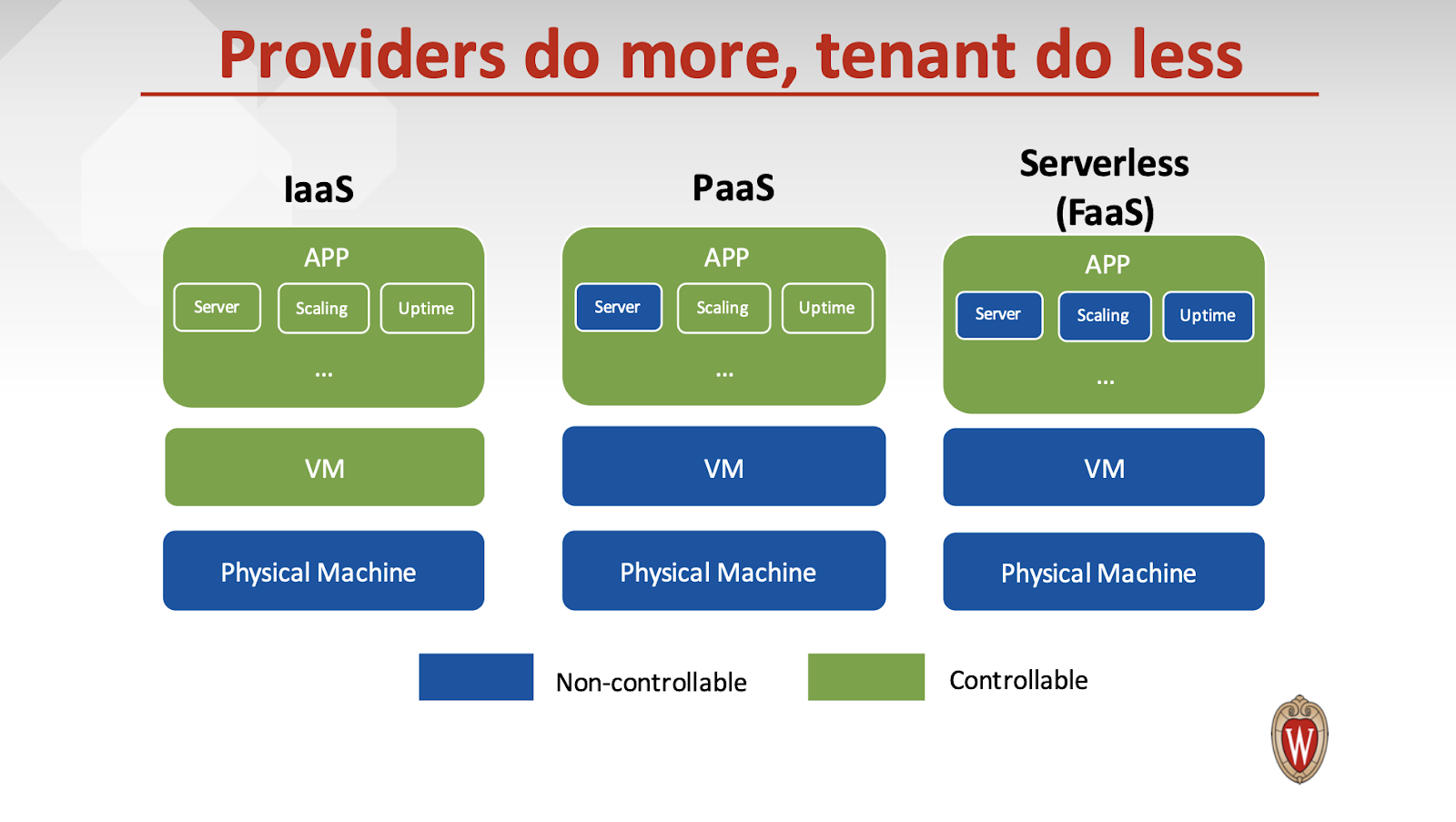
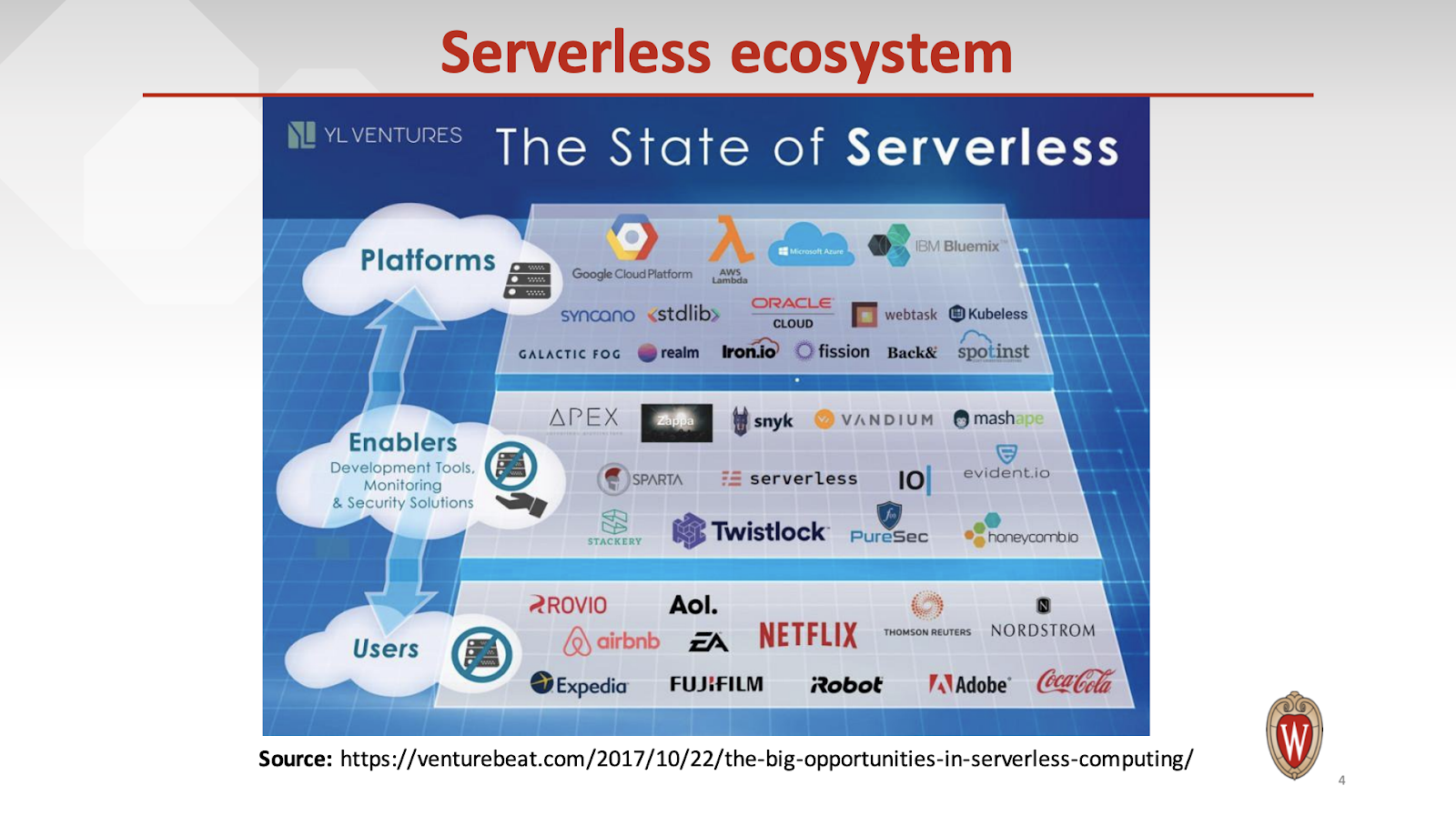
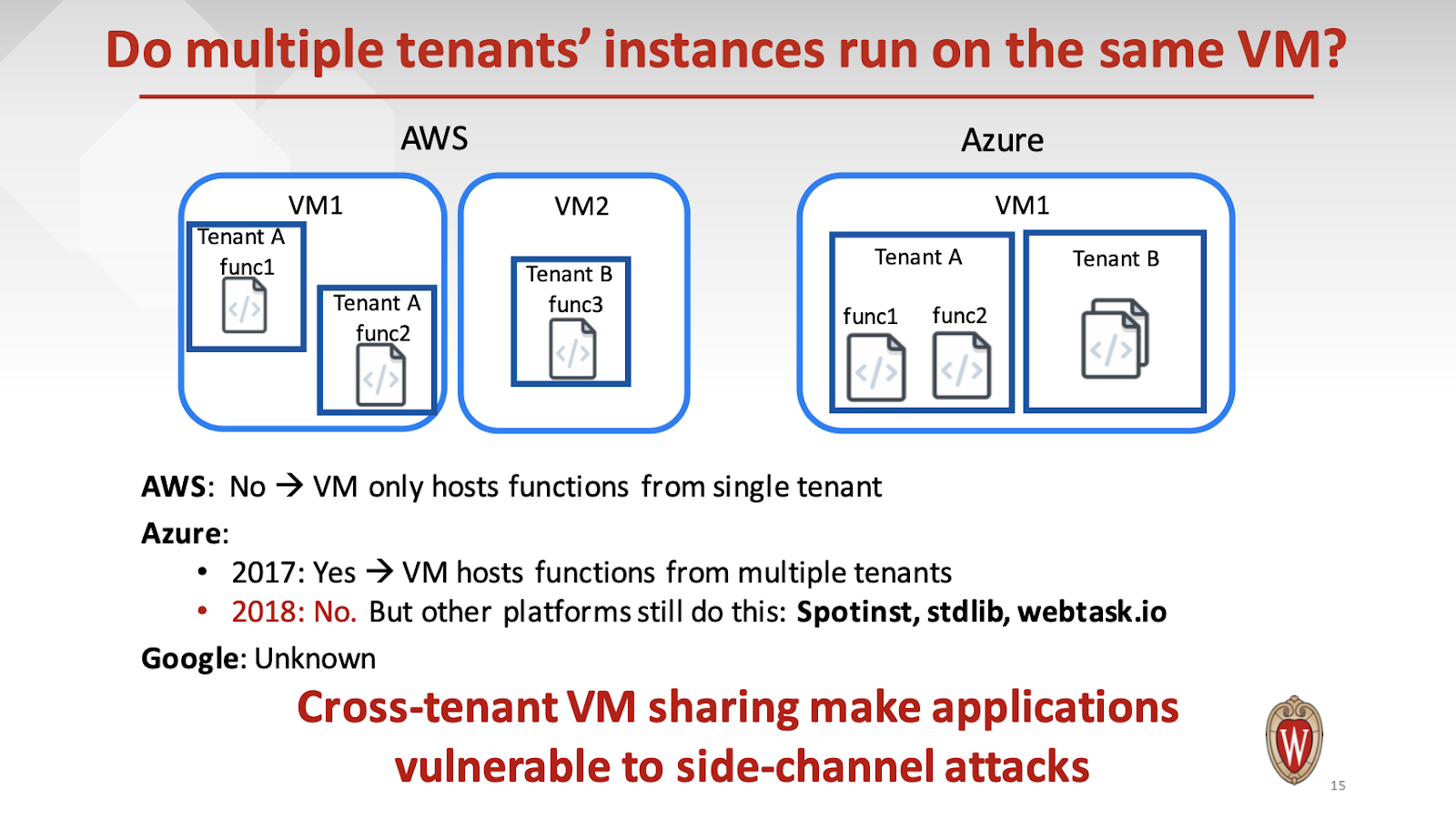
AWS Lambda, Google Cloud Functions, Azure Function 비교 논문 [Peeking Behind the Curtains of Serverless Platforms] Reference Liang Wang, UW-Madison; Mengyuan Li and Yinqian Zhang, The Ohio State University; Thomas Ristenpart, Cornell Tech; Michael Swift, UW-Madison Presentation PPT : https://www.usenix.org/conference/atc18/presentation/wang-liang Github code : https://github.com/liangw89/faas_measure 이번에 읽은 논문은 연구 주제와 비슷한 선행 논문입니다. Serverless Computing은 application에 대한 자원 관리와 스케일링(scaling)을 클라우드 사(AWS, Google, Azure)의 서비스로 관리되는 FaaS(Function-as-a Service) 기술입니다. 클라우드 3사의 서비스는 AWS Lambda, Google Cloud Functions, Azure Functions가 있습니다. 이 논문에서는 실제 클라우드 3사가 주장하는 서비스 스펙에 대해 실제 각종 성능 분석(scalability, coldstart latency, resource efficiency 등)을 진행했으며, 고객의 요구에 맞는 하드웨어 성능을 제공하고 있는 지 측정하였습니다. 3사의 Serverless 서비스에 대해 분석을 했다는 점이 새롭습니다. Serverless computing(FaaS)는 application 서비스 배포(deployment) 아키텍처는 사용자에게 서버와 시스템 관리에 대한비용을 줄여주는 서비스입니다. 아래의 그림을 보시면 IaaS와 PaaS 그리고 FaaS의 차이점을 보실 수 있습니다. 파란색 영역은 개발자가 컨트롤 할 수 없는 영역(Non-controllable)이며, 초록색 영역은 개발자가 컨트롤 할 수 있는 영역입니다. FaaS를 보시면 최소한의 Application 코드에 대해서만 개발을 하면 된다는 것입니다. 사용자는 단순 Memory 설정을 통해서 함수에 코드를 작성하면 되므로 코드 개발에만 집중하면 됩니다. 함수(Function)는 제한된 CPU 시간과 메모리의 Function Instance(VM 위에서 돌아가는 container나, sandbox)에서 실행됩니다. IaaS의 VM 인스턴스와는 달리 가격 책정 정책이 다릅니다. FaaS의 서비스는 호출되는 횟수와 호출 시 실행 시간과 설정한 메모리의 양에 따라서 가격이 측정되기 때문에 IaaS 서비스 보다는 저렴합니다. IaaS의 서비스는 시간당 가격이 측정되어 24시간 운영되는 VM instance보다는 가격적으로 비싸고, 실제 서버의 가용성(utilization) 측면에 있어서도 비용 낭비로 이어질 수 있습니다. AWS Lambda의 가격 정책을 보시죠. https://aws.amazon.com/ko/lambda/pricing/ AWS Lambda의 경우 컴퓨팅 요금 + 월별 요청 요금으로 받습니다. 컴퓨팅 금액은 AWS Lambda에 설정한 메모리의 초당 금액 * 실행 시간을 지불해야 하며, 월별 요청 금액은 1M(1,000,000) 요청 횟수당 가격이 붙습니다. Serverless 에코 시스템(ecosystem)을 보시면 Faas의 플랫폼을 제공하는 Platforms와 개발 API와 모니터링을 제공해주는 Enablers 그리고 실제 사용하는 Users(Netflix, airbnb, expedia, EA 등)들을 볼 수 있습니다. Serverless Computing은 연산량이 적은 작업 부하를 처리하기 위한 디자인 패턴으로 시작되었으나, 이제는 다양한 Application 개발을 위한 프로그래밍 모델로 사용되고 있습니다. 이에 따라 많은 개발자들은 Serverless Platform에 대해서 질문을 갖게 됩니다. DDoS 어택이나 보안에 대해 function은 안전한가? 또는 Serverless 플랫폼에 대해 보장된 성능(performance)를 제공하는가? 이 논문에서는 AWS Lambda와 Azure Functions 그리고 Google Cloud Functions의 자원 관리와 성능에 대해 연구를 진행하고 체계적으로 분리하고 CPU, I/O 그리고 네트워크 대역폭의 성능을 확인 하였고, 고객에게 성능을 보장하는 지 조사하였습니다. 또한 저자는 측정한 방법을 오픈 소스(open source)로 공개하였습니다. https://github.com/liangw89/faas_measure 이 논문의 highlight는 다음과 같습니다. - AWS Lambda는 최고의 확장성(scalability)와 아주 낮은 coldstart 지연 시간(latency)을 가지고 있으나, 동일한 계정의 function instances 간에 AWS는 자원 분리(isolation)의 부족으로 I/O, network, coldstart 성능은 19배로 낮습니다. - AWS Lambda 다음으로 GCF가 성능적으로 우수하였습니다. - Azure는 여러 유형의 VM을 호스트로 사용하기 때문에 성능의 변동량이 큽니다. - Azure는 연구 당시(2018년 5월) 다른 고객(tenant) 둘이 같은 VM에서 실행되도록 되었으며 이는 보안적 문제 요소가 있었습니다. Serverless 컴퓨팅에서 application은 하나 이상의 기능 구현으로 작은 개발 단위로 구성됩니다. 공급자가 되는 클라우드 사는 실행 환경을 제공하고, 자원(resource)를 동적으로 할당하여 확장성(scalability)과 가용성(availability)을 보장합니다. 최근 몇 년 동안 Amazon, Azure, Google 그리고 IBM을 비롯한 많은 클라우드 공급사는 Serverless computing 플랫폼을 개발하여 배포했습니다. 이러한 서비스는 자체 가지고 있는 서버를 Hypervisor를 이용해 Virtual Machine을 만들고 이 위에 Container 또는 다른 형태의 sandbox를 이용해 제한된 자원으로 생성하고 Lambda와 같은 함수를 실행하고 있습니다. 이 논문에서 얘기하는 function instances는 바로 function이 실행되는 container나 sandbox를 지칭합니다. 클라우드 AWS, Azure, Google Cloud의 Function Instances에 대한 요약은 다음의 표에 나와 있습니다. Function Instances는 다음에 발생할 요청을 처리하기 위해 재사용될 수 있습니다. 자 그래서 coldstart는 개념이 나옵니다. coldstart는 container를 새로 만들기 위해 걸리는 latency입니다. 이미 재사용되어 container를 생성 시간이 없고 오직 execution time만 있다면 warm-start라고 합니다. 이 container는 표에서 보이는 각 Timeout의 값에 따라 시간이 지나면 종료가 됩니다. AWS의 경우 300초(5분)이 지나면 container는 종료가 됩니다. coldstart의 latency는 5분이 되기 전에 반복적 호출로 해결할 수 있습니다. Serverless 서비스의 장점은 Function Instances가 유휴(idle) 상태라면 고객은 비용을 지불하지 않습니다. 함수가 실행되는 시간에만 비용을 지불하는 것이죠. AWS, Google은 미리 설정된 함수의 메모리에 가격을 붙이고, Azure는 실제 호출된 동안 사용된 메모리를 지불하며, 추가적으로 Google은 CPU 속도에 따라 요금을 달리 부과합니다. 이 논문에서는 측정 결과를 얻기 위해 동일한 함수의 설정과 작업 부하 그리고 동시 실행(concurrent request)을 조정하여 다양한 설정에서 동일한 실험을 반복했습니다. 함수를 측정하기 위해 측정 함수(measurement function)이라는 함수를 호출하였습니다. 측정하는 단계는 두 개의 작업입니다. (1) 호출하는 시간과 Function instance의 실시간 정보(CPU, Memory) 그리고 (2)는 local disk의 I/O 와 네트워크 처리량(throughput)입니다. 이 함수는 Linux의 proc 파일 시스템(procfs)에 실시간 정보를 수집합니다. 실행 시작과 종료 시간을 저장하고, 랜덤의 16 byte의 ASCII 코드로 구성된 Invocation(호출) ID로 분석하였습니다. 아래 그림의 방법은 Local 디스크는 영구적이지 않고, Function Instances와 동일한 수명을 가지고 있기 때문에 이를 통해 식별 하였습니다. 함수에서의 file write가 가능한 곳은 /tmp 입니다. 이곳에 파일을 작성하고 다른 Instance에 실행되었는지, 또는 coldstart인지 확인하였습니다. 실행되는 Function Instances(container 또는 sandbox)가 동일한 VM에서 실행되는지 확인하기 위해 다음의 그림에 나와 있습니다. AWS는 /proc/self/cgroup에서 확인하였으며, Azure는 WEBSITE_INSTANCE_ID라는 환경 변수를 통해 확인했으며, Google는 알려지지 않습니다. 이들이 실험한 곳은 AWS에서 us-east-1, Google은 us-central-1, Azure의 EAST US에서 실험 하였습니다. 여기서 각 VM들은 4GB의 RAM과 2개의 vCPU를 가졌다고 합니다. 이들은 다양한 언어로 측정했지만, 대부분의 실험은 Python 2.7과 Nodejs6을 사용하였습니다. 이 논문에서는 아키텍처를 추론하기 위해 (1)AWS, Google Cloud, Azure의 공식 문서와 글 그리고 (2) 5만번 이상의 측정을 통해 수집된 정보로 분석 하였습니다. AWS Lambda는 AWS EC2에서 실행 됩니다. (** 저도 연구를 통해 확인해 본 결과 t2.small, c3.large, c4.large 확인 했습니다 **) procfs를 통해 Function Instances(container, sandbox) 뿐만 아니라, Function Instances가 돌아가고 있는 VM의 정보도 프로파일링 할 수 있습니다. 이를 통해 VM이 어떤 EC2 타입이라는 정보도 유추할 수 있습니다. /proc/self/cgroup에서 root id(sandbox-root-)를 통해 식별할 수 있습니다. 이 연구에서는 2 vCPUs와 3.75GB RAM을 통해 c4.large 인스턴스와 비슷하다는 것을 알아냈습니다. 또한 /proc/uptime과 /proc/meminfo를 통해 동일한 커널 가동 시간과 메모리 사용 통계로 얻을 수 있습니다. 또한 uname을 통해 VM의 private IP를 얻을 수 있고 동일한 VM에서 동작하는 Function instances는 동일한 VM의 public IP와 private IP를 갖습니다. Azure는 Function Apps를 사용해 함수를 구성합니다. app은 function에 대한 실행 환경을 포함하는 container입니다. Azure의 경우 환경 변수인 WEBSITE_INSTANCE_ID를 통해 식별할 수 있었으며, 연구 조사 결과 VM은 vCPUs는 1, 2, 4개를 가지고 있습니다. Google은 procfs로부터 액세스할 수 있는 정보를 격리하고 필터링 합니다. 따라서 procfs에 있는 파일은 Function Instances의 사용 통계만 보고합니다. 또한 비활성화되어 실시간으로 정보를 얻을 수 있습니다. /proc/meminfo나 /proc/cpuinfo를 통해 Function Instances는 2GB RAM과 8개의 vCPU를 가지고 있음을 알 수 있습니다. 이전 보안 연구에 따르면 AWS EC2의 같은 위치에 있는 VM은 공격을 허용합니다. 고객(tenant)의 자원인 Function instances가 얼마나 잘 분리되어 있는지 조사하였습니다. AWS은 동일한 고객에게 생성된 Lambda는 같은 VM을 공유할 수 있습니다. 상세한 instance의 배치하는 알고리즘은 뒤에 설명합니다. 이 연구에서는 diskstats를 이용해 I/O 실험을 진행하였습니다. 두 계정에서 동시에 새로운 Lambda를 작성하고 임의의 byte를 쓰고 다른 Lambda에서 diskstats로 통계를 확인합니다. 1주일 동안 실험을 진행하였으나 coresidency는 발견되지 않았습니다. Azure Function의 경우 모든 고객이 동일한 VM 세트를 공유하는 Azure App 서비스의 일부입니다. 따라서 VM 자원도 공유했습니다. 2018년 5월 이전에는 다른 고객간에 동일한 VM을 공유했으나, 5월부터 더 이상 VM을 공유하지 않습니다. 이 연구에서는 Function Instances가 어떠한 VM에서 실행되는지 50000번 이상의 함수 실행으로 VM의 구성을 조사했습니다. Serverless 공급자들은 런타임 정보를 고객으로부터 완전히 숨길 수 없습니다. instance의 runtime과 backend에 대한 지식이 높다면 취약성을 쉽게 발견할 수 있습니다. /proc/cpuinfo의 모델 이름과 프로세서 그리고 /proc/meminfo의 MemTotla을 확인하고 다섯가지 유형의 모델을 확인했습니다. 2 vCPU(E5-2666, 2.9 GHz), 2 vCPU(E5-2680, 2.8GHz), 2 vCPU(E5-2676, 2.4GHz), 1 vCPU(E5-2676, 2.4GHz), 2 vCPU(E5-2686, 2.3GHz)입니다. 각각 비율적으로 20,447 VM 중에 59.3%, 37.5%, 3.1%, 0.01%, 0.09%가 나왔습니다. 다양한 VM 구성을 보여줍니다. 4,104의 VM 중에 vCPU 1개가 54%, vCPU 2개가 25%, vCPU 4개가 21%로 사용되 었습니다. 주어진 vCPU 에 대해 3개의 CPU 모델(Intel 2개, AMD 1개)가 있어 최소 9가지 다른 유형의 VM이 제공되고 있습니다. 정확한 모델명은 알 수 없으나 식별되는 구분 짓는 분류로 이들은 모델 버전은 (79, 85, 63, 45)로 각각 47.1%, 44.7%, 4.2%, 4.0%에 해당합니다. 여기서는 확장성(scalability)에 대해서 이야기 합니다. 동일한 메모리 크기 f1, f2, …, f40의 40개의 function을 생성하고 각 fi를 5*i번의 동시 요청(concurrent request)를 하였습니다. function은 간단하게 15초 sleep을 하고 실행됩니다. 각 VM 설정에 대해 50번씩 측정을 했습니다. AWS는 Concurrent execution에 대해서 다른 타 사보다 성능이 제일 좋습니다. AWS는 새로운 Function instance에 대해 최대 200개 까지 쉽게 확장할 수 있습니다. instance에 최대 가능한 메모리는 3,328MB입니다. AWS Lambda는 인스턴스 배치(placement) 문제를 bin-packing 문제로 취급하고, VM 메모리 사용률을 3,328로 나눈 값을 최대화하기 위해 기존 VM에 Function instance를 배치합니다. 동일한 실행에서의 VM 평균 메모리 사용률은 84.6% ~ 100% 사이였으며 중앙값(median)은 96.2% 였습니다. Azure 문서(documentation)에서는 최대 200개의 Function instance로 확장 가능하며, 10초마다 최대 하나의 instance가 시작될 수 있다고 명시되어 있습니다. 그러나 최대 10개의 Function instance만 동시 실행(Concurrent Execution)합니다. 동시에 실행 중 인 Function instance는 동일한 VM에 없었으며, 함께 배치하려고 시도하지 않았습니다. Azure Function은 1개의 vCPU VM에서 많이 실행됩니다. 다음의 표는 Azure에서 같은 위치에 존재(co-residency) 분석 결과를 보여줍니다. 일반적으로 낮은 성능의 VM에는 cpu contention 같은 성능 저하 문제가 발생하기 때문에 co-residency 는 적절하지 않습니다. 이후에 Azure는 2018년 5월 이후로 cross-tenant co-residency 문제를 해결하였습니다. Google이 HTTP 트리거 기능이 원하는 호출 속도로 신속하게 확장될 수 있다고 주장하지만, 이들의 연구 조사로는 Google은 원하는 확장성을 제공하지 못했습니다. 일반적으로, 낮은 동시성 레벨(예를 들어, 10)에 대해서 조차도 기대된 수의 인스턴스의 약 절반만이 요청되고 나머지는 큐잉되었습니다. 여기서는 Function instances의 coldstart latency에 대해 이야기 합니다. coldstart는 VM에서 새로운 container나 sandbox를 시작하고 런타임 환경을 설정하고, function을 배포하는 작업을 포함합니다. warm-start는 재사용성의 장점으로 요청을 처리하는데 시간이 적게 걸립니다. 여기서는 고유한 function을 생성하여 순차적으로 2번 실행하여 coldstart와 warmstart를 수집하여 AWS(25 ms), Google Cloud(79 ms), Azure(320 ms) 평균 warm start latency를 계산 하였습니다. 실제로 클라우드 공급사마다 다르겠지만 coldstart의 두 가지 유형이 있습니다. container가 다시 실행되거나, VM을 새로 시작할 수도 있습니다. 직관적으로 VM을 새로 시작하는 것이 coldstart의 latency가 길어야 합니다. VM을 새로 시작하는 것이 median 값에 39 ms 정도 오래 걸립니다. 제일 작은 VM 커널 가동 시간은 132초였습니다. 이는 호출 전에 이미 VM 시작되었음을 알 수 있습니다. 따라서 추가적인 지연은 VM을 새로 시작하는 것보다 스케줄링(scheduling : VM 선택)에 의해 발생할 가능성이 더 큽니다. AWS의 실험에서는 각 프로그래밍 언어 별로 latency를 측정하였습니다. python은 가장 낮은 latency를 가지고 있지만, java로 이루어진 함수는 824~976 ms로 latency가 가장 깁니다. 일반적으로 메모리가 증가함에 따라 coldstart의 latency는 감소합니다. AWS가 메모리의 크기에 비례해 CPU 전력을 할당한다는 것입니다. 더 많은 CPU 전력으로 환경 설정이 빨라집니다. Google의 coldstart의 latency는 110 ~ 493 ms 였습니다. 또한 Google은 메모리에 비례하여 CPU를 할당하지만, 메모리 크기는 AWS 보다 coldstart latency의 큰 영향을 미칩니다. Azure는 훨씬 오래 걸리지만 인스턴스에 항상 1.5 GB 메모리가 할당됩니다. coldstart의 median 값은 3,640 ms 였습니다. Azure는 이 문제를 플랫폼 설계와 엔지니어링 문제로 인식하고 개선하기 위해 노력하고 있습니다. Serverless 공급자는 여전히 활성 상태인 경우에도 Function instance를 종료할 수 있습니다. 여기서는 lifetime은 Function Instance가 활성 상태를 유지하는 가장 긴 시간으로 정의합니다. 고객은 application이 메모리 상태(예: db 연결)를 오래 유지하고 coldstart를 피할 수 있습니다. lifetime을 측정하기 위해 서로 다른 빈도로 7일 동안 측정하였습니다. Azure Function는 AWS Lambda와 Google Cloud Function 보다 긴 수명을 가집니다. AWS의 VM의 커널 가동 시간은 9.2 시간이 였습니다. 요청 빈도가 증가하면 VM의 lifetime이 짧아지는 경향이 있습니다. Google의 경우 작업량이 적고, 메모리가 적은 경우 새로운 VM을 시작하는 것으로 보여 coldstart로 인한 성능이 저하될 수 있습니다. 자원(resource)를 효율적으로 사용하기 위해, Serverless 공급자는 유휴(idle) VM 인스턴스를 종료하여 할당된 자원을 재활용해야 합니다. idle VM 인스턴스를 많이 유지하면 VM 메모리 자원이 낭비되므로 더 많은 coldstart를 발생하므로 적당한 자원 관리가 필요합니다. 이들은 1~120분 사이에 두 번 호출 하여 두 함 수가 동일한 Function Instance를 사용하는지 확인하였습니다. AWS의 VM은 최대 27분 동안 유지 되었습니다. 80%는 26분 후에 종료되었습니다. N개의 함수가 있다고 가정할 때, AWS는 2~3개의 Function instance가 남을 때까지 ~300초 마다 1/2씩 종료하고, 27분 후에 남은 Function instance를 종료합니다. Azure에서는 일관된 유휴 시간을 찾을 수 없었습니다. 다른 날에 반복 실험을 하여 최대 22, 40, 120분 이상인 것을 발견하였으며, Google의 경우는 최대 120분을 초과 하였습니다. 고객은 업데이트된 기능에 대해 새로운 코드로 Function이 처리되기를 원합니다. 그러나 실제로 요청시 이전 버전의 function(inconsistent function)이 호출되는 것을 볼 수 있었습니다. 이들은 동시 요청(concurrent request)의 수(k)를 1 또는 50으로 보내고, IAM role, 메모리 크기, 환경 변수 또는 함수 코드를 업데이트 한 후 다시 수행하였습니다. 주어진 환경에서 100회에 걸쳐 실험을 진행했습니다. k=1 실행 시 1 ~ 4%는 일치하지 않는 함수가 실행 되었습니다. 동시 요청(concurrent request) k가 50일 경우에는 80% 중에 적어도 하나는 관련 없는 함수가 실행 되었습니다. 여기서는 성능 분리(performance isolation)를 조사합니다. 주로 AWS와 Azure에 초점을 맞춥니다. CPU 사용률을 측정하기 위해 python의 time.time(), javascript의 Date.now()를 사용해 1,000 ms 동안 지속적으로 time stamp를 기록해 측정합니다. AWS Lambda는 미리 설정된 메모리에 비례해 Function Instance의 CPU 성능을 제공합니다. 그러나 얼마나 정확하게 할당되는 지 세부 정보를 제공하지 않습니다. 서로 다른 1000개의 Function Instance에서 CPU 사용률을 측정였습니다. 다음의 그림 10(a)에서 주어진 메모리 크기에 대해 median 값을 표시하였습니다. 더 높은 메모리를 가진 Function instance는 더 많은 CPU cycle을 얻습니다. AWS의 CPU의 상한값은 2 * Memory / 3328로 근사됩니다. 이들은 같은 VM에서 실행되는 Function instance의 CPU 사용률도 측정하였는데 CPU 점유율이 낮아지지만, 공평하게 공유한다는 것을 발견 하였습니다. Google은 AWS와 동일한 메커니즘(mechanism)을 사용해 메모리 기반으로 CPU cycles을 할당합니다. 메모리가 증가함에 따라 CPU 사용률이 11.1%에서 100%로 증가합니다. 위의 그림 10(b)입니다. Azure는 CPU 사용률이 비교적 높지만 중간(median) 값은 66.9%입니다. coresidency가 높아지면 CPU 사용률이 크게 감소합니다. I/O 처리량을 측정하기 위해 AWS나 Google에서는 dd 명령어를 사용해 로컬 디스크에 512KB의 데이터를 1,000번(fdatasync, dsync 옵션을 사용해 disk에 data가 기록되도록) 하였습니다. Azure에서는 python을 이용해 os.fsync를 이용해 디스크에 기록되는지 확인하고 동일하게 작업을 수행하였습니다. 네트워크의 측정은 iperf를 이용해 확인했습니다. 아래의 그림은 50번에 걸쳐 실험된 VM 인스턴스에 같이 있는 Function instances의 I/O 및 네트워크 처리량을 집계한 것입니다. x축은 동시 실행(concurrent execution)이며, y축은 처리량입니다. I/O는 동시 실행 수가 늘어남에 따라 점유율이 낮아집니다. I/O 성능은 메모리 크기에 비례한 CPU의 영향을 받기 때문에 높은 메모리를 가진 Function instance의 경우 성능이 낮아집니다. Azure는 타입에 따라 자원 할당의 비율이 달라집니다. 네트워크 처리량(throughput)은 비슷합니다. 메모리가 증가함에 따라 I/O와 네트워크 처리량(throughput)은 증가합니다. AWS와 Azure는 공존하는 Function instance 간에 적절한 자원 분리를 제공하지 못해 성능이 상당히 저하될 수 있습니다. Google Cloud Functions은 함수호출이 끝난 후에도 백그라운드(background)로 작업을 실행할 수 있습니다. 실행한 스크립트는 서버에 매 10초마다 10M 파일을 게시했습니다. 살아 있었던 시간은 21시간으로 자원 소비에 대해 비용을 청구하지 않고 네트워크 활동의 로그를 찾을 수 없는 허점을 보였습니다. 반면에 Azure는 모든 활동을 기록했습니다. 이 논문은 AWS, Google, Azure의 Serverless Computing의 서비스에 대해 분석을 진행하였고 각 3사의 자원 관리와 자원 성능 분리에 대해 고찰하였습니다. 연구 주제에 맞는 내용으로 많은 도움이 되었습니다.
USENIX 2018 ‘Peeking Behind the Curtains of Serverless Platforms’ - Conference PaperAbstract
Introduction
Background
Serverless Architectures Demystified
AWS
Azure
Google
Tenant isolation
AWS
Azure
Heterogeneous infrastructure
AWS
Azure
Google
Resource Scheduling
AWS
Azure
Google
Cold-start and VM provisioning
AWS
Azure, Google
Instance Lifetime
Idle instance recycling
AWS
Azure, Google
Inconsistent function usage
Performance Isolation
CPU Utilization
AWS
Azure, Google
I/O and Network
AWS
Azure
Google
Resource accounting
Conclusion
























'AWS' 카테고리의 다른 글
| AWS Lambda OpenCV 라이브러리 빌드 video processing (0) | 2018.12.06 |
|---|---|
| AWS Lambda PIL 라이브러리 빌드 image data augmentation (1) | 2018.12.05 |
| AWS Lambda Python 라이브러리 numpy 배포 패키지 만들기 matmul 실행 (0) | 2018.11.14 |
| AWS Lambda Serverless 프로젝트 5 - 비디오 메타데이터 생성 - AWS 관리, 그룹, 역할, 자원, CloudWatch, CloudTrail, 결제 알람 (0) | 2018.04.26 |
| AWS Lambda Serverless 프로젝트 4 - 비디오 메타데이터 생성 - Lambda, SNS, S3 (1) | 2018.04.22 |