Google Cloud Platform 이용한 텍스트 카테고리 분류 Natural Language API

Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API
첫 링크 글에서 API_KEY Set up을 따라하면서 진행해주세요!

Natural Language API
기사(article) 분류(Classification)
Natural Language API의 classifyText 메소드를 사용하면 단일 API 호출로 텍스트 데이터를 카테고리(category)로 정렬할 수 있습니다. 이 method는 텍스트 문서에 적용되는 내용을 카테고리(category)의 목록으로 반환합니다. 이러한 카테고리(category)는 /Computers & Electronics와 같은 광범위한 범주에서 / Computers & Electronics / Programming / Java (Programming Language)와 같이 매우 특정한 범주에 이르기까지 다양합니다. 700 개가 넘는 범주의 전체 목록을 여기에서 찾을 수 있습니다.
https://cloud.google.com/natural-language/docs/categories

하나의 기사(article)를 분류하여 시작한 다음, 이 방법을 사용하여 큰 뉴스 corpus를 이해하는 방법을 살펴 보겠습니다. 먼저 음식 섹션의 New York Times 기사에서 이 제목과 설명을 봅시다.
“A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.”
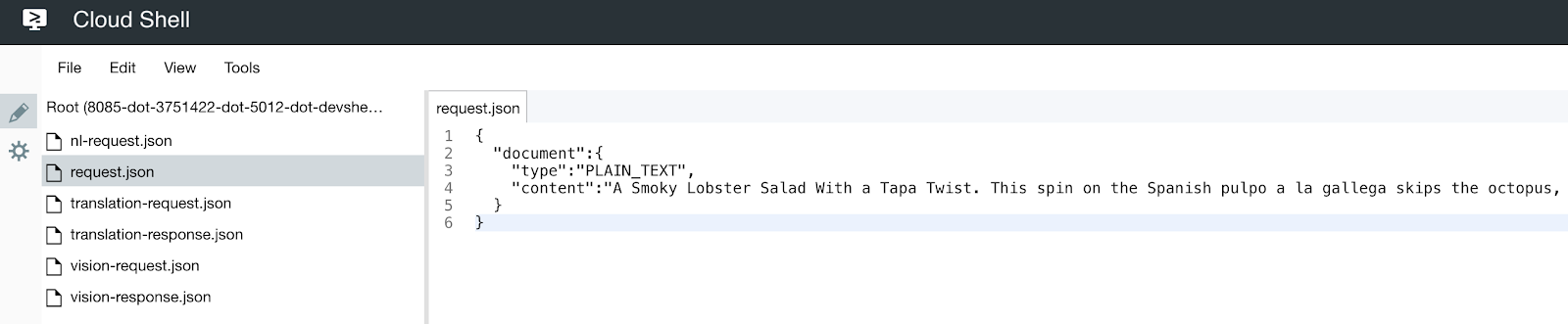
Cloud Shell 환경에서 아래 코드로 request.json 파일을 생성. 원하는 명령 줄 편집기 (nano, vim, emacs) 중 하나를 사용하여 파일을 만들거나 Cloud Shell 코드 편집기를 사용할 수 있습니다.

request.json 이라는 이름으로 파일을 생성하고 다음의 코드를 채워 넣습니다.
{
"document":{
"type":"PLAIN_TEXT",
"content":"A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes."
}
}

자 이제, Natural Language API의 classifyText method를 호출하기 위해 curl을 이용해 request.json 파일을 전송합니다.
$ curl "https://language.googleapis.com/v1/documents:classifyText?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
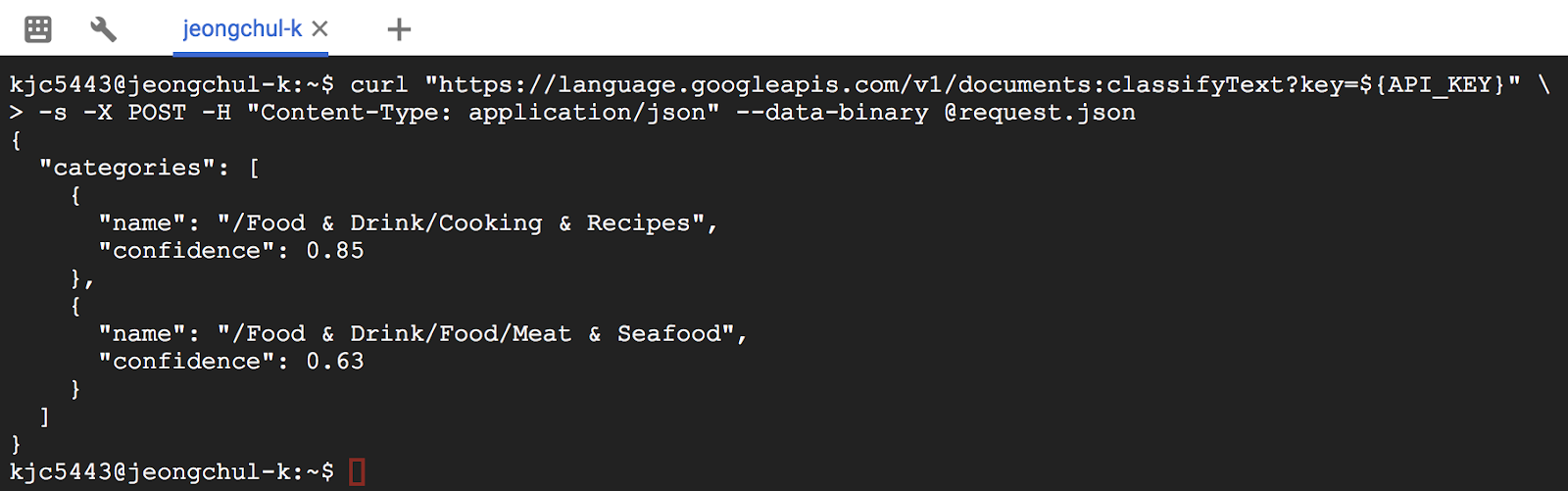
위의 문장에 대해서 2개의 Category를 반환 했습니다.
이 텍스트는 조리법이거나 해산물을 포함한다고 명시적으로 언급하지는 않지만 API는 이를 분류 할 수 있습니다. 단일 기사를 분류하는 것은 좋지만 이 기능의 힘을 실제로 보려면 많은 텍스트 데이터를 분류해봅시다.
Text dataset 분류(Classification)
classifyText 메소드를 이해하기 위해서, 많은 텍스트가 포함된 데이터 세트인 BBC 뉴스 기사의 공용 데이터 세트를 사용해봅시다. 이 데이터 세트는 2004-2005 년의 5 개 주제 분야 (비즈니스, 엔터테인먼트, 정치, 스포츠, 기술)의 2,225 개의 기사로 구성됩니다.이 기사의 일부는 공개 Google Cloud Storage 버킷에 있습니다. 각 기사는 .txt 파일에 있습니다.
http://mlg.ucd.ie/datasets/bbc.html

데이터를 검사하여 Natural Language API로 보내려면 Python 스크립트를 작성하여 Cloud Storage의 각 텍스트 파일을 읽고 classifyText method으로 보내고 결과를 BigQuery 테이블에 저장합니다. BigQuery는 Google 클라우드의 대형 데이터웨어 하우스 도구로 대규모 데이터 세트를 쉽게 저장하고 분석 할 수 있습니다.
작업 할 텍스트의 유형을 보려면 다음 명령을 실행하여 기사 하나를 봅니다 (gsutil은 Cloud Storage의 명령 줄 인터페이스를 제공합니다.)
$ gsutil cat gs://text-classification-codelab/bbc_dataset/entertainment/001.txt

$ gsutil cat gs://text-classification-codelab/bbc_dataset/
$ gsutil ls gs://text-classification-codelab/bbc_dataset/tech/

카테고리화된 텍스트 데이터를 위한 BigQuery Table 생성하기
Natural Language API로 텍스트를 보내기 전에 각 기사(article)의 텍스트(text)와 범주(category)를 저장할 위치가 필요합니다.
콘솔에서 BigQuery로 이동합니다.

다음의 사이트로 이동합니다.

나의 프로젝트 이름에서 드롭다운(dropdown) 버튼을 클릭하여 “Create new dataset” 버튼을 클릭합니다.

Dataset ID에 news_bbc_dataset이라는 이름을 지정합시다.
Dataset location 및 Data expiration 필드에 기본값을 그대로 둘 수 있습니다.
OK 버튼을 클릭합니다.

생성된 데이터셋 이름에 마우스를 이동하고 드롭다운 메뉴를 선택하여 “Create new table“ 버튼을 클릭합니다.

원본 데이터에서 "Create empty table"를 선택합니다. 그런 다음 테이블에 article_data라는 이름을 지정하고 스키마에 다음 3 개의 필드(article_text, category, confidence)를 추가하고 “Create Table” 버튼을 클릭합니다.

테이블(table)이 생성된 것을 볼 수 있습니다.

현재 테이블은 비어 있습니다. Cloud Storage에 있는 article을 읽어와 Natural Language API의 분류(classification)를 돌리고 나온 결과를 BigQuery에 저장합니다.
News data 분류(Classification) and BigQuery 결과 저장
Natural Lanaguage API에 뉴스 데이터를 보내기위한 스크립트를 작성하기 전에 서비스 계정을 만들어야합니다.
이것은 Python 스크립트에서 Natural Language API 및 BigQuery에 인증하는 데 사용됩니다.
먼저 Cloud Shell로 돌아가서 Cloud 프로젝트의 이름을 환경 변수로 내 보냅니다.
<your_project_name>을 본인 프로젝트 이름으로 변경합니다.
$ export PROJECT=<your_project_name>
다음의 명령어로 Cloud Shell로부터 service account를 생성합니다.
$ gcloud iam service-accounts create my-account --display-name my-account
$ gcloud projects add-iam-policy-binding $PROJECT --member=serviceAccount:my-account@$PROJECT.iam.gserviceaccount.com --role=roles/bigquery.admin
$ gcloud iam service-accounts keys create key.json --iam-account=my-account@$PROJECT.iam.gserviceaccount.com
$ export GOOGLE_APPLICATION_CREDENTIALS=key.json

이제 텍스트 데이터를 Natural Language API로 보낼 준비가 되었습니다.
이를 위해 Google Cloud 용 Python 모듈을 사용하여 Python 스크립트를 작성합시다.
어떤 언어에서나 똑같은 것을 성취 할 수 있습니다. cloud client 라이브러리(library)가 많이 있습니다.
classify-text.py라는 파일을 만들고 다음 파일을 복사하십시오. YOUR_PROJECT를 본인 프로젝트의 이름으로 대체합니다.
from google.cloud import storage, language, bigquery
# Set up our GCS, NL, and BigQuery clients
storage_client = storage.Client()
nl_client = language.LanguageServiceClient()
# TODO: replace YOUR_PROJECT with your project name below
bq_client = bigquery.Client(project='YOUR_PROJECT')
dataset_ref = bq_client.dataset('news_bbc_dataset')
dataset = bigquery.Dataset(dataset_ref)
table_ref = dataset.table('article_data') # Update this if you used a different table name
table = bq_client.get_table(table_ref)
# Send article text to the NL API's classifyText method
def classify_text(article):
response = nl_client.classify_text(
document=language.types.Document(
content=article,
type=language.enums.Document.Type.PLAIN_TEXT
)
)
return response
rows_for_bq = []
files = storage_client.bucket('text-classification-codelab').list_blobs()
print("Got article files from GCS, sending them to the NL API (this will take ~2 minutes)...")
# Send files to the NL API and save the result to send to BigQuery
for file in files:
if file.name.endswith('txt'):
article_text = file.download_as_string()
nl_response = classify_text(article_text)
if len(nl_response.categories) > 0:
rows_for_bq.append((article_text, nl_response.categories[0].name, nl_response.categories[0].confidence))
print("Writing NL API article data to BigQuery...")
# Write article text + category data to BQ
errors = bq_client.create_rows(table, rows_for_bq)
assert errors == []

$ python classify-text.py

위의 스크립트를 완료하는 데 약 2분정도 걸리며, 실행 중에 어떤 일이 일어나는지 살펴봅시다.
우리는 google-cloud Python client library(https://googlecloudplatform.github.io/google-cloud-python/)를 사용하여
Cloud Storage, Natural Language API 및 BigQuery에 액세스합니다. 먼저, 각 서비스에 대해 클라이언트(client)가 생성됩니다. BigQuery 테이블에 참조가 생성됩니다. 파일(files)은 공용 버킷의 각 BBC 데이터 세트 파일에 대한 참조입니다. 이 파일들을 반복하고, 기사(article)을 문자열로 다운로드하고, 각각을 classify_text 함수의 Natural Language API로 보냅니다. Natural Language API가 카테고리를 반환하는 모든 기사의 경우 기사과 해당 카테고리 데이터가 rows_for_bq 목록에 저장됩니다. 각 기사를 분류하면 데이터가 create_rows ()를 사용하여 BigQuery에 삽입됩니다.
스크립트 실행이 완료되면 기사 데이터가 BigQuery에 저장되었는지 확인해야 합니다.

BigQuery에서 article_data 테이블을 클릭하고 “Query Table” 버튼을 클릭합니다.

새로운 쿼리(Query) 상자에서 다음의 Query로 입력합니다.
SELECT * FROM [jeongchul-k:news_bbc_dataset.article_data] LIMIT 1000
“RUN QUERY” 버튼을 클릭합니다.
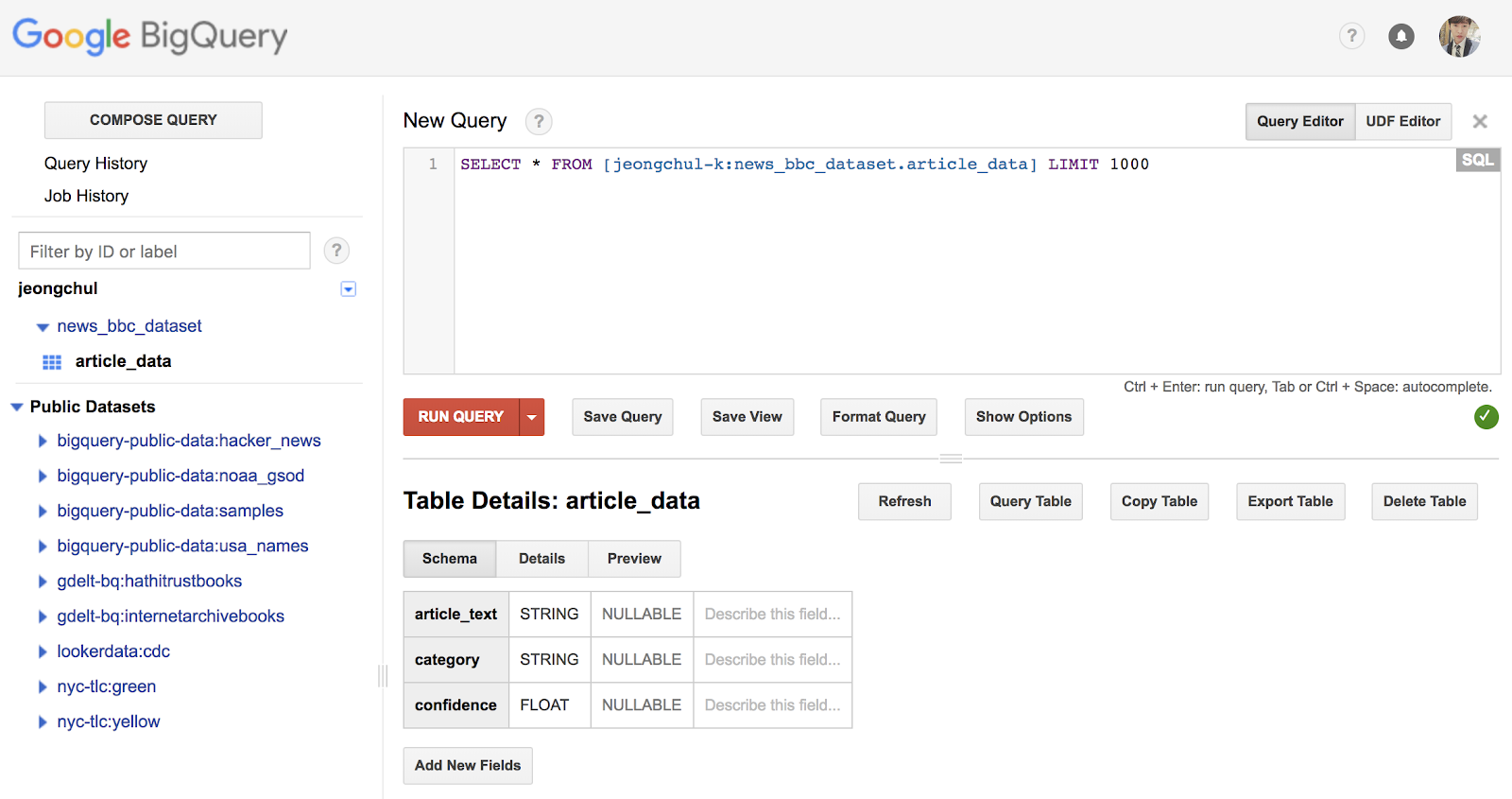
실행된 결과가 Results 로 보여집니다. category field는 Natural Language API가 기사에 대해 반환한 첫 번째 category의 이름을 가지며, confidence는 0과 1 사이의 값으로 API가 기사를 올바르게 분류한 확신도(confidence)를 나타냅니다.

table에서 다른 column을 확인하기 위해 옆으로 드래그해봅시다.
각각의 기사마다 category 분류된 것을 확인할 수 있고, 분류에 대한 확신도(confidence)를 확인할 수 있습니다.
Download sa CSV나 Download as JSON 또는 Save to Google Sheets에 저장합니다.
Save to Google Sheets 버튼을 클릭합니다.
계정을 선택합니다.

허용 버튼을 클릭합니다.

Click to View 버튼을 클릭하면 결과를 Google Sheet에서 확인할 수 있습니다.
이쁘게 탭의 크기를 조정해보았습니다.

BigQuery를 사용하여 분석
먼저 데이터셋에서 가장 일반적인 범주(category)를 살펴봅시다.
BigQuery 콘솔에서 Compose Query 버튼을 클릭합니다.

다음의 쿼리를 입력합니다.
SELECT
category,
COUNT(*) c
FROM
[jeongchul-k.news_bbc_dataset.article_data]
GROUP BY
category
ORDER BY
c DESC
결과는 다음과 같습니다.

만약 / Arts & Entertainment / Music & Audio / Classical Music 같은 카테고리에 대한 기사를 찾고 싶다면 다음과 같은
쿼리(query)를 입력하세요.
SELECT * FROM [jeongchul-k.news_bbc_dataset.article_data]
WHERE category = "/Arts & Entertainment/Music & Audio/Classical Music"
결과를 확인해봅시다.

또는 Natural Language API가 반환한 Confidence가 90%가 넘는 기사(article)를 뽑아봅시다.
다음의 쿼리를 입력합니다.
SELECT
article_text,
category
FROM [jeongchul-k.news_bbc_dataset.article_data]
WHERE cast(confidence as float) > 0.9

블로그를 마치겠습니다. 고생했습니다.
'Google Cloud Platform' 카테고리의 다른 글
| MongoDB using Google Cloud Platform (1) | 2018.06.03 |
|---|---|
| Google Cloud Platform Cloud Vision API를 이용한 이미지, 얼굴 Detection (1) | 2018.04.11 |
| Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API (1) | 2018.04.10 |
| Deployments 관리 Kubernetes in Google Cloud Platform (0) | 2018.04.08 |
| Jenkins Kubernetes Google Cloud (2) | 2018.04.01 |
Google Cloud Platform 이용한 텍스트 카테고리 분류 Natural Language API
Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API
첫 링크 글에서 API_KEY Set up을 따라하면서 진행해주세요!
Natural Language API
기사(article) 분류(Classification)
Natural Language API의 classifyText 메소드를 사용하면 단일 API 호출로 텍스트 데이터를 카테고리(category)로 정렬할 수 있습니다. 이 method는 텍스트 문서에 적용되는 내용을 카테고리(category)의 목록으로 반환합니다. 이러한 카테고리(category)는 /Computers & Electronics와 같은 광범위한 범주에서 / Computers & Electronics / Programming / Java (Programming Language)와 같이 매우 특정한 범주에 이르기까지 다양합니다. 700 개가 넘는 범주의 전체 목록을 여기에서 찾을 수 있습니다.
https://cloud.google.com/natural-language/docs/categories
하나의 기사(article)를 분류하여 시작한 다음, 이 방법을 사용하여 큰 뉴스 corpus를 이해하는 방법을 살펴 보겠습니다. 먼저 음식 섹션의 New York Times 기사에서 이 제목과 설명을 봅시다.
“A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes.”
Cloud Shell 환경에서 아래 코드로 request.json 파일을 생성. 원하는 명령 줄 편집기 (nano, vim, emacs) 중 하나를 사용하여 파일을 만들거나 Cloud Shell 코드 편집기를 사용할 수 있습니다.
request.json 이라는 이름으로 파일을 생성하고 다음의 코드를 채워 넣습니다.
{
"document":{
"type":"PLAIN_TEXT",
"content":"A Smoky Lobster Salad With a Tapa Twist. This spin on the Spanish pulpo a la gallega skips the octopus, but keeps the sea salt, olive oil, pimentón and boiled potatoes."
}
}
자 이제, Natural Language API의 classifyText method를 호출하기 위해 curl을 이용해 request.json 파일을 전송합니다.
$ curl "https://language.googleapis.com/v1/documents:classifyText?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
위의 문장에 대해서 2개의 Category를 반환 했습니다.
이 텍스트는 조리법이거나 해산물을 포함한다고 명시적으로 언급하지는 않지만 API는 이를 분류 할 수 있습니다. 단일 기사를 분류하는 것은 좋지만 이 기능의 힘을 실제로 보려면 많은 텍스트 데이터를 분류해봅시다.
Text dataset 분류(Classification)
classifyText 메소드를 이해하기 위해서, 많은 텍스트가 포함된 데이터 세트인 BBC 뉴스 기사의 공용 데이터 세트를 사용해봅시다. 이 데이터 세트는 2004-2005 년의 5 개 주제 분야 (비즈니스, 엔터테인먼트, 정치, 스포츠, 기술)의 2,225 개의 기사로 구성됩니다.이 기사의 일부는 공개 Google Cloud Storage 버킷에 있습니다. 각 기사는 .txt 파일에 있습니다.
http://mlg.ucd.ie/datasets/bbc.html
데이터를 검사하여 Natural Language API로 보내려면 Python 스크립트를 작성하여 Cloud Storage의 각 텍스트 파일을 읽고 classifyText method으로 보내고 결과를 BigQuery 테이블에 저장합니다. BigQuery는 Google 클라우드의 대형 데이터웨어 하우스 도구로 대규모 데이터 세트를 쉽게 저장하고 분석 할 수 있습니다.
작업 할 텍스트의 유형을 보려면 다음 명령을 실행하여 기사 하나를 봅니다 (gsutil은 Cloud Storage의 명령 줄 인터페이스를 제공합니다.)
$ gsutil cat gs://text-classification-codelab/bbc_dataset/entertainment/001.txt
$ gsutil cat gs://text-classification-codelab/bbc_dataset/
$ gsutil ls gs://text-classification-codelab/bbc_dataset/tech/
카테고리화된 텍스트 데이터를 위한 BigQuery Table 생성하기
Natural Language API로 텍스트를 보내기 전에 각 기사(article)의 텍스트(text)와 범주(category)를 저장할 위치가 필요합니다.
콘솔에서 BigQuery로 이동합니다.
다음의 사이트로 이동합니다.
나의 프로젝트 이름에서 드롭다운(dropdown) 버튼을 클릭하여 “Create new dataset” 버튼을 클릭합니다.
Dataset ID에 news_bbc_dataset이라는 이름을 지정합시다.
Dataset location 및 Data expiration 필드에 기본값을 그대로 둘 수 있습니다.
OK 버튼을 클릭합니다.
생성된 데이터셋 이름에 마우스를 이동하고 드롭다운 메뉴를 선택하여 “Create new table“ 버튼을 클릭합니다.
원본 데이터에서 "Create empty table"를 선택합니다. 그런 다음 테이블에 article_data라는 이름을 지정하고 스키마에 다음 3 개의 필드(article_text, category, confidence)를 추가하고 “Create Table” 버튼을 클릭합니다.
테이블(table)이 생성된 것을 볼 수 있습니다.
현재 테이블은 비어 있습니다. Cloud Storage에 있는 article을 읽어와 Natural Language API의 분류(classification)를 돌리고 나온 결과를 BigQuery에 저장합니다.
News data 분류(Classification) and BigQuery 결과 저장
Natural Lanaguage API에 뉴스 데이터를 보내기위한 스크립트를 작성하기 전에 서비스 계정을 만들어야합니다.
이것은 Python 스크립트에서 Natural Language API 및 BigQuery에 인증하는 데 사용됩니다.
먼저 Cloud Shell로 돌아가서 Cloud 프로젝트의 이름을 환경 변수로 내 보냅니다.
<your_project_name>을 본인 프로젝트 이름으로 변경합니다.
$ export PROJECT=<your_project_name>
다음의 명령어로 Cloud Shell로부터 service account를 생성합니다.
$ gcloud iam service-accounts create my-account --display-name my-account
$ gcloud projects add-iam-policy-binding $PROJECT --member=serviceAccount:my-account@$PROJECT.iam.gserviceaccount.com --role=roles/bigquery.admin
$ gcloud iam service-accounts keys create key.json --iam-account=my-account@$PROJECT.iam.gserviceaccount.com
$ export GOOGLE_APPLICATION_CREDENTIALS=key.json
이제 텍스트 데이터를 Natural Language API로 보낼 준비가 되었습니다.
이를 위해 Google Cloud 용 Python 모듈을 사용하여 Python 스크립트를 작성합시다.
어떤 언어에서나 똑같은 것을 성취 할 수 있습니다. cloud client 라이브러리(library)가 많이 있습니다.
classify-text.py라는 파일을 만들고 다음 파일을 복사하십시오. YOUR_PROJECT를 본인 프로젝트의 이름으로 대체합니다.
from google.cloud import storage, language, bigquery
# Set up our GCS, NL, and BigQuery clients
storage_client = storage.Client()
nl_client = language.LanguageServiceClient()
# TODO: replace YOUR_PROJECT with your project name below
bq_client = bigquery.Client(project='YOUR_PROJECT')
dataset_ref = bq_client.dataset('news_bbc_dataset')
dataset = bigquery.Dataset(dataset_ref)
table_ref = dataset.table('article_data') # Update this if you used a different table name
table = bq_client.get_table(table_ref)
# Send article text to the NL API's classifyText method
def classify_text(article):
response = nl_client.classify_text(
document=language.types.Document(
content=article,
type=language.enums.Document.Type.PLAIN_TEXT
)
)
return response
rows_for_bq = []
files = storage_client.bucket('text-classification-codelab').list_blobs()
print("Got article files from GCS, sending them to the NL API (this will take ~2 minutes)...")
# Send files to the NL API and save the result to send to BigQuery
for file in files:
if file.name.endswith('txt'):
article_text = file.download_as_string()
nl_response = classify_text(article_text)
if len(nl_response.categories) > 0:
rows_for_bq.append((article_text, nl_response.categories[0].name, nl_response.categories[0].confidence))
print("Writing NL API article data to BigQuery...")
# Write article text + category data to BQ
errors = bq_client.create_rows(table, rows_for_bq)
assert errors == []
$ python classify-text.py
위의 스크립트를 완료하는 데 약 2분정도 걸리며, 실행 중에 어떤 일이 일어나는지 살펴봅시다.
우리는 google-cloud Python client library(https://googlecloudplatform.github.io/google-cloud-python/)를 사용하여
Cloud Storage, Natural Language API 및 BigQuery에 액세스합니다. 먼저, 각 서비스에 대해 클라이언트(client)가 생성됩니다. BigQuery 테이블에 참조가 생성됩니다. 파일(files)은 공용 버킷의 각 BBC 데이터 세트 파일에 대한 참조입니다. 이 파일들을 반복하고, 기사(article)을 문자열로 다운로드하고, 각각을 classify_text 함수의 Natural Language API로 보냅니다. Natural Language API가 카테고리를 반환하는 모든 기사의 경우 기사과 해당 카테고리 데이터가 rows_for_bq 목록에 저장됩니다. 각 기사를 분류하면 데이터가 create_rows ()를 사용하여 BigQuery에 삽입됩니다.
스크립트 실행이 완료되면 기사 데이터가 BigQuery에 저장되었는지 확인해야 합니다.
BigQuery에서 article_data 테이블을 클릭하고 “Query Table” 버튼을 클릭합니다.
새로운 쿼리(Query) 상자에서 다음의 Query로 입력합니다.
SELECT * FROM [jeongchul-k:news_bbc_dataset.article_data] LIMIT 1000
“RUN QUERY” 버튼을 클릭합니다.
실행된 결과가 Results 로 보여집니다. category field는 Natural Language API가 기사에 대해 반환한 첫 번째 category의 이름을 가지며, confidence는 0과 1 사이의 값으로 API가 기사를 올바르게 분류한 확신도(confidence)를 나타냅니다.
table에서 다른 column을 확인하기 위해 옆으로 드래그해봅시다.
각각의 기사마다 category 분류된 것을 확인할 수 있고, 분류에 대한 확신도(confidence)를 확인할 수 있습니다.
Download sa CSV나 Download as JSON 또는 Save to Google Sheets에 저장합니다.
Save to Google Sheets 버튼을 클릭합니다.
계정을 선택합니다.
허용 버튼을 클릭합니다.
Click to View 버튼을 클릭하면 결과를 Google Sheet에서 확인할 수 있습니다.
이쁘게 탭의 크기를 조정해보았습니다.
BigQuery를 사용하여 분석
먼저 데이터셋에서 가장 일반적인 범주(category)를 살펴봅시다.
BigQuery 콘솔에서 Compose Query 버튼을 클릭합니다.
다음의 쿼리를 입력합니다.
SELECT
category,
COUNT(*) c
FROM
[jeongchul-k.news_bbc_dataset.article_data]
GROUP BY
category
ORDER BY
c DESC
결과는 다음과 같습니다.
만약 / Arts & Entertainment / Music & Audio / Classical Music 같은 카테고리에 대한 기사를 찾고 싶다면 다음과 같은
쿼리(query)를 입력하세요.
SELECT * FROM [jeongchul-k.news_bbc_dataset.article_data]
WHERE category = "/Arts & Entertainment/Music & Audio/Classical Music"
결과를 확인해봅시다.
또는 Natural Language API가 반환한 Confidence가 90%가 넘는 기사(article)를 뽑아봅시다.
다음의 쿼리를 입력합니다.
SELECT
article_text,
category
FROM [jeongchul-k.news_bbc_dataset.article_data]
WHERE cast(confidence as float) > 0.9
블로그를 마치겠습니다. 고생했습니다.
'Google Cloud Platform' 카테고리의 다른 글
| MongoDB using Google Cloud Platform (1) | 2018.06.03 |
|---|---|
| Google Cloud Platform Cloud Vision API를 이용한 이미지, 얼굴 Detection (1) | 2018.04.11 |
| Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API (1) | 2018.04.10 |
| Deployments 관리 Kubernetes in Google Cloud Platform (0) | 2018.04.08 |
| Jenkins Kubernetes Google Cloud (2) | 2018.04.01 |