
Jeongchul Kim
MLflow 본문
MLflow

Strata Data Conference - New York, NY 2018
SEPT 11-13
safaribook(https://www.safaribooksonline.com/videos/strata-data-conference/9781492025856)
MLflow: An open platform to simplify the machine learning lifecycle - Mani Parkhe (Databricks), Andrew Chen (Databricks)
머신 러닝 개발은 매우 복잡합니다.

ML Lifecycle을 살펴봅시다. databricks에서 정의하는 ML 개발은 다음과 같습니다.
1. Data gathering(raw data)
- Kafka와 같은 실시간 streaming으로 얻어지는 데이터
- Data warehouse, Storage 그리고 Database에 저장되어 있는 데이터
- Tuning, Scale
2. Data Preparation
- Data Preprocessing, Feature Engineering
3. Model Training
- Model training, Model Hyper-parameter tuning, Model Complexity
4. Deploy Model
- 클라우드 서비스, 웹 서비스 제공, Traffic Serving, Real Time 제공
5. Model Exchange
- Storage format, feature name, model parameter 변화
6. Governance
- Team Management

Custom ML Platforms
Google TFX(TensorFlow Extended) : https://www.tensorflow.org/tfx/
Facebook FBLearner : https://code.fb.com/core-data/introducing-fblearner-flow-facebook-s-ai-backbone/
Uber Michelangelo : https://eng.uber.com/michelangelo/
표준화된 Data Preparation과 Model Training과 Deploy를 표준화하고 있어 플랫폼과 함께 개발된다는 장점이 있으나,
프레임워크나 알고리즘이 제한되어 있고, 한 회사의 infrastructure를 사용해야 한다는 단점이 있습니다.
Introducing MLflow
Databricks가 제공하는 MLflow는 오픈 소스로 제공되며, 여러 ML library와 언어를 함께 개발할 수 있고, 어떠한 cloud에서든 같은 방법으로 deploy할 수 있고, 1명 또는 다수의 팀원이 사용하기 쉽게 디자인되어 있습니다.

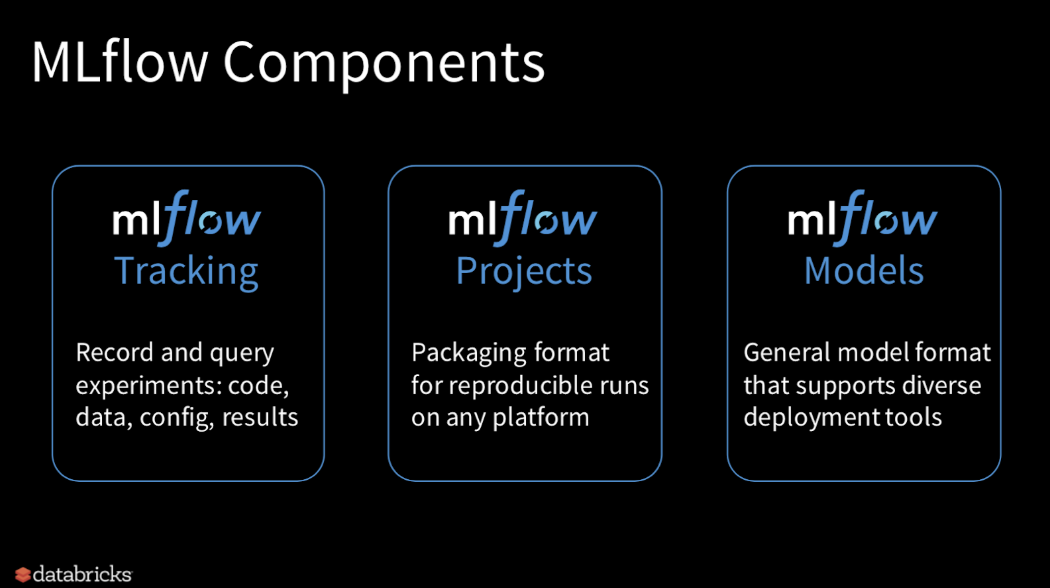
MLflow Components
1. Tracking
- 코드와 모델의 설정(configs) 그리고 결과를 저장하고 쿼리할 수 있습니다.
2. Projects
- 어떠한 platform으로든 다양한 알고리즘으로 쉽게 개발할 수 있습니다.
3. Models
- 모델을 어떠한 platform으로 deploy할 수 있습니다.
Demo
이 발표에서 demo의 발표로는 andrew chen이 맡았으며, Example로 airbnb의 데이터를 예시로 들었습니다.
feature는 numerical 데이터로 이루어져 있습니다. 가격을 예측하는 간단한 regression 모델로 볼 수 있습니다.

모델은 scikit learn 라이브러리를 이용한 python 프로그램입니다.

python 프로그램에 2개의 parameter인 alpha와 L1 ratio를 주고 실행하여 모델의 정확도를 가져옵니다.

이제 모델의 정확도를 높이기 위해 2개의 parameter의 최적값을 찾기 위해 다양한 값을 적용해 볼 것입니다.
MLflow를 사용해봅시다. log로 남길 파라미터와 모델 성능 평가 metric 그리고 모델 값과 figure를 log로 남깁니다.
mlflow.sklearn.log_model의 경우 모델을 serialization, deserialization을 통해 모델을 deploy합니다.

shell script를 이용해 최적의 parameter를 찾는 실험을 진행합니다.

그리고 mlflow ui를 이용해 MLflow의 web ui를 살펴봅니다.
web ui에서는 완료된 모델의 파라미터와 결과를 살펴볼 수 있습니다.

로컬에 저장한 train.parquet과 plot을 확인할 수 있습니다.
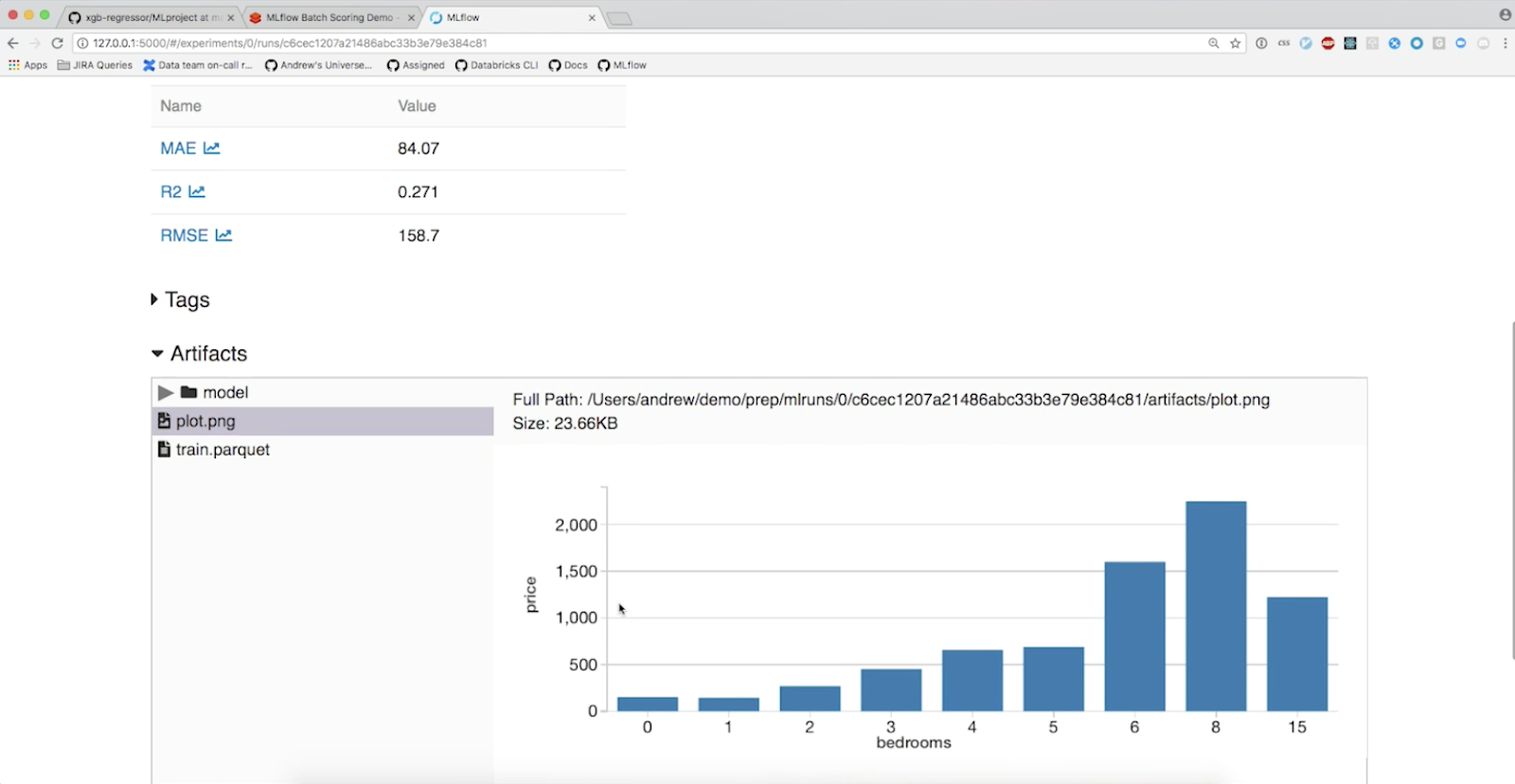
그리고 Serialize된 model도 살펴볼 수 있습니다.

Notebooks이나 Local Apps 그리고 Cloud Jobs을 MLflow의 UI나 API를 통해 tracking server를 제공하고 있습니다.

MLflow 프로젝트는 코드(code)와 entrypoints 그리고 라이브러리를 packaging하여 local(github)이나 remote에서 실행할 수 있습니다.
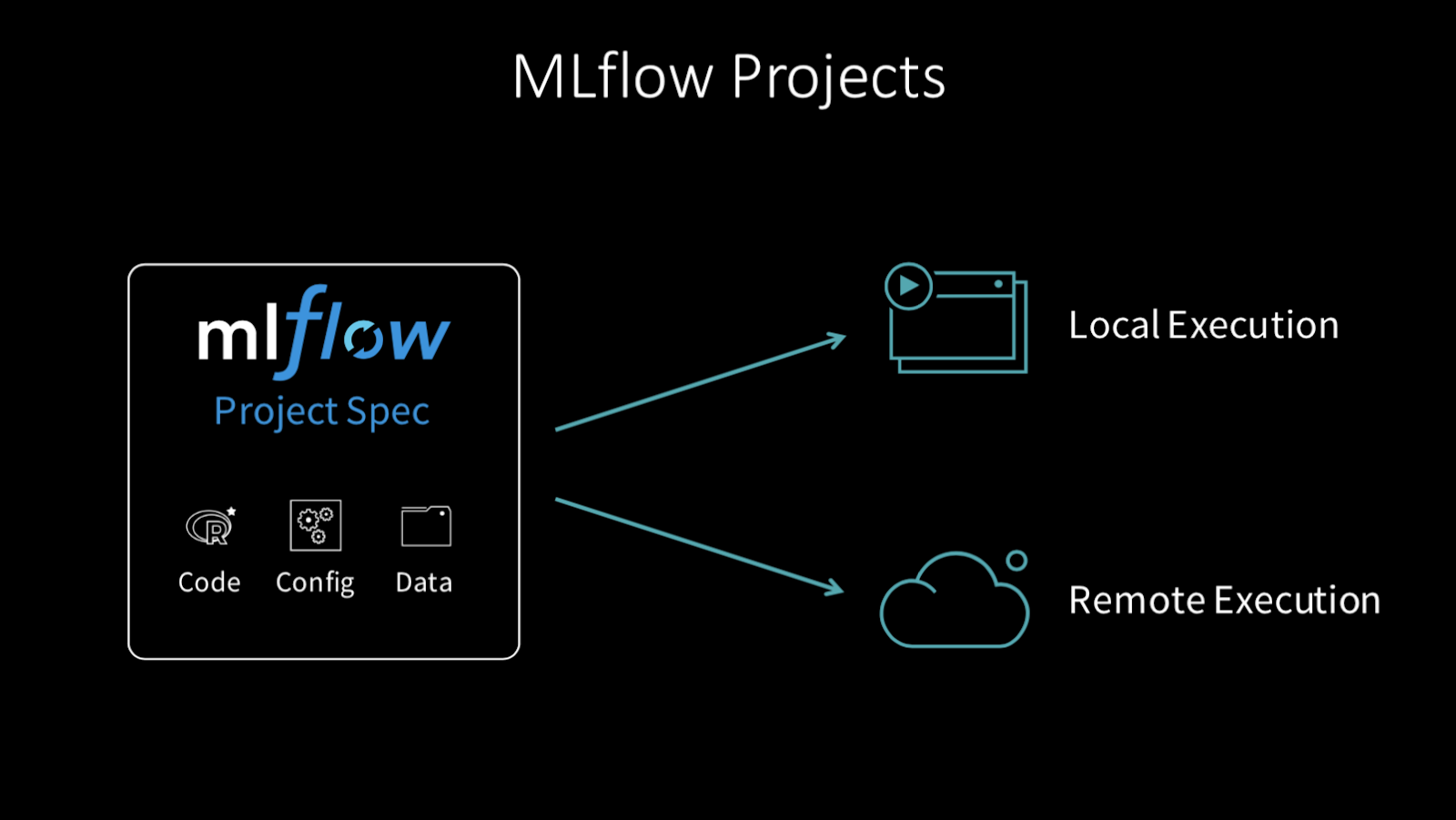

이번 demo는 github에 올라간 serialize된 model을 돌려봅니다.

이제 local laptop에서 mlflow run을 통해 github에 있는 모델을 돌려봅니다.

또한 MLflow web ui에서도 돌아간 작업을 확인할 수 있습니다.

이번엔 MLflow Model을 살펴봅시다.
모델의 deploy에 관한 내용입니다. 다양한 platform(docker, Apache Spark, Azure Machine Learning, Amazon SageMaker)으로 deploy할 수 있습니다.


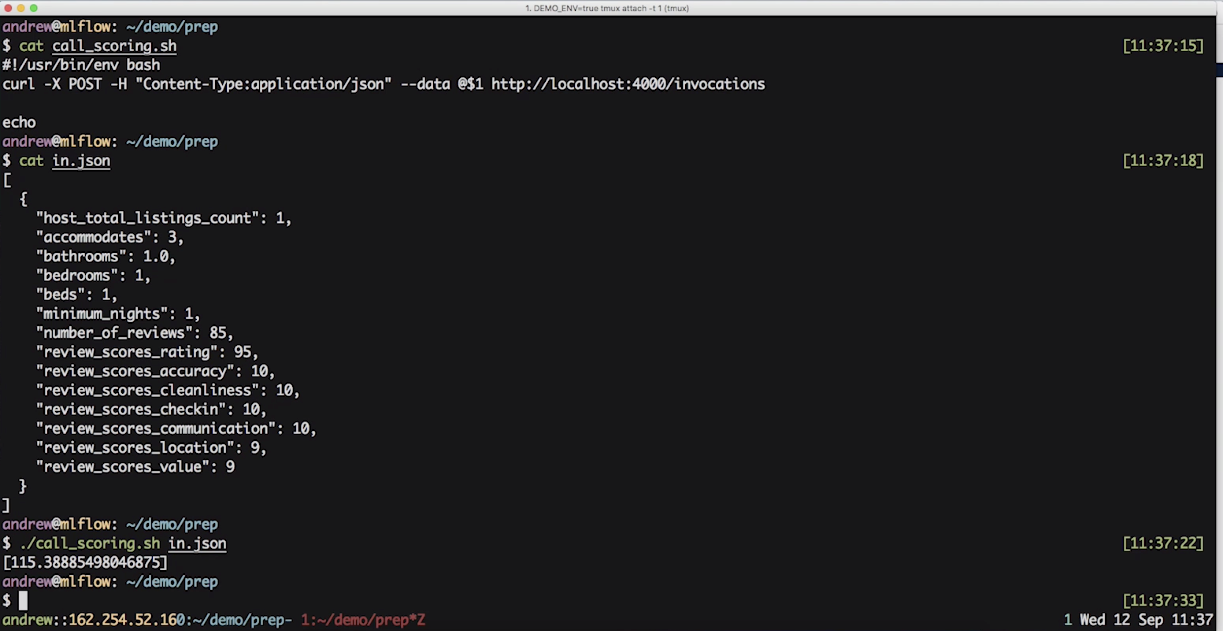
mlflow pyfunc serve 명령어로 모델을 포트 4000을 가진 http서버로 deploy 할 수 있습니다.

우리는 http 서버로 curl을 통해 모델의 예측값을 받아올 수 있습니다.
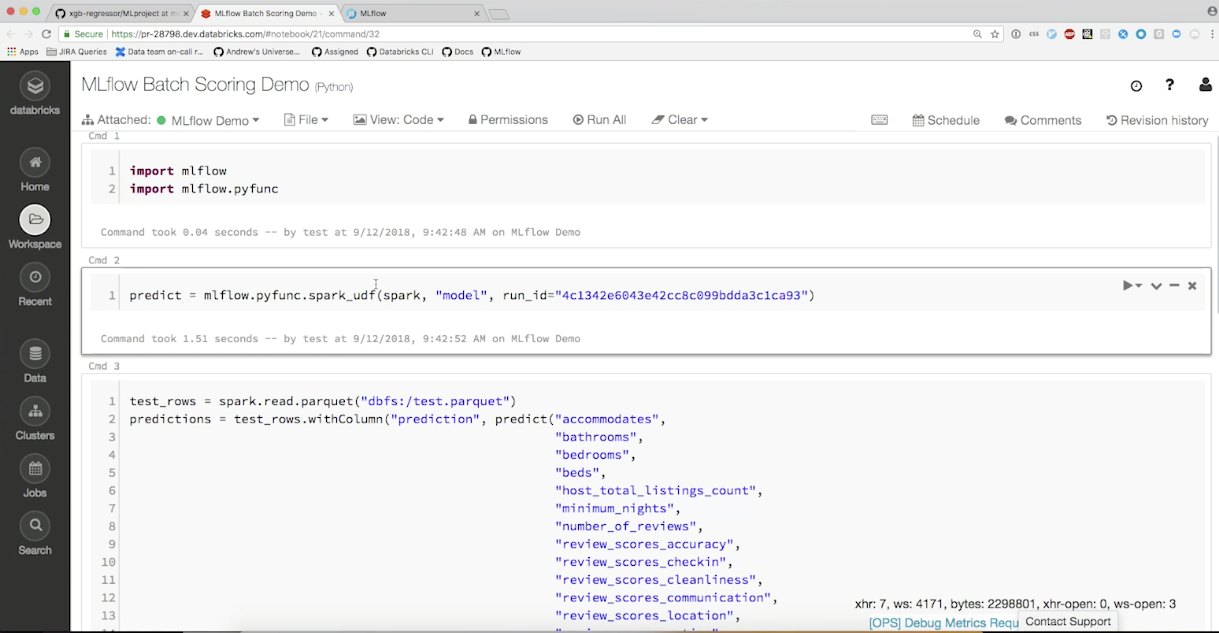
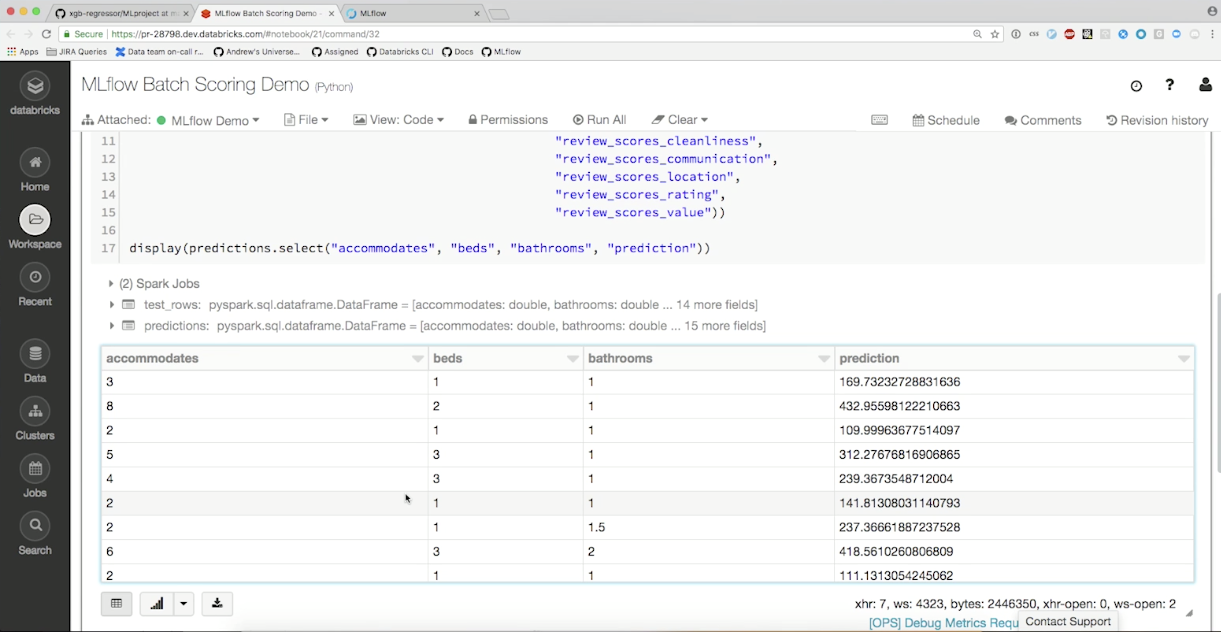
다음은 Databricks의 pySpark Jupyter를 이용한 Batch Scoring demo 입니다.
설치는 간단합니다.

MLflow의 개발 계획 사항입니다.

끝으로 mlflow.org 사이트에서 자세한 사항을 보실 수 있습니다.
