MongoDB using Google Cloud Platform

MongoDB
대표적인 문서 데이터베이스
JSON 문서로 작업

많은 인덱스를 통해 고성능 지원
고 가용성 - 복제 + 최종 일관성(consistency) + 자동 장애 조치(failover)
자동 확장(scaling) - 클러스터 전체에 자동 sharding 지원
각 JSON 문서는 컬렉션(Collection)에 속하며 _id라는 필드(filed)를 가지고 있습니다.
컬렉션 내에서는 _id는 고유해야 합니다.
각 컬렉션은 데이터베이스(database)에 속합니다.

기존의 RDBMS와 MongoDB의 차이점입니다.

문서(Documents)는 그룹화된 정보의 논리적 집합입니다.
JSON에서 객체는 문서 단위가 될 수 있습니다.
컬렉션(collection)
- 문서 그룹입니다.
- 관계형 데이터베이스의 테이블(table)과 동일합니다.
데이터베이스(Database)
- MongoDB는 데이터베이스에 컬렉션을 그룹화합니다.
- 데이터베이스에는 자체 권한이 있으며, 각 데이터베이스는 별도의 파일에 저장됩니다.
_id 필드
- 기본 키로 사용됩니다.
- 컬렉션 내에서 고유해야 하며, 변경 불가능합니다.
- 자동으로 생성 가능합니다.
유연한 스키마(flexible schema)
- 동일한 컬렉션 내의 문서가 특정 구조를 갖도록 강요하지 않습니다.
- 실제로 컬렉션의 문서는 비슷합니다.
Google Cloud Platform을 이용한 Mongo DB Docker 실습
Google Cloud Platform
1. 로그인을 진행합니다.

2. 회원가입을 진행합니다.

3. http://console.cloud.google.com/ 이동하여 “무료 평가판 신청" 버튼을 클릭합니다.

4. 대한민국을 선택하고 동의 및 계속하기 버튼을 클릭합니다.
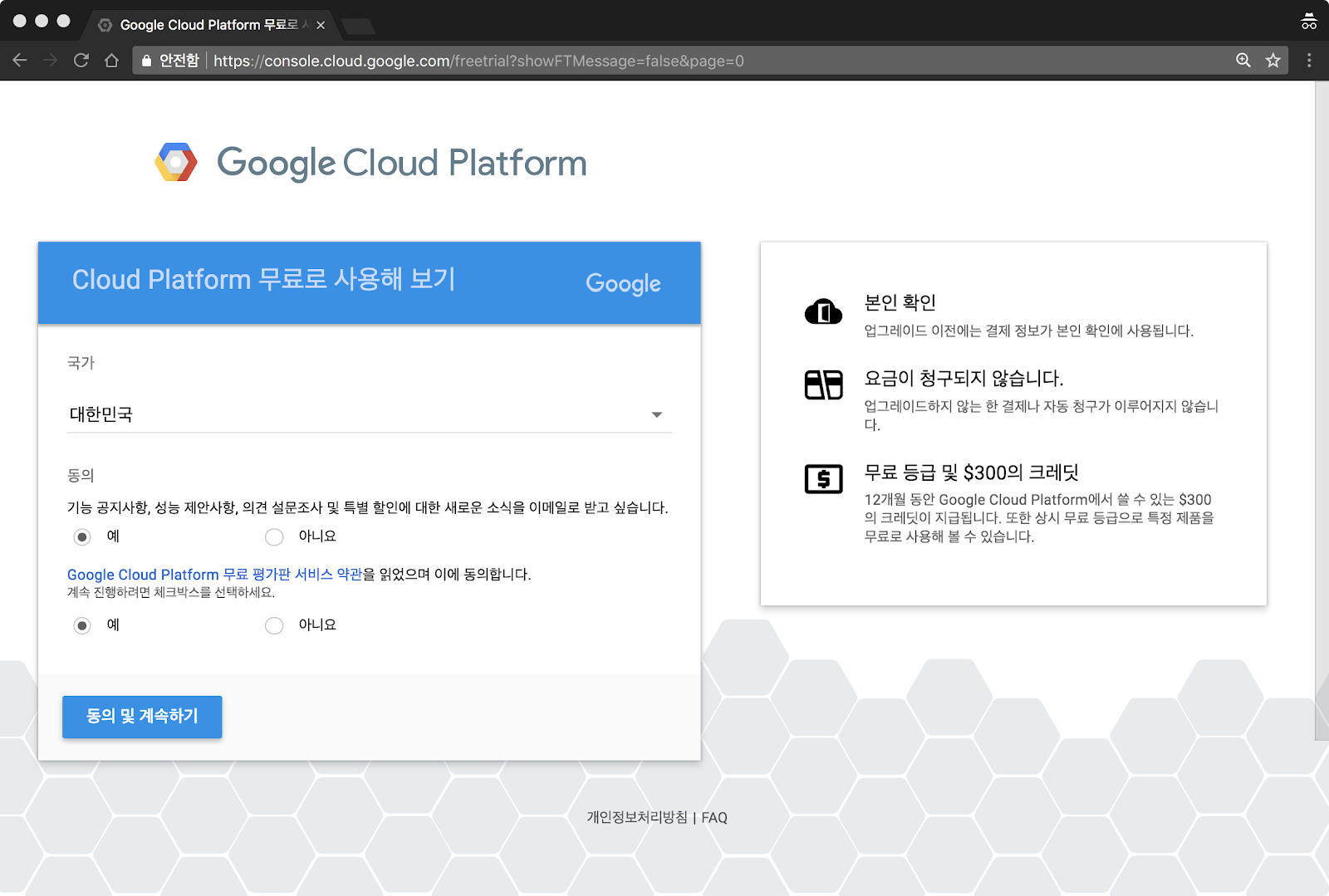
5. 주소와 카드 정보를 입력합니다. 무료 평가판 시작하기 버튼을 클릭합니다.

6. 프로젝트를 생성하기 시작합니다.

7. $300 크레딧을 받았습니다.

8. My First Project를 클릭하면 프로젝트 관리를 할 수 있습니다.

9. 실습을 시작할 준비가 완료되었습니다.

MongoDB Container 시작하기
1. Cloud Shell 버튼을 클릭합니다.

2. “START CLOUD SHELL” 버튼을 클릭하면 Cloud shell을 사용할 VM을 프로비저닝 합니다.

Cloud shell에서 VM에 5GB 영구 홈 디렉터리가 할당됩니다.
"gcloud"는 Google Cloud Platform 용 통합 명령 줄 도구이며 CloudShell에 사전 설치되어 있습니다.
$ gcloud auth list : 로그인 한 계정 정보보기
$ gcloud 설정 목록 프로젝트 : 현재 프로젝트
공식 MongoDB 이미지로 도커를 사용하여 MongoDB 컨테이너 만들기
- MONGO_INITDB_ROOT_USERNAME = mongoadmin
- MONGO_INITDB_ROOT_PASSWORD = secret
이 사용자는 관리자 인증 데이터베이스에서 생성되며 root 역할을합니다.
$ docker run -d --name mongodb -e MONGO_INITDB_ROOT_USERNAME=mongoadmin -e MONGO_INITDB_ROOT_PASSWORD=secret mongo

컨테이너를 생성 한 후, mongoadmin (루트 사용자)으로 컨테이너에서 MongoDB를 실행하는 명령으로 mongodb 컨테이너에 액세스 할 수 있습니다.
$ docker exec -it mongodb mongo -u mongoadmin -psecret --authenticationDatabase admin
// MongoDB 데이터베이스에 대해 인증 할 사용자 이름 (mongoadmin)을 지정합니다. - admin 데이터베이스는 인증 정보를 포함합니다.

MongoDB 실습
Create Operation
Create 또는 Insert 연산으로 collection에 새로운 문서를 추가합니다.
collection이 존재하지 않으면 Insert 연산으로 collection을 생성합니다.
> db.$(collectionName).insertOne()
> db.$(collectionName).insertMany()

문서가 _id 필드를 지정하지 않으면 MongoDB ObjectId 값과 함께 _id 필드를 새 문서에 추가합니다.
컬렉션이 자동으로 생성됩니다.
> db.inventory.insertOne(
{ item: "journal", qty: 25, tags: ["blank", "red"], dim_cm: [ 16, 16 ], status: "A" }
)

컬렉션이 다른 스키마가 있는 여러 문서를 삽입할 수 있습니다.
> db.inventory.insertMany([
{ item: "notebook", qty: 50, tags: ["red", "blank"], dim_cm: [ 14, 21 ], status: "D" },
{ item: "paper", qty: 100, tags: ["red", "blank", "plain"], dim_cm: [ 14, 21 ], status: "A" },
{ item: "planner", qty: 75, tags: ["blank", "red"], dim_cm: [ 22.85, 30 ], status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
])

READ Operation
읽기 작업은 컬렉션에서 문서를 가져옵니다. 즉 문서 모음을 쿼리합니다.
> db.$(collectionName).find()
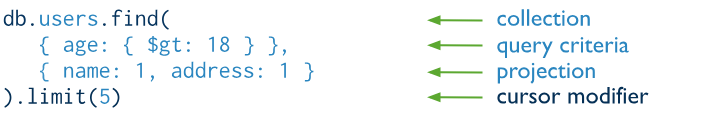
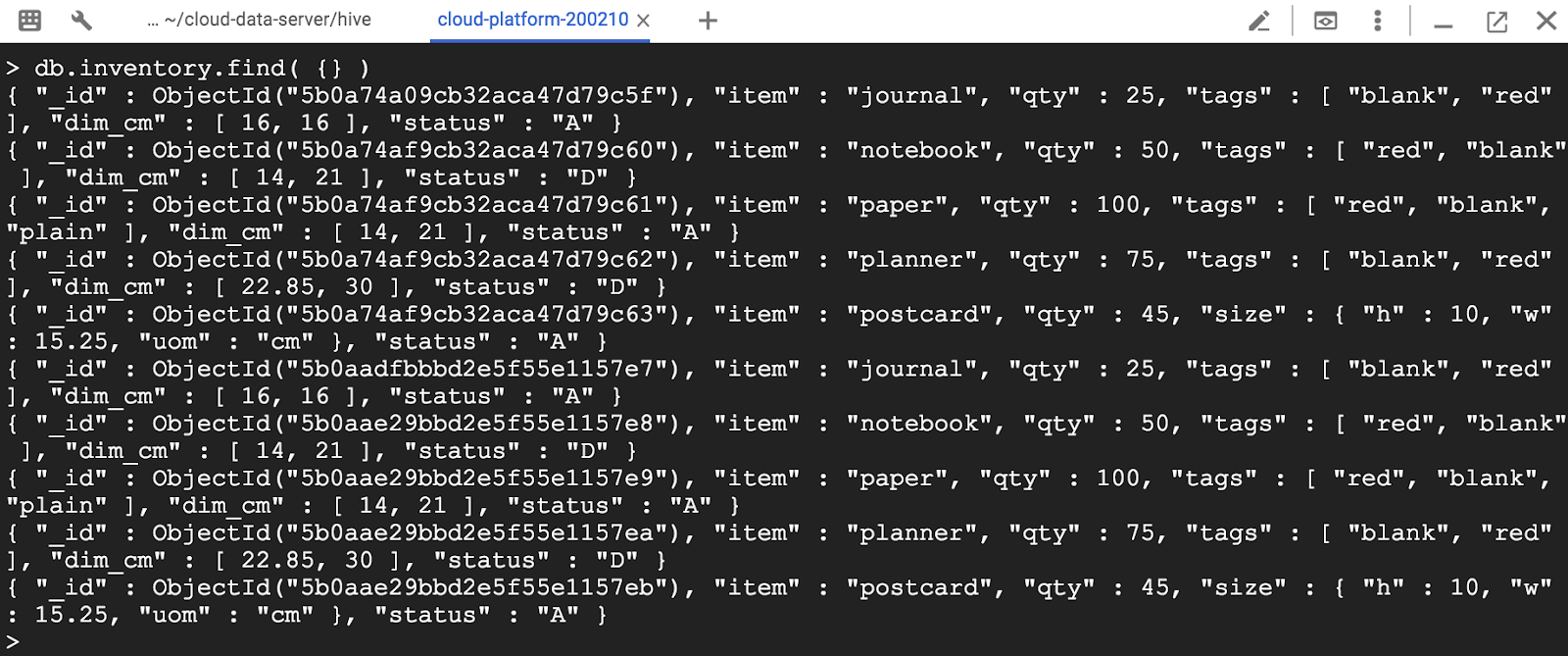
컬렉션의 모든 문서를 선택하려면 빈 문서를 쿼리 필터 매개 변수로 find 메서드에 전달합니다.
문서를 보면 삽입하지 않은 _id 필드를 볼 수 있습니다.
> db.inventory.find( {} )
다음 메서드는 컬렉션에서 문서를 읽을 수도 있지만 단일 문서를 읽습니다.
db. $ (collection) .findOne () 메서드는 db. $ (collection) .find () 메서드이며 제한은 1입니다.
따라서 db.inventory.find ({}) 결과의 첫 번째 문서 인 문서 하나만 보여줍니다.
> db.inventory.findOne( {} )
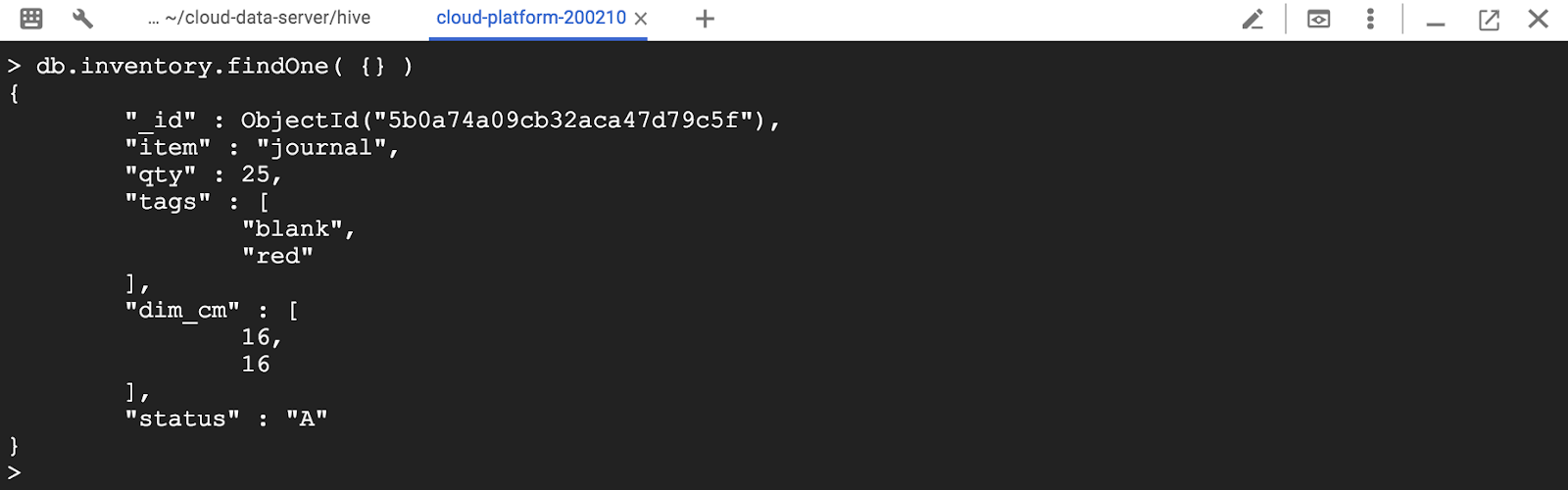
동일 조건을 지정하려면 쿼리 필터 문서에서 {<key> : <value>} 표현식을 사용하십시오.
다음 예는 상태가 "A"인 모든 문서를 인벤토리 모음에서 선택합니다.
> db.inventory.find( { status : "A" } )
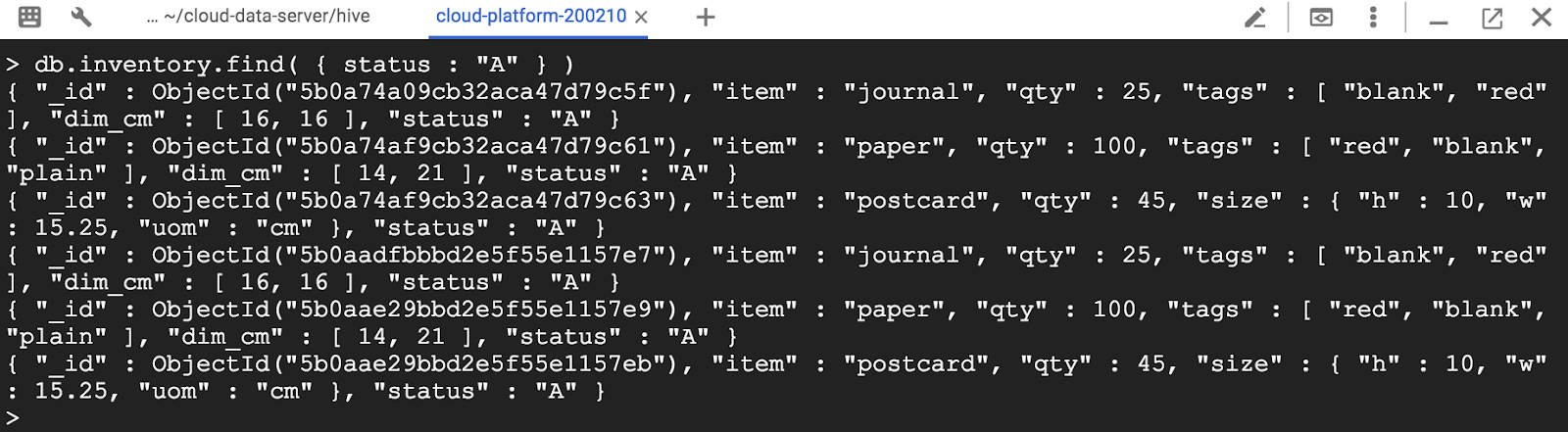
> db.inventory.findOne( { status : "A" } )

쿼리 조건 AND 연산
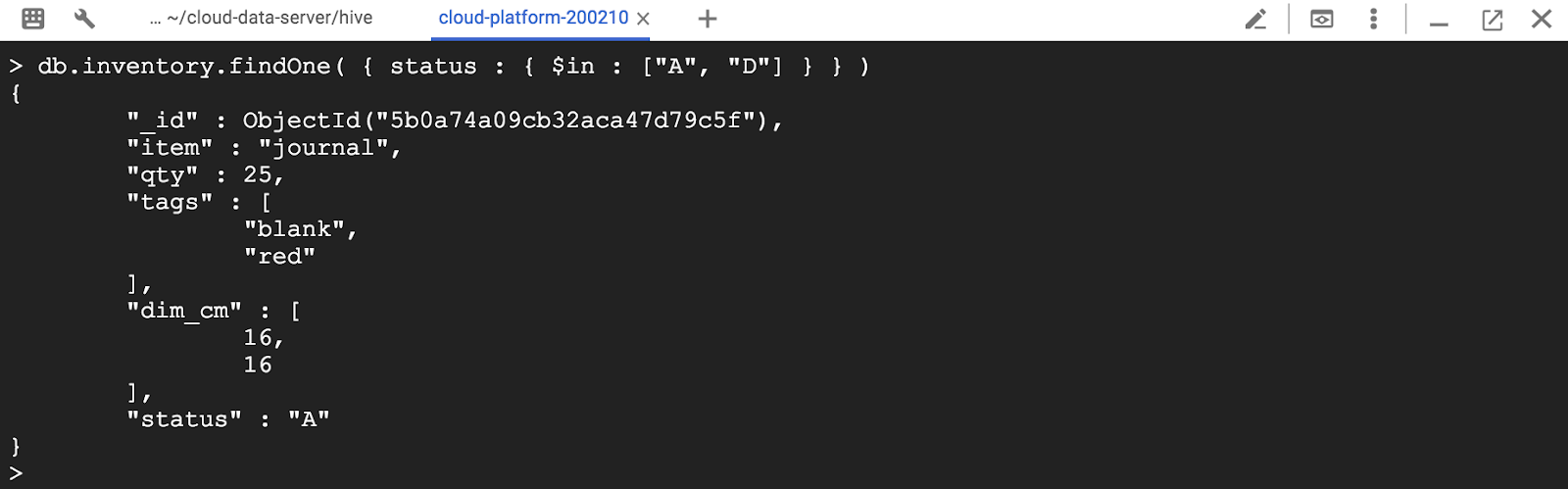
값 목록과 함께 $ in 상태를 지정하는 다음 예제는 상태가 "A"또는 "D"인 인벤토리 모음에서 모든 문서를 검색합니다.
> db.inventory.find( { status : { $in : ["A", "D"] } } )

> db.inventory.findOne( { status : { $in : ["A", "D"] } } )
> db.inventory.find( { status : "A", qty : { $lt : 30 } } )

복합 조회는 콜렉션의 문서에서 둘 이상의 필드에 대한 조건을 지정할 수 있습니다.
형식 : {key-1 : value-1, key-2 : value-2, ...}
다음 예제에서는 상태가 "A"이고 qty가 ($ lt) 30보다 작은 인벤토리 모음의 모든 문서를 검색합니다.
> db.inventory.find( { status : "A", qty : { $lt : 30 } } ).pretty()

쿼리 조건 OR 연산
$or : [조건 1, 조건 2, ...]을 지정하거나 조건을 지정하려면
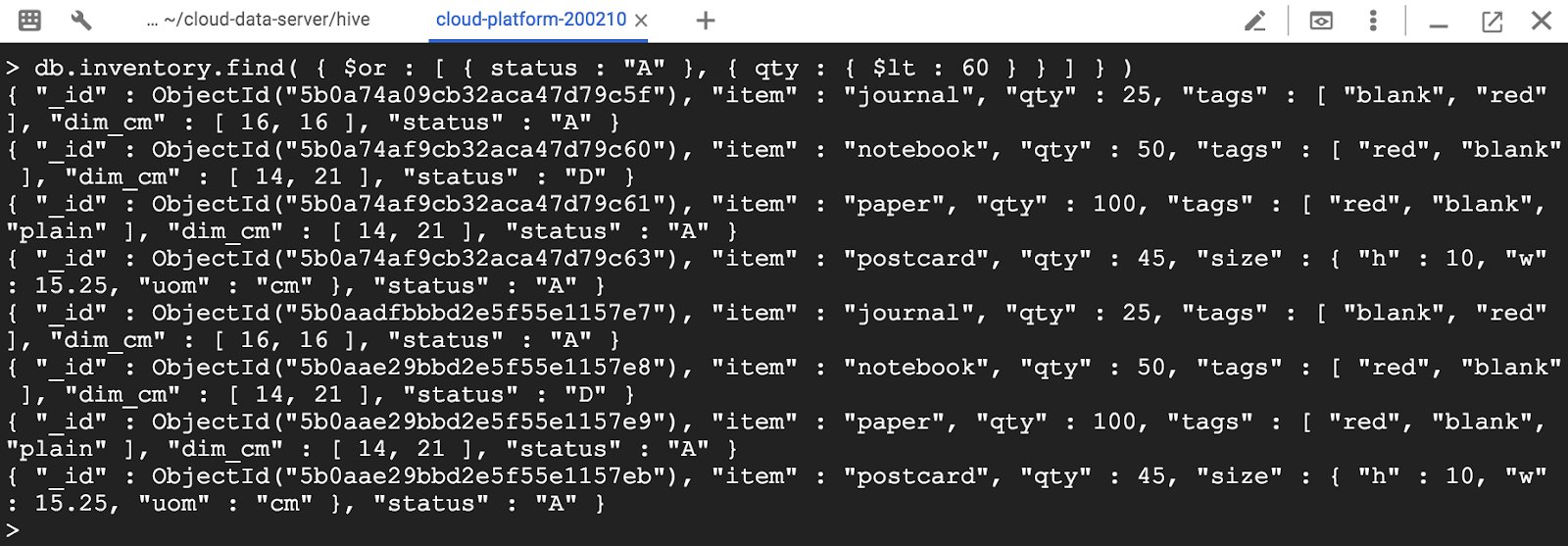
다음 예제에서는 상태가 "A"이거나, qty가 ($ lt) 60보다 작은 인벤토리 모음의 모든 문서를 검색합니다.
> db.inventory.find( { $or : [ { status : "A" }, { qty : { $lt : 60 } } ] } )
다음 예에서는 상태가 "A"이고 qty가 ($ lt) 60보다 작거나 아이템이 p로 시작하는 컬렉션의 문서를 선택합니다.
> db.inventory.find( { status : "A", $or : [ { qty : { $lt : 60 } }, { item : /^p/ } ] } )

Array에 있는 Element 쿼리
다음 예제에서는 태그가 "red"문자열을 요소 중 하나로 포함하는 배열 인 모든 문서를 쿼리합니다.
> db.inventory.find( { tags: "red" } )

다음 연산에서는 dim_cm 배열에 값이 25보다 큰 요소가 하나 이상 포함 된 모든 문서를 쿼리합니다.
> db.inventory.find( { dim_cm: { $gt: 25 } } )

다음 예제에서는 field 태그 값이 "red"와 "blank"와 같은 순서로 정확히 두 개의 요소가있는 배열 인 모든 문서를 쿼리합니다.
> db.inventory.find( { tags: [ "red", "blank"] } )

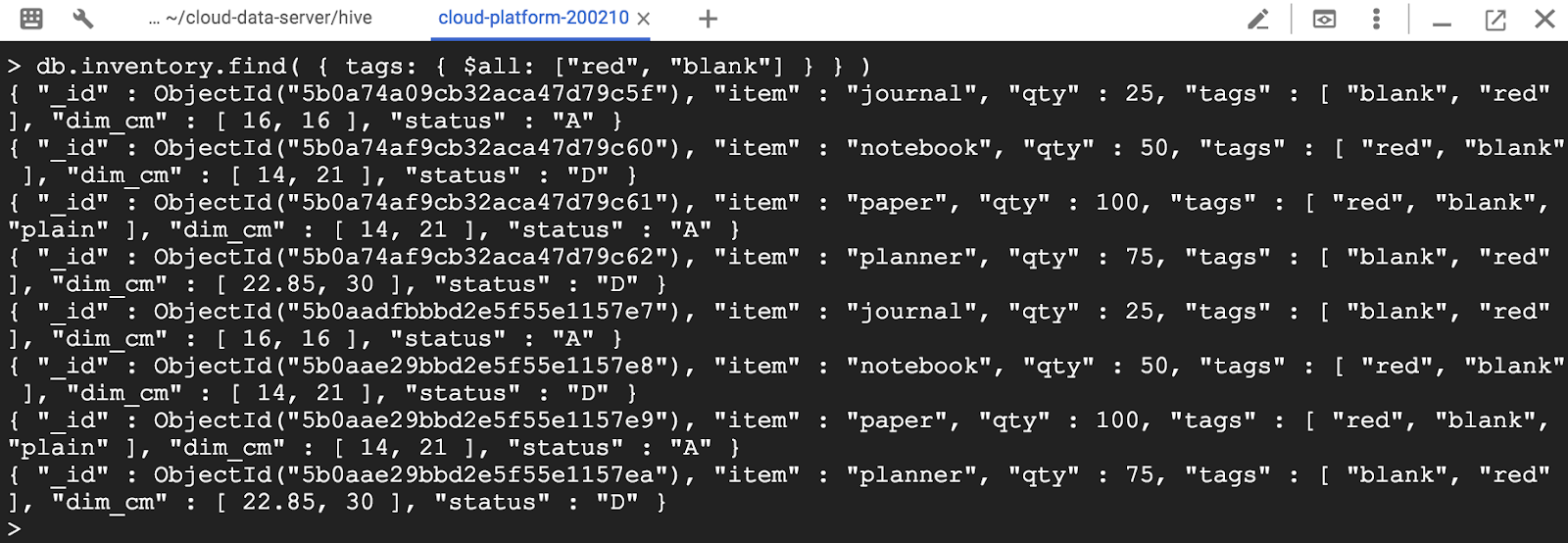
"red"와 "blank"요소를 모두 포함하는 배열을 찾으려면 순서에 관계없이 $ all 연산자를 사용합니다.
> db.inventory.find( { tags: ( $all: [ "red", "blank"] } ) )
적어도 하나의 배열 요소가 지정된 모든 기준을 충족하도록 $ elemMatch 연산자를 사용하여 배열의 요소에 여러 기준을 지정합니다.
다음 예제에서는 dim_cm 배열에 ($ gt) 22보다 크고 ($ lt) 30보다 작은 하나 이상의 요소가 포함 된 문서를 쿼리합니다.
> db.inventory.find( { dim_cm: { $elemMatch: { $gt: 22, $lt: 30 } } } )

점 표기법을 사용하면 배열의 특정 인덱스 또는 위치에있는 요소에 대한 쿼리 조건을 지정할 수 있습니다. 배열은 0부터 시작하는 색인을 사용합니다. 다음 예제에서는 배열 dim_cm의 두 번째 요소가 25보다 큰 모든 문서를 쿼리합니다.
> db.inventory.find( { "dim_cm.1": { $gt: 25 } } )

$ size 연산자를 사용하여 요소 수로 배열을 쿼리합니다. 예를 들어, 다음은 배열 태그에 3 개의 요소가 있는 문서를 선택합니다.
> db.inventory.find( { "tags": { $size: 3 } } )

Projection
projection 매개 변수를 사용하여 일치하는 문서에서 반환되는 필드를 나타낼 수 있습니다. projection 매개 변수는 다음 형식으로 표현 될 수 있습니다.
{field1 : <value>, field2 : <value> ...} 반환 문서에 필드를 포함 시키려면 <값>이 1 또는 참일 수 있습니다.
필드를 제외하려면 0 또는 False가 될 수 있습니다.
find 메소드를 사용하면
db. $ (collection) .find (filter, projection)
다음 조작은 조회와 일치하는 모든 문서를 리턴합니다. 결과 집합에서 항목, 상태 및 _id 필드 만 일치하는 문서로 반환됩니다.
> db.inventory.find( { status: "A"}, { item: 1, status: 1 } )

일치하는 문서에서 반환 할 필드를 나열하는 대신 프로젝션을 사용하여 특정 필드를 제외 할 수 있습니다.
다음 예제에서는 일치하는 문서의 상태 및 인스턴스 필드를 제외한 모든 필드를 반환합니다.
_id 필드도 제외 할 수 있습니다.
> db.inventory.find( { status: "A" }, { _id: 0, status: 0, instock: 0 } )

포함 된 문서 (JSON의 객체)의 특정 필드를 반환 할 수 있습니다. 포함 된 필드를 참조하려면 도트 표기법을 사용하고 프로젝션 문서에서 1로 설정합니다
> db.inventory.find( { status : "A" }, { "size.uom" : 1 } )

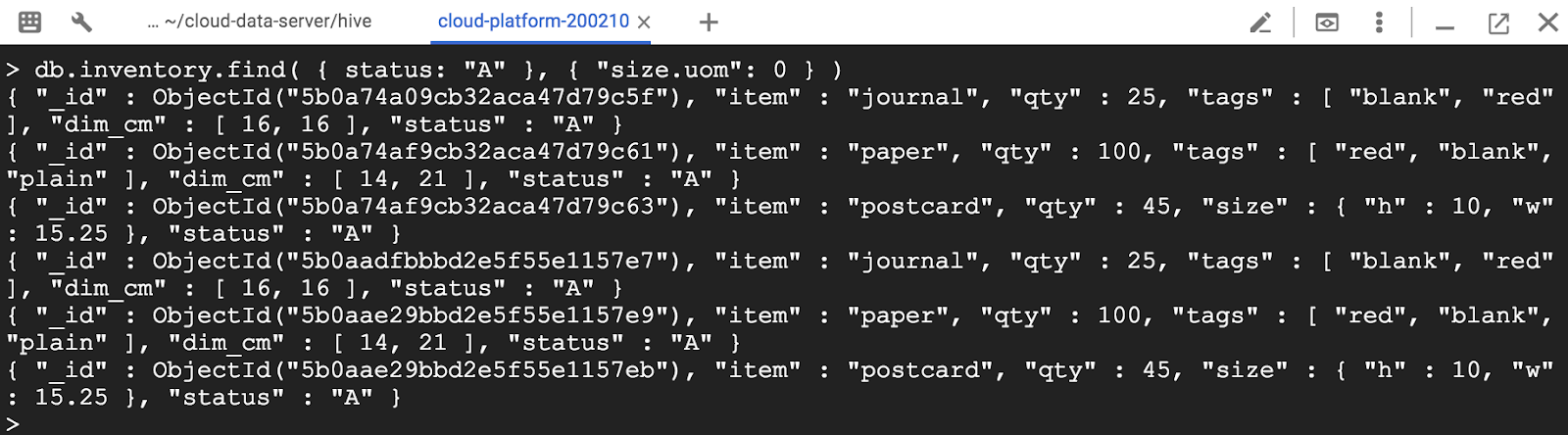
포함된 문서의 특정 필드를 표시하지 않을 수 있습니다. 도트 표기법을 사용하여 투영 문서의 포함 필드를 참조하고 0으로 설정합니다.
> db.inventory.find( { status: "A" }, { "size.uom": 0 } )
Explain
explain () 명령은 MongoDB가 쿼리를 실행할 때 수행중인 작업을 확인하기위한 명령입니다.
explain () 명령을 사용하는 가장 좋은 방법은이 명령을 래핑하는 커서 도우미 방법을 사용하는 것입니다.
> db.collection.find (). explain ()
위의 명령은 db.collection.find () 메소드에 대한 쿼리 계획에 대한 정보를 제공합니다.
> db.collection.find (). explain ( "executionStats")
위의 명령은 평가 된 메소드의 executionStats를 보여줍니다.
> db.inventory.find ({status : "A"}, { "size.uom": 0}) .explain ( "executionStats")
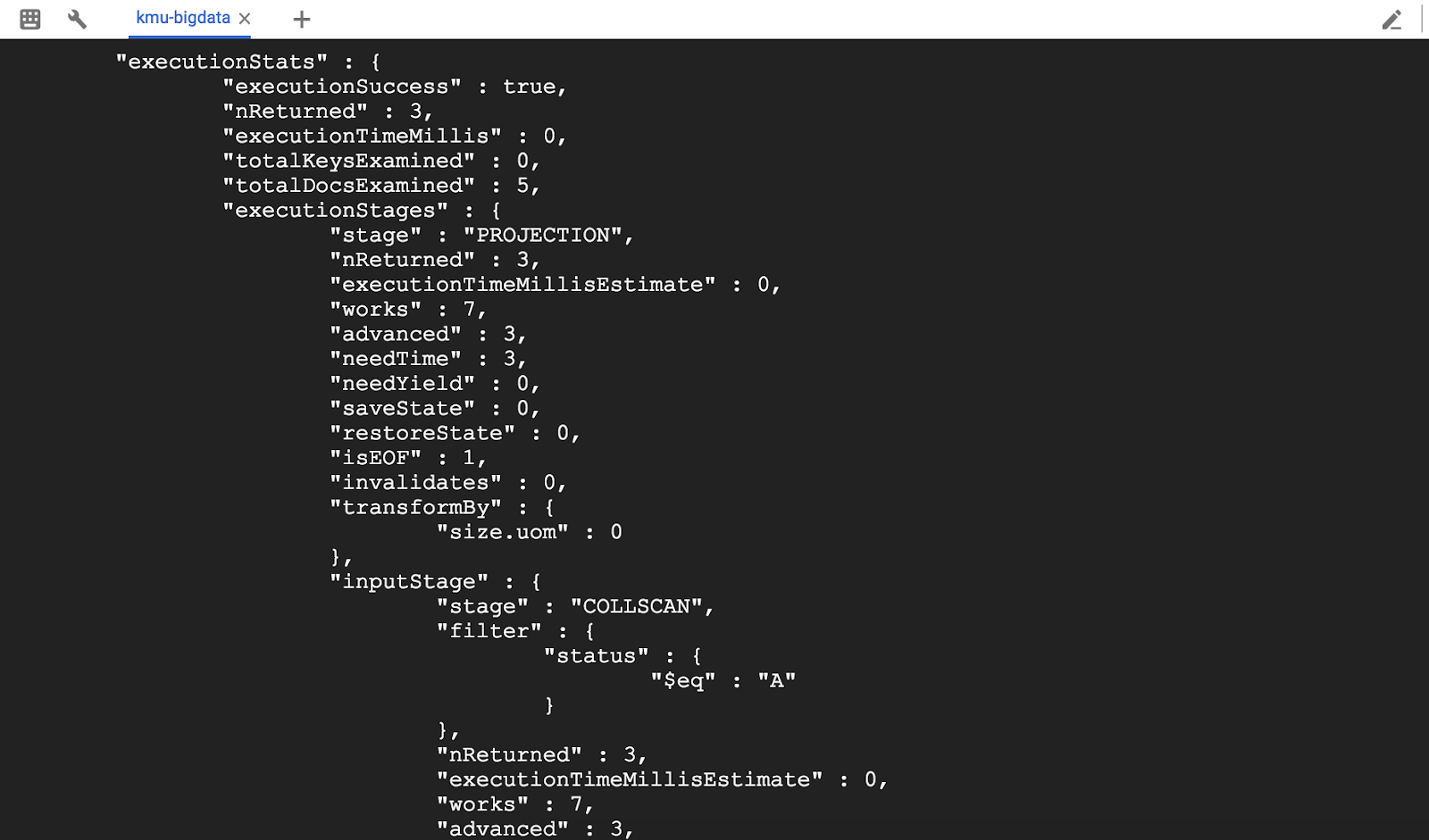
결과는 "queryPlanner", "executionStats", "serverInfo". 우리는 "executionStats"의 값을보고 싶습니다.
nReturned : Shows the number of results of the query.
executionTimeMillis : Shows the total time in milliseconds required for query selection and execution.
TotalKeysExamined : Number of index keys scanned.
TotalDocsExamined : Number of documents scanned.
executionStages : Details the completed execution.
Update
업데이트 작업
업데이트 작업은 컬렉션의 기존 문서를 수정합니다.
업데이트는 문서에서 주어진 키의 값만 변경합니다.
db. $ (collectionName) .updateOne ()
db. $ (collectionName) .updateMany ()
_id 필드를 제외한 문서의 전체 내용을 바꿉니다.
db. $ (collectionName) .replaceOne ()

문서를 업데이트하기 위해, MongoDB는 업데이트 연산자 인 $ set을 제공하여 필드 값을 수정합니다.
다음 예제에서는 인벤토리 컬렉션의 updateOne () 메서드를 사용하여 상태가 "A"인 첫 번째 문서를 업데이트합니다.
> db.inventory.find({status:"A"})
> db.inventory.updateOne(
{ status : "A" },
{ $set: { qty : 200 }}
)
> db.inventory.find({status:"A"})

다음 예제에서는 인벤토리 컬렉션에서 updateMany () 메서드를 사용하여 qty가 100 미만인 문서를 업데이트합니다.
> db.inventory.find( {qty:{$lt:100}})
> db.inventory.updateMany(
{ qty : { $lt : 100 } },
{ $set: { status : "P" }}
)
> db.inventory.find( {qty:{$lt:100}})

Replace
_id 필드를 제외한 문서의 전체 내용을 바꾸려면 완전히 새로운 문서를 replaceOne ()의 두 번째 인수로 전달합니다.
db.collection.replaceOne(
<filter>,
<replacement>
)
필터가 업데이트의 선택 기준입니다. 대체 문서가 대체 문서입니다.
_id 필드가 불변이므로 _id 필드를 생략 할 수 있습니다. _id 필드를 포함하면 현재 값과 동일한 값을 가져야합니다.
> db.inventory.find({status:"P"})
> db.inventory.replaceOne (
{ status : "P" },
{ status : "P", instock : [ { warehouse : "A", qty: 60 }, { warehouse : "B", qty : 40 } ] }
)
> db.inventory.find({status:"P"})

Delete
- 삭제 작업
삭제 작업은 컬렉션에서 문서를 제거합니다.
db. $ (collectionName) .deleteOne ()
db. $ (collectionName) .deleteMany ()

지정된 필터와 일치하는 단일 문서를 삭제하려면 deleteOne () 메서드를 사용합니다.
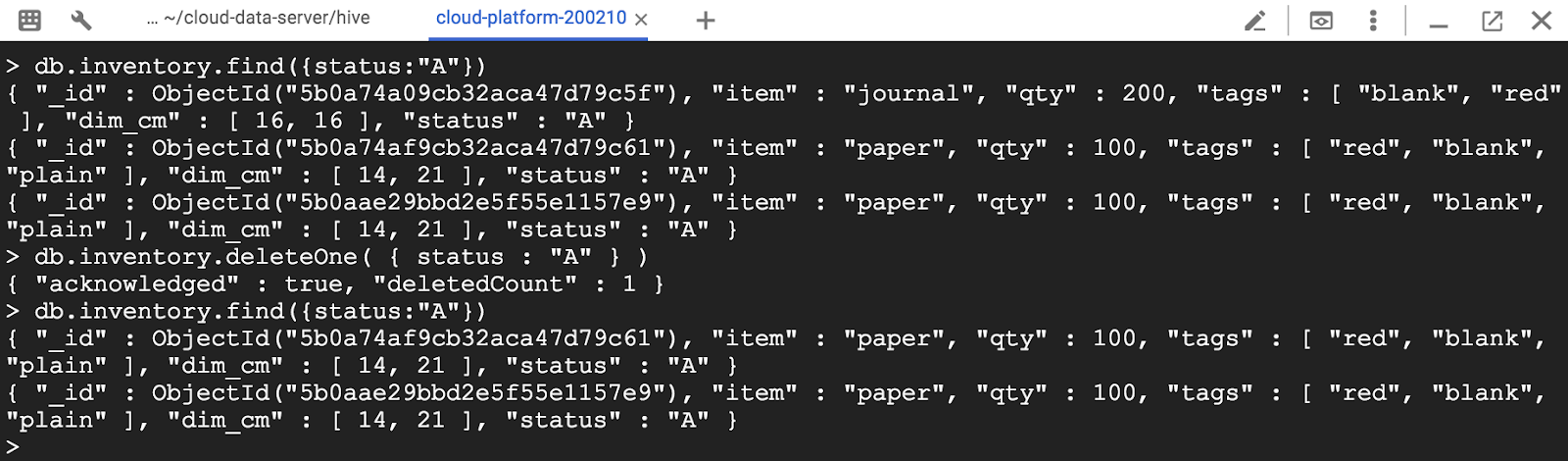
다음 예제에서는 상태가 "A"인 첫 번째 문서를 삭제합니다.
> db.inventory.find({status:"A"})
> db.inventory.deleteOne( { status : "A" } )
> db.inventory.find({status:"A"})
삭제 기준과 일치하는 모든 문서를 삭제하려면 deleteMany () 메서드에 필터 매개 변수를 전달합니다.
다음 예에서는 상태 필드가 "P"인 인벤토리 모음에서 모든 문서를 제거합니다.
> db.inventory.find({status:"P"})
> db.inventory.deleteMany( { status : "P" } )
> db.inventory.find({status:"P"})

다음 예는 컬렉션에서 모든 문서를 제거합니다.
> db.inventory.find({})
> db.inventory.deleteMany( { } )
> db.inventory.find({})

> exit
zips 데이터셋 사용
MongoDB 공식 사이트에서 제시하는 json 파일의 데이터셋을 사용해보겠습니다.
http://media.mongodb.org/zips.json
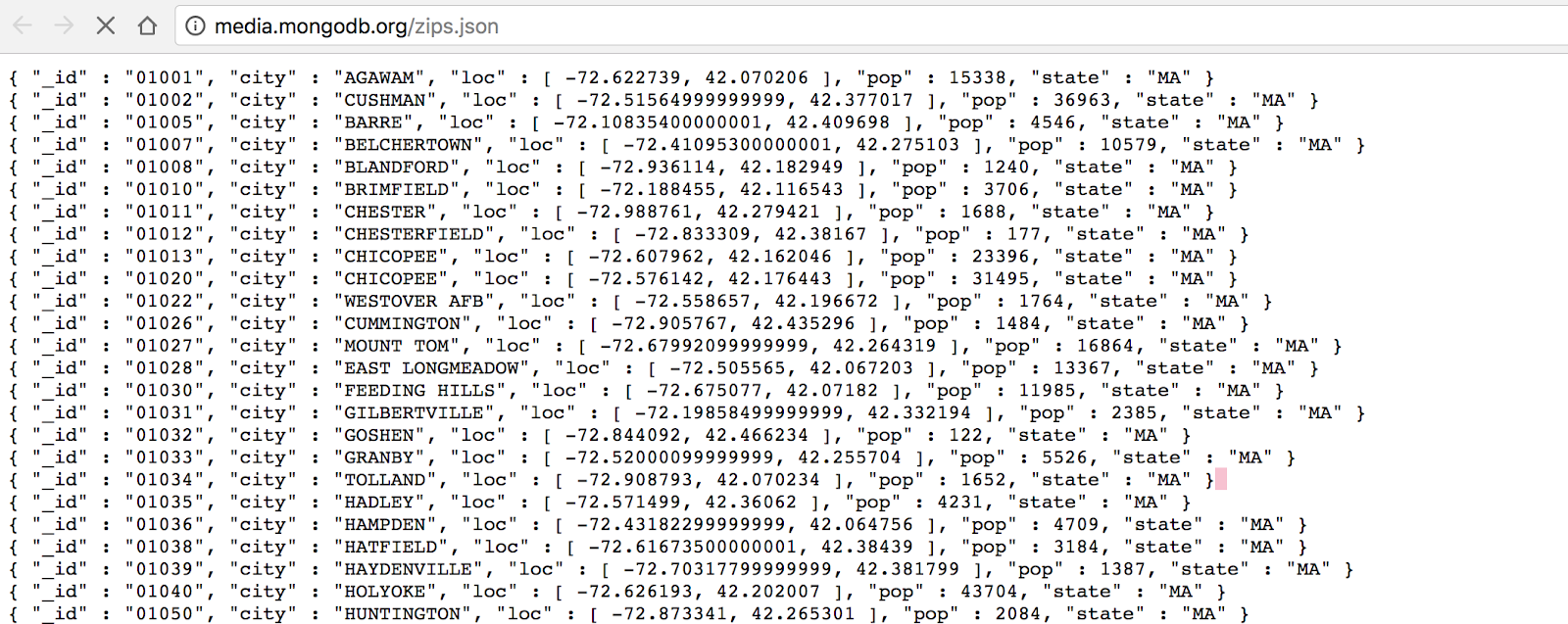
각 필드의 설명은 다음과 같습니다.
_id : zip code의 문자열 입니다.
city : 도시 이름 field
state : 2개의 문자로 구성된 주 이름 field
pop : 인구 수
loc : 위도와 경도의 pair filed
$ wget http://media.mongodb.org/zips.json

docker cp 명령으로 zips.json 파일을 mongodb 컨테이너에 복사하십시오.
docker cp CONTAINER : SRC_PATH DEST_PATH
docker cp SRC_PATH CONTAINER : DEST_PATH
docker cp 유틸리티는 SRC_PATH의 내용을 DEST_PATH에 복사합니다.
컨테이너의 파일 시스템에서 로컬 시스템으로 복사하거나 역순으로 수행 할 수 있습니다.
첫 번째 명령은 CONTAINER의 SRC_PATH를 로컬 DEST_PATH에 복사하는 것입니다.
두 번째 명령은 로컬 시스템의 SRC_PATH를 CONTAINER의 DEST_PATH로 복사하는 것입니다.
$ docker cp zips.json mongodb:/zips.json

다음 명령을 사용하여 mongoDB의 zipcodes 컬렉션으로 zips.json 파일 가져 오기
도커 exec -it CONTAINER COMMAND
mongoimport --collection COLLECTION --file FILEPATH -u 사용자 -pPASSWORD --authenticationDatabase admin
첫 번째 명령은 실행중인 CONTAINER에서 COMMAND를 실행하는 것입니다.
두 번째 명령은 MongoDB에 인증 할 USER에 COLLECTION에 FILEPATH를 삽입하는 것입니다.
$ docker exec -it mongodb mongoimport --collection zipcodes --file zips.json -u mongoadmin -psecret --authenticationDatabase admin

$ docker exec -it mongodb mongo -u mongoadmin -psecret --authenticationDatabase admin

zipcodes 컬렉션을 살펴봅시다.
> db.zipcodes.find( {} )

Aggregation
aggregate () 메서드는 aggregate 파이프 라인을 사용하여 문서를 집계 된 결과로 처리합니다.
aggregate 파이프 라인은 단계로 구성됩니다.

match
문서를 필터링하여 지정된 조건과 일치하는 문서 만 다음 파이프 라인 단계로 전달합니다.
{$ match : {<query>}}
$ match는 쿼리 조건을 지정하는 문서를 사용합니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} } ] )
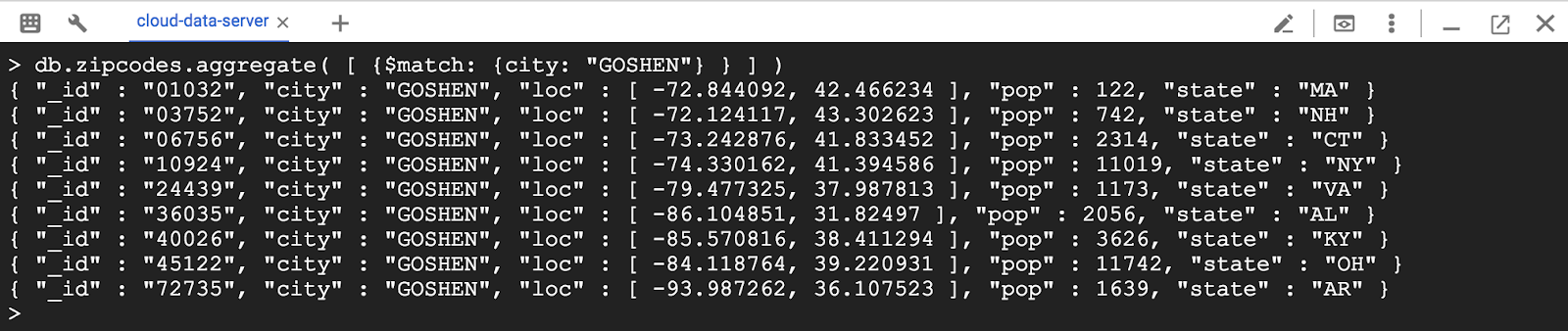
이것은 find 쿼리를 사용하는 다음 작업과 동일합니다.
> db.zipcodes.find( { city: "GOSHEN" } )

project
요청 된 필드가있는 문서를 파이프 라인의 다음 단계로 전달합니다.
{$ project : {<specification (s)>}}
$ 프로젝트는 필드의 포함, _id 필드의 억제, 새로운 필드의 추가 및 기존 필드의 값 재설정을 지정할 수있는 문서를 사용합니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$project: { _id: 0, city: 1, pop: 1 } } ] )
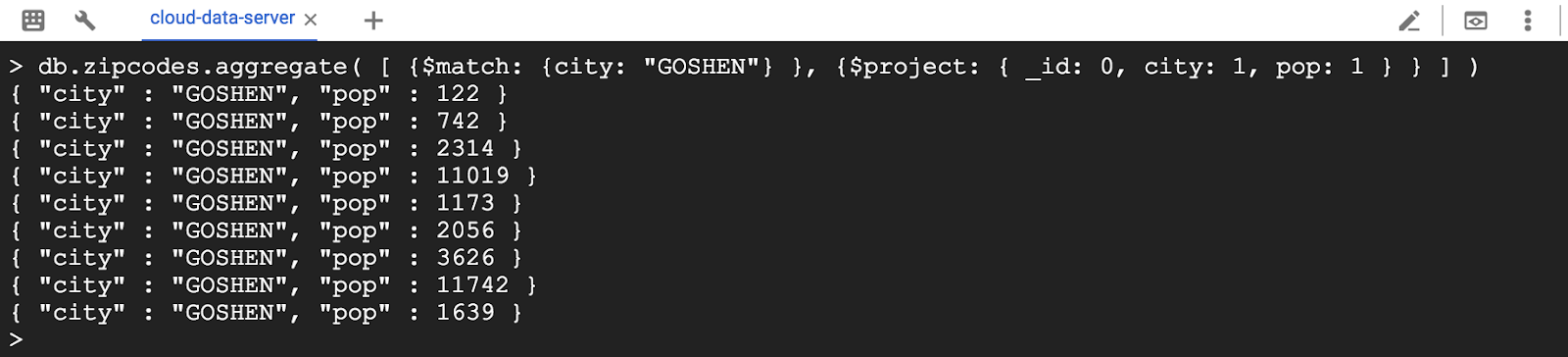
limit
파이프 라인의 다음 단계로 전달되는 문서 수를 제한합니다.
{$ limit : <양의 정수>}
$ limit는 전달할 최대 문서 수를 지정하는 양의 정수입니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$limit: 5}, {$project: { _id: 0, city: 1, pop: 1 } } ] )

모든 입력 문서를 정렬하여 정렬 된 순서로 파이프 라인에 반환합니다.
{$ sort : {<field1> : <sort order>, <field2> : <sort order> ...}}
$ sort는 정렬 할 필드와 각 정렬 순서를 지정하는 문서를 사용합니다.
<정렬 순서>는 1 또는 -1이 될 수 있습니다. 1을 사용하여 오름차순을 지정합니다. 내림차순을 지정하려면 -1을 지정합니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$sort: {pop: 1} }, {$limit: 5}, {$project: {_id: 0, city: 1, pop: 1 } } ] )

> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$sort: {pop: -1} }, {$limit: 5}, {$project: { _id: 0, city: 1, pop: 1 } } ] )

두 값을 비교하여 리턴합니다.
첫 번째 값이 두 번째 값보다 크거나 같으면 True입니다.
첫 번째 값이 두 번째 값보다 작으면 거짓입니다.
{$ gte : [<expression1>, <expression2>]}
> db.zipcodes.aggregate( [
{$match: {city: "GOSHEN"} },
{$project: {_id: 0, city: 1, pop: 1,
popGte: { $gte: [ "$pop", 1000 ] } } }
] )

group
지정된 표현식으로 문서를 그룹화하고 (_id 필드로 정의) 그룹화 한 후 다음 단계로 출력합니다.
출력 문서에는 키별로 구별되는 그룹을 포함하는 _id 필드가 있습니다.
{$ group : {_id : <expression>, <field1> : {<accumulator1> : <expression1>},}}}
_id 및 <accumulator> 식은 유효한 식을 모두 허용 할 수 있습니다.
<accumulator> 연산자는 다음 누적 연산자 중 하나 여야합니다.
$ first : 각 그룹의 첫 번째 문서에서 값을 반환합니다.
$ last : 각 그룹에 대한 마지막 문서의 값을 반환합니다.
$ sum : 숫자 값의 합을 구합니다.
$ avg : 숫자 값의 평균을 반환합니다.
주(state)마다 가장 큰 도시 출력합니다.
> db.zipcodes.aggregate( [
{ $sort: { state: 1, pop: -1 } },
{ $group: { _id: "$state", biggestPopCity: { $first: "$city"}, biggestPopState: { $first: "$pop" } } },
{ $sort: { _id: 1 } },
] )
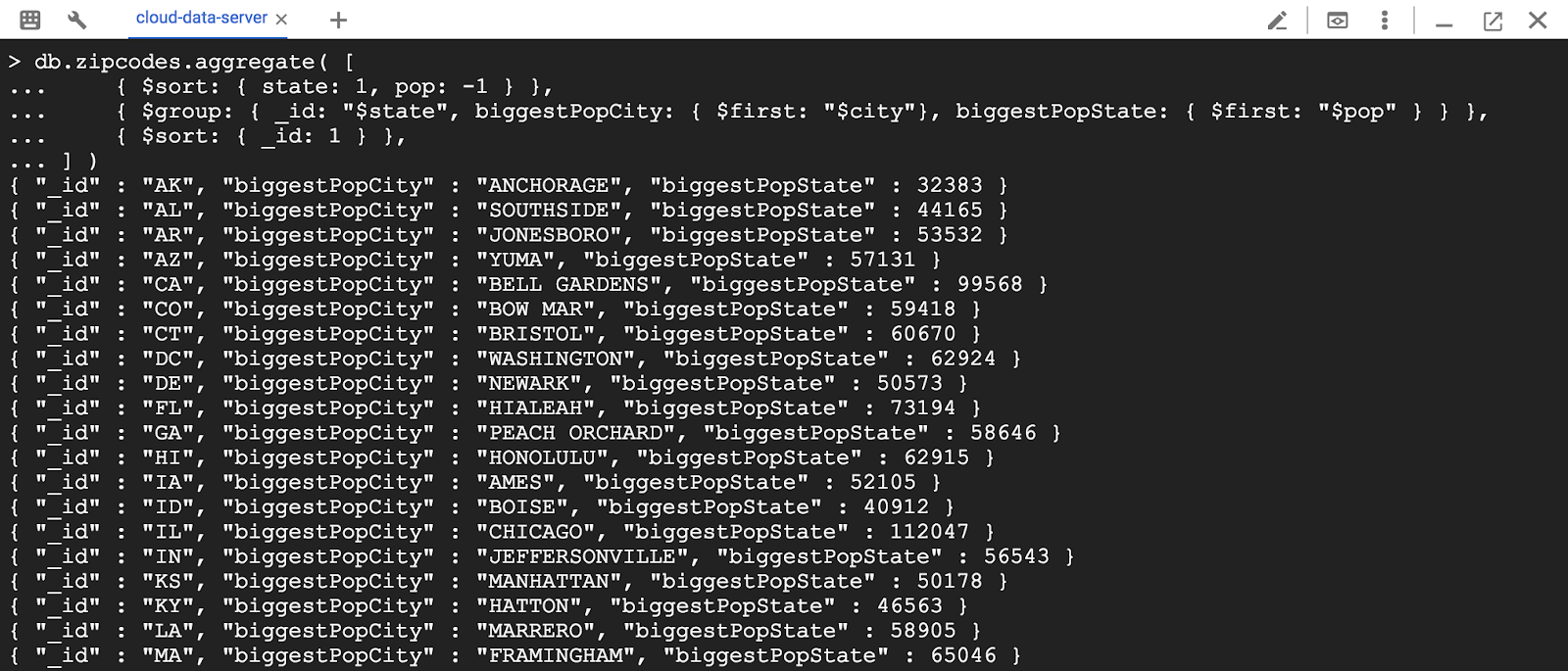
주(state)마다 가장 작은 도시를 출력합니다.
> db.zipcodes.aggregate( [
{ $sort: { state: 1, pop: -1 } },
{ $group: { _id: "$state", smallestPopCity: { $last: "$city"}, smallestPopState: { $last: "$pop" } } },
{ $sort: { _id: 1 } },
] )

천 만 인구 수 이상 주(state)를 출력합니다.
> db.zipcodes.aggregate( [
{ $group: { _id: "$state", totalPop: { $sum: "$pop" } } },
{ $match: { totalPop: { $gt: 10*1000*1000 } } }
] )

평균 도시의 수를 반환합니다.
> db.zipcodes.aggregate( [
{ $group: { _id: { state: "$state", city: "$city" }, pop: { $sum: "$pop" } } },
{ $group: { _id: "$_id.state", avgCityPop: { $avg: "$pop" } } }
] )

Index
MongoDB의 인덱스
트래버스하기 쉬운 형식으로 데이터 세트를 저장하는 특수 데이터 구조
특정 필드 또는 필드 세트의 값은 필드 값에 의해 정렬되어 저장됩니다.
MongoDB에서 쿼리의 효율적인 실행을 지원합니다.
인덱스가 없다면, MongoDB는 전체 콜렉션 스캔을 수행해야합니다
인덱스 및 쿼리 예제

기본적으로 인덱스는 _id 필드로 생성됩니다.
> db.zipcodes.getIndexes()
v는 인덱스 포멧 버전입니다.
key는 인덱스의 value입니다. 1은 오름차순입니다.
name은 인덱스의 이름입니다.
ns는 인덱스의 네임스페이스 입니다.

zipcodes 컬렉션에는 다음 샘플 문서와 유사한 문서가 들어 있습니다.
다음 명령으로 색인을 작성할 수 있습니다.
> db.collection.createIndex ({key : value})

인덱스의 키 설정. 값은 1, -1이 될 수 있습니다.
1은 필드의 오름차순 색인입니다. -1은 내림차순 색인입니다.
다음 작업은 zipcodes 컬렉션의 pop 필드에 오름차순 색인을 만듭니다.
> db.zipcodes.createIndex ({pop : 1}) // 키가 {pop : 1} 인 인덱스를 만듭니다.
"createdCollectionAutomatically": false 인덱스 작성의 일부로 자동으로 콜렉션이 작성되지 않았습니다.
"numIndexesBefore": 1이 인덱스를 만들기 전에 인덱스 수를 1
"numIndexesAfter": 2 이제이 컬렉션에 총 2 개의 인덱스가 있습니다.
> db.zipcodes.createIndex( { pop : 1 } )

팝 인덱스가 추가 된 것을 볼 수 있습니다.
> db.zipcodes.getIndexes ()
이제 2 개의 인덱스 _id 및 pop이 있습니다.
> db.zipcodes.getIndexes()
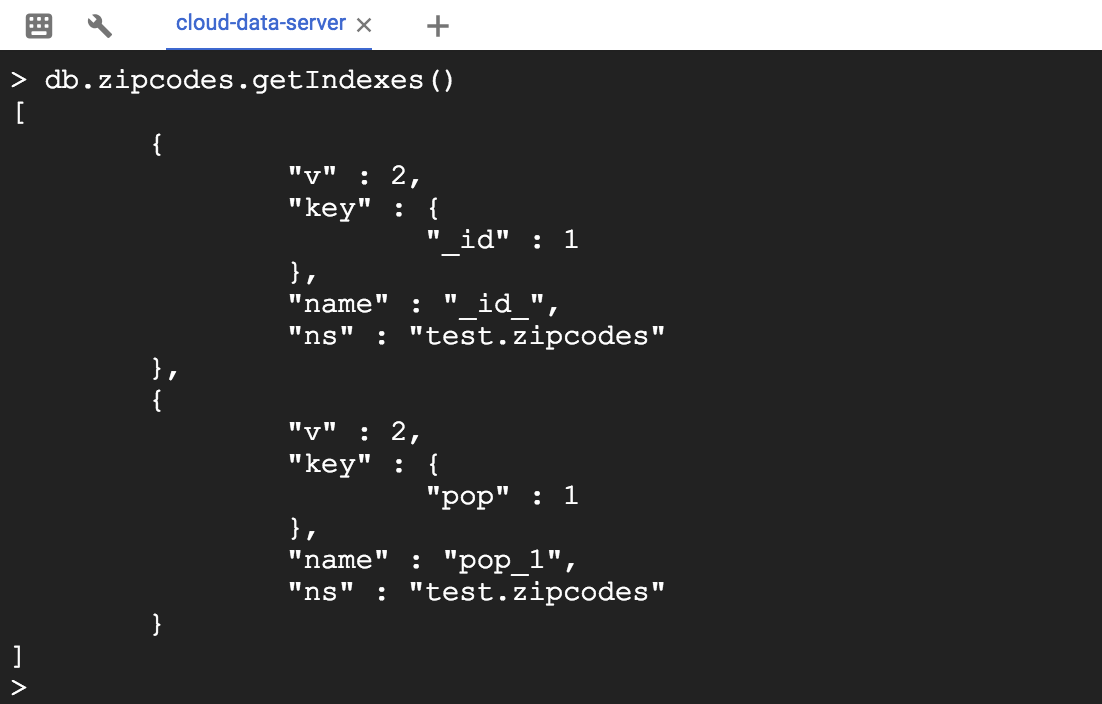
작성된 색인은 다음 명령과 같이 필드 팝에서 선택한 조회를 지원합니다.
> db.zipcodes.find ({pop : 100})
> db.zipcodes.find ({pop : {$ lt : 100}}) # 더 많은 것을 위해 "it"을 입력하십시오

sort () 메소드를 사용하여 질의 결과를 정렬 할 수있다.
정렬 ({key : value})
sort 매개 변수에 정렬 기준이되는 키 (필드)를 지정하고 1 또는 -1 값을 사용하여 오름차순 또는 내림차순 정렬을 지정합니다.
> db.zipcodes.find ({pop : 100}) .sort ({_id : 1}) // 결과를 오름차순 정렬로 표시하십시오.
> db.zipcodes.find ({pop : 100}) .sort ({_id : -1}) // 결과를 내림차순 정렬로 표시합니다.

다음 명령은 상태별로 오름차순 정렬을 지정하고 _id 필드로 오름차순 / 내림차순 정렬을 지정합니다.
> db.zipcodes.find ({pop : 100}) .sort ({state : 1, _id : 1})
> db.zipcodes.find ({pop : 100}) .sort ({state : 1, _id : -1})

Compound Index
복합 색인은 콜렉션의 문서에서 여러 필드에 대한 참조를 보유합니다. 여러 필드에서 일치하는 쿼리를 지원합니다.
복합 인덱스는 인덱스에 대해 순차적으로 정렬합니다.
구문 : db. $ (collection) .createIndex ({index-key1 : order, index-key2 : order, ...})
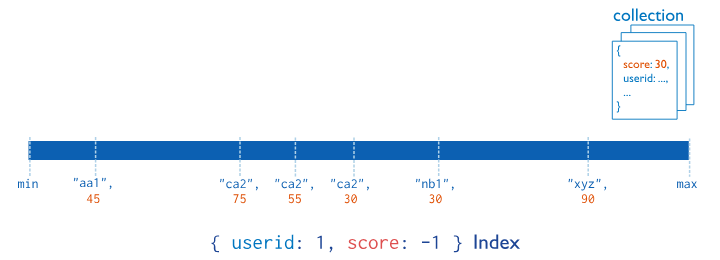
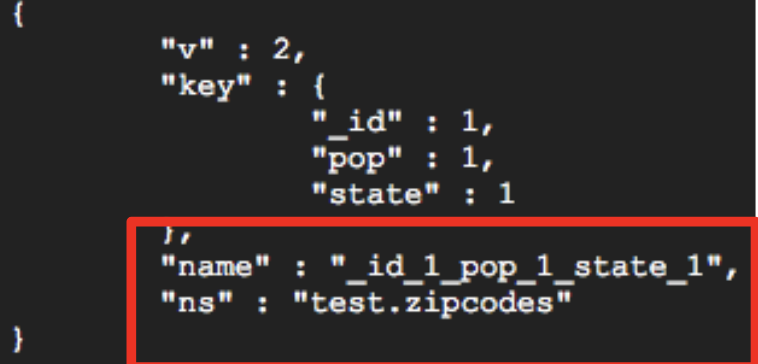
다음 작업은 _id, pop 및 state에 오름차순 색인을 만듭니다.
> db.zipcodes.createIndex ({_id : 1, pop : 1, state : 1})

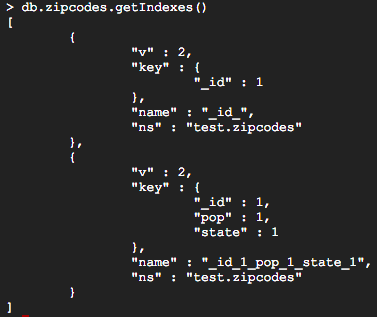
추가 된 복합 색인을 볼 수 있습니다.
> db.zipcodes.getIndexes ()
Index prefix
인덱스 필드의 부분 집합
복합 색인의 경우
{_id : 1, 팝 : 1, 상태 : 1}
색인 접두어
{_id : 1}
{_id : 1, pop : 1}
인덱스 접두사에 대한 쿼리는 성능 이점도 얻습니다.
_id 필드
_id 필드와 pop 필드
_id 필드와 팝 필드 및 상태 필드
쿼리에 인덱스 접두사를 사용하려면 모든 키에 지정된 정렬 방향이 일치해야합니다.
복합 색인 {_id : 1, pop : 1, state : 1}은 정렬을 지원할 수 있습니다.
dropIndex () 메소드를 사용하여 인덱스를 삭제할 수 있습니다.
db.collection.dropIndex (indexName) // 이름이있는 인덱스를 삭제합니다.
db.collection.dropIndex (indexKey) // 키를 사용하여 인덱스를 삭제합니다.
getIndexes () 메소드를 통해 indexName, indexKey를 확인할 수 있습니다.
> db.zipcodes.getIndexes ()

인덱스 이름을 확인하십시오.
> db.zipcodes.getIndexes ()

인덱스 이름에 "pop_1"이있는 인덱스를 삭제하십시오.
> db.zipcodes.dropIndex ( "pop_1")

인덱스 삭제되었는지 확인할 수 있습니다.
> db.zipcodes.getIndexes ()
explain 메소드로 executionStats 파트를 점검하십시오.
> db.zipcodes.find( {"city":"MOUNT TOM"} ).explain("executionStats")
29353 문서를 스캔하는 데 14 밀리 초가 소요되었습니다.
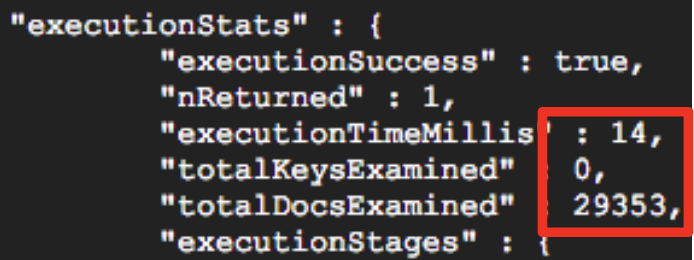
zipcodes 컬렉션의 도시 필드에 오름차순 색인 만들기
> db.zipcodes.createIndex( { "city" : 1 } )

executionStats를 다시 확인하십시오.
> db.zipcodes.find( {"city":"MOUNT TOM"} ).explain("executionStats")

'Google Cloud Platform' 카테고리의 다른 글
| Google Cloud Platform 이용한 엔티티와 감정 분석 Natural Language API (0) | 2018.06.05 |
|---|---|
| MapReduce 프로그래밍(Hadoop) using GCP DataProc (0) | 2018.06.04 |
| Google Cloud Platform Cloud Vision API를 이용한 이미지, 얼굴 Detection (1) | 2018.04.11 |
| Google Cloud Platform 이용한 텍스트 카테고리 분류 Natural Language API (1) | 2018.04.10 |
| Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API (1) | 2018.04.10 |
MongoDB using Google Cloud Platform
MongoDB
대표적인 문서 데이터베이스
JSON 문서로 작업
많은 인덱스를 통해 고성능 지원
고 가용성 - 복제 + 최종 일관성(consistency) + 자동 장애 조치(failover)
자동 확장(scaling) - 클러스터 전체에 자동 sharding 지원
각 JSON 문서는 컬렉션(Collection)에 속하며 _id라는 필드(filed)를 가지고 있습니다.
컬렉션 내에서는 _id는 고유해야 합니다.
각 컬렉션은 데이터베이스(database)에 속합니다.
기존의 RDBMS와 MongoDB의 차이점입니다.
문서(Documents)는 그룹화된 정보의 논리적 집합입니다.
JSON에서 객체는 문서 단위가 될 수 있습니다.
컬렉션(collection)
- 문서 그룹입니다.
- 관계형 데이터베이스의 테이블(table)과 동일합니다.
데이터베이스(Database)
- MongoDB는 데이터베이스에 컬렉션을 그룹화합니다.
- 데이터베이스에는 자체 권한이 있으며, 각 데이터베이스는 별도의 파일에 저장됩니다.
_id 필드
- 기본 키로 사용됩니다.
- 컬렉션 내에서 고유해야 하며, 변경 불가능합니다.
- 자동으로 생성 가능합니다.
유연한 스키마(flexible schema)
- 동일한 컬렉션 내의 문서가 특정 구조를 갖도록 강요하지 않습니다.
- 실제로 컬렉션의 문서는 비슷합니다.
Google Cloud Platform을 이용한 Mongo DB Docker 실습
Google Cloud Platform
1. 로그인을 진행합니다.
2. 회원가입을 진행합니다.
3. http://console.cloud.google.com/ 이동하여 “무료 평가판 신청" 버튼을 클릭합니다.
4. 대한민국을 선택하고 동의 및 계속하기 버튼을 클릭합니다.
5. 주소와 카드 정보를 입력합니다. 무료 평가판 시작하기 버튼을 클릭합니다.
6. 프로젝트를 생성하기 시작합니다.
7. $300 크레딧을 받았습니다.
8. My First Project를 클릭하면 프로젝트 관리를 할 수 있습니다.
9. 실습을 시작할 준비가 완료되었습니다.
MongoDB Container 시작하기
1. Cloud Shell 버튼을 클릭합니다.
2. “START CLOUD SHELL” 버튼을 클릭하면 Cloud shell을 사용할 VM을 프로비저닝 합니다.
Cloud shell에서 VM에 5GB 영구 홈 디렉터리가 할당됩니다.
"gcloud"는 Google Cloud Platform 용 통합 명령 줄 도구이며 CloudShell에 사전 설치되어 있습니다.
$ gcloud auth list : 로그인 한 계정 정보보기
$ gcloud 설정 목록 프로젝트 : 현재 프로젝트
공식 MongoDB 이미지로 도커를 사용하여 MongoDB 컨테이너 만들기
- MONGO_INITDB_ROOT_USERNAME = mongoadmin
- MONGO_INITDB_ROOT_PASSWORD = secret
이 사용자는 관리자 인증 데이터베이스에서 생성되며 root 역할을합니다.
$ docker run -d --name mongodb -e MONGO_INITDB_ROOT_USERNAME=mongoadmin -e MONGO_INITDB_ROOT_PASSWORD=secret mongo
컨테이너를 생성 한 후, mongoadmin (루트 사용자)으로 컨테이너에서 MongoDB를 실행하는 명령으로 mongodb 컨테이너에 액세스 할 수 있습니다.
$ docker exec -it mongodb mongo -u mongoadmin -psecret --authenticationDatabase admin
// MongoDB 데이터베이스에 대해 인증 할 사용자 이름 (mongoadmin)을 지정합니다. - admin 데이터베이스는 인증 정보를 포함합니다.
MongoDB 실습
Create Operation
Create 또는 Insert 연산으로 collection에 새로운 문서를 추가합니다.
collection이 존재하지 않으면 Insert 연산으로 collection을 생성합니다.
> db.$(collectionName).insertOne()
> db.$(collectionName).insertMany()
문서가 _id 필드를 지정하지 않으면 MongoDB ObjectId 값과 함께 _id 필드를 새 문서에 추가합니다.
컬렉션이 자동으로 생성됩니다.
> db.inventory.insertOne(
{ item: "journal", qty: 25, tags: ["blank", "red"], dim_cm: [ 16, 16 ], status: "A" }
)
컬렉션이 다른 스키마가 있는 여러 문서를 삽입할 수 있습니다.
> db.inventory.insertMany([
{ item: "notebook", qty: 50, tags: ["red", "blank"], dim_cm: [ 14, 21 ], status: "D" },
{ item: "paper", qty: 100, tags: ["red", "blank", "plain"], dim_cm: [ 14, 21 ], status: "A" },
{ item: "planner", qty: 75, tags: ["blank", "red"], dim_cm: [ 22.85, 30 ], status: "D" },
{ item: "postcard", qty: 45, size: { h: 10, w: 15.25, uom: "cm" }, status: "A" }
])
READ Operation
읽기 작업은 컬렉션에서 문서를 가져옵니다. 즉 문서 모음을 쿼리합니다.
> db.$(collectionName).find()
컬렉션의 모든 문서를 선택하려면 빈 문서를 쿼리 필터 매개 변수로 find 메서드에 전달합니다.
문서를 보면 삽입하지 않은 _id 필드를 볼 수 있습니다.
> db.inventory.find( {} )
다음 메서드는 컬렉션에서 문서를 읽을 수도 있지만 단일 문서를 읽습니다.
db. $ (collection) .findOne () 메서드는 db. $ (collection) .find () 메서드이며 제한은 1입니다.
따라서 db.inventory.find ({}) 결과의 첫 번째 문서 인 문서 하나만 보여줍니다.
> db.inventory.findOne( {} )
동일 조건을 지정하려면 쿼리 필터 문서에서 {<key> : <value>} 표현식을 사용하십시오.
다음 예는 상태가 "A"인 모든 문서를 인벤토리 모음에서 선택합니다.
> db.inventory.find( { status : "A" } )
> db.inventory.findOne( { status : "A" } )
쿼리 조건 AND 연산
값 목록과 함께 $ in 상태를 지정하는 다음 예제는 상태가 "A"또는 "D"인 인벤토리 모음에서 모든 문서를 검색합니다.
> db.inventory.find( { status : { $in : ["A", "D"] } } )
> db.inventory.findOne( { status : { $in : ["A", "D"] } } )
> db.inventory.find( { status : "A", qty : { $lt : 30 } } )
복합 조회는 콜렉션의 문서에서 둘 이상의 필드에 대한 조건을 지정할 수 있습니다.
형식 : {key-1 : value-1, key-2 : value-2, ...}
다음 예제에서는 상태가 "A"이고 qty가 ($ lt) 30보다 작은 인벤토리 모음의 모든 문서를 검색합니다.
> db.inventory.find( { status : "A", qty : { $lt : 30 } } ).pretty()
쿼리 조건 OR 연산
$or : [조건 1, 조건 2, ...]을 지정하거나 조건을 지정하려면
다음 예제에서는 상태가 "A"이거나, qty가 ($ lt) 60보다 작은 인벤토리 모음의 모든 문서를 검색합니다.
> db.inventory.find( { $or : [ { status : "A" }, { qty : { $lt : 60 } } ] } )
다음 예에서는 상태가 "A"이고 qty가 ($ lt) 60보다 작거나 아이템이 p로 시작하는 컬렉션의 문서를 선택합니다.
> db.inventory.find( { status : "A", $or : [ { qty : { $lt : 60 } }, { item : /^p/ } ] } )
Array에 있는 Element 쿼리
다음 예제에서는 태그가 "red"문자열을 요소 중 하나로 포함하는 배열 인 모든 문서를 쿼리합니다.
> db.inventory.find( { tags: "red" } )
다음 연산에서는 dim_cm 배열에 값이 25보다 큰 요소가 하나 이상 포함 된 모든 문서를 쿼리합니다.
> db.inventory.find( { dim_cm: { $gt: 25 } } )
다음 예제에서는 field 태그 값이 "red"와 "blank"와 같은 순서로 정확히 두 개의 요소가있는 배열 인 모든 문서를 쿼리합니다.
> db.inventory.find( { tags: [ "red", "blank"] } )
"red"와 "blank"요소를 모두 포함하는 배열을 찾으려면 순서에 관계없이 $ all 연산자를 사용합니다.
> db.inventory.find( { tags: ( $all: [ "red", "blank"] } ) )
적어도 하나의 배열 요소가 지정된 모든 기준을 충족하도록 $ elemMatch 연산자를 사용하여 배열의 요소에 여러 기준을 지정합니다.
다음 예제에서는 dim_cm 배열에 ($ gt) 22보다 크고 ($ lt) 30보다 작은 하나 이상의 요소가 포함 된 문서를 쿼리합니다.
> db.inventory.find( { dim_cm: { $elemMatch: { $gt: 22, $lt: 30 } } } )
점 표기법을 사용하면 배열의 특정 인덱스 또는 위치에있는 요소에 대한 쿼리 조건을 지정할 수 있습니다. 배열은 0부터 시작하는 색인을 사용합니다. 다음 예제에서는 배열 dim_cm의 두 번째 요소가 25보다 큰 모든 문서를 쿼리합니다.
> db.inventory.find( { "dim_cm.1": { $gt: 25 } } )
$ size 연산자를 사용하여 요소 수로 배열을 쿼리합니다. 예를 들어, 다음은 배열 태그에 3 개의 요소가 있는 문서를 선택합니다.
> db.inventory.find( { "tags": { $size: 3 } } )
Projection
projection 매개 변수를 사용하여 일치하는 문서에서 반환되는 필드를 나타낼 수 있습니다. projection 매개 변수는 다음 형식으로 표현 될 수 있습니다.
{field1 : <value>, field2 : <value> ...} 반환 문서에 필드를 포함 시키려면 <값>이 1 또는 참일 수 있습니다.
필드를 제외하려면 0 또는 False가 될 수 있습니다.
find 메소드를 사용하면
db. $ (collection) .find (filter, projection)
다음 조작은 조회와 일치하는 모든 문서를 리턴합니다. 결과 집합에서 항목, 상태 및 _id 필드 만 일치하는 문서로 반환됩니다.
> db.inventory.find( { status: "A"}, { item: 1, status: 1 } )
일치하는 문서에서 반환 할 필드를 나열하는 대신 프로젝션을 사용하여 특정 필드를 제외 할 수 있습니다.
다음 예제에서는 일치하는 문서의 상태 및 인스턴스 필드를 제외한 모든 필드를 반환합니다.
_id 필드도 제외 할 수 있습니다.
> db.inventory.find( { status: "A" }, { _id: 0, status: 0, instock: 0 } )
포함 된 문서 (JSON의 객체)의 특정 필드를 반환 할 수 있습니다. 포함 된 필드를 참조하려면 도트 표기법을 사용하고 프로젝션 문서에서 1로 설정합니다
> db.inventory.find( { status : "A" }, { "size.uom" : 1 } )
포함된 문서의 특정 필드를 표시하지 않을 수 있습니다. 도트 표기법을 사용하여 투영 문서의 포함 필드를 참조하고 0으로 설정합니다.
> db.inventory.find( { status: "A" }, { "size.uom": 0 } )
Explain
explain () 명령은 MongoDB가 쿼리를 실행할 때 수행중인 작업을 확인하기위한 명령입니다.
explain () 명령을 사용하는 가장 좋은 방법은이 명령을 래핑하는 커서 도우미 방법을 사용하는 것입니다.
> db.collection.find (). explain ()
위의 명령은 db.collection.find () 메소드에 대한 쿼리 계획에 대한 정보를 제공합니다.
> db.collection.find (). explain ( "executionStats")
위의 명령은 평가 된 메소드의 executionStats를 보여줍니다.
> db.inventory.find ({status : "A"}, { "size.uom": 0}) .explain ( "executionStats")
결과는 "queryPlanner", "executionStats", "serverInfo". 우리는 "executionStats"의 값을보고 싶습니다.
nReturned : Shows the number of results of the query.
executionTimeMillis : Shows the total time in milliseconds required for query selection and execution.
TotalKeysExamined : Number of index keys scanned.
TotalDocsExamined : Number of documents scanned.
executionStages : Details the completed execution.
Update
업데이트 작업
업데이트 작업은 컬렉션의 기존 문서를 수정합니다.
업데이트는 문서에서 주어진 키의 값만 변경합니다.
db. $ (collectionName) .updateOne ()
db. $ (collectionName) .updateMany ()
_id 필드를 제외한 문서의 전체 내용을 바꿉니다.
db. $ (collectionName) .replaceOne ()
문서를 업데이트하기 위해, MongoDB는 업데이트 연산자 인 $ set을 제공하여 필드 값을 수정합니다.
다음 예제에서는 인벤토리 컬렉션의 updateOne () 메서드를 사용하여 상태가 "A"인 첫 번째 문서를 업데이트합니다.
> db.inventory.find({status:"A"})
> db.inventory.updateOne(
{ status : "A" },
{ $set: { qty : 200 }}
)
> db.inventory.find({status:"A"})
다음 예제에서는 인벤토리 컬렉션에서 updateMany () 메서드를 사용하여 qty가 100 미만인 문서를 업데이트합니다.
> db.inventory.find( {qty:{$lt:100}})
> db.inventory.updateMany(
{ qty : { $lt : 100 } },
{ $set: { status : "P" }}
)
> db.inventory.find( {qty:{$lt:100}})
Replace
_id 필드를 제외한 문서의 전체 내용을 바꾸려면 완전히 새로운 문서를 replaceOne ()의 두 번째 인수로 전달합니다.
db.collection.replaceOne(
<filter>,
<replacement>
)
필터가 업데이트의 선택 기준입니다. 대체 문서가 대체 문서입니다.
_id 필드가 불변이므로 _id 필드를 생략 할 수 있습니다. _id 필드를 포함하면 현재 값과 동일한 값을 가져야합니다.
> db.inventory.find({status:"P"})
> db.inventory.replaceOne (
{ status : "P" },
{ status : "P", instock : [ { warehouse : "A", qty: 60 }, { warehouse : "B", qty : 40 } ] }
)
> db.inventory.find({status:"P"})
Delete
- 삭제 작업
삭제 작업은 컬렉션에서 문서를 제거합니다.
db. $ (collectionName) .deleteOne ()
db. $ (collectionName) .deleteMany ()
지정된 필터와 일치하는 단일 문서를 삭제하려면 deleteOne () 메서드를 사용합니다.
다음 예제에서는 상태가 "A"인 첫 번째 문서를 삭제합니다.
> db.inventory.find({status:"A"})
> db.inventory.deleteOne( { status : "A" } )
> db.inventory.find({status:"A"})
삭제 기준과 일치하는 모든 문서를 삭제하려면 deleteMany () 메서드에 필터 매개 변수를 전달합니다.
다음 예에서는 상태 필드가 "P"인 인벤토리 모음에서 모든 문서를 제거합니다.
> db.inventory.find({status:"P"})
> db.inventory.deleteMany( { status : "P" } )
> db.inventory.find({status:"P"})
다음 예는 컬렉션에서 모든 문서를 제거합니다.
> db.inventory.find({})
> db.inventory.deleteMany( { } )
> db.inventory.find({})
> exit
zips 데이터셋 사용
MongoDB 공식 사이트에서 제시하는 json 파일의 데이터셋을 사용해보겠습니다.
http://media.mongodb.org/zips.json
각 필드의 설명은 다음과 같습니다.
_id : zip code의 문자열 입니다.
city : 도시 이름 field
state : 2개의 문자로 구성된 주 이름 field
pop : 인구 수
loc : 위도와 경도의 pair filed
$ wget http://media.mongodb.org/zips.json
docker cp 명령으로 zips.json 파일을 mongodb 컨테이너에 복사하십시오.
docker cp CONTAINER : SRC_PATH DEST_PATH
docker cp SRC_PATH CONTAINER : DEST_PATH
docker cp 유틸리티는 SRC_PATH의 내용을 DEST_PATH에 복사합니다.
컨테이너의 파일 시스템에서 로컬 시스템으로 복사하거나 역순으로 수행 할 수 있습니다.
첫 번째 명령은 CONTAINER의 SRC_PATH를 로컬 DEST_PATH에 복사하는 것입니다.
두 번째 명령은 로컬 시스템의 SRC_PATH를 CONTAINER의 DEST_PATH로 복사하는 것입니다.
$ docker cp zips.json mongodb:/zips.json
다음 명령을 사용하여 mongoDB의 zipcodes 컬렉션으로 zips.json 파일 가져 오기
도커 exec -it CONTAINER COMMAND
mongoimport --collection COLLECTION --file FILEPATH -u 사용자 -pPASSWORD --authenticationDatabase admin
첫 번째 명령은 실행중인 CONTAINER에서 COMMAND를 실행하는 것입니다.
두 번째 명령은 MongoDB에 인증 할 USER에 COLLECTION에 FILEPATH를 삽입하는 것입니다.
$ docker exec -it mongodb mongoimport --collection zipcodes --file zips.json -u mongoadmin -psecret --authenticationDatabase admin
$ docker exec -it mongodb mongo -u mongoadmin -psecret --authenticationDatabase admin
zipcodes 컬렉션을 살펴봅시다.
> db.zipcodes.find( {} )
Aggregation
aggregate () 메서드는 aggregate 파이프 라인을 사용하여 문서를 집계 된 결과로 처리합니다.
aggregate 파이프 라인은 단계로 구성됩니다.
match
문서를 필터링하여 지정된 조건과 일치하는 문서 만 다음 파이프 라인 단계로 전달합니다.
{$ match : {<query>}}
$ match는 쿼리 조건을 지정하는 문서를 사용합니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} } ] )
이것은 find 쿼리를 사용하는 다음 작업과 동일합니다.
> db.zipcodes.find( { city: "GOSHEN" } )
project
요청 된 필드가있는 문서를 파이프 라인의 다음 단계로 전달합니다.
{$ project : {<specification (s)>}}
$ 프로젝트는 필드의 포함, _id 필드의 억제, 새로운 필드의 추가 및 기존 필드의 값 재설정을 지정할 수있는 문서를 사용합니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$project: { _id: 0, city: 1, pop: 1 } } ] )
limit
파이프 라인의 다음 단계로 전달되는 문서 수를 제한합니다.
{$ limit : <양의 정수>}
$ limit는 전달할 최대 문서 수를 지정하는 양의 정수입니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$limit: 5}, {$project: { _id: 0, city: 1, pop: 1 } } ] )
모든 입력 문서를 정렬하여 정렬 된 순서로 파이프 라인에 반환합니다.
{$ sort : {<field1> : <sort order>, <field2> : <sort order> ...}}
$ sort는 정렬 할 필드와 각 정렬 순서를 지정하는 문서를 사용합니다.
<정렬 순서>는 1 또는 -1이 될 수 있습니다. 1을 사용하여 오름차순을 지정합니다. 내림차순을 지정하려면 -1을 지정합니다.
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$sort: {pop: 1} }, {$limit: 5}, {$project: {_id: 0, city: 1, pop: 1 } } ] )
> db.zipcodes.aggregate( [ {$match: {city: "GOSHEN"} }, {$sort: {pop: -1} }, {$limit: 5}, {$project: { _id: 0, city: 1, pop: 1 } } ] )
두 값을 비교하여 리턴합니다.
첫 번째 값이 두 번째 값보다 크거나 같으면 True입니다.
첫 번째 값이 두 번째 값보다 작으면 거짓입니다.
{$ gte : [<expression1>, <expression2>]}
> db.zipcodes.aggregate( [
{$match: {city: "GOSHEN"} },
{$project: {_id: 0, city: 1, pop: 1,
popGte: { $gte: [ "$pop", 1000 ] } } }
] )
group
지정된 표현식으로 문서를 그룹화하고 (_id 필드로 정의) 그룹화 한 후 다음 단계로 출력합니다.
출력 문서에는 키별로 구별되는 그룹을 포함하는 _id 필드가 있습니다.
{$ group : {_id : <expression>, <field1> : {<accumulator1> : <expression1>},}}}
_id 및 <accumulator> 식은 유효한 식을 모두 허용 할 수 있습니다.
<accumulator> 연산자는 다음 누적 연산자 중 하나 여야합니다.
$ first : 각 그룹의 첫 번째 문서에서 값을 반환합니다.
$ last : 각 그룹에 대한 마지막 문서의 값을 반환합니다.
$ sum : 숫자 값의 합을 구합니다.
$ avg : 숫자 값의 평균을 반환합니다.
주(state)마다 가장 큰 도시 출력합니다.
> db.zipcodes.aggregate( [
{ $sort: { state: 1, pop: -1 } },
{ $group: { _id: "$state", biggestPopCity: { $first: "$city"}, biggestPopState: { $first: "$pop" } } },
{ $sort: { _id: 1 } },
] )
주(state)마다 가장 작은 도시를 출력합니다.
> db.zipcodes.aggregate( [
{ $sort: { state: 1, pop: -1 } },
{ $group: { _id: "$state", smallestPopCity: { $last: "$city"}, smallestPopState: { $last: "$pop" } } },
{ $sort: { _id: 1 } },
] )
천 만 인구 수 이상 주(state)를 출력합니다.
> db.zipcodes.aggregate( [
{ $group: { _id: "$state", totalPop: { $sum: "$pop" } } },
{ $match: { totalPop: { $gt: 10*1000*1000 } } }
] )
평균 도시의 수를 반환합니다.
> db.zipcodes.aggregate( [
{ $group: { _id: { state: "$state", city: "$city" }, pop: { $sum: "$pop" } } },
{ $group: { _id: "$_id.state", avgCityPop: { $avg: "$pop" } } }
] )
Index
MongoDB의 인덱스
트래버스하기 쉬운 형식으로 데이터 세트를 저장하는 특수 데이터 구조
특정 필드 또는 필드 세트의 값은 필드 값에 의해 정렬되어 저장됩니다.
MongoDB에서 쿼리의 효율적인 실행을 지원합니다.
인덱스가 없다면, MongoDB는 전체 콜렉션 스캔을 수행해야합니다
인덱스 및 쿼리 예제
기본적으로 인덱스는 _id 필드로 생성됩니다.
> db.zipcodes.getIndexes()
v는 인덱스 포멧 버전입니다.
key는 인덱스의 value입니다. 1은 오름차순입니다.
name은 인덱스의 이름입니다.
ns는 인덱스의 네임스페이스 입니다.
zipcodes 컬렉션에는 다음 샘플 문서와 유사한 문서가 들어 있습니다.
다음 명령으로 색인을 작성할 수 있습니다.
> db.collection.createIndex ({key : value})
인덱스의 키 설정. 값은 1, -1이 될 수 있습니다.
1은 필드의 오름차순 색인입니다. -1은 내림차순 색인입니다.
다음 작업은 zipcodes 컬렉션의 pop 필드에 오름차순 색인을 만듭니다.
> db.zipcodes.createIndex ({pop : 1}) // 키가 {pop : 1} 인 인덱스를 만듭니다.
"createdCollectionAutomatically": false 인덱스 작성의 일부로 자동으로 콜렉션이 작성되지 않았습니다.
"numIndexesBefore": 1이 인덱스를 만들기 전에 인덱스 수를 1
"numIndexesAfter": 2 이제이 컬렉션에 총 2 개의 인덱스가 있습니다.
> db.zipcodes.createIndex( { pop : 1 } )
팝 인덱스가 추가 된 것을 볼 수 있습니다.
> db.zipcodes.getIndexes ()
이제 2 개의 인덱스 _id 및 pop이 있습니다.
> db.zipcodes.getIndexes()
작성된 색인은 다음 명령과 같이 필드 팝에서 선택한 조회를 지원합니다.
> db.zipcodes.find ({pop : 100})
> db.zipcodes.find ({pop : {$ lt : 100}}) # 더 많은 것을 위해 "it"을 입력하십시오
sort () 메소드를 사용하여 질의 결과를 정렬 할 수있다.
정렬 ({key : value})
sort 매개 변수에 정렬 기준이되는 키 (필드)를 지정하고 1 또는 -1 값을 사용하여 오름차순 또는 내림차순 정렬을 지정합니다.
> db.zipcodes.find ({pop : 100}) .sort ({_id : 1}) // 결과를 오름차순 정렬로 표시하십시오.
> db.zipcodes.find ({pop : 100}) .sort ({_id : -1}) // 결과를 내림차순 정렬로 표시합니다.
다음 명령은 상태별로 오름차순 정렬을 지정하고 _id 필드로 오름차순 / 내림차순 정렬을 지정합니다.
> db.zipcodes.find ({pop : 100}) .sort ({state : 1, _id : 1})
> db.zipcodes.find ({pop : 100}) .sort ({state : 1, _id : -1})
Compound Index
복합 색인은 콜렉션의 문서에서 여러 필드에 대한 참조를 보유합니다. 여러 필드에서 일치하는 쿼리를 지원합니다.
복합 인덱스는 인덱스에 대해 순차적으로 정렬합니다.
구문 : db. $ (collection) .createIndex ({index-key1 : order, index-key2 : order, ...})
다음 작업은 _id, pop 및 state에 오름차순 색인을 만듭니다.
> db.zipcodes.createIndex ({_id : 1, pop : 1, state : 1})
추가 된 복합 색인을 볼 수 있습니다.
> db.zipcodes.getIndexes ()
Index prefix
인덱스 필드의 부분 집합
복합 색인의 경우
{_id : 1, 팝 : 1, 상태 : 1}
색인 접두어
{_id : 1}
{_id : 1, pop : 1}
인덱스 접두사에 대한 쿼리는 성능 이점도 얻습니다.
_id 필드
_id 필드와 pop 필드
_id 필드와 팝 필드 및 상태 필드
쿼리에 인덱스 접두사를 사용하려면 모든 키에 지정된 정렬 방향이 일치해야합니다.
복합 색인 {_id : 1, pop : 1, state : 1}은 정렬을 지원할 수 있습니다.
dropIndex () 메소드를 사용하여 인덱스를 삭제할 수 있습니다.
db.collection.dropIndex (indexName) // 이름이있는 인덱스를 삭제합니다.
db.collection.dropIndex (indexKey) // 키를 사용하여 인덱스를 삭제합니다.
getIndexes () 메소드를 통해 indexName, indexKey를 확인할 수 있습니다.
> db.zipcodes.getIndexes ()
인덱스 이름을 확인하십시오.
> db.zipcodes.getIndexes ()
인덱스 이름에 "pop_1"이있는 인덱스를 삭제하십시오.
> db.zipcodes.dropIndex ( "pop_1")
인덱스 삭제되었는지 확인할 수 있습니다.
> db.zipcodes.getIndexes ()
explain 메소드로 executionStats 파트를 점검하십시오.
> db.zipcodes.find( {"city":"MOUNT TOM"} ).explain("executionStats")
29353 문서를 스캔하는 데 14 밀리 초가 소요되었습니다.
zipcodes 컬렉션의 도시 필드에 오름차순 색인 만들기
> db.zipcodes.createIndex( { "city" : 1 } )
executionStats를 다시 확인하십시오.
> db.zipcodes.find( {"city":"MOUNT TOM"} ).explain("executionStats")
'Google Cloud Platform' 카테고리의 다른 글
| Google Cloud Platform 이용한 엔티티와 감정 분석 Natural Language API (0) | 2018.06.05 |
|---|---|
| MapReduce 프로그래밍(Hadoop) using GCP DataProc (0) | 2018.06.04 |
| Google Cloud Platform Cloud Vision API를 이용한 이미지, 얼굴 Detection (1) | 2018.04.11 |
| Google Cloud Platform 이용한 텍스트 카테고리 분류 Natural Language API (1) | 2018.04.10 |
| Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API (1) | 2018.04.10 |