하둡 Flume
Flume
아파치 Flume은 스트리밍 데이터를 수집하기 위한 분산 시스템이다.
이 프로젝트는 인큐베이터 상태에 있는 아파치 프로젝트로, 본래 클라우데라(Cloudera)에서 개발했다.
Flume은 필요에 따라 조절할 수 있는 다양한 수준의 안정성과 전송 보장 기능을 제공한다.
Flume은 사용자 설정을 폭넓게 지원하며, 커스텀 소스 및 데이터 싱크를 추가할 수 있는 플러그인 아키텍처를 지원한다.

Flume을 활용한 HDFS로의 시스템 로그 발행
여러 서버의 애플리케이션 및 시스템에서 생산하는 수많은 로그 파일에 중요한 정보가 있다.
이런 정보를 분석하려면, 하둡 클러스터로 로그 파일을 옮기는 작업을 해야 한다.
데이터 수집 프로그램인 Flume을 활용해 리눅스 로그 파일을 HDFS에 집어넣고, 분산 환경에서 Flume을 실행하는 데 필요한 설정을 살펴보고, 안정성 모드에 대해서도 살펴보자
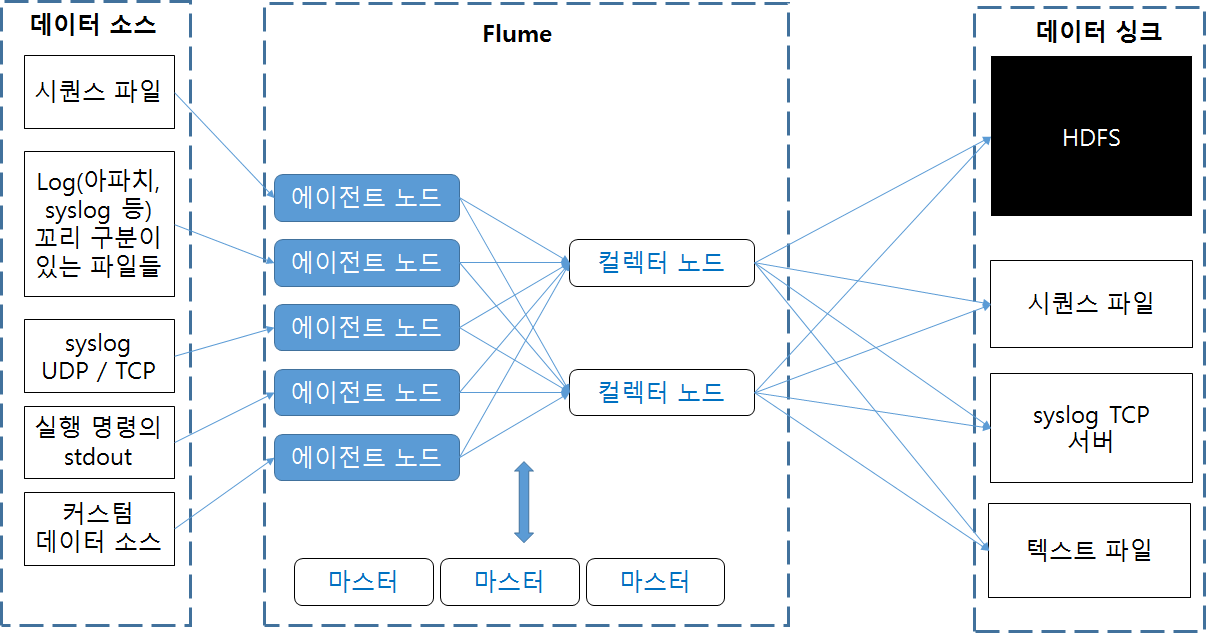
위 그림에서 전체 Flume 배포 환경을 볼 수 있다. 이 환경은 네 개의 주요 컴포넌트(Component)로 이뤄진다.
컴포넌트
> 노드: 데이터 소스에서 데이터 싱크로 데이터를 옮기는 Flume 데이터 경로
에이전트와 컬렉터는 많은 데이터 소스를 효율적이고 안정적으로 처리할 수 있게 배포한
단순 Flume 노드일 뿐이다.
> 에이전트: 로컬 호스트(local host)에서 스트리밍 데이터를 수집해 컬렉터에게 전달한다.
> 컬렉터: 에이전트가 보낸 데이터를 취합해 HDFS에 데이터를 쓴다.
> 마스터: 설정 관리 작업을 수행하고 안정적인 데이터 흐름을 돕는다.
위 그림에서 또한 데이터 소스와 데이터 싱크도 볼 수 있다.
데이터 소스는 다른 곳으로 전송하려는 데이터가 들어 있는 위치를 스트리밍 한다.
이런 위치의 에로는 애플리케이션 로그 및 리눅스 시스템 로그, 커스텀 데이터 소스로 지원할 수 있는 비텍스트 데이터 등이 있다.
데이터 싱크는 해당 데이터의 목적지로서, HDFS, 플랫 파일, 커스텀 데이터 싱크로 지원할 수 있는 임의의 데이터 타깃이 될 수 있다.
Flume을 의사 분산 모드로 실행한다. Flume 컬렉터, 에이전트, 마스터 데몬을 단일 호스트에서 실행한다.
우선 CDH3 설치 가이드를 통해 Flume, Flume 마스터, Flume 노드 패키지를 설치해야 한다.
Flume 설치
http://flume.apache.org/download.html

이 사이트에서 Apache Flume binary(tar.gz) 를 다운로드 받습니다.
또는 $ wget http://apache.mirror.cdnetworks.com/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
$ tar -xvfz apache-flume-1.6.0-bin.tar.gz
$ ln -s apache-flume-1.6.0-bin.tar.gz flume
apache-flume-1.6.0-bin을 압축을 풀고 디렉터리를 flume으로 생성합니다
환경 변수 설정
FLUME_HOME 이라는 환경변수에 방금 설치한 Flume 경로를 입력해 사용자의 bash_profile에 저장해야 합니다. 이어서 FLUME_CONF_DIR 이라는 변수를 입력하고, 이 환경 변수를 Flume 프로세스가 사용하는 설정 파일을 읽어 들입니다.
$ vi ~/.bash_profile
export FLUME_HOME=/home/hadoop/flume
export FLUME_CONF_DIR=/home/hadoop/flume/conf
:wq
source .bash_profile
workflow Test
설치가 완료됐으면 샘플 workflow를 수행해 정상적으로 작동하는 지 확인합니다.
샘플 workflow 파일은 $FLUME_HOME/conf 디렉터리 아래의 flume-conf.properties.template에 있습니다.
conf/flume-env.sh에서 java 경로를 지정한다.
JAVA_HOME=/usr/java/jdkX.X
해당 파일을 복사해 실제 workflow 파일을 생성한다.
$ cd $FLUME_HOME/conf
$ cp flume-conf.properties.template flume.conf
파일이 생성되었으면 flume-agent를 vi 편집기로 수정합니다.
$vi flume.conf
agent.source = seqGenSrc #agent라는 이름을 갖는 workflow의 데이터소스를 지정합니다.
agent.channels = memoryChannel #agent라는 이름을 가지는 workflow에서 사용할 채널을 지정합니다.
agent.sinks = loggerSink #agent workflow에서 사용할 Sync, 즉 데이터를 쓸 곳을 정의 합니다.
# For each one of the sources, the type is defined
agent.sources.seqGenSrc.type = seq #seqGenSrc이라는 데이터 소스의 종류를 지정합니다.
#seq는 0부터 순서대로 번호를 붙이며 숫자를 생성합니다.
agent.sources.seqGenSrc.channels = memoryChannel #seqGenSrc에서 사용할 메모리 채널 이름 지정
# Each sink's type must be defined
agent.sinks.loggerSink.type = logger #싱크가 사용할 타입을 지정한다. logger(자바의 로깅)
agent.sinks.loggerSink.channel = memeoryChannel # 사용할 채널 지정
# Each channel’s ype is defined.
agent.channels.memoryChannel.type = memory # memory 채널의 타입 지정
agent.channels.memoryChannel.capacity = 100 # 채널에 해당하는 옵션. 이벤트를 100까지 저장
:wq
Flume을 실행해볼까요?
$ bin/flume-ng -> Flume의 명령어
agent -> 인자 중 workflow 에이전트를 수행하는 에이전트를 수행
-c conf/ --conf-file conf/flume-conf .properties -> workflow를 정의한 파일을 지정
--name agent -> workflow 중에서 에이전트로 시작하는 작업 수행
-Dflume.root.logger=INFO,console -> logger를 위한 세팅을 한다.
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume.conf .properties --name agent -Dflume.root.logger=INFO,console
위의 인자로 잘 수행되었다면 증가하는 숫자가 화면에 나타납니다.
Flume과 데이터 소스의 연결
Network Stream logging
Netcat 서버를 통해 네트워크 서버를 구동하고, 결과는 터미널을 통해 확인해보겠습니다.
$ cd $FLUME_HOME/conf
$ cp flume-conf.properties.template flume-conf-netcat
다음과 같이 파일을 작성합니다.
$ vi flume-netcat.conf
agent.sources = s1
agent.channels = c1
agent.sinks = k1
### For each one of the sources, the type is defined
agent.sources.s1.type = netcat # netcat은 로컬에 네트워크 서버를 생성합니다.
agent.sources.s1.bind = localhost # bind 주소를 지정
agent.sources.s1.port = 9090 # 서버가 응답할 port를 지정합니다.
### The channel can be defined as follows.
agent.sources.s1.channels = c1
### Each sink’s type must be defined.
agent.sinks.k1.type = logger
### Specify the channel the sink should use
agent.sinks.k1.channel = c1
### Each channel’s type is defined.
agent.channels.c1.type = memory
workflow 파일이 완성됐으면 다음 명령어를 사용해 실행
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume-conf-netcat.properties --name agent -Dflume.root.logger=INFO,console
정상적으로 수행됐으면 스크린의 마지막에 (127.0.0.1:9090)로 이벤트의 발생을 대기하고 있다는 메시지가 출력될 것이다.
serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:9090]
정상적으로 대기상태 확인이 되었다면 터미널을 하나 더 열어 텔넷으로 대기상태에 있는 서버를 호출하고 출력을 원하는 string을 입력해보자
$ telnet localhost 9090
Trying ::: 1…
telnet : connect to address::1: Connection refused
Trying 127.0.0.1 …
Connected to localhost.
Escape character is ‘^]’.
Hello My name is JeongChul
OK
정상적으로 작동됐다면 Flume을 수행한 창에서도 동일하게 Hello My name is JeongChul 라는 문자열이 출력 될 것이다.
org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)} Event: { headers:{} body : XX XX XX XX XX XX XX XX XX XX XX XX XX XX Hello My name is JeongChul }
Multi-Agent
2개의 에이전트를 구성하여, 데이터를 주고 받겠습니다.
Agent1의 Flume workflow 파일 생성
$ cd $FLUME_HOME/conf
$ cp flume-conf.properties.template flume-conf-multi
다음과 같이 파일을 작성합니다.
$ vi flume-conf-multi
### Agent1
agent1.sources = s1
agent1.channels = c1
agent1.sinks = k1
### For each one of the sources, the type is defined
agent1.sources.s1.type = exec
agent1.sources.s1.bind = tail -F /var/log/secure
agent1.sources.s1.channels = c1
### Each sink’s type must be defined.
agent1.sinks.k1.type = avro # 멀티 에이전트를 사용하기 위해 다른 호스트로 보낼 수 있도록 avro 타입의 rpc를 생성한다.
agent1.sinks.k1.hostname = localhost # 로그를 보낼 호스트를 지정합니다.
agent1.sinks.k1.port = 10000 # 포트를 지정한다.
agent1.sinks.k1.channel = c1
### Each channel’s type is defined.
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 100
### Agent2
agent1.sources = s2
agent1.channels = c2
agent1.sinks = k2
### For each one of the sources, the type is defined
agent2.sources.s2.type = avro #agent1에서 보내준 데이터를 받기 위해 avro 서버 생성
agent2.sources.s2.port = 10000 #avro 서버의 포트를 지정, agent1와 통신하기 위해 동일
agent2.sources.s2.bind = localhost # 네트워크를 bind 할 주소
### The channel can be defined as follows.
agent2.sources.s2.channels = c2
### Each sink’s type must be defined.
agent2.sinks.k2.type = logger
### Specify the channel the sink should use
agent2.sinks.k2.channel = c2
### Each channel’s type is defined.
agent2.channels.c2.type = memory
agent2.channels.c2.memoryChannel.capacity = 100
실행을 위해 우선 avro 서버의 flow를 갖고 있는 agent2를 수행한 다음 agent1을 수행한다.
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume-conf-multi --name agent2 -Dflume.root.logger=INFO,console
터미널을 하나 더 열어 agent1을 실행한다.
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume-conf-multi --name agent1 -Dflume.root.logger=INFO,console
agent1에서 데이터 소스를 syslog를 지정했으므로 다음 명령어를 수행한다.
$ echo “<33> hello vis syslog” | nc -t localhost 5140;
정상적으로 세팅돼 있는지 확인하기 위해 agent2를 실행한 화면의 로그를 확인한다.
마지막 줄로 hello via syslog가 찍힌 것을 확인 할 수 있다.
'하둡' 카테고리의 다른 글
| 하둡 설치하기-2 CentOS7 기본 설정 및 JAVA 설치 (1) | 2016.05.06 |
|---|---|
| 하둡 설치하기-1 VirtualBOX와 CentOS7 설치 (1) | 2016.05.04 |
| 하둡 Hadoop 02-1 Data logistics (0) | 2016.04.19 |
| 하둡 Hadoop 01-2 하둡 개요 (0) | 2016.01.28 |
| 하둡 Hadoop 01-1 하둡 개요 (0) | 2016.01.28 |
하둡 Flume
Flume
아파치 Flume은 스트리밍 데이터를 수집하기 위한 분산 시스템이다.
이 프로젝트는 인큐베이터 상태에 있는 아파치 프로젝트로, 본래 클라우데라(Cloudera)에서 개발했다.
Flume은 필요에 따라 조절할 수 있는 다양한 수준의 안정성과 전송 보장 기능을 제공한다.
Flume은 사용자 설정을 폭넓게 지원하며, 커스텀 소스 및 데이터 싱크를 추가할 수 있는 플러그인 아키텍처를 지원한다.
Flume을 활용한 HDFS로의 시스템 로그 발행
여러 서버의 애플리케이션 및 시스템에서 생산하는 수많은 로그 파일에 중요한 정보가 있다.
이런 정보를 분석하려면, 하둡 클러스터로 로그 파일을 옮기는 작업을 해야 한다.
데이터 수집 프로그램인 Flume을 활용해 리눅스 로그 파일을 HDFS에 집어넣고, 분산 환경에서 Flume을 실행하는 데 필요한 설정을 살펴보고, 안정성 모드에 대해서도 살펴보자
위 그림에서 전체 Flume 배포 환경을 볼 수 있다. 이 환경은 네 개의 주요 컴포넌트(Component)로 이뤄진다.
컴포넌트
> 노드: 데이터 소스에서 데이터 싱크로 데이터를 옮기는 Flume 데이터 경로
에이전트와 컬렉터는 많은 데이터 소스를 효율적이고 안정적으로 처리할 수 있게 배포한
단순 Flume 노드일 뿐이다.
> 에이전트: 로컬 호스트(local host)에서 스트리밍 데이터를 수집해 컬렉터에게 전달한다.
> 컬렉터: 에이전트가 보낸 데이터를 취합해 HDFS에 데이터를 쓴다.
> 마스터: 설정 관리 작업을 수행하고 안정적인 데이터 흐름을 돕는다.
위 그림에서 또한 데이터 소스와 데이터 싱크도 볼 수 있다.
데이터 소스는 다른 곳으로 전송하려는 데이터가 들어 있는 위치를 스트리밍 한다.
이런 위치의 에로는 애플리케이션 로그 및 리눅스 시스템 로그, 커스텀 데이터 소스로 지원할 수 있는 비텍스트 데이터 등이 있다.
데이터 싱크는 해당 데이터의 목적지로서, HDFS, 플랫 파일, 커스텀 데이터 싱크로 지원할 수 있는 임의의 데이터 타깃이 될 수 있다.
Flume을 의사 분산 모드로 실행한다. Flume 컬렉터, 에이전트, 마스터 데몬을 단일 호스트에서 실행한다.
우선 CDH3 설치 가이드를 통해 Flume, Flume 마스터, Flume 노드 패키지를 설치해야 한다.
Flume 설치
http://flume.apache.org/download.html
이 사이트에서 Apache Flume binary(tar.gz) 를 다운로드 받습니다.
또는 $ wget http://apache.mirror.cdnetworks.com/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz
$ tar -xvfz apache-flume-1.6.0-bin.tar.gz
$ ln -s apache-flume-1.6.0-bin.tar.gz flume
apache-flume-1.6.0-bin을 압축을 풀고 디렉터리를 flume으로 생성합니다
환경 변수 설정
FLUME_HOME 이라는 환경변수에 방금 설치한 Flume 경로를 입력해 사용자의 bash_profile에 저장해야 합니다. 이어서 FLUME_CONF_DIR 이라는 변수를 입력하고, 이 환경 변수를 Flume 프로세스가 사용하는 설정 파일을 읽어 들입니다.
$ vi ~/.bash_profile
export FLUME_HOME=/home/hadoop/flume
export FLUME_CONF_DIR=/home/hadoop/flume/conf
:wq
source .bash_profile
workflow Test
설치가 완료됐으면 샘플 workflow를 수행해 정상적으로 작동하는 지 확인합니다.
샘플 workflow 파일은 $FLUME_HOME/conf 디렉터리 아래의 flume-conf.properties.template에 있습니다.
conf/flume-env.sh에서 java 경로를 지정한다.
JAVA_HOME=/usr/java/jdkX.X
해당 파일을 복사해 실제 workflow 파일을 생성한다.
$ cd $FLUME_HOME/conf
$ cp flume-conf.properties.template flume.conf
파일이 생성되었으면 flume-agent를 vi 편집기로 수정합니다.
$vi flume.conf
agent.source = seqGenSrc #agent라는 이름을 갖는 workflow의 데이터소스를 지정합니다.
agent.channels = memoryChannel #agent라는 이름을 가지는 workflow에서 사용할 채널을 지정합니다.
agent.sinks = loggerSink #agent workflow에서 사용할 Sync, 즉 데이터를 쓸 곳을 정의 합니다.
# For each one of the sources, the type is defined
agent.sources.seqGenSrc.type = seq #seqGenSrc이라는 데이터 소스의 종류를 지정합니다.
#seq는 0부터 순서대로 번호를 붙이며 숫자를 생성합니다.
agent.sources.seqGenSrc.channels = memoryChannel #seqGenSrc에서 사용할 메모리 채널 이름 지정
# Each sink's type must be defined
agent.sinks.loggerSink.type = logger #싱크가 사용할 타입을 지정한다. logger(자바의 로깅)
agent.sinks.loggerSink.channel = memeoryChannel # 사용할 채널 지정
# Each channel’s ype is defined.
agent.channels.memoryChannel.type = memory # memory 채널의 타입 지정
agent.channels.memoryChannel.capacity = 100 # 채널에 해당하는 옵션. 이벤트를 100까지 저장
:wq
Flume을 실행해볼까요?
$ bin/flume-ng -> Flume의 명령어
agent -> 인자 중 workflow 에이전트를 수행하는 에이전트를 수행
-c conf/ --conf-file conf/flume-conf .properties -> workflow를 정의한 파일을 지정
--name agent -> workflow 중에서 에이전트로 시작하는 작업 수행
-Dflume.root.logger=INFO,console -> logger를 위한 세팅을 한다.
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume.conf .properties --name agent -Dflume.root.logger=INFO,console
위의 인자로 잘 수행되었다면 증가하는 숫자가 화면에 나타납니다.
Flume과 데이터 소스의 연결
Network Stream logging
Netcat 서버를 통해 네트워크 서버를 구동하고, 결과는 터미널을 통해 확인해보겠습니다.
$ cd $FLUME_HOME/conf
$ cp flume-conf.properties.template flume-conf-netcat
다음과 같이 파일을 작성합니다.
$ vi flume-netcat.conf
agent.sources = s1
agent.channels = c1
agent.sinks = k1
### For each one of the sources, the type is defined
agent.sources.s1.type = netcat # netcat은 로컬에 네트워크 서버를 생성합니다.
agent.sources.s1.bind = localhost # bind 주소를 지정
agent.sources.s1.port = 9090 # 서버가 응답할 port를 지정합니다.
### The channel can be defined as follows.
agent.sources.s1.channels = c1
### Each sink’s type must be defined.
agent.sinks.k1.type = logger
### Specify the channel the sink should use
agent.sinks.k1.channel = c1
### Each channel’s type is defined.
agent.channels.c1.type = memory
workflow 파일이 완성됐으면 다음 명령어를 사용해 실행
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume-conf-netcat.properties --name agent -Dflume.root.logger=INFO,console
정상적으로 수행됐으면 스크린의 마지막에 (127.0.0.1:9090)로 이벤트의 발생을 대기하고 있다는 메시지가 출력될 것이다.
serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:9090]
정상적으로 대기상태 확인이 되었다면 터미널을 하나 더 열어 텔넷으로 대기상태에 있는 서버를 호출하고 출력을 원하는 string을 입력해보자
$ telnet localhost 9090
Trying ::: 1…
telnet : connect to address::1: Connection refused
Trying 127.0.0.1 …
Connected to localhost.
Escape character is ‘^]’.
Hello My name is JeongChul
OK
정상적으로 작동됐다면 Flume을 수행한 창에서도 동일하게 Hello My name is JeongChul 라는 문자열이 출력 될 것이다.
org.apache.flume.sink.LoggerSink.process(LoggerSink.java:70)} Event: { headers:{} body : XX XX XX XX XX XX XX XX XX XX XX XX XX XX Hello My name is JeongChul }
Multi-Agent
2개의 에이전트를 구성하여, 데이터를 주고 받겠습니다.
Agent1의 Flume workflow 파일 생성
$ cd $FLUME_HOME/conf
$ cp flume-conf.properties.template flume-conf-multi
다음과 같이 파일을 작성합니다.
$ vi flume-conf-multi
### Agent1
agent1.sources = s1
agent1.channels = c1
agent1.sinks = k1
### For each one of the sources, the type is defined
agent1.sources.s1.type = exec
agent1.sources.s1.bind = tail -F /var/log/secure
agent1.sources.s1.channels = c1
### Each sink’s type must be defined.
agent1.sinks.k1.type = avro # 멀티 에이전트를 사용하기 위해 다른 호스트로 보낼 수 있도록 avro 타입의 rpc를 생성한다.
agent1.sinks.k1.hostname = localhost # 로그를 보낼 호스트를 지정합니다.
agent1.sinks.k1.port = 10000 # 포트를 지정한다.
agent1.sinks.k1.channel = c1
### Each channel’s type is defined.
agent1.channels.c1.type = memory
agent1.channels.c1.capacity = 100
### Agent2
agent1.sources = s2
agent1.channels = c2
agent1.sinks = k2
### For each one of the sources, the type is defined
agent2.sources.s2.type = avro #agent1에서 보내준 데이터를 받기 위해 avro 서버 생성
agent2.sources.s2.port = 10000 #avro 서버의 포트를 지정, agent1와 통신하기 위해 동일
agent2.sources.s2.bind = localhost # 네트워크를 bind 할 주소
### The channel can be defined as follows.
agent2.sources.s2.channels = c2
### Each sink’s type must be defined.
agent2.sinks.k2.type = logger
### Specify the channel the sink should use
agent2.sinks.k2.channel = c2
### Each channel’s type is defined.
agent2.channels.c2.type = memory
agent2.channels.c2.memoryChannel.capacity = 100
실행을 위해 우선 avro 서버의 flow를 갖고 있는 agent2를 수행한 다음 agent1을 수행한다.
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume-conf-multi --name agent2 -Dflume.root.logger=INFO,console
터미널을 하나 더 열어 agent1을 실행한다.
$ bin/flume-ng agent -c conf/ --conf-file ./conf/flume-conf-multi --name agent1 -Dflume.root.logger=INFO,console
agent1에서 데이터 소스를 syslog를 지정했으므로 다음 명령어를 수행한다.
$ echo “<33> hello vis syslog” | nc -t localhost 5140;
정상적으로 세팅돼 있는지 확인하기 위해 agent2를 실행한 화면의 로그를 확인한다.
마지막 줄로 hello via syslog가 찍힌 것을 확인 할 수 있다.
'하둡' 카테고리의 다른 글
| 하둡 설치하기-2 CentOS7 기본 설정 및 JAVA 설치 (1) | 2016.05.06 |
|---|---|
| 하둡 설치하기-1 VirtualBOX와 CentOS7 설치 (1) | 2016.05.04 |
| 하둡 Hadoop 02-1 Data logistics (0) | 2016.04.19 |
| 하둡 Hadoop 01-2 하둡 개요 (0) | 2016.01.28 |
| 하둡 Hadoop 01-1 하둡 개요 (0) | 2016.01.28 |