OpenCL [1] concept

Heterogeneous Platform을 위한 application 개발
- 디바이스(device) 별로 다른 프로그래밍 방법이 존재합니다. (CPU, GPU, FPGA, …)
- 개발 및 유지 보수의 어려움이 있습니다.
OpenCL
Open Computing Language
Heterogeneous Platform을 위한 표준 병렬 프로그래밍 모델입니다.
- 다양한 아키텍처의 디바이스를 위해 프로그래밍이 가능합니다.
- 추상화된 플랫폼 모델을 제공합니다.
Open source로 사용이 되며, 다양한 회사들과 연구 기관에서 표준 개발에 참여하고 있습니다.
- data/task parallel programming 모델 지원 (실제로는 데이터 병렬 프로그래밍 모델을 많이 사용)
- ANSI/ISO C99 기반의 언어와 C++ 지원이 추가
- 코드 이식성(source-code portability) : 다양한 장치에서 실행 가능
- 이식성 있고 효율적인 코드를 작성하기 원하는 프로그래머가 대상
- 많은 벤더(vendor)가 지원 : Altera, AMD, IBM, Intel, NVIDIA, Samsung 등
OpenCL Limit
성능 이식성(performance portability)의 부재
- target 장치에 따라 프로그래머의 최적화가 필요합니다.
- 프로그래밍의 복잡성 - 많은 요소를 직접 통제해야 하며, 최적화를 위해 많은 시간이 소요됩니다.
- 단일 OS 내의 디바이스들만 프로그래밍 가능합니다.
OpenCL VS CUDA
CUDA(Compute Unified Device Architecture)
- https://developer.nivida.com/cuda-zone
- NVIDIA에서 만든 GPU 병렬 프로그래밍 모델
OpenCL과 1:1로 대응되는 점이 많습니다.
하나만 배우면 쉽게 익힐 수 있습니다.
OpenCL standard
- OpenCL 아키텍처(architecture) : 플랫폼(platform) 모델, 실행 모델, 메모리 모델
- OpenCL API 함수
- OpenCL C 언어 명세
OpenCL Framework
OpenCL application을 개발하고 실행하기 위한 소프트웨어 시스템
Platform Layer + Runtime + Compiler
- Platform Layer : host와 1 이상의 device로 이루어진 (가상의) 플랫폼 제공
- Runtime : Host program에서 OpenCL API 함수를 사용할 수 있도록합니다. 각종 객체를 생성, 관리하고, command queue에 들어온 command를 처리합니다.
- OpenCL C Compiler : OpenCL 프로그램 소스 코드로부터 device에서 실행될 바이너리(binary)를 생성합니다. host 프로그램에서 프로그램 객체를 만들고 빌드(build)할 때 불리어 집니다(API 함수 사용)
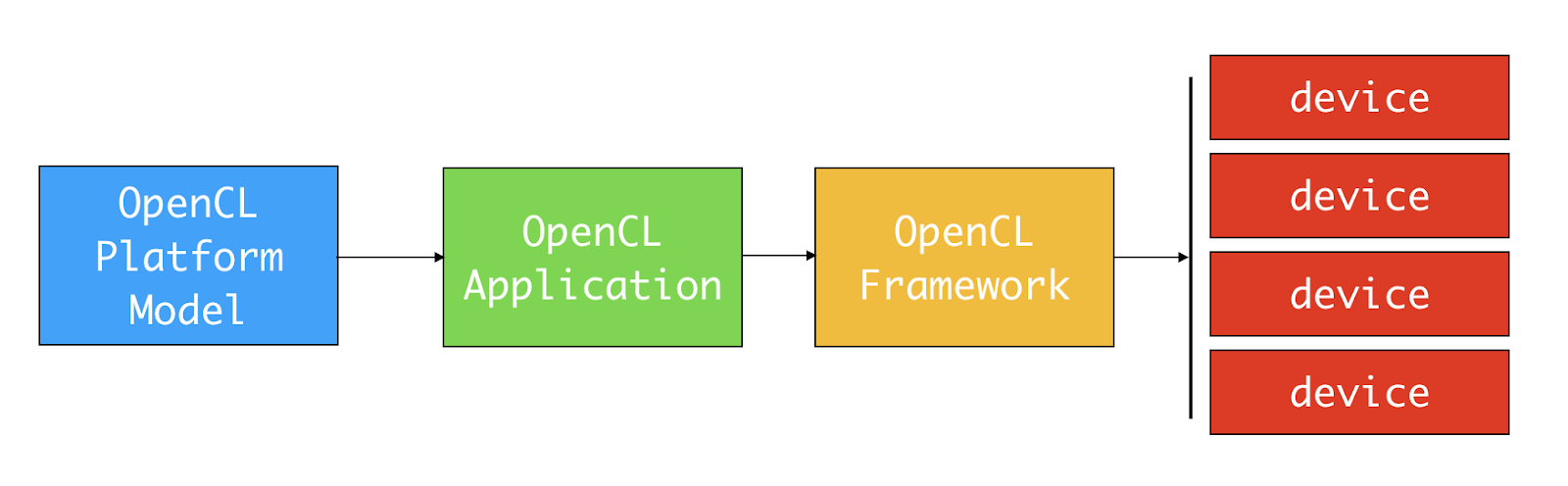
Platform
OpenCL Framework 마다 하나 이상의 플랫폼(platform) 제공합니다.
- 시스템에 여러 벤더(vendor)의 OpenCL 프레임워크가 설치되어 있으면 platform도 여러 개입니다.
- 플랫폼(platform) = 호스트(host) + 하나 이상의 디바이스(device)
* host : CPU에 해당
* device : Multi-core CPU, GPU, FPGA, …

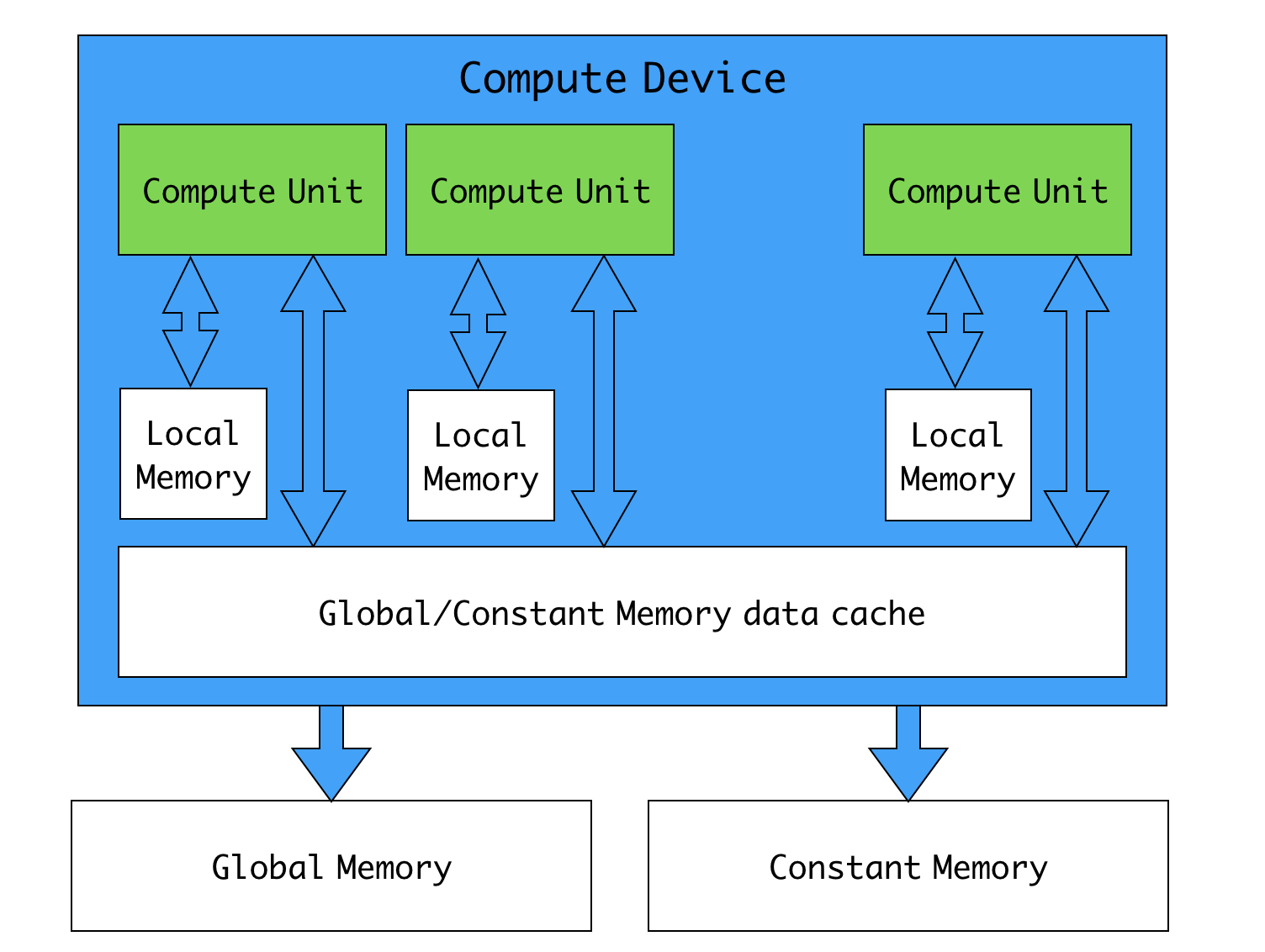
Device
global 메모리(memory)와 constant 메모리 있습니다.
디바이스(device)마다 하나씩 있어서, 해당 device 안에서 접근 가능합니다.
device는 constant memory를 읽을 수 만 있습니다.
device에서는 호스트(host) 메인 메모리에 바로 접근할 수 없습니다.
반면 host에서는 global와 constant memory에 읽기/쓰기가 가능합니다. 이에 따라 main memory와 global/constant memory 사이의 데이터 복사를 담당합니다.
Device는 하나 이상의 Compute Unit(CU)로 구성됩니다.
CU 마다 로컬 메모리(local memory)가 하나씩 있습니다.
- 해당 CU 안에서만 접근이 가능합니다. global/constant memory는 모든 CU가 공유합니다.
- 호스트에서는 접근할 수 없습니다.
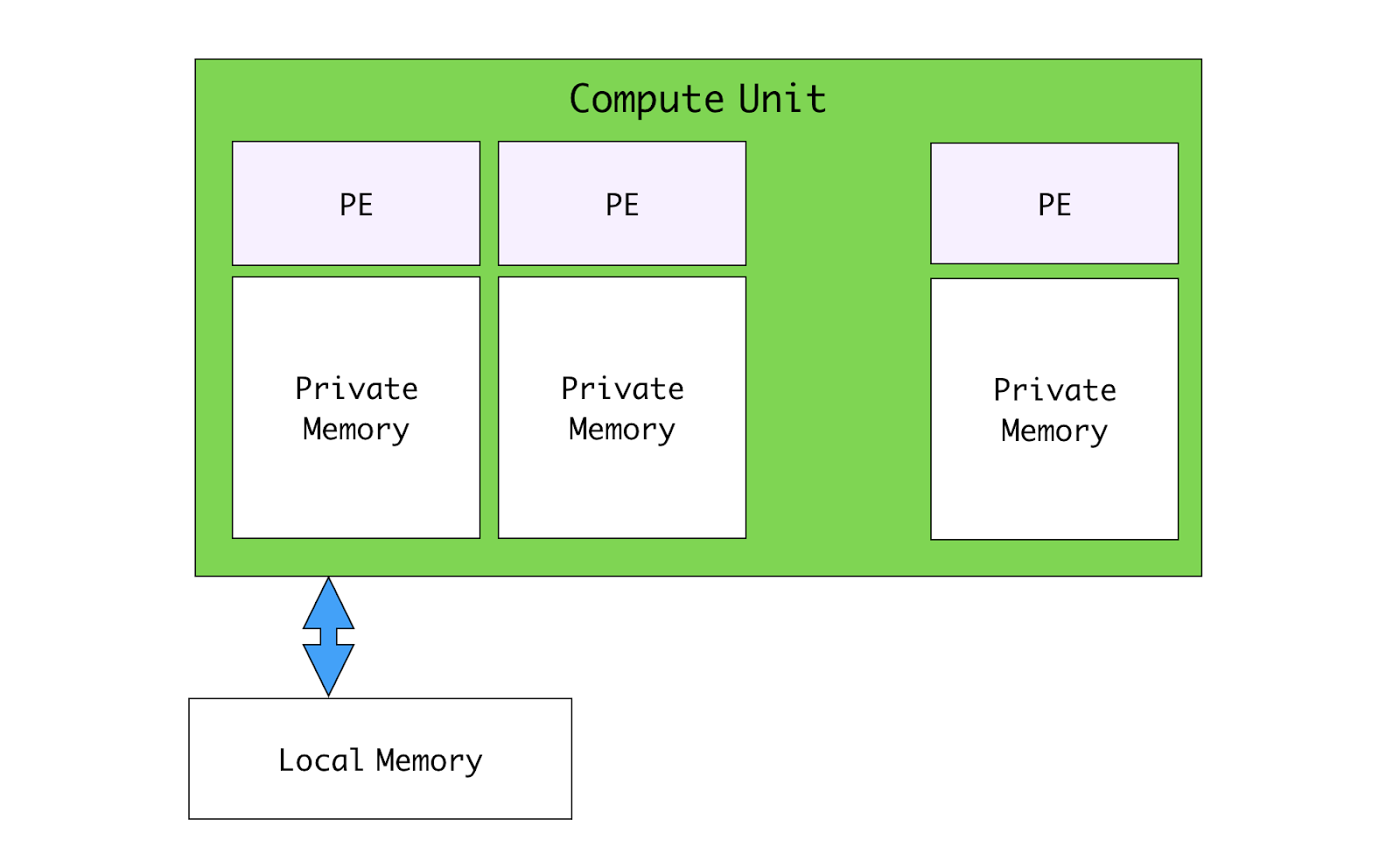
각 CU는 하나 이상의 Processing Element(PE)로 구성됩니다.
PE에서는 실제로 코드를 실행하면서 계산을 수행합니다(SIMD, SPMD 방식)
PE마다 private memory가 하나씩 있습니다.
해당 PE에서만 접근이 가능합니다. local memory는 한 CU 안의 모든 PE가 공유합니다.
OpenCL Application
Host program + OpenCL program
- Host program은 호스트 프로세서에 실행됩니다.
- OpenCL program은 여러 커널(kernel)로 이루어져 있으며 device에서 실행됩니다.

Host program
- 일반적인 프로그래밍 언어(C, C++, Fortran, Java, Python, …)로 작성됩니다.
- OpenCL API 함수를 사용해 device를 관리합니다.
- kernel 단위, 계산(kernel 실행), 데이터 전송, 동기화(synchronization)
Kernel
- OpenCL C 언어로 작성
- device에서 실행되는 코드의 기본 단위
- 많은 instance가 동시에 device에서 실행됩니다. 이에 따라 data parallelism 이용
Host program과 Kernel은 병렬로 실행됩니다. 여러 device를 동시에 사용하는 것도 가능합니다.

OpenCL C
Kernel 작성을 위한 프로그래밍 언어
제약 조건으로는 기존의 표준 헤더 파일(stdio.h, stdlib.h) 지원이 안됩니다. 함수 포인터, 재귀 함수 지원 안됩니다.
확장으로는 다음과 같습니다.
- 벡터(vector) 타입 : char2, int4, float8, double16
- 이미지(image) 타입 : image2d_t
- 주소 공간 한정자(qualifier) : __global, __constant, __local, __private
- 동기화(synchronization)
- 빌트인 함수 : sin(), cos(), printf(), atomic_add(), get_global_id()
Kernel Execution
Host program에서 kernel을 실행할 때 N-차원(dimension) 인덱스(index) 공간 지정합니다.
N = 1,2,3 중 하나이며, 이는 1차원 벡터 또는 흑백 이미지, 색상이 들어간 이미지 처럼 각 dimension에 맞게 지정하도록 선택할 수 있습니다.

work-item
index 공간의 각 제일 작은 사각형마다 kernel instance가 하나씩 실행됩니다.
커널 함수 안에서 OpenCL C의 빌트인 함수(get_global_id 등)을 사용해 index 공간에서의 work-item id를 얻어 올 수 있습니다.
work-group
여러 work-item 들이 work-group 단위로 묶여 있습니다.
모든 work-group의 크기는 동일해야 하기 때문에 같은 사이즈(전체 크기의 약수)로 쪼개야 합니다.
하나의 work-group은 하나의 CU에서 실행됩니다. 같은 CU에 있는 PE는 local memory를 공유합니다.
work-group 안의 여러 work-item들이 CU 안의 여러 PE에서 나누어 실행됩니다.
work-group 크기가 성능에 큰 영향을 미칩니다.


OpenCL kernel 함수
__kernel |
Data Parallel programming model
work-item이 하나의 데이터를 처리합니다.
- kernel 코드는 데이터에 적용되는 명령어의 순서를 정의합니다.
- index 공간은 work-item과 데이터의 맵핑을 결정합니다.
- 각 work-item은 어떤 데이터를 이용해 계산을 수행하는지 확인합니다.
Kernel code Execution object
Context
- kernel이 실행되는 환경
- 다른 객체(object)들을 관리하기 위한 최상위 객체
- context 단위로 명령어 간 동기화 및 메모리 관리를 수행
- 자원 할당(초기화) 및 해제
Command-queue
- device에 커맨드(커널 실행, 데이터 전송, 동기화)를 보내기 위해 필요
- Host program이 command-queue에 command를 넣으면, OpenCL 프레임워크의 런타임 시스템에서 빼내어 실행
- device가 4개면 command-queue도 4개가 있어야 합니다.

Program Object
OpenCL 프로그램의 바이너리(binary)
- IR(Intermediate Representation)일 수도 있고, 실제 실행 가능한 코드일 수 도 있습니다.
바이너리를 미리 만들어 두는 것이 아니라, 실행 중에 컴파일을 하는 경우가 많습니다. 아직까지 device 간 binary 호환성이 지원되지 않기 때문입니다. SPIR 표준으로 시도 중이나 디바이스에 호환이 아직 많이 되고 있지 않습니다.
Memory Object
device의 global/constant memory에 공간을 할당하고 데이터를 저장하기 위해 필요합니다.
host program에서 memory object에 데이터를 읽고 쓸 수 있습니다.
-kernel 함수에서 memory object를 인자로 받을 수 있습니다.
- buffer object: 일반적인 배열(array)과 동일
- image object: 1~3 차원의 데이터를 처리하기 위한 특수 object, 텍스처(texture), 프레임 버퍼(frame buffer), 이미지
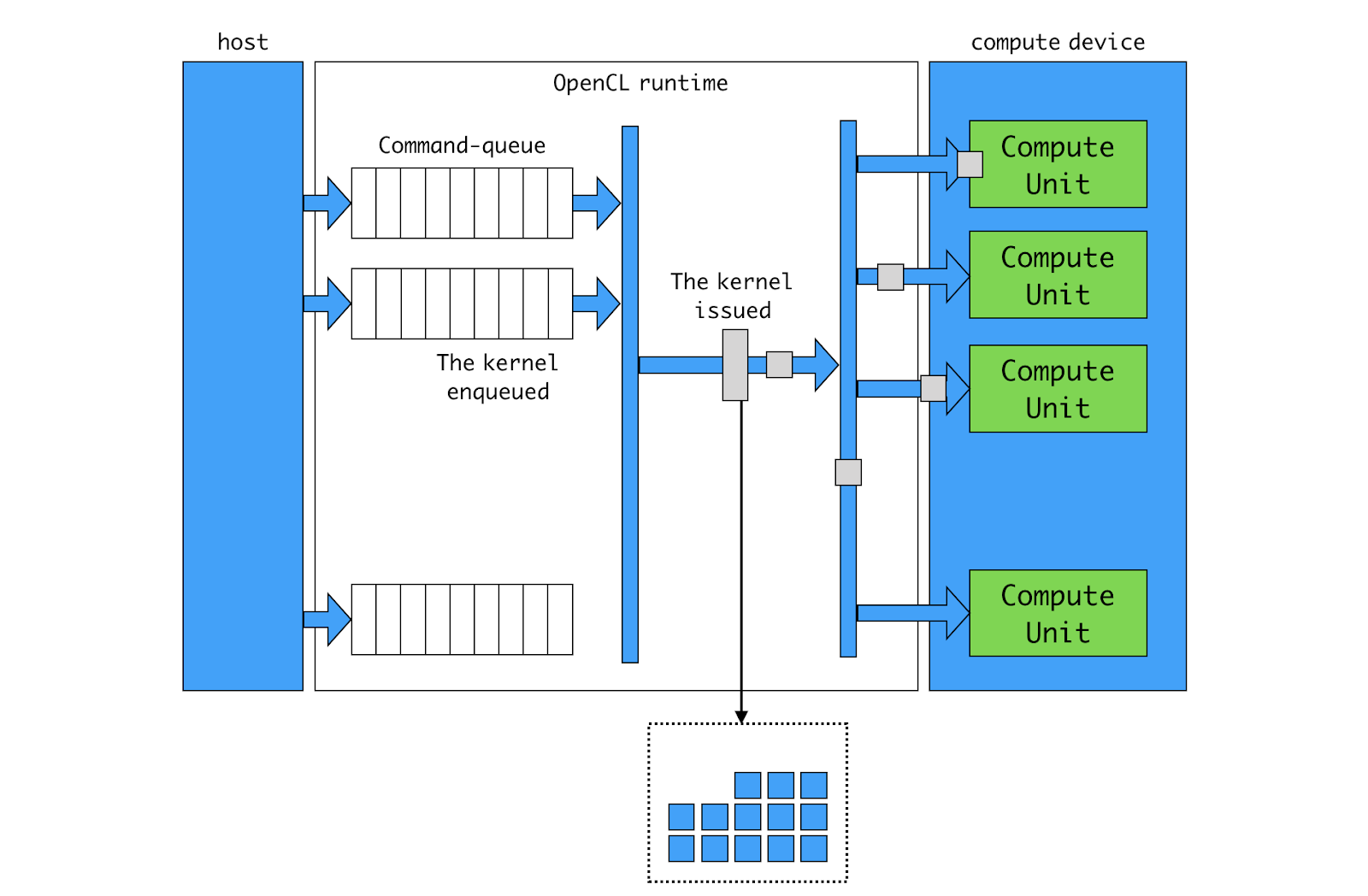
OpenCL Runtime
Host 프로그램이 command-queue에 kernel execution 명령을 넣습니다. kernel 인덱스 공간을 지정합니다.

OpenCL 런타임이 queue에 든 kernel 커맨드를 꺼내어 target device에 이슈(issue) 됩니다.
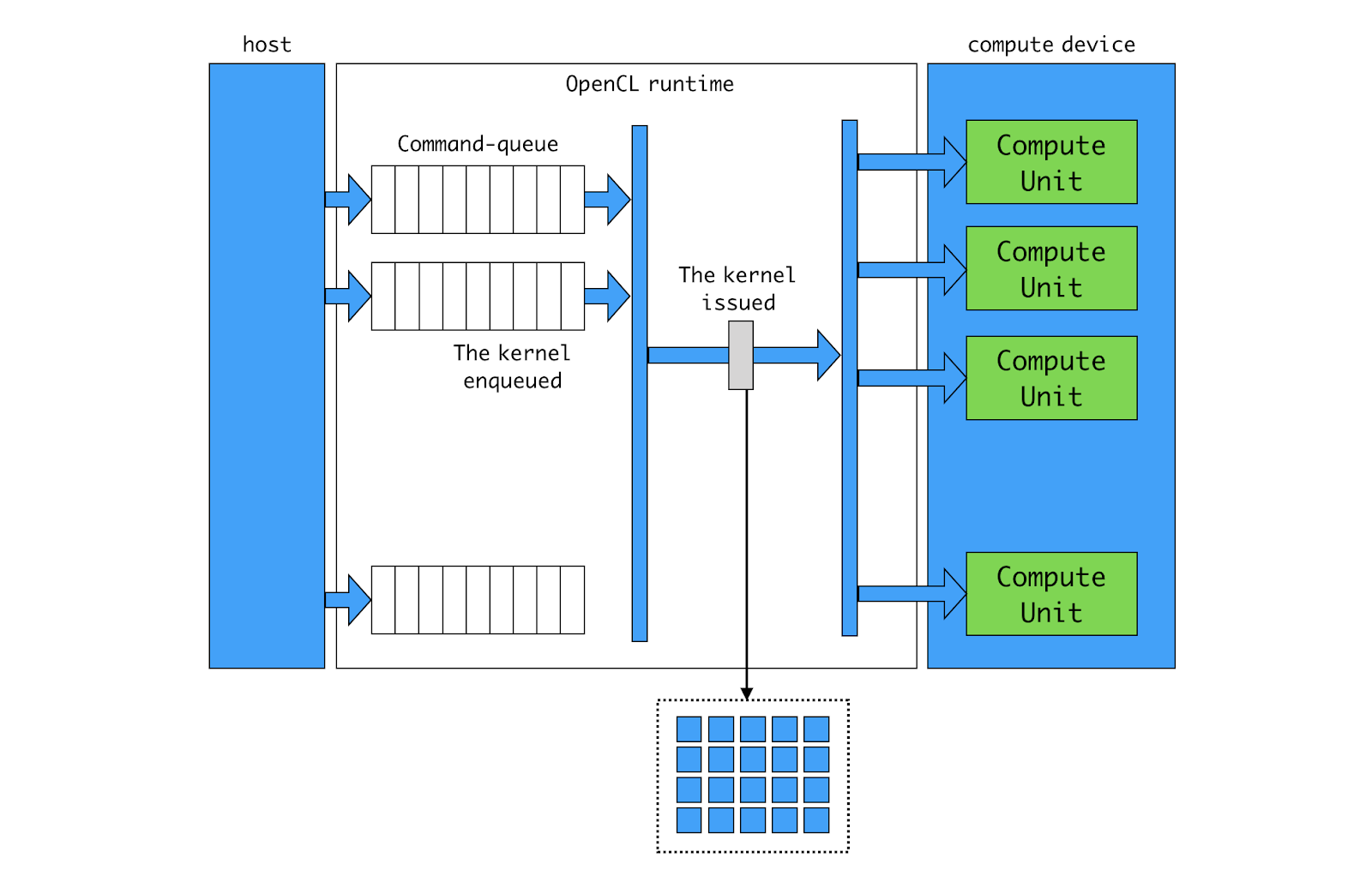
Runtime이 work-group들을 target device 내의 CU(Compute Unit)로 분배합니다.
OpenCL Framework
AMD OpenCL : http://www.amd.com/en-us/solutions/professional/hpc/opencl

Intel OpenCL : https://software.intel.com/en-us/intel-opencl

NVIDIA OpenCL : https://developer.nvidia.com/opencl

'OpenCL' 카테고리의 다른 글
| OpenCL [0] introduction (0) | 2018.08.27 |
|---|---|
| OpenCL[3] Memory Object, Kernel Execution (0) | 2018.08.23 |
| OpenCL[2] platform, device, context, command-queue, program (0) | 2018.08.21 |