R 3.2.1 프로그래밍 - 데이터 프레임의 생성과 연산

데이터 프레임은 행렬과 비슷한 형태로 되어 있으나,
다른 속성을 지닙니다. 행렬은 같은 형태의 객체를 가지는 반면, 데이터 프레임은 각 열들이 서로 다른 형태의 객체를 가질 수 있습니다. 따라서 데이터 프레임은 범주형 변수를 가질 수도 있기 때문에 범주형 자료분석에 유용하게 사용됩니다.

데이터 프레임은 형태가 일반화된 행렬로서, 데이터 프레임이라는 하나의 객체에 여러 종류의 자료가 들어갈 수 있습니다. 데이터 프레임의 각 열은 각각 변수와 대응하며, 분석이나 모형 설정에 적합한 자료 객체입니다.

데이터 프레임의 기초
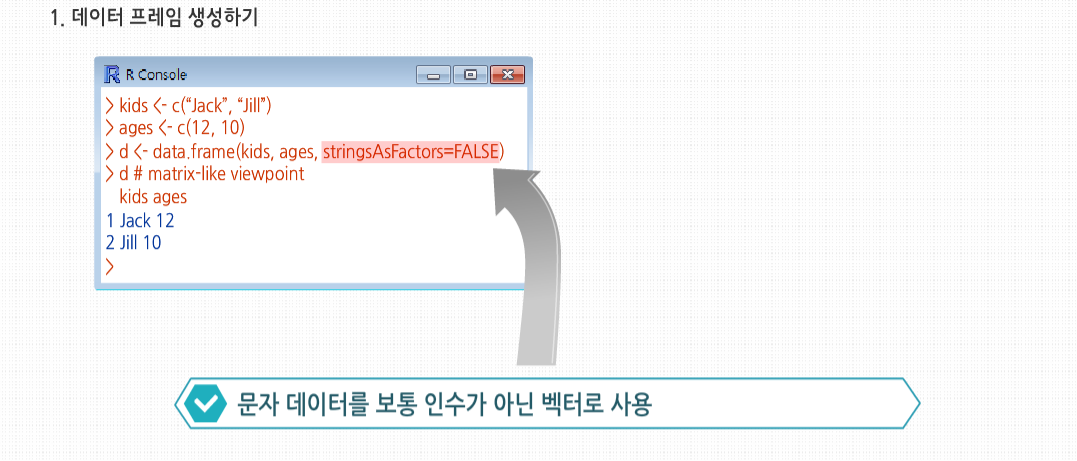
1. 데이터 프레임 생성하기
데이터 프레임의 기초
데이터 프레임 생성하기 학습에 앞서 간단한 예제를 먼저 살펴 봅시다. data.frame()(를 호출하면서 사용한 두 인수는 명확하게 설명 되어 있습니다. 이미 정의된 두 벡터 kids와 ages를 사용한 데이터 프레임을 생성하려는 것 입니다.
하지만 세 번째 인수인 strignsAsFactors=FALSE()에 대해서는 부연설명이 필요합니다. 만약 stringsAsFactors라고 명명된 인수가 따로 정의돼 있지 않다면, 기본적으로 stringsAsFactors는 참(TRUE)값을 가집니다. 이때 options()를 써서 기본값을 나열할 수도 있는데요.

이 예제에서 kids 같은 문자열 벡터를 사용해 데이터 프레임을 생성할 때, R에서는 그 벡터를 인수 Factor로 바꿉니다. 하지만 이 예제에서는 문자 데이터를 보통 인수가 아닌 벡터로 사용하므로 stringsAsFactors를 FALSE로 설정 했습니다.
2. 데이터 프레임에 접근하기
데이터 프레임이 만들어졌으니 잠깐 살펴볼까요?. D는 리스트이므로 구성 요소의 인덱스 값이나 이름을 통해 접근할 수 있습니다. 하지만 행렬처럼 사용할 수도 있는데요. d에 str()을 적용해 구분할 때에도 이를 확인할 수 있습니다. R은 d가 두 값에 대한 데이터를 저장하는 두 가지 관측자로 구성됐다는 것을 알려줍니다.

지금 보시는 데이터 프레임의 첫째 열에 접근하는 방법으로는 세 가지가 있습니다. 바로 d[[1]], d[,1], d$kids입니다. 이 중 세 번째 방법이 다른 두 방법에 비해 보다 명확한데요. 무엇보다 중요한 점은 안전하다는 것입니다. 이 방법이 열을 보다 명확히 정의할 뿐만아니라 다른 열을 잘못 참조할 가능성을 줄여줍니다. 하지만 R 패키지를 작성하는 등의 일반적인 코드에서는 d[,1] 같은 행렬 방식 표기법이 필요하죠. 이는 특히 부분 데이터 프레임을 추출하게 될 때 편리합니다.

3. 시험 성적을 회귀 분석하기
시험 성적을 회귀분석 해보는 예제를 봅시다. 다음 데이터 세트를 보면 각 줄에 한 명의 학생에 대한 세 개의 시험성적이 나와 있습니다. 이는 앞의 str()을 사용한 결과물에서 언급한 것 같은 고전적인 이차원 파일 방식인데요.
여기서는 파일의 한 줄에 통계 데이터 세트에서의 하나의 관측치를 담고 있는 형태입니다. 데이터 프레임의 개념은 이런 데이터를 변수 이름과 함께 하나의 객체로 캡슐화 하는 것입니다. 각 필드는 띄어쓰기로 구분이 됩니다. 또한, CSVcomma-separated value 파일에서 쉼표로 구분되는 것 같이 다른 구분자가 쓰인 경우 미리 명시해야 합니다. 그리고 첫 번째 줄에 기록된 변수명은 데이터에서 사용된 것과 동일한 구분자로 구분돼 있어야 하므로, 이 경우에는 띄어쓰기로 돼 있어야 합니다. 이 예제에서처럼 이름 자체에 띄어쓰기가 돼 있는 경우에는 따옴표로 묶여 있어야 합니다.
자, 그러면 띄어쓰기 부분이 점으로 채워진 열의 이름이 나타나도록 하기 위해 다음과 같이 입력해 봅시다.
결과 값은 다음과 같이 나타납니다.

데이터 프레임의 적용
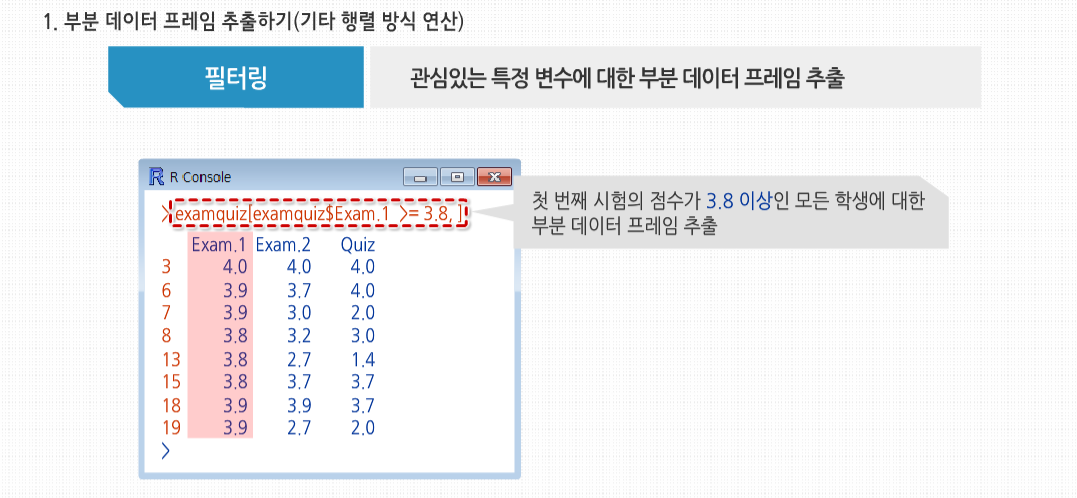
1. 부분 데이터 프레임 추출하기
데이터 프레임의 적용
다양한 행렬 연산은 데이터 프레임에도 적용이 가능합니다. 가장 중요하고 유용한 기능으로, 관심 있는 특정 변수에 대한 부분 데이터 프레임을 추출하기 위한 필터링이 있습니다. 데이터 프레임은 행과 열로 표현할 수 있습니다. 특히 행과 열에 대해 부분 데이터 프레임을 추출하는 것이 가능합니다.
R이 추가로 데이터 프레임을 만들지 않고 대신
벡터 examquiz[2:5,2]를 만들었습니다. 여기에 drop=FALSE를 명시해 주면 이를 하나의 열로 이뤄진 데이터 프레임으로 유지할 수 있습니다. 다양한 행렬 연산은 필터링 또한 가능합니다. 다음은 첫 번째 시험의 점수가 3.8 이상인 모든 학생에 대한 부분 데이터 프레임을 추출하는 방법입니다. 결과 값은 다음과 같습니다. 첫 번째 시험의 점수가 3.8 이상인 학생들만 필터링 되었습니다.
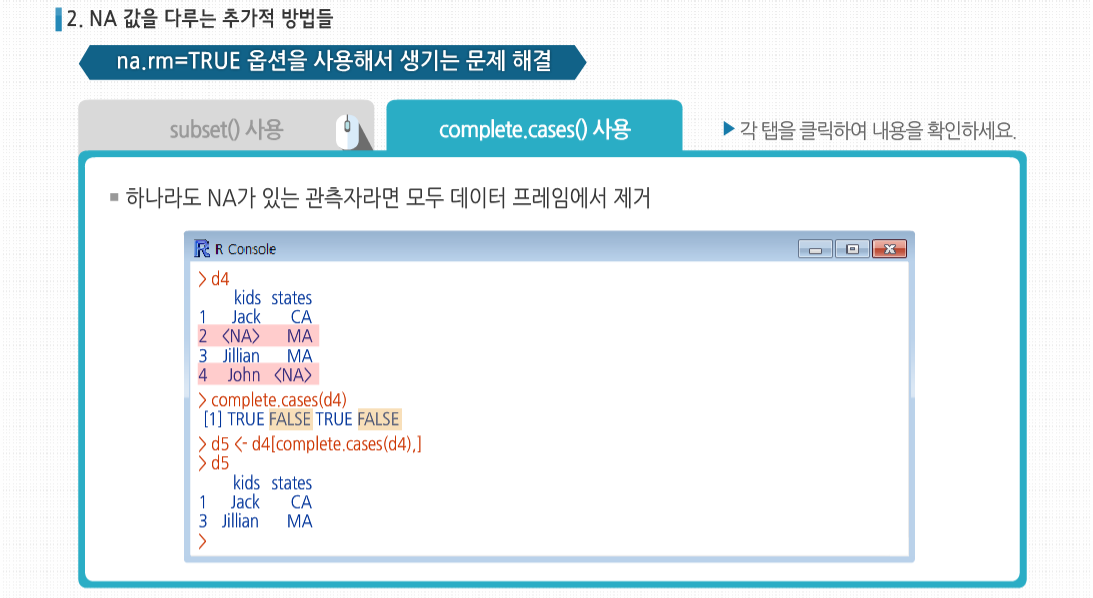
2. NA 값을 다루는 추가적 방법들
NA 값을 다루는 방법들에 대해서 알아봅시다. 우선, 첫 번째 학생의 두 번째 시험 점수가 누락됐다고 가정해봅시다. 이를 데이터 파일로 만들 때 다음과 같이 기록했을 것입니다. 어떤 통계 분석 과정에서든 R은 최선을 다해 결측치를 처리합니다.

하지만 간혹 R이 NA를 무시하도록 na.rm=TRUE 옵션을 설정해야 하는 경우가 있습니다. 지금처럼 시험 점수가 일부 누락된 경우, 두 번째 시험에 대해서 R의 mean()을 사용해 평균값을 계산할 때 첫 번째 학생의 점수는 건너뛰어야 할 것입니다. 그렇지 않을 경우 R은 평균값이 NA라는 결과를 낼 것이기 때문이죠.

그럼 na.rm=TRUE 옵션을 사용해서 생기는 문제는 어떻게 해결할 수 있을까요? subset() 함수를 사용해 해결하는 방법이 있는데요, 데이터 프레임의 열 부분에도 이를 적용할 수 있습니다. 열의 이름은 주어진 데이터 프레임으로부터 가져오는데, 우리가 사용하는 예제에서는 이렇게 입력할 필요가 없습니다. 대신 다음과 같이 수행합니다. 경우에 따라 하나라도 NA가 있는 관측자라면 모두 데이터 프레임에서 제거하고 싶을 수 있는데요. 이럴 땐 간단한 함수인 complete.cases()를 사용하면 됩니다. 2번째, 4번째 값은 불완전하므로 complete.cases(d4)의 결과는 FALSE가 됩니다. 이를 이용해 문제 없는 열을 결과값으로 사용할 수 있습니다.
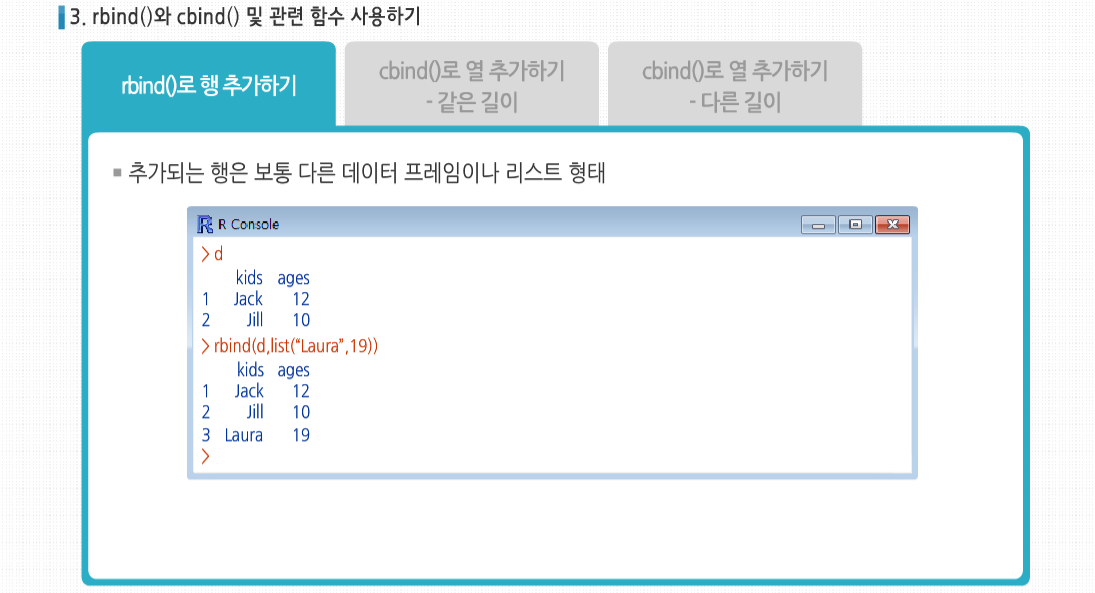
3. rbind()와 cbind() 및 관련 함수 사용하기
행렬 함수인 rbind()와 cbind는 크기 변경이 가능한 데이터 프레임에서도 사용할 수 있습니다.
rbind()를 사용해 행을 추가하거나, cbind()를 사용해 열을 추가할 수 있습니다. rbind()를 사용해 행을 추가할 때, 추가되는 행은 보통 다른 데이터 프레임이나 리스트 형태입니다.
또한 기존 데이터를 이용해 새 열을 추가할 수도 있는데요. 예를 들면 첫 번째 시험과 두 번째 시험의 차이를 하나의 변수로 추가할 수 있습니다. 그런데 이 경우 새 열의 이름은 너무 길고 공백도 있어서 사용하기에 좀 불편합니다. 이는 names()를 사용해 바꿀 수 있지만, 데이터 프레임의 리스트 성질을 사용해 이 결과를 데이터 프레임에 같은 크기의 열에 추가하는 게 더 좋습니다.
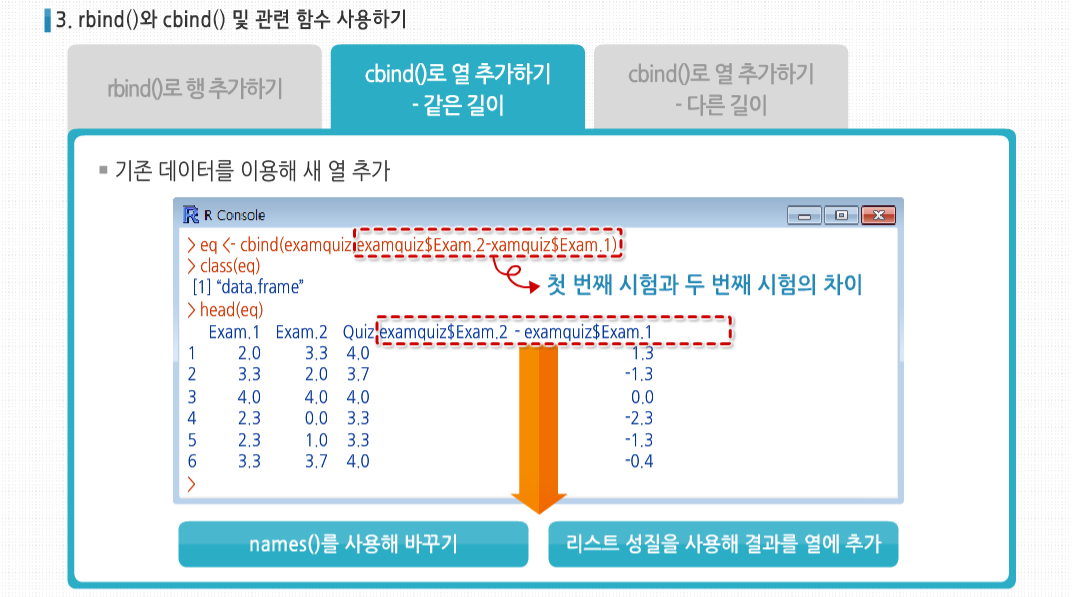
여기서 잠깐, 데이터 프레임 리스트의 성질을 사용해서 같은 크기의 열에 결과를 추가할 수 있는 방법은 무엇일까요? 언제든지 기존 리스트에 새 구성요소를 추가할 수 있으므로 ExamDiff라는 요소를 examquiz라는 리스트 혹은 데이터 프레임에 추가하여 해결하였습니다

또한, cbind()함수는 재사용을 활용할 수 있으므로 데이터 프레임에서 길이가 다른 열 역시 다음과 같이 추가할 수 있습니다.

4. apply() 적용하기
apply()는 한 열의 데이터가 모두 같은 형식일 때 데이터 프레임에 사용할 수 있습니다. 예를 들어 다음과 같이 각 학생 별로 최고 점수를 찾고자 하는 경우에 사용할 수 있습니다.

'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 팩터와 테이블의 이해와 활용 (3) | 2016.05.31 |
|---|---|
| R 3.2.1 프로그래밍 - 데이터 프레임의 결합과 적용 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 적용과 재귀 리스트 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
R 3.2.1 프로그래밍 - 데이터 프레임의 생성과 연산
데이터 프레임은 행렬과 비슷한 형태로 되어 있으나,
다른 속성을 지닙니다. 행렬은 같은 형태의 객체를 가지는 반면, 데이터 프레임은 각 열들이 서로 다른 형태의 객체를 가질 수 있습니다. 따라서 데이터 프레임은 범주형 변수를 가질 수도 있기 때문에 범주형 자료분석에 유용하게 사용됩니다.
데이터 프레임은 형태가 일반화된 행렬로서, 데이터 프레임이라는 하나의 객체에 여러 종류의 자료가 들어갈 수 있습니다. 데이터 프레임의 각 열은 각각 변수와 대응하며, 분석이나 모형 설정에 적합한 자료 객체입니다.
데이터 프레임의 기초
1. 데이터 프레임 생성하기
데이터 프레임의 기초
데이터 프레임 생성하기 학습에 앞서 간단한 예제를 먼저 살펴 봅시다. data.frame()(를 호출하면서 사용한 두 인수는 명확하게 설명 되어 있습니다. 이미 정의된 두 벡터 kids와 ages를 사용한 데이터 프레임을 생성하려는 것 입니다.
하지만 세 번째 인수인 strignsAsFactors=FALSE()에 대해서는 부연설명이 필요합니다. 만약 stringsAsFactors라고 명명된 인수가 따로 정의돼 있지 않다면, 기본적으로 stringsAsFactors는 참(TRUE)값을 가집니다. 이때 options()를 써서 기본값을 나열할 수도 있는데요.
이 예제에서 kids 같은 문자열 벡터를 사용해 데이터 프레임을 생성할 때, R에서는 그 벡터를 인수 Factor로 바꿉니다. 하지만 이 예제에서는 문자 데이터를 보통 인수가 아닌 벡터로 사용하므로 stringsAsFactors를 FALSE로 설정 했습니다.
2. 데이터 프레임에 접근하기
데이터 프레임이 만들어졌으니 잠깐 살펴볼까요?. D는 리스트이므로 구성 요소의 인덱스 값이나 이름을 통해 접근할 수 있습니다. 하지만 행렬처럼 사용할 수도 있는데요. d에 str()을 적용해 구분할 때에도 이를 확인할 수 있습니다. R은 d가 두 값에 대한 데이터를 저장하는 두 가지 관측자로 구성됐다는 것을 알려줍니다.
지금 보시는 데이터 프레임의 첫째 열에 접근하는 방법으로는 세 가지가 있습니다. 바로 d[[1]], d[,1], d$kids입니다. 이 중 세 번째 방법이 다른 두 방법에 비해 보다 명확한데요. 무엇보다 중요한 점은 안전하다는 것입니다. 이 방법이 열을 보다 명확히 정의할 뿐만아니라 다른 열을 잘못 참조할 가능성을 줄여줍니다. 하지만 R 패키지를 작성하는 등의 일반적인 코드에서는 d[,1] 같은 행렬 방식 표기법이 필요하죠. 이는 특히 부분 데이터 프레임을 추출하게 될 때 편리합니다.
3. 시험 성적을 회귀 분석하기
시험 성적을 회귀분석 해보는 예제를 봅시다. 다음 데이터 세트를 보면 각 줄에 한 명의 학생에 대한 세 개의 시험성적이 나와 있습니다. 이는 앞의 str()을 사용한 결과물에서 언급한 것 같은 고전적인 이차원 파일 방식인데요.
여기서는 파일의 한 줄에 통계 데이터 세트에서의 하나의 관측치를 담고 있는 형태입니다. 데이터 프레임의 개념은 이런 데이터를 변수 이름과 함께 하나의 객체로 캡슐화 하는 것입니다. 각 필드는 띄어쓰기로 구분이 됩니다. 또한, CSVcomma-separated value 파일에서 쉼표로 구분되는 것 같이 다른 구분자가 쓰인 경우 미리 명시해야 합니다. 그리고 첫 번째 줄에 기록된 변수명은 데이터에서 사용된 것과 동일한 구분자로 구분돼 있어야 하므로, 이 경우에는 띄어쓰기로 돼 있어야 합니다. 이 예제에서처럼 이름 자체에 띄어쓰기가 돼 있는 경우에는 따옴표로 묶여 있어야 합니다.
자, 그러면 띄어쓰기 부분이 점으로 채워진 열의 이름이 나타나도록 하기 위해 다음과 같이 입력해 봅시다.
결과 값은 다음과 같이 나타납니다.
데이터 프레임의 적용
1. 부분 데이터 프레임 추출하기
데이터 프레임의 적용
다양한 행렬 연산은 데이터 프레임에도 적용이 가능합니다. 가장 중요하고 유용한 기능으로, 관심 있는 특정 변수에 대한 부분 데이터 프레임을 추출하기 위한 필터링이 있습니다. 데이터 프레임은 행과 열로 표현할 수 있습니다. 특히 행과 열에 대해 부분 데이터 프레임을 추출하는 것이 가능합니다.
R이 추가로 데이터 프레임을 만들지 않고 대신
벡터 examquiz[2:5,2]를 만들었습니다. 여기에 drop=FALSE를 명시해 주면 이를 하나의 열로 이뤄진 데이터 프레임으로 유지할 수 있습니다. 다양한 행렬 연산은 필터링 또한 가능합니다. 다음은 첫 번째 시험의 점수가 3.8 이상인 모든 학생에 대한 부분 데이터 프레임을 추출하는 방법입니다. 결과 값은 다음과 같습니다. 첫 번째 시험의 점수가 3.8 이상인 학생들만 필터링 되었습니다.
2. NA 값을 다루는 추가적 방법들
NA 값을 다루는 방법들에 대해서 알아봅시다. 우선, 첫 번째 학생의 두 번째 시험 점수가 누락됐다고 가정해봅시다. 이를 데이터 파일로 만들 때 다음과 같이 기록했을 것입니다. 어떤 통계 분석 과정에서든 R은 최선을 다해 결측치를 처리합니다.
하지만 간혹 R이 NA를 무시하도록 na.rm=TRUE 옵션을 설정해야 하는 경우가 있습니다. 지금처럼 시험 점수가 일부 누락된 경우, 두 번째 시험에 대해서 R의 mean()을 사용해 평균값을 계산할 때 첫 번째 학생의 점수는 건너뛰어야 할 것입니다. 그렇지 않을 경우 R은 평균값이 NA라는 결과를 낼 것이기 때문이죠.
그럼 na.rm=TRUE 옵션을 사용해서 생기는 문제는 어떻게 해결할 수 있을까요? subset() 함수를 사용해 해결하는 방법이 있는데요, 데이터 프레임의 열 부분에도 이를 적용할 수 있습니다. 열의 이름은 주어진 데이터 프레임으로부터 가져오는데, 우리가 사용하는 예제에서는 이렇게 입력할 필요가 없습니다. 대신 다음과 같이 수행합니다. 경우에 따라 하나라도 NA가 있는 관측자라면 모두 데이터 프레임에서 제거하고 싶을 수 있는데요. 이럴 땐 간단한 함수인 complete.cases()를 사용하면 됩니다. 2번째, 4번째 값은 불완전하므로 complete.cases(d4)의 결과는 FALSE가 됩니다. 이를 이용해 문제 없는 열을 결과값으로 사용할 수 있습니다.
3. rbind()와 cbind() 및 관련 함수 사용하기
행렬 함수인 rbind()와 cbind는 크기 변경이 가능한 데이터 프레임에서도 사용할 수 있습니다.
rbind()를 사용해 행을 추가하거나, cbind()를 사용해 열을 추가할 수 있습니다. rbind()를 사용해 행을 추가할 때, 추가되는 행은 보통 다른 데이터 프레임이나 리스트 형태입니다.
또한 기존 데이터를 이용해 새 열을 추가할 수도 있는데요. 예를 들면 첫 번째 시험과 두 번째 시험의 차이를 하나의 변수로 추가할 수 있습니다. 그런데 이 경우 새 열의 이름은 너무 길고 공백도 있어서 사용하기에 좀 불편합니다. 이는 names()를 사용해 바꿀 수 있지만, 데이터 프레임의 리스트 성질을 사용해 이 결과를 데이터 프레임에 같은 크기의 열에 추가하는 게 더 좋습니다.
여기서 잠깐, 데이터 프레임 리스트의 성질을 사용해서 같은 크기의 열에 결과를 추가할 수 있는 방법은 무엇일까요? 언제든지 기존 리스트에 새 구성요소를 추가할 수 있으므로 ExamDiff라는 요소를 examquiz라는 리스트 혹은 데이터 프레임에 추가하여 해결하였습니다
또한, cbind()함수는 재사용을 활용할 수 있으므로 데이터 프레임에서 길이가 다른 열 역시 다음과 같이 추가할 수 있습니다.
4. apply() 적용하기
apply()는 한 열의 데이터가 모두 같은 형식일 때 데이터 프레임에 사용할 수 있습니다. 예를 들어 다음과 같이 각 학생 별로 최고 점수를 찾고자 하는 경우에 사용할 수 있습니다.
'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 팩터와 테이블의 이해와 활용 (3) | 2016.05.31 |
|---|---|
| R 3.2.1 프로그래밍 - 데이터 프레임의 결합과 적용 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 적용과 재귀 리스트 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |