AWS Lambda Serverless MapReduce

오늘은 AWS Lab에서 Serverless computing인 Lambda 서비스를 이용해 MapReduce를 구현한 내용을 살펴보겠습니다.
Serverless Computing이 이슈이기도 하고, MapReduce에 관한 내용이나 성능적인 면에 있어도 많은 연구가 일어나고 있습니다.
원문 내용의 주소는 다음과 같습니다.
Github 코드 주소는 다음과 같습니다.
https://github.com/awslabs/lambda-refarch-mapreduce
Serverless MapReduce 참조 아키텍처는 Amazon S3와 함께 AWS Lambda를 사용해 S3에 저장된 데이터를 처리할 수 있는 MapReduce 프레임워크를 구축합니다. 이 프레임워크를 사용하면 비용 효율적인 파이프 라인(pipeline)을 구축할 수 있습니다.
.
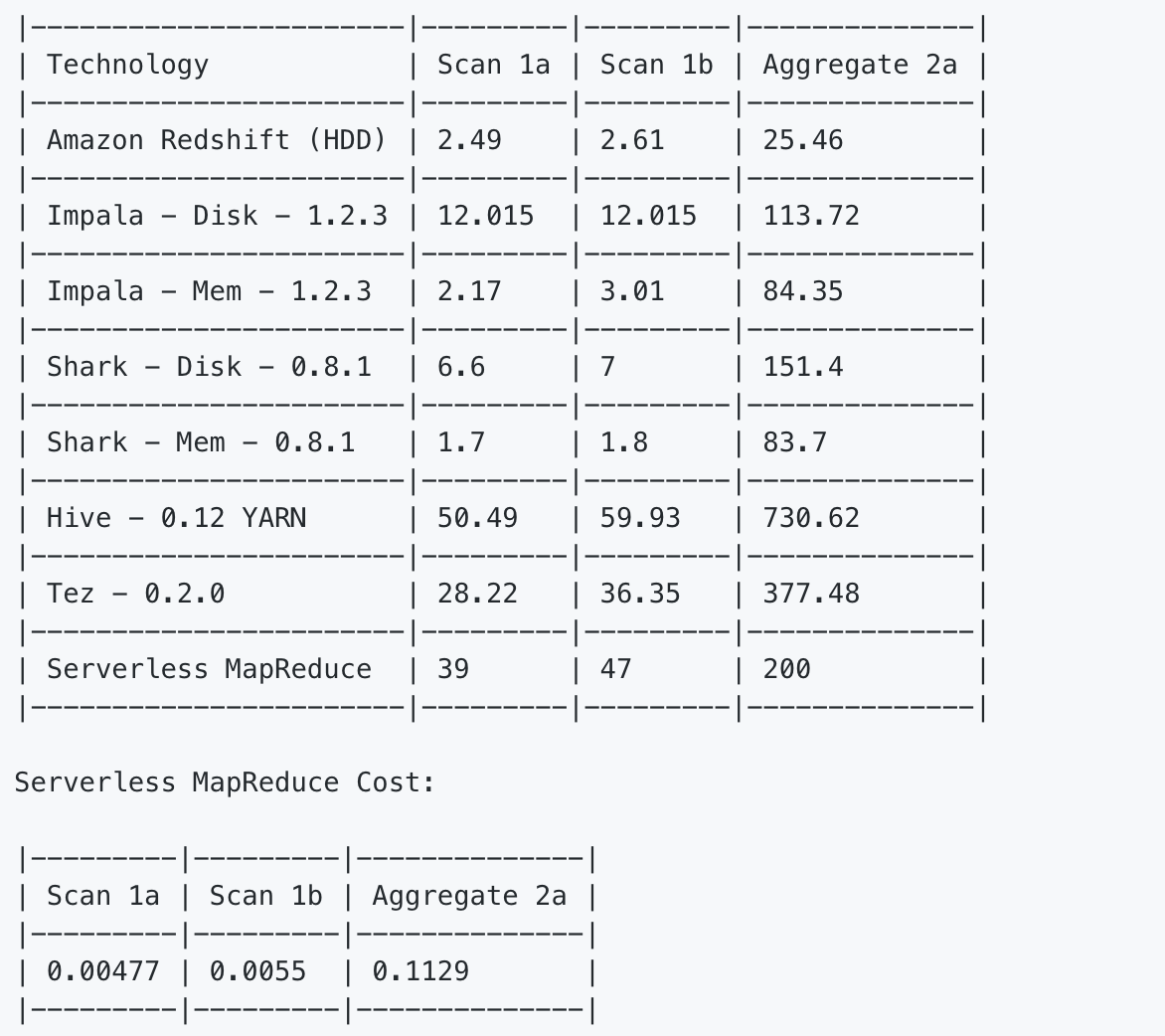
amplab(https://amplab.cs.berkeley.edu/benchmark/) benchmark를 사용하여 다른 Framework 성능 비교를 진행했습니다.
Aggregate의 경우 성능적으로 뒤지지 않으며, 비용 측면에 있어서는 Lambda의 사용 시간당 지불 개념이므로 효율적이다 볼 수 있습니다.
Architecture
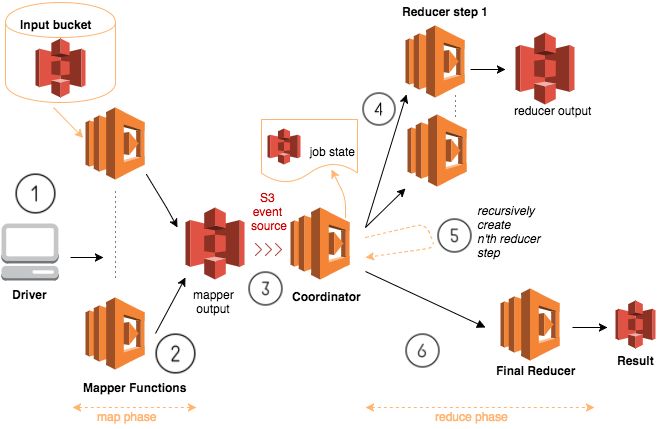
아키텍처는 크게 Mapper와 Reducer와 Coordinator라는 3개의 Lambda functions이 실행됩니다.
Coordinator는 map 단계가 끝났는지 여부를 s3에서 중간 중간 계산 결과를 확인하고 완료가 되었다면, reduce 단계로 실행이 되도록 연결해주는 처리를 합니다.
1. driver.py 드라이버 프로그램이 실행되면 config 파일을 읽어와 mapper와 reducer의 function code 그리고 S3 bucket 경로를 설정합니다.
2. mapper의 동시 실행은 데이터 셋 파티션 개수(예제 데이터셋(24.4GB)은 202개(개당 122MB)로 파티션 되어 있습니다)에 맞춰 최대 병렬 처리 개수를 구합니다.
3. mapper, reducer, coordinator 함수가 동적으로 생성되고, 코드를 업로드합니다. 각각의 함수는 작업이 끝나면 제거됩니다.
4. mapper는 계산 결과를 s3에 저장되고, 이 생성되는 이벤트를 coordinator가 확인합니다.
5. Reducer 작업에서는 reducer가 재귀적으로 호출이 되면서 단 하나의 결과가 생성될 때 까지 reducer 함수를 반복 실행합니다.
Dataset
여기서 예제로 사용하는 데이터셋은 다음의 S3 버킷에 위치합니다.
s3://big-data-benchmark/pavlo/text/1node/
122MB가 202개 있으며 전체 크기는 24.4 GB 됩니다.
- Total Objects: 202
- Total Size: 24.4 GiB
데이터셋을 하나 다운받아 열어보면 다음의 포멧으로 되어 있습니다.
$ aws s3 cp s3://big-data-benchmark/pavlo/text/1node/uservisits/part-00000 .
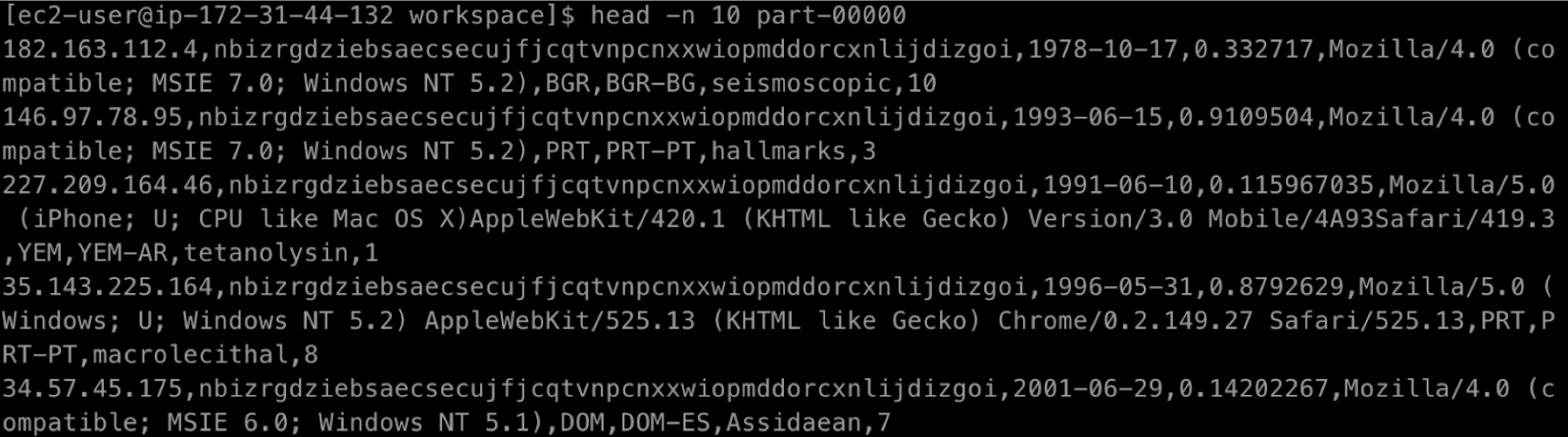
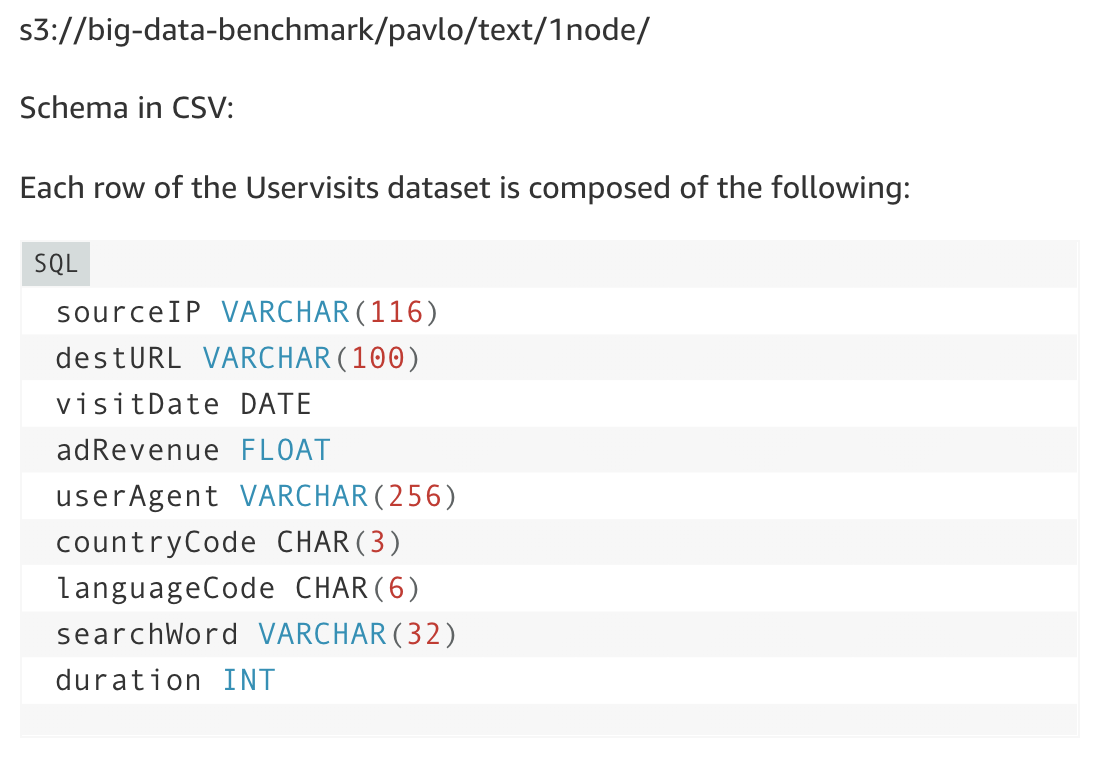
여기서 하는 MR 작업은 sourceIP를 Key 값으로 adRevenue를 더하는 작업입니다.
Mapper와 Reducer가 하려는 동작을 SQL Query로 표현하면 다음과 같습니다.
SELECT SUBSTR(sourceIP, 1, 8), SUM(adRevenue) FROM uservisits GROUP BY SUBSTR(sourceIP, 1, 8)
Set-up
IAM
Lambda와 S3 Bucket의 리스트를 가져오고 읽고 쓸 수 있도록 IAM Role 설정이 필요합니다.
- S3 read/write access
- Cloudwatch log access (logs:CreateLogGroup, logs:CreateLogStream, logs:PutLogEvents)
- X-Ray write access (xray:PutTraceSegments, xray:PutTelemetryRecords)
AWS Configure
$ aws configure
전반적으로 쉽게 실행하기 위해서는 AWS CLI 셋업이 필요합니다.
Code download
원본 코드입니다.
$ git clone https://github.com/awslabs/lambda-refarch-mapreduce
저의 코드는 X-Ray는 사용 안하는 코드로 작성하였습니다. 주석을 일일이 달아놨으니 이해하시는데 도움되실 겁니다.
$ git clone https://github.com/KimJeongChul/lambda-refarch-mapreduce

S3 Download
중간 계산 결과를 저장하고 최종 결과를 저장하기 위한 S3 Bucket을 생성합니다.
$ aws s3 mb s3://YOUR-BUCKET-NAME-HERE

S3 policy
S3 bucket에 다음의 policy를 적용합니다.
$ vi policy.json

IAM Role
필요한 policy를 IAm Role에 등록합니다.
Create the IAM role with respective policy
$ pip install boto3 --user
aws cli 문제가 발생 시 ImportError: cannot import name AliasedEventEmitter
다운그레이드 진행
$ sudo yum downgrade aws-cli.noarch python27-botocore
$ python create-biglambda-role.py

Environment Variable : Role ARN
Serverless MapReduce를 실행하기 위한 role을 환경 변수로 설정합니다.
$ export serverless_mapreduce_role=arn:aws:iam::MY-ACCOUNT-ID:role/biglambda_role

Setting Driver configuration
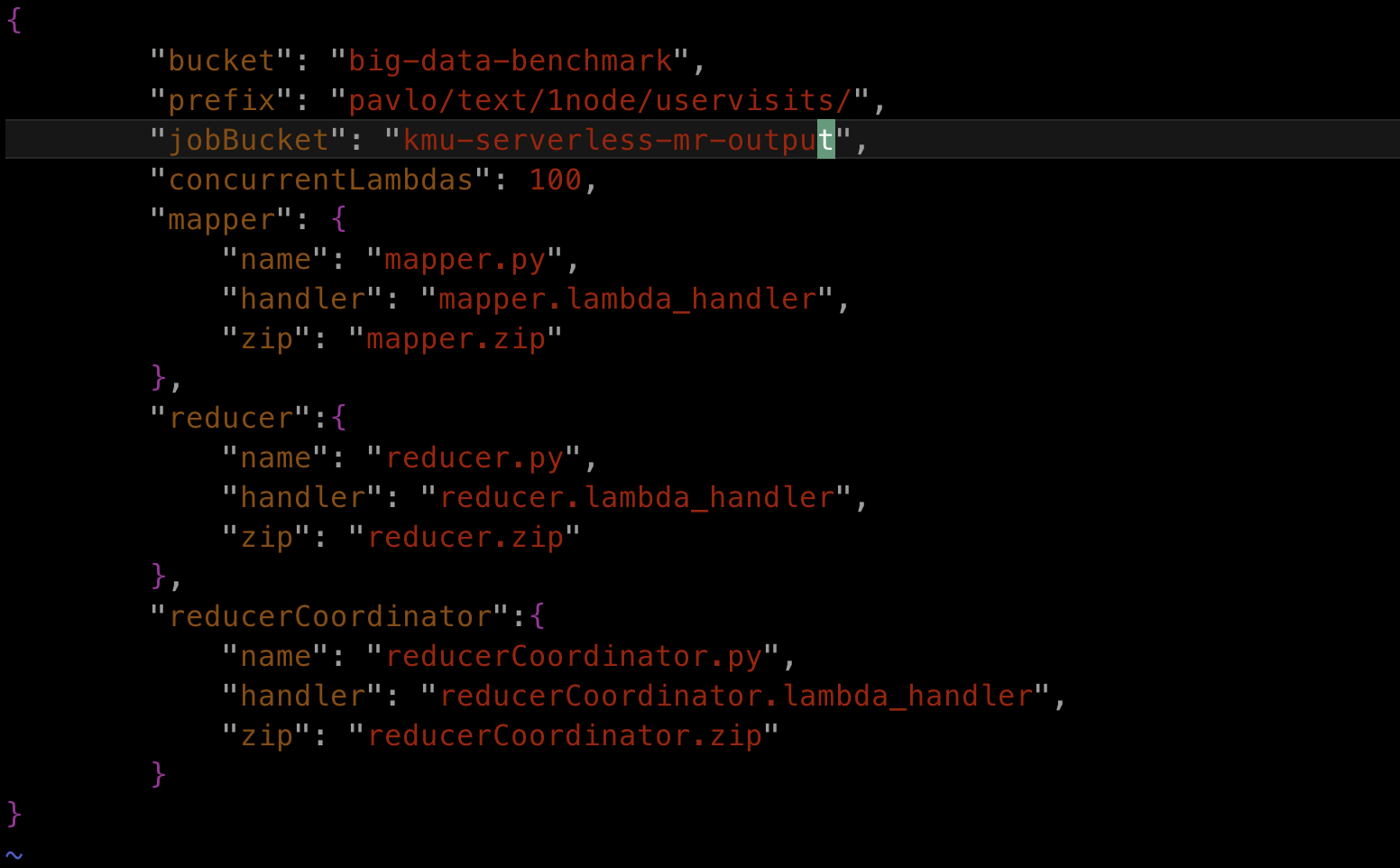
6. driverconfig.json을 수정합니다.
$ ~/lambda-refarch-mapreduce/src/python
$ cat driverconfig.json
jobBucket에 계산 결과가 작성될 S3 Bucket이름을 입력합니다.
{
"bucket": "big-data-benchmark",
"prefix": "pavlo/text/1node/uservisits/",
"jobBucket": "YOUR-BUCKET-NAME-HERE",
"concurrentLambdas": 100,
"mapper": {
"name": "mapper.py",
"handler": "mapper.lambda_handler",
"zip": "mapper.zip"
},
"reducer":{
"name": "reducer.py",
"handler": "reducer.lambda_handler",
"zip": "reducer.zip"
},
"reducerCoordinator":{
"name": "reducerCoordinator.py",
"handler": "reducerCoordinator.lambda_handler",
"zip": "reducerCoordinator.zip"
},
}
Execution Driver Program
$ python driver.py

Mapper 크기 202개


전체 Map이 완료가 되면 Reduce Job이 실행됩니다. 실행되는 중간 과정들은 CloudWatch에서 확인할 수 있습니다.
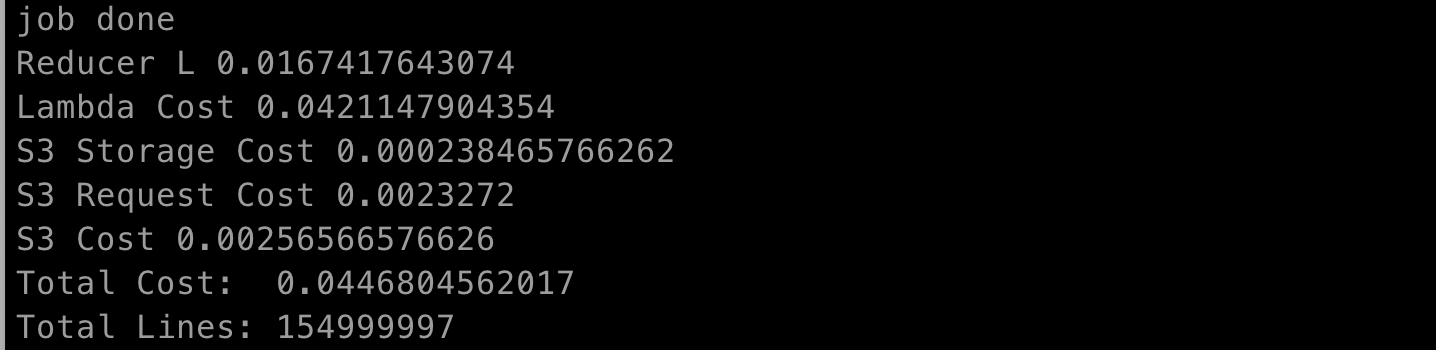
비용 계산에 있어 Lambda 비용이 제일 큽니다.
AWS S3 확인

$ aws s3 ls s3://kmu-serverless-mr-output/bl-release/ --human-readable --recursive --summarize

mapper 202개 생성, reducer 7개
$ aws s3 cp s3://kmu-serverless-mr-output/bl-release/result ./
실제 S3에 저장되는 파일은 json 파일 포멧이며, 중간 계산결과와 마지막 Reduce 결과를 총 포함한 전체 크기가 4.6G 정도로 네트워크 오버헤드는 확실히 클 것으로 예상됩니다.

Driver
https://github.com/KimJeongChul/lambda-refarch-mapreduce/blob/master/src/python/driver.py
Driver 프로그램을 확인해봅시다. 전체적인 MR 작업의 파라미터를 받아오고, 각 map, reduce, coordinator의 function 코드를 패키징하여 Lambda를 생성하고 invoke하며 마지막으로 정리 작업까지 진행합니다.
### utils ####
# 라이브러리와 코드 zip 패키징
def zipLambda(fname, zipname):
# S3 Bucket에 file name(key), json(data) 저장
def write_to_s3(bucket, key, data, metadata):
s3.Bucket(bucket).put_object(Key=key, Body=data, Metadata=metadata)
# 실행 중인 job에 대한 정보를 json 으로 로컬에 저장
def write_job_config(job_id, job_bucket, n_mappers, r_func, r_handler):
######### MAIN #############
## JOB ID 이름을 설정해주세요.
job_id = "bl-release"
# Config 파일
config = json.loads(open('driverconfig.json', 'r').read())
# 1. Driver Job에 대한 설정 파일driverconfig) json 파일의 모든 key-value를 저장
bucket = config["bucket"]
job_bucket = config["jobBucket"]
...
# Lambda의 결과를 읽기 위한 timeout을 길게, connections pool을 많이 지정합니다.
lambda_config = Config(read_timeout=lambda_read_timeout, max_pool_connections=boto_max_connections)
lambda_client = boto3.client('lambda', config=lambda_config)
# prefix와 일치하는 모든 S3 bucket의 key를 가져옵니다.
all_keys = []
for obj in s3.Bucket(bucket).objects.filter(Prefix=config["prefix"]).all():
all_keys.append(obj)
# Memory에 적재가능한 최대 파일 개수를 계산합니다.
bsize = lambdautils.compute_batch_size(all_keys, lambda_memory, concurrent_lambdas)
batches = lambdautils.batch_creator(all_keys, bsize)
n_mappers = len(batches) # 최종적으로 구한 batches의 개수가 mapper로 결정
# 2. Lambda Function 을 생성합니다.
L_PREFIX = "BL"
# Lambda Functions 이름을 지정합니다.
mapper_lambda_name = L_PREFIX + "-mapper-" + job_id;
...
# Job 환경 설정을 json으로 파일 씁니다.
write_job_config(job_id, job_bucket, n_mappers, reducer_lambda_name, config["reducer"]["handler"]);
# 각 mapper와 reducer와 coordinator의 lambda_handler 코드를 패키징하여 압축합니다.
zipLambda(config["mapper"]["name"], config["mapper"]["zip"])
...
# Mapper를 Lambda Function에 등록합니다.
l_mapper = lambdautils.LambdaManager(lambda_client, s3_client, region, config["mapper"]["zip"], job_id,
mapper_lambda_name, config["mapper"]["handler"])
l_mapper.update_code_or_create_on_noexist()
# Reducer를 Lambda Function에 등록합니다.
l_reducer = lambdautils.LambdaManager(lambda_client, s3_client, region, config["reducer"]["zip"], job_id,
reducer_lambda_name, config["reducer"]["handler"])
l_reducer.update_code_or_create_on_noexist()
# Coordinator를 Lambda Function에 등록합니다.
l_rc = lambdautils.LambdaManager(lambda_client, s3_client, region, config["reducerCoordinator"]["zip"], job_id,
rc_lambda_name, config["reducerCoordinator"]["handler"])
l_rc.update_code_or_create_on_noexist()
# Coordinator에 작업을 할 Bucket에 대한 권한(permission)을 부여합니다.
l_rc.add_lambda_permission(random.randint(1,1000), job_bucket)
# Coordinator에 작업을 할 Bucket에 대한 알림(notification)을 부여합니다.
l_rc.create_s3_eventsource_notification(job_bucket)
# 실행 중인 job에 대한 정보를 json 으로 S3에 저장
j_key = job_id + "/jobdata";
data = json.dumps({
"mapCount": n_mappers,
"totalS3Files": len(all_keys),
"startTime": time.time()
})
write_to_s3(job_bucket, j_key, data, {})
######## MR 실행 ########
mapper_outputs = []
# 3. Invoke Mappers
def invoke_lambda(batches, m_id):
'''
Lambda 함수를 호출(invoke) 합니다.
'''
batch = [k.key for k in batches[m_id-1]]
resp = lambda_client.invoke(
FunctionName = mapper_lambda_name,
InvocationType = 'RequestResponse',
Payload = json.dumps({
"bucket": bucket,
"keys": batch,
"jobBucket": job_bucket,
"jobId": job_id,
"mapperId": m_id
})
)
out = eval(resp['Payload'].read())
mapper_outputs.append(out)
print "mapper output", out
# 병렬 실행 Parallel Execution
print "# of Mappers ", n_mappers
pool = ThreadPool(n_mappers)
Ids = [i+1 for i in range(n_mappers)]
invoke_lambda_partial = partial(invoke_lambda, batches)
# Mapper의 개수 만큼 요청 Request Handling
mappers_executed = 0
while mappers_executed < n_mappers:
nm = min(concurrent_lambdas, n_mappers)
results = pool.map(invoke_lambda_partial, Ids[mappers_executed: mappers_executed + nm])
mappers_executed += nm
...
print "all the mappers finished ..."
# Mapper Lambda function 삭제
l_mapper.delete_function()
# 실제 Reduce 호출은 reducerCoordinator에서 실행
# 실행 시간을 이용해 대략적인 비용을 계산합니다.
total_lambda_secs = 0
total_s3_get_ops = 0
total_s3_put_ops = 0
s3_storage_hours = 0
total_lines = 0
for output in mapper_outputs:
total_s3_get_ops += int(output[0])
total_lines += int(output[1])
total_lambda_secs += float(output[2])
mapper_lambda_time = total_lambda_secs
#Note: Wait for the job to complete so that we can compute total cost ; create a poll every 10 secs
# 모든 reducer의 keys를 가져옵니다.
reducer_keys = []
# Reducer의 전체 실행 시간을 가져옵니다.
reducer_lambda_time = 0
while True:
job_keys = s3_client.list_objects(Bucket=job_bucket, Prefix=job_id)["Contents"]
keys = [jk["Key"] for jk in job_keys]
total_s3_size = sum([jk["Size"] for jk in job_keys])
print "check to see if the job is done"
# check job done
if job_id + "/result" in keys:
print "job done"
reducer_lambda_time += float(s3.Object(job_bucket, job_id + "/result").metadata['processingtime'])
for key in keys:
if "task/reducer" in key:
reducer_lambda_time += float(s3.Object(job_bucket, key).metadata['processingtime'])
reducer_keys.append(key)
break
time.sleep(5)
# S3 Storage 비용 - mapper만 계산합니다.
# 비용은 3 cents/GB/month
s3_storage_hour_cost = 1 * 0.0000521574022522109 * (total_s3_size/1024.0/1024.0/1024.0) # cost per GB/hr
s3_put_cost = len(job_keys) * 0.005/1000 # PUT, COPY, POST, LIST 요청 비용 Request 0.005 USD / request 1000
total_s3_get_ops += len(job_keys)
s3_get_cost = total_s3_get_ops * 0.004/10000 # GET, SELECT, etc 요청 비용 Request 0.0004 USD / request 1000
# 전체 Lambda 비용 계산
# Lambda Memory 1024MB cost Request 100ms : 0.000001667 USD
total_lambda_secs += reducer_lambda_time
lambda_cost = total_lambda_secs * 0.00001667 * lambda_memory / 1024.0
s3_cost = (s3_get_cost + s3_put_cost + s3_storage_hour_cost)
# Cost 출력
#print "Reducer Lambda Cost", reducer_lambda_time * 0.00001667 * lambda_memory/ 1024.0
print "Mapper Execution Time", mapper_lambda_time
print "Reducer Execution Time", reducer_lambda_time
...
# Reducer Lambda function 삭제
l_reducer.delete_function()
l_rc.delete_function()
Mapper
https://github.com/KimJeongChul/lambda-refarch-mapreduce/blob/master/src/python/mapper.py
Map 함수에 대해서 정의되어 있습니다.
같은 sourceIp라면 adRevenue를 더하여, 각각의 sourceIp당 adRevenue 정보를 dictionary로 저장합니다.
# S3 session 생성
s3 = boto3.resource('s3')
s3_client = boto3.client('s3')
# Mapper의 결과가 작성될 S3 Bucket 위치
TASK_MAPPER_PREFIX = "task/mapper/";
# 주어진 bucket 위치 경로에 파일 이름이 key인 object와 data를 저장합니다.
def write_to_s3(bucket, key, data, metadata):
s3.Bucket(bucket).put_object(Key=key, Body=data, Metadata=metadata)
def lambda_handler(event, context):
start_time = time.time()
job_bucket = event['jobBucket']
src_bucket = event['bucket']
src_keys = event['keys']
job_id = event['jobId']
mapper_id = event['mapperId']
output = {}
line_count = 0
err = ''
# 입력 CSV => 츌력 JSON 포멧
# 모든 key를 다운로드하고 Map을 처리합니다.
for key in src_keys:
response = s3_client.get_object(Bucket=src_bucket,Key=key)
contents = response['Body'].read()
# Map Function
for line in contents.split('\n')[:-1]:
line_count +=1
try:
data = line.split(',')
srcIp = data[0][:8]
if srcIp not in output:
output[srcIp] = 0
output[srcIp] += float(data[3])
except Exception, e:
print e
time_in_secs = (time.time() - start_time)
# Mapper의 결과를 전처리, 이후에 S3에 저장
pret = [len(src_keys), line_count, time_in_secs, err]
mapper_fname = "%s/%s%s" % (job_id, TASK_MAPPER_PREFIX, mapper_id)
metadata = {
"linecount": '%s' % line_count,
"processingtime": '%s' % time_in_secs,
"memoryUsage": '%s' % resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
}
print "metadata", metadata
write_to_s3(job_bucket, mapper_fname, json.dumps(output), metadata)
return pret
Reducer
https://github.com/KimJeongChul/lambda-refarch-mapreduce/blob/master/src/python/reducer.py
Reducer가 Mapper와 구조적으로 동일하게 보이지만, dictionary의 aggregation을 통해 중간 계산 결과들을 하나의 파일로 축소합니다.
1st reducer: 100 file
2nd reducer : 50 file
…
7th reducer : 2 file
8th reducer : 1 file
# S3 session 생성
s3 = boto3.resource('s3')
s3_client = boto3.client('s3')
# Mapper의 결과가 저장된 S3 Bucket
TASK_MAPPER_PREFIX = "task/mapper/";
# Reducer의 결과를 저장할 S3 Bucket
TASK_REDUCER_PREFIX = "task/reducer/";
# 주어진 bucket 위치 경로에 파일 이름이 key인 object와 data를 저장합니다.
def write_to_s3(bucket, key, data, metadata):
s3.Bucket(bucket).put_object(Key=key, Body=data, Metadata=metadata)
def lambda_handler(event, context):
start_time = time.time()
job_bucket = event['jobBucket']
bucket = event['bucket']
reducer_keys = event['keys']
job_id = event['jobId']
r_id = event['reducerId']
step_id = event['stepId']
n_reducers = event['nReducers']
results = {}
line_count = 0
# 입력 CSV => 츌력 JSON 포멧
# 모든 key를 다운로드하고 Reduce를 처리합니다.
# Reducer는 Mapper의 output 개수에 따라 1/2씩 처리가 되며 Reducer의 step 개수가 결정됩니다.
# Mapper의 output 개수가 64개라면 (step:output개수/1:32/2:16/3:12.8/4:4/5:2/6:1) 총 6단계 reduce 발생
for key in reducer_keys:
response = s3_client.get_object(Bucket=job_bucket, Key=key)
contents = response['Body'].read()
try:
for srcIp, val in json.loads(contents).iteritems():
line_count +=1
if srcIp not in results:
results[srcIp] = 0
results[srcIp] += float(val)
except Exception, e:
print e
time_in_secs = (time.time() - start_time)
pret = [len(reducer_keys), line_count, time_in_secs]
print "Reducer ouputput", pret
if n_reducers == 1:
# 마지막 Reduce 단계의 file은 result로 저장합니다.
fname = "%s/result" % job_id
else:
# 중간 Reduce 단계의 저장
fname = "%s/%s%s/%s" % (job_id, TASK_REDUCER_PREFIX, step_id, r_id)
metadata = {
"linecount": '%s' % line_count,
"processingtime": '%s' % time_in_secs,
"memoryUsage": '%s' % resource.getrusage(resource.RUSAGE_SELF).ru_maxrss
}
write_to_s3(job_bucket, fname, json.dumps(results), metadata)
return pret
ReducerCoordinator
다음으로 제일 중요한 Reducer의 workflow를 중재하고 다음 lambda를 호출하는 coordinator 입니다.
https://github.com/KimJeongChul/lambda-refarch-mapreduce/blob/master/src/python/reducerCoordinator.py
Reduce는 두 개의 파일을 하나로 합치는 과정입니다. stage별로 reduce 작업이 끝나면 다음의 stage로 넘어가야합니다.
이를 s3에서 읽어와 파악을 하고 Lambda(reduce) 를 invoke 합니다.
### STATES 상태 변수
MAPPERS_DONE = 0;
REDUCER_STEP = 1;
# S3 session 생성
s3 = boto3.resource('s3')
s3_client = boto3.client('s3')
# Lambda session 생성
lambda_client = boto3.client('lambda')
# 주어진 bucket 위치 경로에 파일 이름이 key인 object와 data를 저장합니다.
def write_to_s3(bucket, key, data, metadata):
s3.Bucket(bucket).put_object(Key=key, Body=data, Metadata=metadata)
# Reducer의 상태 정보를 bucket에 저장합니다.
def write_reducer_state(n_reducers, n_s3, bucket, fname):
ts = time.time()
data = json.dumps({
"reducerCount": '%s' % n_reducers,
"totalS3Files": '%s' % n_s3,
"start_time": '%s' % ts
})
write_to_s3(bucket, fname, data, {})
# mapper의 파일 개수를 카운트 합니다. 파일 개수가 reducer의 step 수를 결정
def get_mapper_files(files):
ret = []
for mf in files:
if "task/mapper" in mf["Key"]:
ret.append(mf)
return ret
# reducer의 배치 사이즈를 가져옵니다.
def get_reducer_batch_size(keys):
#TODO: Paramertize memory size
batch_size = lambdautils.compute_batch_size(keys, 1536, 1000)
return max(batch_size, 2) # 적어도 배치가 2개 라면 - 종료
# 작업이 끝났는 지 확인합니다.
def check_job_done(files):
# TODO: USE re
for f in files:
if "result" in f["Key"]:
return True
return False
# Reducer의 state 정보를 Bucket에서 가져옵니다.
def get_reducer_state_info(files, job_id, job_bucket):
reducers = [];
max_index = 0;
reducer_step = False;
r_index = 0;
# Step이 완료가 되었는지 확인합니다.
# Reducer의 상태를 확인합니다.
# 마지막 Reducer step인지 결정합니다.
for f in files:
if "reducerstate." in f['Key']:
idx = int(f['Key'].split('.')[1])
if idx > r_index:
r_index = idx
reducer_step = True
# Reducer의 상태가 완료인지 확인합니다.
if reducer_step == False:
return [MAPPERS_DONE, get_mapper_files(files)]
else:
# Reduce steop이 완료되었다면 Bucket에 작성합니다.
key = "%s/reducerstate.%s" % (job_id, r_index)
response = s3_client.get_object(Bucket=job_bucket, Key=key)
contents = json.loads(response['Body'].read())
for f in files:
fname = f['Key']
parts = fname.split('/')
if len(parts) < 3:
continue
rFname = 'reducer/' + str(r_index)
if rFname in fname:
reducers.append(f)
if int(contents["reducerCount"]) == len(reducers):
return (r_index, reducers)
else:
return (r_index, [])
def lambda_handler(event, context):
print("Received event: " + json.dumps(event, indent=2))
start_time = time.time();
# Job Bucket으로 이 Bucket으로부터 notification을 받습니다.
bucket = event['Records'][0]['s3']['bucket']['name']
config = json.loads(open('./jobinfo.json', "r").read())
job_id = config["jobId"]
map_count = config["mapCount"]
r_function_name = config["reducerFunction"]
r_handler = config["reducerHandler"]
### Mapper 완료된 수를 count 합니다. ###
# Job 파일들을 가져옵니다.
files = s3_client.list_objects(Bucket=bucket, Prefix=job_id)["Contents"]
if check_job_done(files) == True:
print "Job done!!! Check the result file"
return
else:
mapper_keys = get_mapper_files(files)
print "Mappers Done so far ", len(mapper_keys)
if map_count == len(mapper_keys):
# 모든 mapper가 완료되었다면, reducer를 시작합니다.
stepInfo = get_reducer_state_info(files, job_id, bucket)
print "stepInfo", stepInfo
step_number = stepInfo[0];
reducer_keys = stepInfo[1];
if len(reducer_keys) == 0:
print "Still waiting to finish Reducer step ", step_number
return
# 메타데이터(metadata)의 파일을 기반으로 Reduce의 배치 사이즈를 계산합니다.
r_batch_size = get_reducer_batch_size(reducer_keys);
print "Starting the the reducer step", step_number
print "Batch Size", r_batch_size
r_batch_params = lambdautils.batch_creator(reducer_keys, r_batch_size);
n_reducers = len(r_batch_params)
n_s3 = n_reducers * len(r_batch_params[0])
step_id = step_number +1;
for i in range(len(r_batch_params)):
batch = [b['Key'] for b in r_batch_params[i]]
# Reducer Lambda를 비동기식(asynchronously)으로 호출(invoke)합니다.
resp = lambda_client.invoke(
FunctionName = r_function_name,
InvocationType = 'Event',
Payload = json.dumps({
"bucket": bucket,
"keys": batch,
"jobBucket": bucket,
"jobId": job_id,
"nReducers": n_reducers,
"stepId": step_id,
"reducerId": i
})
)
print resp
# Reducer의 상태를 S3에 저장합니다.
fname = "%s/reducerstate.%s" % (job_id, step_id)
write_reducer_state(n_reducers, n_s3, bucket, fname)
else:
print "Still waiting for all the mappers to finish .."
Experiment
메모리를 달리하면 연산 compute time이 줄어 전체 latency 시간이 이득이 생기나 메모리당 가격을 매기기 때문에 cost는 올라갑니다.

입력 데이터셋 파일의 하나당 크기가 122M 여서 메모리를 달리해도 배치 사이즈는 1로 고정되어 있습니다. Lambda 메모리가 512MB까지는 돌아가나 그 이상 낮추면 Map에서도 데이터를 적재 못하고 하더래도 Reduce 단계에서도 문제가 생깁니다.
파일의 크기를 10M로 줄여서 테스트를 해보았습니다. 10M 파일을 전체 12G 크기로 하여 1237개의 object로 변경했습니다.
Dataset size: 12963753071.0, nKeys: 1237, avg: 10479994.3985
실험을 돌리면 실제 Mapper에서 처리하는 파일 개수가 달라집니다.

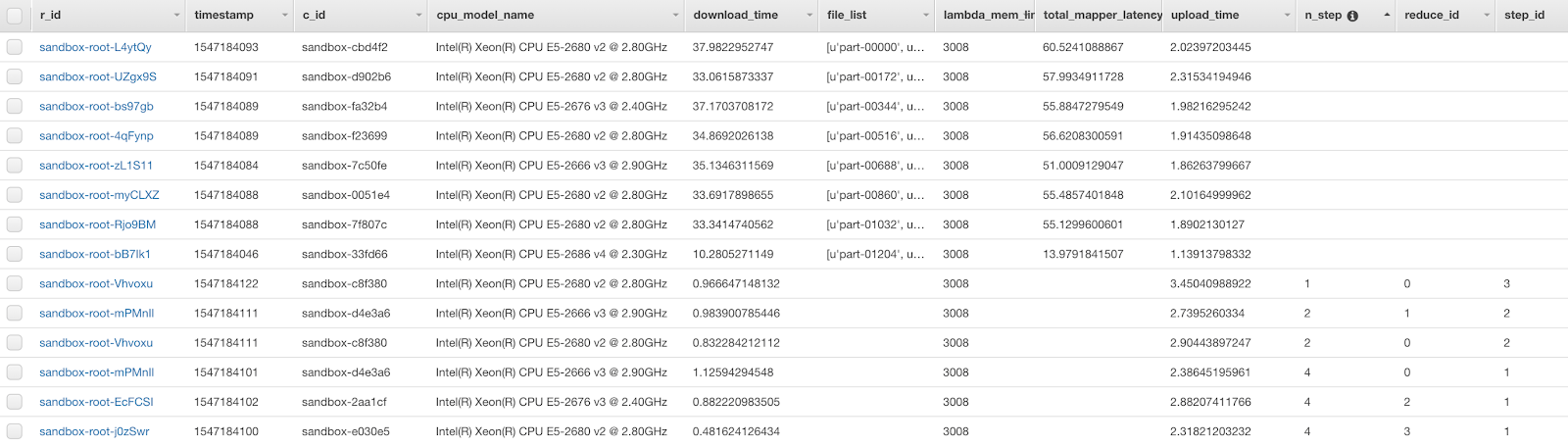
Map과 Reduce에 일어나는 정보를 DynamoDB에 저장하는 코드는 dynamodb branch에 있습니다.
DynamoDB에서 lambda-network-io라는 테이블 생성하시고, r_id(String), timestamp(Number)로 index를 만들어주세요.
추가적으로 DynamoDB 사용 시에 biglambda_role에 AmazonDynamoDBFullAccess를 추가해야 합니다.

결과를 DynamoDB에서 확인할 수 있습니다.
'AWS' 카테고리의 다른 글
| container보다 빠른 새로운 가상화 기술 Firecracker (0) | 2019.04.19 |
|---|---|
| AWS Lambda PyTorch RNN 모델 서빙하기 (0) | 2019.01.23 |
| AWS EC2와 Lambda iPerf3 네트워크 성능 측정 (0) | 2019.01.09 |
| AWS EC2 Ubuntu1804에 GitLab 서버 설치 (0) | 2019.01.07 |
| AWS Lambda OpenCV 라이브러리 빌드 video processing (0) | 2018.12.06 |