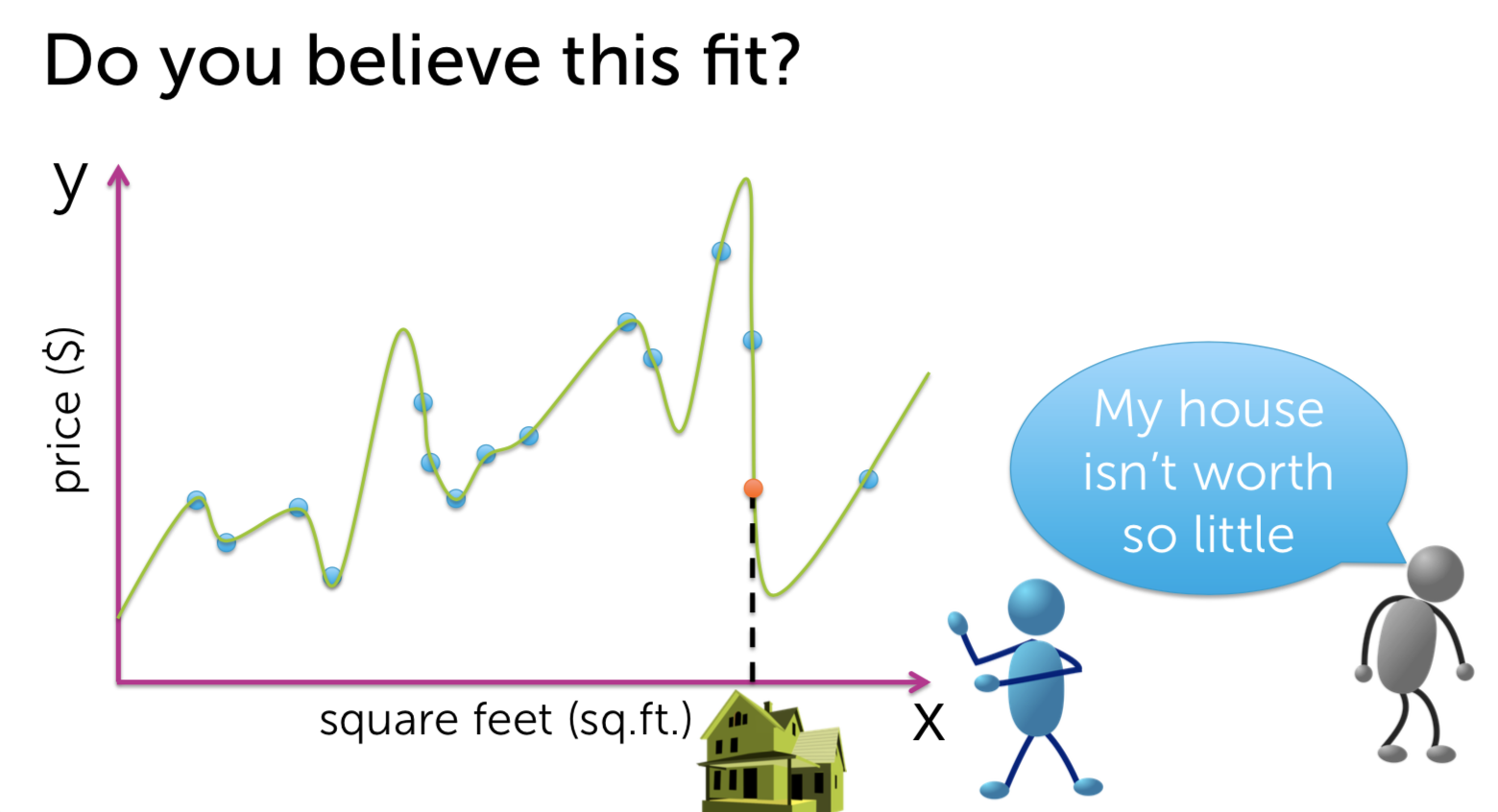
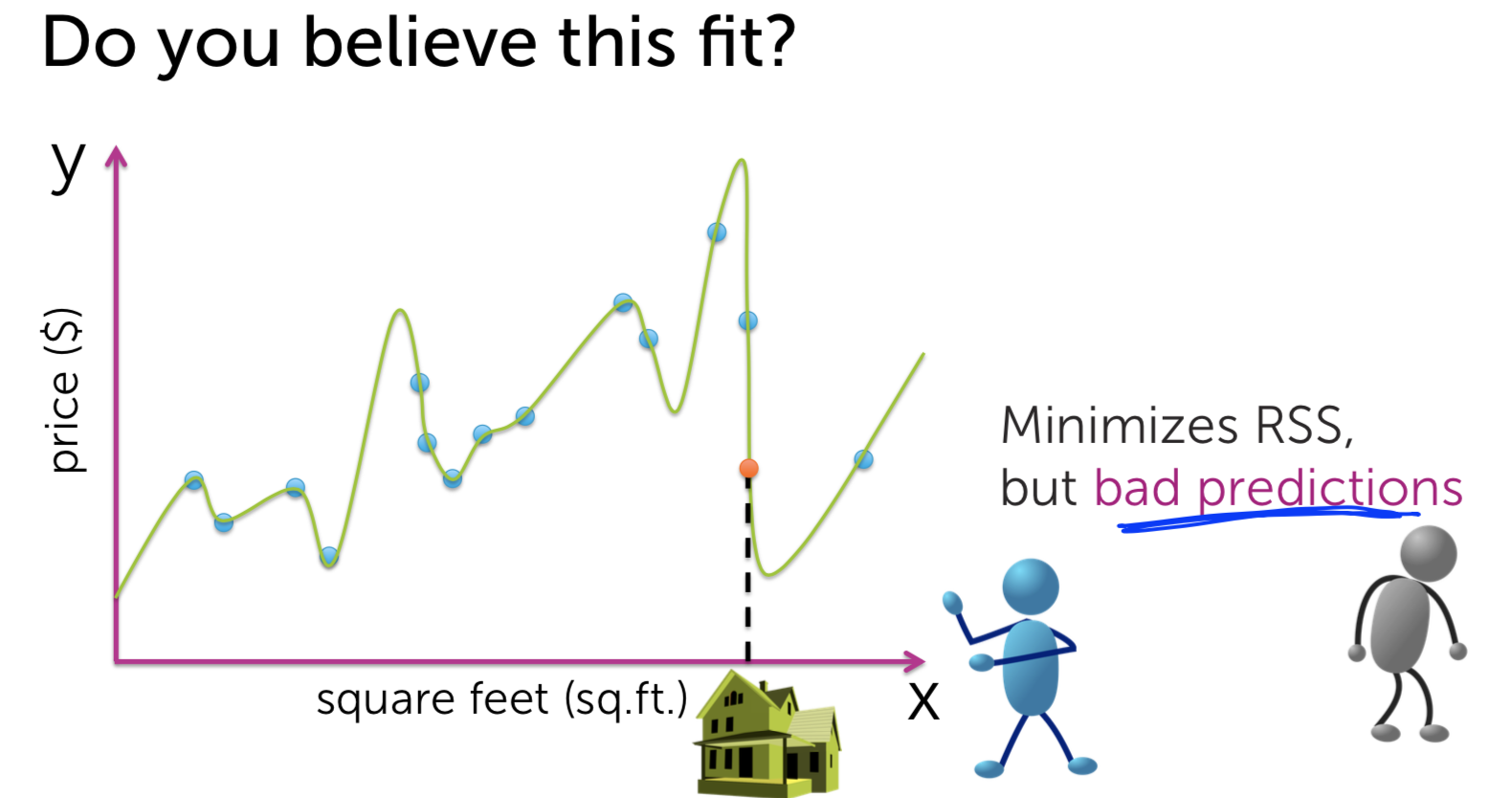
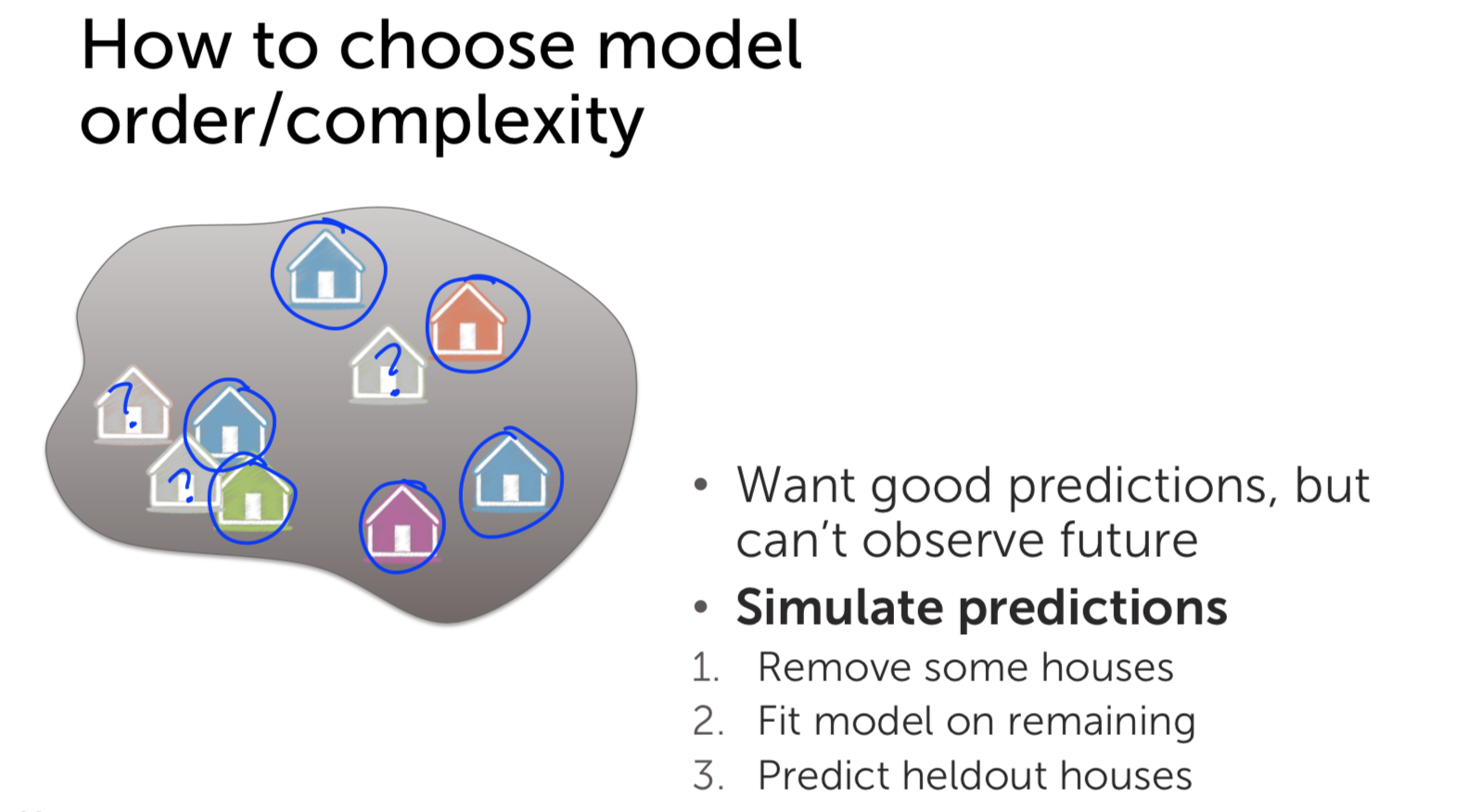
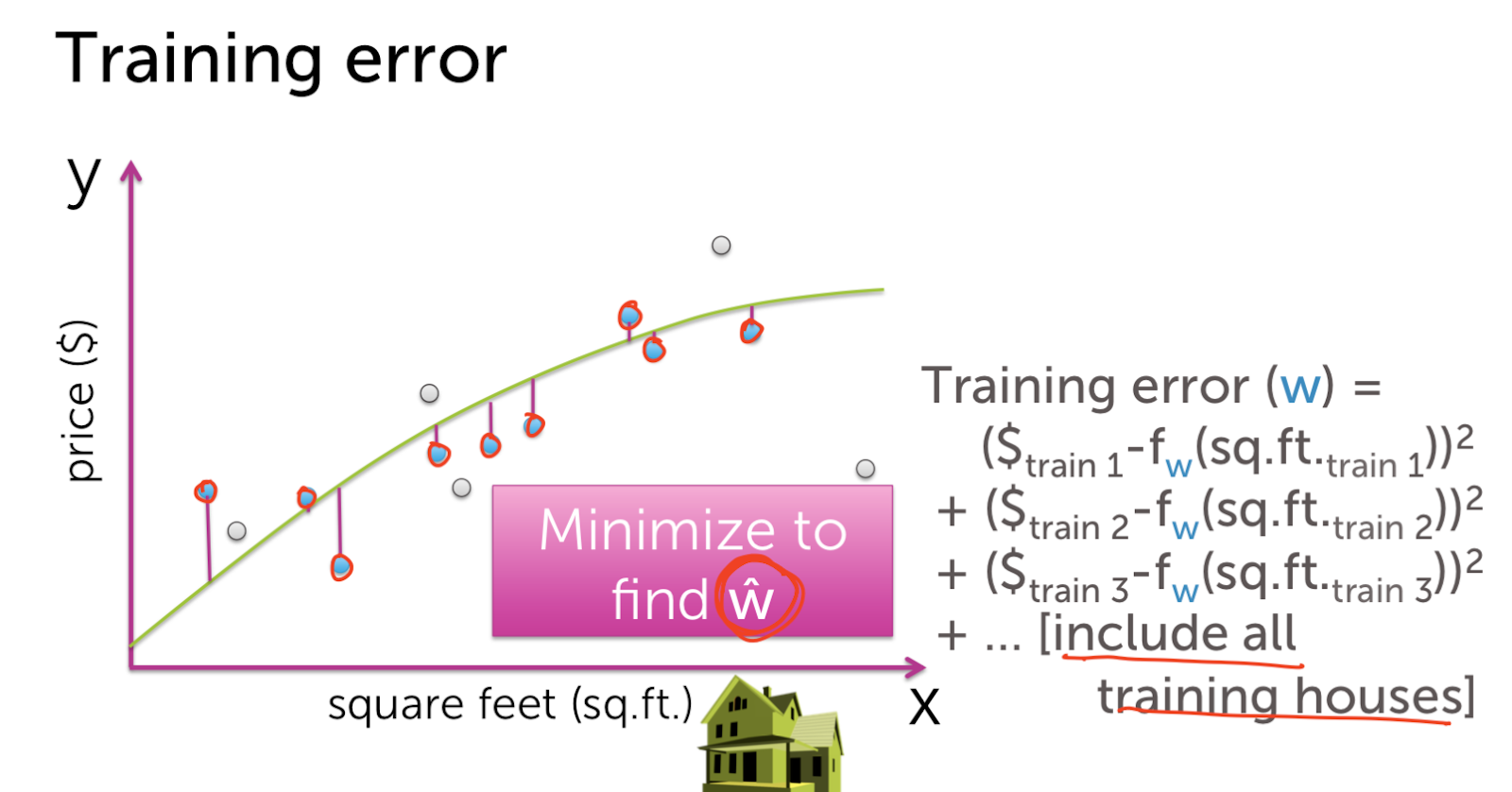
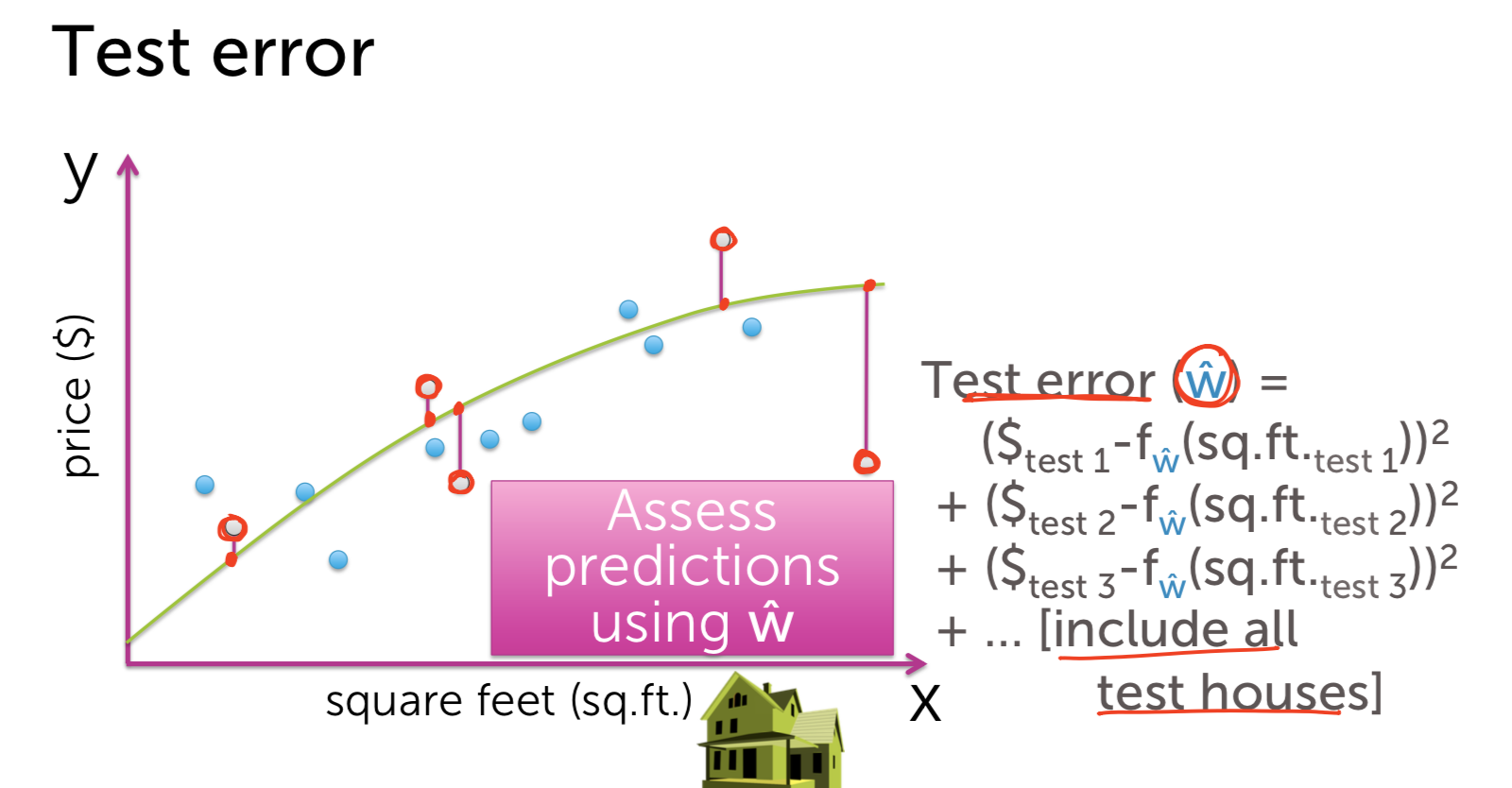
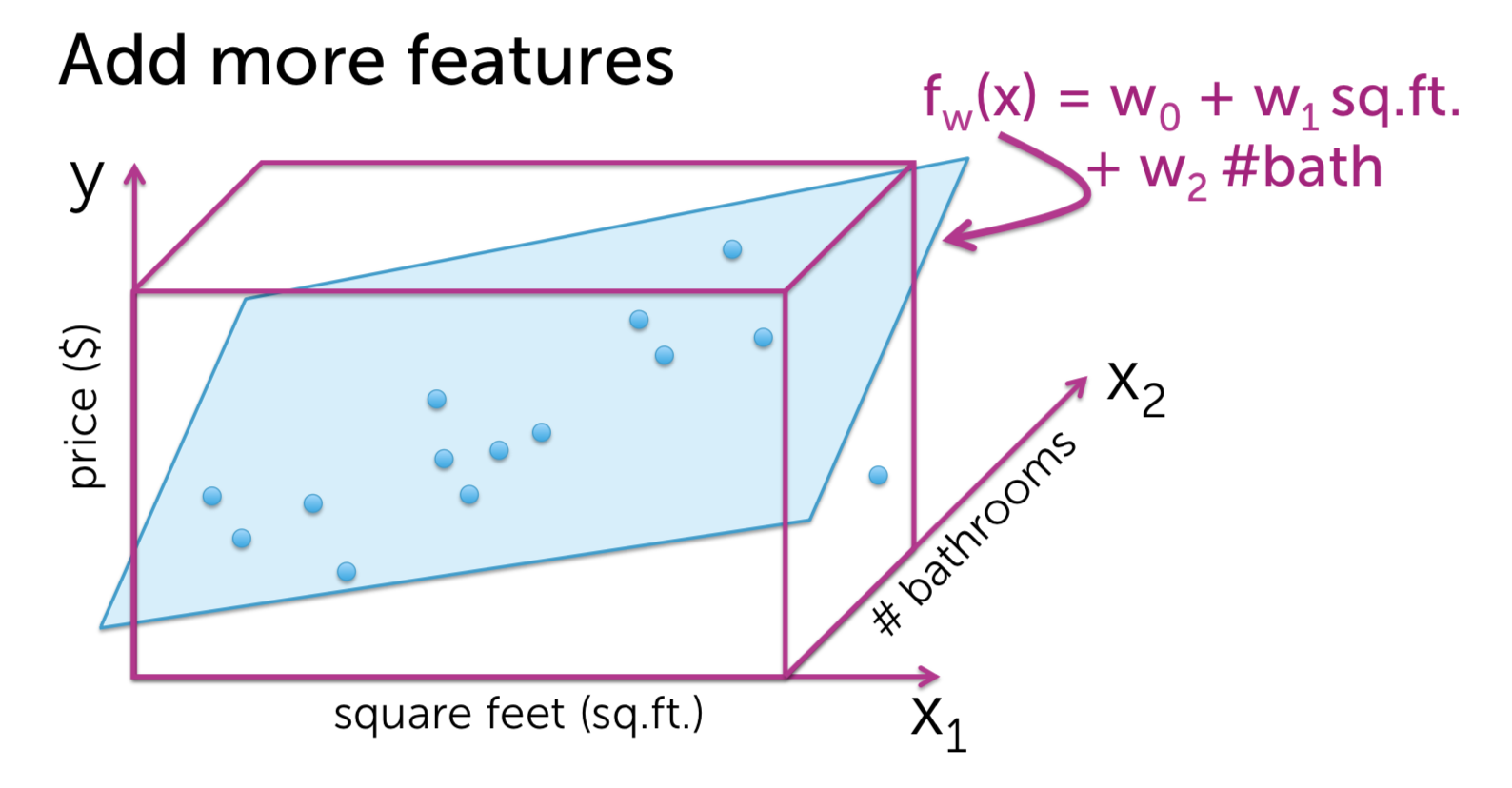
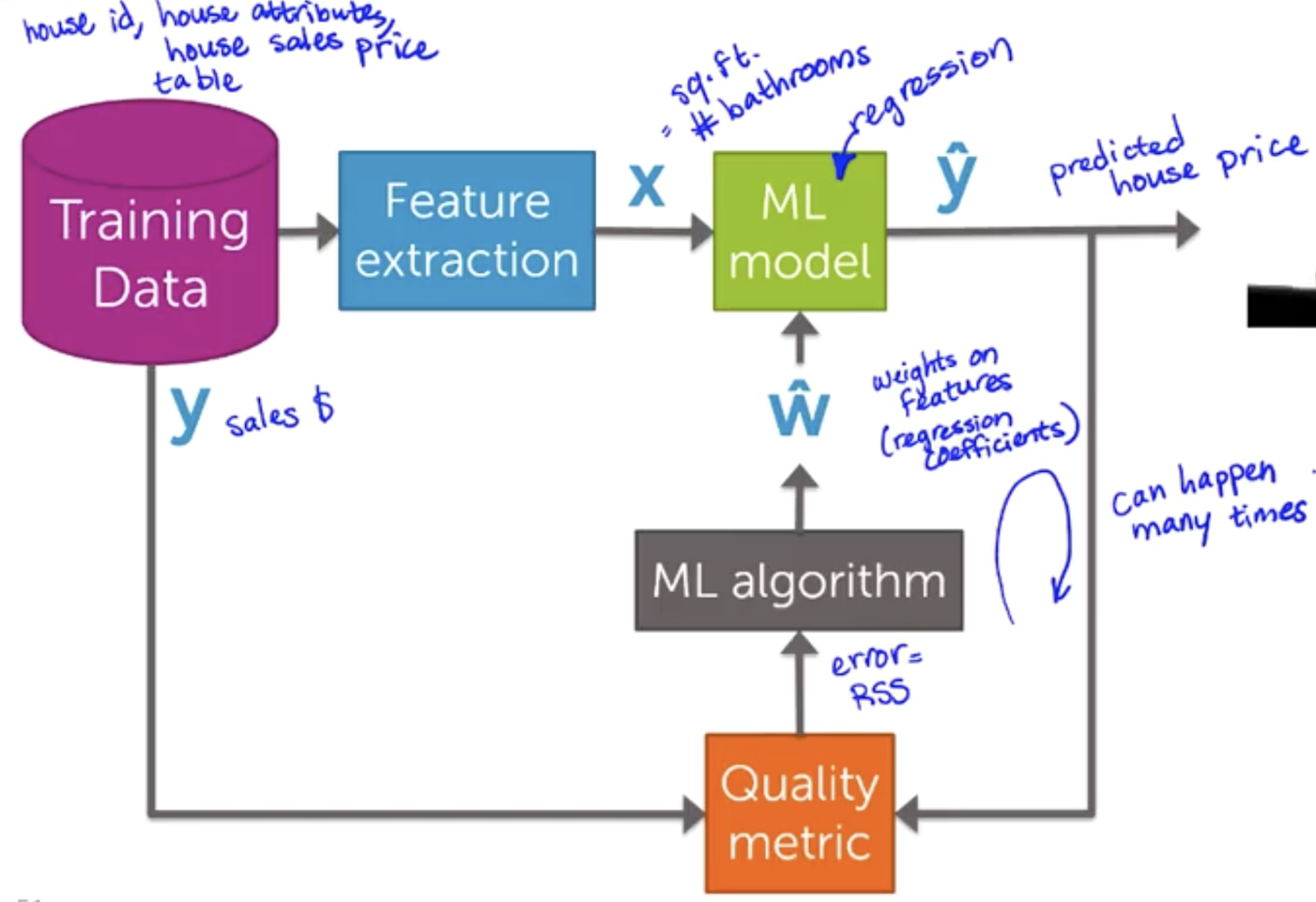
Machine Learning - Predicting House Prices : Regression Machine Learning with the tools IPython Notebook & GraphLab Machine Learning with the tools IPython Notebook & GraphLab Create on AWS Machine Learning with the tools IPython Notebook Usage Machine Learning with the tools IPython Notebook SFrame Regression(회귀) 에 대해서 학습을 합니다. 몇 가지 특징(feature)을 가지고, 특징과 관련된 값이 변화하면서 특징이 변화되는 것을 관측하여 모델링할 것입니다. 그리고 이것을 통해서 집 값을 예측할 것입니다. 집의 특징(feature)로 집의 크기나, 몇 개의 욕실이나 침실을 가지고 있는 지를 통해 집의 매매 가격을 관찰합니다. Regression은 예측(prediction) 작업 뿐만 아니라 분류(classification) 작업도 가능합니다. 예를 들어 메일이 spam인지 아닌지 분류할 수 있습니다. 우리는 regression을 통해 데이터가 가진 feature 들의 중요도(importance)를 분석할 수 있습니다. 집의 가치를 예측하는 문제는 매우 중요한 문제입니다. 미국의 가계 재산은 거의 50%가 부동산에 투자된 것으로 추정됩니다. 이것은 소비자(consumers)나 개인(individuals)이나 정책 입안자(policy makers)에 있어 매우 중요합니다. 우리가 집을 사고 싶어할 때 어떠한 가치로 집의 가치를 평가할까요? 우선 내 이웃(neighborhood)에서 일어난 다른 최근의 판매를 보는 것입니다. 다른 집들은 얼마의 가격(price)에 팔리고 어떻게 생겼는지 주변 지역을 조사합니다. 그리고 최근에 판매 한 것을 기록하는 것입니다. 그리고 판매 된 집의 크기는 얼마인지 확인하여 모든 관찰(observation)을 받아 들이는 것입니다. 미국에서 주택의 크기는 평방 피트(Square feet)로 측정합니다. 그래프의 x축을 평방 피트로 합니다. y축은 집 판매 가격(sales price)이 됩니다. 각 점(point)들은 개별 주택 판매를 나타낸다. 이 x-y 축으로 이루어진 2차원 평면은 자신의 동네에 한 이전의 집 판매들인 것입니다. 여기서 x는 feature(특징), covariate, or predictor(예측 변수) 라고 하며, 경우에 따라 독립 변수(independent variable)라고 한다. y는 observation 또는 response라고 하거나, dependent variable 종속 변수 라고 합니다. 그렇다면 관측치를 사용하여 내가 살 주택을 어떻게 추정할 수 있을까요. 내 집이 얼마나 큰 지를 보고 다른 크기의 주택 판매를 찾아 볼 수 있습니다. 정확히 가격이 일치하는 다른 집은 볼 수 없습니다. 지리학적(geographic)으로 이웃이 아닌, feature인 평방 면적(square footage)으로 이웃을 확인합니다. 특징으로 묶인 이웃이 포함된 좁은 사각형 범위 내의 주택에 대한 모든 주택 판매를 살펴봅니다. 결론은 2개의 집에 대해서만 관찰을 하게 됩니다. 나머지 관찰한 점(observation)들은 버리는 것입니다. 과연 이것은 합리적인 것일까요? 이러한 다른 관찰에 정보가 없다고 생각할 수 없습니다. 우리는 모든 정보를 활용하여 좋은 예측을 내놓아야 합니다. 우리가 방금한 분석 대신에, 주택의 평방 피트 수(square footage)와 주택 판매 가격(house sales price) 간의 관계를 모델링(modeling)을 할 수 있습니다. 이렇게 하면 선형 회귀(Linear Regression)을 사용할 수 있습니다. 주택의 평방 피트와 주택 판매 가격의 관계를 유추할 때 간단한 모델은 데이터를 통해 선을 그리는 것입니다. 여기 데이터에 맞춘(fit) 선이 있습니다. 이 선(line)은 절편 w0(intercept)와 기울기 w1(slope)에 의해 정의됩니다. 종종 w1이 feature x의 가중치(weight) 또는 regression coefficient(회귀 계수)라고 이야기 합니다. 이 가중치(weight)가 해석하는 것은 우리가 집의 평방 피트 x를 변화 시키는 것과 주택 판매의 변화에 얼마나 많은 영향을 미치는 것입니다. 이 w0(intercept)과 w1(slope)이 우리 모델의 매개변수(parameter) 입니다. 이 모델(model)을 명확하게 하기 위해 linear 함수(function)를 사용합니다. fw(x) = w0 + w1*x 로 표현할 수 있다. 여기서 fw(x)의 w 첨자는 (w0, w1) 세트입니다. 여기서의 질문은 이 선(line)이 데이터 세트(data-set)에 올바르고 합당한 선이지 판단하는 것입니다. 우리는 위의 선 말고 다른 선을 대신 그릴 수 있습니다. 그것들 각각은 다른 매개 변수(parameter) 집합 w에 의해 주어집니다. 자 이제 우리는 주어진 선의 비용(cost)에 대해 정의할 수 있습니다. 데이터에 대한 적합성과 관련된 일반적인 cost 계산은 잔여 제곱합(Residual sum of squares = RSS) 입니다. RSS는 x에 대한 실제 데이터값 y와 함수 function의 예측 ^y를 빼고 이 값을 제곱하는 것입니다. RSS를 통해 적합한 선을 취하고 관찰을 합니다. 모델이 예측한 것(prediction)으로 부터 관찰된 값(actual observation)이 얼마나 먼지를 통해 거리(distance)를 알 수 있고, 이것을 residual(잔차, 잔여)라고 합니다. 모든 가능한 line에 RSS(Residual Sum of Squares)를 최소화하는 선을 선택합니다. 이 결과를 ^W 로 표기합니다. 기억해야 할 것은 wo는 intercept이고, w1은 slope 라는 점입니다. 다음에 우리가 평가한 model의 parameter(^wo와 ^w1)를 이용해 나의 집의 가치를 예측할 수 있습니다. 집의 square feet를 함수 ^y에 넣게되면 예측된 가격(price)을 얻을 수 있습니다. 위에서 우리가 예측한(prediction) 집의 가치가 선으로 linear하게 fit 한 것이 적합하지 않을 수도 있습니다. 우리는 이차(quadratic) 함수로 fit 할 수 있습니다. 그렇다면 우리는 다시 RSS(Residual Sum of Squares)를 구할 수 있습니다. 이차(quadratic) 함수는 3개의 parameter를 가집니다. fw(x) = w0 + w1*x + w2*x^2 로 표현되며, intercept인 w0가 있으며, x와 x^2(x의 제곱)의 w1, w2가 있습니다. 우리는 이제 quadratic function으로 data에 fit을 할 것이며, 이른바 이것을 linear regression이라고 합니다. Weight의 3개 parameter를 RSS가 최소화(minimize)하도록 진행합니다. 이번에는 13차 함수(13th order polynomial)를 살펴봅시다. RSS(Residual Sum of Squares)는 0으로 가까워 집니다. 그러나 이러한 함수가 새로운 데이터에 대해서 적당할까요? 나의 집을 13차 함수로 price를 예측(prediction) 한다면, 이전의 2차(quadratic) 함수보다 가치가 없어졌습니다. 과연 어떠한 함수가 reasonable 할까요? 위에서 살펴본 13차 함수(13th order polynomial) 의 fit는 overfitting이라고 합니다. 실제 관측치(actual observation)와 정확히 맞아 떨어지지만, 새로운 예측(prediction)에 대해서는 일반화(generalization)할 수 없습니다. 13차 함수의 fit은 RSS(Residual Sum of Squares)를 최소화하지만, 적절하지 않은 예측(predictions)을 하기 때문에 합당(reasonable)하지 않습니다. 2차 함수(quadratic) fit은 13차 함수보다 RSS가 높지만, 더 적절한 모델(model)이라 생각할 수 있습니다. 우리는 좋은 예측(predictions)을 위해 올바른 모델(model)과 모델의 복잡도(complexity)를 어떻게 선택할 수 있을까요? 그러나 우리는 실제로 미래를 관찰 할 수 없습니다. 실제로 우리가 원하는 예측을 관찰 할 수는 없으며, 실제로 그 때로 가야지만 우리가 잘한 지 알 수 있습니다.. 따라서 모델 선택(model selection)에 대해 생각할 때 어떻게 든 우리는 가지고 있는 데이터만으로 작업해야합니다. 이 경우 좋은 모델을 선택하려고 할 때 어떻게 생각할 수 있을까요? 글쎄요, 우리가 할 수있는 것은 우리가 예측을 시뮬레이션(simulation)하는 것에 대해 생각할 수 있다는 것입니다. 그래서 우리가 가지고있는 데이터 세트를 가져와 집의 일부를 제거 할 것입니다. 그래서 그것들은 회색으로 변한 집들이며, 일시적으로 제거됩니다. 남은 주택에 우리 모델을 맞출 것(fit)입니다. 그래서 이 모든 사람들은 우리가 이전에 말했던 것과 같은 방식을 사용하여 모델에 적합하게 사용할 것입니다. 그리고 우리가 할 일은 모델을 이용해 이전에 지운 data를 예측합니다. 우리는 지운 data를 test로 사용한 것이며, 이 data는 실제 관측치(observed value)와 비교해 모델의 정확도(accuracy)를 판단할 수 있습니다. 모델을 fit하기 위해서 사용된 데이터(집)들은 training set이라고 하며, 모델에 데이터를 넣어 예측하고 관측치에 비교하는 데이터들을 test set이라고 합니다. 우리가 가진 빨간 색 테두리의 파란색 원의 training data를 이용해 Training error를 정의할 수 있습니다. Training data set의 RSS(Residual Sum of Squares)를 계산한 값이 training error 입니다. 우리는 모델의 파라미터(parameter)를 training error를 최소화(minimize)하도록 최적화할 것입니다. 회색의 원은 test set으로 모델을 fit할 때 사용하지 않습니다. 우리의 test-data를 통해 예측값(prediction)과 관측치(observation)의 RSS(Residual Sum of Squares)를 통해 Test error를 정의할 수 있습니다. 모델(model)의 차수(order)를 늘리면(복잡도 complexity 증가), 그 모델은 training-data set의 observation에 더 잘 맞출 수(fit) 있습니다. 즉, 모델의 차수가 증가함에 따라 train-error는 감소한다는 것입니다. 반대로 모델의 차수를 늘리면, est-error는 train dataset에 overfit하게 되며, 새로운 test 데이터에는 일반화될 수 없는 잘못된 예측(prediction)을 하게 되어 test-error가 증가하게 됩니다. 지금까지 우리는 내 집의 가치와 관련된 유일한 특징(feature)은 집의 평방 피트(square feet)라고 가정했습니다. 그러나 데이터 세트를 조금 더 자세히 살펴본 결과, 나는 내 집과 매우 흡사 한 집을 보았습니다. 내 집과 매우 유사한 집의 크기를 가지고 있는 집입니다. 그리고 이 집은 내 집에 대한 예측(prediction)에 분명히 영향을(influence) 미치고 있습니다. 그러나 그 집에는 화장실이 하나 밖에 없다는 것을 알았으며, 화장실이 세 개가 있는 우리 집과 비교할 수 없다는 것을 알았습니다. 그래서 우리가 할 수있는 일은 더 많은 feature 을 추가하는 것입니다. 따라서 평방 피트(square feet)와 가격(price) 간의 관계를 보지 않고 욕실 수(number of bathrooms)를 늘릴 수 있습니다. 데이터 셋에 새로운 feature인 욕실 수를 추가해야 합니다. 이후에 3D 공간에서 각 포인트를 플롯 할 것입니다. 위의 그림은 욕실 수(number of bath)와 가격(price) 대비 평방 피트(square of feet)의 하이퍼 큐브(hypercube)입니다. 이제는 데이터에 선(line)을 맞추는 대신, 공간을 가르는 평면(plane)으로 생각합니다. hyper 평면(plane)의 방정식은 fw(x) = w0 + w1*(sq.ft) + w2*(#bath) 그래서 방정식은 w0을 intercept 로 가집니다. 평면은 y 축을 기준으로 위 아래로 움직이는 곳입니다. 그리고 우리는 평방 피트의 수를 w1, 욕실 수를 w2로 했습니다. 우리가 포함 할 수 있는 많은 특징(feature)들이 있습니다. 우리는 평방 피트, 욕실 수, 침실 수, 주차장 크기, 집이 얼마나 오래 되었는지에 대해 생각할 수 있습니다. 가치 평가에 영향을 미칠 수있는 주택의 특성이 다릅니다. 이것을 해결하고자 우리는 회귀(Regression)에 대해서 배울 것입니다. 우리는 집값을 예측(prediction)하는 작업에 대해 회귀 분석(Regression analysis)을 사용하는 것에 대해 광범위하게 이야기했습니다. 물론 회귀 분석을 사용할 수있는 응용 프로그램의 수는 상당히 많습니다. 몇 가지 예를 들어 설명해 보겠습니다. 자신이 가진 전문 분야에서 받게될 급여를 예측할 수 있습니다. 급여가 얼마나 될지 예측하기 위해서는 전문 분야의 다양한 과정에서의 성과가 어떻게 되는지, 프로젝트의 품질은 어떤지 등 정량적으로 측정해야 합니다. 급여를 예측할 때는 모델 매개 변수 w0, w1, w2 및 w3을 추정하는 것입니다. 회귀(Regression)의 또 다른 적용은 주식 예측(stock prices)을하는 것입니다. 그래서 우리는 내일 주식 가격에 대한 예측이 주가의 최근 역사에 달려 있다는 사실을 생각해 볼 수 있습니다. 그것은 뉴스 이벤트, 세계에서 진행되는 다른 일, 그리고 다른 관련 상품의 가치에 달려 있습니다. 당신이 트위터(Twitter)에 올리면 결국 트윗한 내용을 몇 명이나 리트윗(retweet) 알기를 원합니다. 이것을 예측하기 위해서는 이것은 당신이 얼마나 많은 팔로워(followers)가지고 있는지, 팔로워의 팔로워가 얼마나 많은지, 당신이 트윗한 텍스트의 다른 특징(feature), 포함한 해시 태그(hashtag)의 인기도(popularity), 자신이 가지고있는 트윗의 과거 리트윗(retweet) 수 등. 그리고 이러한 유형의 모델이 실제로 트위터의 리트윗수를 예상하는 데 실제로 도움이 될 수 있습니다. 그리고 또 다른 매우 다른 응용 프로그램은 스마트 하우스(smart house)를 보유하고 있으며, 이 집에는 다양한 센서(sensor)가 있으며, 다른 위치의 온도, 통풍구, 창 블라인드 및 이와 유사한 것들에서 온도 설정과 같이 제어 할 수 있는 많은 것들이 있습니다. 집안의 모든 다른 위치에 온도가 무엇인지를 예측하기 위해 공간 모델을 피팅하는 것이 무엇인지 생각할 수 있습니다. 출처 : Coursera / Emily Fox & Carlos Guestrin / Machine Learning Specialization / University of Washington
CreatePredicting House Prices 집의 가격 예측
Linear Regression 선형 회귀






























'MachineLearning' 카테고리의 다른 글
| Machine Learning - Classification : Analyzing Sentiment (0) | 2018.02.02 |
|---|---|
| Machine Learning - Predicting House Prices : python (0) | 2018.01.30 |
| Matrix Factorization Techniques for Recommender Systems (1) | 2018.01.04 |
| Spark MLlib ALS lastfm dataset (0) | 2017.11.28 |
| Spark Scala Wikipedia dataset (0) | 2017.11.27 |