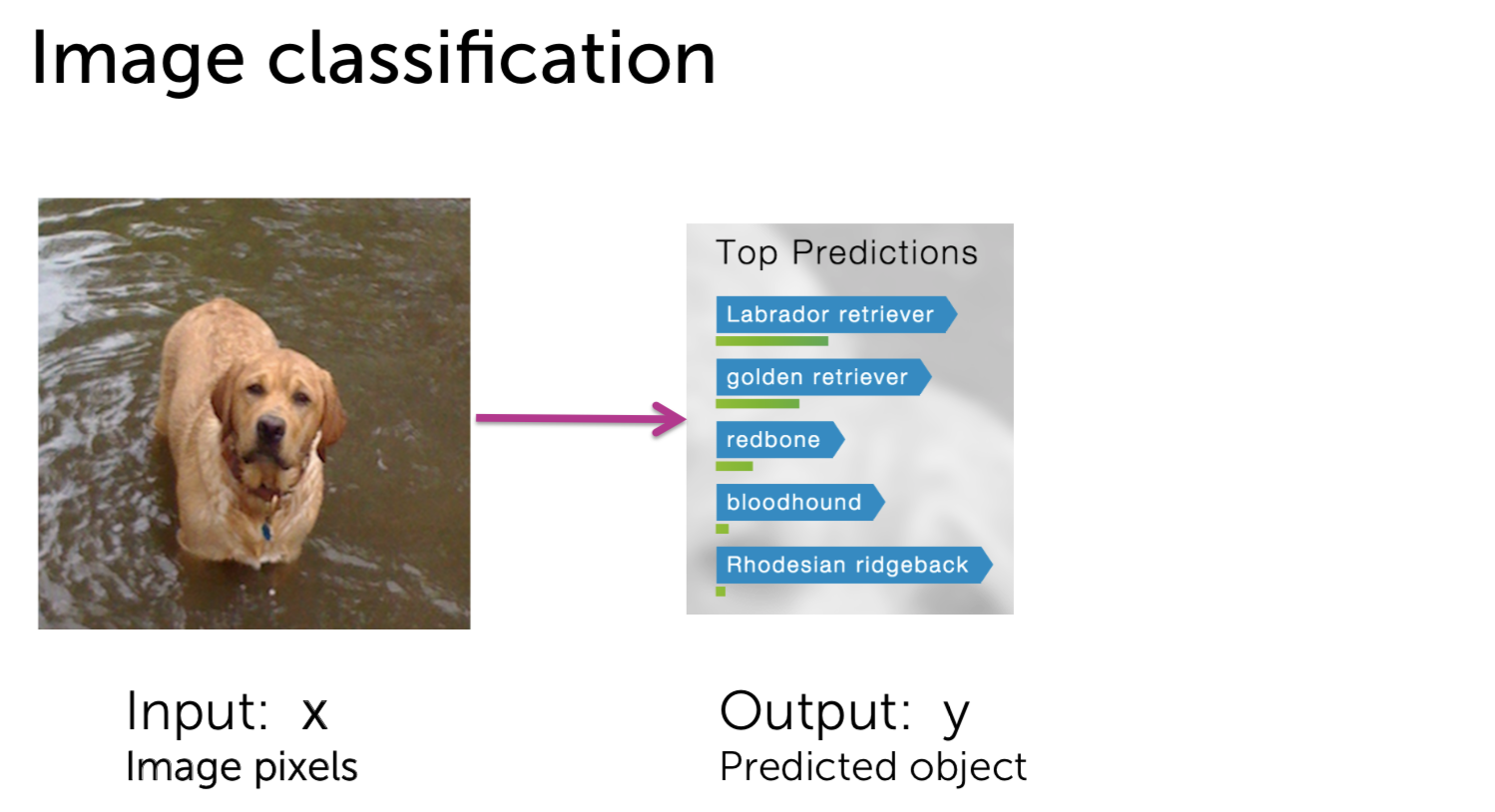
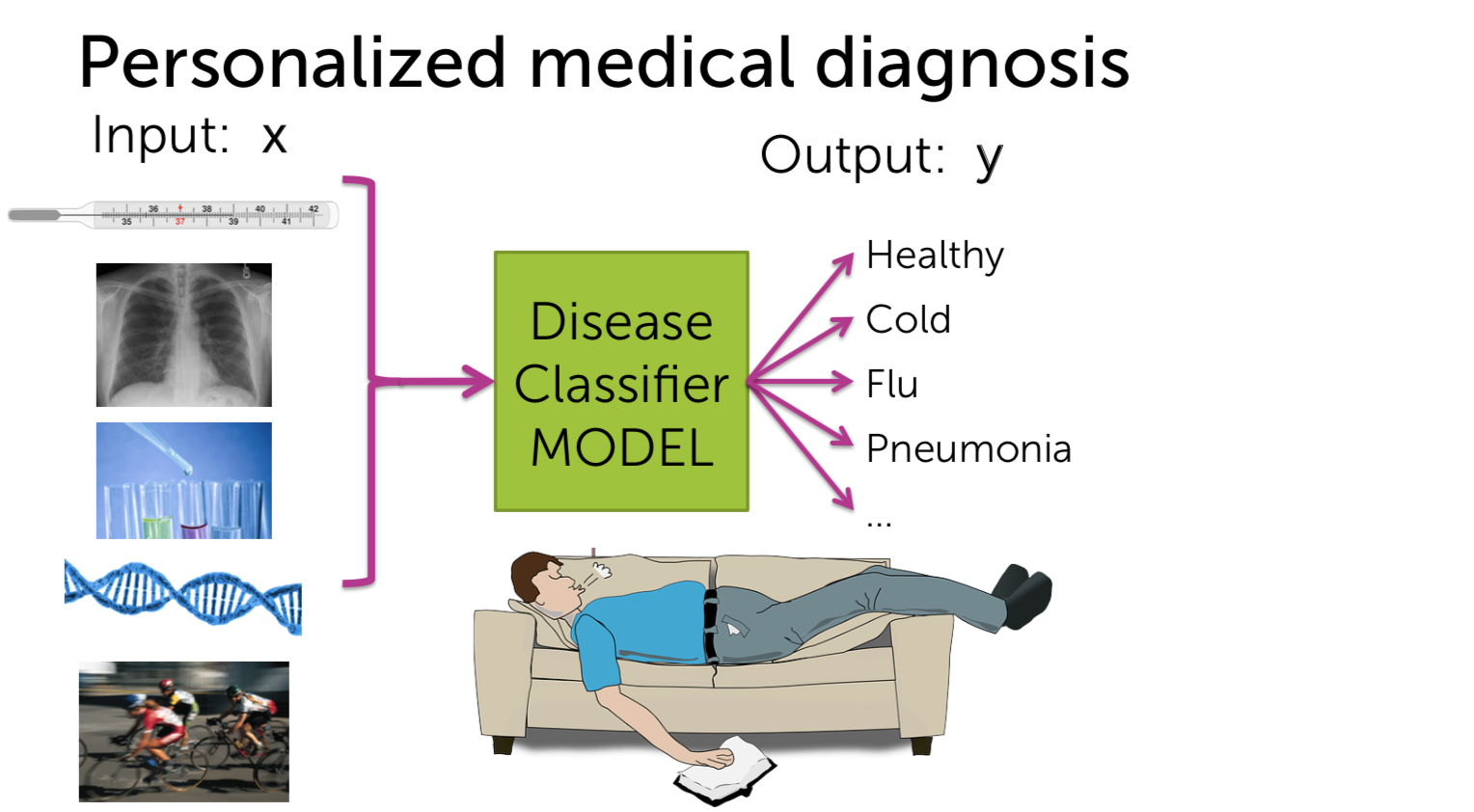
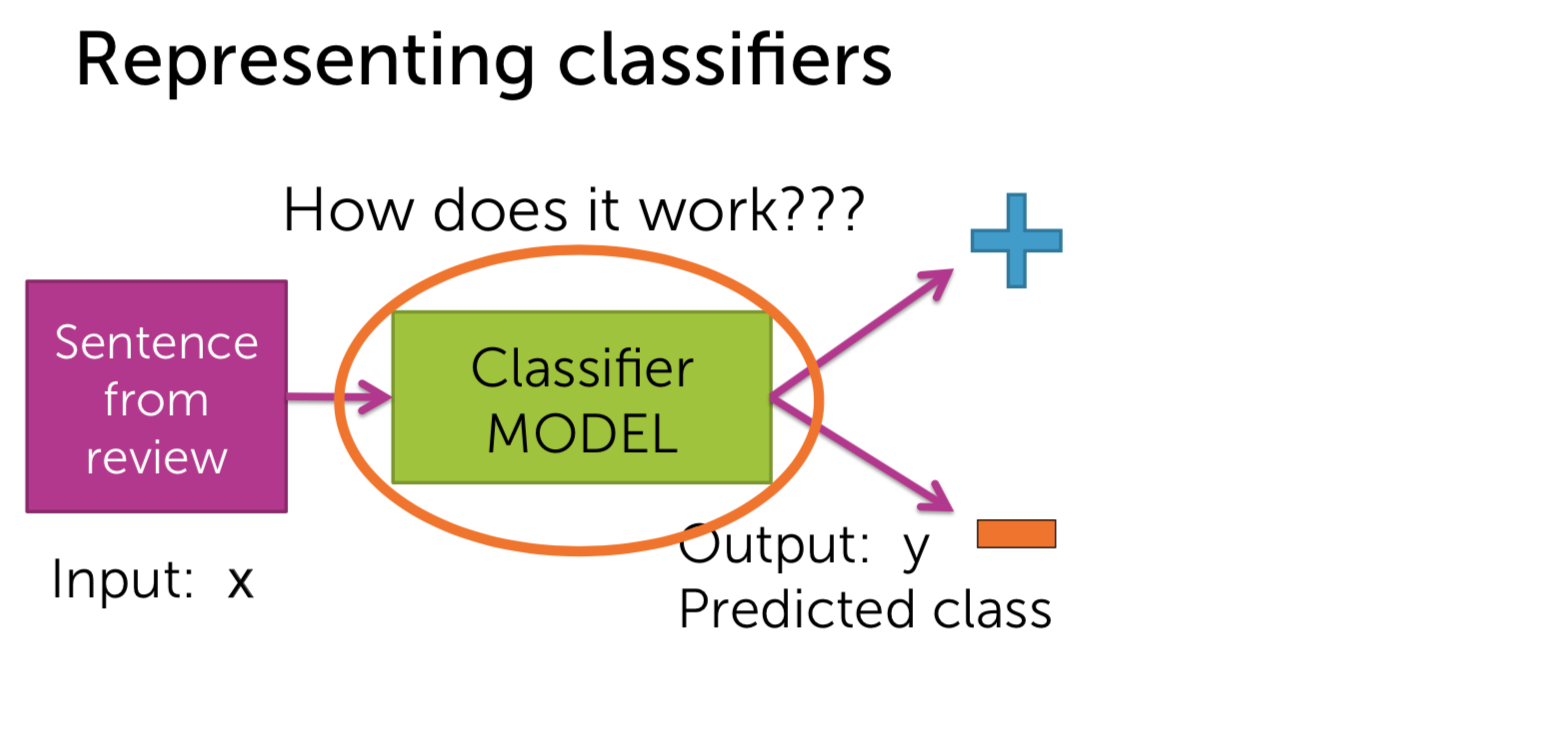
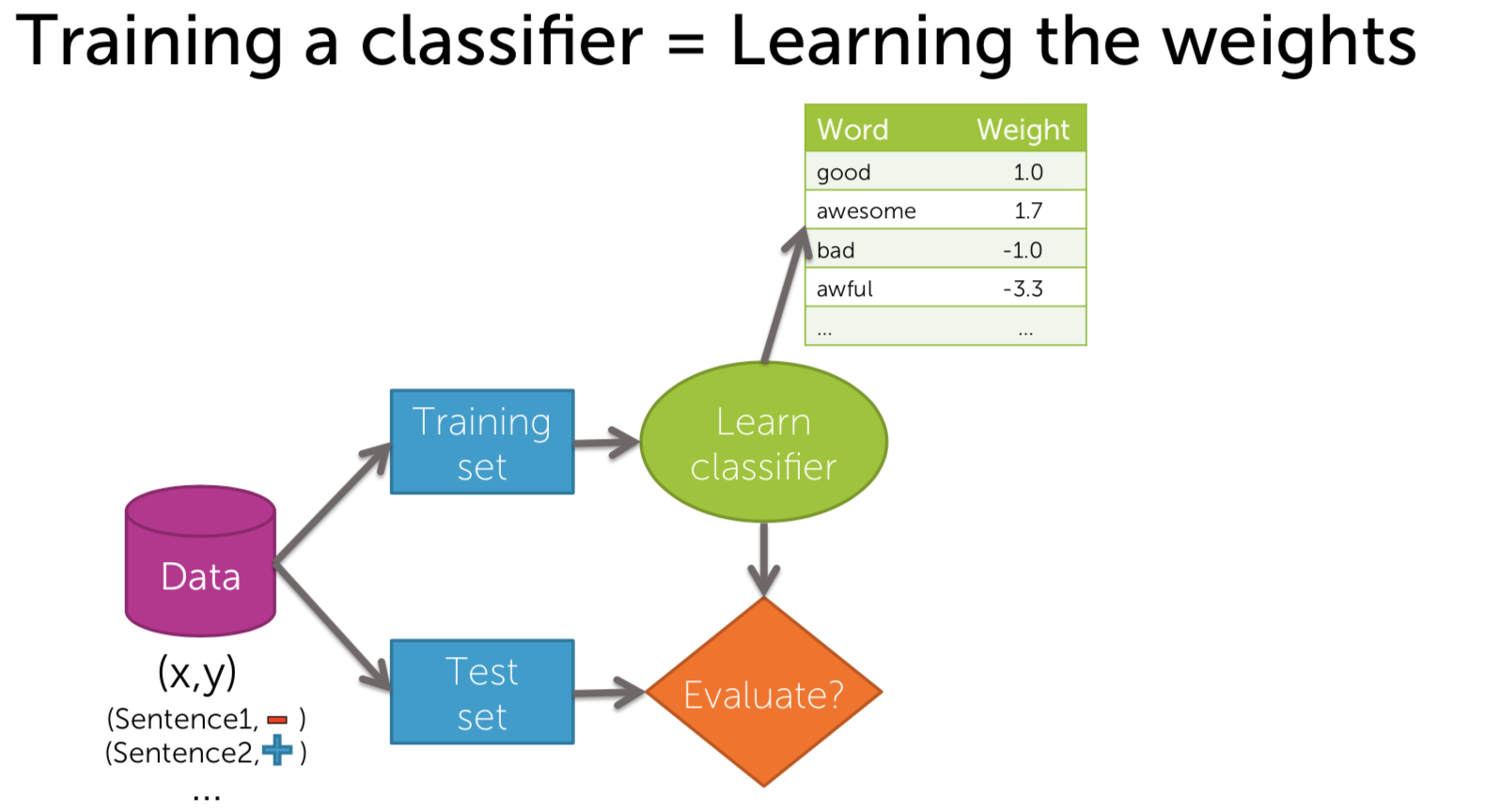
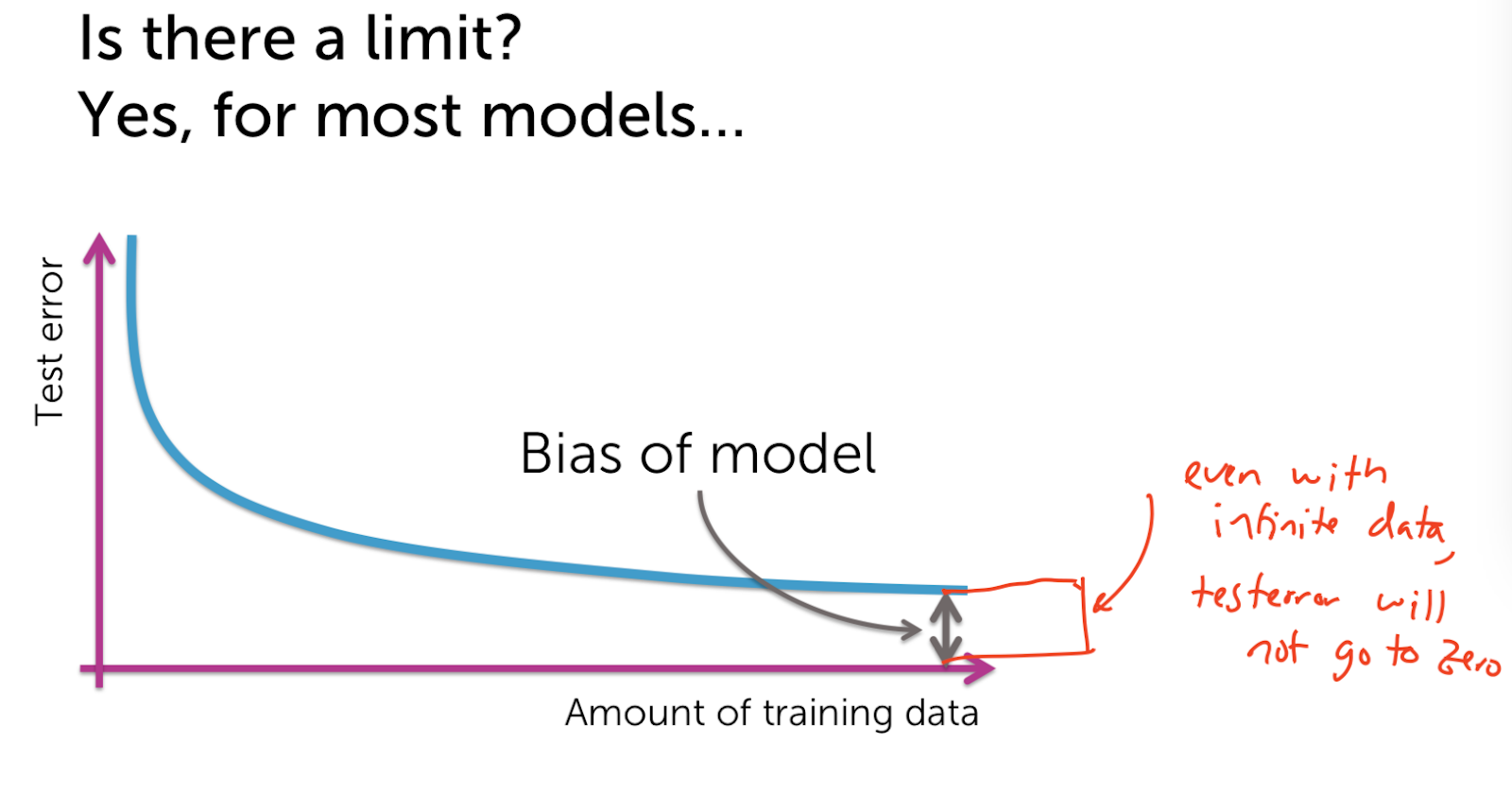
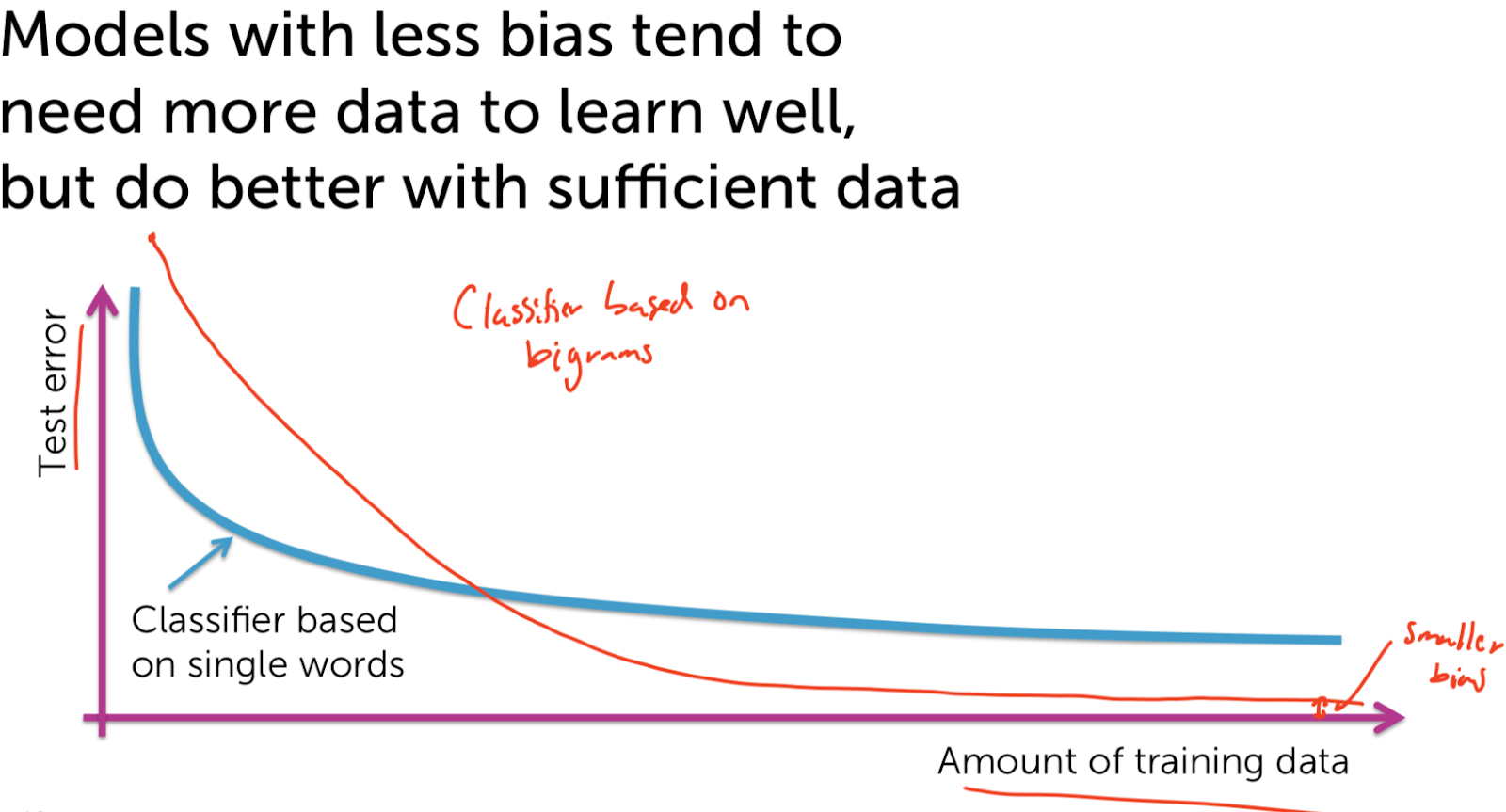
Machine Learning - Classification : Analyzing Sentiment Machine Learning with the tools IPython Notebook & GraphLab Machine Learning with the tools IPython Notebook & GraphLab Create on AWS Machine Learning with the tools IPython Notebook Usage Machine Learning with the tools IPython Notebook SFrame Machine Learning - Predicting House Prices : Regression Machine Learning - Predicting House Prices : python 이번에는 Classification(분류)에 대해서 얘기해보겠습니다. Classification의 예로는 email이 spam인지 아닌지 또는 documents가 sports topic인지 politicis인지, entertainment인지 확인해봅니다. 거기 밖으로 레스토랑 리뷰(restaurant reviews)를 위한 많은 시스템이 있지만, 오늘 우리는 우리가 만들 수 있는 매우 새롭고 흥미로운 것에 대해 이야기 할 것입니다. 오늘은 우리에게 중요한 날이고 우리는 일식 레스토랑을 예약하려 합니다. 그리고 우리는 일본 음식을 좋아하고 정말 멋진 곳에서 일본 음식을 먹고 싶습니다. 그러나 이것은 우리가 살고 있는 시애틀(Seattle)이며, 시애틀은 일본 음식(Japenese food)이 정말 굉장합니다. 그래서 초밥을 먹을 수 있는 곳이 많이 있습니다. 실제로 별 4 개는 정말 좋은 평가(ratings)를 받은 곳이 많습니다. 어쩌면 내가 갈 레스토랑에 대해서 생각할 때 나는 레스토랑의 전반적인 별을 생각하는 것이 아니라, 분위기 면에서 또는 음식의 관점에서 생각하고 있습니까? 사람마다 관점이 다르겠지만 저는 정말로, 가장 신선하고 신선한 생선과 제가 얻을 수있는 가장 훌륭하고 혁신적인 스시를 원합니다. 그래서 우리는 레스토랑의 긍정적인 리뷰(positive review)를 살펴봅니다. 리뷰의 샘플로 “Watching the chefs create incredible edible art made the experience very unique.”를 보자면 레스토랑의 측면에 대해서 생각해본다면 experience는 매우 긍정적(positive)입니다. 그러나 “My wife tried their ramen and it was pretty forgettable.”의 리뷰를 보자면 ramen은 좋지 않다는 것으로 보입니다. 마지막 리뷰로 “All the sushi was delicious! Easily best sushi in Seattle.”를 보자면 sushi는 delicious하고, best라는 단어로 2번의 positive한 답변을 얻었습니다. 그래서 레스토랑 리뷰(restaurant reviews)에 대해 생각할 때, 나는 긍정적이거나 부정적인 레스토랑의 측면을 이해하고, 정말로 그 중 어떤 것이 내 관심사에 영향을 미치는지 생각하고 싶습니다. 따라서 레스토랑 리뷰를 모두 살펴보면서, 새롭고 흥미로운 레스토랑 추천 시스템의 음식을 먹고 싶습니다. experience는 긍정적으로 4 stars 이며, ramen은 별로였지만, 신경쓰지는 않습니다. 그러나, 내가 정말로 신경 쓰는 sushi는 5 stars를 가지고 있고 그 뿐만이 아니라, 나에게 흥미로운 피드백을 줄 것입니다, 예를 들어, 이것은 시애틀에서 가장 좋은 스시입니다. 이제 그 레스토랑이 내가 가고 싶은 곳입니다. 우리는 어떻게 intelligent restaurant review system을 만들 수 있을까요? 우리는 모든 리뷰가 가진 문장을 분석합니다. 리뷰는 여러 개의 문장으로 구성되어 있으며, 몇 개의 문장은 레스토랑의 다른 측면에 대해서 얘기합니다. 우리는 Sentence Sentiment Classifier를 만들어 문장이 긍정적(positive)인지 부정적(negative)한지 살펴봅니다. 우리는 위에서 생성한 sentiment classifier를 이용해 리뷰 중에서 sushi와 관련된 문장들만 선택해 classifier(분류기)에 넣습니다. 이 분류기를 통해 평균 예측(average predictions)으로 5 stars를 가지게 되며, 가장 긍정적인 문장을 확인할 수 있으며, sushi에 대해 부정적인 답변은 볼 수 없는 것으로 확인할 수 있습니다. 우리는 classifiers를 이용해 restaurant review를 분석해볼 것입니다. Classifier는 리뷰로부터 문장인 입력 x를 받으며, Classifier Model을 통해 클래스를 예측하여 출력으로 y 값을 가집니다. 예측값의 예로는 긍정적인(positive)와 부정적인(negative) 클래스(class)를 가질 수 있습니다. 예측하는 클래스가 여러 개(multi class)인 classifier도 있습니다. 입력 x로 webpage를 classifier에 넣으면 출력 y로 3개의 category(Education, Finance, Technology)로 분류할 수 있습니다. 3개, 4개 뿐만 아니라 수천가지의 클래스도 가질 수 있습니다. Classifier의 또 다른 예로는 spam filtering이 있습니다. 입력 x로는 email의 text와 발신자(sender)와 IP 등으로 입력받으며, 예측 결과로는 Spam 인지 아닌지로 분류하게 됩니다. computer vision에서는 많은 분류가 사용됩니다. input으로 이미지의 픽셀 정보(3d array)가 들어가며, output으로 이미지가 무엇을 의미하는 지 분류합니다. 다음의 예에서는 Labrador retriever 리트리버라는 강아지로 인식하고 있습니다. 또한 분류는 medical diagnosis system(의료 진단 시스템)으로 사용할 수 있습니다. 입력으로 사용자의 온도(temperature) 와 x-ray와 medical test를 통해 사용자의 건강 상태를 예측할 수 있습니다. FMRI라고 불리는 기술로 뇌를 스캔한 이미지를 통해, 생각하는 단어를 예측할 수 있습니다. classifier의 가장 주로 사용되는 linear classifier에 대해서 알아봅시다. review의 문장이 입력으로 들어가게 된다면, Classifier Model은 어떻게 동작되는 것일까요? 우리는 간단한 threshold(임계치) classifier를 생각할 수 있습니다. 문장에서 positive와 negative words를 count하여, positive word가 많다면, output은 positive로, 반대의 경우로는 negative로 분류할 수 있습니다. 예를 들어 positive 단어의 리스트로는 great, awesome, good, amazing 등으로 있으며, negative 단어 리스트로는 bad, terrible, disgusting, sucks 과 같은 단어가 있습니다. 입력으로 “Sushi was great, the food was awesome, but the service was terrible.” 들어온다면, 위의 단어 리스트로부터 count를 합니다. 긍정적인 단어는 2개(great, awesome), 부정적인 단어는 1개(terrible)로 되며 최종 결과는 긍정적인 것으로 예측됩니다. 그러나, 이러한 threshold classifier에는 문제가 있습니다. positive/negative 단어의 리스트를 얼마나 갖고 있어야 하는지, 또는 각 단어들 마다 긍정과 부정의 정도가 각기 다릅니다. 또한 good과 not good의 예로 하나의 단어로 positive/negative를 측정하기에는 불분명합니다. 우리는 이러한 issue를 해결하고자, positive/negative 단어에 weight(가중치)를 부여합니다. 예를 들어 good이라는 단어에는 1.0의 가중치를 주며, great는 good 보다 더 positive 하므로 1.5를 부여하고 awesome은 그보다 더 좋은 의미를 내포하므로 2.7을 부여합니다. 마찬가지로 bad와 terrible, awful 에 대해 각기 다른 weight를 부여합니다. 또한 중의적인 단어들에는 positive/negative가 아닌 0.0의 가중치를 부여합니다. input x로 들어온 3개의 문장에 대해서 word의 weight 값을 적용해보면 score(x) = great(1.2) + awesome(1.7) + terrible(-2.1) = 0.8입니다. score(x) >= 0 인 경우 positive class 이며, score(x) < 0 인 경우 negative class 입니다. 즉 x의 output으로 positive class로 예측됩니다. output이 input의 weight의 총합이므로 linear classifier라고 부릅니다. 우리는 간단한 linear classifier에 대해서 알아봤습니다. Score(x)는 문장의 word의 weight의 합입니다. Score(x)가 0보다 크면 output은 +, 0보다 작다면 output은 -입니다. Classifier는 decisions을 결정하기 위해 시도합니다. Decisions은 문장이 positive인지 negative인지 결정합니다. Linear Classifier에서 decision boundary를 이해하기 위해 우리는 2개의 단어의 weight를 0이 아닌 값으로 부여합니다. awesome의 weight가 1.0이고, awful의 weight가 -1.5라면, Score(x) = 1.0 #awesome - 1.5 #awful (# : number of) 입니다. 우리는 x축을 awesome의 개수로, y축을 #awful으로 plot을 그릴 수 있습니다. “Sushi was awesome, the food was awesome, but the service was awful.” 이라는 문장에서는 (2,1)로 point를 찍을 수 있습니다. 예시로 찍힌 점들의 Score(x)를 구한다면 0보다 큰 양수의 값과 0보다 작은 음수의 값으로 decision boundary가 형성됩니다. Score(x)은 직선의 방정식으로 위의 그림과 같은 직선을 얻을 수 있습니다. 이것을 linear decision boundary라고 합니다. 2개의 feature라면 line이 형성되며, 3개의 feature라면 plane(면)이 형성되며, n개의 feature라면 hyperplane(n-dimensions 차원)이 형성됩니다. 더욱더 일반화된 classifier라면 복잡한 shape을 가지게 됩니다. 이전에 배운 Regression model에서 error 측정은 Squared Error의 총합으로 구하였습니다. 그러나, Classification에서는 error에 대한 측정이 다릅니다. input에 대해서 correct인가 wrong인가에 따라 달라지게 됩니다. 우리가 Classifier를 학습할 때 입력 Sentence에 대해 실제값과 예측값은 positive, negative class입니다. Data에서 Training과 Test set으로 split하여 Classifier를 학습합니다. 학습 알고리즘은 각 feature(word)의 weight들을 학습하게 됩니다. 그리고 나서 이 weight들을 적용해 test-set에 대해서 예측을 하고 Evaluation을 진행합니다. Test set 문장에서 “Sushi was great.” +(positive) class로 Classifier로 예측을 합니다. 예측값(predictions)이 +이라면 label과 일치하므로 Correct는 1로 증가합니다. 다음의 Test 예로 “Food was Ok”는 label이 +(positive) class로 Classifier가 예측한 값은 -(negative) class로 mistakes 입니다. Mistakes는 1로 증가합니다. Test Case에 대해 모두 mistakes와 correct를 계산합니다. 2 가지의 흔한 측정 방법이 있습니다. error 측정에 대해서는 mistake 개수에서 test의 총 문장으로 나눕니다. accuracy 측정은 correct 개수에서 test의 총 문장으로 나눕니다. 즉 accuracy는 1-error 입니다. 우리는 classifier로부터 error와 accuracy를 evaluation 하였습니다. data가 주어진 상황에서 현재의 accuracy가 좋은지 어떻게 확인할 수 있을까요? Classification이 좋은지 알기 위해서 첫 번째 baseline은 random guessing을 하는 것입니다. 예를 들어서 binary classification(class : 2개 positive, negative)에서는 random guessing의 경우 accuracy는 50%입니다. k개의 class라면 accuracy는 1/k 입니다. 그래서 classifier가 무의미하지 않으려면, 최소한 random guessing보다는 accuracy가 좋아야 합니다. classifier가 90%의 accuracy를 가진다는 것은 좋은 걸까요? 2010년의 데이터에서는 90% 이메일은 spam라고 보여집니다. 그래서 나는 모든 email을 spam이라고 예측합니다! 나의 정확도는 90%입니다. 과연 이런 예측(prediction)의 정확도는 옳을까요? 이것은 majority class prediction이라고 불리는 문제로 단지 예측 클래스가 가장 보편적(common)이기 때문에 문제가 발생합니다. 그리고 불균형 클래스(imbalance class)가 있는 경우에 놀라운 성능을 발휘할 수 있습니다. imbalance class는 한 클래스가 다른 클래스보다 개수가 훨씬 더 많이 있습니다. 따라서 accuracy가 좋은지 알아 내려고 할 때 imbalance class가 있는지 확인해야 합니다. 따라서 항상 주어진 문제를 파헤 치고 예상되는 예측에 대해 실제로 이해하고, 그 정확성이 문제에 실제로 의미가 있는지 여부를 파악해야합니다. 나의 application에서 필요한 accuracy는 무엇인가? 나의 사용자의 입장에서 충분한가? 우리가 만든 mistake의 영향은 무엇인가? 위의 예제에서 spam filtering에서 accuracy가 좋지 않으면, 아주 중요한 메시지가 spam으로 표시되며, 이는 최악의 상황이 발생됩니다. 이번에는 classifier의 다른 종류의 error에 대해서 살펴봅시다. 위의 보이는 표에서 2x2 사각형을 confusion matrix라고 합니다. confusion matrix는 실제 label과 예측 label에 대한 관계를 나타냅니다. - True Label(+) Predicited Label (+) : True Positive(TP) - True Label(-) Predicited Label (-) : True Negative(TN) - True Label(+) Predicited Label (-) : False Negative(FN) - True Label(-) Predicited Label (+) : False Positive(FP) 위의 Confusion Matrix에서 실제 사례로 각 cost는 다릅니다. FN과 FP에 대해 각각 Spam filtering과 Medical diagnosis(의료 진단)을 살펴봅시다. Spam filtering에서 FN은 spam으로 분류하지 못한 예입니다. 이 경우는 짜증나는 정도(Annoying)입니다. 그러나 FP 경우, 실제 중요한 이메일을 스팸 폴더로 가버린 경우이며, 결국 유실되며 높은 비용(high cost)이 초래됩니다. Medical diagnosis의 경우 FN은 질병이 검출이 안된 경우 입니다. 이 경우는 질병을 치료받지 못해 사망에 이를 수 있습니다. FP는 질병이 없는데 질병이 있다고 분류되어, 부작용이 심한 약을 처방해야 됩니다. FP와 FN 또한 크나큰 high cost가 달려 있습니다. 다음의 예에서는 100개의 Test case에서 true label이 60개의 positive(+)와 40개의 negative(-)를 가진 경우 입니다. 그 중에서 예측 중에서 60개의 positive(+)에서 50개를 correct하고, 40개의 negative(-)에서 35개만 correct 합니다. accuracy는 85/100 = 0.85 입니다. FP rate는 FP/(FP+TN) = 5/35 = 1/7 FN rate = FN/(FN+TP) = 10/50 = 1/5 즉 FN rate가 FP rate보다 높습니다. FP와 FN은 binary classification에서 존재합니다. 이번에는 class가 3개인 경우입니다. 이번에는 Medical diagnosis 분류기에서 100명의 test case 중 실제 true label은 70명이 정상(Healthy), 20명이 감기(Cold) 그리고, 10명이 독감(Flu)입니다. Confusion Matrix에서 주대각선(major diagonal)은 prediction과 true label이 일치하는 경우(correct) 입니다. Regression 모델에서는 Model의 error와 accuracy 간의 관계를 살펴보았습니다. 이번에는 학습이 필요한 data의 양 관계에 대해 살펴봅시다. Machine model에서는 training data의 양의 기준을 세우는 것은 상당히 어렵고 복잡한 것입니다. 첫째로 가장 중요한 것은 data의 quality(품질)입니다. quality가 좋다면, 데이터의 양은 많을 수록 좋습니다. 둘째로 필요한 data의 양을 분석하는 이론적인 기법이 있습니다. 그러나 실무에서 사용할 정도로 정형화되어 있지는 않습니다. 실무에서는 경험적 기법들이 있습니다. data와 quality의 관련성의 중요한 표현법의 중의 하나는 Learning curves입니다. Learning curves는 Training data의 양과 Test accuracy의 관계입니다. Training data가 적다면, Test error는 큽니다. 데이터가 추가되어 질수록 Test error는 줄어듭니다. 한계가 있을까요? 데이터를 추가할 수록 Quality가 무한히 좋아지는 않습니다. Test error는 줄어들지만, 0이 될 수는 없습니다. 일반적으로 gap이 존재하는데 이것을 bias라고 부릅니다. 직관적으로 데이터가 infinite 무한하더라도 test error는 0이 되지 않습니다. 복잡한(complex) model일 수록 bias가 적은 경향이 있습니다. 우리가 만든 Sentiment Classifier를 살펴봅시다. 단어를 하나로 분류하는 classifier는 그럭저럭 성능이 나올지도 모릅니다. 그러나 전 세계의 모든 데이터를 훈련시켜도 다음의 문장은 정확히 분류할 수 없습니다. “The sushi was not good.” not good이라는 뜻을 이해하지 못하기 때문입니다. 더 complex model인 word의 조합을 고려하는 bigram(2개의 단어)를 이용해 not good에 대한 weight를 학습합니다. 위의 문장에 대해서는 분류할 것이고 편향은 줄어듭니다. 더 정확해질 것이고, 더 복잡한 n-gram 모델일지라도 bias는 존재합니다. 파란색 Learning Curves는 하나의 단어를 이용하는 unigram classifier 입니다. 빨간색 Learning Curves는 두개의 단어를 이용하는 bigram classifier입니다. 데이터가 적을 때는 성능이 unigram보다 좋지 않은데, 이는 더 많은 parameter를 fit해야 되기 때문입니다. 그러나 data의 양이 많으면, unigram보다 성능이 좋아집니다. 하지만 bigram에도 bias는 존재하게 됩니다. 주어진 입력 x에 대해 Class의 확률에 대해 알아봅시다. Prediction에 대해 얼마나 Confidence(신뢰도) 할 수 있을까요? 예측이 얼마나 확실했는지 알고 싶습니다. “The sushi & everything else were awesome!” 은 확실하게 positive 입니다. “The sushi was good, the service was OK.” 라는 문장은 확실할 수가 없습니다. classifier를 이용해 결과를 positive/negative 뿐만 아니라 얼마나 확실한지 나타낼 수 있습니다. 이 때 confidence 신뢰도를 확률(probabilities)로 나타냅니다. 우리는 확률을 통해 Decision Boundary를 어떻게 선택해야 할지, FN/FP를 어떻게 잡아야할 지 알 수 있습니다.출처 : Coursera / Emily Fox & Carlos Guestrin / Machine Learning Specialization / University of Washington
Create











































'MachineLearning' 카테고리의 다른 글
| Genetic Algorithm 유전알고리즘 - Introduction (0) | 2018.03.23 |
|---|---|
| Incorporating Field-aware Deep Embedding Networks and Gradient Boosting Decision Trees for Music Recommendation (0) | 2018.02.28 |
| Machine Learning - Predicting House Prices : python (0) | 2018.01.30 |
| Machine Learning - Predicting House Prices : Regression (0) | 2018.01.30 |
| Matrix Factorization Techniques for Recommender Systems (1) | 2018.01.04 |