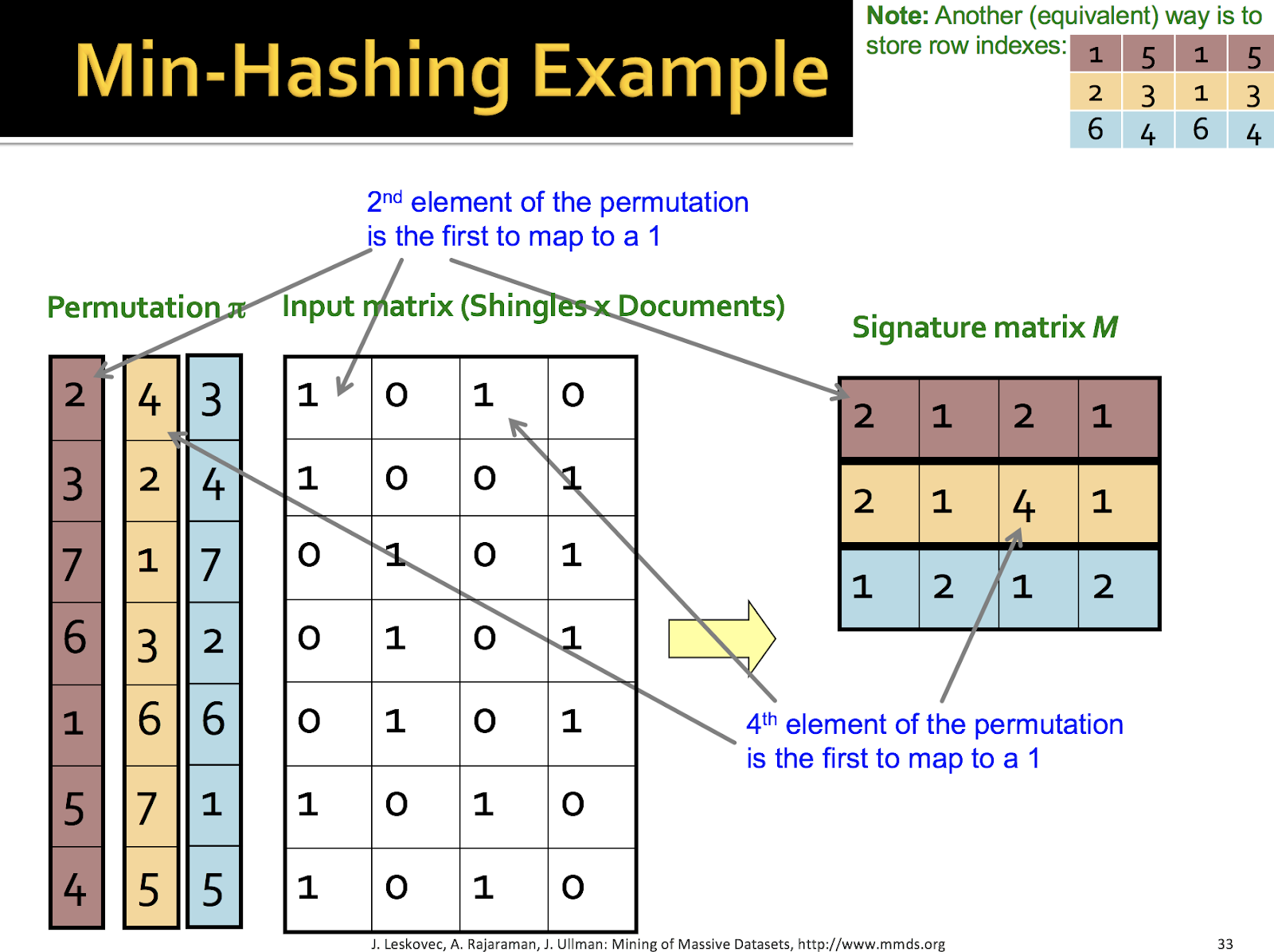
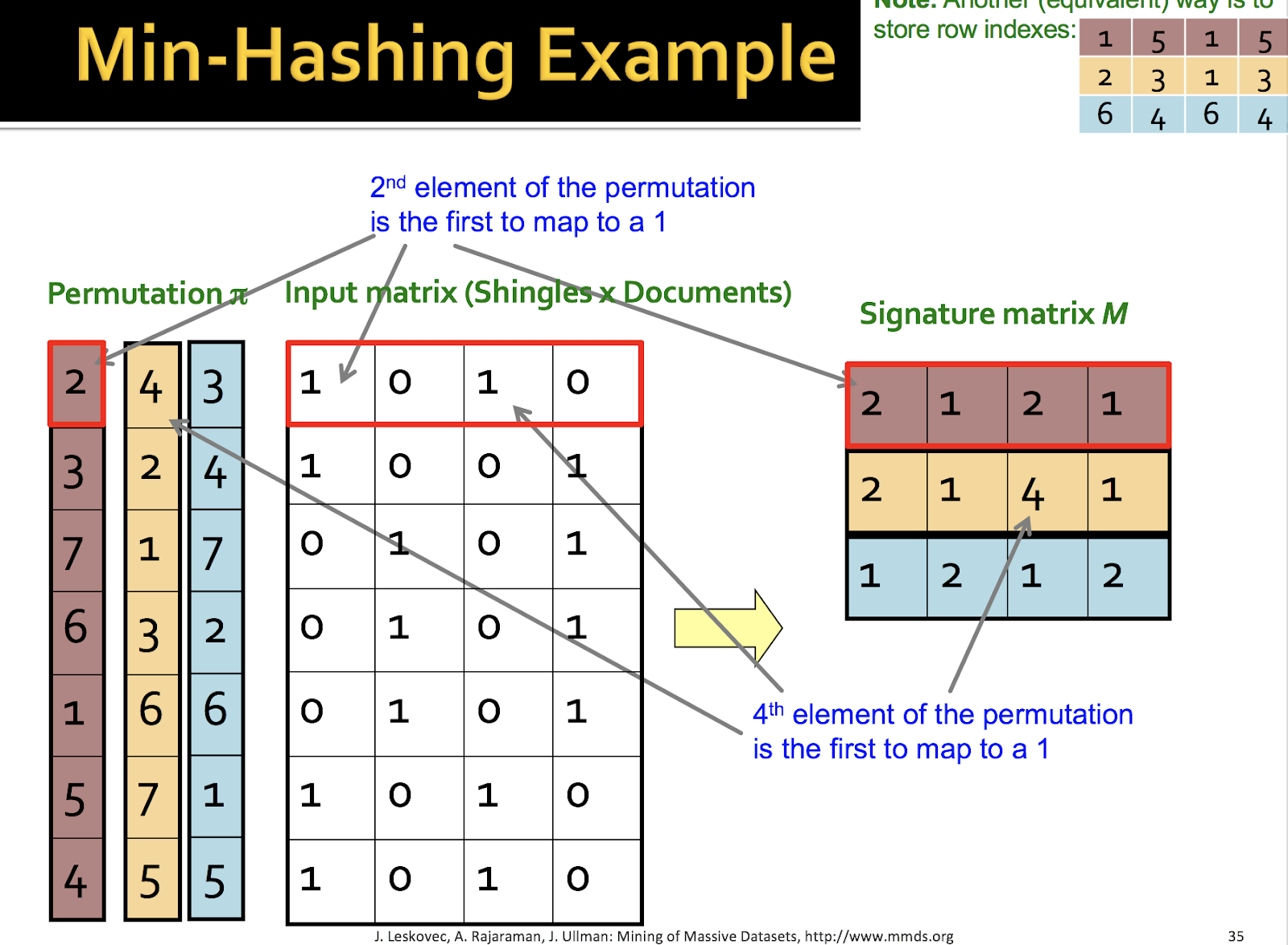
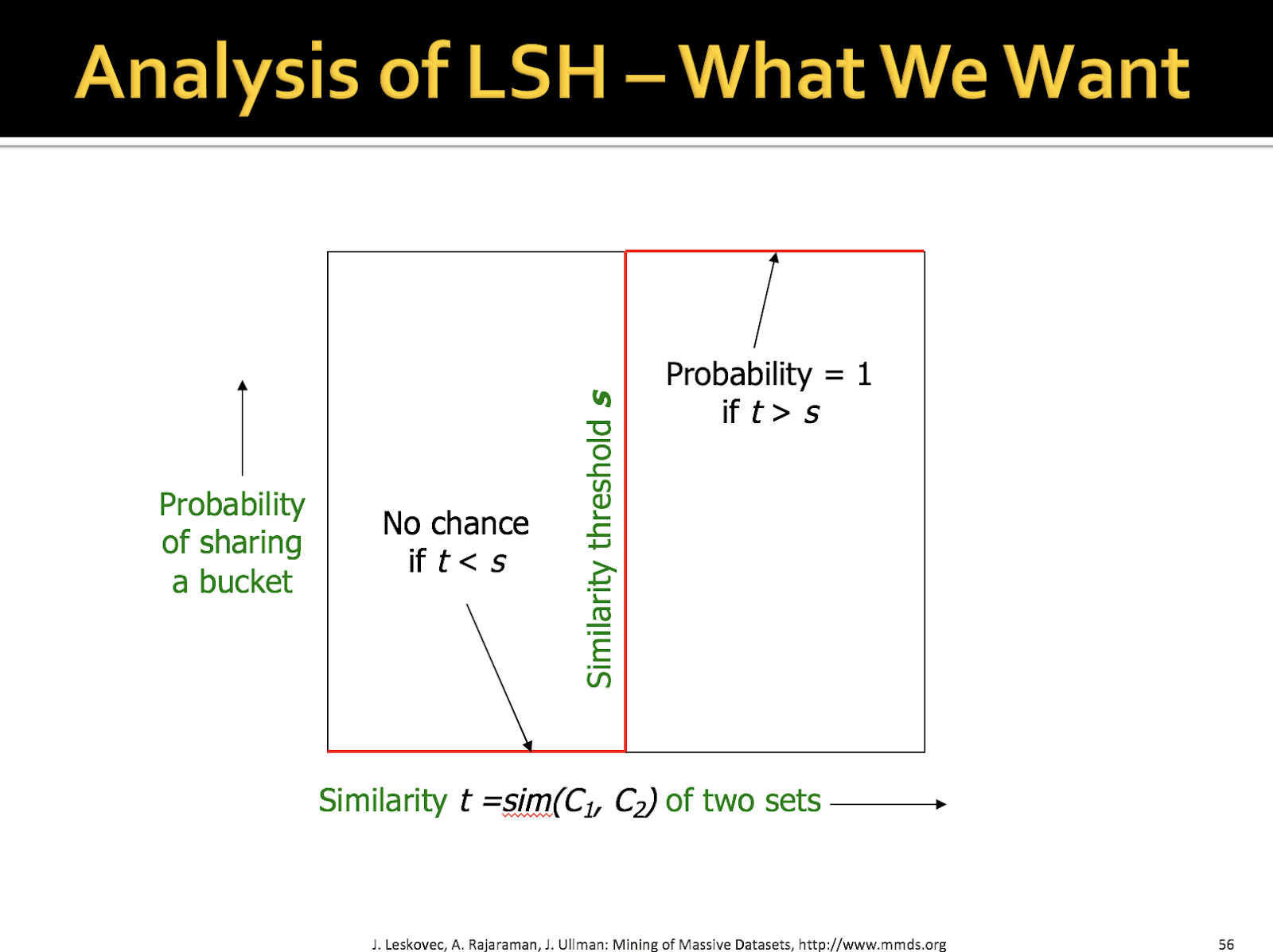
Finding Similar Items : Locality Sensitive Hashing 다음의 게시글은 Stanford University에서 제공하는 Mining of Massive Datasets(http://www.mmds.org)를 이용하여 작성하였습니다. 유사 아이템을 찾는 것은 중요한 기술 중에 하나입니다. 유사한 이미지, 유사한 사용자를 통한 상품 추천, 논문 표절 검사, 유사한 파일 비교 등 많은 분야에서 사용되고 있습니다. 유사한 이미지 검색을 살펴봅시다. 바닷가를 전망으로 한 사진과 유사한 이미지를 찾는다면 다음의 과정을 진행합니다. 우선 입력으로 들어가는 사진에 지붕을 삭제합니다. 그리고 유사한 이미지를 20,000 장의 이미지에서 찾아 제일 가까운 10장(nearest neighbors) 사진은 다음과 같습니다. 기준에 따라 다르겠지만, 바닷가의 사진은 나오지만 정확히 비슷하한 사진은 없습니다. 약 100배를 늘려 데이터셋이 2백만 장인 경우입니다. 제법 유사한 사진들이 많이 나오네요. 유사한 것을 찾는 것은 최대한 데이터셋의 개수 또한 중요해집니다. 고차원(high-dimensional)의 데이터 공간에서 유사한 아이템(near-neighbors)을 찾는 것은 위에서 설명했다 싶이 많은 분야에서 사용됩니다. - 페이지에서 유사한 단어 찾기 - 유사한 상품을 구매한 사용자 - 유사한 특징(feature)를 가진 이미지 고차원의 데이터를 어떻게 유사한지 찾을 것 인지 배워봅시다. 이미지가 주어진다면, 이미지의 픽셀 정보(r,g,b 3차원 matrix)를 하나의 벡터(vector)로 이어붙여 표현할 수 있을 것입니다. 유사함을 찾기 위해 다른 사진과 비교하기 위해서는 벡터의 요소(element) 간의 거리(distance)를 통해 정량화 할 수 있습니다. N장의 이미지의 모든 이미지를 서로 각각(2장씩 모든 pair) 비교하기 위해서는 O(N^2) 라는 시간 복잡도가 발생합니다. 이미지가 전체 10000장이라면 10000*(10000-1)/2 라는 무지막지한 비교가 필요하게 되죠. 이미지가 100만장이라면 현재 컴퓨터의 성능으로 분석하기 위해서 몇 일의 시간이 소요하게 될 것입니다. 알고리즘을 통해 O(N)으로 줄일 수 있다면 많은 시간이 단축되는 마법과 같은 일이 일어나겠죠? 아까 말한 단순한 방법인 n(n-1)/2 를 그림으로 표현하면 다음과 같습니다. 단순한 이 방법을 탈피하고자, A-Priori 방법을 살펴봅시다. 전처리(preprocessing) 과정이 필요합니다. 첫 번째 pass는 유사한 아이템의 쌍(pair)의 후보(candidate)를 찾는 것입니다. 두 번째 pass에서는 찾은 candidate pairs를 카운팅하는 것입니다. 이해를 돕기위해 마켓에서 장바구니를 예를 들어봅시다. 장바구니에 각각의 아이템이 담겨 있습니다. Amazon에서 상점에서 판매되는 상품을 분석한 사례로 아기를 가진 남성들이 기저귀를 사오라는 심부름을 받고 기저귀와 맥주를 함께 사는 것이 목격되었습니다. 이러한 분석의 이해를 통해서 기저귀 옆에 맥주를 놓아 매출 실적을 올릴 수 있겠죠. 장바구니에 담겨 있는 아이템에 대해서 서로 쌍을 만드는 것입니다. 여기서는 Frequent Itemsets이라고 표현했습니다. bread = 1, coke = 2, milk = 3, bread = 4로 정수형 숫자로 간단히 표기(notation)하여 봅시다. 첫 번째 장바구니를 집합으로 표현하면 {1, 2, 3}이고, pair로는 총 3가지인 {1, 2}, {2, 3}, {1, 3}이 나오게 됩니다. 자 이제 Bucket이라는 각 pair의 개수를 관리하는 hash table이 있다고 가정을 하고, 나온 pair에 대해서 개수를 카운트 합니다. 밑의 예시는 0 번째 인덱스(index)의 경우 {1, 2}, {2, 3}의 hash 값이 일치한다고 가정하여 2개가 카운팅 되었고, 5번째 index는 {1, 3}의 hash 값으로 1개가 카운팅 되었습니다. 다음의 장바구니에는 {1, 2, 4} 로 가정된다면 pair가 {1, 2}, {1, 4}, {2, 4}가 나올 것이며 이의 hash 값을 통해 bucket에 쓰여질 것입니다. bucket에 있는 pair에 빈도수(frequency)가 높다면, 같이 구매되는 유사한 상품이라 가정할 수 있습니다. 여기서 언급하는 PCY에 대한 자세한 알고리즘 내용은 다음의 주소를 참고해주세요. http://infolab.stanford.edu/~ullman/mining/pdf/assoc-rules2.pdf 자 이제 Finding Simliar Items로 넘어가 O(N)을 이뤄낸 Locality Sensitive Hashing 에 대해서 천천히 알아봅시다. 고차원(high dimensions) 데이터 공간에서 유사도(similarity)를 구하기 위해 우리는 각 데이터의 거리(distance)를 이용해 구합니다. 여기서는 Jaccard distance와 similarity에 대해서 배워봅시다. 두 가지 집합 C1와 C2가 있다고 가정해봅시다. 두 가지의 집합은 교집합(intersection)과 합집합(union)이 존재할 것이고 우리는 교집합의 개수와 합집합의 개수를 알 수 있습니다. similarity는 교집합의 개수 / 합집합의 개수 입니다. similarity = number of intersection / number of union Jaccard distance는 1 - similarity가 됩니다. Jaccard distance = 1 - similarity 여기서 설명할 예제는 N개(100만개, 또는 10억개)의 문서에서 유사한 문서(중복에 가까운)를 찾는 것입니다. N개에 대해서 2개씩 모든 문서를 비교하기에는 n(n-1)/2 개의 비교가 필요하여 너무 많은 시간이 걸리고, 모든 문서를 처리하기에는 memory의 허용량을 넘을 수 있습니다. 자 그래서, 유사한 문서를 찾기 위해 3가지의 step이 필요합니다. 1. Shingling : 문서를 집합(set)으로 변환합니다. n-gram 방식 2. Min-Hashing : 수많은 문서의 set을 hashing 기법을 통해 짧은 값(signatures)으로 변환합니다. similarity는 보존됩니다. 3. Locality-Sensitive Hashing : 위에서 변환 값(signature)를 기반으로 유사한 pair를 찾고, 그 pair만 정밀하게 검사합니다. 큰 그림을 살펴보면 문서를 Shingling을 통해 K개의 문자열의 집합으로 표현합니다. 그리고 Min-Hashing을 통해 집합을 표현하는 유사도를 보존하는 짧은 정수형(integer) 벡터(vector)로 표현합니다. Locality Sensitive Hashing을 통해 유사도 후보(candidate) pair를 뽑고, 이 pair에 대해서 유사도(similarity) 테스트를 진행합니다. Shingling에 대해서 살펴봅시다. 문서(documents)를 표현하기 위해서 기존의 간단한 방법은 문서에서 나타난 단어의 집합으로 표현하거나, 중요한 단어로 표현하는 것입니다. 그러나, 유사한 문서라는 것은 단어의 순서를 고려해야 하기 때문에 위의 방법으로는 부적절합니다. Shingling은 우리가 잘 알고 있는 n-gram으로도 불립니다. k-shingle(k-gram)은 순차적으로 나타나는 연속된 K개의 token으로 묶어 문서를 표현하는 것입니다. token은 글자(character)가 될 수 있고, 단어(word)가 될 수 있습니다. 예를 들어 문서 D = abcab 라고 가정할 경우, 2-shingles로 표현한 D의 집합은 {ab, bc, ca}이 됩니다. 집합은 중복을 허용하지 않기 때문에 마지막 ab가 없습니다. 중복이 가능한 bag로 표현하자면, {ab, bc, ca, ab}가 되겠습니다. 위에서 구한 shingles가 단어로 이루어진 한글이나 영어라면 그 길이는 길어질 것입니다. {My Name, Name is, is JeongChul, Jeongchul Kim} 이를 짧게 압축시키기 위해 4 bytes로 hash 값으로 표현합니다. 이 압축된 hash 값으로 k-shingles를 나타냅니다. 위의 {ab, bc, ca}는 Hash값으로 {1, 5, 7}로 표현하게 됩니다. 문서 D1은 k-shingles의 집합으로 표현할 수 있습니다. 각각의 문서는 k-shingles의 공간에서 0과 1로 이루어진 벡터(vector)로 표현할 수 있습니다. 이 벡터(vector)는 매우 sparse 할 것입니다. 문서는 순서가 달라도 유사한 텍스트를 가지고 있다면, 같은 shingles를 많이 가지게 됩니다. 일반적으로 k-shingles에서 k개는 문선의 길이로 결정합니다. 문서가 짧다면 k= 5, 긴 문서라면, k는 10개가 적절합니다. 앞에서 계속 얘기가 나왔지만 Min-Hashing과 LSH의 필요성을 다시 한번 살펴보죠. N = 1,000,000 개의 문서라고 가정한다면, 모든 문서의 2개의 pair로 pairwise Jaccard Similarities를 구한다면 N(N-1)/2로 약 5*10^11 비교가 필요합니다. 하루는 약 10^5초 이고, 초당 10^6을 비교할 수 있는 컴퓨팅을 가지고 있다면 약 5일이 걸립니다. N = 10,000,000개라면, 1년 넘게 걸립니다. 많은 유사도 문제는 교집합(intersection)의 부분집합을 찾는 문제로 공식화 됩니다. Encode 집합은 0과 1(bit, boolean) 벡터(vector)를 사용합니다. bitwise AND를 교집합(intersection)의 집합으로 표현하고 bitwise OR을 합집합(union)의 집합으로 해석합니다. 예를 들어 Encode set인 C1과 C2가 있다고 가정할 때 bitwise AND, OR을 통해 1이 되는 경우를 카운트하여 intersection의 개수(크기)와 union의 개수를 계산합니다. C1 = 10111 C2 = 10011 bitwise AND는 index 1, 4, 5가 1이 되므로 intersection의 개수는 3 bitwise OR은 index 1, 3, 4, 5가 1이 되므로 union의 개수는 4가 됩니다. similarity는 3/4 , Jaccard Distance는 1-similarity = 1/4가 됩니다. 우리는 위에서 구한 shingles와 문서에 대해서 co-occurrence matrix를 만들 수 있습니다. Row를 shingles, Column을 documents로 표현할 수 있습니다. 문서의 유사도(similarity)는 Column의 similarity이며, rows가 1인 집합의 Jaccard similarity를 계산하면 됩니다. 0번째와 1번째 Documents의 유사도를 계산해봅시다. 1100111 1110010 bitwise OR을 계산하면 size of intersection은 3이 됩니다. bitwise AND를 계산하면 size of union은 6이 됩니다. Jaccard similarity는 3/6이 됩니다. 쉽네요! 자 이제 문제는 유사한 Columns을 찾는 것으로 바뀝니다. 우리의 목표는 column의 유사도(similarity) 계산을 할 때 작은 signatures 값을 이용해 계산하는 것입니다. 문서에서 발생하는 shingles의 개수가 너무 많아 진다면, 모든 pair를 비교하기 위해서는 많은 시간이 소요됩니다. 자 그래서 우리는 hash 함수 h를 이용해 Column의 C를 작은 signature 값으로 압축합니다. h(C)는 충분히 작은 값으로 RAM의 메모리 양에 계산하기 적합합니다. C1과 C2의 유사도는 h(C1)과 h(C2)의 유사도와 일치합니다. 이는 Broder’s theorem 공식에서 입증되었습니다. 여기서 정의하는 hash 함수 h는 다음과 같습니다. C1과 C2의 similarity가 높다면, hash 값은 비슷해야 한다. C1과 C2의 similarity가 낮다면, hash 값은 달라야 한다. 이 hash 값을 이용해 buckets으로 분류되고, 유사도가 높은 document들은 같은 bucket에 존재하게 됩니다. 기존의 Hash 함수와는 다른 점이 Jaccard similarity에 적합한 hash 함수로 이를 Min-Hashing이라고 불립니다. Min-Hashing 함수는 Column을 이루는 row의 순서를 랜덤(random)으로 위치를 변경합니다. 이를 random permutation π로 표현합니다. [*] permutation : 순열, 치환으로 순서가 부여된 임의의 집합을 다른 순서로 뒤섞는 연산입니다. Min-Hashing의 hash 함수를 정의한다면, random permutation π를 통해 바뀐 순서에서, column C에서 첫 번째 1을 가지고 있는 index를 의미합니다. 예를 들어봅시다. Permutation 3개의 π를 얻을 수 있습니다. 각각의 π는 바뀐 index의 위치를 숫자로 나타냅니다. 첫 번째 갈색 permutation π에 대해서 살펴봅시다. permutation π의 index 1인 row로 갑니다. documents의 값에(Column C1, C2, C3, C4)에 1이 있는 지 확인합니다. C2와 C4에 나타납니다. 그렇다면 C1과 C4의 permutation π의 인덱스 1을 적습니다. C1과 C3이 1일 나타는 값을 찾기 위해 다음의 Permutation π의 index 2번째 row가 1이 나타나는지 확인합니다. 있다면 현재의 permutation π의 인덱스를 적습니다. 노란색 permutation π 또한 비슷한 과정을 거칩니다. permutation의 인덱스를 옮겨가면서 Column의 처음으로 1이 나타는 값에 permutation의 인덱스를 저장하는 방식입니다. 위에서 구한 Min-Hashing의 signature 값을 서로 다른 documents와 비교해 값이 비슷하다면 유사도(similarity)가 높다는 것을 의미합니다. C1과 C3의 문서가 유사도가 높고, C2와 C4가 유사도가 높음을 유추할 수 있습니다. 모든 random permutation π를 통해 계산한 유사도의 확률이 원본의 shingles의 simliarity와 비슷하다는 공식이 형성됩니다. 유사도를 계산해봅시다. 문서와 shingles로 이루어진 Input Matrix를 이용해 similarity를 계산할 수 있습니다. C1과 C3을 계산해봅시다. 1100011 1000011 bitwise AND를 통해 union의 개수는 4 bitwise OR을 통해 intersection의 개수는 3을 얻어 similarity = 3/4 = 0.75라는 값을 얻습니다. 마찬가지로 C2와 C4를 계산하면 0.75를 얻습니다. Min-Hashing으로 similarity를 구하면 C1(221)과 C3(241) 일치하는 지 확률로 similarity을 구할 수 있습니다. 2/3 C2(112)와 C4(112)는 완벽하게 일치하므로 1이라는 값을 얻습니다. 실제 Min-Hashing을 통해서 얻은 similarity과 수치적으로 조금은 부정확하지만 비슷한 결과를 얻을 수 있습니다. 일반적으로 K=100 random permutation을 고르게 됩니다. sig(C)는 column vector라고 고려한다면 sig(C)[i]는 i번째 permutation에서 column C에서 처음으로 1이 나오는 index로 정의합시다. sig(C)[i] = min(πi(C)) 로 수식을 쓸 수 있습니다. 우리의 목표는 Jaccard similarity가 s라는 threshold 이상인 값을 찾습니다. 예를 들어 s가 0.8이라면, similarity가 0.8 이상인 문서들을 찾게 됩니다. LSH는 f(x, y)라는 함수를 사용해 x와 y가 candidate pair인지 확인합니다. Min-Hash 매트릭스인 signature matrix M에서의 column의 hash를 통해 bucket으로 분류됩니다. 유사도(similarity)가 높다면 같은 bucket으로 들어가 candidate pair로 됩니다. 우선 우리는 similarity threshold인 s(0 < s < 1)를 설정합니다. M의 x, y의 column이 candidate pair라면 적어도 similarity는 s 이상을 만족합니다. 유사한 column(문서)는 같은 hash 값을 가지게 되고 높은 가능성으로 같은 bucket으로 들어갑니다. 같은 bucket에 있다면 candidate pair로 지정됩니다. Signature로 이루어진 matrix M은 b개의 band로 묶입니다. band는 r개의 permutation으로 이루어집니다. hash table은 k개의 bucket으로 이루어지며 k는 가능한 클 수록 좋습니다. 같은 bucket에 있는 hash는 적어도 1개 이상의 band에 있어야 합니다. b와 r 값을 조정해 대부분의 유사한 pair가 있도록 조정해야 합니다. 전체 b개 band가 있습니다. 각각의 band(permutation r개로 이루어진 hash)에서 hash 값에 따라 bucket으로 들어갑니다. 메모리가 허락하는 한, Bucket의 개수가 많을 수록 좋습니다. bucket의 개수가 충분 하다면, 유사하지 않은 documents는 서로 같은 bucket에 들어가지 않게 됩니다. 매트릭스 M이 100,000 column(100K 문서)로 가정해봅시다. 각 문서는 100개(permutation)의 정수인 signatures로 이루어집니다. 그러므로 signatures는 40MB로 이루어집니다. b = 20개라면, 각 band의 r은 5가 됩니다. 우리의 목표는 적어도 similarity가 0.8이 되는 문서의 pair를 찾아봅시다. C1과 C2가 0.8의 유사도(similarity)를 가진다면 적어도 하나의 band에서 C1과 C2의 hash가 동일할 확률은 몇 일까요? 하나의 band는 r=5로 이루어져 있다고 가정합시다. 하나의 candidate의 pair로 있을 확률은 0.8 이고, 5개에서 동시에 일어날 확률이므로 특정한 band에서 (0.8)^5 = 0.328 의 확률을 가집니다. 그렇다면 모든 band(20개)에서 C1과 C2가 유사하지 않은 확률은 (1-0.328)^20 = 0.00035 입니다. 0.00035는 False Negative(FN)이 됩니다. 이 뜻은 3000번 중에 한 번은 0.8%의 similarity pairs를 놓칠 확률입니다. 나머지 99.965%의 정확도를 가지게 됩니다. FN에 대해서 다시 생각해보면, 100000번 중에 35번은 유사한 확률을 가진 문서를 유사하지 않다고 잘못 판단한다는 것이며, 생각보다 큰 문제점이 될 수 있습니다. FN은 줄이려면 band의 개수(b)를 늘리거나, band의 element의 개수(r)을 늘려야 합니다. 목표는 동일합니다. similarity가 0.8 이상인 문서의 pair를 찾습니다. 이번엔 C1과 C2의 유사도(similarity) 0.3이라고 가정해봅시다. 특정한 band에서의 C1과 C2가 동일할 확률은 (0.3)^5 = 0.00243 입니다. 적어도 20개의 band 중에서 1개라도 C1과 C2가 동일할 확률은 1 - (1-0.00243)^20 = 0.0474입니다. 이는 다시 말해 유사도 0.3%를 가진 문서 pair가 candidate pair가 될 확률은 4.74% 입니다. 이 확률은 0.8 이상의 문서를 찾는데 0.3%가 유사하다고 잘못 판단하는 경우로 FP에 해당합니다. 우리는 FN에 비해 FP는 관대한 편입니다. 비록 컴퓨팅 자원은 낭비하겠지만, 정밀 검사를 통해 유사하지 않다고 판단할 수 있기 때문입니다. LSH(Locality Sensitive Hashing)은 FN과 FP의 trade-off를 가지게 됩니다. 이에 따라 Min-hashes의 개수(matrix M의 row 개수 = permutation의 개수)와 band의 개수 b 그리고 band를 이루는 row의 개수 r을 잘 설정해야 합니다. 일반적으로 similarity의 임계값(threshold) s를 x축으로 표시하고 hash 값이 같아 bucket을 공유할 확률을 y축으로 놓았을 때 이상적인 분류에 대한 분포 모습은 다음과 같습니다. 실제로 확률분포의 모습은 저렇지 않습니다. 위에서 계산한 값들을 공식화 해봅시다. C1과 C2의 유사도가 t이고 band의 개수는 b, band를 이루는 row는 r개라고 가정합시다. band의 모든 row에서 similarity가 동일할 확률은 t^c 입니다. 동일하지 않은 확률은 1-t^c 입니다. 모든 band에서 동일하지 않은 확률은 (1-t^c)^b 입니다. 적어도 하나의 band에서 동일할 확률은 1-(1-t^c)^b입니다. 이를 t에 대해서 정리하면 s = (1/b)^1/r이라는 값을 얻게 되고 그래프로 표현하면 sigmoid 함수와 비슷한 모양을 얻습니다. b = 20, r=5라고 가정하고, 함수를 분석해봅시다. similarity threshold(s)에 값에 0.2부터 0.8까지 값을 넣으면 다음의 표의 값을 얻을 수 있습니다. 임계값(similarity threshold, s)을 경계로 우리는 면적을 통해 FP와 FN을 계산할 수 있습니다. s보다 큰 경우에 예측하지 못한 경우의 파란색 면적은 FN(False Negative)가 됩니다. s보다 작은 경우 bucket에 공유될 확률에 속하므로 잘못 예측이며, FP(False Positive)가 됩니다.Introduction
Finding Similar Items
Step 1 Shingling
Min-Hashing

Locality Sensitive Hashing





















































'MachineLearning' 카테고리의 다른 글
| Bloom Filter(블룸 필터) (1) | 2018.10.01 |
|---|---|
| EigenDecomposition 고유값 분해, eigenvector (1) | 2018.09.07 |
| Genetic Algorithm 유전알고리즘 - Introduction (0) | 2018.03.23 |
| Incorporating Field-aware Deep Embedding Networks and Gradient Boosting Decision Trees for Music Recommendation (0) | 2018.02.28 |
| Machine Learning - Classification : Analyzing Sentiment (0) | 2018.02.02 |