Stemming
Stemming
정의
색인 파일의 크기를 줄이기 위해 정보 검색 시에 사용
단어(어절) 대신 어간(stem)을 저장 -> 50% 이상의 압축 비율
* 어절 : 어절(語節)은 한국어에서 문장을 구성하고 있는 도막 도막의 성분으로서 발음의 기본이 되는 단위이다.
어절은 띄어쓰기 단위와 동일하다
* 어간 : 어간(語幹)은 문법에서 어형 변화의 기초가 되는 부분을 말한다.
색인 시간과 탐색 시간에서의 stemming 기능
색인 시간
- 색인어가 어간화 되어 효율성과 색인 파일 압축성이 증진
- search time에 이런 연산을 위한 자원 요청이 불필요
탐색 시간
시스템과 탐색 기술에 대한 지식을 요구하지 않고도 용어 합성
stemmer에 의해 찾아진 용어들의 집합에서 용어 선택 -> 오결합 가능성 감소
자동 합성 방법
몇 가지 수식을 사용한 수동이나 stemmer라 불리는 프로그램을 통해 자동 처리
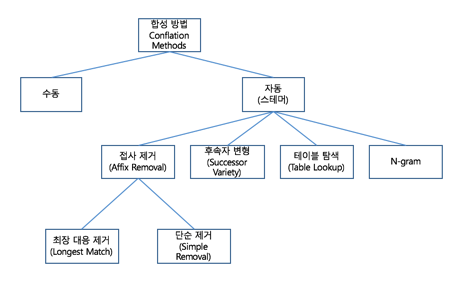
접사 제거(Affix Removal)
하나의 어간을 남기기 위해 용어들의 접두어와 접미어 제거
후속자 변형(Succesor Variety)
본문 내의 글자 연속으로 나타나는 빈도를 사용
테이블 탐색(Table Lookup)
용어와 어간을 테이블에 저장하여 테이블을 탐색
n-gram
용어가 공유할 수 있는 도표나 n-gram 수에 기초한 용어들의 합성
테이블 탐색
모든 색인어와 그 어간을 하나의 테이블에 저장하는 방법
색인용어 engineering, engineered, engineer
어간 engineer
질의로부터 용어들과 색인어들을 table lookup을 통해 어간화가능(B-tree, hash table)
문제점
용어와 어간의 관계에 대한 자료 부족, 저장 오버헤드
후속자 변형
한 문자열의 후속자 변형(successor variety)
본문 내의 단어들 중 글자를 후속하는 상이한 글자 수량
후속자 변형 stemming 처리 3단계
1. 단어에 대한 후속자 변형을 결정한다.
2. 단어를 분할하기 위해 이 정보를 사용한다.
3. 어간으로서 분할 중 1개를 선택한다.
ex) READABLE : READ + ABLE
ex) ABLE, APPLE, READ, READABLE, READING, READS, RED, RISK, ROAD
접두사 | 후속자 변형 | 문자 |
R | 3 | E, I, O |
RE | 2 | A, D |
REA | 1 | D |
READ | 3 | A, I, S |
READA | 1 | B |
READAB | 1 | L |
READABL | 1 | E |
READABLE | 1 | BLANK 없음 |
n-gram stemmers
shared bigram method
용어 합성 방법으로 어간이 생성되지 않음
bigram : 한 쌍의 연속된 글자
shared unique bigram 에 기초하여 한 쌍의 용어들 사이에 관련성 척도 계산
ex) statistics와 statistical
statistics -> st ta at ti st ti ic cs (9개의 bigram)
unique bigrams => at cs ic st ta ti (7개)
statistical -> st ta at ti st ti ic ca al (10개의 bigram)
unique bigrams => al at ca ic st ta ti (8개)
6개의 unique bigram 공유 : at, ic, is, st, ta, ti
Similarity measure
단어 한 쌍에 대한 unique bigram을 기초로 유사도 계산
Dice’s coefficient(n-gram)
= 2 * coefficient / (number of unique n-grams A + number of unique n-grams B)
= 2 * 공통 겹치는 개수 / 유니크한 n 그램 개수의 총합
= 2 * C / (A+B)
A, B : 각각 첫 번째, 두 번째 단어의 unique bigram 개수
C :공유한 unique bigram 개수
위의 예에서는
(2 * 6) / (7 + 8) = 0.8
유사도 : 데이터베이스 내에 있는 용어의 모든 쌍에 대해 결정하며 유사성 행렬르 형성
Affix Removal Stemmers
어간을 남겨두기 위해 용어로부터 접미/접두어를 제거
* 접미사(接尾辭)는 어떤 단어(어근)의 뒤에 붙어 뜻을 첨가하여 하나의 다른 단어를 이루는 말
* 접두사는 파생어를 만드는 형태소의 하나. 어떤 단어의 앞에 붙어 새로운 단어가 되게 하는 말
Most Stemmers are “iterative longest match stammers”
규칙에 따라 한 단어로부터 가능한 가장 긴 스트링 제거
더 이상의 문자들이 제거되지 않을 때 까지 계속 반복
Porter’s Algorithm
규칙으로 처리한다.
1. Stem conditions
V : Vowel, 모음 / C : Consonant, 자음
* 모음 : a,e,i,o,u
* 자음 : 알파벳 26가지 중 위의 다섯가지를 제외한 글자
연속한 VC의 개수를 측정하는 것을 m이라고 한다.
[C](VC)^m[V]
Measure | Examples |
m=0 | AB, CD, EE, ABEE, X, YZ |
m=1 | IVY, SEX, KOR |
m=2 | PRIVATE, OATEN |
2. Suffix conditions
3. Rule conditions
접사 제거를 시작한다.
1. step1a(word); 명사의 복수형 제거
2. step1b(stem); 과거, 과거분사, 현재진행형 제거
3. If (the second or third rul of step 1b was used) step1b1(stem); 복원
4. step1c(stem);
5. step2(stem); m 1 이상
6. step3(stem);
7. step4(stem);
8. step5a(stem);
9. step5b(stem);
'정보검색-데이터마이닝' 카테고리의 다른 글
| 정보 검색 개요 (0) | 2016.10.16 |
|---|---|
| 한글 인코딩과 변환 코딩 (0) | 2016.10.15 |
| 유니코드 Unicode (0) | 2016.10.15 |
| 한글 코드 (1) | 2016.10.15 |
Stemming
Stemming
정의
색인 파일의 크기를 줄이기 위해 정보 검색 시에 사용
단어(어절) 대신 어간(stem)을 저장 -> 50% 이상의 압축 비율
* 어절 : 어절(語節)은 한국어에서 문장을 구성하고 있는 도막 도막의 성분으로서 발음의 기본이 되는 단위이다.
어절은 띄어쓰기 단위와 동일하다
* 어간 : 어간(語幹)은 문법에서 어형 변화의 기초가 되는 부분을 말한다.
색인 시간과 탐색 시간에서의 stemming 기능
색인 시간
- 색인어가 어간화 되어 효율성과 색인 파일 압축성이 증진
- search time에 이런 연산을 위한 자원 요청이 불필요
탐색 시간
시스템과 탐색 기술에 대한 지식을 요구하지 않고도 용어 합성
stemmer에 의해 찾아진 용어들의 집합에서 용어 선택 -> 오결합 가능성 감소
자동 합성 방법
몇 가지 수식을 사용한 수동이나 stemmer라 불리는 프로그램을 통해 자동 처리
접사 제거(Affix Removal)
하나의 어간을 남기기 위해 용어들의 접두어와 접미어 제거
후속자 변형(Succesor Variety)
본문 내의 글자 연속으로 나타나는 빈도를 사용
테이블 탐색(Table Lookup)
용어와 어간을 테이블에 저장하여 테이블을 탐색
n-gram
용어가 공유할 수 있는 도표나 n-gram 수에 기초한 용어들의 합성
테이블 탐색
모든 색인어와 그 어간을 하나의 테이블에 저장하는 방법
색인용어 engineering, engineered, engineer
어간 engineer
질의로부터 용어들과 색인어들을 table lookup을 통해 어간화가능(B-tree, hash table)
문제점
용어와 어간의 관계에 대한 자료 부족, 저장 오버헤드
후속자 변형
한 문자열의 후속자 변형(successor variety)
본문 내의 단어들 중 글자를 후속하는 상이한 글자 수량
후속자 변형 stemming 처리 3단계
1. 단어에 대한 후속자 변형을 결정한다.
2. 단어를 분할하기 위해 이 정보를 사용한다.
3. 어간으로서 분할 중 1개를 선택한다.
ex) READABLE : READ + ABLE
ex) ABLE, APPLE, READ, READABLE, READING, READS, RED, RISK, ROAD
접두사 | 후속자 변형 | 문자 |
R | 3 | E, I, O |
RE | 2 | A, D |
REA | 1 | D |
READ | 3 | A, I, S |
READA | 1 | B |
READAB | 1 | L |
READABL | 1 | E |
READABLE | 1 | BLANK 없음 |
n-gram stemmers
shared bigram method
용어 합성 방법으로 어간이 생성되지 않음
bigram : 한 쌍의 연속된 글자
shared unique bigram 에 기초하여 한 쌍의 용어들 사이에 관련성 척도 계산
ex) statistics와 statistical
statistics -> st ta at ti st ti ic cs (9개의 bigram)
unique bigrams => at cs ic st ta ti (7개)
statistical -> st ta at ti st ti ic ca al (10개의 bigram)
unique bigrams => al at ca ic st ta ti (8개)
6개의 unique bigram 공유 : at, ic, is, st, ta, ti
Similarity measure
단어 한 쌍에 대한 unique bigram을 기초로 유사도 계산
Dice’s coefficient(n-gram)
= 2 * coefficient / (number of unique n-grams A + number of unique n-grams B)
= 2 * 공통 겹치는 개수 / 유니크한 n 그램 개수의 총합
= 2 * C / (A+B)
A, B : 각각 첫 번째, 두 번째 단어의 unique bigram 개수
C :공유한 unique bigram 개수
위의 예에서는
(2 * 6) / (7 + 8) = 0.8
유사도 : 데이터베이스 내에 있는 용어의 모든 쌍에 대해 결정하며 유사성 행렬르 형성
Affix Removal Stemmers
어간을 남겨두기 위해 용어로부터 접미/접두어를 제거
* 접미사(接尾辭)는 어떤 단어(어근)의 뒤에 붙어 뜻을 첨가하여 하나의 다른 단어를 이루는 말
* 접두사는 파생어를 만드는 형태소의 하나. 어떤 단어의 앞에 붙어 새로운 단어가 되게 하는 말
Most Stemmers are “iterative longest match stammers”
규칙에 따라 한 단어로부터 가능한 가장 긴 스트링 제거
더 이상의 문자들이 제거되지 않을 때 까지 계속 반복
Porter’s Algorithm
규칙으로 처리한다.
1. Stem conditions
V : Vowel, 모음 / C : Consonant, 자음
* 모음 : a,e,i,o,u
* 자음 : 알파벳 26가지 중 위의 다섯가지를 제외한 글자
연속한 VC의 개수를 측정하는 것을 m이라고 한다.
[C](VC)^m[V]
Measure | Examples |
m=0 | AB, CD, EE, ABEE, X, YZ |
m=1 | IVY, SEX, KOR |
m=2 | PRIVATE, OATEN |
2. Suffix conditions
3. Rule conditions
접사 제거를 시작한다.
1. step1a(word); 명사의 복수형 제거
2. step1b(stem); 과거, 과거분사, 현재진행형 제거
3. If (the second or third rul of step 1b was used) step1b1(stem); 복원
4. step1c(stem);
5. step2(stem); m 1 이상
6. step3(stem);
7. step4(stem);
8. step5a(stem);
9. step5b(stem);
'정보검색-데이터마이닝' 카테고리의 다른 글
| 정보 검색 개요 (0) | 2016.10.16 |
|---|---|
| 한글 인코딩과 변환 코딩 (0) | 2016.10.15 |
| 유니코드 Unicode (0) | 2016.10.15 |
| 한글 코드 (1) | 2016.10.15 |