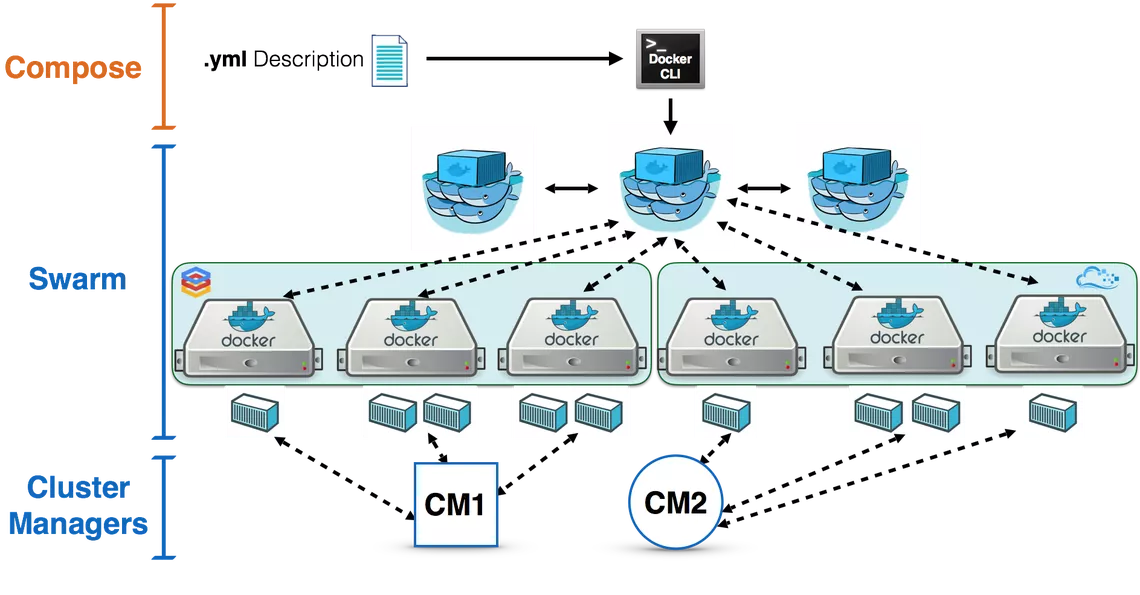
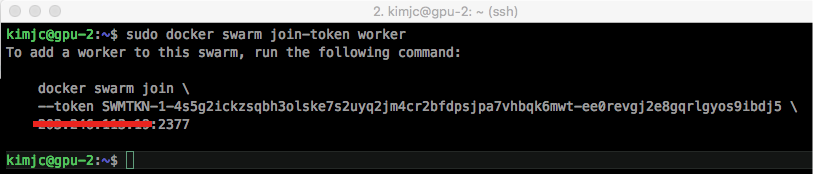
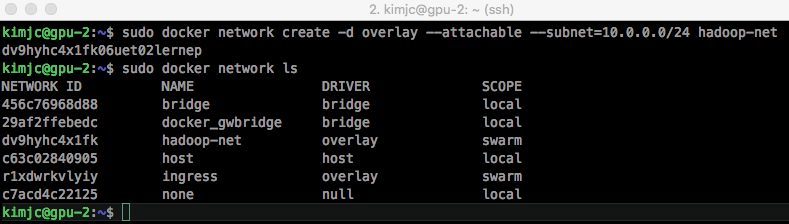
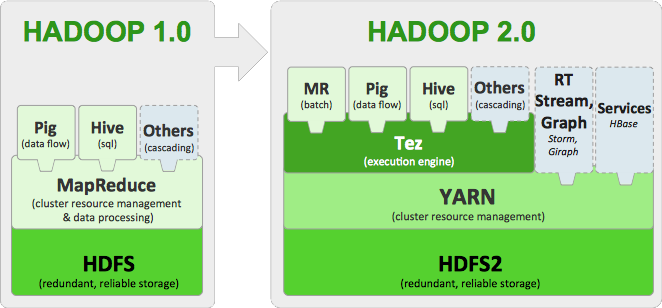
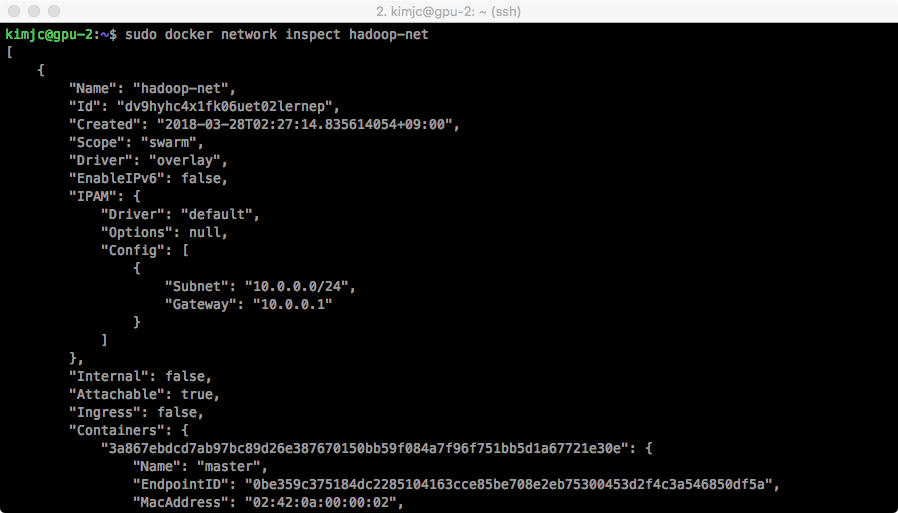
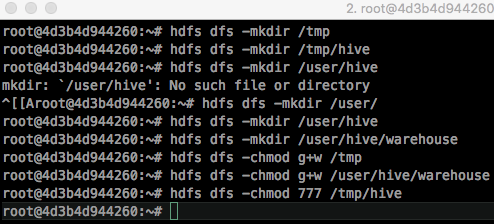
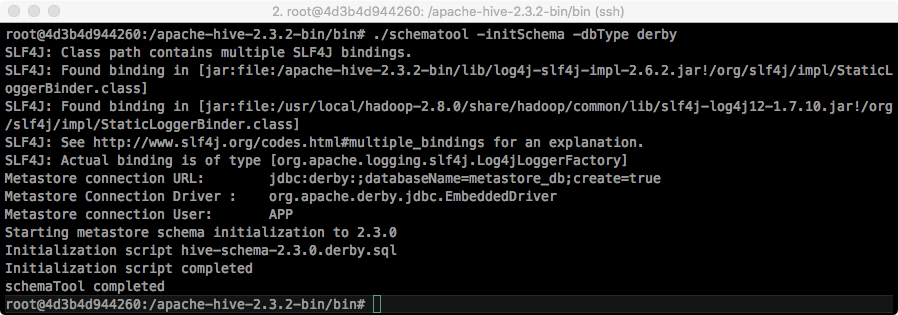
Docker Hadoop 클러스터 Hive 설치 Docker 설치가 완료된 가정 하에서 진행됩니다. Docker swarm을 생성하기 위해서는 서버 중 마스터(master) 노드로 지정해야 합니다. https://docs.docker.com/engine/swarm/manage-nodes/ 하나의 서버에서 SWARM 마스터를 생성하는 docker swarm init 명령어를 실행합니다. 다음에서 나온 docker swarm join -- token [TOKEN값] [HOST-UP]:2377 을 복사하여 다른 서버에 붙여 넣습니다. swarm에서의 Node 상태를 확인하기 위해서는 docker swarm node 명령어를 사용합니다. AVAILABILITY 에서는 스케줄러(scheduler)가 Node에게 task를 부여할 수 있는지 확인할 수 있습니다. - Active : scheduler가 task 할당이 가능한 상태입니다. - Pause : 이미 존재하는 task는 실행 중이지만, scheduler가 새로운 task에 대해서는 할당할 수 없습니다. - Drain : 이미 존재하는 task도 shutdown되며, 사용가능한 node로 스케줄링하게 됩니다. scheduler가 새로운 task에 대해서는 할당할 수 없습니다. MANAGER STATUS 에서는 Leader가 manager node임을 알려주면 모든 swarm 관리와 결정을 합니다. 개개인의 node에 대해서도 상태를 살펴보는 명령어는 다음과 같습니다. swarm의 토큰 값을 다시 확인하기 위해서는 다음의 명령어를 사용합니다. swarm에서 Worker 노드에서 탈퇴하는 것은 docker swarm leave 명령어를 사용하면 됩니다. https://docs.docker.com/network/overlay/ Overlay network는 여러 서버의 Docker daemon hosts 간의 분산 네트워크입니다. Overlay 네트워크를 통해 각기 다른 서버의 IP 주소와 상관없이 같은 subnet mask의 내부 주소를 부여받게 되고, 이를 통해 쉽게 Hadoop 클러스터를 구성할 수 있습니다. 현재 docker의 네트워크 상태를 살펴보기 위해서는 docker network ls 명령어를 사용합니다. docker swarm 네트워크 망을 새로 생성합니다. 생성된 swarm 네트워크를 살펴보기 위해서는 docker network inspect 명령어를 사용합니다. subnet이 설정된 것을 확인할 수 있습니다. 자 이제 container를 실행하여 overlay network에 붙여봅시다. overlay network를 지우기 위해서는 docker network rm 명령어를 사용합니다. 저는 대학교에서 실습 진행을 위해 서버 5대에서 학생 40~50명에게 hadoop container 제공을 위해 Dockerfile을 작성하여 container를 실행하였고 2년 동안 진행하였습니다. Dockerfile Registry 저장소인 DockerHub에서 확인할 수 있습니다. https://hub.docker.com/u/kmubigdata/dashboard/ hadoop은 2.8.0 버전을 사용하고 있습니다. 코드는 github에서 확인할 수 있습니다. https://github.com/kmu-bigdata/ubuntu-hadoop/ Name Node와 Data Node 4개 에 해당하는 container를 5개 생성해봅시다. [server1]name_node = 10.0.0.2 [server1]data-node1 = 10.0.0.3 [server1]data-node2 = 10.0.0.4 [server2]data-node3 = 10.0.0.5 [server3]data-node4 = 10.0.0.6 먼저 Hadoop Namenode를 생성하기 위해 Hadoop이나 YARN에서 사용하는 port를 열어 주기 위해 -p 옵션으로 host와 맵핑해야 합니다. 또한 --add-host로 슬레이브의 ip를 미리 알려주어야 합니다. 명령어를 실행하면, container가 생성됩니다. 현재 실행 중인 container를 살펴봅시다. name-node container bash로 접속합니다. 우선 docker run 에서 add-host 옵션에서 들어간 것은 /etc/hosts 에서 살펴볼 수 있습니다. $ cat /etc/hosts 다음은 기존의 slaves 파일들을 수정합니다. slave1 slave2 slave3 slave4 저장합니다. 자 다음은 datanode들을 생성해봅시다. 이쯤에서 docker network inspect 명령어로 Overlay 네트워크를 확인해봅시다. 현재 Overlay 네트워크에 연결된 container를 살펴볼 수 있으며, container 목록에서 name-node, slave1, slave2의 IP를 확인할 수 있습니다. 자 다음으로 server2에서 slave3, 4 container를 생성합시다. 실행 중인 container 목록을 살펴봅시다. 네트워크 상태를 살펴봅시다. server2에서도 Overlay Network에게 연결을 하게되면, Peers 에서 연결된 Server를 확인할 수 있습니다. server1으로 돌아와 다시 name-node container로 접속합니다. 자 이제 start-all 을 이용해 hadoop을 시작해봅시다. jps 목록에서 NameNode, ResourceManager, SecondaryNameNode가 실행되어야 합니다. 이번에 slave들 중 하나의 container로 들어가 jps로 확인해봅시다. Hadoop 클러스터가 생성되었습니다. 좋습니다. 웹 UI를 확인하기 위해 http://[SERVER_IP]:8088로 접속해봅시다. HADOOP_HOME=/usr/local/hadoop $ hdfs dfs -mkdir /tmp $ hdfs dfs -mkdir /tmp/hive $ hdfs dfs -mkdir /user $ hdfs dfs -mkdir /user/hive $ hdfs dfs -mkdir /user/hive/warehouse $ hdfs dfs -chmod g+w /tmp $ hdfs dfs -chmod g+w /user/hive/warehouse $ hdfs dfs -chmod 777 /tmp/hive $ cd /apache-hive-2.3.2-bin/bin/ $ ./schematool -initSchema -dbType $ ./hiveMulti Server -> Docker Swarm 생성
$ docker swarm init --advertise-addr [HOST-IP]
$ sudo docker node ls
$ sudo docker node inspect self --pretty
$ sudo docker swarm join-token worker
$ sudo docker swarm leave
Overlay 네트워크 생성
$ sudo docker network ls
$ sudo docker network create -d overlay --attachable --subnet=[SUBNET_MASK] [NETWORK_NAME]
$ sudo docker network inspect [NETWORK_NAME]
$ sudo docker network rm hadoop-net
Hadoop Dockerfile
Container 생성하기
Hadoop Namenode container 생성
$ sudo docker run -dit --name master --network hadoop-net --ip 10.0.0.2 -p 8088:8088 -p 8042:8042 -p 8085:8080 -p 4040:4040 -p 2122:22 --add-host=master:10.0.0.2 --add-host=slave1:10.0.0.3 --add-host=slave2:10.0.0.4 --add-host=slave3:10.0.0.5 --add-host=slave4:10.0.0.6 kmubigdata/ubuntu-hadoop /bin/bash
$ sudo docker ps
$ sudo docker exec -it master /bin/bash
$ vi $HADOOP_HOME/etc/hadoop/slaves
Hadoop datanode container 생성
$ sudo docker run -dit --name slave1 --network hadoop-net --ip 10.0.0.3 --add-host=master:10.0.0.2 --add-host=slave1:10.0.0.3 kmubigdata/ubuntu-hadoop /bin/bash
$ sudo docker run -dit --name slave2 --network hadoop-net --ip 10.0.0.4 --add-host=master:10.0.0.2 --add-host=slave1:10.0.0.4 kmubigdata/ubuntu-hadoop /bin/bash
$ sudo docker network inspect hadoop-net
$ sudo docker run -dit --name slave3 --network hadoop-net --ip 10.0.0.5 --add-host=master:10.0.0.2 --add-host=slave3:10.0.0.5 kmubigdata/ubuntu-hadoop /bin/bash
$ sudo docker run -dit --name slave4 --network hadoop-net --ip 10.0.0.6 --add-host=master:10.0.0.2 --add-host=slave4:10.0.0.6 kmubigdata/ubuntu-hadoop /bin/bash
$ sudo docker ps
$ sudo docker network inspect hadoop-net
Hadoop 시작
$ sudo docker exec -it master /bin/bash
$ start-all.sh
$ jps
$ sudo docker exec -it slave4 /bin/bash
$ jps
Hive 설치
$ wget http://mirror.navercorp.com/apache/hive/stable-2/apache-hive-2.3.2-bin.tar.gz
$ tar -xzvf apache-hive-2.3.2-bin.tar.gz
$ cd apache-hive-2.3.2-bin/conf
$ cp hive-env.sh.template hive-env.sh
$ cp hive-default.xml.template hive-default.xml’
$ vi hive-env.sh




































'Google Cloud Platform' 카테고리의 다른 글
| Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API (1) | 2018.04.10 |
|---|---|
| Deployments 관리 Kubernetes in Google Cloud Platform (0) | 2018.04.08 |
| Jenkins Kubernetes Google Cloud (2) | 2018.04.01 |
| Orchestrating Google Cloud with Kubernetes (0) | 2018.03.12 |
| Google Cloud with Kubernetes (0) | 2018.03.09 |