제3장 프로세스(Process)와 쓰레드(Thread)
프로세스란 일반적으로 현재 실행 중인 프로그램을 말하며 라는 일반적인 용어도 사용된다.
실행 중인 프로그램의 의미를 가지는 프로세스는 실행되는 동안 커널이 가진 자원(CPU, Memory, Devices, Files)을 독자적으로 차지해야 할 경우가 많다. 따라서 프로세스는 항상 커널의 자원을 차지하기 위해 경쟁하고 커널은 이들에게 효율적으로 자원을 스케줄링하여 할당하고 회수하는 역할을 한다.
프로세스는 커널이 가진 여러 가지 자원의 할당 및 사용을 위해 커널 함수를 호출하여야 하는데,
이러한 커널 함수들을 일반적으로 시스템 호출(system call)이라 한다. 따라서 동작 중인 컴퓨터 시스템은 커널과 프로세스 간의 관계에 의해 모든 것이 결정되는 것이다.
커널의 자원을 차지하여 실행하고 경쟁하는 스케줄링의 단위는 그 구현 방식에 따라 주소 공간을 개별적으로 가지는 유닉스의 전통적인 프로세스와 그 이후에 등장한 경량급 프로세스로서 주소 공간을 대부분 공유하는 쓰레드(Thread)로 구분되고, 프로세스는 다른 프로세스나 자신 내부에서 여러 쓰레드를 생성할 수 있다.
생성 및 실행 상태는 다르지만, 프로세스나 쓰레드는 리눅스 커널 내부에서 모두 자원을 차지하기 위해 서로 경쟁하는 태스크들로 관리한다. 프로세스에는 커널이 시스템의 관리를 위해 생성한 시스템 프로세스와 사용자가 생성한 사용자 프로세스가 있으며, 일반적으로 시스템 프로세스는 중요한 커널의 내부적 일을 담당하므로 스케줄링의 우선순위가 높은 것이 보통이다.
사용자가 리눅스 시스템에 로그인하며 운영체제와 사용자의 대화를 위해 쉘 프로그램이 실행되는데,
쉘 또한, 하나의 응용 프로세스이며, 쉘을 통한 명령이나 사용자 프로그램의 실행 또한, 모두 프로세스의 형태로 실행된다.
프로세스와 쓰레드의 차이점은 쓰레드에 관한 장에서 상세히 설명하기로 하고, 쓰레드 설명 이전까지는 통합된 개념으로서 프로세스라는 용어를 사용하기로 한다.
프로세스는 생성에서 종료까지 커널의 관리를 받아야 하며, 자원 할당 및 대기, 입출력의 실행 여부에 따라 여러 가지 상태로 변화하게 된다.

<그림> 커널과 프로세스
3.1 프로세스의 상태(
(1) 실행 상태(Running) : 프로세스에 CPU가 할당되어 실행 중인 상태이다.
(2) 준비 상태(Ready) : 커널에 의해 스케줄링 되어 CPU가 할당되면 실행될 수 있는 상태이다.
즉, CPU 할당 기다림
(3) 대기 상태(Blocked) : 프로세스가 CPU 이외의 장치를 사용하는 입출력이나 메시지 수신 등을
커널에 요구하면 이의 종료 시까지 프로세스는 CPU가 필요 없는 정지된 상태가 되는데
이를 대기 상태라 한다. 대기 상태 동안 해당 장치는 이 프로세스를 위해 동작하며, 동작 완료에
의한 입출력의 종료 또는 메세지의 수신 등이 발생하면, 해당 프로세스는 준비 상태로 전이 하게 된다.
커널은 한 프로세스의 대기 상태 동안 CPU를 다른 프로세스에 할당하여 CPU와 입출력 장치가
동시에 동작하도록 하여 자원의 효율성을 높인다.
3.1.1 프로세스의 상태 전이
프로세스는 생성되면 일단 준비 상태에 속한다. 일반적인 단일 CPU의 경우 실행 상태의 프로세스는 하나 뿐이므로 CPU를 기다리는 준비 상태의 프로세스들은 스케줄링 큐를 형성하게 되고, 이들 중 스케줄러에 선택되는 프로세스가 실행 상태가 된다.
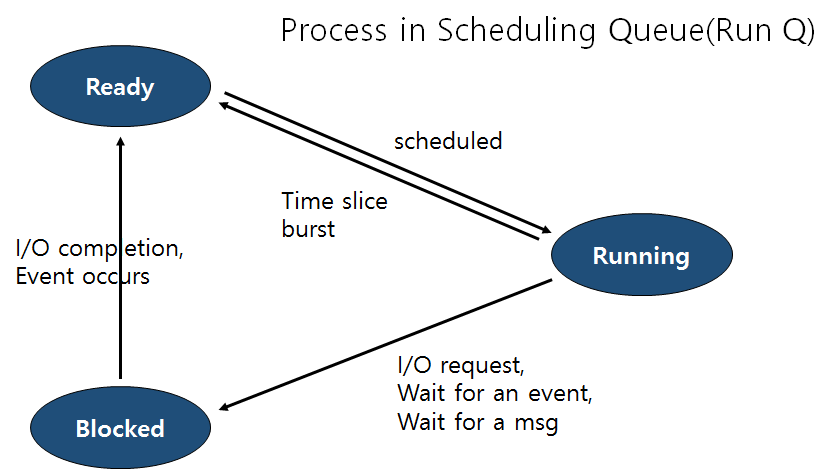
<그림> 프로세스의 상태 전이
실행 상태(Running)의 프로세스가 요청한 입출력의 완료나 어떤 사건을 기다리게 되는 경우, 그 프로세스에는 CPU를 주어도 소용이 없다. 이러한 상태를 대기 상태(Blocked)라고 하며, 원하는 사건이 발생하면 해당 프로세스는 다시 준비 상태(Ready)가 된다.
커널은 CPU를 차지하여 실행 중인 프로세스의 CPU 독점을 방지하기 위해 일반적으로 타임 슬라이스(Time slice)에 의한 시분할 시스템의 개념을 도입하는 것이 보통이다.
타임 슬라이스란 프로세스의 CPU 독점 방지를 위해 매 CPU 차지 시마다 CPU 사용의 한계 구간으로 주어지는 것으로, 커널은 타임 슬라이스를 다 사용한 프로세스에서 일단 CPU를 회수하고 다른 프로세스의 CPU 사용이 차례로 이루어 진 후에 다시 CPU를 할당 한다.
3.1.2 리눅스 프로세스의 상태
1) 리눅스 프로세스의 실행(Running) 상태 : TASK_RUNNING
실행 상태의 프로세스가 중앙 처리기를 회수 당하거나 반납하는 경우에는 크게 두 가지 형태
첫째는 주어진 타임 슬라이스가 다 소진되었거나 그렇지 않다고 하더라도 더욱 높은 우선순위의 프로세스가 있어 중앙 처리기를 회수 당하는 경우,
둘째는 실행 중에 입출력이나 동기화(이벤트 대기)에 관계된 시스템 호출을 하여 중앙 처리기를 커널 내부에 스스로 반납하는 경우.
운영체제에 따라 차이점이 있지만, 리눅스의 경우에는 일반적으로, 프로세스의 실행 상태는 커널 모드 실행(Kernel mode running 또는 System mode running) 상태와 사용자 모드 실행(User mode running) 상태 두 가지로 구분된다.
실행 모드 구분 | 실행 코드 | 시스템 보호 측면 |
사용자 모드 실행 (User Mode Running) | 사용자 프로그램의 코드가 실행된다. 커널 함수 호출이 아닌 일반 라이브러리 함수의 실행도 이에 포함된다. 라이브러리 함수는 프로그램이 적재될 때, 사용자 프로세스의 텍스트 영역에 포함된 것이므로 사용자 모드 실행에 속함 | 중앙 처리기의 상태를 나타내는 특수 레지스터에 현재 명령어의 실행 모드가 사용자 모드로 표시. 자원 보호를 목적 |
커널 모드 실행 (Kernel Mode | 프로세스가 실행 중에 메모리에 상주하는 커널 함수를 호출하였거나 하드웨어 인터럽트가 발생하여, 커널 안의 코드가 수행될 때, 프로세스는 커널 모드 실행 | 현재 실행 모드 : 커널 모드 하드웨어적으로 여러 가지 특권을 가지게 되어, 입출력이나 인트럽트 및 시스템 제어에 관련된 특수 명령어를 수행하고 다른 프로세스의 영역에도 접근 가능하여 메모리 보호 하드웨어도 접근. |
* 시스템 호출(System call)
커널(Kernel)은 프로세스들이 공유하는 컴퓨터 시스템의 모든 자원을 프로세스 간의 충돌이 없고 활용도가 높아지도록 프로세스에 배분한다. 이러한 역할을 커널의 자원 관리(Resource Management) 기능이라 한다. 프로세스는 커널이 가진 자원에 대해 서로 차지하기 위해 경쟁하며 실행되는 프로그램이다. 커널은 이러한 자원관리와 함께, 자원에 대한 쉬운 사용 방법을 프로세스에 제공한다. 커널이 프로세스에 제공하는 자원 할당/보호 및 쉬운 자원 사용 API를 시스템 호출이라 한다. 시스템 호출 함수들은 커널 영역 내부에 있으므로 메모리에 상주하며 여러 프로세스에 의해 공유된다.
시스템 호출 때문에 프로세스가 커널 안으로 진입하는 것을 “trap” 이라 한다.

<그림> 커널 모드 실행과 사용자 모드 실행의 구분
2) 프로세스의 준비(Ready) 상태: TASK_RUNNING
리눅스의 경우 프로세스에 관한 커널의 모든 정보는 태스크 구조체(task_struct)에 저장되는데, 실행 상태와 준비 상태의 프로세스는 모두 TASK_RUNNING으로 표시되고 이 두 상태의 프로세스의 태스크 구조체들은 모두 스케줄링 큐에 연결 리스트 형태로 저장된다. 다만 리눅스 커널에 현재 실행 중인 프로세스의 태스크 구조체는 current라는 커널의 전역 변수가 가리키도록 유지한다.
3) 프로세스의 대기(Blocked) 상태: TASK_INTERRUPTIBLE 또는 TASK_UNINTERRUPTIBLE
프로세스 상태가 대기 중일 때에, 그 태스크 구조체(task_struct)는 스케줄링 큐에서 제거되어 대기 이벤트 별로 형성되는 특정한 대기 큐(queue)에 소속되는 것이 보통이다. 입출력이 완료되거나 기다리던 이벤트가 발생하면 대기 상태의 프로세스는 다시 TASK_RUNNING(준비) 상태가 되어 그 태스크 구조체는 스케줄링 큐(run_queue)로 복귀된다.
리눅스 운영체제의 경우, 대기 상태는 두 가지로 구분된다.
첫째 TASK_UNINTERRPUTIBLE 상태는 대기 중에 해당 프로세스에 응급 사건의 발생을 알리는 시그널(signal)이 전달되어도, 원래의 기다리는 사건이 발생할 때까지 대기를 계속하는 상태.
둘째 TASK_INTERRUPTIBLE 상태는 시그널에 의한 응급 처리를 위해 기다리던 사건에 대한 대기를 중지하고,
준비 상태로 복귀하는 경우.
4) 프로세스의 좀비(EXIT_ZOMBIE) 상태
프로세스의 수행이 종료되면 모든 프로세스의 태스크 구조체와 메모리 영역의 프로그램들을 제거되어야 한다. 그러나 리눅스 커널에서는 해당 프로세스를 생성한 후, 생성 프로세스의 종료를 기다리고 있는 부모(Parent) 프로세스에게 종료 프로세스에 관한 정보를 전달하여야 하므로, 이 정보 전달 시까지 태스크 구조체를 유지한다. 이렇게 실행은 종료되었지만, 태스크 구조체는 유지되고 있는 상태를 좀비 상태라 한다.
5) 프로세스의 중지(TASK_STOPPED) 상태
디버깅의 목적을 위해 프로세스가 일시 중지된 상태이다.
시그널이나 디버깅 개시 명령으로 다시 실행될 수 있다.
6) 기타
부모 프로세스가 없는 경우의 EXIT_DEAD, 태스크 삭제 직전의 TASK_DEAD 상태 존재.
3.2 프로세스의 문맥 교환(Context Switch)
3.2.1 프로세스의 문맥(Context)과 태스크 구조체
정적 자원인 프로그램과는 달리 프로세스는 항상 실행되며 상태 변화를 계속하는 동적인 개체이다.
또한, 프로세스는 수행 중에 자원에 대한 할당 대기와 외부 인터럽트 처리와 같은 급한 작업 때문에, 언제라도 수행이 중지되고, 그 후에 다시 속개되는 일이 반복된다.
따라서 프로세스의 중지 시점에는 프로세스의 실행에 필요한 모든 정보와 환경들이 저장되어야 하고, 속개 시에는 중단 시점의 내용이 그대로 복원되어야 한다. 이렇게 중지 시에 저장되고 속개 시에 복원되는 프로세스의 실행에 필요한 모든 정보를 프로세스의 문맥(context)이라 한다. 프로세스의 문맥은 프로세스의 구성 요소 및 수행 환경과 관련이 있다.
* 프로세스의 문맥(Context) 구성
프로세스의 기본 주소 공간
- 텍스트(Text) 영역 : 프로그램의 코드 부분
- 데이터(Data) 영역 : 프로그램의 전역 변수 부분
- 스택(Stack) 영역 : 프로그램의 지역 변수 부분
- 힙(Heap) 영역 : 프로세스의 동적 메모리 할당 영역
커널 관리의 프로세스 관련 정보(태스크 구조체, task_struct)
- 중앙 처리기 범용 레지스터의 내용 : 일반적 계산을 위해 활용되는 레지스터들의 내용
- 중앙 처리기 특수 레지스터의 내용 : 프로세스의 실행 위치를 나타내는 프로그램 계수기(Program Counter),
스택 포인터(Stack Pointer), 중앙 처리기 상태 레지스터, 가상 메모리 페이지 테이블 관련 정보 등.
- 프로세스 및 프로세스 그룹 식별자
- 사용자 정보, 보안 정보 - 오픈 파일 정보
- 프로세스 상태 - 시그널(Signal) 정보
- 우선순위, 정책 등의 스케줄링 정보 - CPU 사용 시간 정보
- 부모, 형제, 자식 프로세스 정보 - 타이머(Timer) 정보
- 프로그램 정보 - 동기화 정보
- 메모리 영역 정보 - IPC(Inter-process Communication) 관련 정보
위의 문맥 구성에서 프로세스 공간 영역은 메모리에 할당되므로 프로세스의 사용자 공간이 유지되면 자동으로 보존된다. 가상 메모리 관리에 의해 메모리에서 퇴출 당하는 영역도 발생하나 필요 시에 다시 메모리 복귀된다. 프로세스 정보와 관련된 모든 문맥은 태스크 구조체(PCB, Process Control Block)에 위 표와 같이 보관되는데, 이들 중 프로세스 중단 시점에서 반드시 보존되고 실행 개시 시점에 복원되어야 하는 것은 대부분 중앙 처리기 레지스터들의 내용이다. 즉, 레지스터들의 내용은 중앙 처리기를 차지하는 프로세스가 실행되는 동안 모두 변화되기 때문에, 프로세스 중지 시에는 반드시 보존되었다가 수행 속개 시 다시 복원되어야 한다.
리눅스에서는 커널의 프로세스 관리 정보를 담은 구조체(PCB)를 task_struct라 하며,
프로세스가 실행 또는 준비 상태일 때에 태스크 구조체는 CPU 별 스케줄링 큐인 runqueues에 우선순위 연결 리스트(linked list) 방식으로 저장되고 대기 상태일 때에는 스케줄링 큐에서 제거되어 사건 별 대기 큐(sleep queue)에 소속된다.


3.2.2 프로세스 간의 문맥 교환(Context Switching)
스케줄링으로 실행 중인 한 프로세스에서 다른 프로세스로 CPU가 할당될 때에, 중단되는 프로세스가 사용 중인 모든 레지스터의 내용은 보존되고, CPU가 새로 할당되는 프로세스는 자신이 이전에 중단 되었던 시점에서 보존된 모든 레지스터의 내용이 복원되어야 한다. 따라서 CPU 내의 레지스터 입장에서는 현 내용이 보존되고 새로운 내용이 로딩되므로 이를 문맥 교환(Context Switching)라 한다.
교체되는 레지스터에는 프로그램 카운터 레지스터도 포함되므로, 실제로 문맥 교환은 레지스터 내용 교체 후에 새로운 프로세스로 분기(jump)하는 것이 된다. 리눅스 커널 내부의 scheduler에 의해 호출되는 context_switch() 함수는 메모리 관련 정보에 대한 문맥 교환을 하고 switch_to()를 호출하여 레지스터의 내용에 대한 문맥 교환을 하게 된다. 즉 switch_to() 함수에서 새로운 프로세스로 분기 하는데, 유의할 점은 switch_to()에 의해 중단되는 프로세스는 언젠가는 다시 다른 문맥 교환으로 다시 이 지점에서 수행이 속개된다는 점이다.
따라서 프로세스는 커널 내에서 중단되고 실행 속개도 커널 모드에서 다시 시작되는 점을 기억한다.
이러한 문맥 교환 관련 함수들은 모두, CPU의 아키텍처에 따라 그 코드가 달라지므로 일반적으로 어셈블리 언어로 코딩 된다.
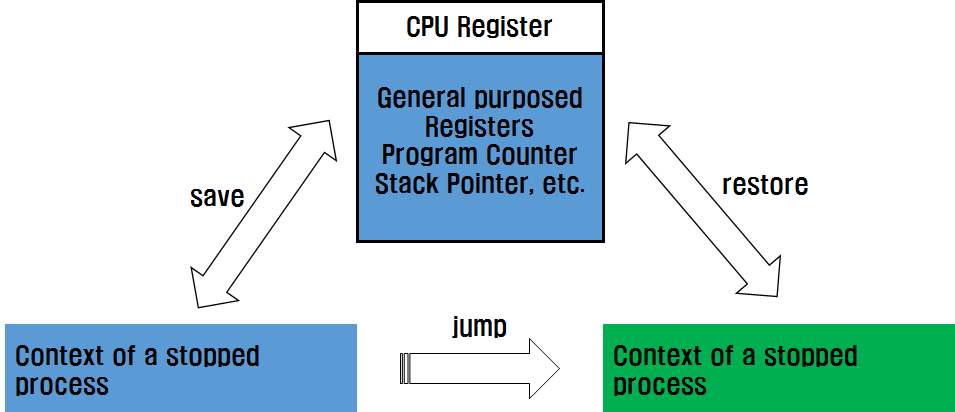
<그림> 프로세스의 문맥 교환

<그림> 프로세스 사이의 문맥 교환
3.3 시스템 호출과 프로세스의 상태 전이
사용자가 요구한 입출력이 완료되기 전 까지는 커널 내의 관련 시스템 호출 처리 루틴뿐만 아니라 디바이스 드라이버의 주축인 인터럽트 처리 루틴이 서로 유기적인 관계를 맺고 동작한다.
이 과정에서는 입출력 완료 대기에 의한 프로세스 대기 상태로의 전이, 문맥 교환이 발생하고, 디스크 입출력을 최소화하기 위한 커널의 버퍼링(S/W 캐싱) 기법도 등장한다.
이러한 처리 과정은 커널의 두 가지 대표적 구성 요소인 시스템 호출과 인터럽트 처리의 관계를 이해하는 중요한 부분.
1) 예제 프로그램
여기서 사용자 프로세스는 디스크 파일을 오픈(Open)하고 read 시스템 호출을 수행한다.
read 시스템 호출이 수행되면 사용자 프로세스와 중앙 처리기는 커널 모드 실행으로 상태가 바뀌며 커널 안의 read 기능 실행 함수로 진입하게 된다.
커널 내부 함수로의 진입은, 중앙 처리기의 모드를 커널 모드 실행으로 바꾸어 여러가지 특권을 갖게 해야 하므로, 일반적인 사용자 모드에서의 함수 호출 기법이 아닌 트랩(trap)이라는 특수 명령어를 수행
* 사용자 프로세스 #define BUF_LENGTH 256 int main() { int file_id; char buffer[BUF_LENGTH]; file_id = open(“data_file”, 0); // read-only-mode open n = read(file_id, buffer, BUF_LENGTH); // 사용자 모드에서 실행 중 시스템 호출을 하여 커널로 진입하며 커널 모드 실행으로 전환 // 복귀 시는 다시 사용자 모드 } |
2) 커널의 시스템 호출 처리 루틴
리눅스의 경우, 디스크 파일 입력을 위한 시스템 호출 처리 루틴은 파일 시스템 및 매체의 종류, 가상 메모리 및 페이지 버퍼 관리 등과 연결되어 매우 복잡한 구조를 가진다.
이러한 복잡한 과정을 피하고 핵심 개념의 이해를 돕기 위해 리눅스 구조를 축약하여 의사 코드로 설명한다.
디스크 파일 입력을 위한 시스템 호출은 다음과 같은 작업을 수행한다.
① 읽고자 하는 물리적 디스크 블록이 이미 커널의 시스템 버퍼에 있으면 이를 사용자에게 반환하고 사용자
모드로 복귀한다.
시스템 버퍼는 한번 read 하였던 디스크 블록에 대한 중복 디스크 입출력을 피하려고 커널이 커널 메모리
영역에 메모리 허용 한도 내에서 디스크 블록을 유지하고 있는 영역으로,
리눅스에서 전통적인 buffer cache나 가상 메모리 관리를 위한 page cache로 유지하는데 이는 파일
시스템의 종류에 따라 달라진다.(가장 많이 사용되는 ext3 file system의 경우 page cache를 사용한다.)
② 시스템 버퍼에 원하는 디스크 블록이 없거나 모자라는 경우에는 해당 블록을 시스템 버퍼에 적재하기 위해
버퍼를 할당 받고, 디스크 입출력 정보를 탑재한 입출력 제어 블록을 생성하여 디스크 입출력 요구 큐에
등록한다.
③ 디스크 입출력 요구 큐에 등록된 프로세스의 입출력이 완료될 때까지 프로세스는 대기 상태(Blocked)로
전환하며 문맥 교환을 통하여 다른 프로세스에 CPU를 넘긴다. 즉 프로세스는 시스템 호출 처리 루틴
내부에서 수행이 중지되는 상태가 된다.(대기 상태)
④ 입출력 큐에 등록된 입출력이 디바이스 드라이버에 의해 추후에 완료되면, 프로세스는 준비 상태로
전이되고, 스케줄링을 받아 다시 실행이 속개되면(중지 되었던 위치에서 다시 커널 모드 실행) 커널의
시스템 호출 루틴은 시스템 버퍼의 내용을 사용자 영역에 복사하고 사용자 모드로 복귀하여 시스템 호출을
완료한다.
위의 ③이 수행이 중지된 상태(대기 상태)에서 ④의 상태로 오는 과정에는 디스크 디바이스 드라이버 인터럽트 처리 루틴과 스케줄러(문맥 교환 : Context Switching)가 작용하게 된다.
즉 ③에서 ④로 되는 과정에는 디스크 입출력의 진행 및 완료, 준비 상태로의 전이, 커널 모드 실행 모드로의 전이가 차례로 있어야 한다.
다음의 프로그램은 위와 같은 작업을 수행하는 커널 내부의 디스크 입력 루틴인 read와 디스크 인터럽트 핸들러를 의사 코드로 축약한 것이다.
위와 같은 과정은 파일 시스템의 종류에 따라 달라지나, 시스템 호출인 sys_read에서 시작하여 캐시 찾기와 디스크 입출력을 하는 핵심 루틴인 do_generic_mapping_read에 도착하기까지는 여러 경로의 루틴을 거치게 된다.
과정
① sys_read : file offsetwjdqh ghlremr
② vfs_read : open mode, access check, security check
③ do_sync_read (ext3 file의 경우, read 요청 관련 정보 생성)
④ __generic_file_aio_read : 가상 메모리 관리의 page cache를 사용하는 모든 file system의 read routine
⑤ do_generic_file_read -> do_generic_mapping_read
* 커널 read 함수의 의사코드, sys_read로부터 여러 경로로 (다음 내용은 do_generic_file_read를 의사 코드로 축약한 것임) void do_generic_mapping_read(,,,) { // 커널 모드 실행 find_get_page routine 호출; // 파일 mapping의 index로 해당 부분을 page cache에 찾아 반환 // page cahce에서 있는 경우, file_read_actor를 통해 __copy_to_user로 user area에 copy하고, // 실패한 경우에는 다음을 수행 no_cached_page: // free page를 할당한다. read page: // file system에 따른 read_page routine을 호출한다. // ext3 file system의 경우는 ext3_readpage -> mpage_readpage 호출 /* mpage_readpage 루틴은 디스크 I/O 요청 블록을 생성하여 disk I/O 요구 큐에 삽입 (mpage_bio_submit -> generic_make_request) */ Context Switching을 수행한다. // 대기 상태에서 깨어나면 디스크 I/O는 완료된 상태이고, // 이 프로세스는 준비 상태를 거쳐 이미 커널 모드 실행 상태로 전환된 것임 // page cache가 준비되었으므로 fing_get_page() routine 호출 // 부분 부터 반복 } 위의 루틴 수행 후, 종국에는 ret_from_sys_call을 통해 사용자 모드로 복귀한다. |
S/W Caching : 일반적인 디스크 기반의 운영체제에는 파일 입출력 및 가상 메모리 관리와 관련해서 많은 디스크 입출력이 발생한다. 그러나 디스크 입출력은 중앙 처리기의 처리 속도보다 매우 느리므로, 시스템의 성능 향상을 위해 디스크 입출력을 가능한 한 최소화하여야 한다. 이를 위해 대부분의 커널은 읽어온 디스크 블록의 재활용을 위해 커널 내의 일정 메모리 공간이 허용하는 한도 내에서 시스템 버퍼(각종 S/W 캐시, 가상 메모리의 page cache)에 이를 저장한다.
그리고 후에 발생하는 디스크 입출력 요구가 있을 때에 시스템 버퍼에 이 블록이 있으면 디스크 입출력 없이 이를 찾아 재활용하게 된다.
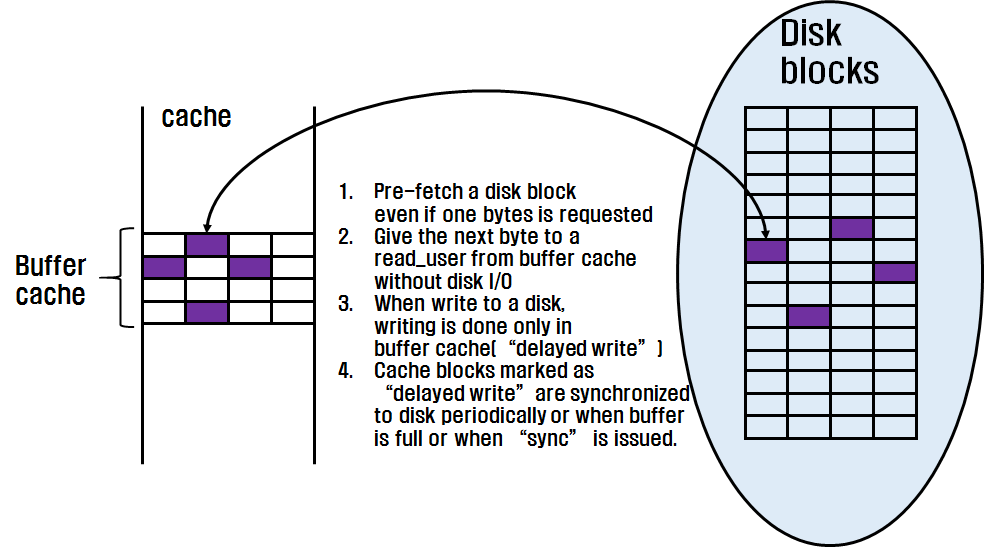
<그림> 버퍼 캐시
DMA 디스크 입출력: 디스크 입출력은 블록(보통 4K~32K 정도) 단위의 DMA(Direct Memory Access) 방식으로 진행된다. 이러한 디스크 입출력은 CPU의 처리 속도보다 상대적으로 느리므로 디스크 입출력 요구들의 큐가 형성되기 마련이다. 디스크 입출력 요구 큐는 한 단위의 디스크 입출력에 필요한 모든 정보를 가지는 입출력 정보 블록의 리스트로 형성된다.
이러한 정보는 <메모리의 주소, 디스크 트랙/섹터 주소, 입출력 바이트 수, 읽기/쓰기> 들로 구성되고 디스크 입출력은 중앙 처리기가 이러한 정보로 디스크 제어기에 입출력 명령을 내림으로써 시작된다.
일단 입출력이 시작되면 중앙 처리기는 더는 관여하지 않으므로 디스크 제어기가 메모리와 디스크 간에 자료를 직접 이동 시킴으로써 입출력을 진행한다. 이 기간에 CPU는 다른 프로세스를 수행할 수 있으며, 디스크 제어기는 디스크 블록 입출력의 완료 시에 이 사실을 인터럽트를 발생 시켜 CPU에게 통보한다.
따라서 입출력 수행 중에 CPU는 명령어의 패치(fetch)를 위해, 디스크 제어기는 입출력 자료의 읽기나 쓰기를 위해 메모리에 동시에 접근하게 되고, 메모리에 대한 충돌 시에는 DMA가 우선권을 가진다. (cycle stealing)
다음은 프로세스가 실질적 대기 상태로 진입하는 block_wait_queue_running 관한 설명
block_wait_queue_running 함수에서 커널 모드로 실행 중인 프로세스는 대기 상태가 되어 대기하는 사건이 발생할 때까지 기다리게 되는데, 이 과정 설명
* 커널 내부 함수 block_wait_queue_running inline void block_wait(request_queue_t *q) prepare_to_wait_exclusive(.., &wait, TASK_UNINTERRUPTIBLE); // wait queue에 삽입, task 대기 상태로 전환 // 여기서 TASK_UNITERRUPTIBLE 상태는 signal 발생해도 깨어나지 않음을 의미한다. io_schedule(); // 위 함수를 호출하여 문맥 교환(Context Switching)을 수행하고 // 다시 깨어날 때에는 disk I/O는 완료되고 ready 상태를 거쳐 scheduling을 받아 running 상태로 됨 // 이러한 과정에 관여하는 것은 disk 제어기에 대한 커널 interrupt hanlder이다. } |
* inline 함수 : 인라인 함수는 프로그램의 코드들 가운데 컴파일된 함수 코드가 삽입된다. 이는 컴파일러에 의해 해당 인라인 함수가 함수 코드로 대체됨을 뜻한다. 이렇듯 인라인 함수를 사용하면, 프로그램은 해당 코드를 수행하기 위해 위의 일반 함수 수행처럼 메모리에 있는 함수의 주소를 찾아 점프할 필요가 없어지게 되어, 일반 함수보다 약간이나마 빠른 수행 속도를 갖을 수 있다. 그러나 만약 크기가 큰 코드를 가진 함수를 인라인 함수로 사용하고, 10번을 호출게 된다면, 해당 프로그램 코드 사이에 10개의 복사본을 갖게 됨으로써, 메모리 사용면에서 좋지 않을 수 있다. 또한 함수 수행의 속도에서도 일반 함수 크기가 작다면, 함수 수행을 위해 점프하고, 돌아오는 시간이 적으므로 속도로 얻을 수 있는 이익이 작을 수 있다.
위의 의사 코드에서 io_schedule() 함수는 현 실행 프로세스를 중지시키고 새로운 프로세스에 중앙 처리기를 할당하는 문맥 교환(Context Switching) 함수이다. 그 과정은 중앙 처리기 레지스터 내용과 같은 시스템 문맥을 중단될 프로세스의 태스크 구조체(PCB)에 저장하고, 새로 선정된 프로세스의 태스크 구조체 내에 보존되었던 문맥을 레지스터들에 복귀시키는 것이다.
저장 및 복귀되는 레지스터에는 프로그램 계수기(Program Counter)도 포함되기 때문에 이러한 문맥 교환이 일어나면 자동으로 예전에 중지되었던 프로세스의 코드 부분으로 분기가 일어나 실행이 시작된다.
여기서 주지해야 할 사실은 문맥 교환으로 실행이 중지되는 프로세스도 이와 마찬가지로 언젠가는 다른 프로세스의 문맥 교환에 의해 현 지점으로 돌아오게 된다는 것이다.
따라서 switch_to는 함수로 표현되지만, 수행을 마치고 당장 복귀되는 일반 함수와 달리 다른 프로세스로 분기되었다가 다시 다른 프로세스의 문맥 교환에 의해 돌아오는 특수한 형태의 함수로 생각할 수 있다.
이제 이러한 예의 나머지 설명 부분은 디스크 입출력을 요청한 프로세스가 문맥 교환을 통해 대기 상태로 정지되어 다른 프로세스가 실행되는 상태에서, 어떠한 과정을 통해 디스크 입출력이 진행되고 다시 이전 프로세스가 실행 상태로 복귀되는지에 대한 것이다.
3) 디스크 인터럽트 처리 루틴
예제의 입출력 요청 프로세스가 커널 내부의 문맥 교환으로 중지된 상태에서, 디스크 입출력의 진행은 디스크 제어기로부터의 인터럽트를 처리하는 커널 루틴이 담당하게 된다. 디스크 입출력 처리 루틴의 주요 작업
① 입출력 종료로 인터럽트가 발생하면 인터럽트 처리 루틴은 입출력이 종료된 프로세스의 태스크 구조체를 준비 상태(TASK_RUNNING)로 만들어 스케줄링 큐(run_queue)에 재 삽입한다. 이러한 행위를 일반적으로 wake_up이라 하며 준비 상태가 된 프로세스는 스케줄링을 기다리게 된다.
② 입출력 요구 큐에 등록된 다음 입출력 정보 블록으로 디스크 제어기에 입출력을 명령한다.
위에서 입출력이 완료되어 다시 준비 상태(TASK_RUNNING)로 전환되는 프로세스는 일반적으로 사용자 모드에서 실행할 때보다 높은 우선순위를 할당 받아 스케줄링 큐로 삽입된다. 그 이유는 시스템 호출 실행 중에 중지되었다 다시 깨어난 프로세스를 일반 사용자 실행 모드의 프로세스 보다 먼저 실행시켜 주기 위함이다.
다음은 어떤 다른 프로세스의 실행 중에 디스크 입출력 완료 인터럽트가 발생하여 진입하게 되는 인터럽트 처리 루틴의 개념 설명이다.
* 디스크 인터럽트 추리 루틴(,,,) // 커널 모드 실행 { // 입출력 완료 인터럽트의 경우 // 디스크 입출력 큐의 가장 앞(front)에 있는 입출력 요구가 수행 완료된 것임. 디스크 입출력 요구 큐가 수행된 입출력 정보 블록을 제거; 스케줄링 큐에 삽입; // wake up 디스크 입출력 대기 큐의 다음 요구 블록의 입출력 정보로, 디스크 제어기에 명령을 내려 다음 입출력을 시작 시킴; ret_from_interrupt; // 복귀 과정에서 스케줄러가 동작한다. } |
위와 같은 일련의 인터럽트 처리 후에는 준비 상태로 가게 된 예제 프로세스는 커널 내의 여러 부분에 위치하는 문맥 교환 호출로 다른 프로세스로부터 중앙처리기를 할당 받아 자신이 예전에 문맥 교환을 한 지점을 다시 복귀하게 된다.
커널 내에서 문맥 교환이 일어나는 경우는 두 가지 유형이다.
① 프로세스가 시스템 호출을 하고 해당 커널 함수 안에서 입출력 요구 등을 하여 프로세스가 대기 상태로 전환하며 자발적으로 문맥 교환(voluntary context switch)를 하는 경우
② 시스템 호출 및 인터럽트의 처리 과정에서 여러 가지 이유(타임 슬라이스의 소진, 프로세스의 대기 종료 및 생성, 우선 순위의 변화 등)로 스케줄링이 필요하다는 플래그(current->need_resched)가 설정된 경우,
인터럽트의 처리 및 시스템 호출 완료 직후 사용자 모드로의 복귀 이전에 스케줄러가 수행되며 이 때 우선 순위가 현재 프로세스 보다 높은 프로세스가 있으면 비자발적 문맥 교환(involuntary context switch)이 일어난다. 현 프로세스의 타임 슬라이스가 다 소진된 경우도 클럭 인터럽트 처리 과정에서 이러한 사실을 알게 되고, 이때에도 인터럽트 처리를 마치고 사용자 모드로 복귀하는 과정에서 문맥 교환이 발생한다.
단 문맥 교환 발생 시점에 관한 중요한 사실은 인터럽트 처리는 반드시 단기간에 완료하여야 하므로 인터럽트의 처리 도중에는 문맥 교환이 있을 수 없다는 사실과 문맥 교환은 반드시 커널 모드 수행 시에 이루어지므로 프로세스는 반드시 커널 안에서 수행이 중지되고 커널 안에서 다시 수행이 속개된다는 점이다.
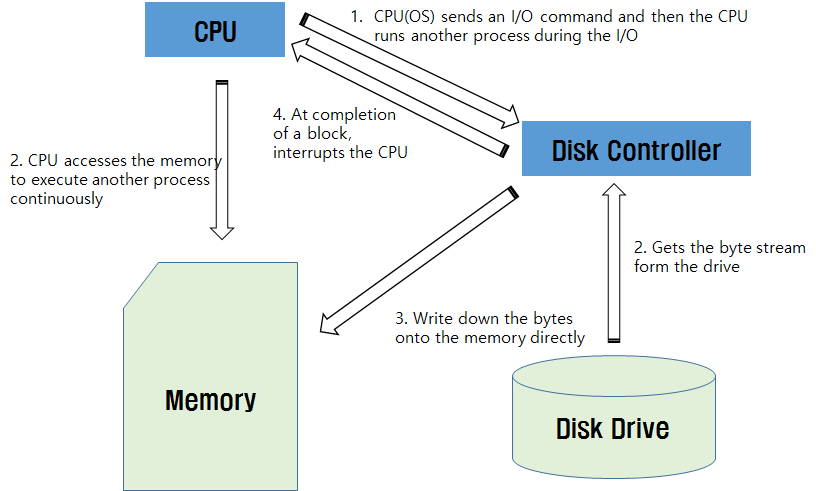
<그림 Disk DMA I/O>
4) Timer 인터럽트 처리 루틴
모든 운영체제는 일정한 시간 간격(1 millli-sec, 10)으로 인터럽트를 발생 시키는 타이머를 가진다.
타이머 인터럽트는 정상적인 경우에 가장 우선 순위가 높은 인터럽트이다. 타이머 인터럽트가 발생하면 하던 작업(커널 작업이나 프로세스 실행)을 즉시 중지하고, 커널 내의 인터럽트 처리기(Interrput handler)로 분기하여 여러 가지 작업을 수행한다.
① 부팅 이후로부터의 시스템 시간 업데이트(jiffies ++)
② 주기적 커널 함수 작업 호출
③ 현재 실행 중인 프로세스의 잔여 타임 슬라이스 감축, 잔여 타임 슬라이스가 0이 된 경우 다른 프로세스를
스케줄링하여 하므로, 인터럽트 처리가 끝난 후 재스케줄링 할 수 있도록 PCB 내의 need_resched
플래그를 1로 설정한다.
④ sleep이나 alarm을 설정한 프로세스에 대한 서비스 수행
⑤ 비사용 메모리가 부족할 경우 커널의 swapper 프로세스를 깨워(ready), swapper가 후에 스케줄링을
받으면 메모리를 비우는 작업을 수행토록 한다.
⑥ return_from_interrput 수행
* Clock interrput hanlder Update the system time; Call timeout functions (every n ticks) Wakeup blocked processes in time queue; (processes called sleep etc.) Wakeup kernel processes if free memory size is under the threshold (wakeup Swapper kernel process and Swapout pages)
current _PCB.time_slice_left --; if(time_slice_left == 0) currentPCB.need_resched = 1; Re-compute user mode priorty; and do something; Return from Interrput ( == Ret from syscall)
if(currentPCB.need_resched) { currentPCB.state = ready; Choose the process with the highest priority from the Scheduling Queue; Do Context_Switch(...); } // this must be the last step of clock interrupt handler. |
Return_from_interrput 는 need_resched 플래그를 테스트하여 재스케줄링이 필요하면 가장 높은 우선 순위의 프로세스를 골라 현 프로세스와 문맥 교환을 수행한다. 이와 같은 문맥 교환은 인터럽트 처리 내에서 수행되어서는 안되고 반드시 인터럽트 처리가 종료된 후에 하여야 한다.
리눅스의 인터럽트는 인터럽트를 disable 시키고 신속히 단기간에 처리하는 fast interrput와
그 인터럽트 처리 과정이 길어 인터럽트 disalbe 모드에서 수행되는 인터럽트 처리 루틴(ISR: Interrput Service Routine)과 인터럽트 enable 모드에서 시스템 호출 함수가 종료된 뒤에 수행되는 bottom-half(or Soft IRQ)의 단계로 처리되는 slow interrput로 구분된다.
키보드 인터럽트는 fast interrupt의 대표적인 예이고, 디스크나 타이머 인터럽트는 처리 과정이 길어 ISR과 bottom-half로 나누어 처리되는 slow interrput이다.

<그림> 커널 내에서 문맥 교환이 일어나는 위치
3.4 프로세스의 생성과 소멸
리눅스 운영체제에서 프로세스의 생성과 소멸 관련 기본 시스템 호출은 다음과 같다.
FORK(2) #include <sys/types.h>man fork #include <unistd.h> pid_t fork(void); 입력 값 : 없음 반환 값 : - parent 프로세스 : child 프로세스의 PID - 에러 : -1 |
fork 시스템 호출은 실행 중인 프로세스가 자신과 같은 프로그램 내용을 가지는 새로운 프로세스를 생성할 때 사용된다. fork를 호출한 프로세스를 parent 프로세스라 하고, 새로 생성되는 프로세스를 child 프로세스라 한다. parent 프로세스의 fork 호출이 완료되면 fork에서의 반환(return)은 parent와 child process의 두 곳으로 이루어진다. Parent에게는 child의 프로세스 식별자가 반환되고 child에게는 0이 반환되어 자신이 parent인지 child인지를 구별하도록 한다.
새로 생성되는 child 프로세스의 data와 stack은 fork 시의 parent의 상태를 복사하지만, 별도의 공간에 할당되어 각각 다른 영역을 사용한다.

<그림> 커널과 프로세스의 주소 공간

<그림> fork에 의한 프로세스 생성 이후의 주소 공간
* Fork에 의한 프로세스의 생성과 협동 작업 #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> #include <stdio.h> int global_int = 5; int main() { pid_t pid; ... if((pid = fork()) == 0) { // child global_int = 6; printf(“child’s data = %d\n”, global_int); // 6 출력 exit(0); }else { // parent global_int = 7; } printf(“ parent’s data = %d\n”,global_int); // 6 출력 |
위의 예에서 fork 이후의 parent 와 child 프로세스는 커널에 의해 각각 다른 프로세스로 관리되는 것으로 각각 별도로 스케줄링을 받게 된다. 따라서 타임 슬라이스 만료나 입출력 요구에 의한 스케줄링으로 수시로 CPU가 각 프로세스에 할당되므로, 두 프로세스의 실행 부분 부분은 정해진 수선 없이 실행된다. 따라서 마치 두 프로세스가 동시에 수행되는 것처럼 보이고, 또한, 실제로 다중 CPU 시스템에서는 병렬로 동시에 실행될 수 있다. 이러한 프로그램을 병렬(concurrent) 프로그램이라 한다.
위의 예에서 전역 변수인 global_int는 초기값이 5인 상태에서 복사되지만, child는 별도의 데이터 공간을 갖기 때문에 fork 이후에 global_int는 실제로 두 개가 독립적으로 존재한다. 프로세스 fork 이후에 각 프로세스의 메모리 영역은 프로그램 코드 부분인 TEXT만 공유하고 나머지 부분은 독자적 공간을 갖게 된다.
3.4.1 프로세스의 종료와 child 프로세스 종료 대기
위의 두 프로세스는 child 프로세스의 종료/소멸 시점을 기준으로 다시 하나의 수행 흐름으로 합쳐지는 동기화가 수행될 수 있다.
프로세스의 종료를 위한 시스템 호출 exit는 다음과 같다.
_EXIT(2) #include <stdlib.h> void exit(int status); 입력 값 - status : 반환되는 상태 값 반환 값 : 없음 |
exit는 프로세스의 종료와 함께 프로세스의 사용자 메모리 영역을 해제하며, wait 시스템 호출을 통해 child 프로세스의 종료를 기다리는 parent 프로세스를 깨워주는 역할을 한다.
이 때 exit의 입력 변수는 wait 시스템 호출의 매개 변수로 반환 된다.
parent 프로세스가 child 프로세스의 종료를 기다리는 동기화 도구로 사용하는 wait 시스템 호출은 다음.
WAIT(2) #include <sys/types.h> #include <sys/wait.h> pid_t wait(int *stat_loc); 입력 값 - stat_loc : child 프로세스의 상태 정보를 받기 위한 버퍼 반환 값 - 정상 : 하위 프로세스 식별자 - 에러 : -1 |
이러한 wait 시스템 호출은 parent 프로세스가 병행으로 어떤 작업을 시킨 child 프로세스의 종료를 기다리는 경우에 사용한다. wait과 exit은 병행으로 실행되는 두 프로세스에 의해 호출되므로 어떤 것이 먼저 일어나는지 알 수 없으며 wait보다 exit이 먼저 일어난 경우, wait에 의한 동기화까지의 child의 상태를 zombie 상태라고 하며, zombie 상태의 child는 parent의 wait에 의해 태스크 구조체가 시스템에서 완전 소멸된다.
* fork와 wait, exit의 활용 예 if( fork() == 0 ) { // child ..... if( fork () === 0 ) { // child of child .... exit(0); } .... wait(); // death of grand-son ... exit(0); } ... // parent wait(); // death of child if( fork() == 0 ) { // child .... // A part exit(0); } if( fork() == 0 ) { // child sibling .... // B part exit(0); } |
3.4.2 child 프로세스의 상속
fork된 child 프로세스는 parent 프로세스의 변수값 들을 상속하고, 그 외에도 여러 가지 상태나 사용 자원, 스케줄링 정보 등을 상속 받게 된다.
> open된 파일의 상속에 대해서 설명
fork된 child는 parent가 fork 이전에 open한 파일을 그 상태 그대로 상속하는데, open된 file descriptor id와 각 파일의 내재적 접근 위치(read/write offset)도 상속하고 공유하게 된다. read/write offset을 공유하므로 parent와 child가 같은 파일에 입출력하게 되면 서로에게 영향을 미치게 된다.
* Parent와 Child의 파일 공유의 예 #include <sys/types.h> #inlcude <sys/wait.h> #include <unistd.h> #include <fcntl.h> #include <stdio.h> int main() { int old_fd, new_fd, n; char buf; old_fd = open(“input_file”,O_RDONLY); // read-only mode new_fd = open(“output_file”,O_WRONLY | O_CREAT,0666); // write-only , file creation fork(); while((n = read(old_fd, &buf, 1)) != 0) write(new_fd,&buf,n);
close(old_fd); close(new_fd); |
위의 프로그램은 새로 만든 output_file에 input_file의 내용을 1 byte 씩 모두 복사하는 프로그램이다.
파일을 open하고 crate 한 후, fork를 실행하므로 open된 파일의 상속에 의해 parent와 child는 각각 두 파일을 사용할 수 있다.
이 때, 두 프로세스는 read/write offset을 공유하므로 파일의 크기는 두 배가 되지 않으며 원래의 크기대로 복사가 수행된다. 단 여기서 주의할 점은 병행 프로그램의 특성상, parent가 read를 실행하고 write를 실행하기 이전에 스케줄링이 발생하여 child가 실행되고, child의 read와 write후에 parent의 write가 실행될 수 있다는 점이다.
이런 시나리오로 병행 프로그램이 실행되면 복사된 파일의 크기는 같지만 출력 파일의 순서가 원래의 입력 파일의 순서에서 바뀔 수 있다는 점이다.
따라서 위의 병행 프로그램은 복사 순서에 무관한 경우는 올바르지만, 순서까지 유지해야 하는 복사의 경우에는 잘못된 프로그램이다. 이러한 문제를 임계 구역(critical section) 문제라 하는데, 이의 해결책으로
상호배제(mutual exclusion) 도구들이 운영체제에 의해 제공됨.
3.5 프로세스의 프로그램 교체(로딩)을 위한 시스템호출 exec 그룹
실행 중인 프로세스가 exec 시스템 호출 그룹 중 하나를 호출하게 되면, 실행 중인 프로세스의 text, data, stack 영역 등은 지정된 실행 파일의 내용으로 적재되어 새로운 프로그램이 실행된다. 프로세스의 몸체는 새로운 실행 파일의 내용으로 교체되지만, 프로세스 id, parent-child 관계, open 하였던 파일 등 여러 프로세스의 환경은 그대로 유지된다. exec 시스템 호출 그룹은 execl, execle, execv, execve, execlp, execvp 등, 인수가 약간 씩 다른 여러 개의 호출로 구성된다.
EXECVE #include <unistd.h> int execve(const char *path, const char *argv[], char const *envp[]); 입력값 - path : 프로그램의 경로명 - argv : 프로그램의 인수들에 대한 포인터 - envp : 환경 변수로의 포인터 반환값 - 정상 : 없음 - 에러 : -1 |
exec 계열의 시스템 호출은 새로운 프로그램을 적재(load)하고 적재된 프로그램의 main 함수를 실행하는 것이므로 정상적인 경우에는 return 되지 않는다. 단 지정한 실행 파일이 없거나 실행 불가능한 경우에는 error return 하게 된다.
* fork와 exec 시스템 호출의 사용한 소규모 쉘의 예 #include <sys/types.h> #include <sys/wait.h> #include <unistd.h> #include <stdlib.h> /* exit() */ #include <string.h> /* strlen() */ #include <stdio.h> #define PROMPT “$>” #define LINE_LENGTH 80 int main(void) { char buffer[LINE_LENGTH]; pid_t pid; int c, count = 0; int background = 0; for(;;) { printf(PROMPT); count = 0; while(1) { exit(0); // normal exit if( count < LINE_LENGTH) buffer[count++] = c; if( c == ‘\n’ count < LINE_LENGTH) { buffer[count - 1] = 0; break; } if( count >= LINE_LENGTH) { printf(“input too long\n”); count = 0; printf(PROMPT); contiune; } } // end of while if(strlen(buffer) == 0 || (strlen(buffer) == 1 && buffer[strlen(buffer)-1] == ‘&’)) continue; // to for loop if( buffer[strlen(buffer)-1] == ‘&’) { background = 1; buffer[strlen(buffer)-1] = ‘\0’; } if( (pid = fork() ) < 0) { perror(“fork failed”); exit(1); }else if( pid == 0 ) { // child process execlp(buffer, buffer, (char *)0); perror(“exclp failed”); exit(1); } if( background = 1) continue; while( wait(&pid) 1= pid ) ; // wait for the exit of foregroud } // end of for } |
위의 프로그램은 간단한 쉘을 구성해 본 예제이다.
위 프로그램이 수행되면 사용자 화면에는 “$>”의 프롬프트(prompt)가 나타나고, 사용자는 자신이 실행시키고자 하는 프로그램을 입력하게 된다. parent 프로세스는 쉘과 같은 실행 형태로 child를 fork하고, fork 된 child는 입력으로 받은 프로그램을 execlp를 통하여 실행하게 된다. parent 프로세스는 fork와 exec를 통해 실행되는 child의 수행 완료를 waitpid를 통해 기다리고, child의 실행이 exit를 통해 완료되면 다시 프롬프트를 출력하여 다음 실행할 프로그램을 입력받는다.
단 사용자의 프로그램 이름 입력 시 “&” 기호를 붙이게 되면 이는 백 그라운드(background) 프로세스로 실행시키라는 의미로 parent는 child의 실행 완료를 기다리지 않고 바로 프롬프트를 출력하여 다음 프로그램명을 입력받는다. 백그라운드로 실행되는 프로세스가 언젠가 종료되면 지정된 포어그라운드(foregorund)를 기다리는 wait loop에 의해 zombie 상태에서 소멸된다.

<그림> exec 계열 시스템 호출 이전과 이후
'Linux' 카테고리의 다른 글
| 파일 시스템 (1) | 2015.12.19 |
|---|---|
| 리눅스 스케줄링 (0) | 2015.12.19 |
| 리눅스 활용을 위한 기본 지식 (0) | 2015.12.19 |
| Linux Overview (0) | 2015.12.19 |
| 01 서론 (0) | 2015.08.18 |