13 웹 해킹의 이해
웹의 이해
1. 인터넷의 역사
웹의 이해
처음 해커는 우리가 알고 있는 컴퓨터의 취약점을 악용하는 사용자가 아니었습니다. 메사추세츠 공과대학의 모형 기차 제작 동아리인 TMRC에서, 전자 장치로 기차, 트랙, 스위치를 제어하여 ‘보다 빠르게 조작하다’라는 의미로 사용되었습니다.
기차를 잘 움직이게 하기 위하여 컴퓨터를 연구하게 되었고 그 대상이 기차에서 컴퓨터 자체에 대한 연구와 프로그램을 개발하는 쪽으로 변화하게 됨으로써 해킹이라는 의미가 현재의 의미로 사용되었습니다.

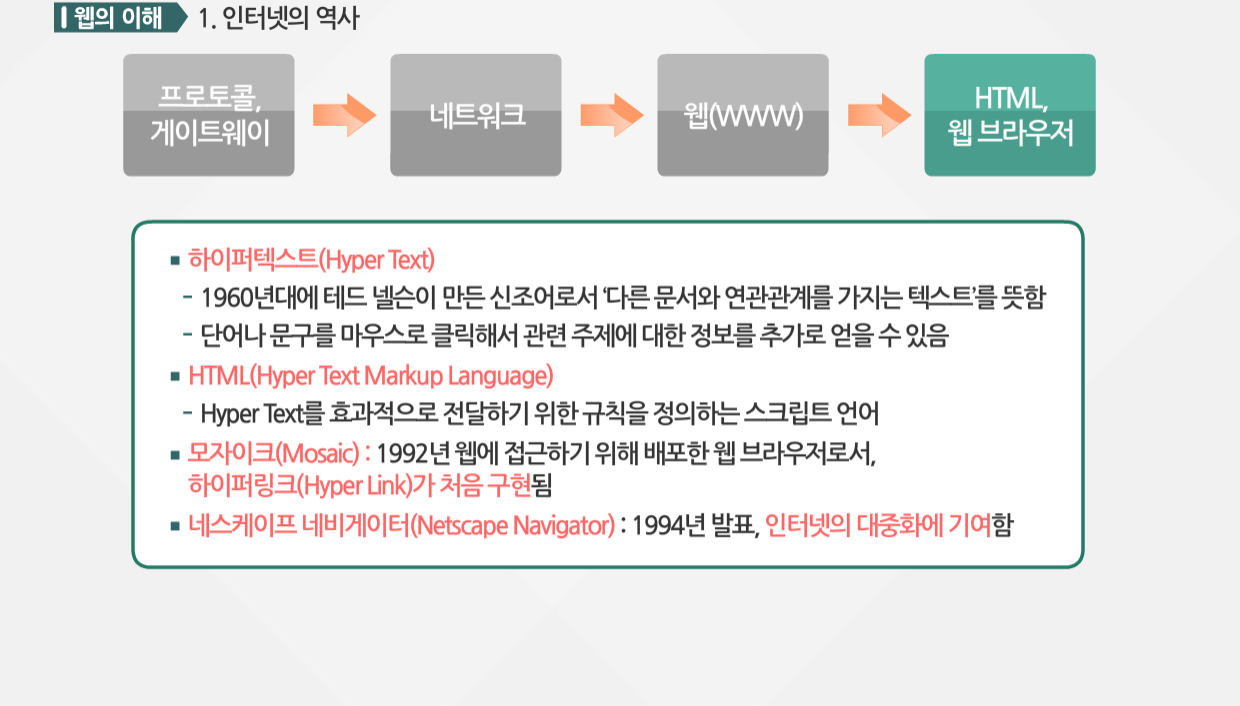
웹에 대한 이해를 위해 인터넷의 역사를 살펴보도록 하겠습니다. 인터넷은 프로토콜과 게이트웨이에서 네트워크로, 웹에서 HTML 웹 브라우저로 발전하였습니다. 인터넷은 처음에 대학의 연구실 간의 데이터 전송을 위해 개발되었는데요. 초기에는 단순히 하나의 시스템과 멀리 떨어져 있는 다른 시스템간의 통신을 위한 프로토콜로 만들어졌습니다. 그 후, 프로토콜을 해석한 후 이를 다른 프로토콜로 바꾸어 다른 시스템에 전송해 주는 게이트웨이가 개발되었죠.

그 다음, 1969년 미 국방부 산하 고등연구 계획국에 의해 전 세계 주요 거점을 연결하는 네트워크가 만들어졌습니다. 이 네트워크를 알파넷이라고 부르며, 곧 인터넷이 시작되었습니다. 한국의 경우, 1994년 한국통신이 카이스트와 연구기관의 학술 교육 및 정보 교류용으로 제공한 ‘하나망’을 일반인에게 개방하여 코넷을 시작함으로써 인터넷에 첫 발을 내딛게 됩니다.

웹 주소의 시작인 WWW는 전 세계 규모의 거미집 또는 거미집 모양의 망이라는 뜻으로, 흔히 웹이라고 합니다. 1989년 스위스 제네바의 유럽 원자핵 공동 연구소에서 근무하던 ‘팀 버너스 리’에 의해 연구 목적의 프로젝트로 시작되는데요.
WWW의 프로젝트의 목적은 전 세계에 흩어져 있는 종업원 및 연구자와 연구 결과나 아이디어를 공유할 수 있는 방법을 찾기 위해서였습니다.

처음 계획할 무렵에는 웹을 ‘Hyper Text Project’라고 불렀습니다.
하이퍼텍스트란 60년대 데드 넬슨이 만든 신조어로 다른 문서와 연관관계를 가지는 텍스트라는 뜻입니다. 하이퍼텍스트를
이용하면 단어나 문구를 마우스 클릭을 통해 관련 주제에 대한 다른 정보를 가지는 문서로 이동하여 정보를 추가로 얻을 수 있습니다. 현재 웹 문서로 가장 흔히 쓰이는 HTML은 하이퍼덱스트를 효과적으로 전달하기 위한 규칙을 정의하는 스트립트 언어입니다.
웹에 접근하기 위해서는 웹 브라우저가 필요합니다. 웹 브라우저인 모자이크는 1992년 배포되었으며, 글자 위에서 마우스 버튼을
클릭할 수 있는 하이퍼링크가 처음 구현되어 인터넷 초기에 붐을 일으킨 촉발제 역할을 하였습니다.
1994년에 발표된 네스케이프 네비게이터는 인터넷 대중화에 기여했지만 현재는 사라진 웹 브라우저입니다.
2. HTTP
이번에는 HTTP에 대해 알아보겠습니다. HTTP는 0.9 버전부터 사용되었는데요. 단순히 읽기 기능만 가능하였습니다. 0.9 버전의 연결 과정을 보면 연결 요청을 받은 서버는 그 클라이언트에 대해 서비스를 준비합니다. 서버가 준비 상태가 되면, 클라이언트는 읽고자 하는 문서를 서버에 요청합니다. 서버는 웹 문서 중 클라이언트가 요청한 문서를 클라이언트에 전송하고 연결을 종료합니다. HTTP 0.9 버전은 하나의 웹 페이지 안에 존재하는 텍스트와 그림마다 connect 과정을 반복해서 거쳐야 하기 때문에 비효율적이라는 단점이 있습니다.

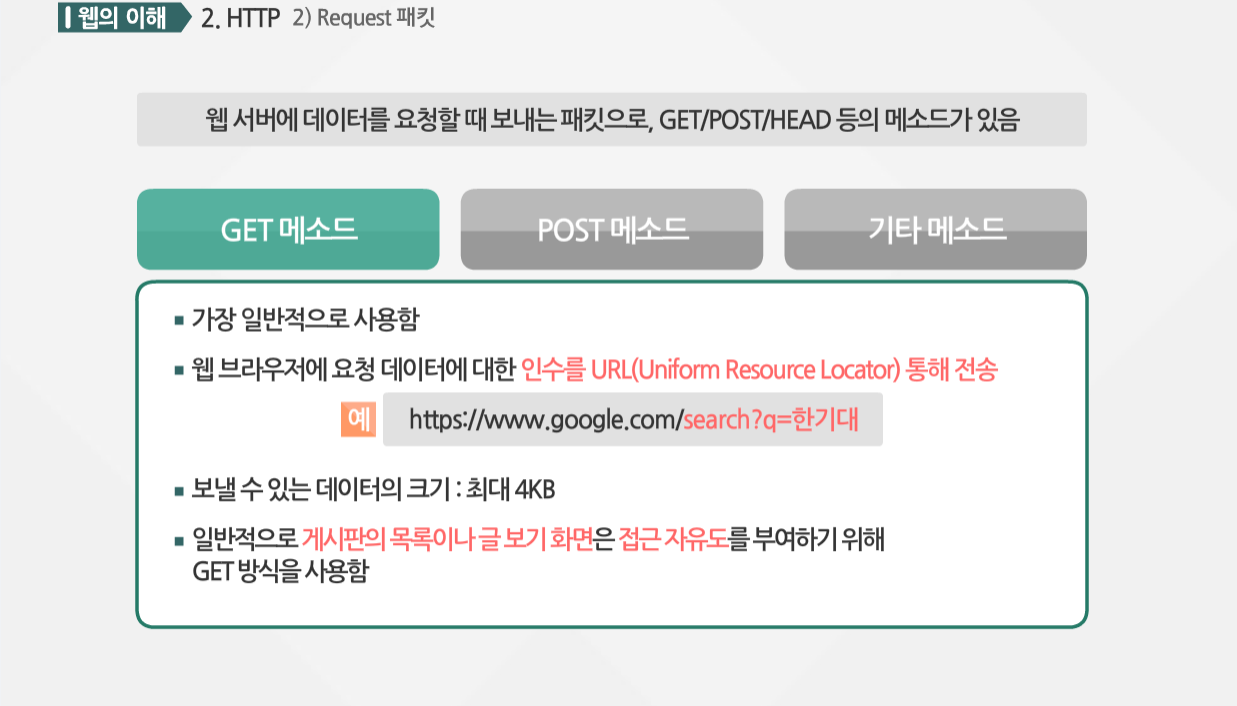
Request 패킷이란 웹 서버에 데이터를 요청할 때 보내는 메시지로서, GET/POST/HEAD 등이 있습니다. GET 메소드는 가장 일반적으로 사용되는데요. 웹 브라우저에 요청 데이터에 대한 인수를 URL을 통해 전달하는 방식을 말합니다. 보시는 예와 구글에서 서치할 내용이 명시가 되죠. 보낼 수 있는 데이터의 크기는 최대 4KB입니다.
일반적으로 게시판의 목록이나 글 보기 화면은 접근 자유도를 부여하기 위해 GET 방식을 사용합니다.
POST 메소드는 GET과 함께 가장 많이 사용되는 메소드입니다. URL에 요청 데이터를 기록하지 않고 소켓을 이용해 데이터를 전송하죠. POST 방식에서와 같은 인수 부분이 존재하지 않습니다. 인수값을 URL을 통해 전송하지 않기 때문에 다른 이가 링크를 통해 해당 페이지를 볼 수 없습니다.
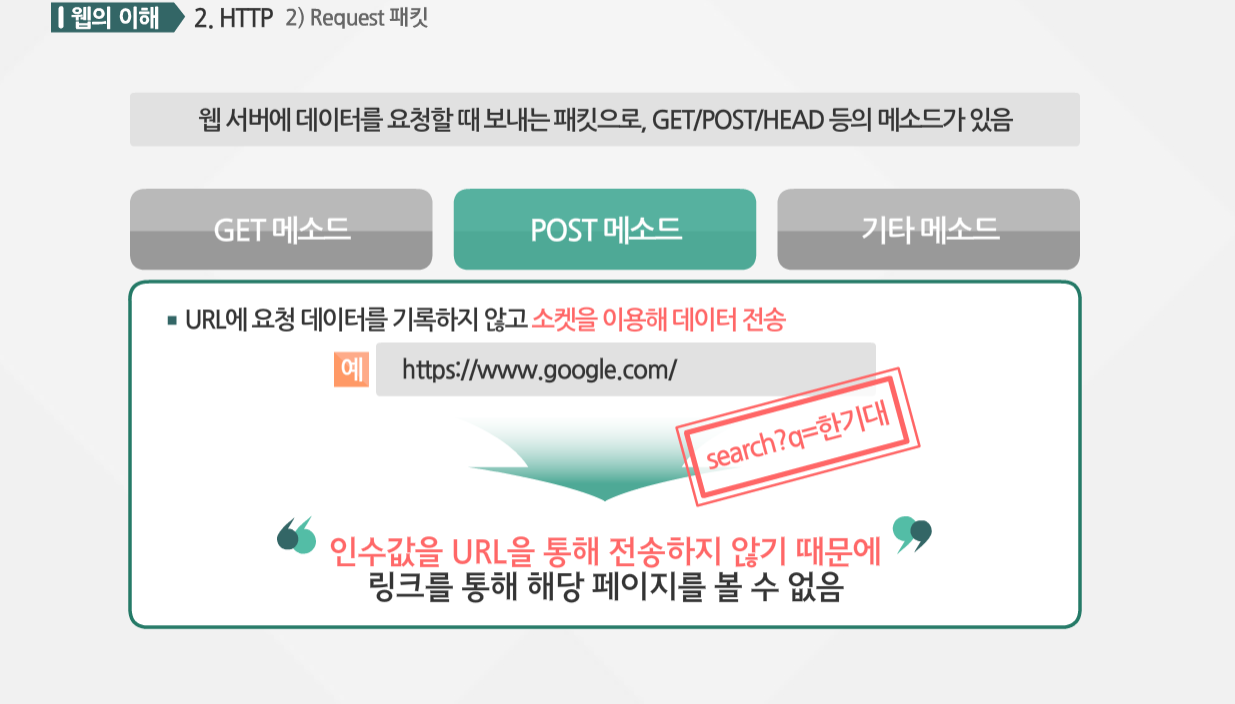
이 방식은 접근이 자유롭지 못하고, 웹 브라우저의 ‘뒤로’ 버튼을 클릭하면 포스트의 버퍼 부분이 사라져 ‘새로고침’ 경고 문구가 뜨는 단점이 있습니다. 그렇지만 파일 업로드는 POST로만 전송 가능하며, 보낼 수 있는 데이터의 크기의 제한이 없습니다.
보내려는 데이터가 URL을 통해서 노출되지 않기 때문에 보안 면에서 매우 중요합니다. 일반적으로 게시판의 글 저장/수정/삭제 등은 보안 등을 위해서는 POST 방식을 사용합니다.

기타 메소드 중에서 HEAD 메소드는 서버 측의 데이터를 검색하고 요청하는데 사용하며 OPTIONS 메소드는 자원에 대한 요구/응답 관계에서 관련된 선택사항의 정보를 요청할 때 사용합니다. PUT 메소드는 메시지에 포함되어 있는 데이터를 지정한 URI 장소에 그 이름으로 저장하며 DELETE 메소드는 URI에 지정되어 있는 자원을 서버에서 제거합니다. TRACE 메소드는 요구 메시지의 최종 수신처까지의 루프백 검사용으로 사용됩니다.

3. 웹 언어
인터넷 웹 브라우저에 사용되는 웹 언어를 HTML과 SSS, CSS로 나누어 살펴보겠습니다.

HTML는 가장 단순한 형태의 웹 언어입니다. 웹 서버에 HTML 문서를 저장하고 있다가 클라이언트가 특정 HTML 페이지를 요청하면 웹 서버가 검색하여 해당 HTML 문서를 클라이언트로 전송해주고 브라우저가 HTML을 처리하는데 이런 웹 페이지를 정적인(Static) 웹 페이지라고 합니다. 이때 HTML 페이지를 요청하는 것은 HTTP 프로토콜을 따르게 됩니다.
단순한 형태의 HTML문서는 클라이언트의 웹 브라우저를 통해 웹 서버의 무엇인가를 바꿀 수 있는 가능성이 매우 낮기 때문에 웹을 이용한 공격이 매우 어렵습니다.

SSS는 Server Side Script로, ASP나 JSP와 같은 언어가 있습니다. 이러한 언어는 동적인 페이지를 제공하는 스크립트를 언어입니다. 스크립트에 HTML 확장자 대신 ASP 또는 JSP의 확장자를 가진 웹 문서를 요청하면 ASP는 DLL이나 OCX 같은 파일을 이용해, JSP는 서블릿을 이용해 요청을 처리하고 그 결과를 HTML 파일로 만들어 클라이언트에 전송합니다. 웹 서버가 스크립트 엔진에게 요청하여
스크립트와 일반 HTML 페이지를 생성하기 때문에 동적인 페이지를 제공하는 스크립트입니다.

CSS는 Client Side Script로 웹 서비스에 이용되는 스크립트에는 자바 스크립트나 비주얼 베이직 스크립트 등이 있습니다. 이들은
서버가 아닌 클라이언트 측의 웹 브라우저에 의해 해석되고 적용됩니다.
CSS언어에서는 클라이언트가 자바 스크립트를 작성합니다. 클라이언트가 웹 페이지에 포함된 스크립트 파일을 요청하면 웹 서버가
해당 스크립트 파일을 검색하여 해당 스크립트 파일을 브라우저에 반환하게 됩니다. 브라우저가 클라이언트측 스크립트를 처리하므로 서버가 아닌 클라이언트 측의 웹 브라우저에 의해 해석, 적용되는 모습을 볼 수 있습니다.

웹 사이트 정보 수집
1. 웹 프록시의 이용
웹 사이트 정보 수집
웹 사이트 정보 수집 방법으로는 웹 프록시를 이용한 방법과 구글 해킹, 파일 접근법이 있습니다.

그럼 웹 사이트 정보 수집이 어떻게 이루어 지는지 각각에 대해 자세히 살펴볼까요?
프록시란 클라이언트가 자신을 통해서 다른 네트워크 서비스에 간접적으로 접속할 수 있게 해 주는 컴퓨터나 응용 프로그램입니다.
웹 해킹에 많이 사용되는 프록시 툴로는 Paros가 있습니다.

Paros에 대해서 좀더 알아보겠습니다. Paros는 오른쪽 위에는 웹 서버에 대한 요청, 응답, 현재 붙잡고 있는 창으로 구성되어 있습니다.
Trap에서는 아래쪽의 Trap request와 Trap response 항목을 체크해야 해당 패킷을 붙잡아 보는 것이 가능합니다.
웹 프록시 Paros를 이용해 정보를 수집하기 위해서는 [도구]-[인터넷 옵션]-[연결]-[LAN 설정]에서 프록시 서버를 그림과 같이 설정해주어야 합니다. 이 때 사용되는 127.0.0.1을 흔히 루프백(Loopback) 주소라 하는데, PC 자기 자신을 의미합니다. 8080은 Paros의 서비스 포트입니다.

프록시 서버를 설정 후에 Paros에서 웹 사이트 취약점 스캐닝을 통해 특정 웹 사이트에 취약점을 수집할 수 있습니다.

2. 구글 해킹
웹 해킹을 하면서 많은 정보를 수집하는 유용한 방법으로 검색 엔진을 이용하는데요. 흔히 이러한 정보 수집 방법으로 구글을 사용합니다.

구글에서는 여러 가지 고급 검색 기능을 제공합니다. 검색 인자 중 site를 사용하면 특정 도메인으로 지정한 사이트에서 검색하려는 문자열이 포함된 사이트를 찾습니다. 검색 인자로 filetype을 사용하면 특정한 파일 유형에 한해서 검색하는 문자가 들어있는 사이트를 찾게 됩니다. 그리고 link를 사용하면 링크로써 검색하는 문자가 들어 있는 사이트를 찾게 됩니다.
Cache는 특정 검색어에 해당하는 캐시된 페이지를 보여줍니다. Intitle은 페이지의 제목에 검색하는 문자가 들어 있는 사이트를 찾으며, Inurl은 페이지의 URL에 검색하는 문자가 들어 있는 사이트를 찾게 됩니다.

구글에서 제공하는 고급 검색 기능에 대해서 좀더 자세히 알아볼까요? Site 검색 인자는 특정 사이트에 한정된 검색을 수행할 때사용할 수 있습니다. 직접 Site 검색 인자로 구글에서 검색을 한 화면입니다. 예시와 같이 특정한 도메인 내에 존재하는 admin이란 문자열을 찾을 수 있습니다.

Filetype 검색 인자는 특정 파일 유형에 대해 검색할 때 사용합니다. 예시는 검색어로 파일 확장자가
txt이고 패스워드라는 문자열이 들어간 파일을 검색한 화면입니다.

link 검색 인자는 특정 링크가 포함되어 있는 페이지를 검색할 때 사용됩니다. 예시와 같이 주소를 링크하고 있는 웹 페이지를 검색할 수 있습니다.

Cache 검색 인자는 구글에서 백업해 둔 페이지의 정보를 보고자 할 때 사용합니다. 관리자가 자신이 관리하는 웹의 취약점을 확인하여 이를 수정하더라도, 검색 엔진에 의해 백업된 데이터에 취약점 정보 노출될 수 있기 때문에 관리자도 검색 엔진에 백업된 자신의 사이트를 주기적으로 확인하는 것이 좋습니다.

캐시로 인해 노출되면 안 되는 정보가 백업되어 있을 경우에는 이를 삭제해
달라고 정식으로 요청해야 합니다.
intitle 검색 인자는 페이지의 제목에 검색하는 문자가 들어 있는 사이트를 찾을 때 사용하는데요. 디렉터리 리스팅 취약점이 존재하는 사이트를 쉽게 찾을 수 있습니다.

inurl 검색 인자는 site와 기능이 유사기능을 수행합니다. 예시와 같이 URL에 사이트 주소와 login이라는 문자열을 모두 포함하는 사이트를 검색합니다.

구글 검색으로 인해 웹 사이트의 취약점이 파악되는 것을 회피하기 위한 방법으로, 서버의 홈 디렉터리에 robots.txt 파일을 만들어 검색할 수 없게 만들 수 있습니다. robots.txt 파일이 있으면 구글 검색 엔진은 robots.txt에 있는 디렉터리는 검색하지 않습니다. robots.txt 파일은 Useragent와 Disallow를 통해 검색엔진의 검색을 차단할 수 있습니다. 구글 해킹을 막는 또 다른 방법에 대해서는 마우스 버튼을 클릭하여 세부 내용을 확인하세요.




3. 파일 접근
웹 사이트의 파일에 대한 접근에 대해서 알아보겠습니다. 디렉터리 리스팅은 웹 브라우저에서 웹 서버의 특정 디렉터리를 열면 그 디렉터리에 있는 파일과 디렉터리 목록이 모두 나열되는 것을 말합니다. 웹 서버의 디렉터리 구조를 알면 웹 브라우저 주소창에 해당 경로를 입력하여 직접 접근할 수 있는데요. 디렉터리 리스팅으로 비정상적인 파일 접근이 가능하게 됩니다.

상용 프로그램을 이용한 편집은 확장자가 bak이나 old인 백업 파일을 자동으로 생성되는 경우가 있습니다. 이러한 백업 파일들은 서버 측에서 실행되고 결과만 웹 페이지로 보여주는 ASP, JSP 파일과는 달리 클라이언트가 그 파일을 직접 다운로드 받을 수 있습니다. 이렇게 획득한 소스 파일에는 서버의 로직뿐만 아니라 네트워크 정보 등 다양한 정보가 포함되어 있을 수 있으며, 대부분의 웹 스캐너는 이러한 파일을 자동으로 찾을 수 있습니다. 따라서 사용 프로그램을 통해 소스 코드를 편집할 경우 임시/백업 파일의 생성과 관리가 중요합니다.

파일을 다운로드할 때 가장 많이 쓰이는 방법은 웹 서버에서 제공하는 파일 다운로드 페이지를 이용하는 것입니다. 정상적인 경우는 예와 같은 다운로드 경로를 사용하지만, 게시판에서 글 목록을 보여주는 list.jsp 파일의 위치가 쉽게 노출된다면 주소창에 예와 같이 입력하여 list.jsp의 파일 다운로드가 쉽게 가능하게 됩니다.

파일 시스템에서 .은 현재 디렉터리를 ..은 상위 디렉터리를 의미합니다. 공격자가 디렉터리 리스팅 방법 등으로 서버의 파일 구조를 알고 있으면 디렉터리 이동 명령인자를 통해 상위에 다른 위치에 있는 파일을 다운로드 할 수 있습니다.

보기는 웹 서버의
다운로드 filename 변수를 조작하여 상위에 존재하는 파일을 다운로드 하는 모습을 보여 주고 있습니다.
다음 보기들은 파일 경로 변경 명령인자를 사용하여 다양한 위치에 존재하는 파일들 다운로드 하는 예시입니다. 마우스 버튼을 클릭하여 세부 내용을 확인하세요.

'정보 보호' 카테고리의 다른 글
| 15 기타 웹 보안 취약점 (0) | 2016.02.18 |
|---|---|
| 14 주요 웹 보안 취약점 (2) | 2016.02.18 |
| 12 네트워크 기반 공격 (1) | 2016.02.13 |
| 시큐리티 하이테크 정보보안 세미나 -2 (1) | 2016.02.03 |
| 시큐리티 하이테크 정보보안 세미나 (0) | 2016.02.03 |
13 웹 해킹의 이해
웹의 이해
1. 인터넷의 역사
웹의 이해
처음 해커는 우리가 알고 있는 컴퓨터의 취약점을 악용하는 사용자가 아니었습니다. 메사추세츠 공과대학의 모형 기차 제작 동아리인 TMRC에서, 전자 장치로 기차, 트랙, 스위치를 제어하여 ‘보다 빠르게 조작하다’라는 의미로 사용되었습니다.
기차를 잘 움직이게 하기 위하여 컴퓨터를 연구하게 되었고 그 대상이 기차에서 컴퓨터 자체에 대한 연구와 프로그램을 개발하는 쪽으로 변화하게 됨으로써 해킹이라는 의미가 현재의 의미로 사용되었습니다.
웹에 대한 이해를 위해 인터넷의 역사를 살펴보도록 하겠습니다. 인터넷은 프로토콜과 게이트웨이에서 네트워크로, 웹에서 HTML 웹 브라우저로 발전하였습니다. 인터넷은 처음에 대학의 연구실 간의 데이터 전송을 위해 개발되었는데요. 초기에는 단순히 하나의 시스템과 멀리 떨어져 있는 다른 시스템간의 통신을 위한 프로토콜로 만들어졌습니다. 그 후, 프로토콜을 해석한 후 이를 다른 프로토콜로 바꾸어 다른 시스템에 전송해 주는 게이트웨이가 개발되었죠.
그 다음, 1969년 미 국방부 산하 고등연구 계획국에 의해 전 세계 주요 거점을 연결하는 네트워크가 만들어졌습니다. 이 네트워크를 알파넷이라고 부르며, 곧 인터넷이 시작되었습니다. 한국의 경우, 1994년 한국통신이 카이스트와 연구기관의 학술 교육 및 정보 교류용으로 제공한 ‘하나망’을 일반인에게 개방하여 코넷을 시작함으로써 인터넷에 첫 발을 내딛게 됩니다.
웹 주소의 시작인 WWW는 전 세계 규모의 거미집 또는 거미집 모양의 망이라는 뜻으로, 흔히 웹이라고 합니다. 1989년 스위스 제네바의 유럽 원자핵 공동 연구소에서 근무하던 ‘팀 버너스 리’에 의해 연구 목적의 프로젝트로 시작되는데요.
WWW의 프로젝트의 목적은 전 세계에 흩어져 있는 종업원 및 연구자와 연구 결과나 아이디어를 공유할 수 있는 방법을 찾기 위해서였습니다.
처음 계획할 무렵에는 웹을 ‘Hyper Text Project’라고 불렀습니다.
하이퍼텍스트란 60년대 데드 넬슨이 만든 신조어로 다른 문서와 연관관계를 가지는 텍스트라는 뜻입니다. 하이퍼텍스트를
이용하면 단어나 문구를 마우스 클릭을 통해 관련 주제에 대한 다른 정보를 가지는 문서로 이동하여 정보를 추가로 얻을 수 있습니다. 현재 웹 문서로 가장 흔히 쓰이는 HTML은 하이퍼덱스트를 효과적으로 전달하기 위한 규칙을 정의하는 스트립트 언어입니다.
웹에 접근하기 위해서는 웹 브라우저가 필요합니다. 웹 브라우저인 모자이크는 1992년 배포되었으며, 글자 위에서 마우스 버튼을
클릭할 수 있는 하이퍼링크가 처음 구현되어 인터넷 초기에 붐을 일으킨 촉발제 역할을 하였습니다.
1994년에 발표된 네스케이프 네비게이터는 인터넷 대중화에 기여했지만 현재는 사라진 웹 브라우저입니다.
2. HTTP
이번에는 HTTP에 대해 알아보겠습니다. HTTP는 0.9 버전부터 사용되었는데요. 단순히 읽기 기능만 가능하였습니다. 0.9 버전의 연결 과정을 보면 연결 요청을 받은 서버는 그 클라이언트에 대해 서비스를 준비합니다. 서버가 준비 상태가 되면, 클라이언트는 읽고자 하는 문서를 서버에 요청합니다. 서버는 웹 문서 중 클라이언트가 요청한 문서를 클라이언트에 전송하고 연결을 종료합니다. HTTP 0.9 버전은 하나의 웹 페이지 안에 존재하는 텍스트와 그림마다 connect 과정을 반복해서 거쳐야 하기 때문에 비효율적이라는 단점이 있습니다.
Request 패킷이란 웹 서버에 데이터를 요청할 때 보내는 메시지로서, GET/POST/HEAD 등이 있습니다. GET 메소드는 가장 일반적으로 사용되는데요. 웹 브라우저에 요청 데이터에 대한 인수를 URL을 통해 전달하는 방식을 말합니다. 보시는 예와 구글에서 서치할 내용이 명시가 되죠. 보낼 수 있는 데이터의 크기는 최대 4KB입니다.
일반적으로 게시판의 목록이나 글 보기 화면은 접근 자유도를 부여하기 위해 GET 방식을 사용합니다.
POST 메소드는 GET과 함께 가장 많이 사용되는 메소드입니다. URL에 요청 데이터를 기록하지 않고 소켓을 이용해 데이터를 전송하죠. POST 방식에서와 같은 인수 부분이 존재하지 않습니다. 인수값을 URL을 통해 전송하지 않기 때문에 다른 이가 링크를 통해 해당 페이지를 볼 수 없습니다.
이 방식은 접근이 자유롭지 못하고, 웹 브라우저의 ‘뒤로’ 버튼을 클릭하면 포스트의 버퍼 부분이 사라져 ‘새로고침’ 경고 문구가 뜨는 단점이 있습니다. 그렇지만 파일 업로드는 POST로만 전송 가능하며, 보낼 수 있는 데이터의 크기의 제한이 없습니다.
보내려는 데이터가 URL을 통해서 노출되지 않기 때문에 보안 면에서 매우 중요합니다. 일반적으로 게시판의 글 저장/수정/삭제 등은 보안 등을 위해서는 POST 방식을 사용합니다.
기타 메소드 중에서 HEAD 메소드는 서버 측의 데이터를 검색하고 요청하는데 사용하며 OPTIONS 메소드는 자원에 대한 요구/응답 관계에서 관련된 선택사항의 정보를 요청할 때 사용합니다. PUT 메소드는 메시지에 포함되어 있는 데이터를 지정한 URI 장소에 그 이름으로 저장하며 DELETE 메소드는 URI에 지정되어 있는 자원을 서버에서 제거합니다. TRACE 메소드는 요구 메시지의 최종 수신처까지의 루프백 검사용으로 사용됩니다.
3. 웹 언어
인터넷 웹 브라우저에 사용되는 웹 언어를 HTML과 SSS, CSS로 나누어 살펴보겠습니다.
HTML는 가장 단순한 형태의 웹 언어입니다. 웹 서버에 HTML 문서를 저장하고 있다가 클라이언트가 특정 HTML 페이지를 요청하면 웹 서버가 검색하여 해당 HTML 문서를 클라이언트로 전송해주고 브라우저가 HTML을 처리하는데 이런 웹 페이지를 정적인(Static) 웹 페이지라고 합니다. 이때 HTML 페이지를 요청하는 것은 HTTP 프로토콜을 따르게 됩니다.
단순한 형태의 HTML문서는 클라이언트의 웹 브라우저를 통해 웹 서버의 무엇인가를 바꿀 수 있는 가능성이 매우 낮기 때문에 웹을 이용한 공격이 매우 어렵습니다.
SSS는 Server Side Script로, ASP나 JSP와 같은 언어가 있습니다. 이러한 언어는 동적인 페이지를 제공하는 스크립트를 언어입니다. 스크립트에 HTML 확장자 대신 ASP 또는 JSP의 확장자를 가진 웹 문서를 요청하면 ASP는 DLL이나 OCX 같은 파일을 이용해, JSP는 서블릿을 이용해 요청을 처리하고 그 결과를 HTML 파일로 만들어 클라이언트에 전송합니다. 웹 서버가 스크립트 엔진에게 요청하여
스크립트와 일반 HTML 페이지를 생성하기 때문에 동적인 페이지를 제공하는 스크립트입니다.
CSS는 Client Side Script로 웹 서비스에 이용되는 스크립트에는 자바 스크립트나 비주얼 베이직 스크립트 등이 있습니다. 이들은
서버가 아닌 클라이언트 측의 웹 브라우저에 의해 해석되고 적용됩니다.
CSS언어에서는 클라이언트가 자바 스크립트를 작성합니다. 클라이언트가 웹 페이지에 포함된 스크립트 파일을 요청하면 웹 서버가
해당 스크립트 파일을 검색하여 해당 스크립트 파일을 브라우저에 반환하게 됩니다. 브라우저가 클라이언트측 스크립트를 처리하므로 서버가 아닌 클라이언트 측의 웹 브라우저에 의해 해석, 적용되는 모습을 볼 수 있습니다.
웹 사이트 정보 수집
1. 웹 프록시의 이용
웹 사이트 정보 수집
웹 사이트 정보 수집 방법으로는 웹 프록시를 이용한 방법과 구글 해킹, 파일 접근법이 있습니다.
그럼 웹 사이트 정보 수집이 어떻게 이루어 지는지 각각에 대해 자세히 살펴볼까요?
프록시란 클라이언트가 자신을 통해서 다른 네트워크 서비스에 간접적으로 접속할 수 있게 해 주는 컴퓨터나 응용 프로그램입니다.
웹 해킹에 많이 사용되는 프록시 툴로는 Paros가 있습니다.
Paros에 대해서 좀더 알아보겠습니다. Paros는 오른쪽 위에는 웹 서버에 대한 요청, 응답, 현재 붙잡고 있는 창으로 구성되어 있습니다.
Trap에서는 아래쪽의 Trap request와 Trap response 항목을 체크해야 해당 패킷을 붙잡아 보는 것이 가능합니다.
웹 프록시 Paros를 이용해 정보를 수집하기 위해서는 [도구]-[인터넷 옵션]-[연결]-[LAN 설정]에서 프록시 서버를 그림과 같이 설정해주어야 합니다. 이 때 사용되는 127.0.0.1을 흔히 루프백(Loopback) 주소라 하는데, PC 자기 자신을 의미합니다. 8080은 Paros의 서비스 포트입니다.
프록시 서버를 설정 후에 Paros에서 웹 사이트 취약점 스캐닝을 통해 특정 웹 사이트에 취약점을 수집할 수 있습니다.
2. 구글 해킹
웹 해킹을 하면서 많은 정보를 수집하는 유용한 방법으로 검색 엔진을 이용하는데요. 흔히 이러한 정보 수집 방법으로 구글을 사용합니다.
구글에서는 여러 가지 고급 검색 기능을 제공합니다. 검색 인자 중 site를 사용하면 특정 도메인으로 지정한 사이트에서 검색하려는 문자열이 포함된 사이트를 찾습니다. 검색 인자로 filetype을 사용하면 특정한 파일 유형에 한해서 검색하는 문자가 들어있는 사이트를 찾게 됩니다. 그리고 link를 사용하면 링크로써 검색하는 문자가 들어 있는 사이트를 찾게 됩니다.
Cache는 특정 검색어에 해당하는 캐시된 페이지를 보여줍니다. Intitle은 페이지의 제목에 검색하는 문자가 들어 있는 사이트를 찾으며, Inurl은 페이지의 URL에 검색하는 문자가 들어 있는 사이트를 찾게 됩니다.
구글에서 제공하는 고급 검색 기능에 대해서 좀더 자세히 알아볼까요? Site 검색 인자는 특정 사이트에 한정된 검색을 수행할 때사용할 수 있습니다. 직접 Site 검색 인자로 구글에서 검색을 한 화면입니다. 예시와 같이 특정한 도메인 내에 존재하는 admin이란 문자열을 찾을 수 있습니다.
Filetype 검색 인자는 특정 파일 유형에 대해 검색할 때 사용합니다. 예시는 검색어로 파일 확장자가
txt이고 패스워드라는 문자열이 들어간 파일을 검색한 화면입니다.
link 검색 인자는 특정 링크가 포함되어 있는 페이지를 검색할 때 사용됩니다. 예시와 같이 주소를 링크하고 있는 웹 페이지를 검색할 수 있습니다.
Cache 검색 인자는 구글에서 백업해 둔 페이지의 정보를 보고자 할 때 사용합니다. 관리자가 자신이 관리하는 웹의 취약점을 확인하여 이를 수정하더라도, 검색 엔진에 의해 백업된 데이터에 취약점 정보 노출될 수 있기 때문에 관리자도 검색 엔진에 백업된 자신의 사이트를 주기적으로 확인하는 것이 좋습니다.
캐시로 인해 노출되면 안 되는 정보가 백업되어 있을 경우에는 이를 삭제해
달라고 정식으로 요청해야 합니다.
intitle 검색 인자는 페이지의 제목에 검색하는 문자가 들어 있는 사이트를 찾을 때 사용하는데요. 디렉터리 리스팅 취약점이 존재하는 사이트를 쉽게 찾을 수 있습니다.
inurl 검색 인자는 site와 기능이 유사기능을 수행합니다. 예시와 같이 URL에 사이트 주소와 login이라는 문자열을 모두 포함하는 사이트를 검색합니다.
구글 검색으로 인해 웹 사이트의 취약점이 파악되는 것을 회피하기 위한 방법으로, 서버의 홈 디렉터리에 robots.txt 파일을 만들어 검색할 수 없게 만들 수 있습니다. robots.txt 파일이 있으면 구글 검색 엔진은 robots.txt에 있는 디렉터리는 검색하지 않습니다. robots.txt 파일은 Useragent와 Disallow를 통해 검색엔진의 검색을 차단할 수 있습니다. 구글 해킹을 막는 또 다른 방법에 대해서는 마우스 버튼을 클릭하여 세부 내용을 확인하세요.
3. 파일 접근
웹 사이트의 파일에 대한 접근에 대해서 알아보겠습니다. 디렉터리 리스팅은 웹 브라우저에서 웹 서버의 특정 디렉터리를 열면 그 디렉터리에 있는 파일과 디렉터리 목록이 모두 나열되는 것을 말합니다. 웹 서버의 디렉터리 구조를 알면 웹 브라우저 주소창에 해당 경로를 입력하여 직접 접근할 수 있는데요. 디렉터리 리스팅으로 비정상적인 파일 접근이 가능하게 됩니다.
상용 프로그램을 이용한 편집은 확장자가 bak이나 old인 백업 파일을 자동으로 생성되는 경우가 있습니다. 이러한 백업 파일들은 서버 측에서 실행되고 결과만 웹 페이지로 보여주는 ASP, JSP 파일과는 달리 클라이언트가 그 파일을 직접 다운로드 받을 수 있습니다. 이렇게 획득한 소스 파일에는 서버의 로직뿐만 아니라 네트워크 정보 등 다양한 정보가 포함되어 있을 수 있으며, 대부분의 웹 스캐너는 이러한 파일을 자동으로 찾을 수 있습니다. 따라서 사용 프로그램을 통해 소스 코드를 편집할 경우 임시/백업 파일의 생성과 관리가 중요합니다.
파일을 다운로드할 때 가장 많이 쓰이는 방법은 웹 서버에서 제공하는 파일 다운로드 페이지를 이용하는 것입니다. 정상적인 경우는 예와 같은 다운로드 경로를 사용하지만, 게시판에서 글 목록을 보여주는 list.jsp 파일의 위치가 쉽게 노출된다면 주소창에 예와 같이 입력하여 list.jsp의 파일 다운로드가 쉽게 가능하게 됩니다.
파일 시스템에서 .은 현재 디렉터리를 ..은 상위 디렉터리를 의미합니다. 공격자가 디렉터리 리스팅 방법 등으로 서버의 파일 구조를 알고 있으면 디렉터리 이동 명령인자를 통해 상위에 다른 위치에 있는 파일을 다운로드 할 수 있습니다.
보기는 웹 서버의
다운로드 filename 변수를 조작하여 상위에 존재하는 파일을 다운로드 하는 모습을 보여 주고 있습니다.
다음 보기들은 파일 경로 변경 명령인자를 사용하여 다양한 위치에 존재하는 파일들 다운로드 하는 예시입니다. 마우스 버튼을 클릭하여 세부 내용을 확인하세요.
'정보 보호' 카테고리의 다른 글
| 15 기타 웹 보안 취약점 (0) | 2016.02.18 |
|---|---|
| 14 주요 웹 보안 취약점 (2) | 2016.02.18 |
| 12 네트워크 기반 공격 (1) | 2016.02.13 |
| 시큐리티 하이테크 정보보안 세미나 -2 (1) | 2016.02.03 |
| 시큐리티 하이테크 정보보안 세미나 (0) | 2016.02.03 |