R 3.2.1 프로그래밍 - 리스트의 적용과 재귀 리스트

연결 리스트는 각 노드가 데이터와 포인터를
가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조를 말합니다.

연결 리스트는 이름에서 말하듯이 데이터를 담고 있는 노드들이 서로 연결되어 있는데, 노드의 포인터가 다음이나 이전의 노드와의 연결을 담당하게 됩니다. 연결 리스트는 늘어선 노드의 중간지점에서도 자료의 추가와 삭제가 O(1)의 시간에 가능하다는 장점을 갖습니다. 그러나 배열이나 트리 구조와는 달리 특정 위치의 데이터를 검색해 낼 때는O(n)의 시간이 걸리는 단점도 갖고 있습니다.

연결 리스트의 종류로는 단순 연결 리스트, 이중 연결 리스트, 원형 연결 리스트가 있습니다. 단순 연결 리스트는 각 노드에 자료 공간과 한 개의 포인터 공간이 있고, 각 노드의 포인터는 다음 노드를 가리킵니다.

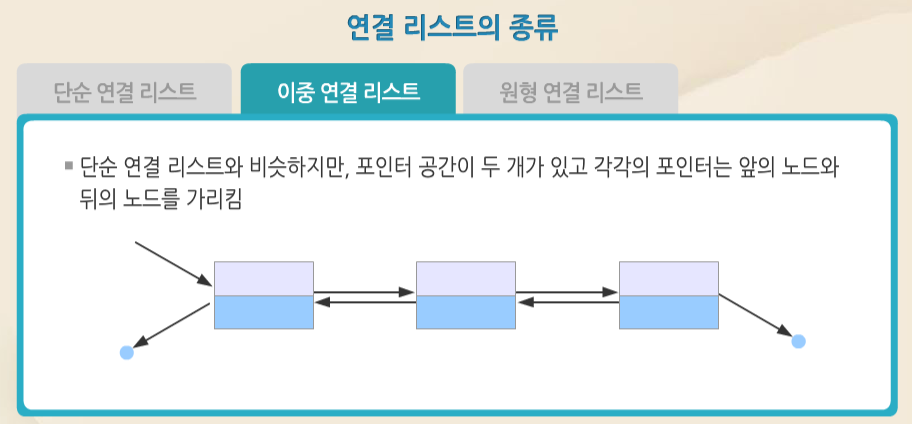
이중 연결 리스트의 구조는 단순 연결 리스트와 비슷하지만, 포인터 공간이 두 개가 있고 각각의 포인터는 앞의 노드와 뒤의 노드를 가리킵니다.
원형 연결 리스트는 일반적인 연결 리스트에 마지막 노드와 처음 노드를 연결시켜 원형으로 만든 구조를 말합니다.

리스트의 응용
1. 리스트 구성 요소와 값에 접근하기
리스트의 응용
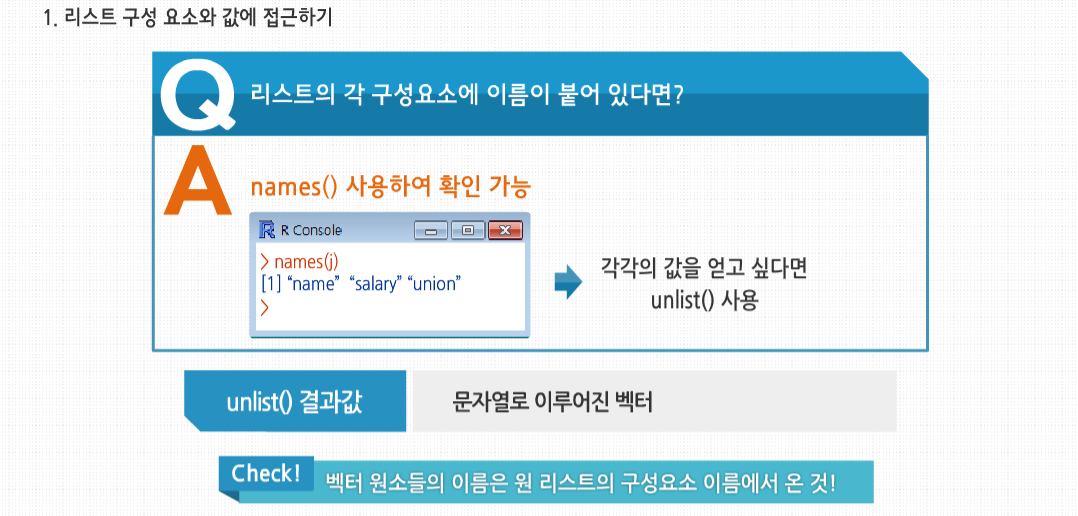
리스트 j의 name, salary, union처럼 리스트의 각 구성요소에 이름이 붙어 있다면, names()를 사용해 이를
확인할 수 있습니다. 또한 이에 대한 각각의 값을 얻고 싶다면, unlist()를 사용하면 됩니다. unlist()의 결과값은
문자열로 이뤄진 벡터입니다. 벡터 원소들의 이름은 원 리스트의 구성요소 이름에서 온 것임을 기억해 둡시다.
그러나 만약 값이 숫자로 시작한다면 숫자형 벡터를 얻게 됩니다. 따라서 이 경우 unlist()의 결과값은
숫자형 벡터입니다. 그럼 혼합된 경우는 어떠할까요? 이런 경우 R은 최대로 포함할 수 있는 형태를 고릅니다.
이 경우에는 문자열입니다. 이를 보면 각 형태에도 우선순위가 있다고 생각할 수 있고, 실제로 그렇습니다.
unlist()에 대하여 R에서는 리스트의 구성요소가 해체돼서 일반적 형식이 될 때, 그 결과는 보통 문자형 벡터로
나옵니다. 벡터는 각 구성요소 형식 중 다음 서열에서 최대한 높은 수치를 취합니다.


페어리스트의 경우 리스트로 취급합니다. wu는 리스트가 아닌 벡터지만, R은 각 원소에 이름을 붙여주었습니다. 이는 각 이름을 NULL로 설정해 제거할 수 있습니다. 다음과 같이
unname()을 사용해 각 원소의 이름을 직접 제거할 수도 있습니다. 필요한 경우 wu에 이름을 그대로 남겨 놓는 게좋을 수도 있으나, 필요 없다고 생각된다면 wun을 사용하지 않고, wu에 바로 값을 할당할 수도 있습니다.

2. 리스트에 함수 적용하기
리스트에 함수를 간편하게 적용할 수 있도록 하는 두 함수는 lapply()와 sapply() 입니다. list apply를 위한
lapply()는 행렬에 apply()를 적용하는 것처럼, 특정 함수를 리스트의 각 요소 혹은 리스트화 된 벡터에 적용하고 결과값으로 리스트를 반환합니다. 예제를 보면 R은 1:3과 25:29에 median()을 적용해 결과값으로 2와 27로 이뤄진 리스트를 반환했습니다. 이 경우 lapply()의 결과값은 벡터나 행렬로 간단하게 나타낼 수 있는데, 이런 역할을 하는 함수가 simplified [1]apply를 단순화한 sapply() 함수 입니다.

벡터화된 벡터 함수를 벡터에 적용하는 경우, 함수를 직접 적용하는 대신 sapply()를 사용하면 결과값을 원하는 행렬 형태로 만들 수 있습니다.
텍스트 일치 결과 생성 함수인 findwords()는 단어 별로 인덱싱 된 단어 위치의 리스트를 반환합니다.

이는 여러 면에서 리스트를 정렬하는 데 편리합니다. 입력 파일로 testconcorda.txt를 넣었을 때 결과입니다.
그리고 알파벳 순서대로 단어를 정렬해 보여주는 코드를 살펴보겠습니다. 단어가 각 리스트 요소의 이름이므로 names()를 호출해 단어들을 간단히 추출할 수 있습니다. 이를 알파벳 순서대로 정렬하고, 코드의 5번째 줄에서 리스트 인덱스로 이 버전을 사용합니다. 리스트에서 부분 리스트를 뽑아내기 위해 대괄호를 겹쳐 사용하지 않고 하나만 사용한다는 것을 기억합시다. 이때 sort() 대신 order를 사용할 수도 있습니다.

실행결과를 살펴볼까요? 제대로 잘 동작하고 있습니다. and가 가장 처음에 나오고 이어서 be가 나오는 형태입니다. 단어의 빈도 순서대로 정렬하는 것도 비슷한 방식으로 구현할 수 있습니다. 코드의 3번째 줄에서 wrdlst의 각 원소는 입력한 파일에서 주어진 단어의 위치를 표현하는 숫자로 된 벡터라는 사실을 활용합니다.
length()를 이 벡터에 호출하면, 각 단어가 파일에서 몇 번이나 나왔는지 알 수 있습니다. 그러므로 sapply()를
호출한 결과값은 단어의 빈도에 대한 벡터가 됩니다. 여기서도 sort()를 사용할 수 있지만, order()가 좀더
직관적입니다.

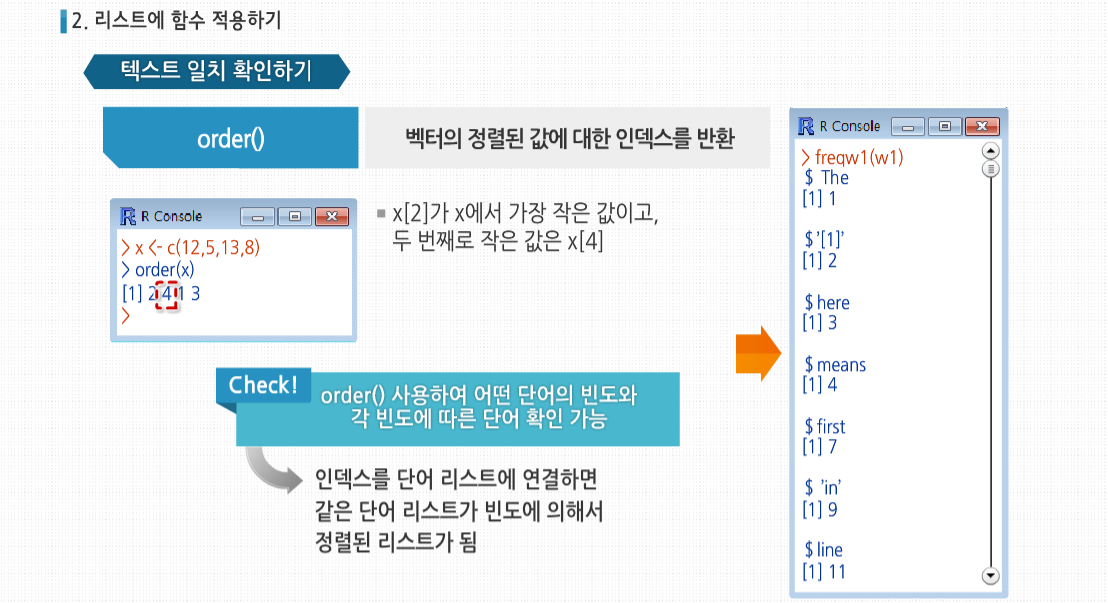
order()는 원래 벡터의 정렬된 값에 대한 인덱스를 반환합니다. 예제를 보면 여기서 결과값의 뜻은
x[2]가 x에서 가장 작은 값이고, 두 번째로 작은 값은 x[4]라는 의미입니다. 이 경우 order()를 사용해 어떤 단어의 빈도가 가장 낮은지, 두 번째로 낮은 빈도의 단어는 무엇인지 등을 알 수 있습니다. 이런 인덱스를 단어 리스트에 연결하면 같은 단어 리스트가 빈도에 의해서 정렬된 리스트가 됩니다. 결과 값을 확인하면 빈도가 가장 낮은 것부터 시작해 가장 높은 것까지 순서대로 정렬되었습니다.
고급 리스트
1. Abalone 데이터 사용하기
고급 리스트기
전복 성별 데이터에 lapply() 함수를 적용하기 위한 예제를 살펴 봅시다.
수컷, 암컷, 새끼 전복으로 구분된 관측치의 인덱스에 대해 알기 위해 성별에 대한 벡터를 가지고 간단한 테스트 예제를 만들어 봅시다. 목적 달성을 위해서 다음과 같이 실행 할 수 있을 것입니다. lapply()의 첫 번째 인자는 리스트여야 합니다.
여기서는 벡터를 사용하고 있지만, lapply()에서 이 벡터를 강제로 리스트 형태로 변환할 것입니다. 또한 lapply()의 두 번째 인자에는 함수가 들어가야 합니다. 여기에는 함수의 이름이나 이 예제에서처럼 실제 코드가 들어갈 수 있습니다. 이것을 익명(Anonymous) 함수라고 합니다. 이후 lapply()는 이 익명 함수를 “M”에, 그 다음 “F”, “I” 순으로 적용합니다.

첫 번째 경우에 함수는 which(g==”M”)를 실행해 g에서 수컷으로 분류된 인덱스의 벡터를 만듭니다. 이어서 암컷과 새끼 전복 인덱스를 만든 후, lapply()에서는 이 세 벡터가 든 리스트를 반환할 것입니다. 여기서 가장 중요한 객체는 g의 성별 벡터지만, lapply()에서 첫 번째 인자로 사용한 것은 이것이 아니란 사실입니다.
대신 가능한 세 개의 성별이 들어간 평범한 벡터가 인수로 들어갔습니다. 대신 g는 두 번째 실인수인 함수 내에서만 잠시 언급됩니다. 이는 R에서 일반적으로 사용되는 형태입니다.

2. 재귀 리스트
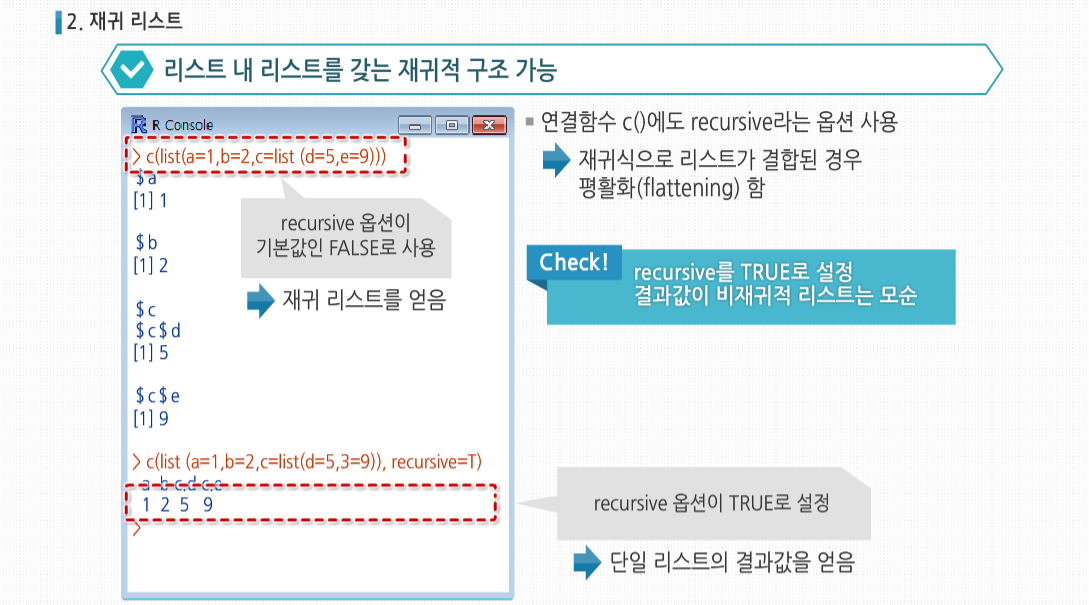
리스트는 리스트 내에 리스트를 갖는 재귀적 구조가 가능합니다. 예제를 살펴보면 두 개의 구성 요소를 가진 리스트를 만드는데, 두 요소 역시 리스트 입니다. 연결함수 c()에도 recursive라는 옵션을 사용할 수 있는데, 이는 재귀식으로 리스트가 결합된 경우
평활화(flattening)를 합니다. 전자의 경우 recursive 옵션이 기본값인 FALSE로 사용돼, 기본 리스트 내의
구성요소인 c가 리스트 형태를 가진 재귀 리스트를 얻었습니다. 후자의 경우에는 recursive 옵션이 TRUE로 설정돼, 구성요소의 이름은 재귀적으로 보이나 실제로는 단일 리스트인 결과값을 얻었습니다.
recursive를 TRUE로 설정했는데 비재귀적(nonrecursive) 리스트를 얻는다는 것은 모순적입니다.
'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 데이터 프레임의 결합과 적용 (0) | 2016.05.13 |
|---|---|
| R 3.2.1 프로그래밍 - 데이터 프레임의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
| R 3.2.1 프로그래밍 - 행렬과 배열 만들기 (0) | 2016.05.07 |
R 3.2.1 프로그래밍 - 리스트의 적용과 재귀 리스트
연결 리스트는 각 노드가 데이터와 포인터를
가지고 한 줄로 연결되어 있는 방식으로 데이터를 저장하는 자료 구조를 말합니다.
연결 리스트는 이름에서 말하듯이 데이터를 담고 있는 노드들이 서로 연결되어 있는데, 노드의 포인터가 다음이나 이전의 노드와의 연결을 담당하게 됩니다. 연결 리스트는 늘어선 노드의 중간지점에서도 자료의 추가와 삭제가 O(1)의 시간에 가능하다는 장점을 갖습니다. 그러나 배열이나 트리 구조와는 달리 특정 위치의 데이터를 검색해 낼 때는O(n)의 시간이 걸리는 단점도 갖고 있습니다.
연결 리스트의 종류로는 단순 연결 리스트, 이중 연결 리스트, 원형 연결 리스트가 있습니다. 단순 연결 리스트는 각 노드에 자료 공간과 한 개의 포인터 공간이 있고, 각 노드의 포인터는 다음 노드를 가리킵니다.
이중 연결 리스트의 구조는 단순 연결 리스트와 비슷하지만, 포인터 공간이 두 개가 있고 각각의 포인터는 앞의 노드와 뒤의 노드를 가리킵니다.
원형 연결 리스트는 일반적인 연결 리스트에 마지막 노드와 처음 노드를 연결시켜 원형으로 만든 구조를 말합니다.
리스트의 응용
1. 리스트 구성 요소와 값에 접근하기
리스트의 응용
리스트 j의 name, salary, union처럼 리스트의 각 구성요소에 이름이 붙어 있다면, names()를 사용해 이를
확인할 수 있습니다. 또한 이에 대한 각각의 값을 얻고 싶다면, unlist()를 사용하면 됩니다. unlist()의 결과값은
문자열로 이뤄진 벡터입니다. 벡터 원소들의 이름은 원 리스트의 구성요소 이름에서 온 것임을 기억해 둡시다.
그러나 만약 값이 숫자로 시작한다면 숫자형 벡터를 얻게 됩니다. 따라서 이 경우 unlist()의 결과값은
숫자형 벡터입니다. 그럼 혼합된 경우는 어떠할까요? 이런 경우 R은 최대로 포함할 수 있는 형태를 고릅니다.
이 경우에는 문자열입니다. 이를 보면 각 형태에도 우선순위가 있다고 생각할 수 있고, 실제로 그렇습니다.
unlist()에 대하여 R에서는 리스트의 구성요소가 해체돼서 일반적 형식이 될 때, 그 결과는 보통 문자형 벡터로
나옵니다. 벡터는 각 구성요소 형식 중 다음 서열에서 최대한 높은 수치를 취합니다.
페어리스트의 경우 리스트로 취급합니다. wu는 리스트가 아닌 벡터지만, R은 각 원소에 이름을 붙여주었습니다. 이는 각 이름을 NULL로 설정해 제거할 수 있습니다. 다음과 같이
unname()을 사용해 각 원소의 이름을 직접 제거할 수도 있습니다. 필요한 경우 wu에 이름을 그대로 남겨 놓는 게좋을 수도 있으나, 필요 없다고 생각된다면 wun을 사용하지 않고, wu에 바로 값을 할당할 수도 있습니다.
2. 리스트에 함수 적용하기
리스트에 함수를 간편하게 적용할 수 있도록 하는 두 함수는 lapply()와 sapply() 입니다. list apply를 위한
lapply()는 행렬에 apply()를 적용하는 것처럼, 특정 함수를 리스트의 각 요소 혹은 리스트화 된 벡터에 적용하고 결과값으로 리스트를 반환합니다. 예제를 보면 R은 1:3과 25:29에 median()을 적용해 결과값으로 2와 27로 이뤄진 리스트를 반환했습니다. 이 경우 lapply()의 결과값은 벡터나 행렬로 간단하게 나타낼 수 있는데, 이런 역할을 하는 함수가 simplified [1]apply를 단순화한 sapply() 함수 입니다.
벡터화된 벡터 함수를 벡터에 적용하는 경우, 함수를 직접 적용하는 대신 sapply()를 사용하면 결과값을 원하는 행렬 형태로 만들 수 있습니다.
텍스트 일치 결과 생성 함수인 findwords()는 단어 별로 인덱싱 된 단어 위치의 리스트를 반환합니다.
이는 여러 면에서 리스트를 정렬하는 데 편리합니다. 입력 파일로 testconcorda.txt를 넣었을 때 결과입니다.
그리고 알파벳 순서대로 단어를 정렬해 보여주는 코드를 살펴보겠습니다. 단어가 각 리스트 요소의 이름이므로 names()를 호출해 단어들을 간단히 추출할 수 있습니다. 이를 알파벳 순서대로 정렬하고, 코드의 5번째 줄에서 리스트 인덱스로 이 버전을 사용합니다. 리스트에서 부분 리스트를 뽑아내기 위해 대괄호를 겹쳐 사용하지 않고 하나만 사용한다는 것을 기억합시다. 이때 sort() 대신 order를 사용할 수도 있습니다.
실행결과를 살펴볼까요? 제대로 잘 동작하고 있습니다. and가 가장 처음에 나오고 이어서 be가 나오는 형태입니다. 단어의 빈도 순서대로 정렬하는 것도 비슷한 방식으로 구현할 수 있습니다. 코드의 3번째 줄에서 wrdlst의 각 원소는 입력한 파일에서 주어진 단어의 위치를 표현하는 숫자로 된 벡터라는 사실을 활용합니다.
length()를 이 벡터에 호출하면, 각 단어가 파일에서 몇 번이나 나왔는지 알 수 있습니다. 그러므로 sapply()를
호출한 결과값은 단어의 빈도에 대한 벡터가 됩니다. 여기서도 sort()를 사용할 수 있지만, order()가 좀더
직관적입니다.
order()는 원래 벡터의 정렬된 값에 대한 인덱스를 반환합니다. 예제를 보면 여기서 결과값의 뜻은
x[2]가 x에서 가장 작은 값이고, 두 번째로 작은 값은 x[4]라는 의미입니다. 이 경우 order()를 사용해 어떤 단어의 빈도가 가장 낮은지, 두 번째로 낮은 빈도의 단어는 무엇인지 등을 알 수 있습니다. 이런 인덱스를 단어 리스트에 연결하면 같은 단어 리스트가 빈도에 의해서 정렬된 리스트가 됩니다. 결과 값을 확인하면 빈도가 가장 낮은 것부터 시작해 가장 높은 것까지 순서대로 정렬되었습니다.
고급 리스트
1. Abalone 데이터 사용하기
고급 리스트기
전복 성별 데이터에 lapply() 함수를 적용하기 위한 예제를 살펴 봅시다.
수컷, 암컷, 새끼 전복으로 구분된 관측치의 인덱스에 대해 알기 위해 성별에 대한 벡터를 가지고 간단한 테스트 예제를 만들어 봅시다. 목적 달성을 위해서 다음과 같이 실행 할 수 있을 것입니다. lapply()의 첫 번째 인자는 리스트여야 합니다.
여기서는 벡터를 사용하고 있지만, lapply()에서 이 벡터를 강제로 리스트 형태로 변환할 것입니다. 또한 lapply()의 두 번째 인자에는 함수가 들어가야 합니다. 여기에는 함수의 이름이나 이 예제에서처럼 실제 코드가 들어갈 수 있습니다. 이것을 익명(Anonymous) 함수라고 합니다. 이후 lapply()는 이 익명 함수를 “M”에, 그 다음 “F”, “I” 순으로 적용합니다.
첫 번째 경우에 함수는 which(g==”M”)를 실행해 g에서 수컷으로 분류된 인덱스의 벡터를 만듭니다. 이어서 암컷과 새끼 전복 인덱스를 만든 후, lapply()에서는 이 세 벡터가 든 리스트를 반환할 것입니다. 여기서 가장 중요한 객체는 g의 성별 벡터지만, lapply()에서 첫 번째 인자로 사용한 것은 이것이 아니란 사실입니다.
대신 가능한 세 개의 성별이 들어간 평범한 벡터가 인수로 들어갔습니다. 대신 g는 두 번째 실인수인 함수 내에서만 잠시 언급됩니다. 이는 R에서 일반적으로 사용되는 형태입니다.
2. 재귀 리스트
리스트는 리스트 내에 리스트를 갖는 재귀적 구조가 가능합니다. 예제를 살펴보면 두 개의 구성 요소를 가진 리스트를 만드는데, 두 요소 역시 리스트 입니다. 연결함수 c()에도 recursive라는 옵션을 사용할 수 있는데, 이는 재귀식으로 리스트가 결합된 경우
평활화(flattening)를 합니다. 전자의 경우 recursive 옵션이 기본값인 FALSE로 사용돼, 기본 리스트 내의
구성요소인 c가 리스트 형태를 가진 재귀 리스트를 얻었습니다. 후자의 경우에는 recursive 옵션이 TRUE로 설정돼, 구성요소의 이름은 재귀적으로 보이나 실제로는 단일 리스트인 결과값을 얻었습니다.
recursive를 TRUE로 설정했는데 비재귀적(nonrecursive) 리스트를 얻는다는 것은 모순적입니다.
'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 데이터 프레임의 결합과 적용 (0) | 2016.05.13 |
|---|---|
| R 3.2.1 프로그래밍 - 데이터 프레임의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
| R 3.2.1 프로그래밍 - 행렬과 배열 만들기 (0) | 2016.05.07 |