OpenCL[0] introduction 기존의 슈퍼 컴퓨터의 성능이 기존 데스크탑 컴퓨터의 성능으로 요구되면서 HW/SW 기술이 전달되고 있습니다. 2020년 경에 Exa-scale(1018 flops)의 슈퍼 컴퓨터가 나올 것으로 예상되고 있습니다. 이에 따라 새로운 프로세서 및 소프트웨어 기술의 개발을 필요로 하고 있습니다. Intel의 CEO인 Moore가 만들어낸 법칙으로 Die 당 직접된 트랜지스터의 개수는 거의 2년에 2배씩 증가. * 반도체 Die 란 : 집적 회로에서 다이(Die)는 반도체 물질의 자그마한 사각형 조각을 말하며, 여기에 회로가 제작되어 있습니다. 일반적으로 하나의 웨이퍼에 여러 개의 집적 회로가 생산됩니다. 웨이퍼는 절단을 통해 여러 개의 조각으로 나뉘는데 각 조각에는 한 개의 집적 회로가 담겨있습니다. 이러한 각 조각들을 다이라고 부릅니다. 2014년부터 1달러에 살 수 있는 트랜지스터(transregister)의 개수가 줄어들었고, 공장에서 직접으로 생산하는 cost가 늘어나서 Moore 법칙과 물리적 한계로 포기하였습니다. 트랜지스터가 많으면 성능이 증가한다는 것입니다. 1 cycle의 명령어를 처리하는 frequency가 높아지면 열이 발생합니다. 즉, CPU의 전력소모는 코어의 clock frequency에 비례합니다. CPU의 열 발산은 전력 소모에 비례합니다. 성능은 높아질 수록 트랜지스터가 많이 필요하게 되며, 무한정 CPU의 clock frequency를 증가할 수 없기 때문에 한계가 생깁니다. Mobile device의 경우 battery life가 문제가 생깁니다. 이에 따라 power wall의 해결책으로 멀티코어(multi-core)가 제시됩니다. core clock을 높이는 방법도 있지만, 프로세서(processor)의 성능을 높이는 방법으로 동시에 실행하는 명령(instruction)을 병렬로 실행합니다. Instruction Level Parallelism 한계 명령어를 실행하고 받은 결과를 다음의 명령어가 실행되는 의존 관계(dependencies)가 있는 경우 동시에 실행되지 못하는 한계가 존재합니다. 2개 이상의 독립적인 프로세서(processor)를 담고 있는 칩을 multi-core라고 합니다 core의 개수가 8~16개 이상이면 manycore라고 합니다. power-wall과 ILP 한계의 해결책이 될 수 있습니다. Die 당 직접된 코어(core)개수는 거의 2년에 2배씩 증가하고 있습니다. 60개 이상의 core가 한 개의 칩에 들어가 있습니다. 3D-stacking Optical communication Carbon nanotube transistors Neuromorphic computing -> 인간의 Neuron을 모방해서 컴퓨팅으로 연구, 딥러닝과 다릅니다. Quantum computing -> Microsoft, Google, 디바이스로 연구 중입니다. Neuromorphic computing Accelerators - FPGAs -> OpenCL - GPUs -> CUDA(nvidia), OpenCL(Open source) 여러 개의 같은 종류의 코어가 하나의 칩 안에 존재합니다. - Intel Xeon, AMD Opteron, ARM Cortex MPCore, IBM Power7 등 - AMD(dual core를 먼저 만듬, 주가가 많이 오름) 두 가지 이상의 서로 다른 종류의 프로세서(processor)를 가진 컴퓨터 시스템입니다. - CPU, GPU, FPGA, DSP 등 - 고성능 달성이 쉽고, 전력 효율이 좋습니다. - 범용 프로세서(자원 관리) + 가속기(계산 전용) * 가속기(accelerator) : 특정한 작업을 범용 CPU보다 더 빨리 처리할 수 있는 프로세서 수 천개의 간단한 코어(scalar processor) SP(4칙 연산을 프로세서)가 16~32개 들어 있는 Unit이 많이 들어가 있습니다. GPU의 구조 : 수 천 개의 간단한 코어(scala processor) p: 병렬화 될 수 있는 부분의 순차 실행 시간 1-p : 병렬화 될 수 없는 부분의 순차 실행 시간 n : 프로세서의 개수 p = 0.88 n = 4 1- p = 0.12 speed up = 1 / 0.12 + 0.22 = 1 / 0. 34 = 2.94 가속기 코어 하나가 두 개의 범용 코어가 가격이 같다고 가정한다. 한 개의 가속기 코어는 한 개의 범용 코어보다 두 배 빠르다고 가정합니다. p = 0.88 1 - p = 0.12 speed up = 1 / 0.12 + ((0.72 / 4) / 2) + (0.16 / 2) application 마다 Multi-core, GPU, FPGAs를 사용하느냐에 따라 성능이 달라집니다. 전력 소모 문제 해결을 위해 가속기와 범용 CPU를 혼용하는 heterogeneous 시스템이 늘어나는 추세입니다. Microsoft Research - MS의 Data center에서 검색 엔진을 가속시키기 위해 FPGA를 이용 - FPGA를 Deep Learning에 재사용(GPU보다 3X 좋은 전력 효율) 코어(core)가 늘어남에 따라 HW가 차지하는 성능보다는 SW로 올리는 성능이 중요합니다. 병렬화 오버헤드(overhead)가 중요합니다. application을 개발할 때 병렬 컴퓨터 간의 인터페이스(interface) 고성능과 쉬운 프로그래밍을 동시에 달성하는 것이 중요하지만 어렵습니다. Shared Memory Parallel programming model - OpenMP - Pthread Message passing parallel programming model - MPI Accelerator programming model - OpenCL - CUDA - OpenMP 4개의 기본 하드웨어 구성요소 - 입력 장치 - 출력 장치 - 주기억 장치(Main Memory) : 프로그램과 데이터를 모두 저장 - 중앙 처리 장치(Central Processing, Unit) : 제어장치 + ALU 컴퓨터가 실제로 읽고, 해석하고, 실행하는 프로그램 ALU는 산술 연산과 논리 연산 처리 제어장치는 주기억장치에서 instruction을 순서대로 가져와(fetch) 해석(decode)하고 실행(execute)합니다. 다음에 가져올 instruction의 주소(address)는 CPU 내 레지스터(register) 프로그램 카운터(program counter)에 저장 fetch-decode- execute cycle, 컴퓨터가 꺼질 때까지 반복합니다. Hardware 테크닉으로 instruction을 처리하는 throughput을 증가시키는 방법 - CPU clock cycle 당 실행되는 instruction의 개수 3개의 스테이지(stage)를 가진 pipeline, 각 stage는 독립적으로 동작 가능 - IF : Instruction Fetch - ID : Instruction Decode, Register Fetch - EX : EXecute 각 명령어(instruction)이 실행이 끝내려면 3 cycle이 걸린다고 가정을 해봅시다. 또 각 pipeline의 stage는 1 cycle이 걸린다고 가정합니다. Instruction의 수가 많으면 한 cycle에 한 명령어(instruction)을 실행하는 효과가 발생됩니다. 보통 여러가지 functional unit이 CPU 내에 존재합니다. - 정수, 부동소수점 연산, load/store 등 실행 과정은 다음과 같습니다. - instruction fetch and decode - 피 연산자가 사용 가능하면, instruction에 맞는 functional unit으로 execute 하드웨어에 의한 동적인 명령어의 스케줄링(scheduling) 기법 입니다. 성능을 높이기 위해 채택하는 방식입니다. 실행 과정 - 앞의 과정과 동일 - instruction에 맞게 RS(Reservation Station)에 보냄(issue) - instruction은 피 연산자가 사용 가능할 때 까지 기다림 - 피 연산자가 사용 가능하면 execute - 결과값이 RB(Reorder Buffer)에 들어감 - 명령어가 fetch된 순서대로 연산의 결과값이 register에 쓰여짐 현대의 CPU는 여러 개의 instruction을 동시에 fetch하고 decode하여, RS에 보내어 execute합니다. Instruction level parallelism Task parallelism Data parallelism 다른 종류의 task를 동시에 실행합니다. 응용 프로그램을 여러 개의 병렬 task를 나눕니다. 연관성(dependencies)는 graph로 주로 표현합니다. loop-level parallelism 같은 연산을 다른 데이터에 동시에 적용한다. 데이터가 많을 수록 병렬성도 증가합니다. for(i = 0; i < 32; i ++) Single Instruction Multiple Data low level의 register 적용 한 개의 instruction을 복사한 여러 개의 instruction이 같은 연산을 타입과 크기가 같은 여러 개의 다른 데이터를 동시에 적용합니다. 주로 컴파일러(compiler)가 자동으로 벡터화(vector)하여 적용합니다. Single Program Multiple Data high level의 코드의 프로그램 적용 같은 코드를 다른 데이터 아이템에 동시에 실행합니다.Moore’s Law
Power Wall
Instruction Level Parallelism
Multi core
Nvidia Tegra 3
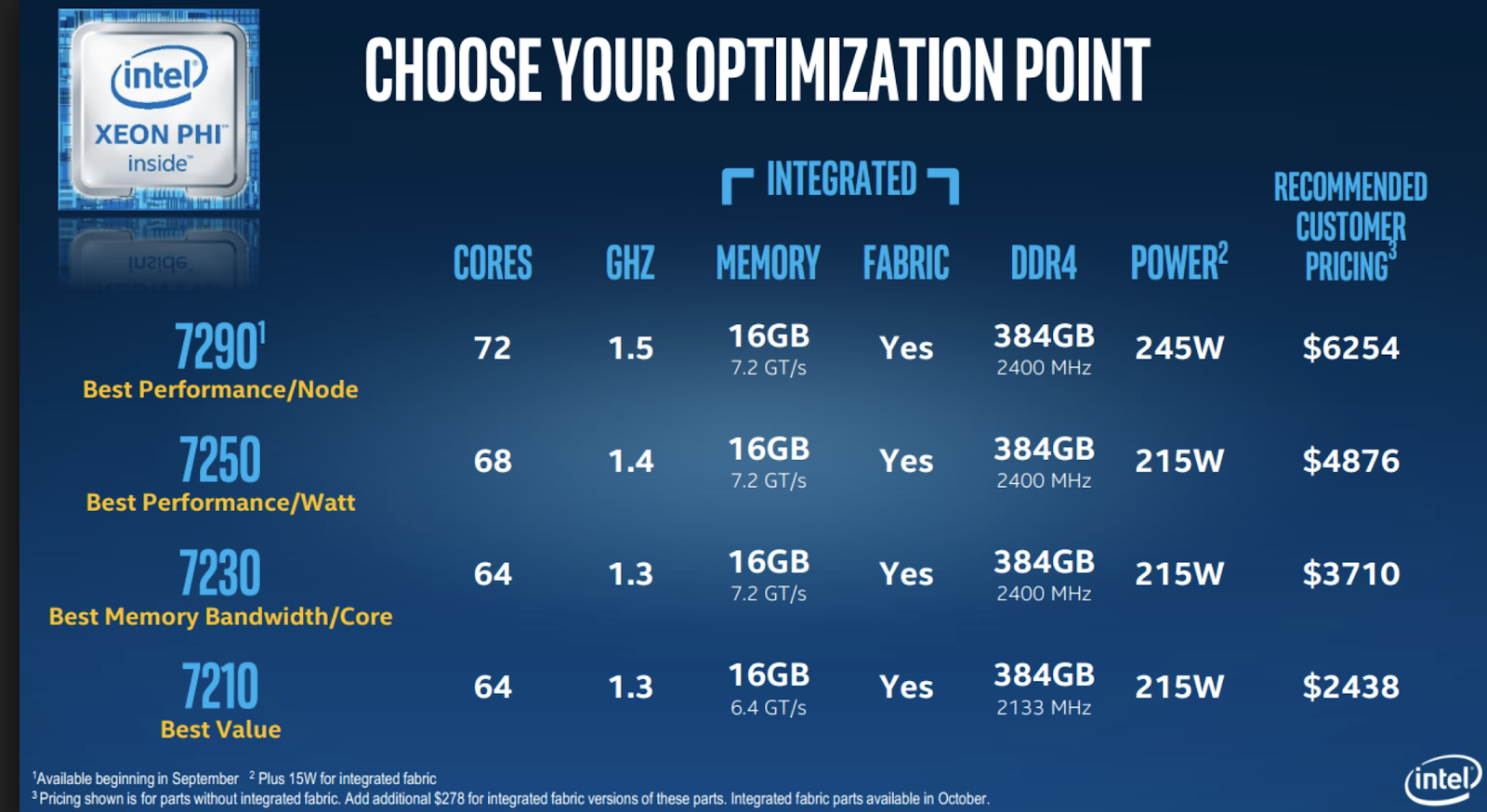
Intel Xeon Phi
Post-Moore’s Era
Homogeneous 멀티코어
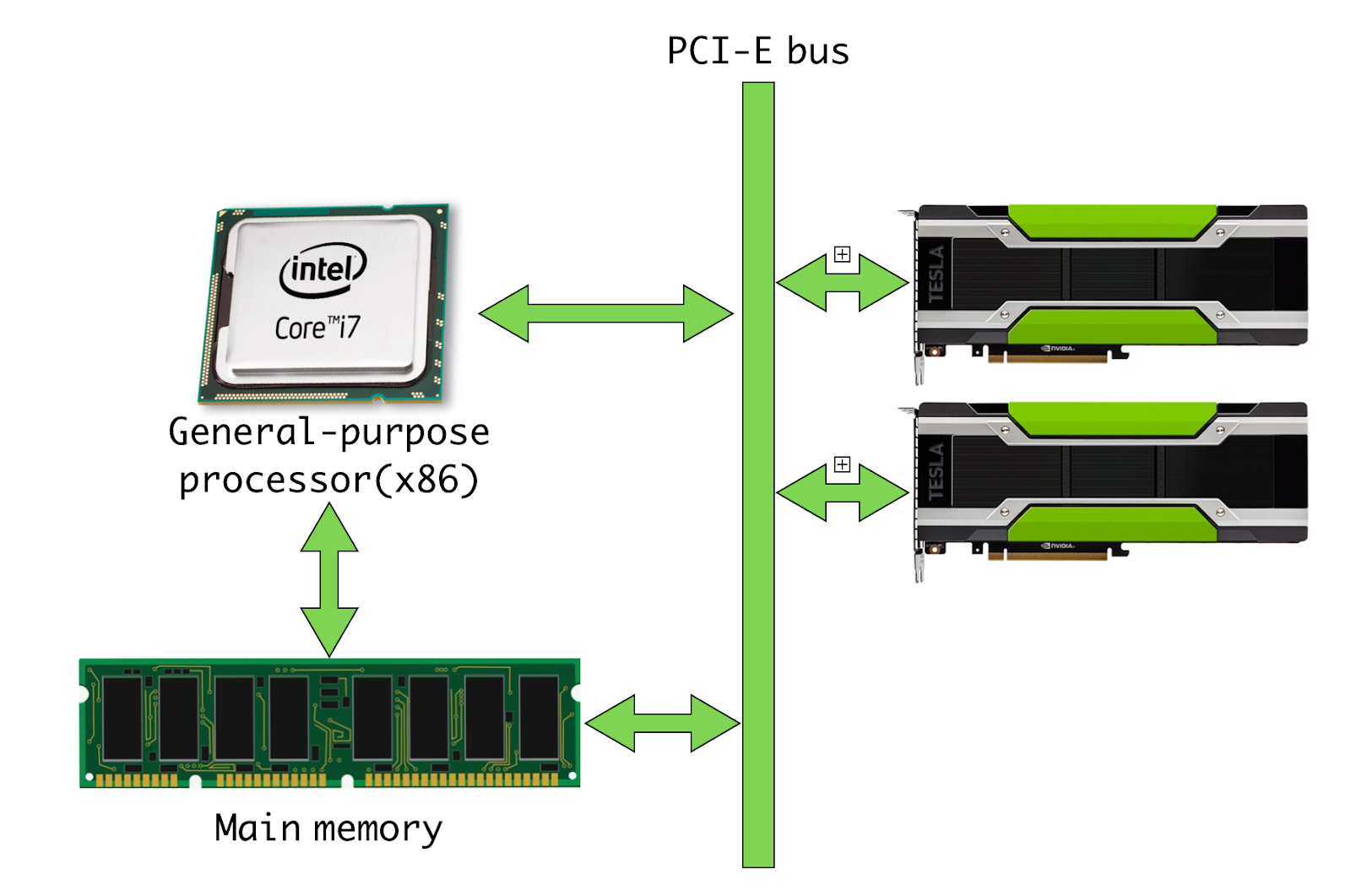
Heterogeneous 컴퓨터 시스템
GPGPU(GPU)
Amdahl’s Law
Top 500, Green 500
Deep Learning을 위한 FPGA
Multicore Programming
Parallels Programming
Parallels Programming Model
폰 노이만(Von Neumann) 아키텍처
Machine Code
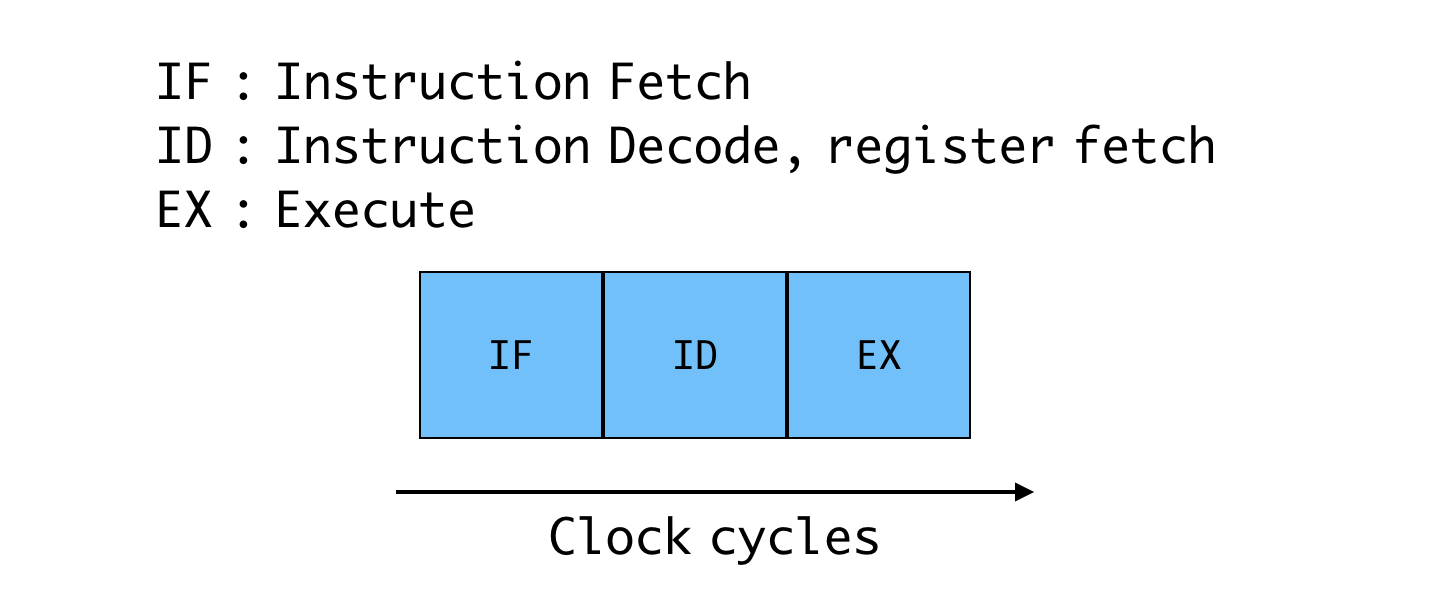
Instruction cycle
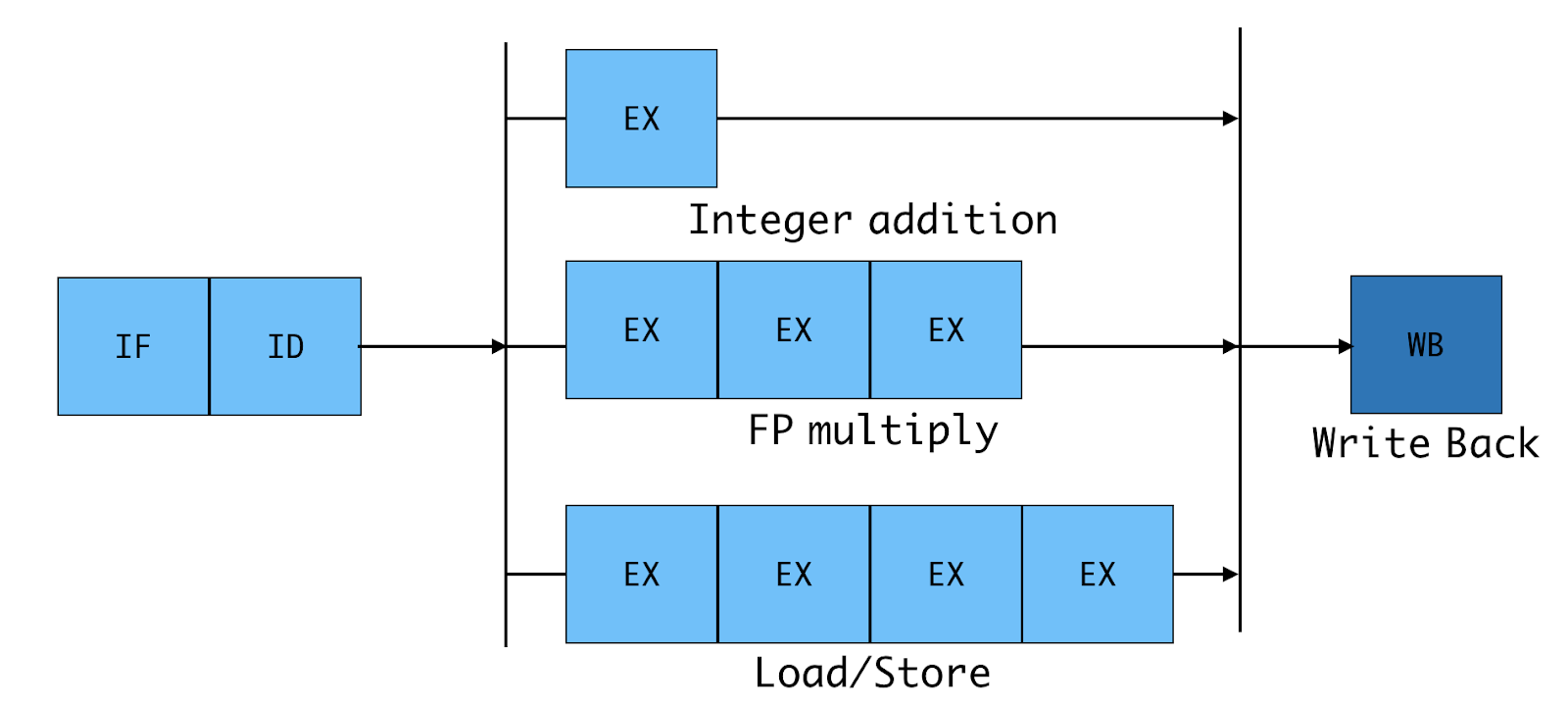
Pipelining
Instruction Pipeline
In-order Execution
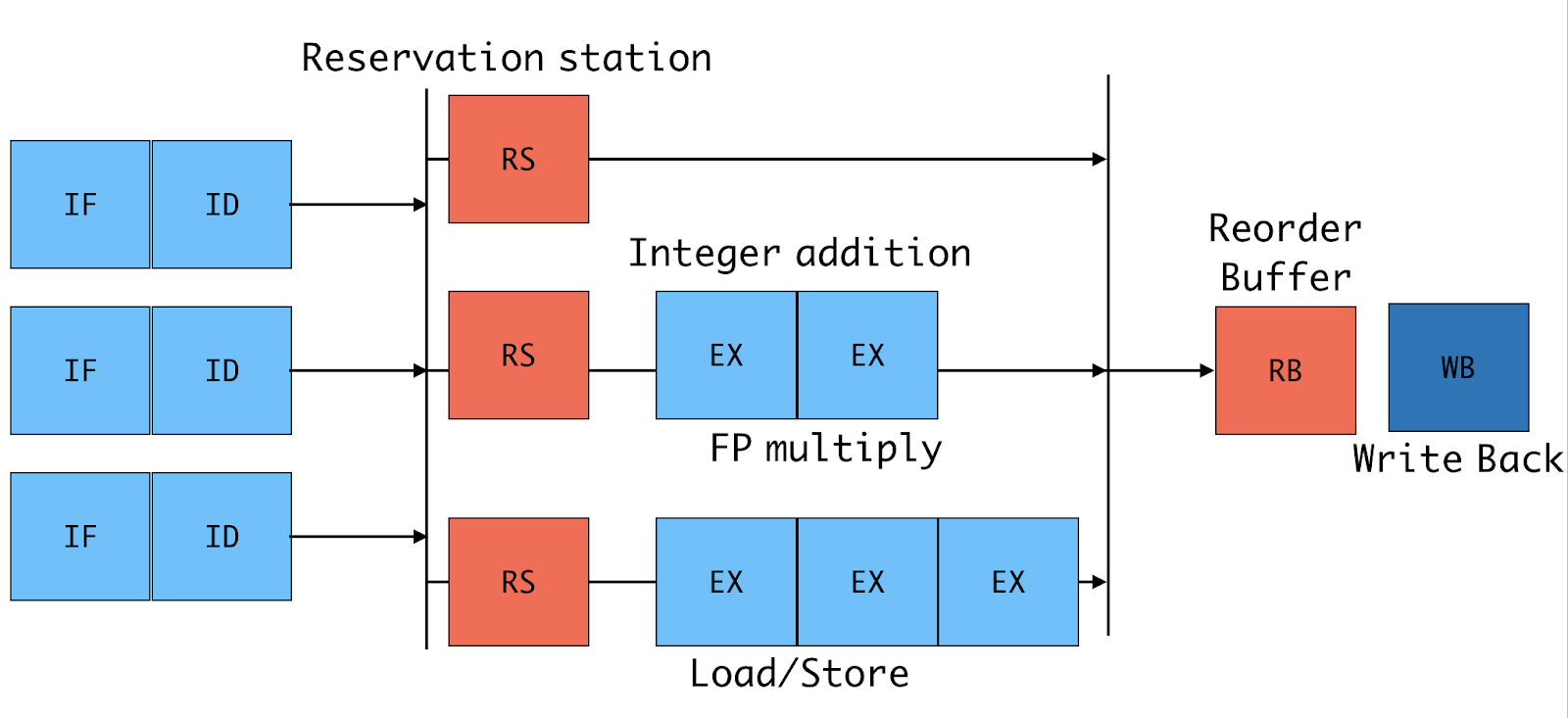
Out-of-Order Execution(OoO)
Superscalar CPU
Parallelism
Task parallelism
Data parallelism
{
c[i] = a[i] + b[i];
}SIMD
SPMD













'OpenCL' 카테고리의 다른 글
| OpenCL[3] Memory Object, Kernel Execution (0) | 2018.08.23 |
|---|---|
| OpenCL[2] platform, device, context, command-queue, program (0) | 2018.08.21 |
| OpenCL [1] concept (0) | 2018.08.21 |