Matrix Factorization Techniques for Recommender Systems
Yehuda Koren, Yahoo Reserach
Robert Bell and Chris Volinsky, AT&T Labs - Research
ABSTRACT
Netflix Prize 대회에서 Matrix Factorization 모델은 implicit(내재되어 있는) feedback과 temporal effect 그리고, confidence levels 등 추가적인 정보를 사용하면서, 제품을 추천하기 위한 고전적인 Nearest-Neighbor 알고리즘보다 우수합니다.
현대 소비자들은 선택의 폭이 넓습니다. 전자 소매 업체 및 컨텐츠 제공 업체는 다양한 특별 요구 사항 및 취향을 충족시킬 수 있는 전례없는 기회를 제공하여 엄청난 양의 제품을 제공합니다. 소비자를 가장 적합한 제품과 조화시키는 것이 사용자 만족도(satisfaction)와 충성도(loyalty)를 높이는데 중요합니다. 따라서 더 많은 소매 업체는 제품의 사용자 관심 패턴을 분석하여 사용자의 취향(taste)에 맞는 맞춤 권장 사항을 제공하는 추천 시스템에 관심을 갖게되었습니다. 좋은 개인화 맞춤 추천이 사용자 경험(user experience)에 또 다른 차원을 추가할 수 있기 때문에 Amazon.com 및 Netflix와 같은 전자 상거래 리더는 추천 시스템을 웹 사이트의 중요한 부분으로 만들었습니다.
이러한 시스템은 특히 영화, 음악 및 TV 프로그램과 같은 엔터테인먼트 제품에 유용합니다. 많은 고객이 동일한 영화를 볼 것이고 각 고객은 수많은 영화를 볼 것입니다. 고객은 특정 영화에 대한 만족도를 나타내는 것으로 입증되었으므로 어떤 영화가 어떤 고객에게 호소하는지에 대한 방대한 양의 데이터를 이용할 수 있습니다. 회사는 이 데이터를 분석하여 특정 고객에게 영화를 추천 할 수 있습니다.
RECOMMENDER SYSTEM STRATEGIES
대체로 추천 시스템은 두 가지 전략 중 하나를 기반으로합니다. Content Filtering 접근 방식은 각 사용자(user) 또는 제품(product)을 특성화(characterize)하기 위해 프로필(profile)을 만듭니다. 예를 들어, 영화 프로필에는 장르, 참여하는 배우, 흥행 장르와 관련된 속성 등이 포함될 수 있습니다. 사용자 프로필에는 인구 통계학적 정보 또는 적절한 설문지에 제공된 답변이 포함될 수 있습니다. 프로필을 사용하면 프로그램에서 사용자를 일치하는 제품과 연결할 수 있습니다. 물론 Content-based 전략을 사용하려면 수집할 수 없거나 쉽게 수집할 수 없는 외부 정보를 수집해야합니다.
Content Filtering 의 성공적인 실현은 인터넷 라디오 서비스 Pandora.com에 사용되는 Music Genome Project입니다. 숙련된 음악 분석가는 수백 가지의 독특한 음악적 특성을 기반으로 음악 게놈 프로젝트의 각 노래에 점수를 매 깁니다. 이러한 속성(attributes) 또는 유전자는 노래의 음악적 정체성 뿐만 아니라 청취자의 음악적 취향을 이해하는 데 관련된 많은 중요한 자질을 포착합니다.
Content Filtering 대신 명시적인(explicit) 프로필을 만들지 않고, 이전 거래 기록(transaction) 또는 제품 등급(product ratings)과 같은 과거 사용자 행동에만 의존 할 수 있습니다. 이 접근법은 협업 필터링(Collaborative Filtering)으로 알려져 있습니다. 이 용어는 첫 추천 시스템인 Tapestry의 개발자가 만들어 냈습니다. 협업 필터링은 사용자간의 관계와 제품 간의 상호 의존성(interdependencies)을 분석하여 새로운 사용자-항목 연결(user-item associations)을 식별합니다.
Collaborative Filtering의 주요 장점은 도메인(domain)이 없다는 것입니다. 그러나 Content Filtering을 사용하여 파악하기가 어렵고 프로필 작성이 어려운 데이터 측면을 처리할 수 있습니다. 일반적으로 Content-based 기술보다 정확한 반면, Collaborative Filtering은 시스템의 새로운 제품(products) 및 사용자(users)를 처리 할 수 없기 때문에 cold start problem 라고 불립니다. 이 측면에서는 Content Filtering이 우수합니다.
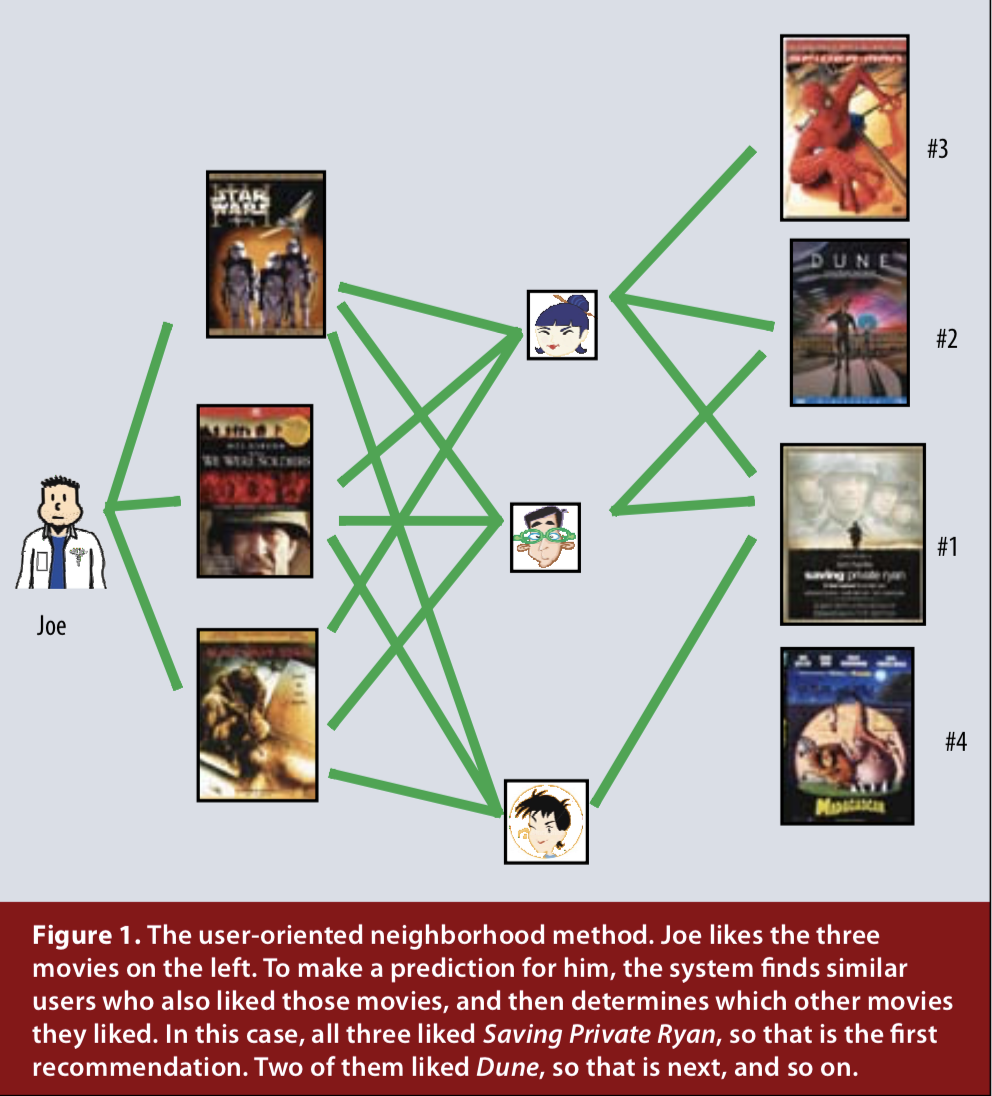
Collaborative Filtering의 주요 두 영역은 인접 방법(neighbor methods) 및 잠재 요인(latent factor) 모델입니다. neighbor methods 방법은 항목간(item) 또는 사용자간(user) 관계를 계산하는데 중점을 둡니다. item-oriented 접근법은 동일한 사용자가 "인접한(neighboring)" 항목의 등급(rating)을 기준으로 항목에 대한 사용자의 선호도(preference)를 평가합니다. 제품의 이웃(neighbors)은 동일한 사용자가 평가할 때 유사한 등급을 얻는 경향이 있는 다른 제품(product)입니다. 예를 들어, Saving Private Ryan 영화를(라이언 일병 구하기) 생각해보십시오. 그 이웃에는 전쟁 영화, 스필버그 영화, 톰 행크스 영화 등이 포함될 수 있습니다. Saving Private Ryan에 대한 특정 사용자의 등급을 예측하려면 이 사용자가 실제로 평가한 가장 가까운 이웃을 찾아야합니다. 그림 1에서 알 수 있듯이 사용자 중심 접근 방식은 서로의 등급을 보완 할 수있는 마음이 맞는 사용자를 식별합니다.
잠재 요인 모델(Latent factor Models)은 등급 패턴(rating pattern)에서 추론된 20-100 가지 요소(factor)에 대해 항목(item)과 사용자(user)를 특성화(하여 등급을 설명하려고하는 대안 방법입니다. 어떤 면에서, 이러한 요소(factor)는 인간이 창조한 노래 유전자에 대한 컴퓨터화 된 대안을 포함합니다. 영화의 경우, 발견된 요소(factor)는 코미디 대 드라마, action의 양 또는 children orientation과 같은 분명한 차원을 측정할 수 있습니다. 인물 개발(character development) 또는 기이함(quirkiness)과 같은 잘 정의되지 않은 차원(dimensions); 또는 완전히 해석할 수 없는(uninterpretable) 차원. 사용자의 경우 각 요인(factor)은 해당 영화 요소에서 점수(score)가 높은 영화를 얼마나 좋아하는지 측정합니다.
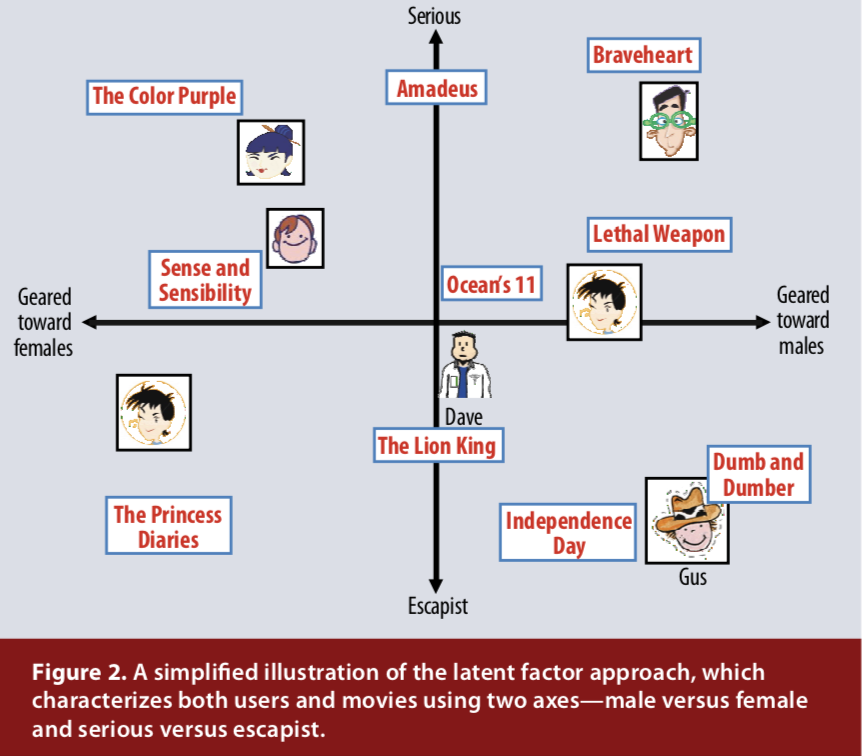
그림 2는 이 아이디어를 2차원의 단순화된 예제로 보여줍니다. 여성 vs 남성 지향적과 심각한(serious) vs 도피주의자(escapist)로 특징 지어지는 두 개의 가정적인 차원을 생각해 보자. 이 그림은 몇 가지 유명한 영화와 몇 가지 가상의 사용자가 이 두 가지 차원에 속할 수 있는 위치를 보여줍니다. 이 모델의 경우 영화에 대한 사용자의 예상 평점(predict rating)은 영화의 평균 평점(average rating)과 비교하여 그래프의 영화 및 사용자 위치의 내적(dot product)과 같습니다. 예를 들어, Gus는 Dumb and Dumber 사랑하고 The Color Purple을 싫어하고, 평균에 대해 Braveheart를 평가할 것으로 기대합니다. 일부 영화(예: Ocean's 11) 및 사용자(예: Dave)는 이 두 가지 차원에서 상당히 중립적인 특성을 갖습니다.
MATRIX FACTORIZATION METHODS
잠재 요인 모델(latent factor models)의 가장 성공적인 실현 중 일부는 Matrix Factorization(행렬 인수분해)를 기반으로합니다. 그것의 기본 형태에서, Matrix Factorization는 항목 등급 패턴(item rating patterns)으로부터 추론된 인자(factor)의 벡터(vector)에 의해 아이템(item)과 사용자(user)를 특징 만듭니다. 아이템과 사용자 요소 간의 높은 일치는 권장 사항으로 이어집니다. 이러한 방법은 예측 정확도(predictive accuracy)와 좋은 확장성(scalability)을 결합하여 최근 몇 년 동안 널리 보급되었습니다. 또한 다양한 실제 상황을 모델링할 때 많은 유연성을 제공합니다.
추천 시스템(Recommender system)은 사용자를 나타내는 차원과 관심있는 항목을 나타내는 차원으로 매트릭스에 배치되는 여러 유형의 입력 데이터에 의존합니다. 가장 편리한 데이터는 사용자가 제품에 대한 관심에 대해 명시적으로 입력(explicit input)하는 고품질의 명시적 피드백(explicit feedback)입니다. 예를 들어, Netflix는 영화의 별표 등급(ratings)을 수집하고, TiVo는 사용자가 엄지 손가락 업 및 아래(thumbs-up and down)로 버튼을 눌러 TV 프로그램에 대한 선호도(preference)를 나타냅니다. 명시적 사용자 피드백(explicit user feedbacks)을 평점(ratings)이라고합니다. 일반적으로 명시적인 피드백(explicit feedback)은 희박한 행렬(sparse matrix)을 구성합니다. 단일 사용자가 가능한 항목의 비율을 낮게 평가할 가능성이 있기 때문입니다.
Matrix Factorization의 장점은 추가 정보(information)의 통합(incorporation)을 허용한다는 것입니다. 명시적 피드백(Explicit feedback)을 사용할 수 없는 경우 추천 시스템은 구매 내역, 검색 기록, 검색 패턴 또는 마우스 이동을 포함한 사용자 행동을 관찰하여 의견을 간접적으로 반영하는 암시적 피드백(Implicit feedback)을 사용하여 사용자 환경 설정을 유추 할 수 있습니다. 암시적 피드백(Implicit Feedback)은 대개 이벤트의 존재 또는 부재를 나타내므로 일반적으로 밀도가 높은 행렬(Dense matrix)로 표시됩니다.
A BASIC MATRIX FACTORIZATION MODEL
Matrix Factorization 모델은 사용자와 아이템을 차원(dimensionality) f의 공동 잠재요인(latent factor) 공간으로 매핑하여, 사용자-아이템 상호 작용(user-item interaction)을 해당 공간에서 내적(inner product)으로 모델링합니다. 따라서, 각 아이템 i는 벡터 qiℝf 와 연관되며, 각 사용자 u는 벡터 puℝf와 연관 됩니다. 주어진 아이템 i에 대해 qi의 element는 item이 양수 또는 음수인 요소(factor)를 어느 정도 보유하고 있는지를 측정합니다. 주어진 사용자 u에 대해 pu의 element는 양수와 음수를 통해 해당 factor에서 높은 item에 대해 사용자가 갖는 관심의 정도를 측정합니다. 내적 값의 결과 qiTpu는 사용자 u와 아이템 i 사이의 상호 작용(interaction), 즉 아이템의 특성(characteristics)에 대한 사용자의 전반적인 관심(interest)을 포착합니다. 이 값은 사용자 i의 평점(rations)한 아이템 i와 유사하며 rui로 표시되며, 다음과 같이 평가됩니다.

주요한 난제는 각 아이템과 사용자의 요소(factor) 벡터(vector) qi,puℝf 에 대한 맵핑(mapping)을 계산하는 것입니다. 추천 시스템이 이 맵핑(mapping)을 완료한 후, 방정식 1을 사용하여 사용자(user)가 어떤 아이템에 부여할 등급(rating)을 쉽게 추정할 수 있습니다.
이러한 모델은 정보 검색(information retrieval)에서 잠재 의미론적 요소(latent semantic factor)를 식별하기위한 잘 확립된 기법인 Singular Value Decomposition(SVD)와 밀접하게 관련되어 있습니다. Collaborative Filtering 도메인에 SVD를 적용하려면 사용자-아이템 평가(user-item rating) 매트릭스(matrix)를 인수분해(factoring) 해야 합니다. 이는 종종 사용자 항목 평가 매트릭스에서 희소성(sparseness)으로 인해 손실된 값(missing value)이 많아서 어려움이 생깁니다. 행렬(matrix)에 대한 지식이 불완전한 경우 기존 SVD는 정의되지 않습니다. 더욱이, 비교적 적은 수의 알려진 entry만을 부주의하게 처리하는 것은 overfitting하기 쉽습니다.
이전 시스템은 대치(imputation)에 의존하여 누락된 등급(missing ratings)을 채우고 등급 매트릭스(rating matrix)를 조밀하게(dense) 만듭니다. 그러나 데이터 양이 크게 늘어남에 따라 대체 비용이 매우 높을 수 있습니다. 또한, 부정확한(inaccurate) 대치(imputation)는 데이터를 상당히 왜곡시킬 수 있습니다. 따라서보다 최근의 연구에서는 정규화 된(regularized) 모델을 통해 overfitting을 피하면서 관측된 등급만 직접 모델링하는 것이 좋습니다. 요소 벡터 (factor vector: pu and qi)를 학습하기 위해, 시스템은 알려진 등급 세트에 대한 정규화 제곱 오차(Regularized Squared Error)를 최소화합니다:

여기서, k는 rui가 알려진 (u, i) 쌍의 training set입니다.
시스템은 이전에 관찰된 등급(ratings)에 맞추어 모델을 학습합니다. 그러나 목표는 미래의 알려지지 않은 등급을 예측하는(predict) 방식으로 이전의 등급을 일반화하는 것입니다. 따라서, 시스템은 그 규모가 제한을 받는(penalized) 학습된 매개 변수(parameters)를 정규화함으로써 관측된 데이터를 overfitting을 방지해야합니다. 상수 λ는 정규화의 범위를 제어하며, 대개 교차 유효성 검사(Cross-Validation)에 의해 결정됩니다. Ruslan Salakhutdinov와 Andriy Mnih의 "Probabilistic Matrix Factorization"은 정규화를 위한 확률론적 토대를 제공합니다.
LEARNING ALGORITHMS
식 2를 최소화하는 두 가지 접근법은 Stochastic Gradient Descent(SGD)와 Alternating Least Squares(ALS)입니다.
Stochastic Gradient Descent
Simon Funk는 방정식 2 (http://sifter.org/~simon/journal/20061211.html)의 SGD(확률적 그래디언트 강하) 최적화(Optimization)를 대중화하였으며, 여기서 알고리즘은 training set의 모든 등급(rating)을 반복합니다. 각각의 주어진 training 경우에 대해, 시스템은 rui를 예측하고 연관된 예측 오차(prediction error)를 계산합니다.

그런 다음 그라디언트의 반대 방향으로 에 비례하는 크기로 매개 변수(parameter)를 수정하여 다음을 산출합니다.

이 인기있는 접근법은 구현이 쉽고 상대적으로 빠른 실행 시간을 제공합니다. 그러나 어떤 경우에는 ALS 최적화를 사용하는 것이 좋습니다.
Alternating Least Squares
pu, qi 둘 다 알려지지 않은 값이기(unknown) 때문에, 방정식 2는 볼록하지(convex) 않습니다. 그러나 미지수(unknowns) 중 하나를 수정한다면, 최적화(optimization) 문제는 2차(quadratic)로 되어 최적으로 해결할 수 있습니다. 따라서 ALS 기법은 qi를 고정하고 pu를 고정하는 사이에서 회전합니다. 모든 pu가 고정되면, 시스템은 최소 제곱 문제(least-squares)를 푸는 것에 의해 재계산하고(recompute), 그 반대의 경우도 마찬가지입니다. 이렇게하면 각 단계가 수렴(convergence)될 때까지 식 2가 감소합니다.
SGD가 ALS보다 쉽고 빠르지만, ALS는 적어도 두 가지 경우에 유리합니다. 첫 번째는 시스템이 병렬 처리(parallelization)를 사용할 수 있는 경우 입니다. ALS에서 시스템은 다른 아이템 요인(factor)과 독립적으로(independently) 각 qi를 계산하고 다른 사용자 요인과 독립적으로 각 pu를 계산합니다. 이것은 알고리즘의 대규모 병렬화를 야기합니다. 두 번째 경우는 암시적(implicit) 데이터를 중심으로 하는 시스템을 위한 것입니다. training set는 희소성(sparse)이 낮은 것으로 간주 될 수 없기 때문에, Gradient descent처럼 각 단일 training case를 반복하면 실용적이지 않습니다. ALS는 이러한 경우를 효율적으로 처리 할 수 있습니다.
ADDING BIASES
Collaborative Filtering에 대한 Matrix Factorization 접근법의 한 가지 이점은 다양한 데이터 측면 및 기타 애플리케이션 별 요구 사항을 처리 할 수 있는 유연성(flexibility)입니다. 이것은 동일한 학습 framework 내에서 방정식 1에 대한 조정을 요구합니다. 방정식 1은 서로 다른 등급(rating) 값을 산출하는 사용자와 아이템 간의 상호 작용(interaction)을 포착합니다. 그러나 관찰된 등급 값의 편차(variation)는 상호 작용과 관계없이 편향(bias) 또는 절편(intercept)으로 알려진 사용자 또는 아이템과 관련된 영향으로 인한 것입니다. 예를 들어, 일반적인 Collaborative Filtering 데이터는 일부 사용자가 다른 사용자보다 높은 등급을 부여하고 일부 아이템이 다른 사용자보다 높은 등급을 받는 큰 체계적인(systematic) 경향(tendency)을 나타냅니다. 결국, 일부 제품은 다른 제품보다 더 좋게(또는 나쁘게) 인식됩니다.
따라서 형식 qiTpu의 상호 작용(interaction)에 의해 전체 등급 값을 설명하는 것은 현명하지 않을 수 있습니다. 대신 시스템은 개별 사용자 또는 아이템 bias가 설명 할 수 있는 값의 일부를 식별하여 데이터의 정확한 상호 작용 부분만 요인 모델링(factor modeling)에 적용합니다. 등급 rui에 포함된 bias의 1차 근사(approximation)는 다음과 같습니다.

rui 등급과 관련된 편향(bias)은 bui로 표시되며 사용자 및 아이템 효과를 설명합니다. 전반적인 평균 등급은 μ로 표시됩니다. 파라미터 bu 및 bi는 평균(average)으로부터 각각 사용자 u 및 아이템 i의 관측된 표준 편차(deviations)를 나타냅다. 예를 들어, 타이타닉 영화의 사용자 Joe 등급에 대한 1차 예상치를 원한다고 가정해봅시다. 이제 모든 영화에 대한 평균 평점 μ는 3.7 등급입니다. 또한 타이타닉 영화는 평균 영화보다 낫기 때문에 평균 이상으로 0.5 등급을 얻는 경향이 있습니다. 반면에 Joe는 평균 사용자보다 0.3 등급 낮은 경향이 있는 중요한 사용자입니다. 따라서 Joe의 Titanic 등급 평가는 3.9 등급 (3.7 + 0.5 - 0.3)입니다. bias는 다음과 같이 수식 1을 확장합니다.

여기서 관찰된 등급(rating)은 전역 평균(global average), 아이템 bias, 사용자 bias 및 사용자-아이템 상호 작용(interaction)의 네 가지 구성 요소로 나뉩니다. 이를 통해 각 구성 요소는 해당 구성 요소와 관련된 신호(signal)의 일부만 설명 할 수 있습니다. 시스템은 제곱 오차 함수(squared error function)을 최소화하여 학습합니다.

bias는 관찰된 신호의 대부분을 캡쳐하는 경향이 있으므로, 정확한 모델링이 중요합니다. 따라서 다른 모델보다 정교한 bias 모델을 제공합니다.
ADDITIONAL INPUT SOURCES
종종 시스템은 cold-start problem을 처리해야 하며, 많은 사용자가 매우 적은 수의 등급을 제공하기 때문에 자신의 취향에 대한 일반적인 결론에 도달하기가 어렵습니다. 이 문제를 해결하는 방법은 사용자에 대한 추가 정보 소스를 통합하는 것(incorporate)입니다. 추천 시스템(Recommender systems)은 implicit feedback을 사용하여 사용자 선호(preference)에 대한 통찰력을 얻을 수 있습니다. 사실, 사용자는 명시적(explicit) 등급을 제공하려는 사용자의 의지와 상관없이 행동 정보를 수집 할 수 있습니다. 소매 업체는 고객의 구매 또는 검색 기록을 사용하여 고객이 제공 할 수 있는 등급(ratings) 외에도 자신의 경향을 파악할 수 있습니다.
단순화를 위해 Boolean Implicit Feedback이 있는 경우를 생각해보십시오. N(u)는 사용자 u가 implicit preferences를 표현한 아이템의 집합을 나타냅니다. 이렇게 하면 시스템은 암시적으로 선호하는 항목을 통해 사용자를 프로파일합니다. 여기서 아이템 요인(factor)의 새로운 세트가 필요합니다. 아이템 i는 xiℝf 와 연관됩니다. 따라서, N(u)에서 아이템에 대한 선호도(preference)를 보여준 사용자(user)는 벡터(vector)로 특징화됩니다.

이 합을 정규화(normalizing) 하는 것은 종종 유익합니다. 예를 들어 다음과 같이

또 다른 정보 소스는 알려진 사용자 속성 (예 : 인구 통계)입니다. 다시 말하지만, 단순화(simplicity)를 위해 사용자 u가 성별, 연령 그룹, 우편 번호, 소득 수준 등을 설명할 수있는 속성(attribute) 집합 A(u)에 해당하는 Boolean 특성을 고려해야 합니다. 구분을 지을 수 있는 요소 벡터(factor vector) yaℝf는 사용자와 연관된 속성(attribute) 집합을 통해 사용자 a를 설명하는 각 속성에 해당합니다.
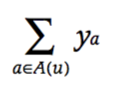
Matrix Factorization 모델은 모든 신호 소스(signal sources)를 통합하여, 다음의 강화된 사용자 표현을 합니다.

앞의 예제는 데이터가 부족할 경우에 사용자 표현을 향상시키는데 사용되었으나, 필요할 때 비슷하게 아이템에 처리할 수 있습니다.
TEMPORAL DYNAMICS
지금까지 제시된 모델은 정적이었습니다. 실제로 새로운 선택(selection)이 등장함에 따라 제품 인식(perception)과 인기(popularity)가 끊임없이 변화합니다. 마찬가지로 고객의 성향(inclination)도 진화하여 취향을 재정의하게됩니다. 따라서, 시스템은 사용자-항목 상호 작용(interaction)의 동적인 시간 이동 특성(time-drifting nature)을 반영하는 시간 효과(temporal effect)를 설명해야한다.
Matrix Factorization은 temporal effect를 모델링하는 데 적합하므로 정확도(accuarcy)를 크게 향상시킬 수 있습니다. 등급을 별개의 용어로 분해하면 시스템이 서로 다른 시간적 측면(temporal aspect)을 개별적으로 처리 할 수 있습니다. 특히, 다음 용어는 시간에 따라 변한다 : 아이템 bias, bi(t); 사용자 bias, bu(t); 및 사용자 선호도, pu(t).
첫 번째 temporal effect는 아이템의 인기가 시간이 지남에 따라 변할 수 있다는 사실을 나타냅니다. 예를 들어, 영화는 새로운 영화에서 배우의 출연과 같은 외부 이벤트에 의해 트리거되어 인기를 얻거나 벗어날 수 있습니다. 그러므로,이 모델들은 아이템 bias bi를 시간의 함수로 취급합니다. 두 번째 temporal effect는 사용자가 시간 경과에 따라 기준선(baseline) 등급을 변경할 수 있게 합니다. 예를 들어, 평균 영화 "4 starts"을 평가하는 경향이 있는 사용자는 이제 그러한 영화를 "3 stars"로 평가할 수 있습니다. 이는 사용자의 등급 척도에서의 자연스러운 표류(압력), 사용자가 다른 최근 등급에 관련이 있는 등급을 지정한다는 사실, 주택 보유자 내의 정체감이 시간이 지남에 따라 변할 수 있다는 사실을 알 수 있습니다. 따라서, 이들 모델에서, 파라미터 bu는 시간의 함수이다.
시간적 역동성(Temporal dynamics)은 이것을 뛰어넘는다. 사용자 선호도(preference) 및 사용자(user)와 아이템(item)간의 상호작용(interaction)에도 영향을 줍니다. 사용자는 시간이 지남에 따라 선호도(preference)를 변경합니다. 예를 들어, 심리적 스릴러(psychological thrillers) 장르의 팬은 1년 후 범죄 드라마(crime dramas) 팬이 될 수 있습니다. 마찬가지로 인간도 특정 배우(actors)와 감독(directors)에 대한 인식을 변화시킵니다. 이 모델은 사용자 요소 (vector pu)를 시간의 함수로 취하여 효과(effect)를 설명합니다. 반면에 사람과 달리 아이템은 본질적으로 정적(static)이기 때문에 정적 아이템 특성 인 qi)를 지정합니다.
시간에 따라 변하는 매개 변수의 정확한 parameter은 시간 t 에서의 등급(ratings)에 대한 동적 예측(dynamic prediction) 규칙으로 식 4를 대체합니다.

INPUTS WITH VARYING CONFIDENCE LEVELS
몇 가지 설정에서 모든 관측된 등급(rating)이 동일한 가중치(weight) 또는 신뢰도(confidence)를 가질 자격이 없습니다. 예를 들어, 대규모 광고는 특정 아이템(item)의 투표(vote)에 영향을 미칠 수 있으며, 장기적인 특성을 적절하게 반영하지 못합니다. 마찬가지로 시스템이 특정 아이템의 등급을 기울이려고 하는 적대적인 사용자에게 직면 할 수도 있습니다.
또 다른 예는 implicit feedback 에 구축된 시스템입니다. 진행 중인 사용자(user) 행동을 해석하는 시스템에서 사용자의 정확한 선호도(preference) 수준은 정량화하기 어렵습니다. 따라서 시스템은 "제품을 좋아할 것"또는 "제품에 관심이 없을 것"이라고 말하는 더 까다로운 2진(binary) 표현으로 작업합니다. 이러한 경우 예상된 선호도에 신뢰도(confidence) 점수를 부가하는 것이 중요합니다. 사용자가 특정 프로그램을 시청한 시간이나 사용자가 특정 아이템을 구입 한 빈도와 같이 행동 빈도를 설명하는 사용 가능한 수치를 통해 신뢰도(confidence)을 얻을 수 있습니다. 이 수치는 각 관찰의 신뢰도를 나타냅니다. 사용자 신뢰도(confidence)와 아무런 관련이 없는 다양한 요소(factor)가 일회성 이벤트를 유발할 수 있습니다. 그러나 되풀이되는(recurring) 이벤트는 사용자의 의견을 반영할 가능성이 큽니다.
Matrix Factorization(행렬 인수 분해) 모델은 다양한 신뢰 수준(confidence level)을 쉽게 받아 들일 수 있으므로 덜 의미있는 관측(observation)에는 더 적은 가중치(weight)를 부여합니다. rui 를 관찰하는 것에 대한 확신이 cui 로 표시된다면, 모델은 다음과 같이 신뢰도를 설명하기 위해 비용 함수(cost function) (식 5)를 향상시킵니다.

이러한 스키마(scheme)가 포함된 실제 응용 프로그램에 대한 자세한 내용은 "Collaborative Filtering for Implicit Feedback Datasets"을 참조하세요.
Y.F. Hu, Y. Koren, and C. Volinsky, “Collaborative Filtering for Implicit Feedback Datasets,” Proc. IEEE Int’l Conf. Data Mining (ICDM 08), IEEE CS Press, 2008, pp. 263-272.
NETFLIX PRIZE COMPETITION
2006 년 온라인 DVD 대여 회사인 Netflix는 추천 시스템의(recommender system) 상태를 개선하기 위한 경진대회(contest)를 발표했습니다. 이것을 가능하게 하기위해 이 회사는 익명의 고객 약 50 만 명과 1만 5천 개 이상의 영화에 등급(ratings)을 매기는 1 억 개 이상의 training-set을 발표했습니다. 각 영화의 등급은 1~5 입니다. 참여 팀은 약 300 만 개 등급의 test-set에 대한 예상(predict) 등급을 제출하고 Netflix는 파악된 truth(label)을 기반으로 RMSE (Root-Mean-Square Error)를 계산합니다. Netflix 알고리즘의 RMSE 성능을 10 % 이상 향상시킬 수있는 첫 번째 팀은 1 백만 달러의 상금을 수여합니다. 어떤 팀도 10% 목표에 도달하지 못하면 Netflix는 각 경쟁 후 첫 번째로 팀에 5만 달러의 Progress Prize를 제공합니다.
경진대회(contest)는 Collaborative Filtering(협업 필터링) 필드에서 본격적인 탄력을 주었습니다. 이 시점까지는 협업 필터링 연구를 위해 공개적으로 사용할 수 있는 유일한 데이터는 훨씬 작은 규모였습니다. 이 데이터의 공개와 경쟁의 매력으로 인해 에너지와 활동이 폭발적으로 증가했습니다. 경진대회 웹 사이트 (www.netflixprize.com)에 따르면 182 개국 48,000 개 팀이 데이터를 다운로드했습니다.
원래 BellKor라고 불렸던 우리 팀의 항목은 2007 년 여름 경쟁에서 1위 자리를 차지했으며 당시 최고 점수 인 2007 Progress Prize에서 Netflix보다 8.43 % 우수했습니다. 나중에 우리는 Big Chaos 팀과 함께 2008 Progress Prize에서 9.46 %의 점수를 받았습니다. 이 글을 쓰는 시점에서 우리는 여전히 10 %의 랜드 마크로 도약하고 있습니다.
우리의 우승 항목은 100가지가 넘는 다양한 예측 변수 세트(predictor set)로 구성되며, 대부분이 여기에 설명된 방법의 변형을 사용하는 Factorization Models(인수 분해) 모델입니다. 다른 상위 팀과 토론하고 공개 콘테스트 포럼에 게시하면 등급 예측(ratings prediction)을 위한 가장 인기 있고 성공적인 방법임을 알 수 있습니다.
Netflix 사용자-영화(user-movie) matrix를 고려하면 영화 선호도(preference)를 예측하는 데 가장 묘사적인 차원(descriptive dimensions)을 발견 할 수 있습니다. 우리는 매트릭스 분해(Matrix Decomposition)로부터 처음 몇 가지 중요한 차원(dimensions)을 식별하고 이 새로운 공간에서 영화의 위치를 탐색 할 수 있습니다. 그림 3은 Netflix 데이터 Matrix Factorization(행렬 인수 분해)의 처음 두 요소를 보여줍니다. 영화는 요인 벡터(factor vectors)에 따라 배치됩니다. 영화에 익숙한 사람은 잠재 요소(latent factor)에서 명확한 의미를 볼 수 있습니다. 첫 번째 요소 벡터 (x 축)에서 왼쪽으로는 남성 또는 청소년 청중 (Half Baked, Freddy vs. Jason)을 겨냥한 저조한 코미디와 공포 영화를 가지고 있으며, 반대편 오른쪽에는 강한 여성의 드라마 또는 코미디가 포함되어 있습니다.(Sophie 's Choice, Moonstruck). 두 번째 인수 분해 축 (y 축)은 주류 정식 영화 (아마겟돈, 런 어웨이 브라이드)의 상단과 하단에 독립적이고 비판적으로 호소력있는 기발한 영화(Punch-Drunk Love, I Heart Huckabees)를 가지고 있습니다. 이 경계선들 사이에는 흥미로운 교차점이 있습니다. 왼쪽 상단에는 인디가 낮은 혈통을 만나는 곳으로 킬 빌 (Kill Bill)과 내츄럴 보른 킬러 (Natural Born Killers)가 있습니다. 오른쪽 아래에는 여성 중심의 영화가 주류 군중을 즐겁게하는 것인 The Sound of Music이 있습니다. 중간에 헤매고, 모든 유형에 호소하는 것은 The Wizard of Oz입니다.

이 그림에서 서로 인접한 일부 영화는 일반적으로 결합되지 않습니다. 예를 들어 Annie Hall과 Citizen Kane은 서로 옆에 있습니다. 그들은 스타일론적으로 매우 다르지만, 유명 감독들로부터 높은 평가를 얻은 고전 영화와 공통점이 많습니다. 사실, 인수 분해의 세 번째 차원은이 둘을 분리하게 만듭니다.
우리는 Factorization(인수 분해)를 위해 여러 가지 구현과 매개 변수화(parameterization)를 시도했습니다. 그림 4는 RMSE에 영향을 미치는 모델과 매개 변수의 수와 implicit feedback(암시적 피드백)이 있는 사용자 프로필 향상, 시간 구성 요소를 추가하는 두 가지 변종 등의 분석의 진화하는 구현 성능을 보여줍니다. 각 요인 모델의 정확성은 관련된 매개 변수의 수를 늘림으로써 향상됩니다. 이는 요인 모델(factor model)의 차원(dimensionality)을 증가시키는 것과 같습니다 (차트의 숫자로 표시됨).
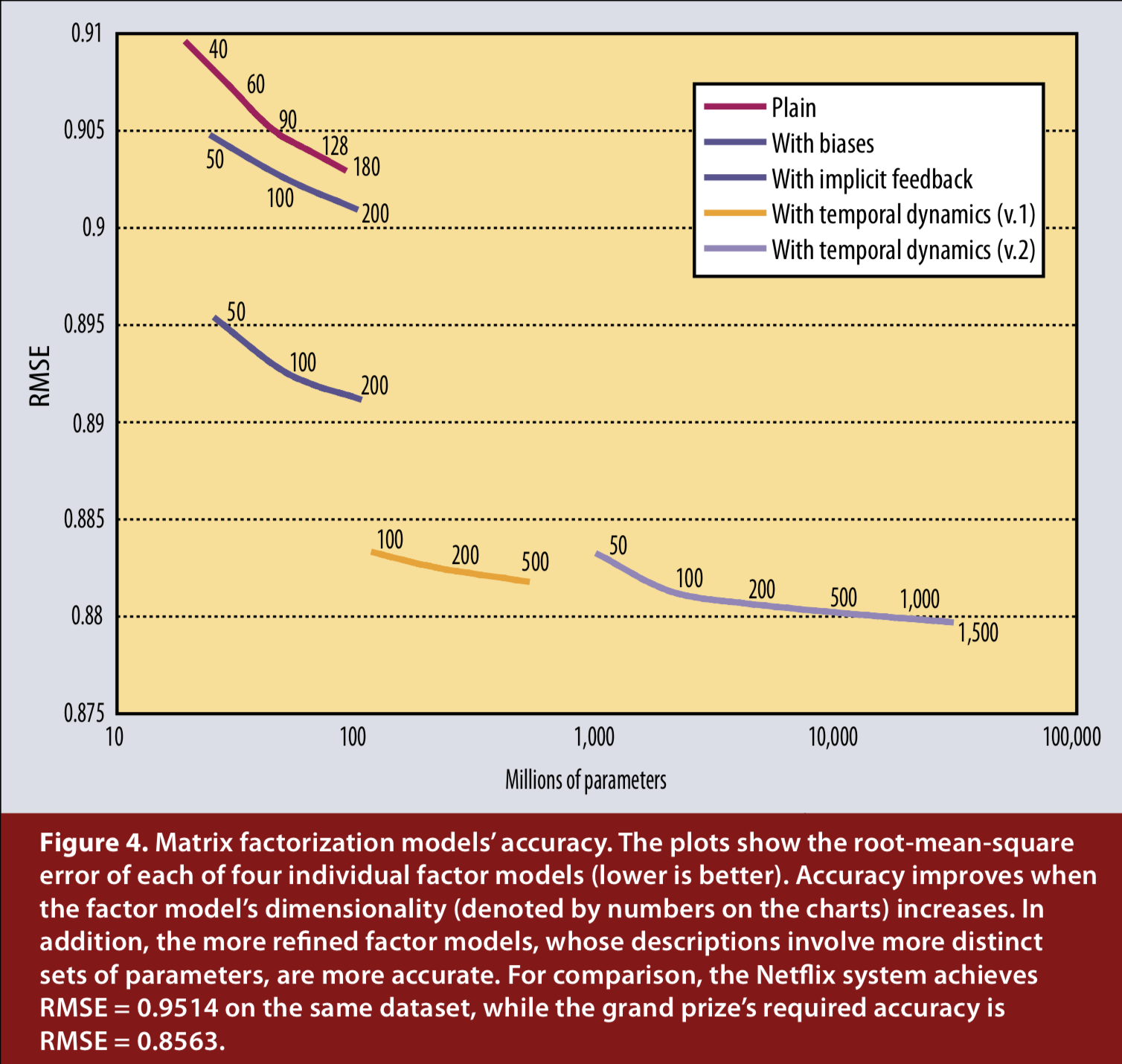
복잡한 매개 변수 집합을 포함하는 요인 모델(factor model)은 더 정확합니다. 사실, 시간 구성 요소는 데이터에 상당한 시간적 효과(temporal effect)가 있으므로 모델링에 특히 중요합니다.
Matrix Factorization(매트릭스 인수 분해) 기술은 Collaborative Filtering(협업 필터링) 권장 사항 내에서 지배적인 방법론이 되었습니다. Netflix Prize 데이터와 같은 데이터 세트를 사용한 경험은 고전적인 가장 가까운 이웃 기술보다 정확도가 뛰어나다는 것을 보여주었습니다. 동시에 시스템은 비교적 쉽게 학습 할 수있는 소형 메모리 효율적인 모델을 제공합니다. 이러한 기법을 더욱 편리하게 만드는 것은 모델이 여러 형태의 피드백, 시간적 동력학 및 신뢰 수준과 같이 자연스럽게 많은 데이터 측면을 통합 할 수 있다는 것입니다.
'MachineLearning' 카테고리의 다른 글
| Machine Learning - Predicting House Prices : python (0) | 2018.01.30 |
|---|---|
| Machine Learning - Predicting House Prices : Regression (0) | 2018.01.30 |
| Spark MLlib ALS lastfm dataset (0) | 2017.11.28 |
| Spark Scala Wikipedia dataset (0) | 2017.11.27 |
| DART: Dropouts meet Multiple Additive Regression Trees (0) | 2017.11.14 |
Matrix Factorization Techniques for Recommender Systems
Yehuda Koren, Yahoo Reserach
Robert Bell and Chris Volinsky, AT&T Labs - Research
ABSTRACT
Netflix Prize 대회에서 Matrix Factorization 모델은 implicit(내재되어 있는) feedback과 temporal effect 그리고, confidence levels 등 추가적인 정보를 사용하면서, 제품을 추천하기 위한 고전적인 Nearest-Neighbor 알고리즘보다 우수합니다.
현대 소비자들은 선택의 폭이 넓습니다. 전자 소매 업체 및 컨텐츠 제공 업체는 다양한 특별 요구 사항 및 취향을 충족시킬 수 있는 전례없는 기회를 제공하여 엄청난 양의 제품을 제공합니다. 소비자를 가장 적합한 제품과 조화시키는 것이 사용자 만족도(satisfaction)와 충성도(loyalty)를 높이는데 중요합니다. 따라서 더 많은 소매 업체는 제품의 사용자 관심 패턴을 분석하여 사용자의 취향(taste)에 맞는 맞춤 권장 사항을 제공하는 추천 시스템에 관심을 갖게되었습니다. 좋은 개인화 맞춤 추천이 사용자 경험(user experience)에 또 다른 차원을 추가할 수 있기 때문에 Amazon.com 및 Netflix와 같은 전자 상거래 리더는 추천 시스템을 웹 사이트의 중요한 부분으로 만들었습니다.
이러한 시스템은 특히 영화, 음악 및 TV 프로그램과 같은 엔터테인먼트 제품에 유용합니다. 많은 고객이 동일한 영화를 볼 것이고 각 고객은 수많은 영화를 볼 것입니다. 고객은 특정 영화에 대한 만족도를 나타내는 것으로 입증되었으므로 어떤 영화가 어떤 고객에게 호소하는지에 대한 방대한 양의 데이터를 이용할 수 있습니다. 회사는 이 데이터를 분석하여 특정 고객에게 영화를 추천 할 수 있습니다.
RECOMMENDER SYSTEM STRATEGIES
대체로 추천 시스템은 두 가지 전략 중 하나를 기반으로합니다. Content Filtering 접근 방식은 각 사용자(user) 또는 제품(product)을 특성화(characterize)하기 위해 프로필(profile)을 만듭니다. 예를 들어, 영화 프로필에는 장르, 참여하는 배우, 흥행 장르와 관련된 속성 등이 포함될 수 있습니다. 사용자 프로필에는 인구 통계학적 정보 또는 적절한 설문지에 제공된 답변이 포함될 수 있습니다. 프로필을 사용하면 프로그램에서 사용자를 일치하는 제품과 연결할 수 있습니다. 물론 Content-based 전략을 사용하려면 수집할 수 없거나 쉽게 수집할 수 없는 외부 정보를 수집해야합니다.
Content Filtering 의 성공적인 실현은 인터넷 라디오 서비스 Pandora.com에 사용되는 Music Genome Project입니다. 숙련된 음악 분석가는 수백 가지의 독특한 음악적 특성을 기반으로 음악 게놈 프로젝트의 각 노래에 점수를 매 깁니다. 이러한 속성(attributes) 또는 유전자는 노래의 음악적 정체성 뿐만 아니라 청취자의 음악적 취향을 이해하는 데 관련된 많은 중요한 자질을 포착합니다.
Content Filtering 대신 명시적인(explicit) 프로필을 만들지 않고, 이전 거래 기록(transaction) 또는 제품 등급(product ratings)과 같은 과거 사용자 행동에만 의존 할 수 있습니다. 이 접근법은 협업 필터링(Collaborative Filtering)으로 알려져 있습니다. 이 용어는 첫 추천 시스템인 Tapestry의 개발자가 만들어 냈습니다. 협업 필터링은 사용자간의 관계와 제품 간의 상호 의존성(interdependencies)을 분석하여 새로운 사용자-항목 연결(user-item associations)을 식별합니다.
Collaborative Filtering의 주요 장점은 도메인(domain)이 없다는 것입니다. 그러나 Content Filtering을 사용하여 파악하기가 어렵고 프로필 작성이 어려운 데이터 측면을 처리할 수 있습니다. 일반적으로 Content-based 기술보다 정확한 반면, Collaborative Filtering은 시스템의 새로운 제품(products) 및 사용자(users)를 처리 할 수 없기 때문에 cold start problem 라고 불립니다. 이 측면에서는 Content Filtering이 우수합니다.
Collaborative Filtering의 주요 두 영역은 인접 방법(neighbor methods) 및 잠재 요인(latent factor) 모델입니다. neighbor methods 방법은 항목간(item) 또는 사용자간(user) 관계를 계산하는데 중점을 둡니다. item-oriented 접근법은 동일한 사용자가 "인접한(neighboring)" 항목의 등급(rating)을 기준으로 항목에 대한 사용자의 선호도(preference)를 평가합니다. 제품의 이웃(neighbors)은 동일한 사용자가 평가할 때 유사한 등급을 얻는 경향이 있는 다른 제품(product)입니다. 예를 들어, Saving Private Ryan 영화를(라이언 일병 구하기) 생각해보십시오. 그 이웃에는 전쟁 영화, 스필버그 영화, 톰 행크스 영화 등이 포함될 수 있습니다. Saving Private Ryan에 대한 특정 사용자의 등급을 예측하려면 이 사용자가 실제로 평가한 가장 가까운 이웃을 찾아야합니다. 그림 1에서 알 수 있듯이 사용자 중심 접근 방식은 서로의 등급을 보완 할 수있는 마음이 맞는 사용자를 식별합니다.
잠재 요인 모델(Latent factor Models)은 등급 패턴(rating pattern)에서 추론된 20-100 가지 요소(factor)에 대해 항목(item)과 사용자(user)를 특성화(하여 등급을 설명하려고하는 대안 방법입니다. 어떤 면에서, 이러한 요소(factor)는 인간이 창조한 노래 유전자에 대한 컴퓨터화 된 대안을 포함합니다. 영화의 경우, 발견된 요소(factor)는 코미디 대 드라마, action의 양 또는 children orientation과 같은 분명한 차원을 측정할 수 있습니다. 인물 개발(character development) 또는 기이함(quirkiness)과 같은 잘 정의되지 않은 차원(dimensions); 또는 완전히 해석할 수 없는(uninterpretable) 차원. 사용자의 경우 각 요인(factor)은 해당 영화 요소에서 점수(score)가 높은 영화를 얼마나 좋아하는지 측정합니다.
그림 2는 이 아이디어를 2차원의 단순화된 예제로 보여줍니다. 여성 vs 남성 지향적과 심각한(serious) vs 도피주의자(escapist)로 특징 지어지는 두 개의 가정적인 차원을 생각해 보자. 이 그림은 몇 가지 유명한 영화와 몇 가지 가상의 사용자가 이 두 가지 차원에 속할 수 있는 위치를 보여줍니다. 이 모델의 경우 영화에 대한 사용자의 예상 평점(predict rating)은 영화의 평균 평점(average rating)과 비교하여 그래프의 영화 및 사용자 위치의 내적(dot product)과 같습니다. 예를 들어, Gus는 Dumb and Dumber 사랑하고 The Color Purple을 싫어하고, 평균에 대해 Braveheart를 평가할 것으로 기대합니다. 일부 영화(예: Ocean's 11) 및 사용자(예: Dave)는 이 두 가지 차원에서 상당히 중립적인 특성을 갖습니다.
MATRIX FACTORIZATION METHODS
잠재 요인 모델(latent factor models)의 가장 성공적인 실현 중 일부는 Matrix Factorization(행렬 인수분해)를 기반으로합니다. 그것의 기본 형태에서, Matrix Factorization는 항목 등급 패턴(item rating patterns)으로부터 추론된 인자(factor)의 벡터(vector)에 의해 아이템(item)과 사용자(user)를 특징 만듭니다. 아이템과 사용자 요소 간의 높은 일치는 권장 사항으로 이어집니다. 이러한 방법은 예측 정확도(predictive accuracy)와 좋은 확장성(scalability)을 결합하여 최근 몇 년 동안 널리 보급되었습니다. 또한 다양한 실제 상황을 모델링할 때 많은 유연성을 제공합니다.
추천 시스템(Recommender system)은 사용자를 나타내는 차원과 관심있는 항목을 나타내는 차원으로 매트릭스에 배치되는 여러 유형의 입력 데이터에 의존합니다. 가장 편리한 데이터는 사용자가 제품에 대한 관심에 대해 명시적으로 입력(explicit input)하는 고품질의 명시적 피드백(explicit feedback)입니다. 예를 들어, Netflix는 영화의 별표 등급(ratings)을 수집하고, TiVo는 사용자가 엄지 손가락 업 및 아래(thumbs-up and down)로 버튼을 눌러 TV 프로그램에 대한 선호도(preference)를 나타냅니다. 명시적 사용자 피드백(explicit user feedbacks)을 평점(ratings)이라고합니다. 일반적으로 명시적인 피드백(explicit feedback)은 희박한 행렬(sparse matrix)을 구성합니다. 단일 사용자가 가능한 항목의 비율을 낮게 평가할 가능성이 있기 때문입니다.
Matrix Factorization의 장점은 추가 정보(information)의 통합(incorporation)을 허용한다는 것입니다. 명시적 피드백(Explicit feedback)을 사용할 수 없는 경우 추천 시스템은 구매 내역, 검색 기록, 검색 패턴 또는 마우스 이동을 포함한 사용자 행동을 관찰하여 의견을 간접적으로 반영하는 암시적 피드백(Implicit feedback)을 사용하여 사용자 환경 설정을 유추 할 수 있습니다. 암시적 피드백(Implicit Feedback)은 대개 이벤트의 존재 또는 부재를 나타내므로 일반적으로 밀도가 높은 행렬(Dense matrix)로 표시됩니다.
A BASIC MATRIX FACTORIZATION MODEL
Matrix Factorization 모델은 사용자와 아이템을 차원(dimensionality) f의 공동 잠재요인(latent factor) 공간으로 매핑하여, 사용자-아이템 상호 작용(user-item interaction)을 해당 공간에서 내적(inner product)으로 모델링합니다. 따라서, 각 아이템 i는 벡터 qiℝf 와 연관되며, 각 사용자 u는 벡터 puℝf와 연관 됩니다. 주어진 아이템 i에 대해 qi의 element는 item이 양수 또는 음수인 요소(factor)를 어느 정도 보유하고 있는지를 측정합니다. 주어진 사용자 u에 대해 pu의 element는 양수와 음수를 통해 해당 factor에서 높은 item에 대해 사용자가 갖는 관심의 정도를 측정합니다. 내적 값의 결과 qiTpu는 사용자 u와 아이템 i 사이의 상호 작용(interaction), 즉 아이템의 특성(characteristics)에 대한 사용자의 전반적인 관심(interest)을 포착합니다. 이 값은 사용자 i의 평점(rations)한 아이템 i와 유사하며 rui로 표시되며, 다음과 같이 평가됩니다.
주요한 난제는 각 아이템과 사용자의 요소(factor) 벡터(vector) qi,puℝf 에 대한 맵핑(mapping)을 계산하는 것입니다. 추천 시스템이 이 맵핑(mapping)을 완료한 후, 방정식 1을 사용하여 사용자(user)가 어떤 아이템에 부여할 등급(rating)을 쉽게 추정할 수 있습니다.
이러한 모델은 정보 검색(information retrieval)에서 잠재 의미론적 요소(latent semantic factor)를 식별하기위한 잘 확립된 기법인 Singular Value Decomposition(SVD)와 밀접하게 관련되어 있습니다. Collaborative Filtering 도메인에 SVD를 적용하려면 사용자-아이템 평가(user-item rating) 매트릭스(matrix)를 인수분해(factoring) 해야 합니다. 이는 종종 사용자 항목 평가 매트릭스에서 희소성(sparseness)으로 인해 손실된 값(missing value)이 많아서 어려움이 생깁니다. 행렬(matrix)에 대한 지식이 불완전한 경우 기존 SVD는 정의되지 않습니다. 더욱이, 비교적 적은 수의 알려진 entry만을 부주의하게 처리하는 것은 overfitting하기 쉽습니다.
이전 시스템은 대치(imputation)에 의존하여 누락된 등급(missing ratings)을 채우고 등급 매트릭스(rating matrix)를 조밀하게(dense) 만듭니다. 그러나 데이터 양이 크게 늘어남에 따라 대체 비용이 매우 높을 수 있습니다. 또한, 부정확한(inaccurate) 대치(imputation)는 데이터를 상당히 왜곡시킬 수 있습니다. 따라서보다 최근의 연구에서는 정규화 된(regularized) 모델을 통해 overfitting을 피하면서 관측된 등급만 직접 모델링하는 것이 좋습니다. 요소 벡터 (factor vector: pu and qi)를 학습하기 위해, 시스템은 알려진 등급 세트에 대한 정규화 제곱 오차(Regularized Squared Error)를 최소화합니다:
여기서, k는 rui가 알려진 (u, i) 쌍의 training set입니다.
시스템은 이전에 관찰된 등급(ratings)에 맞추어 모델을 학습합니다. 그러나 목표는 미래의 알려지지 않은 등급을 예측하는(predict) 방식으로 이전의 등급을 일반화하는 것입니다. 따라서, 시스템은 그 규모가 제한을 받는(penalized) 학습된 매개 변수(parameters)를 정규화함으로써 관측된 데이터를 overfitting을 방지해야합니다. 상수 λ는 정규화의 범위를 제어하며, 대개 교차 유효성 검사(Cross-Validation)에 의해 결정됩니다. Ruslan Salakhutdinov와 Andriy Mnih의 "Probabilistic Matrix Factorization"은 정규화를 위한 확률론적 토대를 제공합니다.
LEARNING ALGORITHMS
식 2를 최소화하는 두 가지 접근법은 Stochastic Gradient Descent(SGD)와 Alternating Least Squares(ALS)입니다.
Stochastic Gradient Descent
Simon Funk는 방정식 2 (http://sifter.org/~simon/journal/20061211.html)의 SGD(확률적 그래디언트 강하) 최적화(Optimization)를 대중화하였으며, 여기서 알고리즘은 training set의 모든 등급(rating)을 반복합니다. 각각의 주어진 training 경우에 대해, 시스템은 rui를 예측하고 연관된 예측 오차(prediction error)를 계산합니다.
그런 다음 그라디언트의 반대 방향으로 에 비례하는 크기로 매개 변수(parameter)를 수정하여 다음을 산출합니다.
이 인기있는 접근법은 구현이 쉽고 상대적으로 빠른 실행 시간을 제공합니다. 그러나 어떤 경우에는 ALS 최적화를 사용하는 것이 좋습니다.
Alternating Least Squares
pu, qi 둘 다 알려지지 않은 값이기(unknown) 때문에, 방정식 2는 볼록하지(convex) 않습니다. 그러나 미지수(unknowns) 중 하나를 수정한다면, 최적화(optimization) 문제는 2차(quadratic)로 되어 최적으로 해결할 수 있습니다. 따라서 ALS 기법은 qi를 고정하고 pu를 고정하는 사이에서 회전합니다. 모든 pu가 고정되면, 시스템은 최소 제곱 문제(least-squares)를 푸는 것에 의해 재계산하고(recompute), 그 반대의 경우도 마찬가지입니다. 이렇게하면 각 단계가 수렴(convergence)될 때까지 식 2가 감소합니다.
SGD가 ALS보다 쉽고 빠르지만, ALS는 적어도 두 가지 경우에 유리합니다. 첫 번째는 시스템이 병렬 처리(parallelization)를 사용할 수 있는 경우 입니다. ALS에서 시스템은 다른 아이템 요인(factor)과 독립적으로(independently) 각 qi를 계산하고 다른 사용자 요인과 독립적으로 각 pu를 계산합니다. 이것은 알고리즘의 대규모 병렬화를 야기합니다. 두 번째 경우는 암시적(implicit) 데이터를 중심으로 하는 시스템을 위한 것입니다. training set는 희소성(sparse)이 낮은 것으로 간주 될 수 없기 때문에, Gradient descent처럼 각 단일 training case를 반복하면 실용적이지 않습니다. ALS는 이러한 경우를 효율적으로 처리 할 수 있습니다.
ADDING BIASES
Collaborative Filtering에 대한 Matrix Factorization 접근법의 한 가지 이점은 다양한 데이터 측면 및 기타 애플리케이션 별 요구 사항을 처리 할 수 있는 유연성(flexibility)입니다. 이것은 동일한 학습 framework 내에서 방정식 1에 대한 조정을 요구합니다. 방정식 1은 서로 다른 등급(rating) 값을 산출하는 사용자와 아이템 간의 상호 작용(interaction)을 포착합니다. 그러나 관찰된 등급 값의 편차(variation)는 상호 작용과 관계없이 편향(bias) 또는 절편(intercept)으로 알려진 사용자 또는 아이템과 관련된 영향으로 인한 것입니다. 예를 들어, 일반적인 Collaborative Filtering 데이터는 일부 사용자가 다른 사용자보다 높은 등급을 부여하고 일부 아이템이 다른 사용자보다 높은 등급을 받는 큰 체계적인(systematic) 경향(tendency)을 나타냅니다. 결국, 일부 제품은 다른 제품보다 더 좋게(또는 나쁘게) 인식됩니다.
따라서 형식 qiTpu의 상호 작용(interaction)에 의해 전체 등급 값을 설명하는 것은 현명하지 않을 수 있습니다. 대신 시스템은 개별 사용자 또는 아이템 bias가 설명 할 수 있는 값의 일부를 식별하여 데이터의 정확한 상호 작용 부분만 요인 모델링(factor modeling)에 적용합니다. 등급 rui에 포함된 bias의 1차 근사(approximation)는 다음과 같습니다.
rui 등급과 관련된 편향(bias)은 bui로 표시되며 사용자 및 아이템 효과를 설명합니다. 전반적인 평균 등급은 μ로 표시됩니다. 파라미터 bu 및 bi는 평균(average)으로부터 각각 사용자 u 및 아이템 i의 관측된 표준 편차(deviations)를 나타냅다. 예를 들어, 타이타닉 영화의 사용자 Joe 등급에 대한 1차 예상치를 원한다고 가정해봅시다. 이제 모든 영화에 대한 평균 평점 μ는 3.7 등급입니다. 또한 타이타닉 영화는 평균 영화보다 낫기 때문에 평균 이상으로 0.5 등급을 얻는 경향이 있습니다. 반면에 Joe는 평균 사용자보다 0.3 등급 낮은 경향이 있는 중요한 사용자입니다. 따라서 Joe의 Titanic 등급 평가는 3.9 등급 (3.7 + 0.5 - 0.3)입니다. bias는 다음과 같이 수식 1을 확장합니다.
여기서 관찰된 등급(rating)은 전역 평균(global average), 아이템 bias, 사용자 bias 및 사용자-아이템 상호 작용(interaction)의 네 가지 구성 요소로 나뉩니다. 이를 통해 각 구성 요소는 해당 구성 요소와 관련된 신호(signal)의 일부만 설명 할 수 있습니다. 시스템은 제곱 오차 함수(squared error function)을 최소화하여 학습합니다.
bias는 관찰된 신호의 대부분을 캡쳐하는 경향이 있으므로, 정확한 모델링이 중요합니다. 따라서 다른 모델보다 정교한 bias 모델을 제공합니다.
ADDITIONAL INPUT SOURCES
종종 시스템은 cold-start problem을 처리해야 하며, 많은 사용자가 매우 적은 수의 등급을 제공하기 때문에 자신의 취향에 대한 일반적인 결론에 도달하기가 어렵습니다. 이 문제를 해결하는 방법은 사용자에 대한 추가 정보 소스를 통합하는 것(incorporate)입니다. 추천 시스템(Recommender systems)은 implicit feedback을 사용하여 사용자 선호(preference)에 대한 통찰력을 얻을 수 있습니다. 사실, 사용자는 명시적(explicit) 등급을 제공하려는 사용자의 의지와 상관없이 행동 정보를 수집 할 수 있습니다. 소매 업체는 고객의 구매 또는 검색 기록을 사용하여 고객이 제공 할 수 있는 등급(ratings) 외에도 자신의 경향을 파악할 수 있습니다.
단순화를 위해 Boolean Implicit Feedback이 있는 경우를 생각해보십시오. N(u)는 사용자 u가 implicit preferences를 표현한 아이템의 집합을 나타냅니다. 이렇게 하면 시스템은 암시적으로 선호하는 항목을 통해 사용자를 프로파일합니다. 여기서 아이템 요인(factor)의 새로운 세트가 필요합니다. 아이템 i는 xiℝf 와 연관됩니다. 따라서, N(u)에서 아이템에 대한 선호도(preference)를 보여준 사용자(user)는 벡터(vector)로 특징화됩니다.
이 합을 정규화(normalizing) 하는 것은 종종 유익합니다. 예를 들어 다음과 같이
또 다른 정보 소스는 알려진 사용자 속성 (예 : 인구 통계)입니다. 다시 말하지만, 단순화(simplicity)를 위해 사용자 u가 성별, 연령 그룹, 우편 번호, 소득 수준 등을 설명할 수있는 속성(attribute) 집합 A(u)에 해당하는 Boolean 특성을 고려해야 합니다. 구분을 지을 수 있는 요소 벡터(factor vector) yaℝf는 사용자와 연관된 속성(attribute) 집합을 통해 사용자 a를 설명하는 각 속성에 해당합니다.
Matrix Factorization 모델은 모든 신호 소스(signal sources)를 통합하여, 다음의 강화된 사용자 표현을 합니다.
앞의 예제는 데이터가 부족할 경우에 사용자 표현을 향상시키는데 사용되었으나, 필요할 때 비슷하게 아이템에 처리할 수 있습니다.
TEMPORAL DYNAMICS
지금까지 제시된 모델은 정적이었습니다. 실제로 새로운 선택(selection)이 등장함에 따라 제품 인식(perception)과 인기(popularity)가 끊임없이 변화합니다. 마찬가지로 고객의 성향(inclination)도 진화하여 취향을 재정의하게됩니다. 따라서, 시스템은 사용자-항목 상호 작용(interaction)의 동적인 시간 이동 특성(time-drifting nature)을 반영하는 시간 효과(temporal effect)를 설명해야한다.
Matrix Factorization은 temporal effect를 모델링하는 데 적합하므로 정확도(accuarcy)를 크게 향상시킬 수 있습니다. 등급을 별개의 용어로 분해하면 시스템이 서로 다른 시간적 측면(temporal aspect)을 개별적으로 처리 할 수 있습니다. 특히, 다음 용어는 시간에 따라 변한다 : 아이템 bias, bi(t); 사용자 bias, bu(t); 및 사용자 선호도, pu(t).
첫 번째 temporal effect는 아이템의 인기가 시간이 지남에 따라 변할 수 있다는 사실을 나타냅니다. 예를 들어, 영화는 새로운 영화에서 배우의 출연과 같은 외부 이벤트에 의해 트리거되어 인기를 얻거나 벗어날 수 있습니다. 그러므로,이 모델들은 아이템 bias bi를 시간의 함수로 취급합니다. 두 번째 temporal effect는 사용자가 시간 경과에 따라 기준선(baseline) 등급을 변경할 수 있게 합니다. 예를 들어, 평균 영화 "4 starts"을 평가하는 경향이 있는 사용자는 이제 그러한 영화를 "3 stars"로 평가할 수 있습니다. 이는 사용자의 등급 척도에서의 자연스러운 표류(압력), 사용자가 다른 최근 등급에 관련이 있는 등급을 지정한다는 사실, 주택 보유자 내의 정체감이 시간이 지남에 따라 변할 수 있다는 사실을 알 수 있습니다. 따라서, 이들 모델에서, 파라미터 bu는 시간의 함수이다.
시간적 역동성(Temporal dynamics)은 이것을 뛰어넘는다. 사용자 선호도(preference) 및 사용자(user)와 아이템(item)간의 상호작용(interaction)에도 영향을 줍니다. 사용자는 시간이 지남에 따라 선호도(preference)를 변경합니다. 예를 들어, 심리적 스릴러(psychological thrillers) 장르의 팬은 1년 후 범죄 드라마(crime dramas) 팬이 될 수 있습니다. 마찬가지로 인간도 특정 배우(actors)와 감독(directors)에 대한 인식을 변화시킵니다. 이 모델은 사용자 요소 (vector pu)를 시간의 함수로 취하여 효과(effect)를 설명합니다. 반면에 사람과 달리 아이템은 본질적으로 정적(static)이기 때문에 정적 아이템 특성 인 qi)를 지정합니다.
시간에 따라 변하는 매개 변수의 정확한 parameter은 시간 t 에서의 등급(ratings)에 대한 동적 예측(dynamic prediction) 규칙으로 식 4를 대체합니다.
INPUTS WITH VARYING CONFIDENCE LEVELS
몇 가지 설정에서 모든 관측된 등급(rating)이 동일한 가중치(weight) 또는 신뢰도(confidence)를 가질 자격이 없습니다. 예를 들어, 대규모 광고는 특정 아이템(item)의 투표(vote)에 영향을 미칠 수 있으며, 장기적인 특성을 적절하게 반영하지 못합니다. 마찬가지로 시스템이 특정 아이템의 등급을 기울이려고 하는 적대적인 사용자에게 직면 할 수도 있습니다.
또 다른 예는 implicit feedback 에 구축된 시스템입니다. 진행 중인 사용자(user) 행동을 해석하는 시스템에서 사용자의 정확한 선호도(preference) 수준은 정량화하기 어렵습니다. 따라서 시스템은 "제품을 좋아할 것"또는 "제품에 관심이 없을 것"이라고 말하는 더 까다로운 2진(binary) 표현으로 작업합니다. 이러한 경우 예상된 선호도에 신뢰도(confidence) 점수를 부가하는 것이 중요합니다. 사용자가 특정 프로그램을 시청한 시간이나 사용자가 특정 아이템을 구입 한 빈도와 같이 행동 빈도를 설명하는 사용 가능한 수치를 통해 신뢰도(confidence)을 얻을 수 있습니다. 이 수치는 각 관찰의 신뢰도를 나타냅니다. 사용자 신뢰도(confidence)와 아무런 관련이 없는 다양한 요소(factor)가 일회성 이벤트를 유발할 수 있습니다. 그러나 되풀이되는(recurring) 이벤트는 사용자의 의견을 반영할 가능성이 큽니다.
Matrix Factorization(행렬 인수 분해) 모델은 다양한 신뢰 수준(confidence level)을 쉽게 받아 들일 수 있으므로 덜 의미있는 관측(observation)에는 더 적은 가중치(weight)를 부여합니다. rui 를 관찰하는 것에 대한 확신이 cui 로 표시된다면, 모델은 다음과 같이 신뢰도를 설명하기 위해 비용 함수(cost function) (식 5)를 향상시킵니다.
이러한 스키마(scheme)가 포함된 실제 응용 프로그램에 대한 자세한 내용은 "Collaborative Filtering for Implicit Feedback Datasets"을 참조하세요.
Y.F. Hu, Y. Koren, and C. Volinsky, “Collaborative Filtering for Implicit Feedback Datasets,” Proc. IEEE Int’l Conf. Data Mining (ICDM 08), IEEE CS Press, 2008, pp. 263-272.
NETFLIX PRIZE COMPETITION
2006 년 온라인 DVD 대여 회사인 Netflix는 추천 시스템의(recommender system) 상태를 개선하기 위한 경진대회(contest)를 발표했습니다. 이것을 가능하게 하기위해 이 회사는 익명의 고객 약 50 만 명과 1만 5천 개 이상의 영화에 등급(ratings)을 매기는 1 억 개 이상의 training-set을 발표했습니다. 각 영화의 등급은 1~5 입니다. 참여 팀은 약 300 만 개 등급의 test-set에 대한 예상(predict) 등급을 제출하고 Netflix는 파악된 truth(label)을 기반으로 RMSE (Root-Mean-Square Error)를 계산합니다. Netflix 알고리즘의 RMSE 성능을 10 % 이상 향상시킬 수있는 첫 번째 팀은 1 백만 달러의 상금을 수여합니다. 어떤 팀도 10% 목표에 도달하지 못하면 Netflix는 각 경쟁 후 첫 번째로 팀에 5만 달러의 Progress Prize를 제공합니다.
경진대회(contest)는 Collaborative Filtering(협업 필터링) 필드에서 본격적인 탄력을 주었습니다. 이 시점까지는 협업 필터링 연구를 위해 공개적으로 사용할 수 있는 유일한 데이터는 훨씬 작은 규모였습니다. 이 데이터의 공개와 경쟁의 매력으로 인해 에너지와 활동이 폭발적으로 증가했습니다. 경진대회 웹 사이트 (www.netflixprize.com)에 따르면 182 개국 48,000 개 팀이 데이터를 다운로드했습니다.
원래 BellKor라고 불렸던 우리 팀의 항목은 2007 년 여름 경쟁에서 1위 자리를 차지했으며 당시 최고 점수 인 2007 Progress Prize에서 Netflix보다 8.43 % 우수했습니다. 나중에 우리는 Big Chaos 팀과 함께 2008 Progress Prize에서 9.46 %의 점수를 받았습니다. 이 글을 쓰는 시점에서 우리는 여전히 10 %의 랜드 마크로 도약하고 있습니다.
우리의 우승 항목은 100가지가 넘는 다양한 예측 변수 세트(predictor set)로 구성되며, 대부분이 여기에 설명된 방법의 변형을 사용하는 Factorization Models(인수 분해) 모델입니다. 다른 상위 팀과 토론하고 공개 콘테스트 포럼에 게시하면 등급 예측(ratings prediction)을 위한 가장 인기 있고 성공적인 방법임을 알 수 있습니다.
Netflix 사용자-영화(user-movie) matrix를 고려하면 영화 선호도(preference)를 예측하는 데 가장 묘사적인 차원(descriptive dimensions)을 발견 할 수 있습니다. 우리는 매트릭스 분해(Matrix Decomposition)로부터 처음 몇 가지 중요한 차원(dimensions)을 식별하고 이 새로운 공간에서 영화의 위치를 탐색 할 수 있습니다. 그림 3은 Netflix 데이터 Matrix Factorization(행렬 인수 분해)의 처음 두 요소를 보여줍니다. 영화는 요인 벡터(factor vectors)에 따라 배치됩니다. 영화에 익숙한 사람은 잠재 요소(latent factor)에서 명확한 의미를 볼 수 있습니다. 첫 번째 요소 벡터 (x 축)에서 왼쪽으로는 남성 또는 청소년 청중 (Half Baked, Freddy vs. Jason)을 겨냥한 저조한 코미디와 공포 영화를 가지고 있으며, 반대편 오른쪽에는 강한 여성의 드라마 또는 코미디가 포함되어 있습니다.(Sophie 's Choice, Moonstruck). 두 번째 인수 분해 축 (y 축)은 주류 정식 영화 (아마겟돈, 런 어웨이 브라이드)의 상단과 하단에 독립적이고 비판적으로 호소력있는 기발한 영화(Punch-Drunk Love, I Heart Huckabees)를 가지고 있습니다. 이 경계선들 사이에는 흥미로운 교차점이 있습니다. 왼쪽 상단에는 인디가 낮은 혈통을 만나는 곳으로 킬 빌 (Kill Bill)과 내츄럴 보른 킬러 (Natural Born Killers)가 있습니다. 오른쪽 아래에는 여성 중심의 영화가 주류 군중을 즐겁게하는 것인 The Sound of Music이 있습니다. 중간에 헤매고, 모든 유형에 호소하는 것은 The Wizard of Oz입니다.
이 그림에서 서로 인접한 일부 영화는 일반적으로 결합되지 않습니다. 예를 들어 Annie Hall과 Citizen Kane은 서로 옆에 있습니다. 그들은 스타일론적으로 매우 다르지만, 유명 감독들로부터 높은 평가를 얻은 고전 영화와 공통점이 많습니다. 사실, 인수 분해의 세 번째 차원은이 둘을 분리하게 만듭니다.
우리는 Factorization(인수 분해)를 위해 여러 가지 구현과 매개 변수화(parameterization)를 시도했습니다. 그림 4는 RMSE에 영향을 미치는 모델과 매개 변수의 수와 implicit feedback(암시적 피드백)이 있는 사용자 프로필 향상, 시간 구성 요소를 추가하는 두 가지 변종 등의 분석의 진화하는 구현 성능을 보여줍니다. 각 요인 모델의 정확성은 관련된 매개 변수의 수를 늘림으로써 향상됩니다. 이는 요인 모델(factor model)의 차원(dimensionality)을 증가시키는 것과 같습니다 (차트의 숫자로 표시됨).
복잡한 매개 변수 집합을 포함하는 요인 모델(factor model)은 더 정확합니다. 사실, 시간 구성 요소는 데이터에 상당한 시간적 효과(temporal effect)가 있으므로 모델링에 특히 중요합니다.
Matrix Factorization(매트릭스 인수 분해) 기술은 Collaborative Filtering(협업 필터링) 권장 사항 내에서 지배적인 방법론이 되었습니다. Netflix Prize 데이터와 같은 데이터 세트를 사용한 경험은 고전적인 가장 가까운 이웃 기술보다 정확도가 뛰어나다는 것을 보여주었습니다. 동시에 시스템은 비교적 쉽게 학습 할 수있는 소형 메모리 효율적인 모델을 제공합니다. 이러한 기법을 더욱 편리하게 만드는 것은 모델이 여러 형태의 피드백, 시간적 동력학 및 신뢰 수준과 같이 자연스럽게 많은 데이터 측면을 통합 할 수 있다는 것입니다.
'MachineLearning' 카테고리의 다른 글
| Machine Learning - Predicting House Prices : python (0) | 2018.01.30 |
|---|---|
| Machine Learning - Predicting House Prices : Regression (0) | 2018.01.30 |
| Spark MLlib ALS lastfm dataset (0) | 2017.11.28 |
| Spark Scala Wikipedia dataset (0) | 2017.11.27 |
| DART: Dropouts meet Multiple Additive Regression Trees (0) | 2017.11.14 |