Machine Learning Introduction출처 : Coursera / Emily Fox & Carlos Guestrin / Machine Learning Specialization / University of Washington
Machine Learning with the tools IPython Notebook & GraphLab
Create
Machine Learning with the tools IPython Notebook & GraphLab Create on AWS
Machine Learning with the tools IPython Notebook Usage
Machine Learning with the tools IPython Notebook SFrame
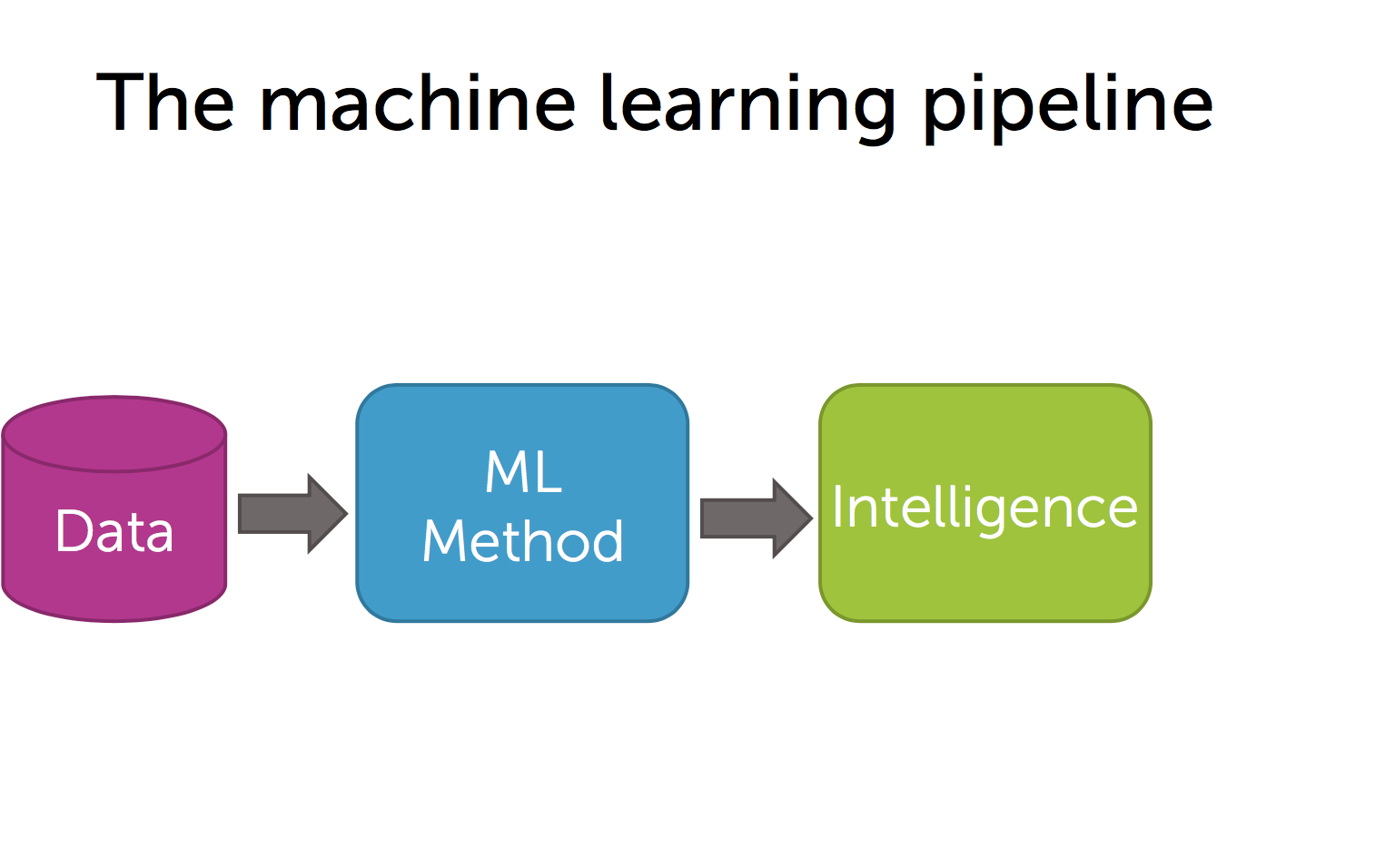
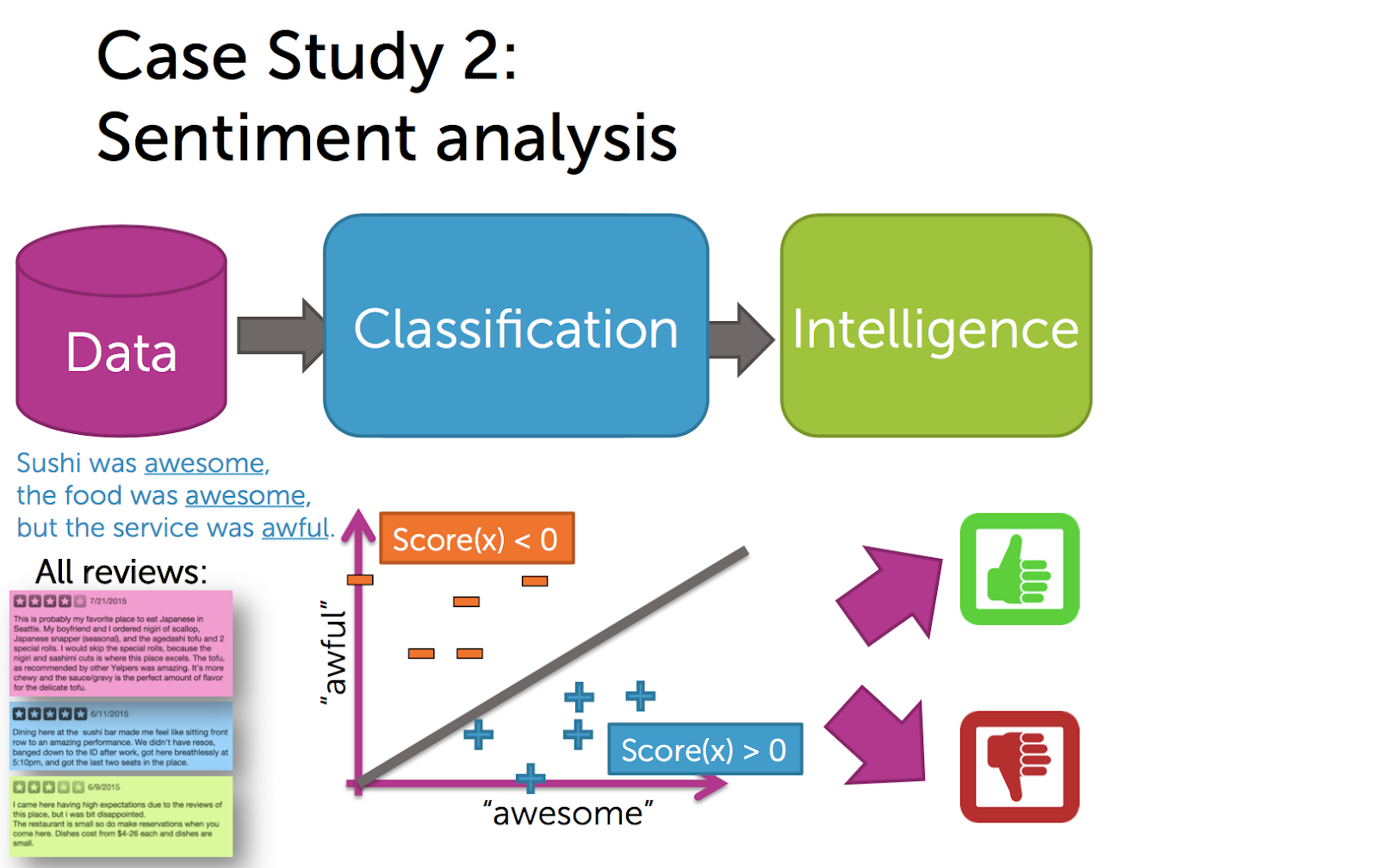
작은 데이터 세트나 데이터를 가지고, 뭔지 모를 기계학습 알고리즘에 넣어준 다음 내 곡선(그래프)가 다른 사람 곡선보다 낫다면서 Machine Learning 학회에 논문을 제출하곤 했습니다. 세계에 대해 고찰하고 사물에 대해 추론하는 지능형 애플리케이션(Intelligent Applications) 최근 들어 멋지고 흥분되는 일은 이런 지능형 애플리케이션의 영향력이 기계학습(machine learning)을 사용하여 날로 커지고 있다는 것입니다. 실제로 여러 산업 분야에서 성공을 이룬 회사를 살펴봅시다. 파괴적이라 불리는 회사를 보면 시장을 놓고 완전히 변화시킵니다. 지능형 애플리케이션으로 차별화하는 경우가 많은데, 바로 기계학습을 핵심으로 하는 것입니다. 예를 들어 아마존(Amazon)은 자사 웹사이트에 상품추천을 도입함으로써 유통업계를 초토화시켰습니다. 구글(Google)은 기계학습의 힘을 빌린 타겟팅 광고로 사람들이 뭘 클릭할지 알아내 광고 시장을 선점하였습니다. 영화 유통 회사인 넷플릭스(Netflix)는 영화 소비 방식을 바꿨습니다. 웹으로 가서 스트리밍으로 보고 추천 시스템을 통해 수 천 개의 영화 중 내가 좋아하는 영화가 무엇인지 찾아줍니다. 판도라(Pandora) 같은 회사를 보면 음악 추천 시스템으로 내가 좋아하는 음악을 찾아줍니다. 페이스북(Facebook)은 나와 친구가 될만한 사람을 연결해 줍니다. 우버(Uber)는 운전자와 승객 사이의 실시간(real time) 연결을 최적화함으로써 택시 업계를 선점하고 있습니다. 이 모든 분야에서 기계 학습은 핵심 기술이며, 이 회사들의 상품을 특별하게 만들어 줍니다. 이 특화 과정에서 기계 학습을 여러 측면에서 살펴보고, 지능형 애플리케이션(Intelligent application)을 만들 수 있도록 도와줍니다. 다음의 파이프 라인을 계속 보게 될텐데, 데이터에서 시작해서 데이터에 대한 새로운 분석을 가능하게 하는 기계 학습법을 도입합니다. 이런 분석은 지능을 가져다 줍니다. 예를 들어, 지금 어떤 상품을 구매할 지 알아내는 지능인 것입니다. 이제 이 파이프 라인을 가지고 다양한 설정과 다양한 응용, 여러 알고리즘을 거치면서 서로 어떻게 연결되는지 이해하면 당신만의 똑똑한 지능형 애플리케이션을 만들 수 있습니다. 첫 번째 사례 연구에서 우리는 주택 가치를 예측할 것입니다. 따라서 우리가 파생하는 Intelligence는 시장에 없는 집과 관련된 가치입니다. 그래서, 우리는 가치가 무엇인지 알지 못하므로, 데이터에서 배우게 됩니다. 우리의 데이터는 무엇일까요? 이 경우에는 다른 주택을 살펴보고 집 판매 가격을보고 관심있는 주택의 집값을 알려줍니다. 판매 가격 외에 다른 특징(feature)을 살펴볼 것입니다. 집에 얼마나 많은 침실이 있는지. 욕실, 평방 피트 수 등 입니다. 그리고 우리가 할 일은 기계 학습 방법입니다. 집 속성을 판매 가격과 관련시킬 것입니다. 왜냐하면 우리가 이 모델을 우리의 집 수준의 특징과 관측 된 판매 가격과의 관계로 배울 수 있으며, 새로운 주택에 대한 예측을 위해 사용할 수 있기 때문입니다. 우리는 집 속성을 가져 와서 집 판매 가격을 예측합니다. 그리고이 방법을 회귀(regression)라고 합니다. 두 번째 사례 연구에서는 일부 레스토랑에 대한 리뷰가 있는 정서 분석 작업을 탐구합니다. 예를 들어,이 경우에는 “스시가 굉장했다. 음식은 훌륭했지만, 서비스는 끔찍했다.” 우리는 이 리뷰를 듣고 그것이 긍정적인 정서를 가지고 있는지를 분류 할 수 있어야 합니다. 그것은 좋은 리뷰, 엄지 손가락 또는 부정적인 감정, 엄지 손가락으로 표현합니다. 우리는 다른 많은 리뷰를 살펴볼 것입니다. 이 정서 분류를 위한 관계를 이해하기 위해서 검토하려는 텍스트와 검토 등급을 살펴 봅니다. 예를 들어,이 경우에는 아마도 awesome이라는 단어를 사용하는 횟수와 awful이라는 단어를 사용하는 횟수를 기준으로 이 리뷰의 텍스트를 분석 할 수 있습니다. 그리고 우리가 가지고 있는 다른 리뷰에서, 우리는 긍정적이거나 부정적인지 여부에 관계없이 이 단어의 사용법의 균형에 근거한 결정 경계(decision boundary)를 배울 것입니다. 그리고 우리가 다른 리뷰에서 배운 방식은 텍스트와 관련된 등급(ratings)에 기반합니다. 따라서 이 방법을 분류 방법(classification method)라고 합니다. 세 번째 사례 연구에서 우리는 문서 검색(Document Retrieval) 작업을 할 것입니다. 여기서 우리가 원하는 것은, 우리가 파생하는 Intelligence는 독자가 관심을 갖는 기사(article)나 책(book) 등입니다. 그리고 우리가 가지고 있는 데이터는 우리가 추천 할 수 있는 가능한 기사의 거대한 모음이다. 이 경우, 우리가 할 일은 관련 기사 그룹을 기반으로 이 데이터에서 구조를 찾아내는 것 입니다. 예를 들어, 스포츠 및 세계 뉴스와 엔터테인먼트 및 과학에 대한 기사 모음이 있을 수 있습니다. 그리고 우리가 이 구조를 찾고 우리가 사전에 가지고 있지 않은 유형의 레이블을 가진 문서 모음에 주석단다면, 우리는 이것을 데이터로부터 추론(infer)하려고 합니다. 매우 빠른 문서 검색을 위해 이 도구를 사용할 수 있습니다. 왜냐하면 세계 뉴스에 대한 기사를 읽고 다른 기사를 검색하고 싶다면 이미 검색해야 할 기사를 알고 있기 때문입니다. 우리는 이것을 클러스터링(Clustering)이라고 부릅니다. 네 번째 사례 연구에서는, 지난 10 년 동안 많은 영역에서 많은 영향을 받은 협업 필터링(collaborative filtering)이라는 매우 흥미로운 작업을 할 것입니다. 특히, 우리는 제품(product)을 추천(recommendation)하기 위해, 과거의 구매 이력(purchase history)를 가져와 당신이 구매할 다른 제품을 추천하기 위해 노력합니다. 따라서, 이 경우 제품 추천을 위한 Intelligence 를 유도하기 위해, 사용할 데이터는 이전에 구입한 제품과 앞으로 구매할 제품과의 관계(relationship)를 이해해야 합니다. 이렇게 하려면 다른 사용자의 구매 내역(purchase history)을 사용합니다. 여기서 핵심 아이디어는 이 데이터를 가져와 그림 속의 사각형(square)처럼 고객이 실제로 구입한 제품을 나타내는 고객(customers) 별 제품(product) 매트릭스(matrix)로 정렬하는 것입니다. 이것은 그 고객이 실제로 좋아하는 제품입니다. 이 매트릭스(matrix)를 통해 제품에 대한 특징(feature)과 사용자(user)의 특징을 배우게 됩니다. 그리고 내가 설명한 이 데이터에서 사용자와 제품에 대한 특징을 배우게 됩니다. 우리는 이러한 특징을 사용하여 사용자가 좋아하는 것, 사용자가 좋아하는 여러 가지 속성 및 제품이 실제로 이러한 특성에 관한 것인지 얼마나 많은 합의가 이루어 졌는지 확인할 수 있습니다. 따라서 여기에 표시되는 예에서는 사용자가 엄마 일 수 있지만 엄마인 다른 사용자와 비슷한 특정 특징이 있습니다. 그리고 그로부터 우리는 제품에 대해 추론 할 수 있습니다. 예를 들어, 엄마인 경우, 관심있는 아기 용품을 추천할 수 있습니다. 그리고 우리는 이 정보를 사용하여 추천(recommendation)을 구성합니다. 그리고 이 매트릭스(matrix)에서 시작되는 이러한 유형의 접근 방식은 고객 및 제품에 대한 학습된 특징(feature)에 대한 고객 제품 매트릭스를 매트릭스 분해(matrix factorization)라고 한다. 마지막 사례 연구에서 시각적 제품 추천자(Visual product) recommender)를 살펴 보겠습니다. 그래서 여기에, 우리의 데이터는 누군가가 웹으로 가서 텍스트가 아닌 이미지를 입력 합니다. 그들은 검은 색 신발, 검은 색 부츠, 하이힐, 또는 신발을 신는 것과 같은 이미지를 넣을 것입니다. 그리고 그들이 원하는 것은 그들이 관심을 가질만한 일련의 신발 결과를 원한다는 것입니다. 따라서 신발은 시각적으로 사진과 유사합니다. 그리고 그들은이 아이템을 구매할 사람들을 검색 할 수 있기를 원합니다. 이미지에서 일련의 관련 이미지로 이동할 수있게하려면이 이미지와 유사한 다른 이미지를 찾기 위해 이미지에 대해 아주 좋은 특징(feature)이 있어야합니다. 그리고 우리가 그 세부적인 특징(feature)들을 파생시키는 방식은 심층 학습(Deep Learning)이라고 불리는 것입니다. 특히 우리는 신경 네트워크(Neural Network)의 모든 레이어(layer)가 점점 더 많은 설명 기능을 제공하는 신경 네트워크를 살펴볼 것입니다. 그래서 여기서 보여주는 작은 예제에서 첫 번째 레이어는 이미지에서 다른 가장자리(edge) 같은 것을 감지 할 수 있습니다. 하나는 두 번째 레이어로 이동하지만 모서리(corner))와 더 묘사적인 특징(feature)을 감지하기 시작합니다. 이 레이어에서 더 깊고 깊어지면 더 복잡한 특징(feature)이 생깁니다. 보시다시피, 우리는 일련의 실제 사례 연구, 현실 세계의 문제 및 기계 학습을 사용한 실제 솔루션을 살펴볼 것입니다. 그리고 이를 통해 우리는 많은 권력을 가진 일련의 방법을 탐구 할 것입니다. 그리고 우리가 사용한 정확한 사례 연구가 아닌 새로운 문제에 대한 새로운 기계 학습 기술을 개발하고 배포 할 수 있게 할 것입니다. 우리는 기계 학습을 가르치기 위한이 use-case 접근법을 개척했습니다. 그리고 그 과정에서 우리는 개념을 이해하는 사람들로부터 많은 긍정적인 피드백을 보았습니다. 따라서 우리는 첫 번째 코스의 유스 케이스부터 시작할 것입니다. 또한 use-case로 시작하여 핵심 개념과 기술을 구축하고, 품질(quality)을 측정하고, 지능형 애플리케이션이 잘 작동하는지 여부를 이해할 수있는 기술을 실제로 파악할 수 있습니다. 그리고 결국에는 지능형 응용 프로그램을 만들 계획입니다. 따라서 지능적인 애플리케이션을 구축하려면 일반적으로 어떤 작업을 해야 하는지 생각해야 합니다. 정서 분석(Sentiment analysis) 문제와 어떤 모델, 어떤 머신 학습(machine learning) 모델을 사용할 것인가, 그리고 벡터 머신(vector machine)이나 회귀(regression)를 지원하는 모델(model)의 파라미터(parameter)를 최적화(optimize)하기 위해 사용할 때 어떤 방법으로 풀어 낼 것인가? 그리고 이것이 정말로 내가 원하는 정보를 제공하는 것과 같은 질문을 던집니다. 해당 시스템의 품질을 어떻게 측정 할 수 있습니까? 따라서 이 전문 분야에서 우리가해야 할 일은 모델을 설명하고 코스에 따라 모델을 최적화하는 방법의 핵심 부분을 공부하는 것입니다. 그리고 이 첫 번째 과정은 우리가 해결하고자 하는 과제, 기계 학습 방법이 무엇인지, 그리고 이를 측정하는 방법을 파악하는 데 초점을 맞출 것입니다. 그리고 알고리즘을 블랙 박스로 사용함으로써 우리는 다양한 지능형 멋진 애플리케이션을 함께 구축 할 수있게 될 것입니다. 그리고 실제로 코드를 작성하고 빌드하고 다양한 방법으로 보여줍니다. . 다음 과정에서는 회귀 과정에서는 실제 가치를 예측하는 다양한 모델에 대해 이야기 할 것입니다. 예를 들어, 주택의 특징(feature)에서 얻은 집값. 그리고 우리는 선형 회귀(linear regression) 기술에 대해 논의 할 것이며, 우리는 능선 회귀(ridge regression)와 Lasso 같은 고급 기술을 토론하여 문제에 가장 적합한 특징(feature)을 선택할 수 있게 할 것입니다. 우리는 그라디언트 디센트(gradient descent)와 좌표 하강(coordinate descent)과 같은 최적화 기법에 대해 설명하고 이들 모델의 파라미터를 최적화 할 것입니다. Loss function, bias-variation 트레이드 오프(trade-off), 교차 검증(cross-validation)과 같은 핵심 기계 학습 개념 뿐 아니라, 실제로 이 방법을 사용하고 종류를 개선하고 개발하고 응용 프로그램을 빌드하는 데 필요한 사항을 학습할 것이다. 다음 과정인 분류(classficiation)에서는 우리는 분류감정 분석 유스 케이스를 빌드할 것이다. 선형 분류기(linear classifier)부터 선형 회귀(linear regression), 로지스틱 회귀(logistic regression), 서포트 벡터 머신(SVM)과 같은 고급 기능에 이르기까지 다양합니다. 그러나 커널(Kernel) 의사 결정 트리(decision tree)를 추가하면 비선형 복잡한 특징(non-linear feature)을 처리 할 수 있습니다. 우리는 이러한 기술을 대규모로 처리하고 최적화(optimization)하는 방법에 대해 이야기할 것이며, 이들을 조합하는(ensemble) 부스팅(boosting)을 공부할 것입니다. 이러한 머신러닝(machine learning)의 기본 개념으로 분류기(classifier)를 만들고 확장하며, 다른 방법(method)에 적용할 수 있습니다. 다음 과정에서는 클러스터링(Clustering) 및 검색(Retrieval)을 배울 것이며, 특히 문서의 문맥(context)에 초점을 맞출 것입니다. 그래서 우리는 Nearest Neighbors 기술 뿐만 아니라, 고급 클러스터링(clustering) 기술과 mixture of Gaussians, Latent Dirichlet Allocation(LDA)으로 텍스트 분석 클러스터링 기술을 사용할 수 있습니다. 우리는 이러한 것들을 뒷받침하는 알고리즘인 KD-Trees와 샘플림(Sampling) 그리고 기대 최대화(Expectation maximization)의 기술로 확장하는 방법을 이야기 할 것입니다. 이제 핵심 개념은 실제로 이러한 것들의 규모(scale)를 조정하고, 품질(Quality)를 측정하고, 실제 Hadoop 시스템을 이용한 map-reduce 분산 알고리즘 기술을 이용합니다. 네 번째 과정에서는 실제로 분산 머신 리닝인 map-reduce 코드를 작성할 것입니다. 이제 최종 과정에서는 널리 적용할 수 있는 행렬 인수 분해(Matrix Factorization) 및 차원 축소(Dimensionality Reduction) 기술에 초점을 맞출 것입니다. 특히 추천 시스템(recommendation)에 제품 추천을 위한 기술로 초점을 둡니다. 따라서 우리는 협업 필터링(collaborative filtering), matrix factorization, PCA 기술을 공부합니다. 좌표 하강(Coordinate descent), 고유 분해(Eigen decomposition), SVD와 같은 최적화 기술을 공부합니다. 이를 추천자의 도메인에서 다양한 추천을 선택하는 방법과 큰 문제로 확장하는 법을 학습합니다. 캡스톤에서는 recommenders와 text와 image data, 감정 분석(sentiment), 딥러닝(deep learning)을 사용해 볼 것입니다.Machine learning is changing the world.
Old View of ML
Intelligent Application in the industry
The machine learning pipeline
Case Study 1 : Predicting house prices
Case Study 2 : Sentiment analysis
Case Study 3 : Document retrieval
Case Study 4 : Product recommendation
Case Study 5 : Visual product recommender
Specialization overview
First course
Second Course : Regression
Third Course : Classification
Fourth Course : Clustering & Retrival
Fifth Course : Matrix Factorization & Dimensionality Reduction
Sixth Course : Capstone














'MachineLearning' 카테고리의 다른 글
| Machine Learning with the tools IPython Notebook Usage (0) | 2017.02.04 |
|---|---|
| Machine Learning with the tools IPython Notebook & GraphLab Create on AWS (0) | 2017.02.04 |
| Machine Learning with the tools IPython Notebook & GraphLab Create (0) | 2017.02.02 |
| ML 기계학습 - 지도학습 (0) | 2016.12.26 |
| ML 기계학습의 정의와 분류 (0) | 2016.12.26 |