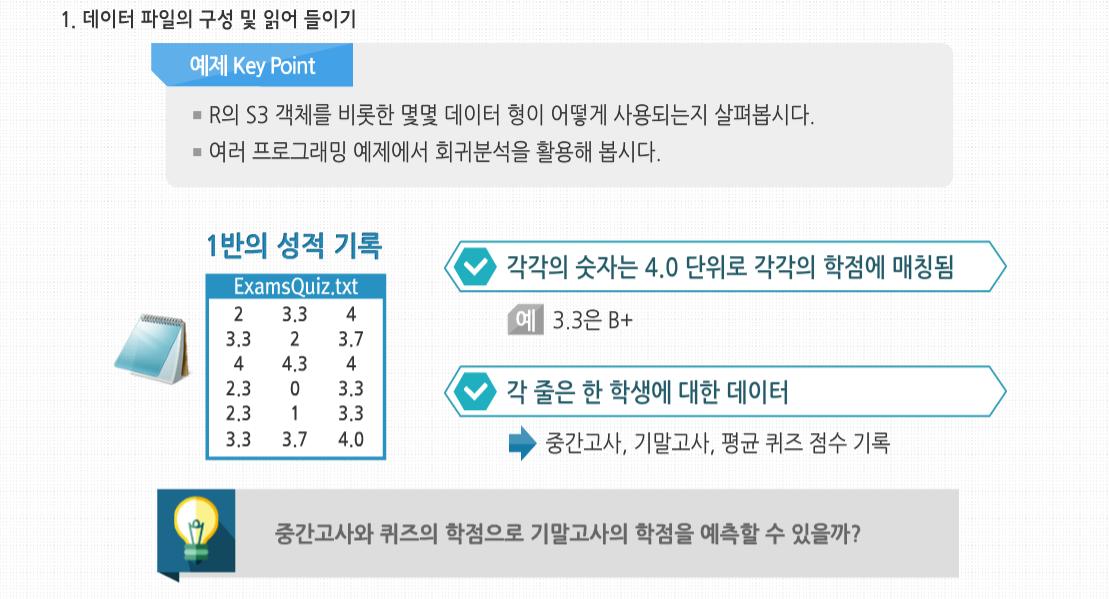
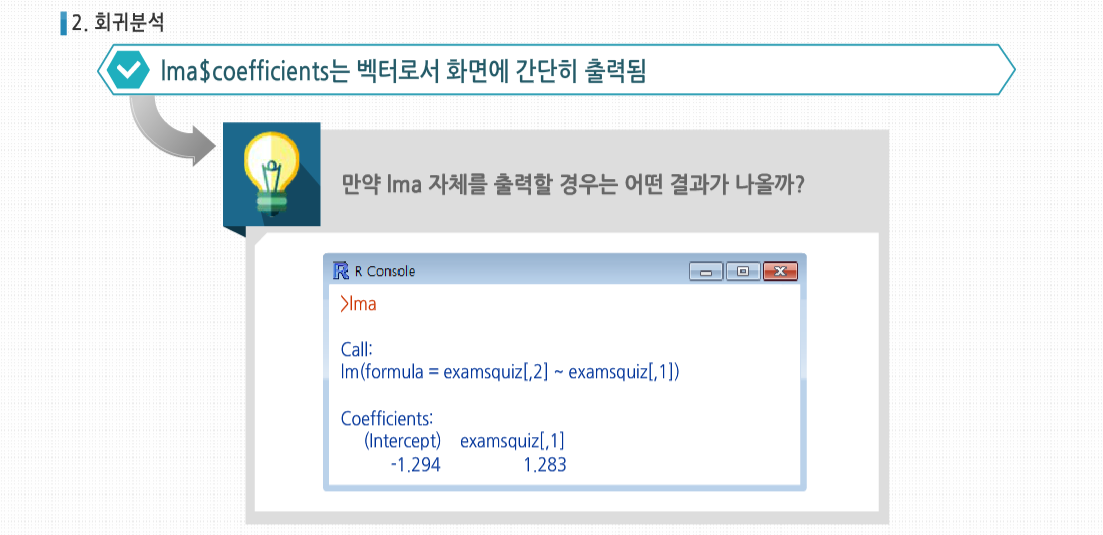
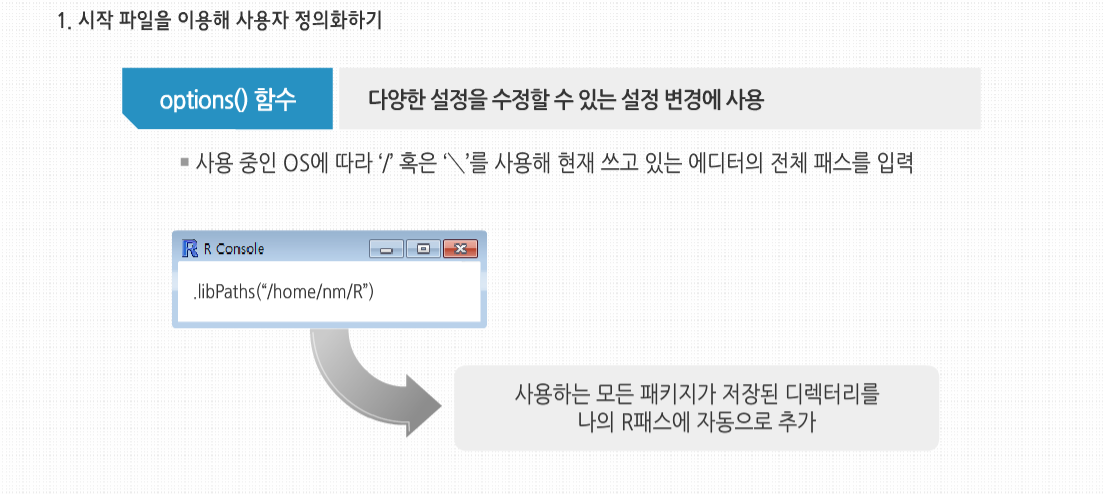
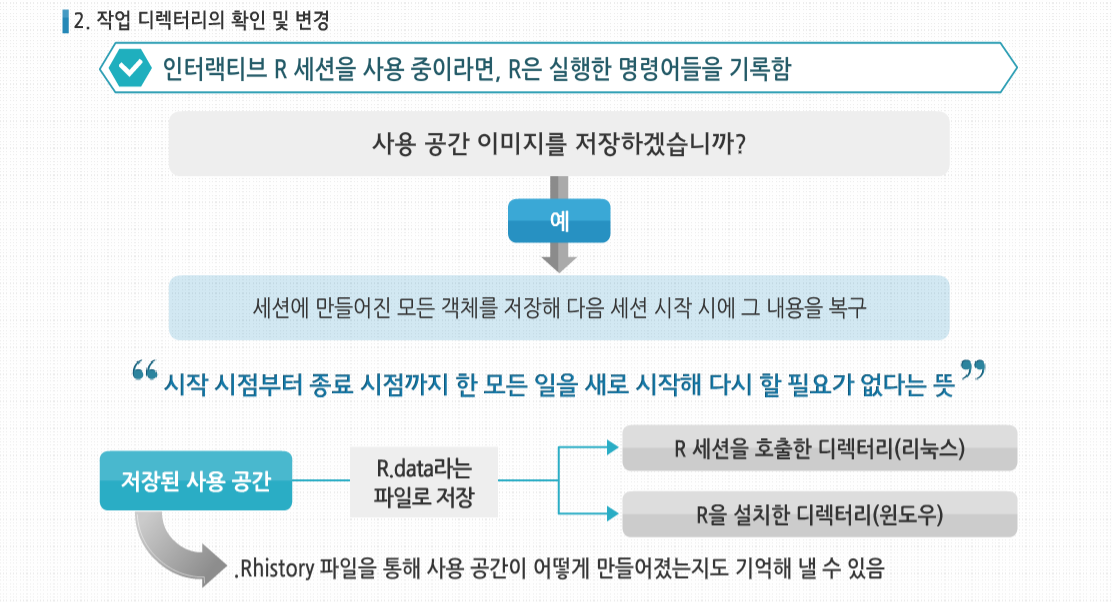
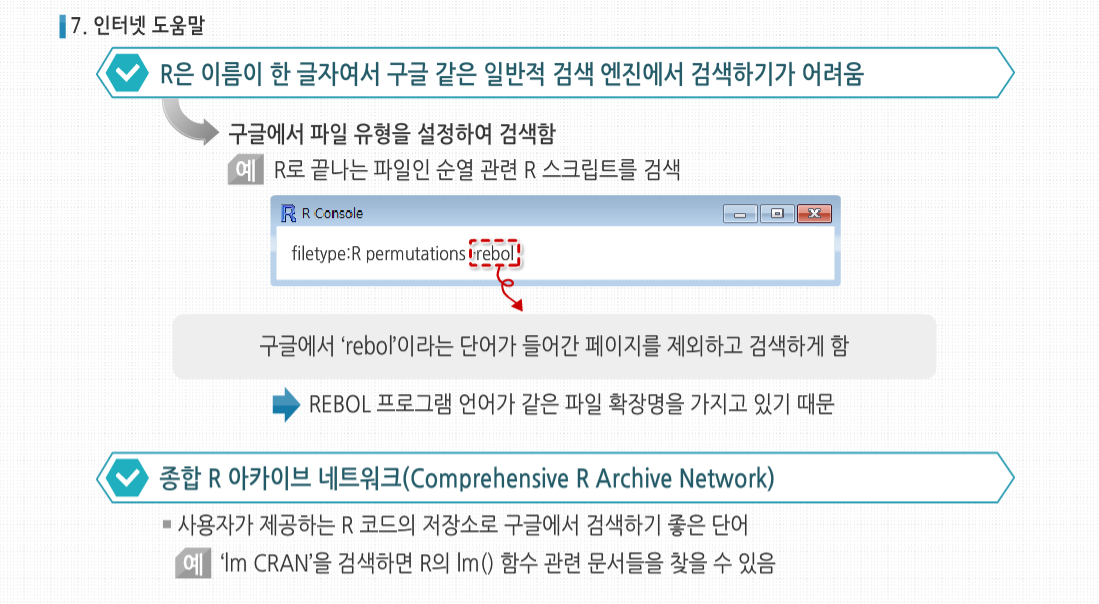
R 3.2.1 프로그래밍 - 시작과 종료 및 도움말 시작하기 회귀분석(Regression Analysis)이란 일반적으로 한 변량값의 변화와 다른 한 변량값의 변화가 갖는 수학적인 함수식을 파악함으로써 두 변량 사이의 상호관계를 추론하게 되는 방법을 말합니다. 회귀(回歸)란 용어는 아버지와 자녀들의 신장을 비교 연구하였던 19세기 말 영국의 유전학자인 Francis Galton의 연구에서 유래하였다고 합니다. 이후 이 용어는 둘 또는 그 이상의 변량들 관계의 특성을 묘사하는 데 사용되고 있습니다. 회귀분석의 적용 예로 맥주에 대한 수요 분석 예시를 살펴 봅시다. 우리 나라의 향 후 맥주 수요를 알고 싶다고 하는 경우, 맥주 수요에 영향을 미치는 변수가 단 하나밖에 없다고 가정해본다면, 알고 싶은 맥주 수요가 종속 변수고, 그 맥주 수요에 영향을 미치는 변수가 독립 변수가 될 것입니다. 그래서 종속 변수를 #5 Y로 놓고 독립 변수를 X로 놓으면, Y = aX + b입니다. 사실 이 b는 X가 0인 경우, 즉 독립 변수가 아무런 영향력이 없는 경우를 말합니다. 그렇다 해도 기본적으로 자연 발생적인 맥주 수요는 있게 마련이므로 X가 0라고 해도 있게 되는 기본적인 수요입니다. 즉, 우리가 아는 Y 절편을 의미합니다. 이제 a와 b라는 수치를 알아야 우리가 X라는 변수값을 대입하면 Y값을 얻게 되는 것입니다. 회귀분석이란 이와 같이 독립 변수에 영향을 미치는 종속 변수가 단 하나밖에 없는 경우를 말합니다. 확장 예제: 시험 성적 회귀 분석 확장예제 : 시험 성적 회귀분석 시험 성적을 간단한 회귀분석 해보도록 합시다. 이 예제에서는 실제로 프로그래밍할 일은 많지 않지만 R의 S3객체를 비롯한 몇몇 데이터 형이 어떻게 사용되는 지를 볼 수 있습니다. 또한 앞으로 다룰 여러 프로그래밍 예제의 기초가 될 것입니다. 여기에 1반의 성적이 기록된 ExamsQuiz.txt라는 파일이 있습니다. 이 파일의 내용은 다음과 같습니다. 각각의 숫자는 4.0 단위로 각각의 학점에 매칭됩니다. 예를 들어 3.3은 B+인 식입니다. 각 줄은 한 학생에 대한 데이터로서 중간고사, 기말고사, 평균 퀴즈 점수가 기록돼 있습니다. 이 파일에 기록되어 있는 중간고사와 퀴즈의 학점으로 기말고사의 학점을 예측할 수 있을까요? 일단 데이터 파일을 읽어 들입니다. 파일에는 각각의 학생들의 점수를 가리키는 변수에 대한 이름이 첫 줄에 기록돼 있지 않으므로, 함수 호출 시 header=FALSE라고 정의해 줬습니다. 이는 함수의 기본 인수에 대한 예시이기도 합니다. 사실 header인수의 기본값은 원래 FALSE이므로 굳이 이렇게 명시해 줄 필요는 없지만, 이렇게 확실히 해두는 것이 좋습니다. 이제 데이터 파일의 내용은 R의 데이터 프레임 객체인 examsquiz에 기록됐습니다. 파일이 제대로 읽혔는지 체크하기 위해 앞 몇 줄만 확인해 봅시다. 데이터의 이름이 지정돼 있지 않으므로 R에서 각 행에 V1, V2, V3라고 이름을 붙였습니다. 열 번호는 왼쪽에서 볼 수 있습니다. 그럼 본격적으로 회귀분석을 시작해 봅시다. 우선 exam1에서 exam2를 예측해 봅시다. 그리고 lm() 함수를 호출해 R에서 다음의 예측 방정식을 만들어 봅시다. 여기서 β0 과 β1 은 데이터를 통해 추정할 상수입니다. 다르게 말하자면 이 데이터에서 (exam1, exam2) 쌍으로 이뤄진 값을 직선에 최대한 맞출 것입니다. 이때 고전적인 최소 제곱법을 사용해 계산할 것입니다. examsquiz 데이터 프레임의 첫째 행인 exam1 전체는 examsquiz[ ,1]로 나타낼 수 있음을 기억하시기 바랍니다. 첫 번째 기호를 생략한 것은 이 행 전체를 나타내겠다는 뜻입니다. exam2 값도 비슷한 방법으로 표현할 수 있습니다. 그러므로 lm() 함수는 examsquiz의 첫 번째 행 값으로 둘째 행 값을 예측할 것입니다. 데이터 프레임을 벡터를 원소를 가진 리스트로 생각해 다음과 같이 쓸 수도 있습니다. 여기서 각 행은 이 리스트의 V1, V2,V3에 해당하는 요소입니다. lm()의 결과는 lma라는 객체에 저장돼 있습니다. 이 객체는 lm 클래스의 인스턴스입니다. attribute()를 호출해 이 객체의 요소들을 확인할 수 있습니다. 보통, 보다 자세한 수치를 확인하기 위해 str(lma)를 호출합니다. βi 에 대한 추정치는 lma$coefficients에 저장돼 있습니다. 이런 이름을 프롬프트에 입력해 값을 출력할 수 있습니다. 또한 너무 짧아져서 이름이 모호해질 정도가 아니라면 각 요소 이름을 단축해 타이핑을 적게 하는 것도 가능합니다. 예를 들어 리스트가 xyz, xywa, xbcde라는 요소로 이뤄졌다면, 두 번째와 세 번째 요소는 xyw와 xb로 축약해 사용할 수 있습니다. 이를 통해 다음처럼 입력하는 것도 가능합니다. lma$coefficients는 벡터로서 화면에 간단히 출력됩니다. 하지만 만약 lma 자체를 출력할 경우 어떤 결과가 나오는지 확인해 봅시다. 여기서 잠깐, R은 왜 이 내용 외의 lma의 다른 요소들은 출력하지 않을까요? 답은 R이 제네릭 함수 중 하나인 print() 함수를 사용한다는 데에 있습니다. 제네릭 함수로서 print()는 lm 클래스 객체를 출력하는 print.lm() 함수가 동작하도록 할 뿐이고, 실제 이 함수가 동작한 값이 출력됩니다. 제네릭 함수인 summary() 함수를 호출하면 lma의 내용을 보다 상세히 볼 수 있습니다. 이 함수는 내부에서 summary.lm() 함수를 호출해 회귀분석에 최적화된 요약 내용을 출력합니다. 다른 많은 제네릭 함수 또한이 클래스에 대해 정의돼 있습니다. exam1 과 quiz 점수를 모두 이용해 exam2의 값을 예측하는 방정식을 추정하기 위해서는 + 기호를 사용합니다. 여기서 + 기호는 두 값의 합을 계산하는 뜻이 아님을 기억합시다. 이는 예측 변수를 구분하는 기호로 사용될 뿐입니다. 시작과 종료 시작과 종료 R의 시작과 종료에 대해 살펴봅시다. 다른 복잡한 프로그램들처럼 R의 구동방식 또한 시작 파일을 이용해 사용자 정의화할 수 있습니다. 게다가 R은 실행한 기록이나 결과물 같은 세션의 전체 혹은 일부를 저장할 수 있습니다. 만약 모든 R 세션을 시작할 때 실행됐으면 하는 R 명령어가 있다면, 그 명령어를 현재 R이 구동되는 디렉터리나 홈 디렉터리의 .Rprofile 파일에 넣어 놓으면 됩니다. 홈 디렉터리는 이 파일을 먼저 찾아 실행해 이 파일에서 특정 프로젝트 별 사용자 프로파일을 사용할 수 있게 해 줍니다. 예를 들어 R에서 edit() 함수를 호출했을 때, 사용할 텍스트 에디터를 설정하고 싶다면 .Rprofile 파일 안에 다음과 같은 한 줄을 입력하면 됩니다. 이는 리눅스 사용자일 때에 한해 적용됩니다. R의 options() 함수는 다양한 설정을 수정할 수 있는 설정 변경에 사용됩니다. 사용 중인 OS에 따라 ‘/’ 혹은 ‘\’를 사용해 현재 쓰고 있는 에디터의 전체 패스를 입력할 수 있습니다. 예를 들어, 집에서 사용하는 리눅스 머신의 .Rprofile에 다음과 같은 줄을 입력했다고 가정합시다. 이 줄은 내가 사용하는 모든 패키지가 저장된 디렉터리를 나의 R패스에 자동으로 추가한다는 내용입니다. 많은 프로그램처럼 R은 현재 사용 중인 디렉터리를 쓰려는 경향이 있습니다. 이 디렉터리는 리눅스나 맥OS 사용자라면 보통 R을 구동할 때 사용 중인 디렉터리가 될 것입니다. 윈도우의 경우에는 보통 ‘내문서‘ 폴더를 말합니다. 이때 R 세션에서 다른 파일을 참조하려면, 해당 파일들이 이런 디렉터리에 포함돼 있어야 합니다. 그러므로 항상 이와 같은 명령어를 사용해 현재의 디렉터리를 확인해야 합니다. 또한 다음의 예제처럼 현재 사용하려는 디렉터리를 “”를 사용해 setwd()명령어 안에 입력함으로써 현재 사용 중인 디렉터리를 변경할 수 있습니다. 이렇게 하면 현재 사용 중인 디렉터리가 q로 바뀝니다. 인터랙티브 R 세션을 사용 중이라면, R은 실행한 명령어들을 기록할 것입니다. 만약 R 세션 종료 시에 나오는 ‘사용 공간 이미지를 저장하겠습니까?’라는 질문에 ‘예’라고 답하면, R은 그 세션에 만들어진 모든 객체를 저장해 다음 세션 시작 시에 그 내용을 복구할 것입니다. 시작 시점부터 종료 시점까지 한 모든 일을 새로 시작해 다시 할 필요가 없다는 뜻입니다. 저장된 사용 공간은 R 세션을 호출한 디렉터리(리눅스)나 R을 설치한 디렉터리(윈도우)에 R.data라는 파일로 저장됩니다. 명령어를 기록하는 .Rhistory 파일을 통해 사용 공간이 어떻게 만들어졌는지도 기억해 낼 수 있습니다. 보다 빠르게 R을 시작하거나 종료할 때 Vanillal 옵션을 적용해 R을 실행하면, 파일들을 로딩하고 세션 내용을 끝에서 종료하는 단계를 건너뛸 수 있습니다. Vanilla와 ‘모두 로딩하는 단계‘ 사이의 옵션들도 있습니다. 시작 파일에 대한 정보를 보다 자세히 알고 싶다면 다음과 같이 입력해 R의 온라인 도움말을 검색할 수도 있습니다. 도움말 사용하기 도움말 사용하기 R에 대해 더 배우고 싶다면 방대한 양의 리소스를 활용할 수 있습니다. 우선 웹에서 제공하는 다양한 기능을 이용할 수 있습니다. 또한 상당수는 R 내부에 문서화돼 있습니다. 이번 시간에는 R의 내장 도움말 일부와 인터넷 도움말의 일부를 함께 살펴 보겠습니다. 온라인 도움말을 보기 위해서는 help()를 호출하는 방법이 있습니다. 예를 들어 seq() 함수에 대한 정보가 필요하면 다음과 같이 입력합니다. help()의 단축키는 ‘?’입니다. 특수 문자와 일부 예약어들을 help() 함수에 사용할 때는 “”를 동시에 사용해야 합니다. 예를 들어 〈 에 대한 도움말을 보기 위해서는 다음과 같이 입력하면 됩니다. for 반복문에 대한 온라인 도움말을 보고 싶다면 다음과 같이 입력합니다. 각 도움말에는 예제가 실려 있습니다. R의 매우 좋은 기능 중 하나는 example() 함수를 사용해 이 예제들을 실제로 실행해 볼 수 있다는 것입니다. 다음 예제를 함께 살펴봅시다. seq() 함수는 산술적 방법을 통해 다양한 방법의 숫자 배열을 생성합니다. R에서 example(seq)를 실행하면 몇 개의 예제가 눈 앞에서 실행되는 것을 볼 수 있습니다. 이게 그래픽의 경우 얼마나 유용한지 상상해 보시기 바랍니다. example()함수는 그래픽의 경우 더욱 유용하게 사용 가능합니다. 그래픽 예제를 보고 싶다면 다음과 같이 입력합니다. 이 명령어를 통해 persp()함수의 예제 그래프들을 볼 수 있습니다. 다음 것을 보고 싶다면 R콘솔에서 엔터 키를 입력합니다. 각 예제의 코드는 콘솔에서 보여지므로 각 변수의 값을 바꿔 실행해 볼 수 있습니다. R의 문서를 구글 검색처럼 검색하려면 help.search() 함수를 사용하면 됩니다. 예를 들어 다변량 정규 분포 식을 통한 변수를 무작위로 생성하는 함수가 필요하다고 가정해볼까요? 이 경우 다음과 같이 검색할 수 있습니다. 이 경우 나온 답변의 일부만 발췌하면 mvrnorm()이라는 함수가 이런 일을 해 줄 것이고, 이 함수는 MASS 패키지에 있음을 알 수 있습니다. help.search()의 단축키 역시 ‘?’를 갖고 사용합니다. R의 내부 도움말 파일은 특정 함수에 대해 문서 이상의 내용을 포함하고 있습니다. 예를 들어 mvrnorm() 함수는 MASS 패키지에 포함돼 있습니다. 이 함수에 대해 다음과 같이 입력하면 관련 정보를 볼 수 있습니다. 또한 전체 패키지에 대한 내용을 보고 싶다면 다음과 같이 입력합니다. 도움말은 일반적인 주제에 대해서도 사용할 수 있습니다. 예를 들어 파일 관련 내용에 대해 알고 싶다면, 다음과 같이 입력해 보시기 바랍니다. 이 경우 file.create() 같은 파일을 다루는 많은 함수에 대한 정보를 얻을 수 있습니다. 몇몇 다른 주제들은 다음과 같습니다. 특정 주제를 염두 해 두지 않더라도 검색해 보면 도움이 될 것입니다. OS의 쉘에서 명령어를 바로 입력 가능한 배치 모두가 있다는 사실을 기억해 봅시다. 이 경우 도움말을 사용하려면 다음과 같이 입력합니다. 예를 들어 INSTALL 명령어와 관련된 모든 옵션을 알고 싶다면, 다음과 같이 입력하시면 됩니다. 인터넷에는 R 관련 훌륭한 정보가 많습니다. 몇 개만 제시하면 다음과 같습니다. R은 이름이 한 글자여서 구글 같은 일반적 검색 엔진에서 검색하기가 어렵습니다. 다만 적용해 볼 수 있는 몇 가지 트릭이 있습니다. 그 중 하나는 구글에서 파일 유형을 설정하는 것입니다. R로 끝나는 파일인 순열 관련 R 스크립트를 검색하고 싶다면 다음과 같이 입력합니다. -rebol은 구글에서 ‘rebol’이라는 단어가 들어간 페이지를 제외하고 검색하게 합니다. REBOL 프로그램 언어가 같은 파일 확장명을 갖고 있기 때문입니다. 종합 R 아카이브 네트워크(comprehensive R Archive Network)는 사용자가 제공하는 R 코드의 저장소로서 구글에서 검색하기 좋은 단어입니다. 예를 들어 ‘1m CRAN’을 검색하면 R의 lm() 함수 관련 문서들을 찾을 수 있습니다.1. Data 파일의 구성 및 읽어 들이기
2. 회귀분석
3. 요약
1. 시작 file을 이용해 사용자 정의하기
2. 작업 directory의 확인 및 변경
1. R의 도움말 사용하기
2. help() 함수
3. example() 함수
4. 무엇을 찾는 정확하게 모르는 경우의 사용 방법
5. 다른 주제들에 대한 도움말
6. 배치 모드에서 도움말
7. 인터넷 도움말





















'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
|---|---|
| R 3.2.1 프로그래밍 - 행렬과 배열 만들기 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 이해 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - R의 개요와 데이터 구조 (0) | 2016.05.07 |