하둡 설치하기-3 Zookeeper, Hadoop 설치
이전 포스트
하둡
하둡 설치하기-1 VirtualBOX와 CentOS7 설치
하둡 설치하기-2 CentOS7 기본 설정 및 JAVA 설치
3부 Zookeeper 및 Hadoop 설치
Zookeeper 설치
Zookeeper는 분산환경에서 서버들간에 상호조정이 필요한 다양한 서비스를 제공하는 시스템입니다.
Firefox에서 zookeeper를 검색합니다.

사이트로 이동합니다.
현재 이용가능한 버전이 보입니다.

우리는 3.4.8 버전을 사용할 것입니다.
zookeeper를 다운받기 위해 다음의 명령어를 입력하고 다운을 받습니다.
또한 압축을 풀고 소프트 링크로 묶습니다.
** opt 디렉터리에서 다음의 명령어를 실행해 주세요
[namenode@localhost ~]$ wget
http://apache.mirror.cdnetworks.com/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz

압축을 풉니다.
[namenode@localhost ~]$ tar -xvzf zookeeper-3.4.8.tar.gz
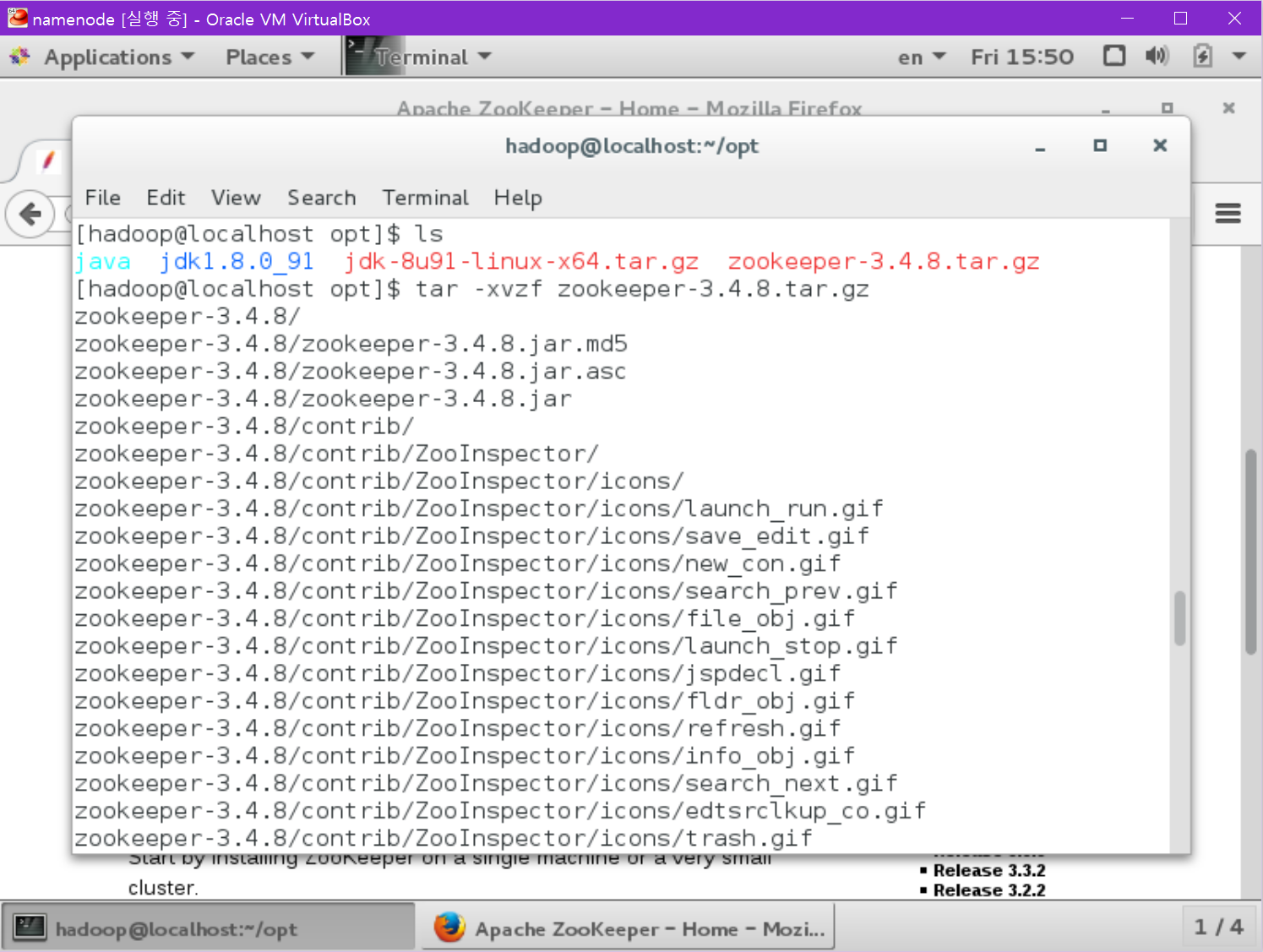
[namenode@localhost ~] ln -s zookeeper-3.4.8 zookeeper

우선 zookeeper의 환경 설정 파일을 만들어야 합니다. 기존의 sample.cfg를 복사합니다.
[namenode@localhost ~] cd zookeeper/conf
[namenode@localhost ~] cp zoo_sample.cfg zoo.cfg
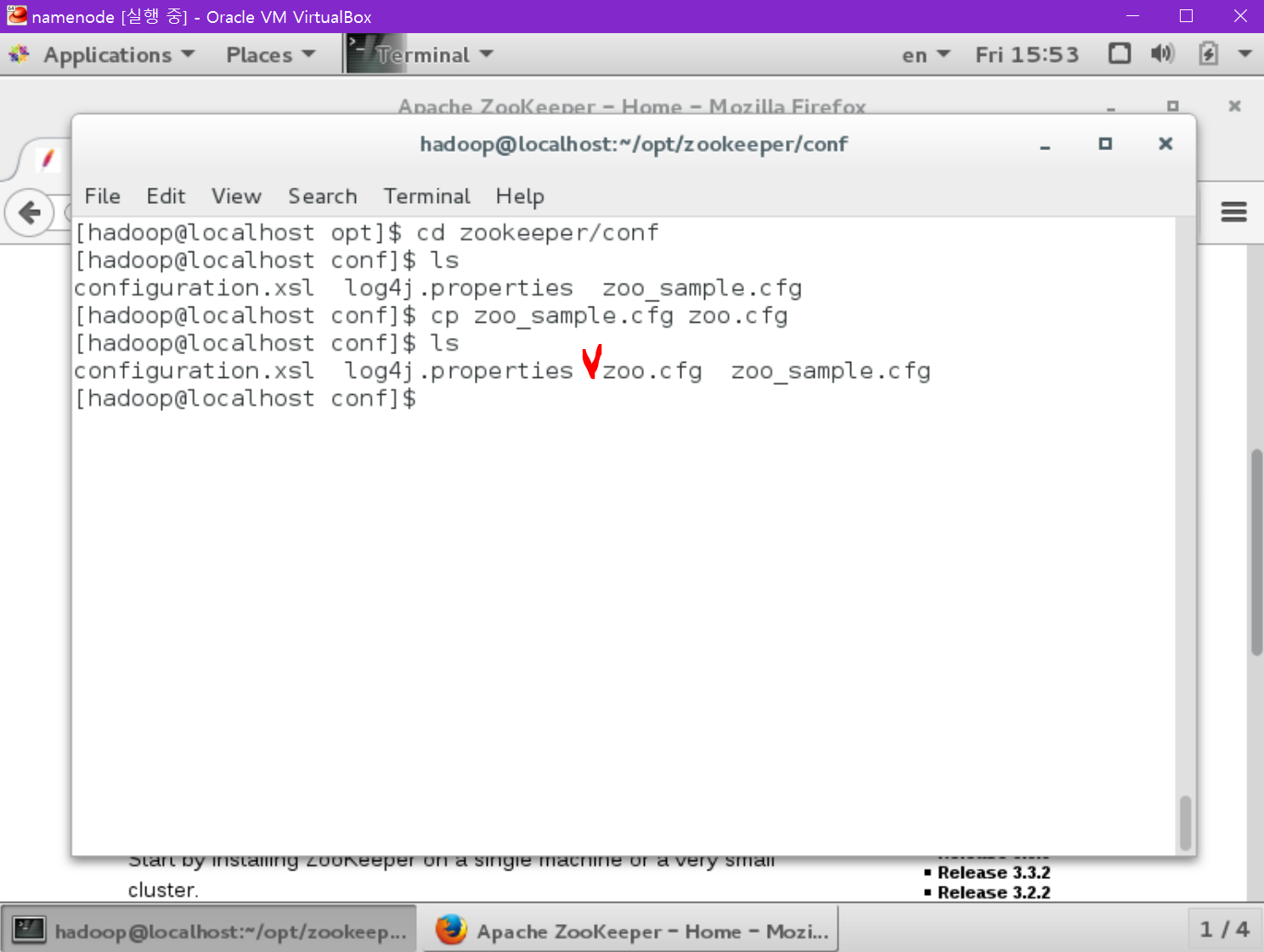
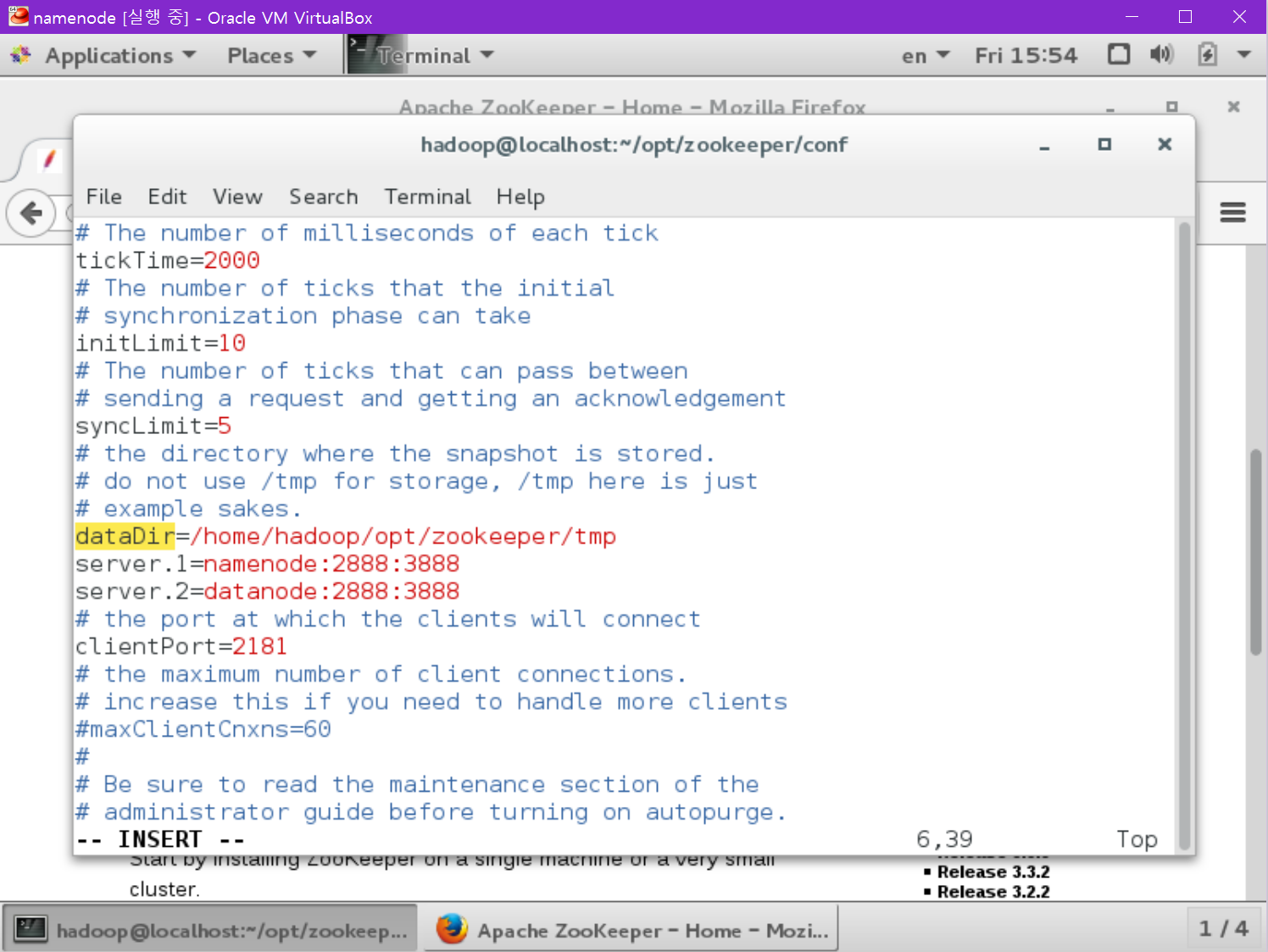
zoo.cfg를 vi로 열어 수정합니다.
dataDir=/home/hadoop/opt/zookeeper/tmp
server.1=namenode:2888:3888
server.2=datanode:2888:3888
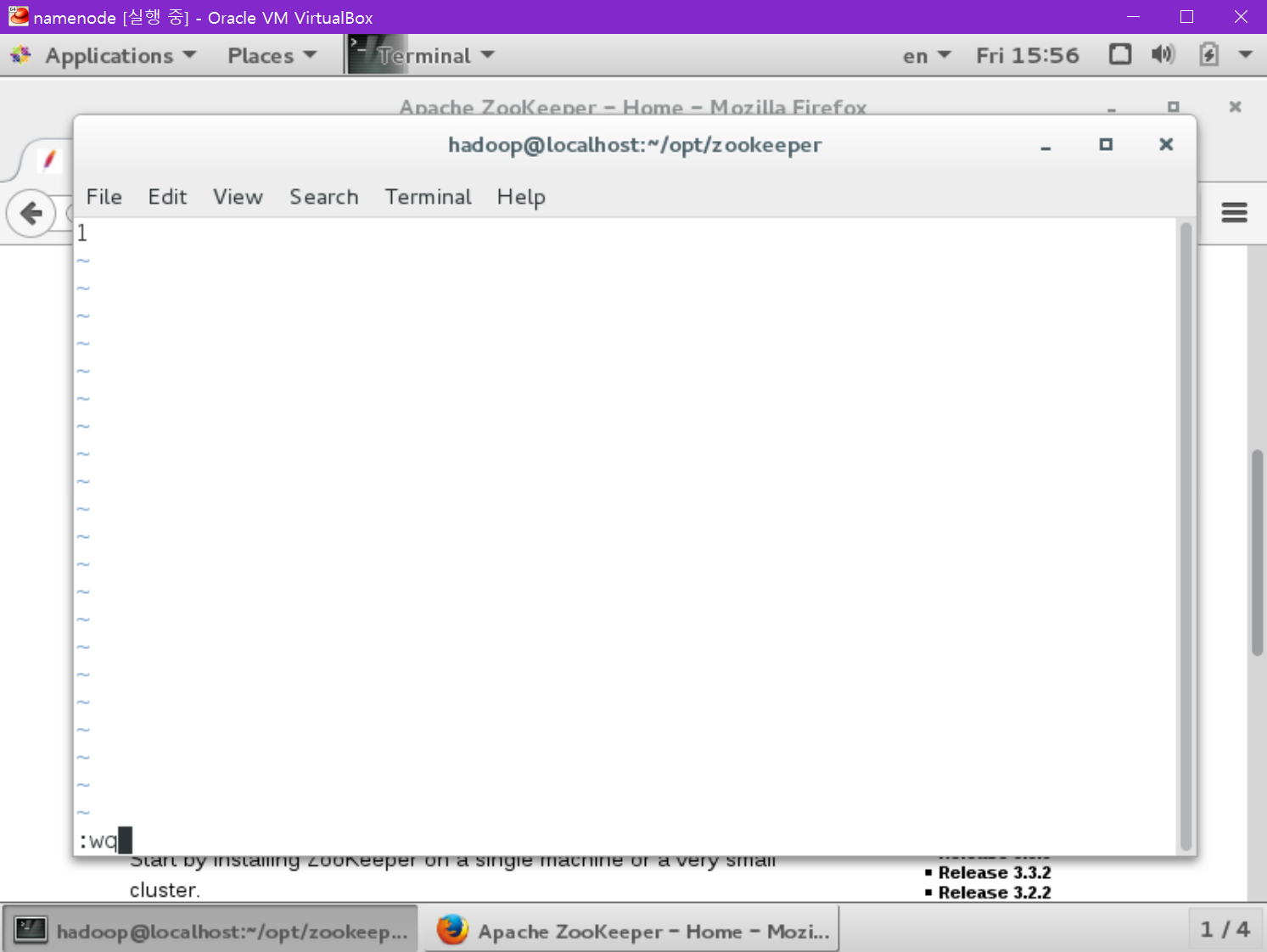
다음은 zookeeper에서 myid를 지정해야 합니다.
[namenode@localhost ~] cd ~/opt/zookeeper
[namenode@localhost ~] vi myid

namenode는 1이고, datanode는 2 입니다.
다음으로 Zookeeper의 환경변수를 설정해야 합니다.
# ZOOKEEPER
export ZOOKEEPER_HOME=/home/hadoop/opt/zookeeper
다음 PATH 줄 수정
export PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
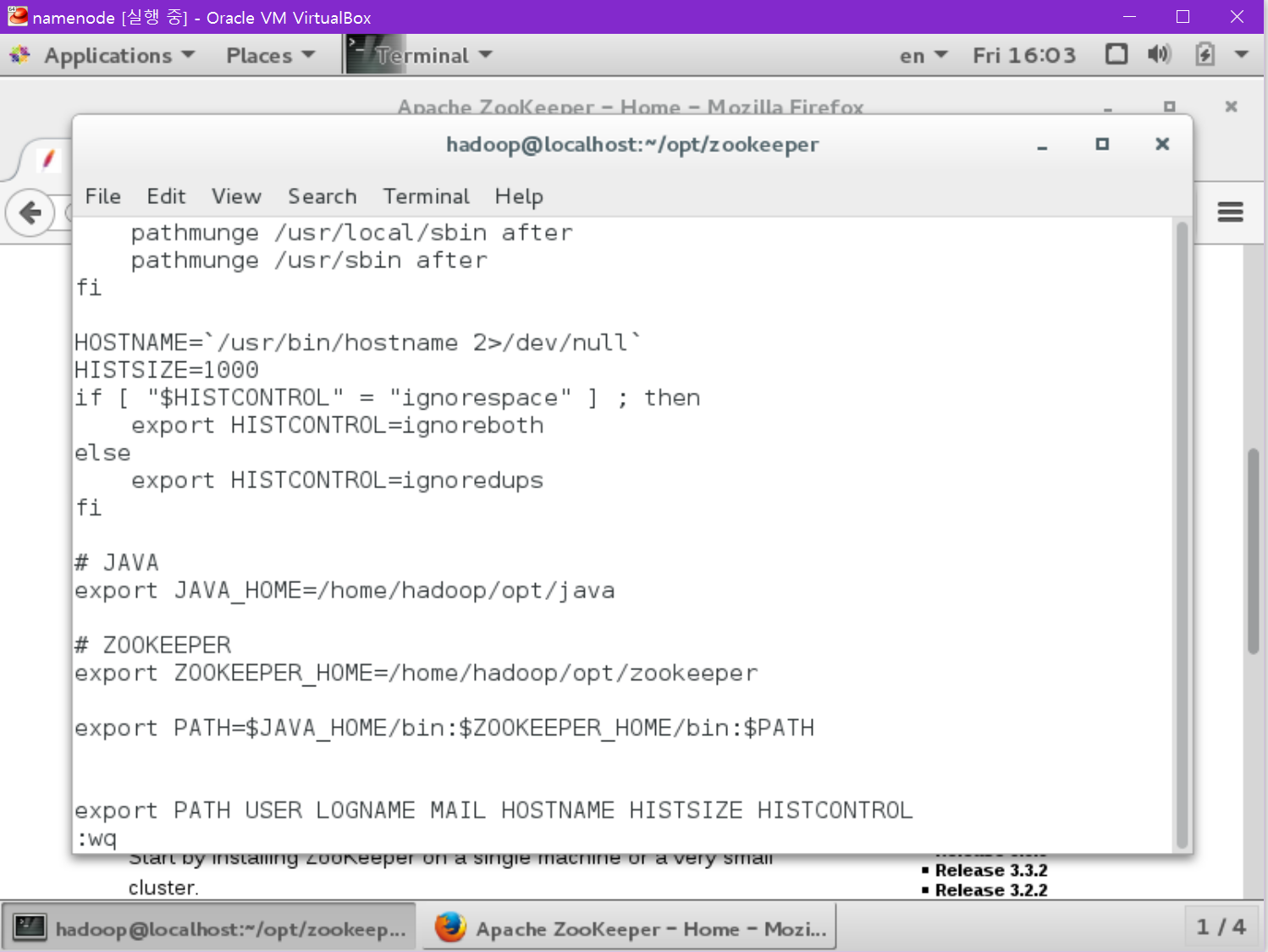
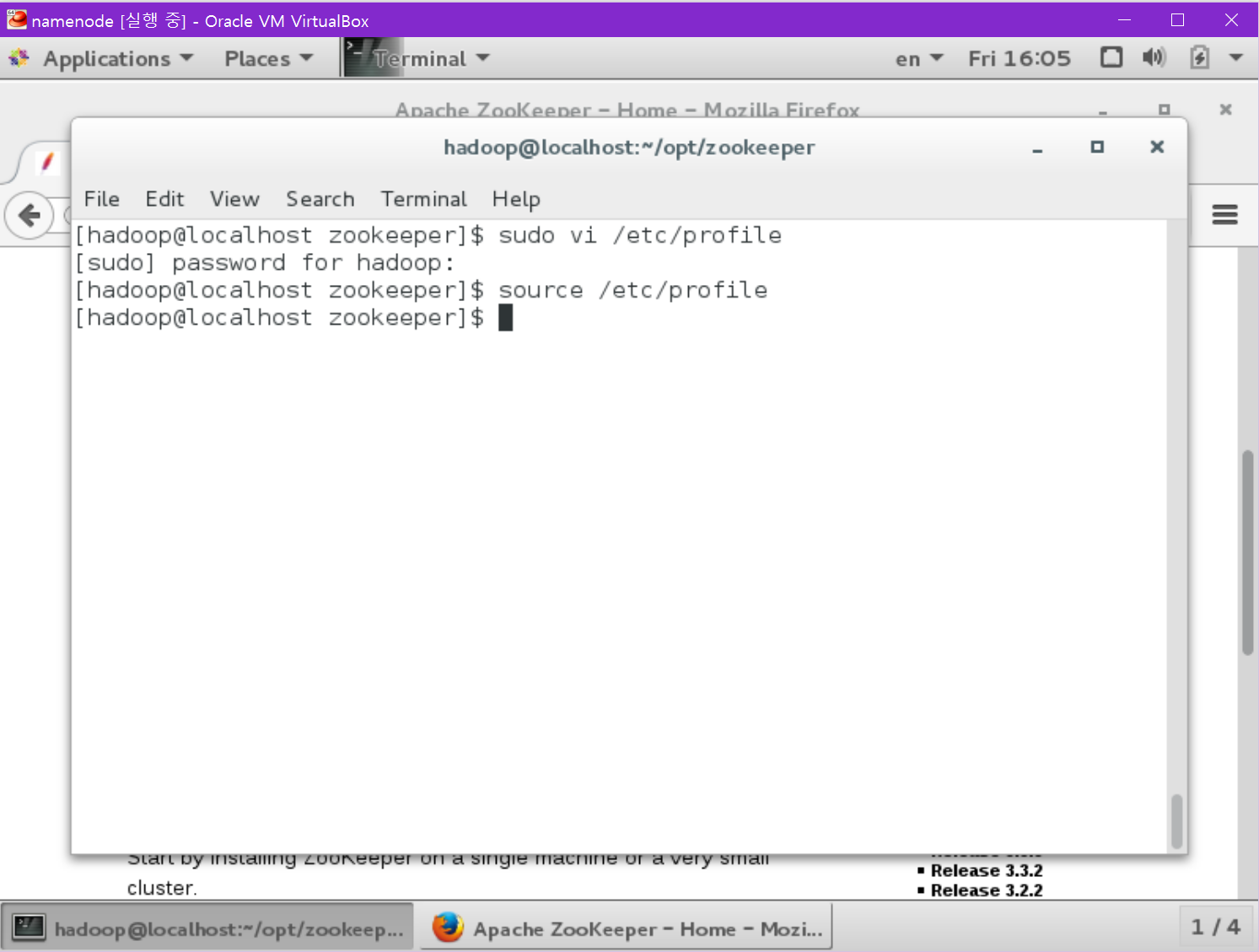
/etc/profile을 업데이트 합니다.
[namenode@localhost ~] source /etc/profile
Hadoop 1.2.1 설치
이번에는 Firefox에 hadoop을 검색해봅시다.
http://hadoop.apache.org/ 사이트로 이동합니다.
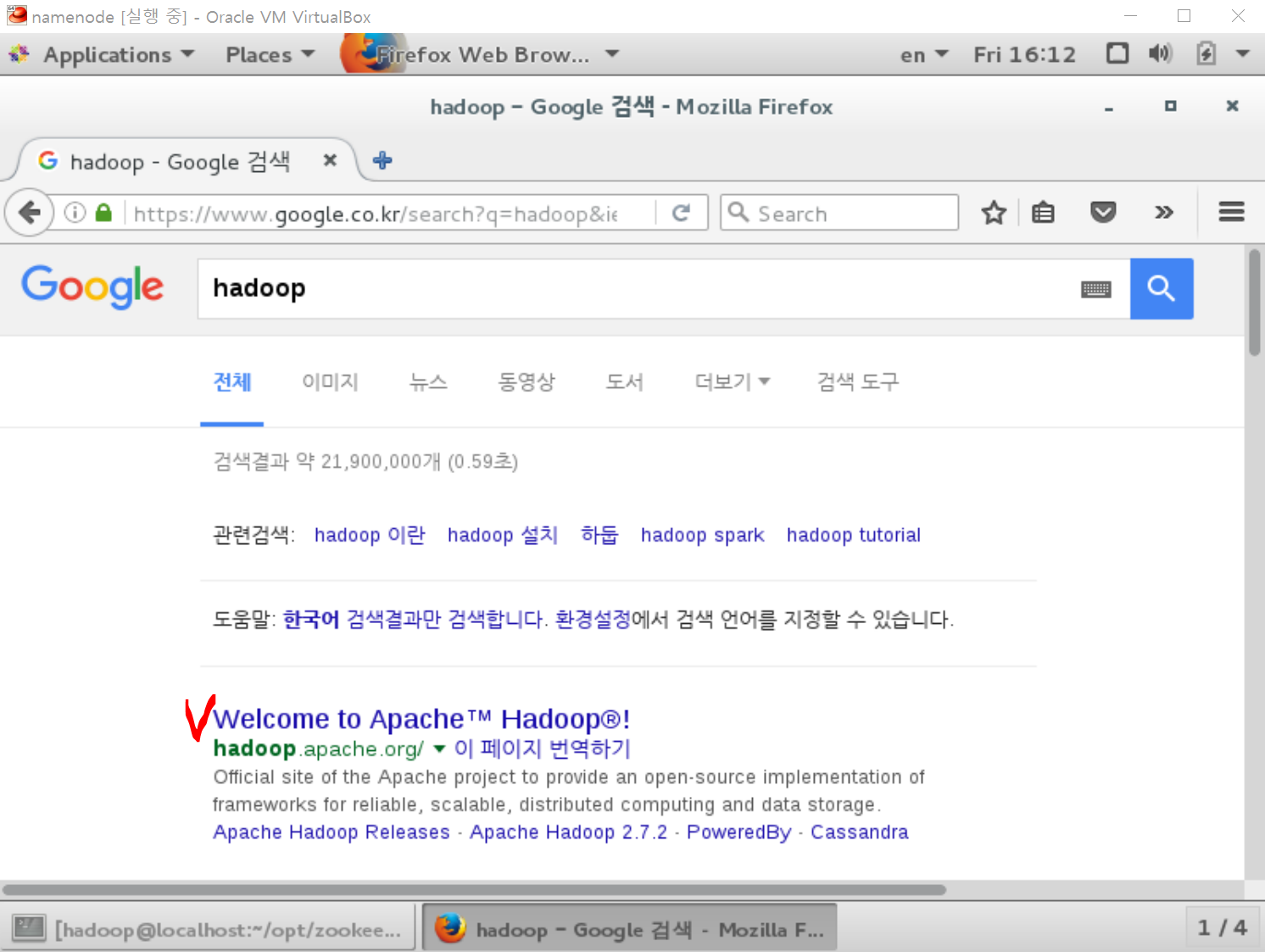
우리는 첫 하둡 설치로 1.2.1 버전을 설치할 것입니다. (추후에 2 버전 설치)
opt 디렉터리에서 다음의 명령어를 실행합니다.
[namenode@localhost ~] cd ~/opt
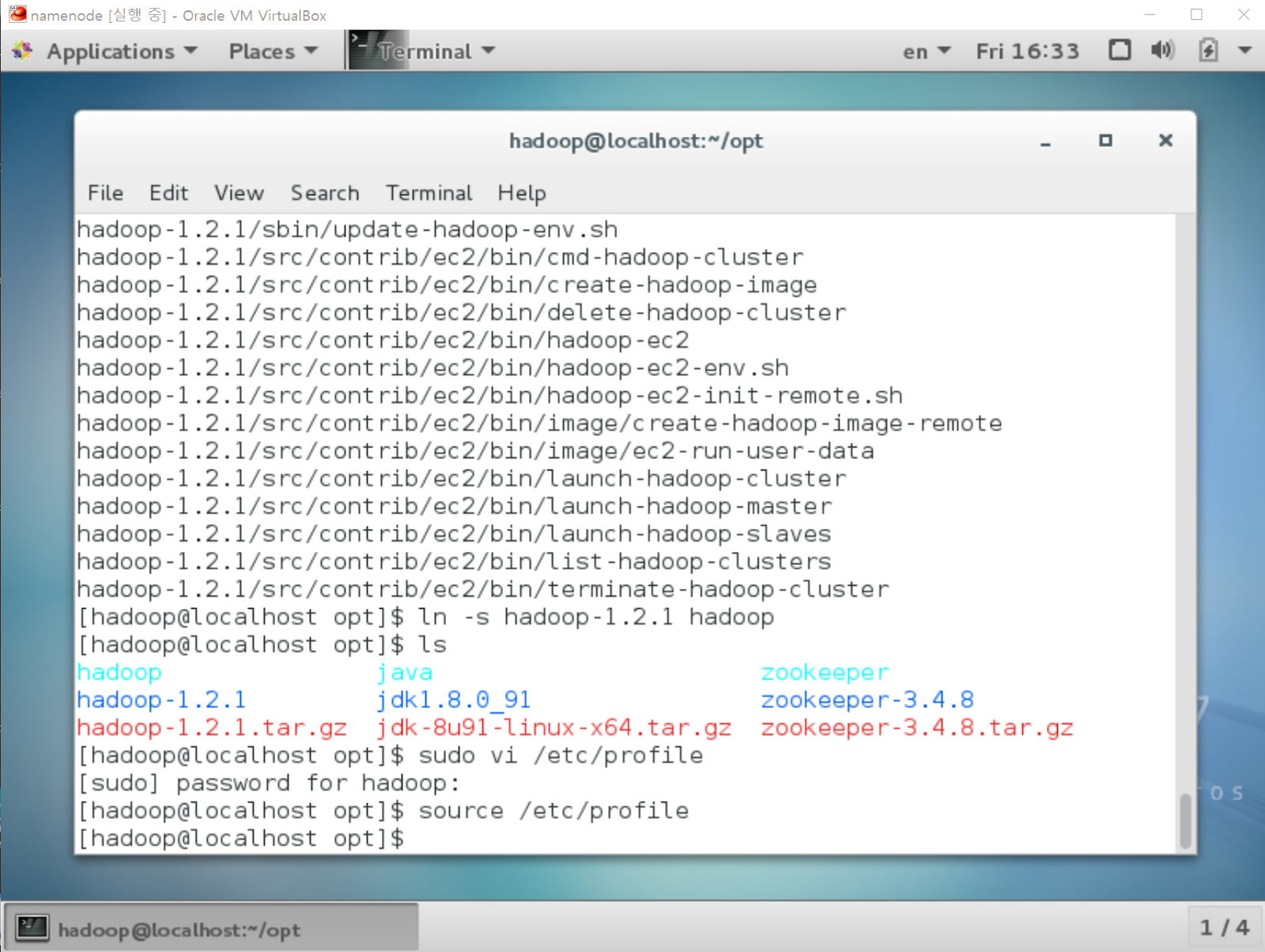
[namenode@localhost ~] wget http://apache.mirror.cdnetworks.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
[namenode@localhost ~] tar -xvzf hadoop-1.2.1.tar.gz
[namenode@localhost ~] ln -s hadoop-1.2.1 hadoop
다운을 받고, 압축을 풀고, 소프트링크 파일을 생성하였습니다.


환경 설정 파일을 적용해보겠습니다.
[namenode@localhost ~] sudo vi /etc/profile
다음의 소스를 입력합니다.
export HADOOP_HOME=/home/hadoop/opt/hadoop
export HADOOP_COMMON_HOME= =/home/hadoop/opt/hadoop export HADOOP_YARN_HOME= =/home/hadoop/opt/hadoop
export HADOOP_CONF_DIR=/home/hadoop/opt/hadoop/conf
export PATH=(이전의코드에뒤로붙입니다):$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
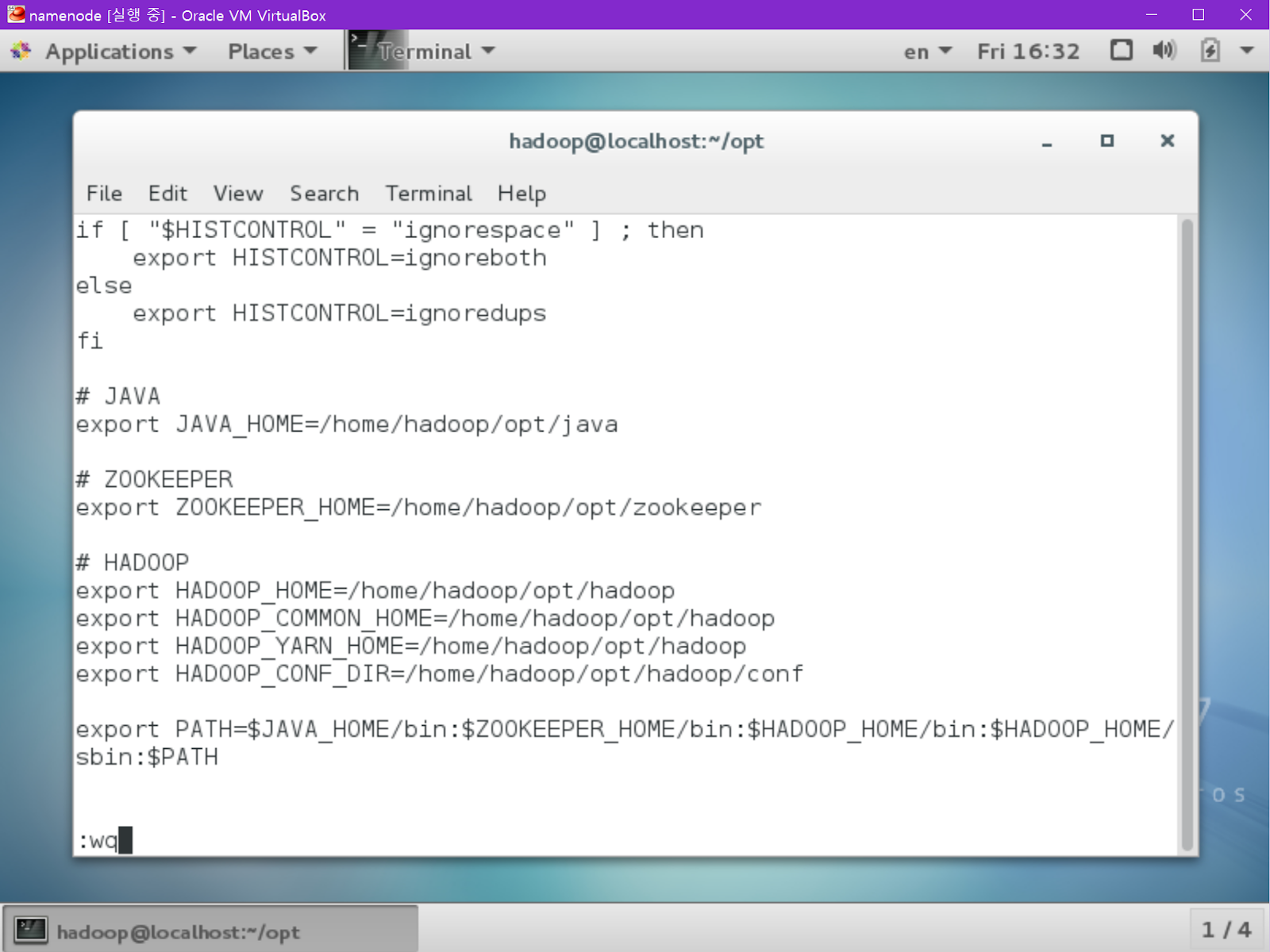
소스 업데이트를 잊지 맙시다.
[namenode@localhost ~] source /etc/profile
자 이어서 Hadoop의 환경 설정(/opt/hadoop/conf/)을 진행해야 합니다.
•hadoop-env.sh
•slaves
•masters
•core-site.xml
•hdfs-site.xml
•mapred-site.xml

차근차근 진행해보죠
hadoop-env.sh
[namenode@localhost ~] vi hadoop-env.sh

다음 부분을 주석(#) 삭제하고, export JAVA_HOME=/home/hadoop/opt/java로 변경합니다.
또한 밑에, export HADOOP_HOME=/home/hadoop/opt/hadoop을 추가합니다.
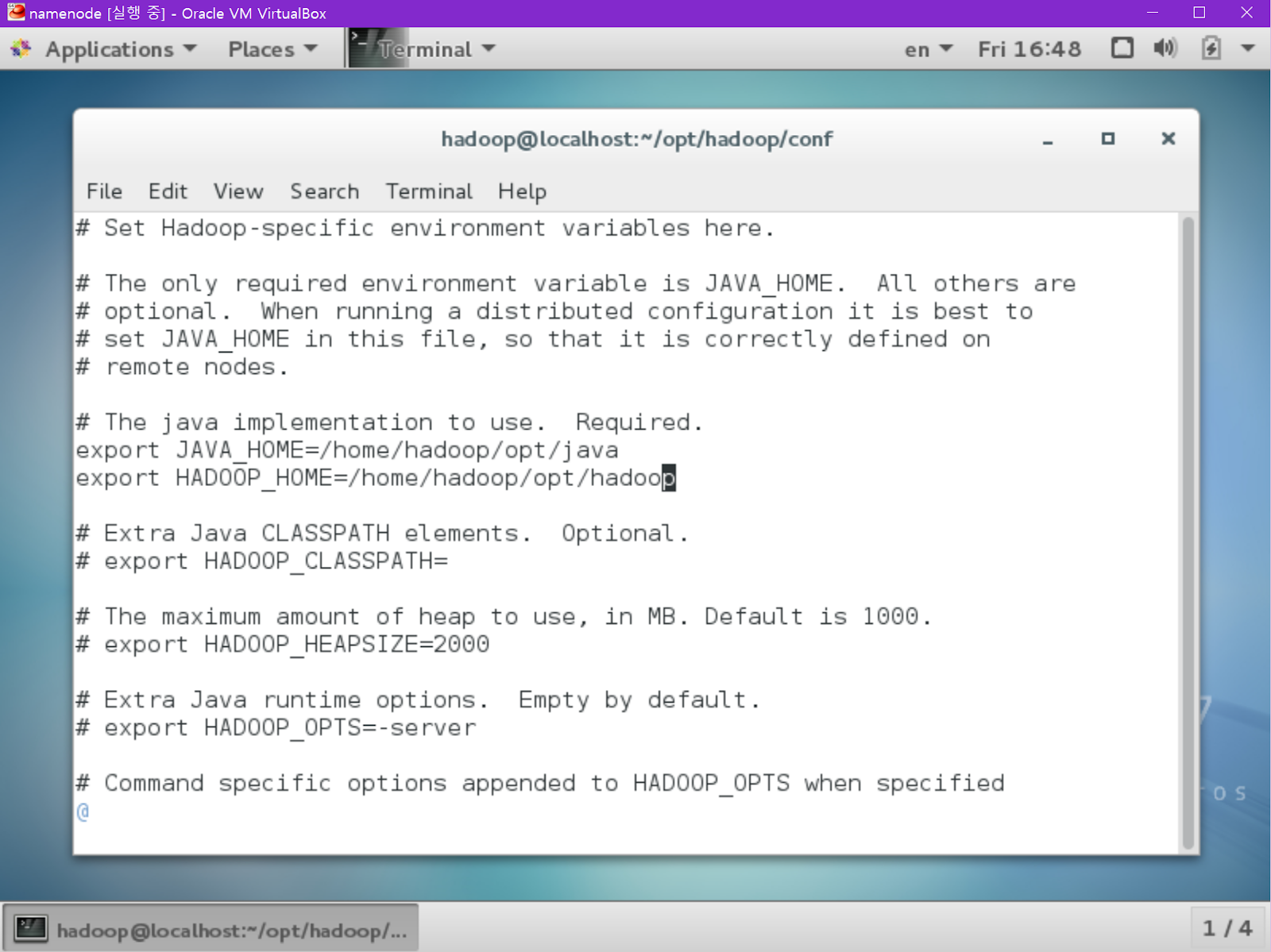
/(단축키)를이용해 LOG_DIR을 검색합니다.
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs

다음은 _SLAVES를 검색합니다.
export HADOOP_SLAVES=${HADOOP_HOME}/conf/slaves

다음은 PID_DIR을 검색합니다
export HADOOP_PID_DIR=${HADOOP_HOME}/pids
로 수정합니다.

slaves
[namenode@localhost ~] vi slaves
datanode 를 입력합니다.

masters
[namenode@localhost ~] vi masters
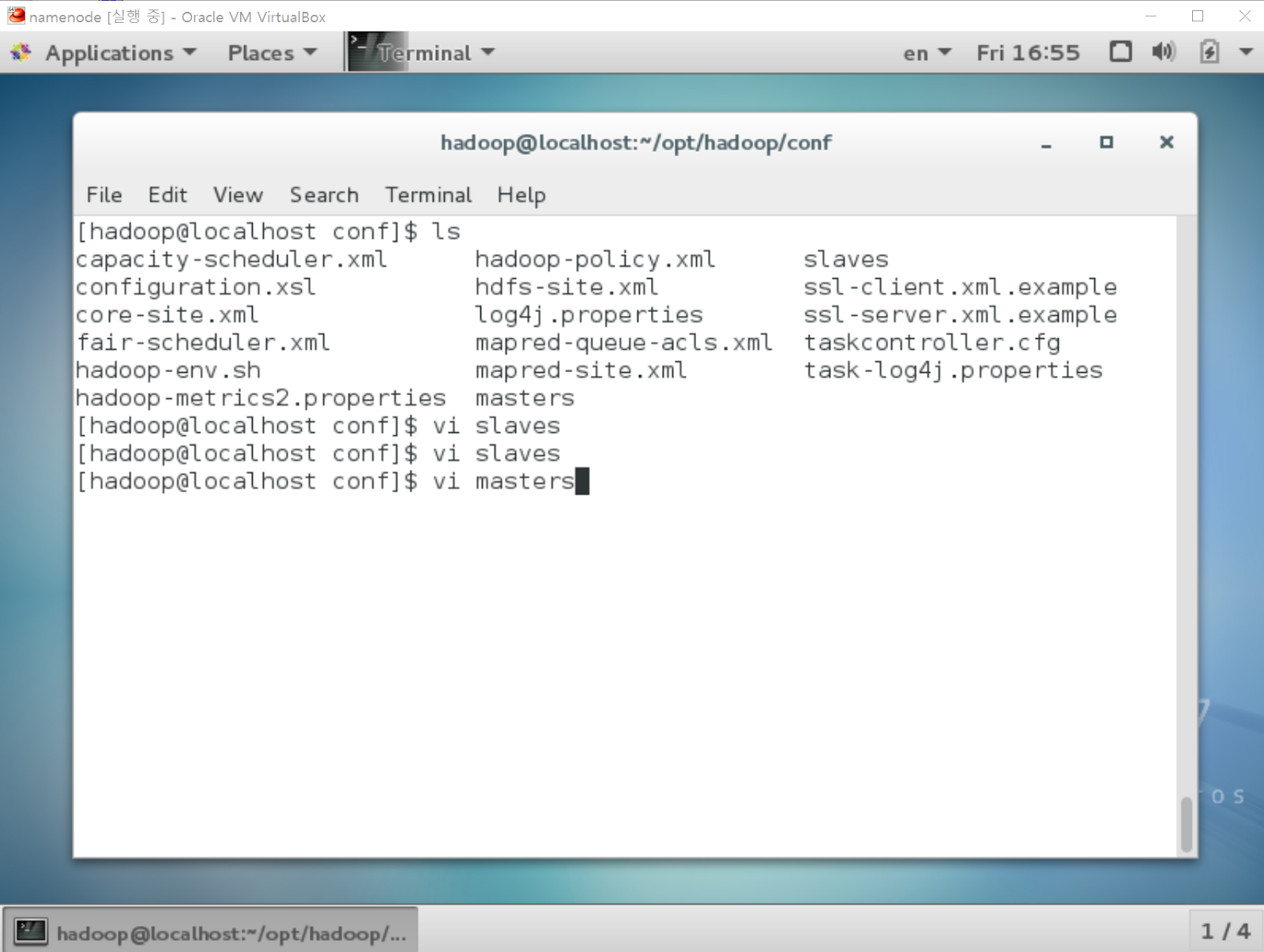
namenode을 입력합니다.

이제부터는 xml파일 수정인데 미리 다음의 코드를 만들어주시고 복붙하면서 작업해주세요
<property>
<name></name>
<value></value>
</property>
core-site.xml
[namenode@localhost ~] vi core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/opt/hadoop/tmp</value>
</property>
</configuration>
다음과 입력하고 저장합니다.

hdfs-site.xml
[namenode@localhost ~] vi hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.name.edits.dir</name>
<value>${dfs.name.dir}</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/opt/hadoop/dfs/data</value>
</property>
</configuration>

mapred-site.xml
[namenode@localhost ~] vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>namenode:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>${hadoop.tmp.dir}/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>${hadoop.tmp.dir}/mapred/system</value>
</property>
</configuration>


완료되었습니다.
datanode 생성하기
datanode 생성(namenode 복제)
datanode를 생서하기 앞서 namenode를 끕니다.
Oracle VM VirtualBox 관리자 창을 오픈합니다.
namenode를 선택하여 설정을 누르고 네트워크에서 어댑터를 추가해야 합니다.
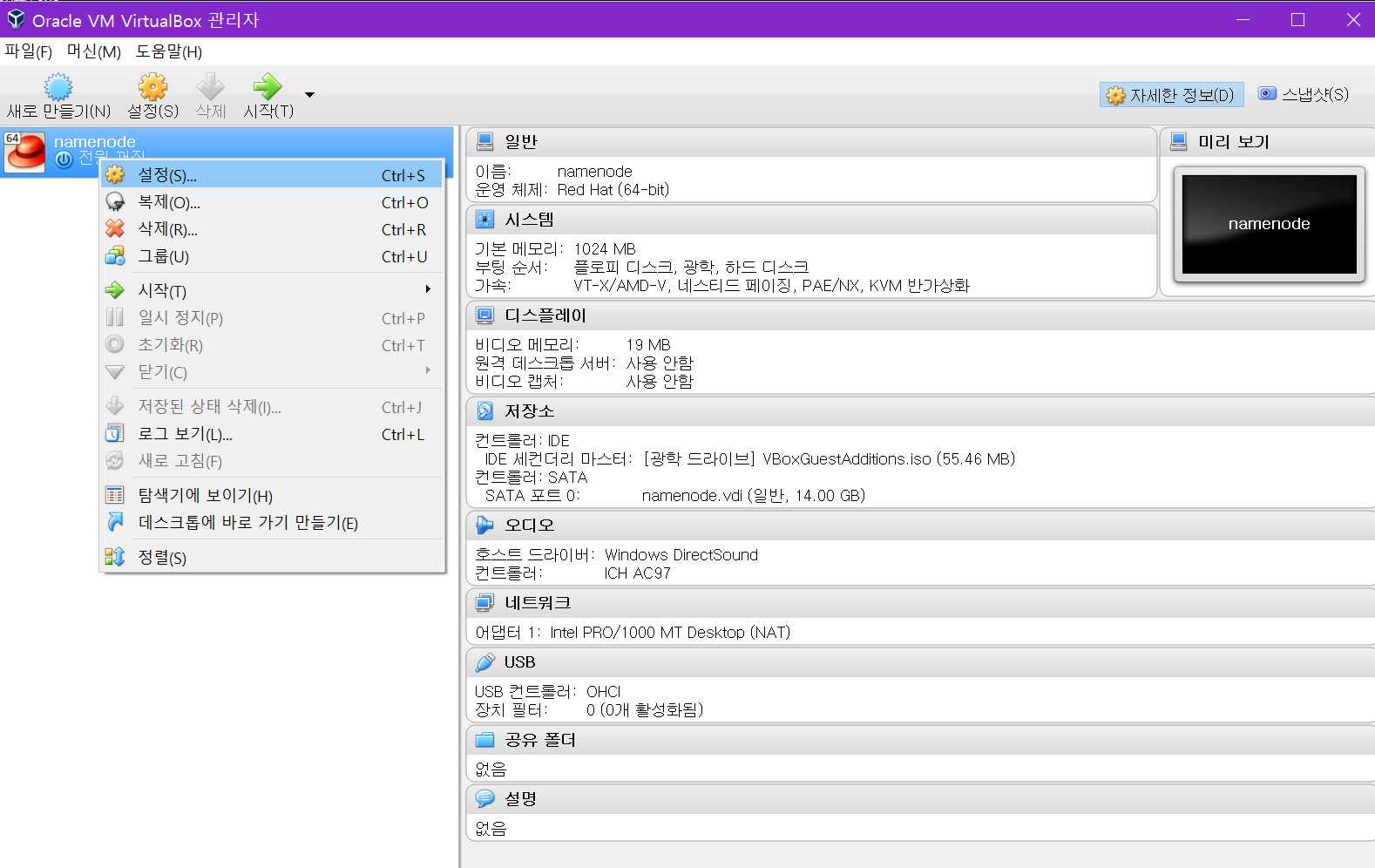
어댑터 2에서 네트워크 어댑터 사용하기를 선택합니다.
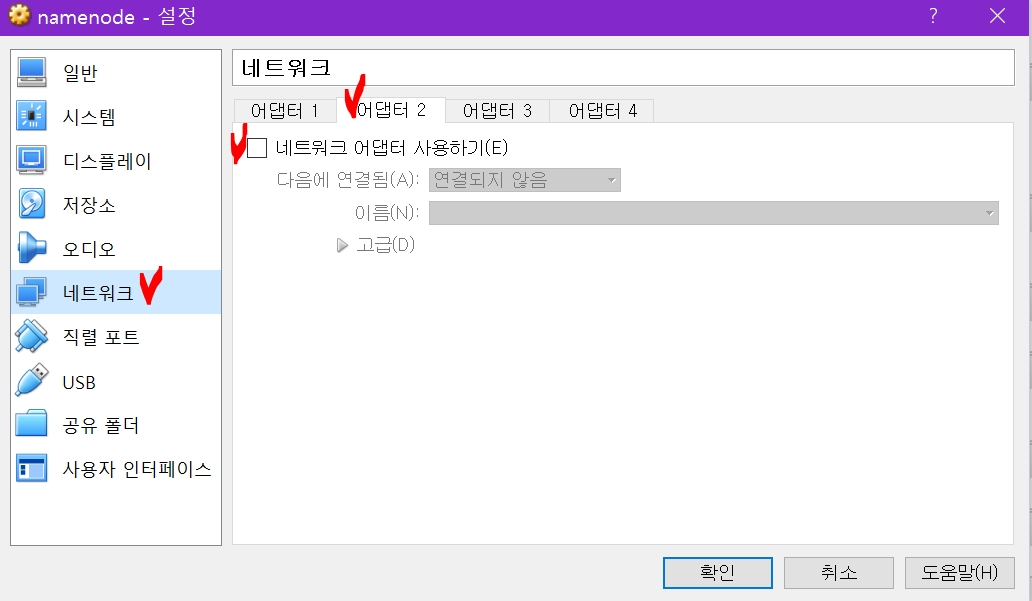
다음에 연결됨에서 호스트 전용 어댑터를 선택하고 확인 버튼을 누릅니다.
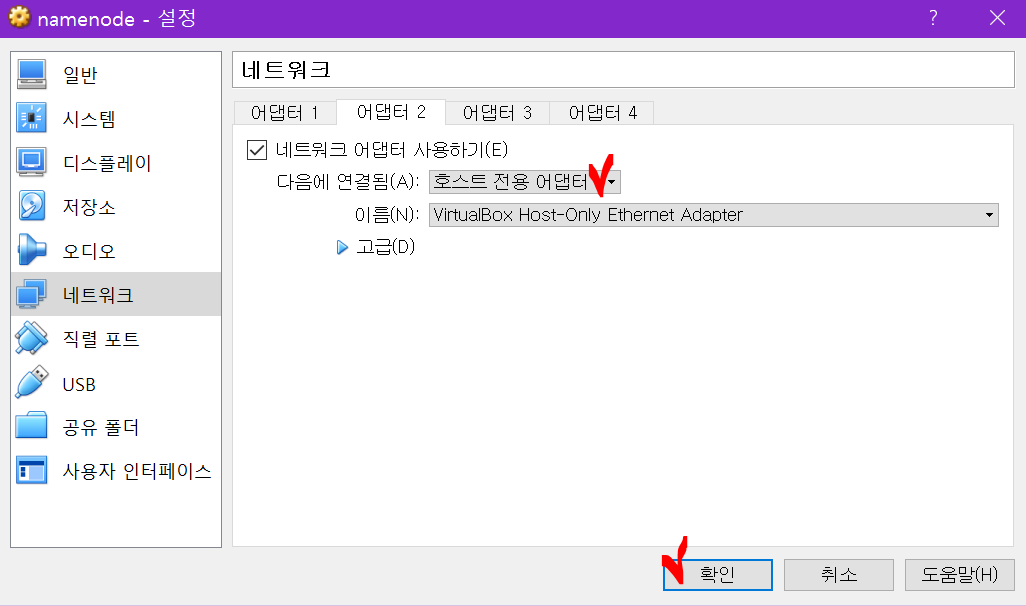
복제를 눌러 namenode를 복사합니다.
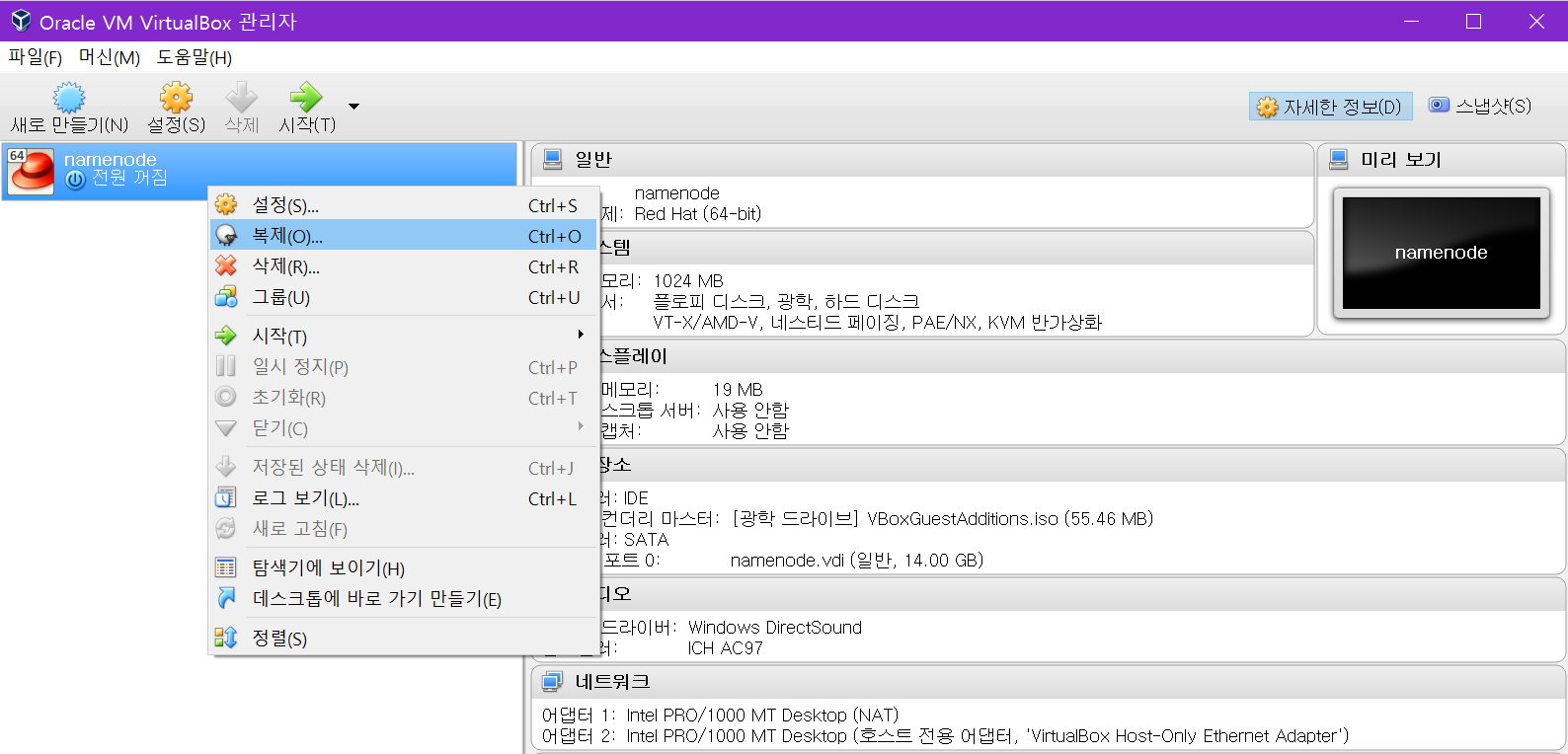
다음의 팝업 창에서 datanode로 변경하고 모든 네트워크 카드의 mac 주소 초기화를 체크합니다.

복제 버튼을 누릅니다.
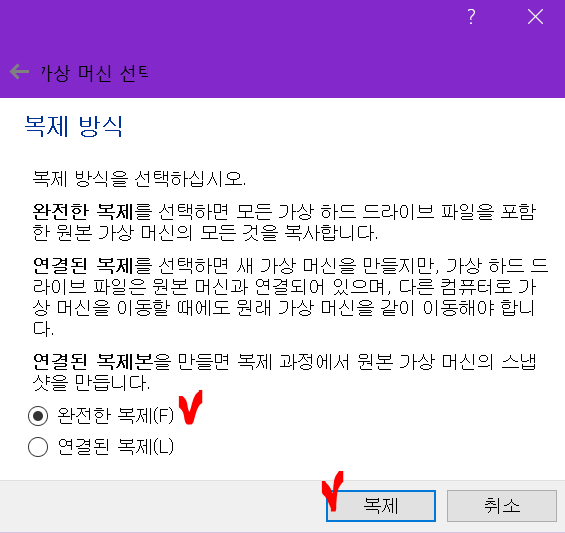
복제 중입니다.
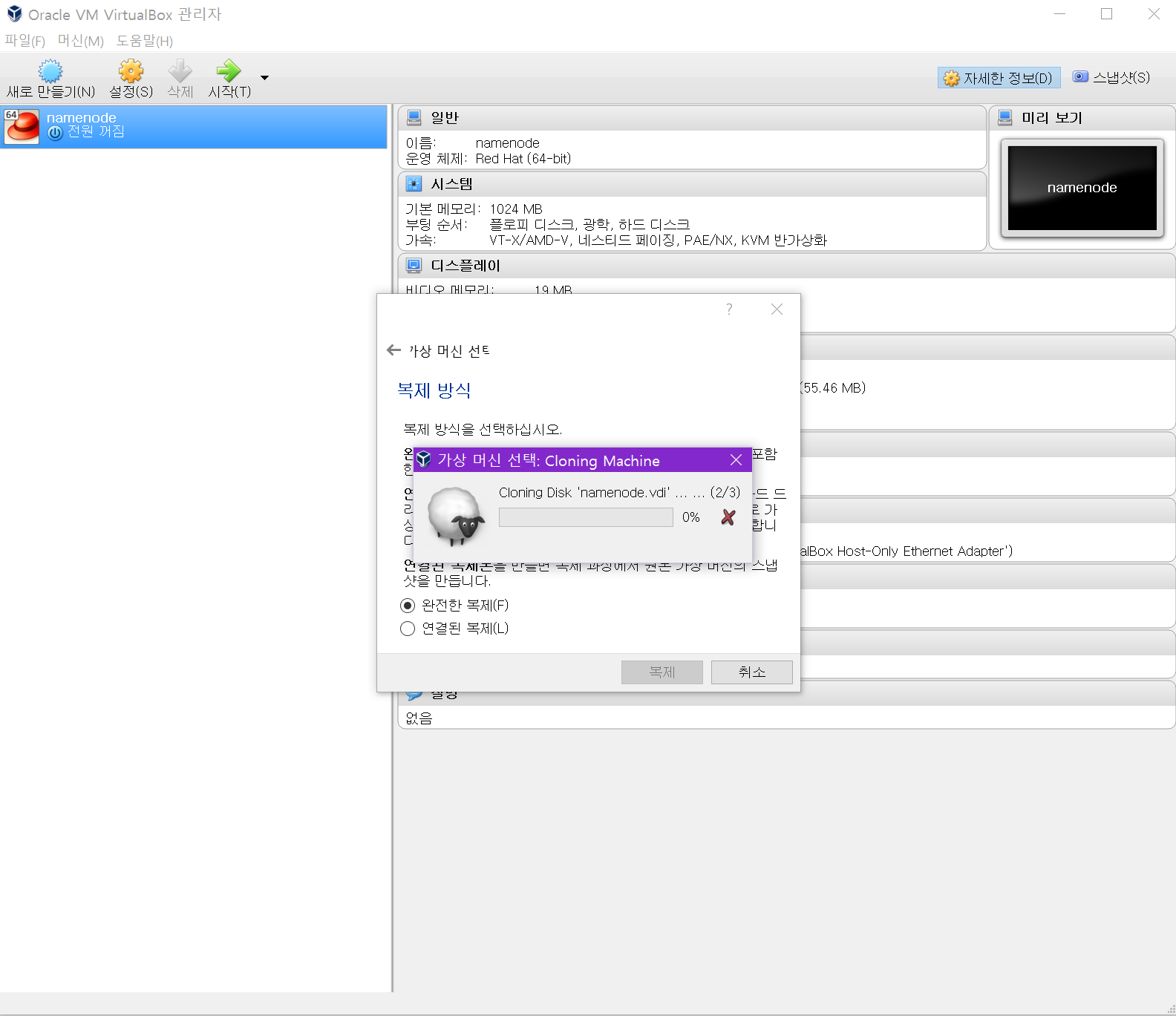
완료되면 목록에서 datanode를 확인할 수 있습니다.

우선 namenode 부터 시작 합니다.
이어서 datanode로 시작합니다.
hadoop 사용자로 로그인 합니다.
두 개의 머신의 ifconfig를 통해 ip를 차례대로 확인합니다.
namenode ->192.168.56.101
datanode -> 192.168.56.102
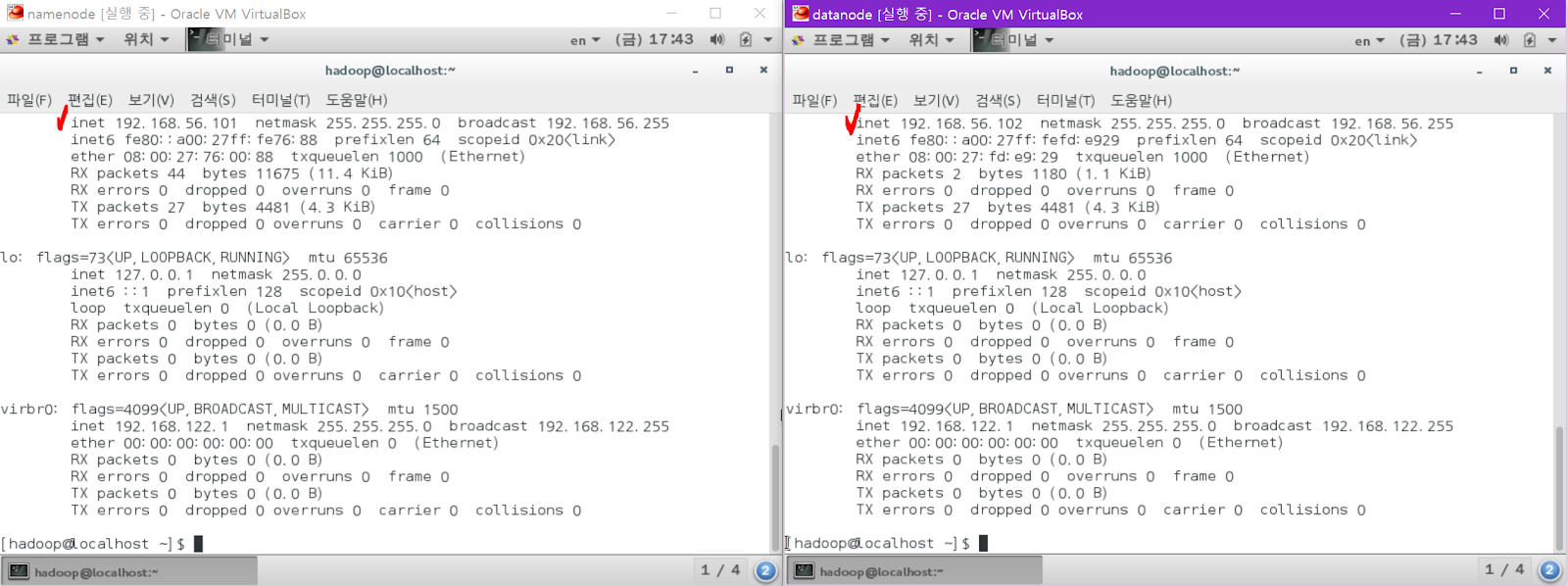
datanode를 선택하고 다음의 명령어를 입력합니다.
[hadoop@localhost ~] sudo vi /etc/sysconfig/network

CentOS 7에서는 다음의 명령어로 호스트 네임을 변경할 수 있습니다.
namenode에서 다음을 실행합니다.
[hadoop@localhost ~] hostnamectl set-hostname namenode
[hadoop@localhost ~] hostname
[hadoop@localhost ~] sudo reboot
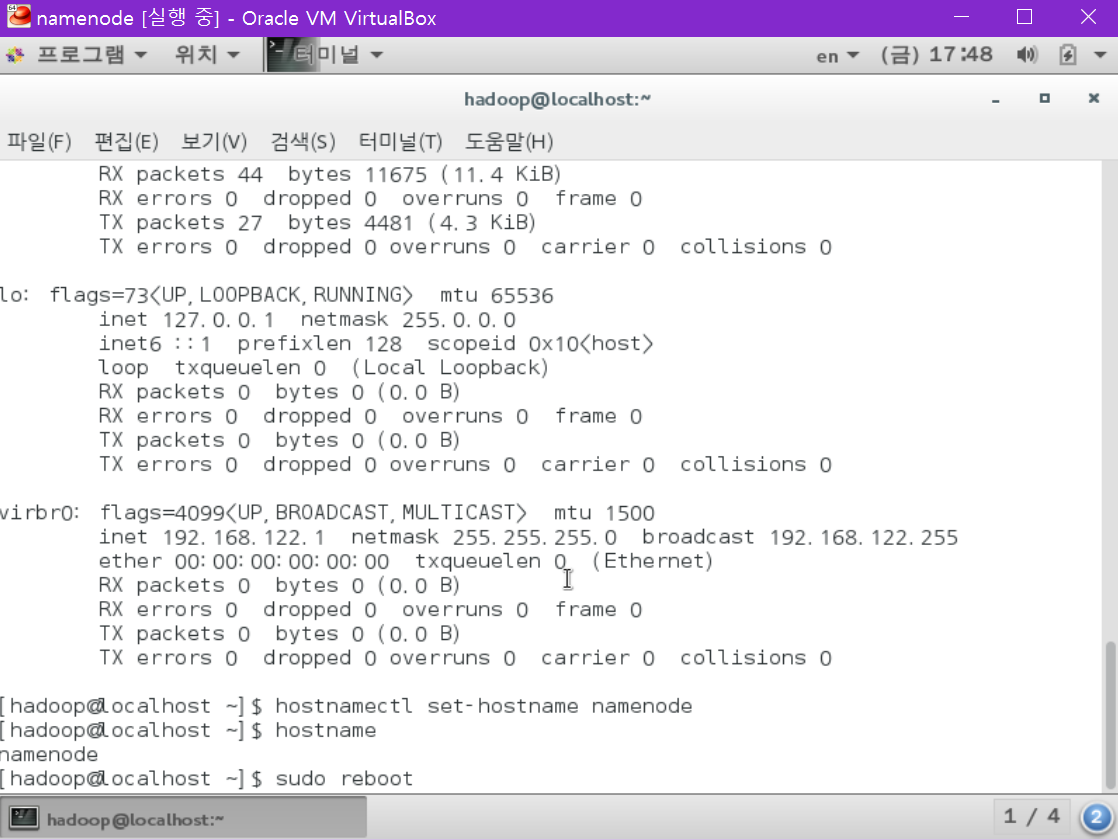
datanode에서 다음을 실행합니다.
[hadoop@localhost ~] hostnamectl set-hostname datanode
[hadoop@localhost ~] hostname
[hadoop@localhost ~] sudo reboot

최종 리부팅하고 터미널을 오픈하면 hostname이 변경된것을 확인할 수 있습니다.
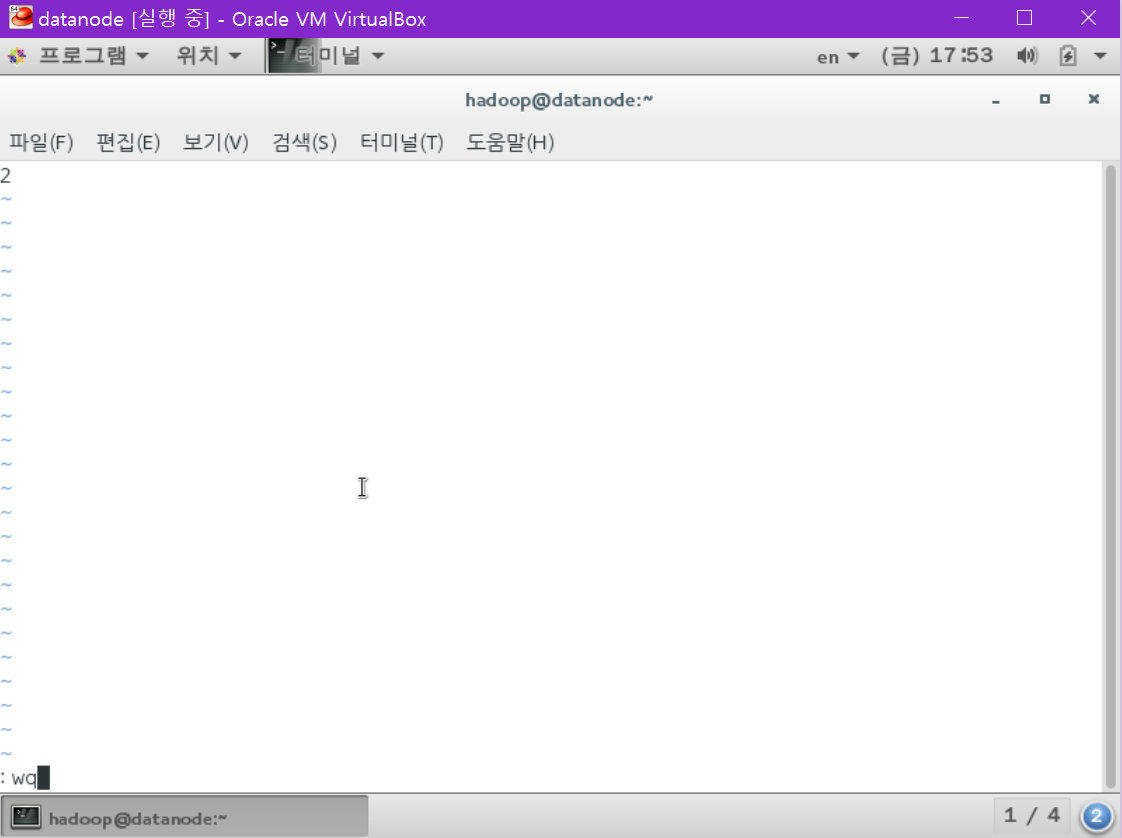
datanode의 Zookeeper myid를 변경해야 합니다.
[hadoop@datanode ~] cd ~/opt/zookeeper && vi myid
2로 변경합니다.
SSH 통신
다음에서는 SSH 통신을 진행할 것입니다.
namenode로 들어갑니다.
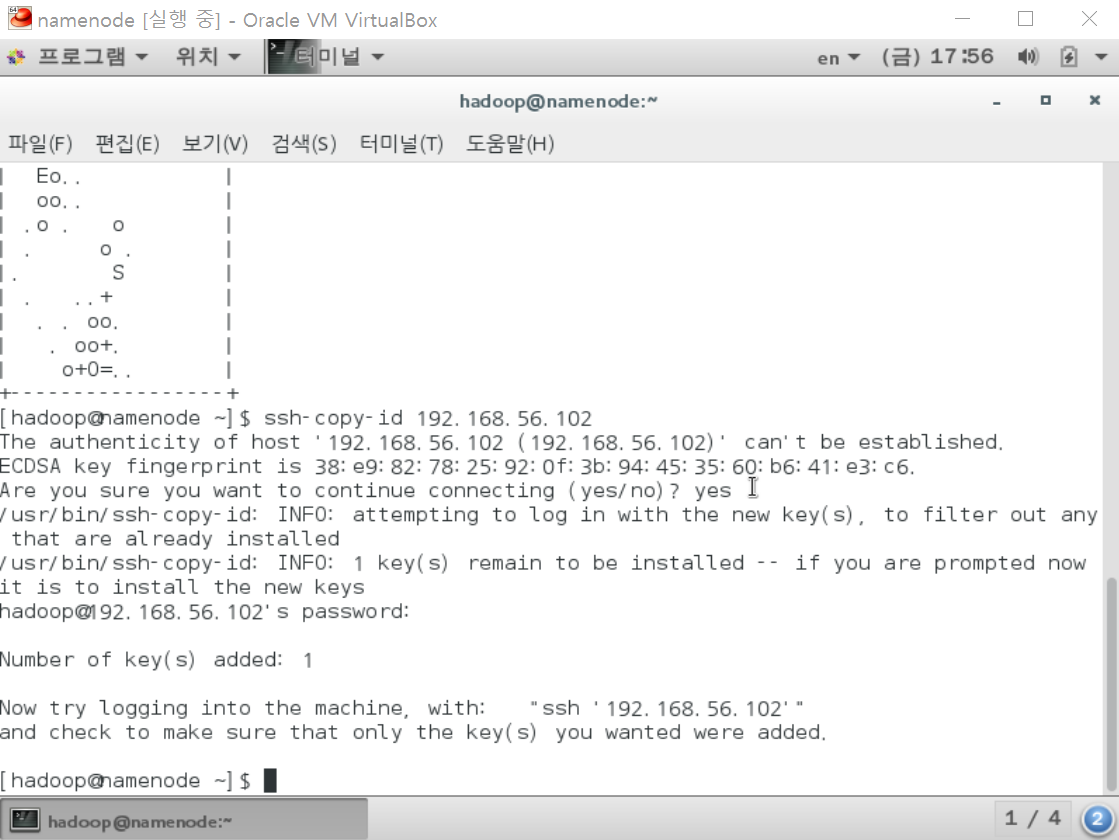
[hadoop@namenode ~] ssh-keygen -t rsa
enter enter enter

[hadoop@namenode ~] ssh-copy-id 192.168.56.102
yes 비밀번호 입력
자 이제 SSH 통신을 진행해봅니다.
[hadoop@namenode ~] ssh datanode
yes

터미널 창이 datanode 쉘로 변경되는 것을 확인할 수 있습니다.
이곳 배쉬에서 위의 ssh-keygen을 똑같이 실행합니다.
[hadoop@datanode ~] ssh-keygen -t rsa
[hadoop@datanode ~] ssh-copy-id 192.168.56.101

자 이제 exit 명령어를 입력해 ssh 통신에서 logout 합니다.
[hadoop@datanode ~] exit
하둡 실행하기
namenode에서 다음의 명령어를 실행합니다.
[hadoop@namenode ~] hadoop namenode -format

[hadoop@namenode ~] cd ~/opt/hadoop/bin
[hadoop@namenode ~] start-all.sh
실행 도중에 datanode의 비밀번호를 입력하셔야 됩니다.

[hadoop@namenode ~]jps
다음과 같이 JPS / NameNode / SecondaryNameNode / JobTracker 가 나와야 합니다.

datanode로 이동합니다.
똑같이 jps 명령어를 실행해봅니다.
다음과 같이 JPS / DataNode / TaskTracker 가 나와야 성공입니다.

DataNode가 나오지 않는 군요…
이럴 경우에는 log를 살펴봐야 합니다.
[hadoop@datanode ~] cd ~/opt/hadoop/logs
[hadoop@namenode ~] vi hadoop-hadoop-datanode-datanode.log

vi를 통해 열어 보니 다음과 같은 에러를 볼 수 있습니다.
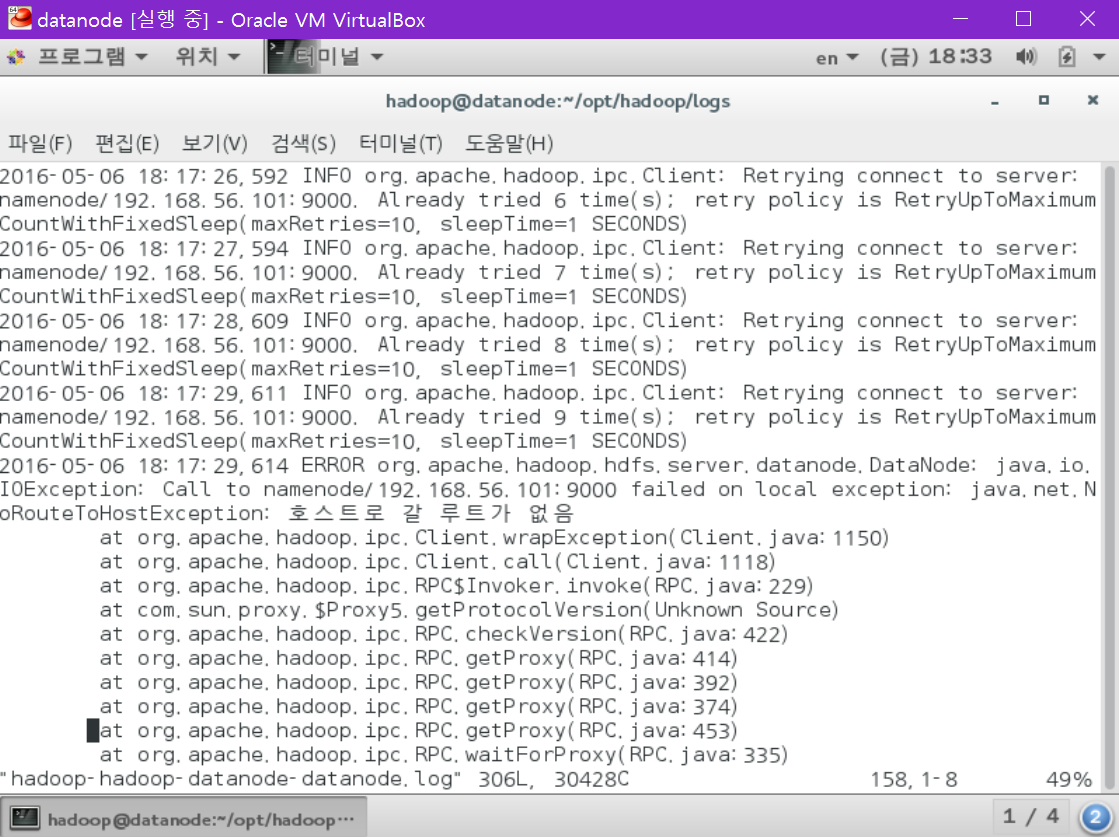
주로 이러한 ‘호스트로 갈 루트가 없음’ 문제는 방화벽 해제를 통해 해결을 볼 수 있습니다.
namenode와 datanode에 다음과 같은 명령어를 입력합니다 .
iptables 서비스를 중지
[hadoop@namenode]$ sudo systemctl stop iptables
[hadoop@datanode]$ sudo systemctl stop iptables
하둡 정지 시키는 경우는 다음의 명령어를 입력합니다.
/opt/hadoop/bin/에서
[hadoop@namenode ~] stop-all.sh
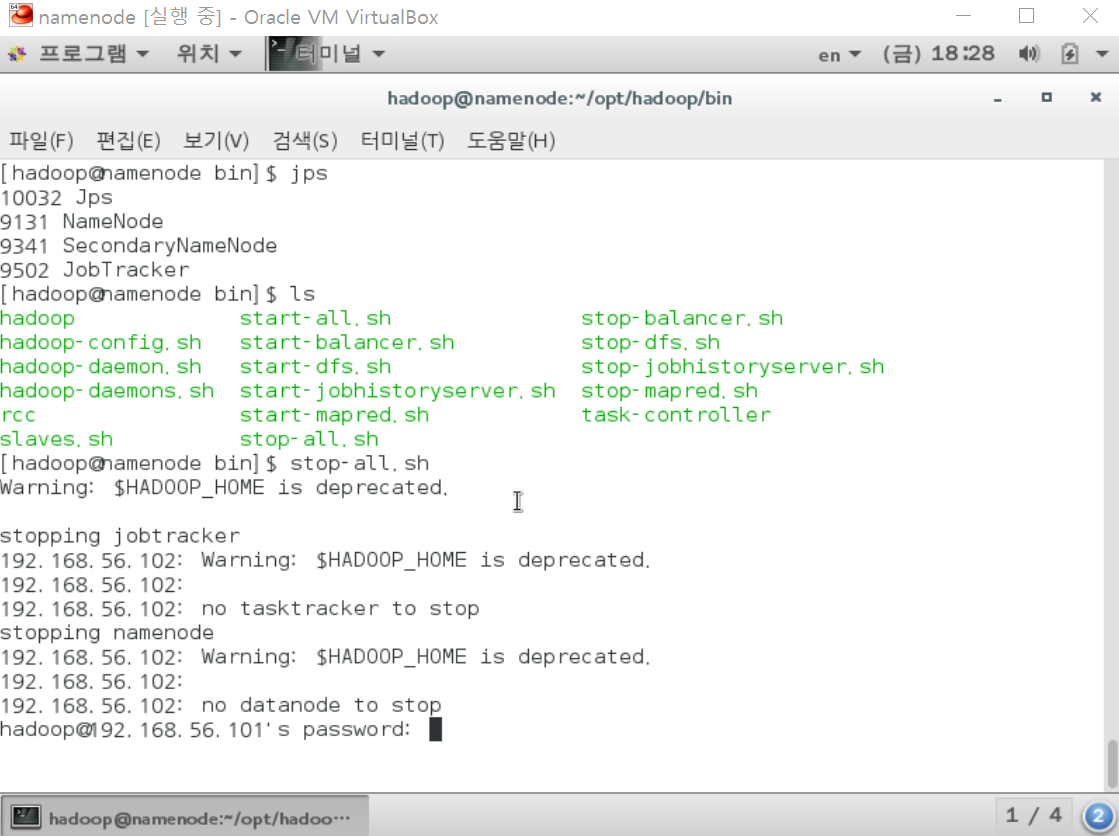
자 이제 다시 한번 돌려볼까요.
[hadoop@namenode ~] start-all.sh
[hadoop@namenode ~] jps

자 이제는 datanode에서 jps를 확인해 봅니다.
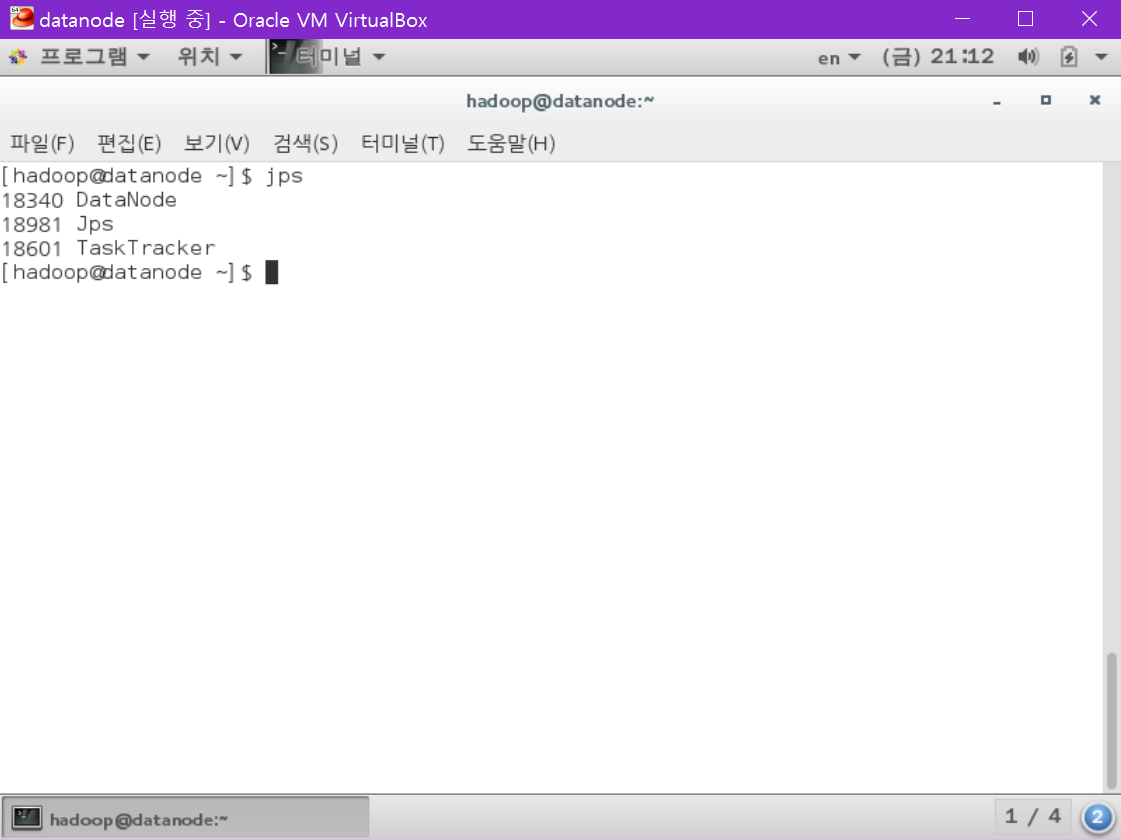
완벽합니다.
하둡 사용 중에 강제 종료를 당할 시에는 실시간 메타데이터가 끊기게 되어 오류가 생깁니다.
(namenode에서는 메타데이터가 datanode에서는 데이터 조각이 사라집니다.)
이럴 시에는 ~/opt/hadoop/dfs 의 dfs 디렉터리를 삭제하시면 됩니다. 이후에 hadoop -format 부터 다시 시작해야 합니다.
'하둡' 카테고리의 다른 글
| 하둡 설치하기-2 CentOS7 기본 설정 및 JAVA 설치 (1) | 2016.05.06 |
|---|---|
| 하둡 설치하기-1 VirtualBOX와 CentOS7 설치 (1) | 2016.05.04 |
| 하둡 Hadoop 02-1 Data logistics (0) | 2016.04.19 |
| 하둡 Flume (0) | 2016.04.19 |
| 하둡 Hadoop 01-2 하둡 개요 (0) | 2016.01.28 |
하둡 설치하기-3 Zookeeper, Hadoop 설치
이전 포스트
하둡
하둡 설치하기-1 VirtualBOX와 CentOS7 설치
하둡 설치하기-2 CentOS7 기본 설정 및 JAVA 설치
3부 Zookeeper 및 Hadoop 설치
Zookeeper 설치
Zookeeper는 분산환경에서 서버들간에 상호조정이 필요한 다양한 서비스를 제공하는 시스템입니다.
Firefox에서 zookeeper를 검색합니다.
사이트로 이동합니다.
현재 이용가능한 버전이 보입니다.
우리는 3.4.8 버전을 사용할 것입니다.
zookeeper를 다운받기 위해 다음의 명령어를 입력하고 다운을 받습니다.
또한 압축을 풀고 소프트 링크로 묶습니다.
** opt 디렉터리에서 다음의 명령어를 실행해 주세요
[namenode@localhost ~]$ wget
http://apache.mirror.cdnetworks.com/zookeeper/zookeeper-3.4.8/zookeeper-3.4.8.tar.gz
압축을 풉니다.
[namenode@localhost ~]$ tar -xvzf zookeeper-3.4.8.tar.gz
[namenode@localhost ~] ln -s zookeeper-3.4.8 zookeeper
우선 zookeeper의 환경 설정 파일을 만들어야 합니다. 기존의 sample.cfg를 복사합니다.
[namenode@localhost ~] cd zookeeper/conf
[namenode@localhost ~] cp zoo_sample.cfg zoo.cfg
zoo.cfg를 vi로 열어 수정합니다.
dataDir=/home/hadoop/opt/zookeeper/tmp
server.1=namenode:2888:3888
server.2=datanode:2888:3888
다음은 zookeeper에서 myid를 지정해야 합니다.
[namenode@localhost ~] cd ~/opt/zookeeper
[namenode@localhost ~] vi myid
namenode는 1이고, datanode는 2 입니다.
다음으로 Zookeeper의 환경변수를 설정해야 합니다.
# ZOOKEEPER
export ZOOKEEPER_HOME=/home/hadoop/opt/zookeeper
다음 PATH 줄 수정
export PATH=$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$PATH
/etc/profile을 업데이트 합니다.
[namenode@localhost ~] source /etc/profile
Hadoop 1.2.1 설치
이번에는 Firefox에 hadoop을 검색해봅시다.
http://hadoop.apache.org/ 사이트로 이동합니다.
우리는 첫 하둡 설치로 1.2.1 버전을 설치할 것입니다. (추후에 2 버전 설치)
opt 디렉터리에서 다음의 명령어를 실행합니다.
[namenode@localhost ~] cd ~/opt
[namenode@localhost ~] wget http://apache.mirror.cdnetworks.com/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz
[namenode@localhost ~] tar -xvzf hadoop-1.2.1.tar.gz
[namenode@localhost ~] ln -s hadoop-1.2.1 hadoop
다운을 받고, 압축을 풀고, 소프트링크 파일을 생성하였습니다.
환경 설정 파일을 적용해보겠습니다.
[namenode@localhost ~] sudo vi /etc/profile
다음의 소스를 입력합니다.
export HADOOP_HOME=/home/hadoop/opt/hadoop
export HADOOP_COMMON_HOME= =/home/hadoop/opt/hadoop export HADOOP_YARN_HOME= =/home/hadoop/opt/hadoop
export HADOOP_CONF_DIR=/home/hadoop/opt/hadoop/conf
export PATH=(이전의코드에뒤로붙입니다):$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
소스 업데이트를 잊지 맙시다.
[namenode@localhost ~] source /etc/profile
자 이어서 Hadoop의 환경 설정(/opt/hadoop/conf/)을 진행해야 합니다.
•hadoop-env.sh
•slaves
•masters
•core-site.xml
•hdfs-site.xml
•mapred-site.xml
차근차근 진행해보죠
hadoop-env.sh
[namenode@localhost ~] vi hadoop-env.sh
다음 부분을 주석(#) 삭제하고, export JAVA_HOME=/home/hadoop/opt/java로 변경합니다.
또한 밑에, export HADOOP_HOME=/home/hadoop/opt/hadoop을 추가합니다.
/(단축키)를이용해 LOG_DIR을 검색합니다.
export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
다음은 _SLAVES를 검색합니다.
export HADOOP_SLAVES=${HADOOP_HOME}/conf/slaves
다음은 PID_DIR을 검색합니다
export HADOOP_PID_DIR=${HADOOP_HOME}/pids
로 수정합니다.
slaves
[namenode@localhost ~] vi slaves
datanode 를 입력합니다.
masters
[namenode@localhost ~] vi masters
namenode을 입력합니다.
이제부터는 xml파일 수정인데 미리 다음의 코드를 만들어주시고 복붙하면서 작업해주세요
<property>
<name></name>
<value></value>
</property>
core-site.xml
[namenode@localhost ~] vi core-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/opt/hadoop/tmp</value>
</property>
</configuration>
다음과 입력하고 저장합니다.
hdfs-site.xml
[namenode@localhost ~] vi hdfs-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://namenode:9000</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/opt/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.name.edits.dir</name>
<value>${dfs.name.dir}</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/opt/hadoop/dfs/data</value>
</property>
</configuration>
mapred-site.xml
[namenode@localhost ~] vi mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>namenode:9001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>${hadoop.tmp.dir}/mapred/local</value>
</property>
<property>
<name>mapred.system.dir</name>
<value>${hadoop.tmp.dir}/mapred/system</value>
</property>
</configuration>
완료되었습니다.
datanode 생성하기
datanode 생성(namenode 복제)
datanode를 생서하기 앞서 namenode를 끕니다.
Oracle VM VirtualBox 관리자 창을 오픈합니다.
namenode를 선택하여 설정을 누르고 네트워크에서 어댑터를 추가해야 합니다.
어댑터 2에서 네트워크 어댑터 사용하기를 선택합니다.
다음에 연결됨에서 호스트 전용 어댑터를 선택하고 확인 버튼을 누릅니다.
복제를 눌러 namenode를 복사합니다.
다음의 팝업 창에서 datanode로 변경하고 모든 네트워크 카드의 mac 주소 초기화를 체크합니다.
복제 버튼을 누릅니다.
복제 중입니다.
완료되면 목록에서 datanode를 확인할 수 있습니다.
우선 namenode 부터 시작 합니다.
이어서 datanode로 시작합니다.
hadoop 사용자로 로그인 합니다.
두 개의 머신의 ifconfig를 통해 ip를 차례대로 확인합니다.
namenode ->192.168.56.101
datanode -> 192.168.56.102
datanode를 선택하고 다음의 명령어를 입력합니다.
[hadoop@localhost ~] sudo vi /etc/sysconfig/network
CentOS 7에서는 다음의 명령어로 호스트 네임을 변경할 수 있습니다.
namenode에서 다음을 실행합니다.
[hadoop@localhost ~] hostnamectl set-hostname namenode
[hadoop@localhost ~] hostname
[hadoop@localhost ~] sudo reboot
datanode에서 다음을 실행합니다.
[hadoop@localhost ~] hostnamectl set-hostname datanode
[hadoop@localhost ~] hostname
[hadoop@localhost ~] sudo reboot
최종 리부팅하고 터미널을 오픈하면 hostname이 변경된것을 확인할 수 있습니다.
datanode의 Zookeeper myid를 변경해야 합니다.
[hadoop@datanode ~] cd ~/opt/zookeeper && vi myid
2로 변경합니다.
SSH 통신
다음에서는 SSH 통신을 진행할 것입니다.
namenode로 들어갑니다.
[hadoop@namenode ~] ssh-keygen -t rsa
enter enter enter
[hadoop@namenode ~] ssh-copy-id 192.168.56.102
yes 비밀번호 입력
자 이제 SSH 통신을 진행해봅니다.
[hadoop@namenode ~] ssh datanode
yes
터미널 창이 datanode 쉘로 변경되는 것을 확인할 수 있습니다.
이곳 배쉬에서 위의 ssh-keygen을 똑같이 실행합니다.
[hadoop@datanode ~] ssh-keygen -t rsa
[hadoop@datanode ~] ssh-copy-id 192.168.56.101
자 이제 exit 명령어를 입력해 ssh 통신에서 logout 합니다.
[hadoop@datanode ~] exit
하둡 실행하기
namenode에서 다음의 명령어를 실행합니다.
[hadoop@namenode ~] hadoop namenode -format
[hadoop@namenode ~] cd ~/opt/hadoop/bin
[hadoop@namenode ~] start-all.sh
실행 도중에 datanode의 비밀번호를 입력하셔야 됩니다.
[hadoop@namenode ~]jps
다음과 같이 JPS / NameNode / SecondaryNameNode / JobTracker 가 나와야 합니다.
datanode로 이동합니다.
똑같이 jps 명령어를 실행해봅니다.
다음과 같이 JPS / DataNode / TaskTracker 가 나와야 성공입니다.
DataNode가 나오지 않는 군요…
이럴 경우에는 log를 살펴봐야 합니다.
[hadoop@datanode ~] cd ~/opt/hadoop/logs
[hadoop@namenode ~] vi hadoop-hadoop-datanode-datanode.log
vi를 통해 열어 보니 다음과 같은 에러를 볼 수 있습니다.
주로 이러한 ‘호스트로 갈 루트가 없음’ 문제는 방화벽 해제를 통해 해결을 볼 수 있습니다.
namenode와 datanode에 다음과 같은 명령어를 입력합니다 .
iptables 서비스를 중지
[hadoop@namenode]$ sudo systemctl stop iptables
[hadoop@datanode]$ sudo systemctl stop iptables
하둡 정지 시키는 경우는 다음의 명령어를 입력합니다.
/opt/hadoop/bin/에서
[hadoop@namenode ~] stop-all.sh
자 이제 다시 한번 돌려볼까요.
[hadoop@namenode ~] start-all.sh
[hadoop@namenode ~] jps
자 이제는 datanode에서 jps를 확인해 봅니다.
완벽합니다.
하둡 사용 중에 강제 종료를 당할 시에는 실시간 메타데이터가 끊기게 되어 오류가 생깁니다.
(namenode에서는 메타데이터가 datanode에서는 데이터 조각이 사라집니다.)
이럴 시에는 ~/opt/hadoop/dfs 의 dfs 디렉터리를 삭제하시면 됩니다. 이후에 hadoop -format 부터 다시 시작해야 합니다.
'하둡' 카테고리의 다른 글
| 하둡 설치하기-2 CentOS7 기본 설정 및 JAVA 설치 (1) | 2016.05.06 |
|---|---|
| 하둡 설치하기-1 VirtualBOX와 CentOS7 설치 (1) | 2016.05.04 |
| 하둡 Hadoop 02-1 Data logistics (0) | 2016.04.19 |
| 하둡 Flume (0) | 2016.04.19 |
| 하둡 Hadoop 01-2 하둡 개요 (0) | 2016.01.28 |