- return 타입은 void 여야 합니다.
__kernel void square(__global int *input, __global int *output)
{
int id = get_global_id(0);
output[id] = input[id] * input[id];
} |
Kernel Attribute
kernel 함수에 특별한 정보를 추가하기 위하여 __attribute__ 키워드 사용합니다.
__kernel void => __kernel __attribute__((...)) void
__attribute__((vec_type_hint(<type>)))
- kernel의 주된 계산 너비(computational width)
- 컴파일러 힌트 : 자동 벡터화(auto-vectorization)에 도움을 줄 수 있습니다.
- <type>은 빌트인 스칼라(scala) 타입 또는 벡터(vector) 타입 중의 하나입니다.
- 지정되지 않은 경우 __attribute__((vect_type_hint(float4)))
__attribute__((work_group_size_hint(X, Y, Z)))
- kernel이 주로 사용할 work-group 크기에 대한 compiler에 도움을 줍니다.
__attribute__((reqd_work_group_size(X, Y, Z)))
- kernel execution을 위해 꼭 사용해야 할 work-group 크기
- kernel command를 command-queue에 넣을 때 잘못 지정하면, runtime error 발생합니다.
Scala Type
host API와 host 프로그램에서 사용되는 scala type
- OpenCL C의 대부분의 scala type에 대응합니다.

Vector Type

Address Space Qualifier
__global, __constant, __local, __private를 사용하면 각각 데이터가 global, constant, local, private 메모리에 있다는 것을 나타냅니다. kernel 함수의 변수 선언 앞에 붙으면 어떤 메모리 영역에 할당될지를 사용합니다.
- __global, __constant : buffer를 만들어서 인자로 넘깁니다.
- __local : host에서 값은 못쓰지만, 할당은 가능합니다.
- __private : 사용할 수 없습니다.
- 전역 변수는 선언과 동시에 초기화를 해야합니다.
__kernel void add(__global int *A, __constant int *B)
{
int i = get_global_id(0);
__private int x;
__local float y[20];
A[i] = A[i] + B
} |
work-itme function
dimindx 는 0부터 get_work_dim() -1 사이의 값입니다.
index 공간의 function
- 차원(dimensions) : uint get_work_dim()
- 전체 크기 : size_t get_global_size(uint dimindx)
- work-group 크기 : size_t get_local_size(uint dimindx)
- work-group 개수 : size_t get_num_groups(uint dimindx)
현재 work-item의 function
- global id : size_t get_global_id(uint dimindx)
- local id : size_t get_local_id(uint dimidx)
현재 work-group의 function
- work-group id : size_t get_group_id(uint dimidx)
Local Memory
Compute Unit(CU)마다 local memory가 하나씩 있습니다. 해당 CU에서만 접근이 가능합니다.
GPU의 경우, global memory에 접근하는 것보다 빠릅니다.
- global memory : GPU의 off-chip memory
- local memory : GPU SM 안의 Shared context
kernel 함수에서 할당해야 합니다.
- kernel 함수 안에서 __local 을 붙여 변수/배열 선언합니다.
- kernel 함수에서 __local 포인터를 인자로 받습니다.
- sizeof(int)*64 = 256Byte로 할당해라
- 할당과 동시에 초기화를 할 수 없습니다. kernel 실행 중에 따로 초기화를 해주어야 합니다.
Global memory의 캐시(cache) 역할을 합니다.
- global memory의 같은 위치를 여러 work-item이 읽을 경우
- 처음 한 번만 읽어서 local memory에 저장합니다.
OpenCL Memory Consistency
메모리의 내용이 서로 다른 work-item에게 항상 같게 보일 필요는 없기 때문에 위의 상황에서 문제가 발생합니다.
동기화(synchronization)을 사용해야 합니다.
- work-group barrier
- atomic operation
work-group Barrier
kernel에서 barrier() 함수를 이용합니다.
- void barrier(cl_mem_fence_flags flags)
- work-group 안의 모든 work-item이 barrier를 동시에 통과합니다. 모든 work-item이 barrier까지 코드를 실행 후에 그 다음 코드를 실행합니다.
- local memory에 대한 consistency 보장 : barrier(CLK_LOCAL_MEM_FENCE)
- global memory에 대한 consistency 보장 : barrier(CLK_GLOBAL_MEM_FENCE)
서로 다른 work-group 간의 동기화는 지원하지 않는 다는 것을 유의해야 합니다.
work-group 안의 모든 work-item이 barrier()를 실행하거나, 전체가 실행하지 않아야 합니다. (if 문 분기점을 조심해야 합니다.)
Matrix Multiplication
A는 ROW_A X COL_A 행렬
B는 ROW_B X COL_B 행렬
C = A*B 를 구합니다.

프로그램은 인자 값으로 0과 1을 받아 sequential 또는 parallel로 실행을 합니다.
kernel.cl의 코드는 다음과 같습니다.
__kernel void mat_mul(__global float *A,
__global float *B,
__global float *C,
int ROW_A,
int COL_A,
int COL_B) {
int i = get_global_id(1);
int j = get_global_id(0);
int k;
float sum = 0.0f;
if( i < ROW_A && j < COL_B) {
for(k = 0; k < COL_A; k++) {
sum += A[i * COL_A + k] * B[k * COL_B + j];
}
C[i * COL_B + j] = sum;
}
} |
sequential 코드는 다음과 같습니다.
mat_mul_seq.c
void mat_mul_seq(float *A, float *B, float *C,
int ROW_A, int COL_A, int COL_B) {
int i, j, k;
for (i = 0; i < ROW_A; i++) {
for (j = 0; j < COL_B; j++) {
C[i * COL_B + j] = 0.0f;
for (k = 0; k < COL_A; k++) {
C[i * COL_B + j] += A[i * COL_A + k] * B[k * COL_B + j];
}
}
}
} |
병렬로 처리되는 parallel OpenCL 코드는 다음과 같습니다.
mat_mul_opencl.c
#include <stdio.h>
#include <stdlib.h>
#include <CL/cl.h>
#define CHECK_ERROR(err) \
if (err != CL_SUCCESS) { \
printf("[%s:%d] OpenCL error %d\n", __FILE__, __LINE__, err); \
exit(EXIT_FAILURE); \
}
double get_time(); // use the get_time() function in mat_mul.c
char *get_source_code(const char *file_name, size_t *len) {
char *source_code;
size_t length;
FILE *file = fopen(file_name, "r");
if (file == NULL) {
printf("[%s:%d] Failed to open %s\n", __FILE__, __LINE__, file_name);
exit(EXIT_FAILURE);
}
fseek(file, 0, SEEK_END);
length = (size_t)ftell(file);
rewind(file);
source_code = (char *)malloc(length + 1);
fread(source_code, length, 1, file);
source_code[length] = '\0';
fclose(file);
*len = length;
return source_code;
}
void mat_mul_opencl(float *A, float *B, float*C, int ROW_A, int COL_A, int COL_B) {
cl_platform_id platform;
cl_device_id device;
cl_context context;
cl_command_queue queue;
cl_program program;
char *kernel_source;
size_t kernel_source_size;
cl_kernel kernel;
cl_int err;
// Get platform
err = clGetPlatformIDs(1, &platform, NULL);
CHECK_ERROR(err);
// Get device gpu
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 1, &device, NULL);
CHECK_ERROR(err);
// Create context
context = clCreateContext(NULL, 1, &device, NULL, NULL, &err);
CHECK_ERROR(err);
// Create Queue
queue = clCreateCommandQueue(context, device, 0, &err);
CHECK_ERROR(err);
// Get kernel source
kernel_source = get_source_code("kernel.cl", &kernel_source_size);
// Create program
program = clCreateProgramWithSource(context, 1, (const char**)&kernel_source,
&kernel_source_size, &err);
CHECK_ERROR(err);
// Build program
err = clBuildProgram(program, 1, &device, "", NULL, NULL);
if(err == CL_BUILD_PROGRAM_FAILURE) {
size_t log_size;
char *log;
// Get program build
err = clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
0, NULL, &log_size);
CHECK_ERROR(err);
// Get build log
log = (char*)malloc(log_size + 1);
err = clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG,
log_size, log, NULL);
CHECK_ERROR(err);
log[log_size] = '\0';
printf("Compiler error : \n%s\n", log);
free(log);
exit(0);
}
CHECK_ERROR(err);
// Create kernel
kernel = clCreateKernel(program, "mat_mul", &err);
CHECK_ERROR(err);
cl_mem bufferA, bufferB, bufferC;
// Create buffer
bufferA = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(float)*ROW_A*COL_A,
NULL, &err);
CHECK_ERROR(err);
bufferB = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(float)*COL_A*COL_B,
NULL, &err);
CHECK_ERROR(err);
bufferC = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float)*ROW_A*COL_B,
NULL, &err);
CHECK_ERROR(err);
double start_time = get_time();
// Write buffer
err = clEnqueueWriteBuffer(queue, bufferA, CL_FALSE, 0, sizeof(float)*ROW_A*COL_A, A, 0, NULL, NULL);
CHECK_ERROR(err);
err = clEnqueueWriteBuffer(queue, bufferB, CL_FALSE, 0, sizeof(float)*COL_A*COL_B, B, 0, NULL, NULL);
CHECK_ERROR(err);
// Set kernel arguments
err = clSetKernelArg(kernel, 0, sizeof(cl_mem), &bufferA);
CHECK_ERROR(err);
err = clSetKernelArg(kernel, 1, sizeof(cl_mem), &bufferB);
CHECK_ERROR(err);
err = clSetKernelArg(kernel, 2, sizeof(cl_mem), &bufferC);
CHECK_ERROR(err);
err = clSetKernelArg(kernel, 3, sizeof(cl_int), &ROW_A);
CHECK_ERROR(err);
err = clSetKernelArg(kernel, 4, sizeof(cl_int), &COL_A);
CHECK_ERROR(err);
err = clSetKernelArg(kernel, 5, sizeof(cl_int), &COL_B);
CHECK_ERROR(err);
// Set global, local size
size_t global_size[2] = {COL_B, ROW_A};
size_t local_size[2] = {16, 16};
global_size[0] = (global_size[0] + local_size[0] - 1) / local_size[0] * local_size[0];
global_size[1] = (global_size[1] + local_size[1] - 1) / local_size[1] * local_size[1];
// Enquque nd range kernel
err = clEnqueueNDRangeKernel(queue, kernel, 2, NULL, global_size, local_size, 0, NULL, NULL);
CHECK_ERROR(err);
err = clEnqueueReadBuffer(queue, bufferC, CL_TRUE, 0, sizeof(float)*ROW_A*COL_B, C, 0, NULL, NULL);
CHECK_ERROR(err);
double end_time = get_time();
printf("Elasped Time(excl. initialization): %f sec\n", end_time - start_time);
// Release OpenCL object
clReleaseMemObject(bufferA);
clReleaseMemObject(bufferB);
clReleaseMemObject(bufferC);
clReleaseKernel(kernel);
clReleaseProgram(program);
clReleaseCommandQueue(queue);
clReleaseContext(context);
printf("Finished!\n");
} |
그리고 실제 main되는 코드는 다음과 같습니다.
mat_mul.c
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <sys/time.h>
#include <unistd.h>
static int ROW_A = 1000;
static int COL_A = 1000;
static int COL_B = 1000;
double get_time() {
struct timeval tv;
gettimeofday(&tv, NULL);
return (double)tv.tv_sec + (double)1e-6 * tv.tv_usec;
}
void mat_mul_seq(float *A, float *B, float *C,
int ROW_A, int COL_A, int COL_B);
void mat_mul_opencl(float *A, float *B, float *C,
int ROW_A, int COL_A, int COL_B);
void verify(float *A, float *B, float *C,
int ROW_A, int COL_A, int COL_B);
int main(int argc, char *argv[]) {
if (argc < 2) {
printf("Usage: %s <option>\n", argv[0]);
exit(EXIT_FAILURE);
}
int option = atoi(argv[1]);
float *A = (float*)malloc(sizeof(float) * ROW_A * COL_A);
float *B = (float*)malloc(sizeof(float) * COL_A * COL_B);
float *C = (float*)malloc(sizeof(float) * ROW_A * COL_B);
int i, j;
for (i = 0; i < ROW_A; i++) {
for (j = 0; j < COL_A; j++) {
A[i * COL_A + j] = (float)(rand() % 1000) / 100.0f;
}
}
for (i = 0; i < COL_A; i++) {
for (j = 0; j < COL_B; j++) {
B[i * COL_B + j] = (float)(rand() % 1000) / 100.0f;
}
}
printf("Matrix Multiplication\n");
printf("C[%d X %d] = A[%d X %d] X B[%d X %d]\n",
ROW_A, COL_B, ROW_A, COL_A, COL_A, COL_B);
if (option == 0) {
printf("Sequential version...\n");
double start_time = get_time();
mat_mul_seq(A, B, C, ROW_A, COL_A, COL_B);
double end_time = get_time();
printf("Elapsed time: %f sec\n", end_time - start_time);
} else if (option == 1) {
printf("OpenCL version...\n");
double start_time = get_time();
mat_mul_opencl(A, B, C, ROW_A, COL_A, COL_B);
double end_time = get_time();
printf("Elapsed time (incl. initialization): %f sec\n", end_time - start_time);
} else {
printf("Invalid option!\n");
exit(EXIT_FAILURE);
}
verify(A, B, C, ROW_A, COL_A, COL_B);
free(A);
free(B);
free(C);
return 0;
}
void verify(float *A, float *B, float *C,
int ROW_A, int COL_A, int COL_B) {
int i, j, k;
float sum;
for (i = 0; i < ROW_A; i++) {
for (j = 0; j < COL_B; j++) {
sum = 0.0f;
for (k = 0; k < COL_A; k++) {
sum += A[i * COL_A + k] * B[k * COL_B + j];
}
if (fabsf(C[i * COL_B + j] - sum) > 0.1) {
printf("Verification failed! C[%d][%d]: %f vs. %f\n",
i, j, C[i * COL_B + j], sum);
return;
}
}
}
printf("Verification success!\n");
} |
컴파일을 진행합니다.
$ make
순차 코드 실행
$ thorq --add --mode single --device gpu/1080 ./matmul 0

OpenCL 코드 실행
$ thorq --add --mode single --device gpu/1080 ./matmul 1

약 2배가 안되는 차이가 발생합니다. matrix size를 증가해보겠습니다.

엄청난 차이가 발생합니다. 232초 대비 OpenCL은 3초 정도가 차이가 발생됩니다.

