2018년 카카오 blind 코딩 테스트 - 후보키 python
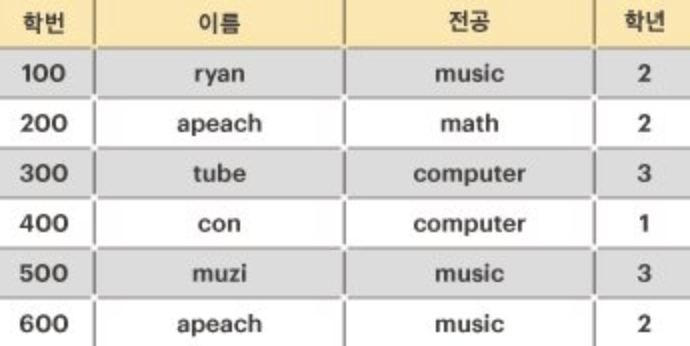
출처 : https://programmers.co.kr/learn/courses/30/lessons/42890
문제 풀이
후보키를 계산하기 위해서는 모든 column의 부분집합을 구해야 합니다.
유일성을 만족하는 부분 집합을 구하기
유일성을 만족하는 부분 집합 중에서 최소성 만족하는 남기기
[1] get_all_subset(iterable) : 모든 부분 집합을 구하는 함수를 사용합니다.
itertools.chain() : list/tuples/iterable을 연결합니다.
itertools.combination() : 조합을 계산합니다.
전체 부분 집합을 구하기 위해서는 다음과 같습니다.
예시로 column이 name, address, major라고 할 때 0부터 column 전체 개수 만큼 돌아야 전체의 부분집합을 구할 수 있게 되죠.
combinations(column, 0)
()
combinations(column, 1)
('name',)
('address',)
('major',)
combinations(column, 2)
('name', 'address')
('name', 'major')
('address', 'major')
combinations(column, 3)
('name', 'address', 'major')
[2] 유일성을 만족하는 부분 집합을 구해야 합니다.
정해놓은 column의 부분집합에서 유일성을 만족하는지 안하는지 원소들을 검사를 해야 됩니다.
set을 이용해서 집합을 만들고 in이라는 키워드를 이용해 있는지 없는지 확인하면 됩니다.
[3] 최소성을 만족하는 부분 집합을 구한다.
column의 적은 개수 만으로도 후보키를 뽑을 수 있는지 확인하려면 부분 집합인지 확인하면 됩니다.
set(A).issubet(B) A가 B의 부분 집합 인지 확인하면 최소성을 만족할 수 있습니다.
'Algorithm' 카테고리의 다른 글
| 2018년 카카오 blind 코딩 테스트 - 길 찾기 게임 python (0) | 2019.09.21 |
|---|---|
| 2018년 카카오 blind 코딩 테스트 - 무지의 먹방 라이브 python (1) | 2019.09.21 |
| 2018년 카카오 blind 코딩 테스트 - 실패율 python (0) | 2019.09.21 |
| 2018년 카카오 blind 코딩 테스트 - 오픈채팅방 python (0) | 2019.09.21 |
| programmers lv1 문자열 다루기 기본 python (0) | 2019.09.21 |
2018년 카카오 blind 코딩 테스트 - 후보키 python
출처 : https://programmers.co.kr/learn/courses/30/lessons/42890
문제 풀이
후보키를 계산하기 위해서는 모든 column의 부분집합을 구해야 합니다.
유일성을 만족하는 부분 집합을 구하기
유일성을 만족하는 부분 집합 중에서 최소성 만족하는 남기기
[1] get_all_subset(iterable) : 모든 부분 집합을 구하는 함수를 사용합니다.
itertools.chain() : list/tuples/iterable을 연결합니다.
itertools.combination() : 조합을 계산합니다.
전체 부분 집합을 구하기 위해서는 다음과 같습니다.
예시로 column이 name, address, major라고 할 때 0부터 column 전체 개수 만큼 돌아야 전체의 부분집합을 구할 수 있게 되죠.
combinations(column, 0)
()
combinations(column, 1)
('name',)
('address',)
('major',)
combinations(column, 2)
('name', 'address')
('name', 'major')
('address', 'major')
combinations(column, 3)
('name', 'address', 'major')
[2] 유일성을 만족하는 부분 집합을 구해야 합니다.
정해놓은 column의 부분집합에서 유일성을 만족하는지 안하는지 원소들을 검사를 해야 됩니다.
set을 이용해서 집합을 만들고 in이라는 키워드를 이용해 있는지 없는지 확인하면 됩니다.
[3] 최소성을 만족하는 부분 집합을 구한다.
column의 적은 개수 만으로도 후보키를 뽑을 수 있는지 확인하려면 부분 집합인지 확인하면 됩니다.
set(A).issubet(B) A가 B의 부분 집합 인지 확인하면 최소성을 만족할 수 있습니다.
'Algorithm' 카테고리의 다른 글
| 2018년 카카오 blind 코딩 테스트 - 길 찾기 게임 python (0) | 2019.09.21 |
|---|---|
| 2018년 카카오 blind 코딩 테스트 - 무지의 먹방 라이브 python (1) | 2019.09.21 |
| 2018년 카카오 blind 코딩 테스트 - 실패율 python (0) | 2019.09.21 |
| 2018년 카카오 blind 코딩 테스트 - 오픈채팅방 python (0) | 2019.09.21 |
| programmers lv1 문자열 다루기 기본 python (0) | 2019.09.21 |