R 3.2.1 프로그래밍 - 행렬과 배열 만들기

이번 시간에 학습할 행렬과 배열에 대한 배경지식을 먼저 살펴보겠습니다 행렬이란 무엇일까요? 행렬은 행과 열에 수를배열하여 직4각형을 이루게 한 수의 집합을 말합니다. 각 수들을 행렬의 원소 또는 성분이라고 말하며, 행렬은 수학의여러 분야에서는 물론 공학·물리학·경제학·통계학 등에서 널리 응용되고 있습니다.

역사적으로 처음에는 행렬이 아니라 행렬식 이라는 정방행렬과 연관된 수 값이 인식되었다가 점차 대수적인 것으로 행렬의개념이 나타나게 되었고, 19세기 영국의 수학자 A.케일리는 행렬이라는 용어를 도입하고 행렬의 대수적 개념을 발달시켰습니다.

행렬 연산의 기초
1. 행렬 만들기
행렬 연산의 기초
행렬 연산의 기초, 행렬 만들기를 본격적으로 학습하기 전에 행렬의 구조에 대해서 알아봅시다. 행렬의 행과 열은 1부터 시작합니다. 예를 들어 행렬 a의 왼쪽 위 끝은 a[1,1]로 표기합니다. 행렬의 내부 저장 공간은 열 우선 배열(Column-Major Order) 방식입니다. 이는 1번 열 전체가 저장되고 2번 열 전체가 저장되는 방식입니다.

행렬을 만드는 한 가지 방법은 matrix() 함수를 이용하는 것입니다. 첫 번째 열로 가정한 1, 2와 두 번째 열로 가정한 3, 4를 matrix함수에 붙여서 사용합니다. 그러므로 여기서 데이터는 (1,2,3,4)입니다. 그리고 행과 열의 수를 지정해 줍니다. R에서는 열 우선 배열 방식을 사용한다는 점을 감안하여
행렬에 네 숫자를 배치하도록 합니다. 앞에서 행렬의 공간을 지정했고, 네 숫자를 배치했고, 또한 사용된 ncol이나 nrow 값 모두 적합했으므로 이제 두 변수를 모두 지정해 줄 필요가 없습니다. 총 4개의 원소에 대해 2개의 행을 가진다면, 이는 2개의 열을 가진다는 의미를 내포하고 있습니다.

행렬 Y를 출력하면 R에서는 자동으로 행렬 표시를 해줍니다. 예를 들어 [ ,2]는 2번 열 전체를 말합니다. 행렬 Y 를 생성하는 다른 방법은 각각의 원소를 지정해주는 것입니다. 이때 R에 y는 행렬이고 행과 열이 몇 개인지 미리 알려줘야 한다는 것을 기억해 둡시다. 행렬의 내부 저장소는 열 우선 배열 형식이지만, matrix()에서 byrow 인수를 참으로 설정하면 데이터가 행 우선 배열 방식으로 입력됩니다.
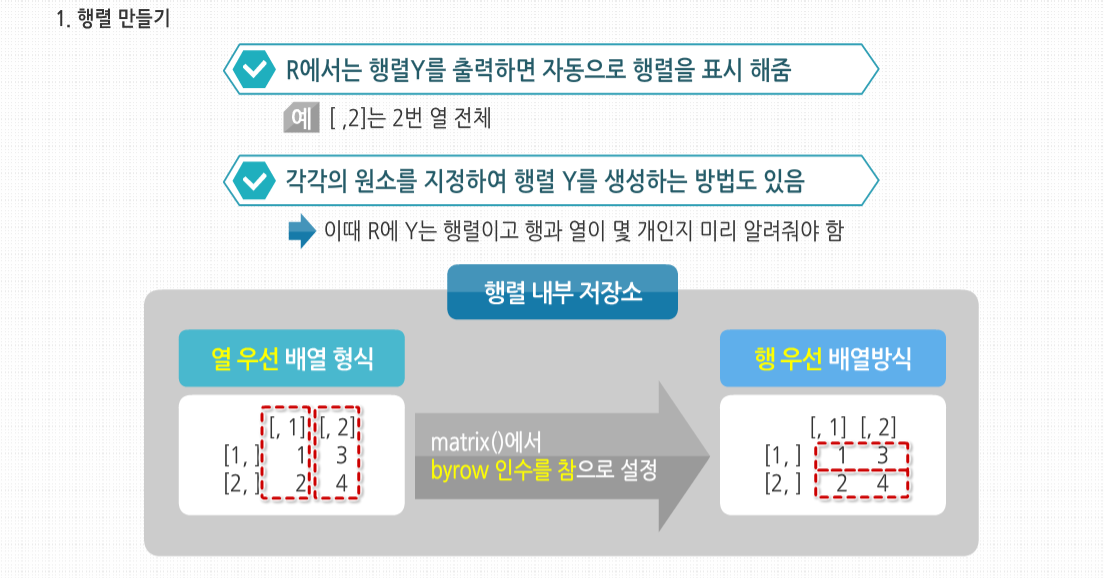
byrow를 사용한 예제를 살펴보겠습니다. 행렬은 여전히 열 우선 배열 형식으로 저장된다는 것을 기억합시다. byrow 인수는 ‘입력’ 때에만 행 우선 형태가 가능하도록 합니다. 이 방식은 데이터 파일을 열부터 기록해 사용하고자 하는 경우 편리합니다.

2. 일반 행렬 연산(선형 대수 연산 처리, 행렬 Indexing)
행렬에서 사용하는 일반적인 연산 몇 가지를 살펴보겠습니다. 여기엔 선형대수, 행렬 인덱싱, 행렬 필터링 등이 포함됩니다. 선형대수연산은 행렬 간 곱, 행렬-상수 간 곱, 행렬 간 합 등을 처리할 수 있습니다. 다음 y를 사용한 세가지 연산이 각각 살펴봅시다.

행렬 인덱싱에 대해 알아보겠습니다. 지금부터 벡터에 대해 사용한 연산들을 동일하게 행렬에 적용해 볼 것입니다. z의 2, 3번 열에 행 전체를 가져온 부분 행렬을 호출했습니다. 그러자 2, 3번째 열 전체가 추출되었습니다.
다음은 열 대신 행에서 추출한 예제입니다. y의 2, 3번째 행에 열 전체를 호출해 보았습니다. 또한 2,3번째 행의 2번째 열만 호출 할수도 있습니다. 부분행렬에 다음과 같이 값을 할당할 수도 있습니다. 이 예제에서 y의 첫 번째와 세 번째 행에 새로운 값을 할당했습니다.

부분행렬에 값을 할당하는 또 다른 예도 있습니다. 벡터에서 특정 원소를 제외하는 용도로 사용됐던 음수의 경우는 행렬에서도 동일한 방식으로 사용됩니다. 다음과 같은 명령어를 통해 y에서 두 번째 행을 제외한 모든 행을 호출했습니다. 결과는 다음과 같이 두 번째 행을 제외한 모든 행이 호출 되었습니다.

행렬 연산의 활용
1. 이미지 다루기
행렬 연산의 활용
행렬 연산의 활용 중 이미지 다루기에 대해 살펴보겠습니다. 이미지 파일의 배부는 픽셀들이 행과 열로 나열된 행렬로 돼 있습니다. 흑백 이미지의 경우 각 픽셀당 이미지의 강도 즉 밝기를 저장하고 있습니다. 그러므로 28개의 행과 88개의 열이픽셀을 가진 이미지의 강도는 28개의 행과 88개의 열을 가진 행렬에 저장하고 있다는 뜻이 됩니다. 컬러 이미지의 경우에는빨강, 녹색, 파랑에 대한 강도를 저장한 세 개의 행렬이 저장되지만, 일단은 흑백 이미지에 대해서 설명해 드리도록 하겠습니다.

미국 러시모어산 국립기념관(Mount Rushmore National Memorial) 사진을 사용해서 예시 문제를 실습해
보겠습니다. 우선, pixmap 라이브러리를 사용해 이미지 파일을 읽어 들여보겠습니다. 파일명이 mtrush.pgm인 파일을 읽어와 pixmap 객체로 만들고 그것을 다음의 그림처럼 플로팅 했을때, 이 클래스가 어떻게 구성됐는지 볼까요?
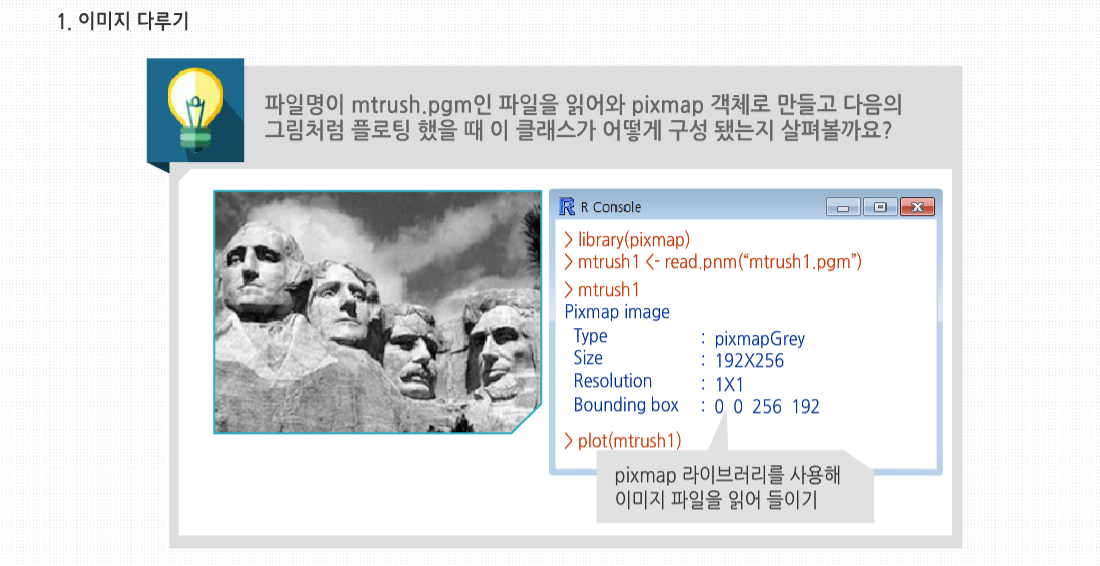
이 클래스는 각 요소가 $가 아닌 @로 지정된 S4 유형입니다. 여기서 중요한 부분은 강도에 대한 행렬인 mtrush1@grey입니다. 예제에서 이 행렬은 192 행과 256 열을 가집니다. 이 클래스에서 강도는 회색의 정도가 표현된 0.0(검정)부터 1.0(흰색)까지의 범위 내의 숫자들로 저장돼 있습니다. 예를 들어 28 행의 88 번째 열의 픽셀은 꽤 밝은 편입니다.

그렇다면, 루즈벨트 대통령의 이미지를 없애기 위해서는 어떻게 해야 할까요?

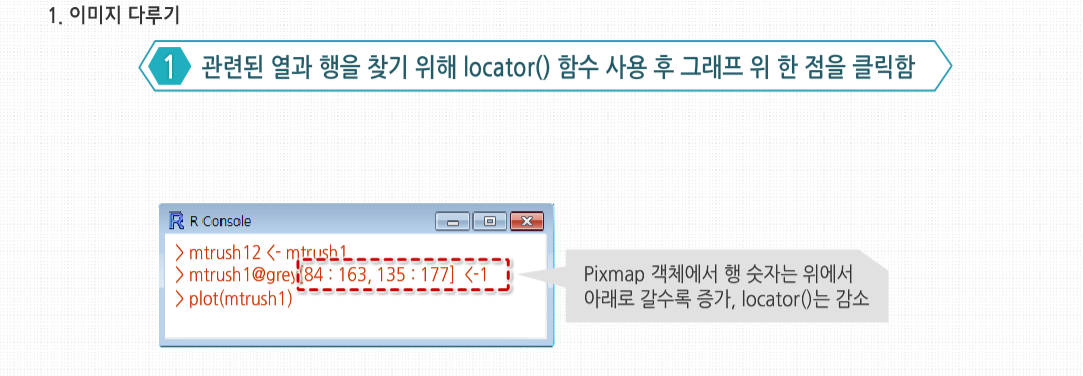
관련된 열과 행을 찾기 위해 R의 locator() 함수를 사용할 수 있습니다. 이 함수를 호출한 상태에서 그래프 위의 한 점을 클릭하면, 그 점의 정확한 위치를 알려줍니다. 이 예제에서는 루즈벨트 모습이 그림의 84-163 행과 135-177 열에 위치함을 나타냈습니다. Pixmap 객체에서 행 숫자는 위에서 아래로 갈수록 증가하고, locator()의 경우는 반대입니다.
이미지에서 이 부분을 없애 버리기 위해 이 부분의 모든 픽셀 값을 1.0으로 바꿉니다.이 결과, 다음의 그림과 같이 루즈벨트 대통령의 모습이 사라졌습니다.

루즈벨트 대통령의 이미지를 왜곡 시키고 싶다면 어떻게 해야 할까요?
루즈벨트 대통령의 형태를 왜곡시키고 싶다면 그림에 무작위로 노이즈를 넣어서 사용할 수 있습니다.

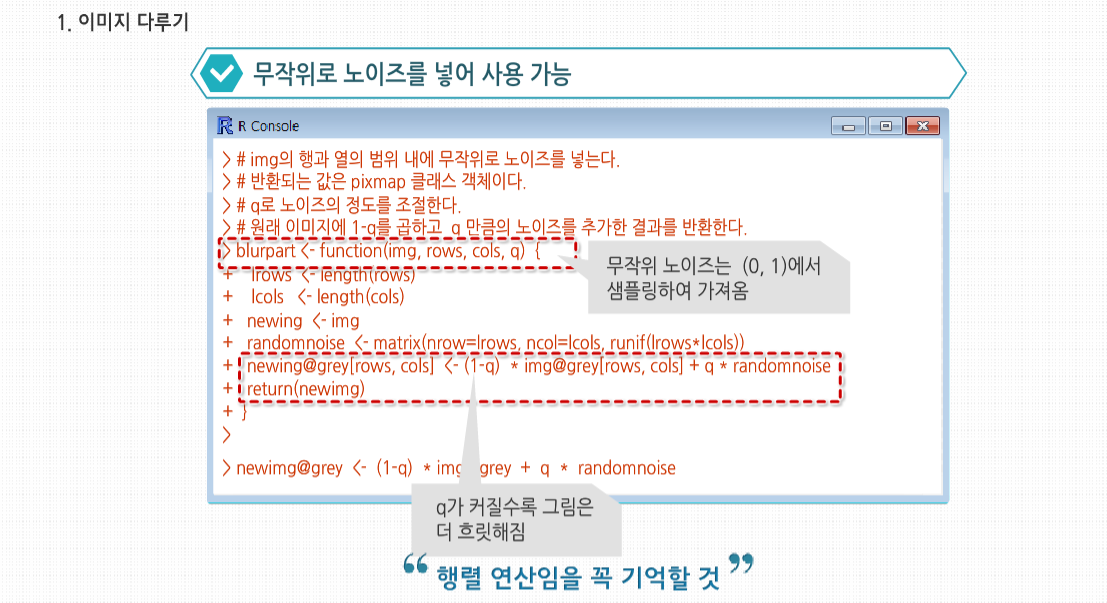
다음 코드처럼 하면 됩니다. 주석에 나온 대로 무작위로 노이즈를 생성한 후에 원 픽셀과 노이즈에 가중치를 줘 평균을 냈습니다. 매개변수 q로 노이즈의 가중치를 조절합니다. 이때 q가 커질수록 그림은 더 흐릿해집니다.
무작위 노이즈는 (0, 1)에서 샘플링해서 가져옵니다. 이 예제는 행렬 연산이라는 것을 기억하시기 바랍니다.
여기서 잠깐, 다음 빈칸에 제시된 q값을 드래그해서 넣어보고 그에 따른 이미지의 변화를 살펴봅시다.
그럼 이제 실제로 적용해 볼까요? 다음의 그림처럼 루즈벨트 대통령의 이미지의 형태가 왜곡되었습니다.
2. 행렬 필터링
행렬 필터링에 대해서 알아보도록 하겠습니다. 벡터에서처럼 행렬에서도 필터링할 수 있습니다. 다만 문법에 유의해야 합니다.
간단한 예제를 보면서 시작해 보겠습니다. 일단 x의 두 번째 열인 x[,2]인 원소가 3보다 크거나 같은지를 판단합니다. 그리고 그 결과로 나온 불리언 벡터를 j에 할당합니다. 다음과 같이 x에 j를 사용합니다. 여기서 x[j,]를 계산해 2번 열의 원소 중 최소 3 이상이었던 행들을 가져옵니다. X[j,]는 j의 원소 중 참인 값의 x의 행입니다.

성능 기준으로 봤을 때 j를 계산하는 것은 다음 조건을 모두 만족하므로 완벽하게 벡터화된 연산이라는 것을 다시 한번 상기할 필요가 있습니다. 즉, x[,2]는 벡터이고, >= 는 두 벡터를 비교하며, 3은 3으로 만들어진 벡터로 재사용됩니다. 또한 J는 x에 의해 정의 됐지만 x에서 값을 추출할 때 사용됨을 알 수 있습니다. 하지만 굳이 이런 방식으로 할 필요는 없다는 것을 기억해 두시기 바랍니다.

필터링 기준은 필터링이 적용될 변수와 관계없는 변수를 사용할 수 있습니다. 다음 예제는 이전 예제와 동일한 x를 사용합니다. Z %% 2== 1은 각 원소가 홀수인지를 판단해 (TRUE, FALSE, TRUE)라는 값을 내놓습니다. 이 결과로 x의 1번째와 3번째 행의 값을 추출합니다.

행을 추출할 때의 조건을 좀더 복잡하게 적용한 예시를 봅시다. 좀더 일반적으로 얘기하면 부분행렬 추출 역시 동일한 방식을.m[,1]>1은 n의 첫째 열의 모든 원소를 1과 비교해 (FALSE, TRUE, TRUE)를 반환합니다. 이후 m[,2]>2도 유사한 방식으로 (FALSE ,FALSE, TRUE)를 반환합니다. 그리고 여기서 (FALSE, TRUE, TRUE)와 (FALSE ,FALSE, TRUE) 간에 논리부호 AND를 사용하여 (FALSE ,FALSE, TRUE)라는 결과값을 가져옵니다. 이를 m의 열 인덱스로 활용해 m의 세 번째 행을 가져온 것입니다.
이때 if문 내에서 사용하는 스칼라값 비교에 사용하는 &&가 아닌 벡터의 불리언 AND 연산자인 &를 사용했다는 것을 기억하시기 바랍니다.

여기서 잠깐, 이 예제에서 이상한 점 혹시 알아 차리셨나요? 필터링한 결과는 1-2 크기의 부분행렬이
아닌 2개의 원소를 가진 벡터가 됐습니다.
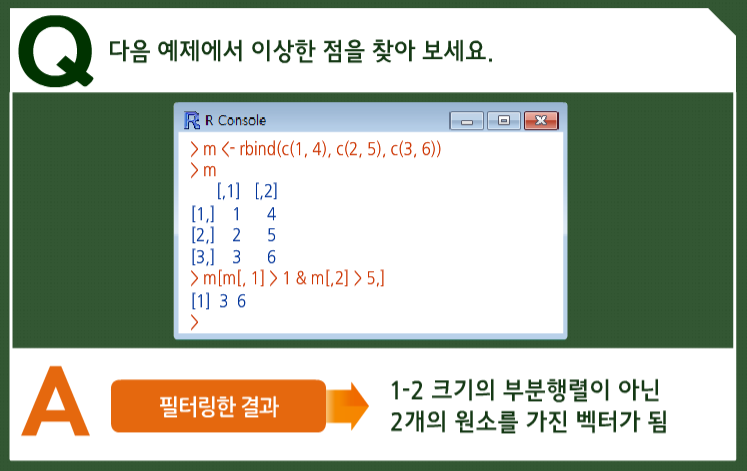
원소는 정확하게 나왔으나, 데이터 형태는 다릅니다. 이런 경우 이 값을 행렬용 함수에 적용하면 문제가 생깁니다. 이를 해결하기 위해 데이터의 2차원 성격을 그대로 유지한다고 R에게 미리 알려주는
drop이라는 인수를 사용하면 됩니다. 행렬은 벡터이므로 벡터 연산자를 그대로 적용할 수 있습니다. 다음 예제를 볼까요? 벡터 인덱싱 관점에서 봤을 때, m의 1, 3, 5, 6번째 원소는 2보다 큽니다. 예를 들어 5번째 원소의 경우 m의 2번 행째 행 2번째 열에 위치한 원소로 10의 값을 가지므로 2보다 큽니다.

3. 공분산 행렬 생성하기
공분산 행렬 생성하기에 대해 알아보겠습니다. 이 예제에서는 인수를 행렬로 갖는 row()와 col()를 사용합니다. 예를 들어 a라는 행렬에서 row(a[2,8])은 a의 원소의 행 번호인 2를 반환할 것입니다. 물론 row() 는 행, col()은 열을 반환하기 때문에 row(a[2,8])은 2번째 행에 있다는 것을 이미 파악하고 있습니다. 그럼 이 함수가 어디에 유용한 걸까요?
다변량 정규 분포 시뮬레이션 코드를 작성할 때 예를 들어 MASS 라이브러리에서 mvrnorm()을 사용한다고 하면 공분산 행렬 정의가 필요합니다.
예를 들자면 1열의 2행의 원소는 2열의 1행의 원소와 같습니다. n변량 정규 분포를 사용한다고 가정해 보겠습니다. 이때 행렬은 n개의 열과 n개의 행을 가질 것입니다. 각 n개의 변수들이 변수 쌍에서의 상관계수 rho 및 분산 1을 갖게 하려고 합니다. N = 3이고 rho =0.2라면 행렬은 예제와 같이 될 것입니다.

공분산 행렬을 생성하는 코드예제를 봅시다. 이 코드가 어떻게 동작하는지 살펴보면 첫 번째로, row()가 행 번호를 반환하는 것처럼 col()은 해당 인수의 열 번호를 반환합니다. 그리고 3번째 줄의 row(m)은 정수값을 가진 행렬을 반환합니다. 행렬의 각 원소는 m의 원소 각각의 열 번호를 가리킵니다.

예를 들자면 다음과 같습니다. row(m) == col (m)이란 식은 TRUE와 FALSE 값을 갖는 행렬을 반환합니다. 행렬의 대각선상에 있는 원소에서는 TRUE 값이 나올 것이고 다른 곳의 원소에서는 FALSE 값이 나올 것입니다. 이항 연산자, 이 경우에는 등가(==)도 함수의 일종이라는 것을 다시 한번 기억해두시기 바랍니다. 물론 (row())와 (col())가 호출된다는 것도 기억 하시기 바랍니다. 이 경우 앞서 언급한 대로 TRUE/FALSE 행렬이 인수로 들어가므로, 출력되는 행렬에는 각 위치에 1이나 rho의 값이 들어갈 것입니다.

'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
|---|---|
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 이해 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 시작과 종료 및 도움말 시작하기 (0) | 2016.05.07 |
R 3.2.1 프로그래밍 - 행렬과 배열 만들기
이번 시간에 학습할 행렬과 배열에 대한 배경지식을 먼저 살펴보겠습니다 행렬이란 무엇일까요? 행렬은 행과 열에 수를배열하여 직4각형을 이루게 한 수의 집합을 말합니다. 각 수들을 행렬의 원소 또는 성분이라고 말하며, 행렬은 수학의여러 분야에서는 물론 공학·물리학·경제학·통계학 등에서 널리 응용되고 있습니다.
역사적으로 처음에는 행렬이 아니라 행렬식 이라는 정방행렬과 연관된 수 값이 인식되었다가 점차 대수적인 것으로 행렬의개념이 나타나게 되었고, 19세기 영국의 수학자 A.케일리는 행렬이라는 용어를 도입하고 행렬의 대수적 개념을 발달시켰습니다.
행렬 연산의 기초
1. 행렬 만들기
행렬 연산의 기초
행렬 연산의 기초, 행렬 만들기를 본격적으로 학습하기 전에 행렬의 구조에 대해서 알아봅시다. 행렬의 행과 열은 1부터 시작합니다. 예를 들어 행렬 a의 왼쪽 위 끝은 a[1,1]로 표기합니다. 행렬의 내부 저장 공간은 열 우선 배열(Column-Major Order) 방식입니다. 이는 1번 열 전체가 저장되고 2번 열 전체가 저장되는 방식입니다.
행렬을 만드는 한 가지 방법은 matrix() 함수를 이용하는 것입니다. 첫 번째 열로 가정한 1, 2와 두 번째 열로 가정한 3, 4를 matrix함수에 붙여서 사용합니다. 그러므로 여기서 데이터는 (1,2,3,4)입니다. 그리고 행과 열의 수를 지정해 줍니다. R에서는 열 우선 배열 방식을 사용한다는 점을 감안하여
행렬에 네 숫자를 배치하도록 합니다. 앞에서 행렬의 공간을 지정했고, 네 숫자를 배치했고, 또한 사용된 ncol이나 nrow 값 모두 적합했으므로 이제 두 변수를 모두 지정해 줄 필요가 없습니다. 총 4개의 원소에 대해 2개의 행을 가진다면, 이는 2개의 열을 가진다는 의미를 내포하고 있습니다.
행렬 Y를 출력하면 R에서는 자동으로 행렬 표시를 해줍니다. 예를 들어 [ ,2]는 2번 열 전체를 말합니다. 행렬 Y 를 생성하는 다른 방법은 각각의 원소를 지정해주는 것입니다. 이때 R에 y는 행렬이고 행과 열이 몇 개인지 미리 알려줘야 한다는 것을 기억해 둡시다. 행렬의 내부 저장소는 열 우선 배열 형식이지만, matrix()에서 byrow 인수를 참으로 설정하면 데이터가 행 우선 배열 방식으로 입력됩니다.
byrow를 사용한 예제를 살펴보겠습니다. 행렬은 여전히 열 우선 배열 형식으로 저장된다는 것을 기억합시다. byrow 인수는 ‘입력’ 때에만 행 우선 형태가 가능하도록 합니다. 이 방식은 데이터 파일을 열부터 기록해 사용하고자 하는 경우 편리합니다.
2. 일반 행렬 연산(선형 대수 연산 처리, 행렬 Indexing)
행렬에서 사용하는 일반적인 연산 몇 가지를 살펴보겠습니다. 여기엔 선형대수, 행렬 인덱싱, 행렬 필터링 등이 포함됩니다. 선형대수연산은 행렬 간 곱, 행렬-상수 간 곱, 행렬 간 합 등을 처리할 수 있습니다. 다음 y를 사용한 세가지 연산이 각각 살펴봅시다.
행렬 인덱싱에 대해 알아보겠습니다. 지금부터 벡터에 대해 사용한 연산들을 동일하게 행렬에 적용해 볼 것입니다. z의 2, 3번 열에 행 전체를 가져온 부분 행렬을 호출했습니다. 그러자 2, 3번째 열 전체가 추출되었습니다.
다음은 열 대신 행에서 추출한 예제입니다. y의 2, 3번째 행에 열 전체를 호출해 보았습니다. 또한 2,3번째 행의 2번째 열만 호출 할수도 있습니다. 부분행렬에 다음과 같이 값을 할당할 수도 있습니다. 이 예제에서 y의 첫 번째와 세 번째 행에 새로운 값을 할당했습니다.
부분행렬에 값을 할당하는 또 다른 예도 있습니다. 벡터에서 특정 원소를 제외하는 용도로 사용됐던 음수의 경우는 행렬에서도 동일한 방식으로 사용됩니다. 다음과 같은 명령어를 통해 y에서 두 번째 행을 제외한 모든 행을 호출했습니다. 결과는 다음과 같이 두 번째 행을 제외한 모든 행이 호출 되었습니다.
행렬 연산의 활용
1. 이미지 다루기
행렬 연산의 활용
행렬 연산의 활용 중 이미지 다루기에 대해 살펴보겠습니다. 이미지 파일의 배부는 픽셀들이 행과 열로 나열된 행렬로 돼 있습니다. 흑백 이미지의 경우 각 픽셀당 이미지의 강도 즉 밝기를 저장하고 있습니다. 그러므로 28개의 행과 88개의 열이픽셀을 가진 이미지의 강도는 28개의 행과 88개의 열을 가진 행렬에 저장하고 있다는 뜻이 됩니다. 컬러 이미지의 경우에는빨강, 녹색, 파랑에 대한 강도를 저장한 세 개의 행렬이 저장되지만, 일단은 흑백 이미지에 대해서 설명해 드리도록 하겠습니다.
미국 러시모어산 국립기념관(Mount Rushmore National Memorial) 사진을 사용해서 예시 문제를 실습해
보겠습니다. 우선, pixmap 라이브러리를 사용해 이미지 파일을 읽어 들여보겠습니다. 파일명이 mtrush.pgm인 파일을 읽어와 pixmap 객체로 만들고 그것을 다음의 그림처럼 플로팅 했을때, 이 클래스가 어떻게 구성됐는지 볼까요?
이 클래스는 각 요소가 $가 아닌 @로 지정된 S4 유형입니다. 여기서 중요한 부분은 강도에 대한 행렬인 mtrush1@grey입니다. 예제에서 이 행렬은 192 행과 256 열을 가집니다. 이 클래스에서 강도는 회색의 정도가 표현된 0.0(검정)부터 1.0(흰색)까지의 범위 내의 숫자들로 저장돼 있습니다. 예를 들어 28 행의 88 번째 열의 픽셀은 꽤 밝은 편입니다.
그렇다면, 루즈벨트 대통령의 이미지를 없애기 위해서는 어떻게 해야 할까요?
관련된 열과 행을 찾기 위해 R의 locator() 함수를 사용할 수 있습니다. 이 함수를 호출한 상태에서 그래프 위의 한 점을 클릭하면, 그 점의 정확한 위치를 알려줍니다. 이 예제에서는 루즈벨트 모습이 그림의 84-163 행과 135-177 열에 위치함을 나타냈습니다. Pixmap 객체에서 행 숫자는 위에서 아래로 갈수록 증가하고, locator()의 경우는 반대입니다.
이미지에서 이 부분을 없애 버리기 위해 이 부분의 모든 픽셀 값을 1.0으로 바꿉니다.이 결과, 다음의 그림과 같이 루즈벨트 대통령의 모습이 사라졌습니다.
루즈벨트 대통령의 이미지를 왜곡 시키고 싶다면 어떻게 해야 할까요?
루즈벨트 대통령의 형태를 왜곡시키고 싶다면 그림에 무작위로 노이즈를 넣어서 사용할 수 있습니다.
다음 코드처럼 하면 됩니다. 주석에 나온 대로 무작위로 노이즈를 생성한 후에 원 픽셀과 노이즈에 가중치를 줘 평균을 냈습니다. 매개변수 q로 노이즈의 가중치를 조절합니다. 이때 q가 커질수록 그림은 더 흐릿해집니다.
무작위 노이즈는 (0, 1)에서 샘플링해서 가져옵니다. 이 예제는 행렬 연산이라는 것을 기억하시기 바랍니다.
여기서 잠깐, 다음 빈칸에 제시된 q값을 드래그해서 넣어보고 그에 따른 이미지의 변화를 살펴봅시다.
그럼 이제 실제로 적용해 볼까요? 다음의 그림처럼 루즈벨트 대통령의 이미지의 형태가 왜곡되었습니다.
2. 행렬 필터링
행렬 필터링에 대해서 알아보도록 하겠습니다. 벡터에서처럼 행렬에서도 필터링할 수 있습니다. 다만 문법에 유의해야 합니다.
간단한 예제를 보면서 시작해 보겠습니다. 일단 x의 두 번째 열인 x[,2]인 원소가 3보다 크거나 같은지를 판단합니다. 그리고 그 결과로 나온 불리언 벡터를 j에 할당합니다. 다음과 같이 x에 j를 사용합니다. 여기서 x[j,]를 계산해 2번 열의 원소 중 최소 3 이상이었던 행들을 가져옵니다. X[j,]는 j의 원소 중 참인 값의 x의 행입니다.
성능 기준으로 봤을 때 j를 계산하는 것은 다음 조건을 모두 만족하므로 완벽하게 벡터화된 연산이라는 것을 다시 한번 상기할 필요가 있습니다. 즉, x[,2]는 벡터이고, >= 는 두 벡터를 비교하며, 3은 3으로 만들어진 벡터로 재사용됩니다. 또한 J는 x에 의해 정의 됐지만 x에서 값을 추출할 때 사용됨을 알 수 있습니다. 하지만 굳이 이런 방식으로 할 필요는 없다는 것을 기억해 두시기 바랍니다.
필터링 기준은 필터링이 적용될 변수와 관계없는 변수를 사용할 수 있습니다. 다음 예제는 이전 예제와 동일한 x를 사용합니다. Z %% 2== 1은 각 원소가 홀수인지를 판단해 (TRUE, FALSE, TRUE)라는 값을 내놓습니다. 이 결과로 x의 1번째와 3번째 행의 값을 추출합니다.
행을 추출할 때의 조건을 좀더 복잡하게 적용한 예시를 봅시다. 좀더 일반적으로 얘기하면 부분행렬 추출 역시 동일한 방식을.m[,1]>1은 n의 첫째 열의 모든 원소를 1과 비교해 (FALSE, TRUE, TRUE)를 반환합니다. 이후 m[,2]>2도 유사한 방식으로 (FALSE ,FALSE, TRUE)를 반환합니다. 그리고 여기서 (FALSE, TRUE, TRUE)와 (FALSE ,FALSE, TRUE) 간에 논리부호 AND를 사용하여 (FALSE ,FALSE, TRUE)라는 결과값을 가져옵니다. 이를 m의 열 인덱스로 활용해 m의 세 번째 행을 가져온 것입니다.
이때 if문 내에서 사용하는 스칼라값 비교에 사용하는 &&가 아닌 벡터의 불리언 AND 연산자인 &를 사용했다는 것을 기억하시기 바랍니다.
여기서 잠깐, 이 예제에서 이상한 점 혹시 알아 차리셨나요? 필터링한 결과는 1-2 크기의 부분행렬이
아닌 2개의 원소를 가진 벡터가 됐습니다.
원소는 정확하게 나왔으나, 데이터 형태는 다릅니다. 이런 경우 이 값을 행렬용 함수에 적용하면 문제가 생깁니다. 이를 해결하기 위해 데이터의 2차원 성격을 그대로 유지한다고 R에게 미리 알려주는
drop이라는 인수를 사용하면 됩니다. 행렬은 벡터이므로 벡터 연산자를 그대로 적용할 수 있습니다. 다음 예제를 볼까요? 벡터 인덱싱 관점에서 봤을 때, m의 1, 3, 5, 6번째 원소는 2보다 큽니다. 예를 들어 5번째 원소의 경우 m의 2번 행째 행 2번째 열에 위치한 원소로 10의 값을 가지므로 2보다 큽니다.
3. 공분산 행렬 생성하기
공분산 행렬 생성하기에 대해 알아보겠습니다. 이 예제에서는 인수를 행렬로 갖는 row()와 col()를 사용합니다. 예를 들어 a라는 행렬에서 row(a[2,8])은 a의 원소의 행 번호인 2를 반환할 것입니다. 물론 row() 는 행, col()은 열을 반환하기 때문에 row(a[2,8])은 2번째 행에 있다는 것을 이미 파악하고 있습니다. 그럼 이 함수가 어디에 유용한 걸까요?
다변량 정규 분포 시뮬레이션 코드를 작성할 때 예를 들어 MASS 라이브러리에서 mvrnorm()을 사용한다고 하면 공분산 행렬 정의가 필요합니다.
예를 들자면 1열의 2행의 원소는 2열의 1행의 원소와 같습니다. n변량 정규 분포를 사용한다고 가정해 보겠습니다. 이때 행렬은 n개의 열과 n개의 행을 가질 것입니다. 각 n개의 변수들이 변수 쌍에서의 상관계수 rho 및 분산 1을 갖게 하려고 합니다. N = 3이고 rho =0.2라면 행렬은 예제와 같이 될 것입니다.
공분산 행렬을 생성하는 코드예제를 봅시다. 이 코드가 어떻게 동작하는지 살펴보면 첫 번째로, row()가 행 번호를 반환하는 것처럼 col()은 해당 인수의 열 번호를 반환합니다. 그리고 3번째 줄의 row(m)은 정수값을 가진 행렬을 반환합니다. 행렬의 각 원소는 m의 원소 각각의 열 번호를 가리킵니다.
예를 들자면 다음과 같습니다. row(m) == col (m)이란 식은 TRUE와 FALSE 값을 갖는 행렬을 반환합니다. 행렬의 대각선상에 있는 원소에서는 TRUE 값이 나올 것이고 다른 곳의 원소에서는 FALSE 값이 나올 것입니다. 이항 연산자, 이 경우에는 등가(==)도 함수의 일종이라는 것을 다시 한번 기억해두시기 바랍니다. 물론 (row())와 (col())가 호출된다는 것도 기억 하시기 바랍니다. 이 경우 앞서 언급한 대로 TRUE/FALSE 행렬이 인수로 들어가므로, 출력되는 행렬에는 각 위치에 1이나 rho의 값이 들어갈 것입니다.
'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
|---|---|
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 이해 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 시작과 종료 및 도움말 시작하기 (0) | 2016.05.07 |