Spark MLlib ALS lastfm dataset

1. Spark MLlib

Spark MLlib은 머신 러닝(ML, Machine Learning)을 사용할 수 있는 Spark의 Library 입니다.
모든 데이터가 RDD로 표현된 distributed dataset을 이용해 Spark 클러스터에서 병렬(parallel execution)로 실행할 수 있게 설계되어 있습니다
Distributed Random Forests(RF), K-means, ALS(Alternating Least Squares) 알고리즘을 포함하고 있습니다. MLlib은 사이즈가 큰 분산 대용량 dataset에 적용하기 적절하며 작은 dataset을 갖고 있다면, single machine을 위한 학습 라이브러리(scikit-learn) 적용하여, map()을 써서 병렬로 처리하는 것이 낫습니다.
2. ALS(Alternating Least Squares)
Collaborative Filtering은 다양한 item에 대한 user의 평점(rating)과 상호 작용이 혼합하여 새로운 item를 추천하는 recommendation system을 위한 기술입니다.
예를 들어, 2명이 청취한 음악이 같은 곡이 많다면, 같은 음악의 취향을 가질 것이라고 예측하는 것이 CF의 예입니다.
MLlib는 클러스터(cluster)에서 정량화가 우수한 Collaborative Filtering 알고리즘인 ALS를 포함하고 있습니다.
ALS Paper : https://dl.acm.org/citation.cfm?id=1608614
ALS는 mllib.recommendation.ALS 클래스에 있습니다.
https://spark.apache.org/docs/2.2.0/mllib-collaborative-filtering.html
ALS는 user 벡터와 item 벡터의 곱이 rating에 근접하도록 각 user와 item에 대한 feature vector(특징 벡터)를 정의하는 것으로 동작합니다.
latent-factor
latent-factor는 직접적으로 관찰되거나 측정이 되지 않는 잠재력을 가진 factor입니다. https://en.wikipedia.org/wiki/Factor_analysis
latent-factor로 만들어진 모델은 다수의 user와 item 사이에서 관측된 interaction을 상대적으로 적은 수의 관측되지 않은 것(unobserved)을 설명할 때 사용합니다.
MF(Matrix Factorization)
user와 item data를 Matrix X로 표현합니다. X는 user i가 artist j의 음악을 들었다면, A의 i행, j열에 값이 존재하는 Matrix입니다. X는 sparse matrix이며, 그 이유는 user-artist의 모든 조합에서 각 user가 모든 artist의 음악을 듣지 않고, 소수의 음악만 청취하기 때문에 대부분의 값은 0입니다.
MF 알고리즘을 통해 X를 Matrix L과 R의 행렬곱(Matrix Multiplication)으로 분해할 수 있습니다.
Matrix X가 (n,m)으로 표현된다면, L(n,k)은 row가 n이고, column은 k개(rank)로 표현되며, R`(k,m)는 row가 k, column이 m으로 표현됩니다. 여기서 k개의 column은 interaction하는 data를 설명하는 latent factor 입니다.
(n,m) = (n,k) * (k,m)

원래의 matrix X는 sparse 한 것에 비해 행렬곱은 dense 하므로, matrix completion 이라고도 합니다.
user가 평가하지 않은 data를 생성하게 되며, matrix X에서 값이 없었던 부분(missing value)를 제외하고 error를 RMSE(Root Mean Sqaured Error)로 계산하는 것이 objective function이 됩니다.
Alternating Least Squares(ALS)
위에서의 Matrix L과 R을 계산하기 위해 ALS 알고리즘을 사용합니다.
Netflix Prize 대회에서 나온 논문 <Collaborative Filtering for Implicit Feedback Datasets>
http://yifanhu.net/PUB/cf.pdf 과 <Large-scale Parallel Collaborative Filtering for the Netflix Prize>에서 구현된 알고리즘입니다. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.173.2797&rep=rep1&type=pdf
R의 값을 모르지만, 무작위로 값이 선택된 row vector로 초기화할 수 있습니다. 선형대수(algebra)를 통해 주어진 X와 R에 대한 최적의 L을 구할 수 있습니다. L의 각 row i는 R과 X의 한 row 함수로 독립적으로 계산할 수 있습니다. 독립적으로 수행이 가능하니 병렬 처리가 가능하고, 대규모로 연산시 적은 시간이 소모됩니다.
위의 수식을 계산하여 양 값은 일치할 수 없지만, 두 matrix에 대응되는 원소(element) 간 차의 제곱의 합을 최소화하는 것입니다. 여기서 최소제곱(Least Squares)이 유래되었습니다.
같은 방법으로 L로부터 Rj을 계산할 수 있습니다. 그리고 같은 방법으로 Rj로부터 L를 계산할 수 있습니다. 이 과정을 Alternating이라고 합니다. 비록 R은 무작위로 만들었지만 반복을 거칠 수록 L과 R이 에러율이 적어진 값으로 수렴합니다.
Explicit vs Implicit Feedback
Matrix Factorization(행렬 인수 분해) 기반 Collaborative Filtering(협업 필터링)에 대한 표준 접근 방식은 user-item matrix의 항목을 user가 item에 지정한 explicit preferences(예 : 영화에 등급을 부여하는 사용자)으로 취급합니다.
implicit feedback (예 : views, clicks 클릭 수, purchases 구매, likes 좋아요, shares 공유 등)에만 access 하는 것은 많은 실제 사용 사례에서 일반적입니다. 즉 사용자와 아티스트 사이의 관계가 어떤 explicit feedback나 ‘좋아요'버튼으로 직접 주어지는 대신, 다른 행위로부터 유추할 수 있는 형식이므로 implicit feedback이라고 합니다. 이러한 data를 처리하기 위해 spark.mllib에서 사용된 접근법은 Implicit Feedback dataset에 대한 CF(협업 필터링)에서 가져 왔습니다. 본질적으로 rating matrix를 직접 modeling하는 대신 이 방법은 data를 user actions (예 : 클릭 수 또는 누군가가 영화를 보는 데 소비한 누적 기간)의 관찰 strength를 나타내는 숫자로 취급합니다. 이러한 수치는 item에 부여 된 explicit rating 보다는 관찰된 user preference에 대한 신뢰도(confidence)와 관련이 있습니다. 그런 다음 model은 item에 대한 user의 예상되는 기본 설정을 예측하는 데 사용할 수있는 잠재 요인(latent factors)을 찾으려고 시도합니다.
ALS usage
ALS를 사용하기 위해서는 mllib.recommendation.Rating 객체의 RDD, user ID, product ID, rating을 넘겨야 합니다. ID는 32bit integer로 표현됩니다. user나 item이 같은 hash 값을 가지더라도 결과에 큰 영향을 미치지 않습니다. 중복되지 않는 ID를 가지도록 item ID의 mapping table을 만들어 broadcast 할 수 있습니다.
ALS는 결과를 표현하는 MatrixFactorizationModel을 반환하는데, predict(userID, productID)를 사용하여 rating을 예측할 수 있습니다. 혹은 model.recommend Products(userID, numProducts)을 사용하여 주어진 user에 대해 최적의 numProducts()의 추천 상품을 찾을 수 있습니다.
3. lastfm dataset
lastfm은 영국의 인터넷 라디오 방송과 음악 추천 시스템(recommendation system)을 병합한 웹 사이트입니다. 각 사용자의 프로필을 바탕으로 사용자의 취향에 맞는 곡을 추천하며, 비슷한 취향의 이용자를 서로 연결시켜, 개개인에게 맞춤 radio station을 제공합니다.


https://labrosa.ee.columbia.edu/millionsong/lastfm

Download dataset
dataset은 user_artist_data.txt, artist_data.txt, artist_alias.txt가 있습니다.
1. user_artist_data.txt
user_artist_data.txt 파일에는 141,000명의 user와 160만 명의 artist와 2,420만 건의 음악 재생 정보가 재생 횟수(plays)와 함꼐 저장되어 있습니다.
2. artist_data.txt
artist_data.txt 파일에는 각각의 artist에 unique한 ID 정보가 저장되어 있습니다.
3. artist_alias.txt
aritst_alias.txt 파일에는 각 artist에 대한 다양한 표기법이 기록된 artistID와 해당 artistID를 맵핑(mapping)하고 있습니다.
$ wget http://bit.ly/2ms3z6w
$ mv 2ms3z6w lastfm.tgz
$ tar -zxvf lastfm.tgz
$ hdfs dfs -put lastfm /dataset/

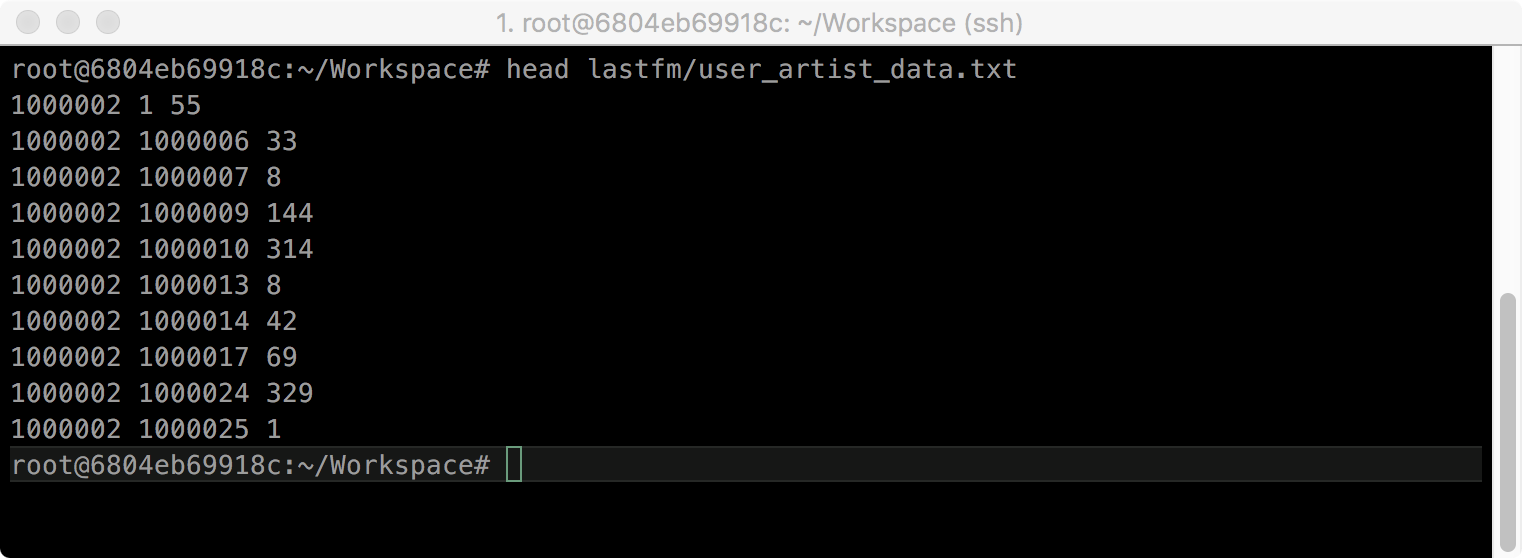
$ head lastfm/user_artist_data.txt
첫 번째 column은 user ID, 두 번째 column은 artist ID, 세 번째 column은 plays(rating) 입니다.
$ head lastfm/artist_data.txt
첫 번째 Column은 artist ID이며, 두 번째 column은 artist 이름입니다.

$ head lastfm/artist_alias.txt
alias는 같은 artist이지만, 다른 명으로 되어 있는 artist ID를 합쳐 놓은 것입니다.
예를 들어 G Dragon 과 GD는 같은 artist 이지만, name이 다르게 판단됩니다. 이를 위해 artist_alias.txt를 이용해 같은 ID로 식별하도록 사용됩니다.

Data Preprocessing
$ spark-shell --master spark://node-1:7077 --driver-memory 4g
ALS를 동작시키기 위해서 Row - userID, Column - artistID, Value - number of plays로 matrix를 만들어줘야 합니다.
> val rawUserArtistData = spark.read.textFile("hdfs:///dataset/lastfm/user_artist_data.txt")
> rawUserArtistData.take(5).foreach(println)

> val userArtistDF = rawUserArtistData.map { line =>
val Array(user, artist, score) = line.split(' ')
(user.toInt, artist.toInt)
}.toDF("user", "artist")
> userArtistDF.agg(min("user"), max("user"), min("artist"), max("artist")).show

> val rawArtistData = spark.read.textFile("hdfs:///dataset/lastfm/artist_data.txt")
> rawArtistData.take(5).foreach(println)

rawArtistData를 보면 Tab으로 ID와 Name이 구분되어 있다. ID 다음 Tab으로 Name이 구분지어진다.
span method를 사용해 두 개를 분리합니다.
http://www.scala-lang.org/api/2.7.1/scala/List.html
span method에서 참고
span method는 boolean으로 판단하여 두 개의 list를 생성합니다.
첫 번째 list는 boolean condition이 false인 경우로 생성되고, 두 번째 list는 true인 경우로 생성됩니다.
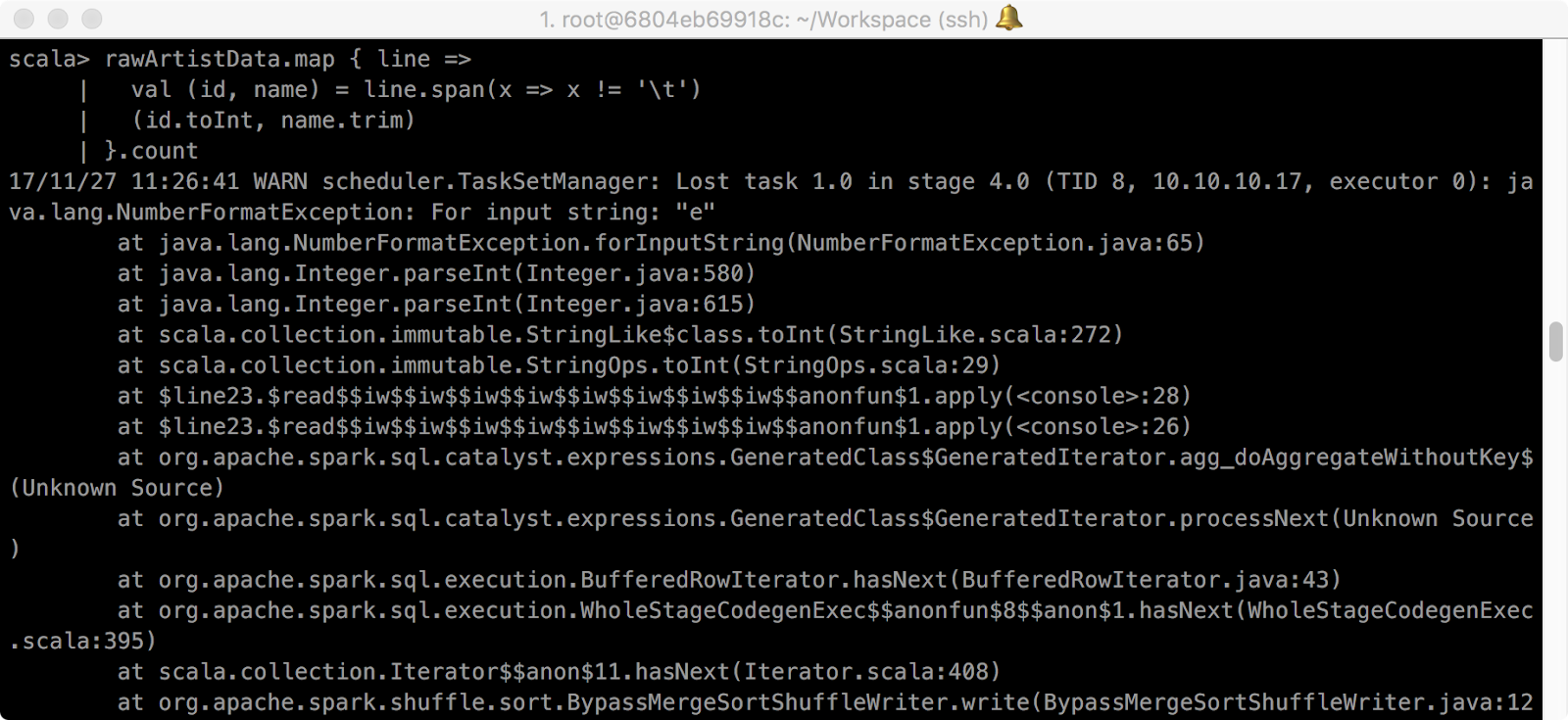
span method를 사용해 처리하다보면 tab이 없거나, space가 포함된 경우 NumberFormatException이 발생합니다.
> rawArtistData.map { line =>
val (id, name) = line.span(x => x != '\t')
(id.toInt, name.trim)
}.count
map을 사용하게 되면 각 entry 당 하나의 output이 나오기 때문에 mapping 되지 않는 element가 있는 상황에서는 사용할 수 가 없어 error case에 대해 handling 하기 어렵습니다. filter를 사용하여 parsing되지 않는 행을 제거할 수 있지만, parsing을 두 번해야 합니다.
각 element에 대응되는 것이 없거나, 하나 또는 여러 개에 대응될 때 flatMap을 사용해 error case를 처리합니다.
Option은 때에 따라서 존재하지 않을 수 있는 값입니다. 1은 Some에, 0은 None에 대응합니다.
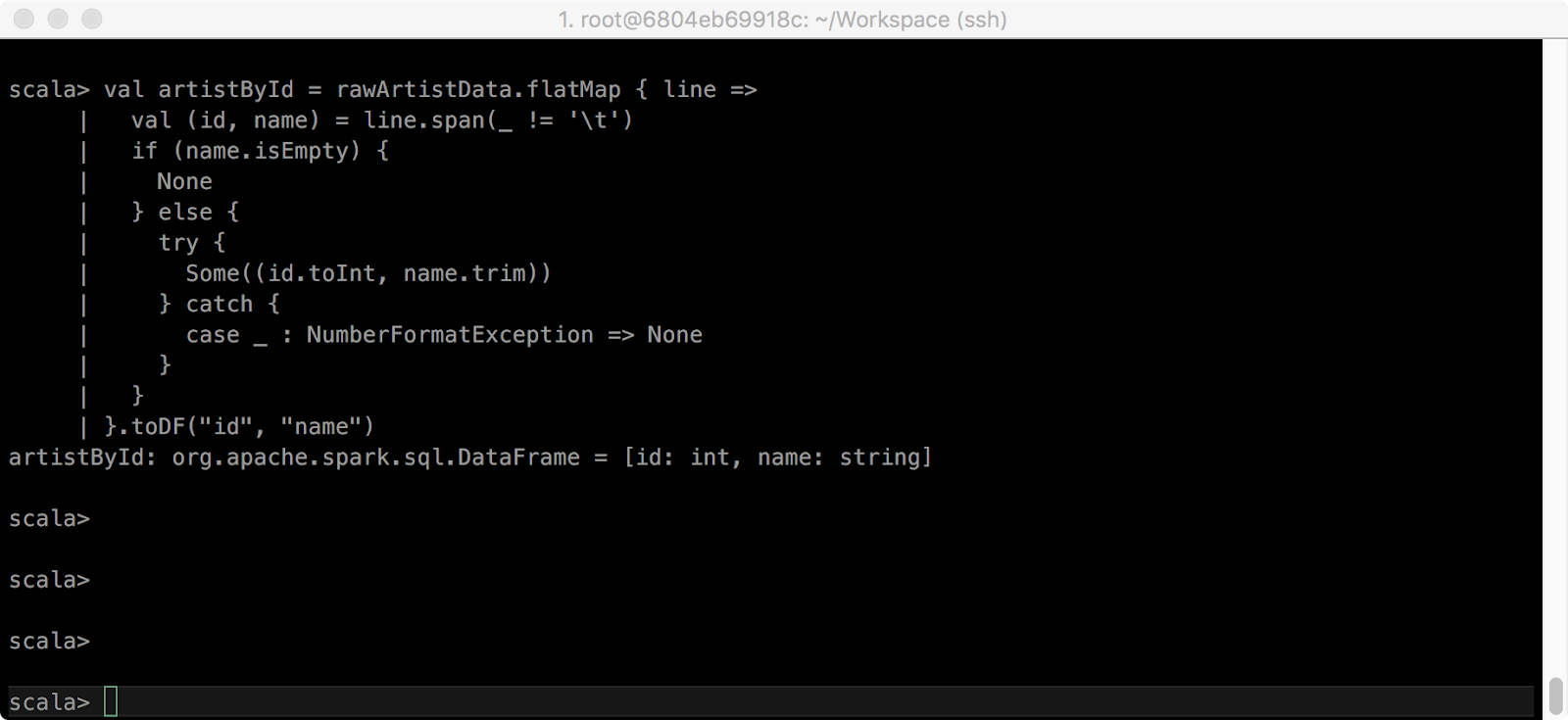
> val artistById = rawArtistData.flatMap { line =>
val (id, name) = line.span(_ != '\t')
if (name.isEmpty) {
None
} else {
try {
Some((id.toInt, name.trim))
} catch {
case _ : NumberFormatException => None
}
}
}.toDF("id", "name")
> artistById.show

이번에는 artist name의 alias 파일을 이용해 alias 정보를 처리합니다.
> val rawArtistAlias = spark.read.textFile("hdfs:///dataset/lastfm/artist_alias.txt")
> val artistAlias = rawArtistAlias.flatMap { line =>
val Array(artist, alias) = line.split('\t')
if(artist.isEmpty) {
None
} else {
Some((artist.toInt, alias.toInt))
}
}.collect().toMap
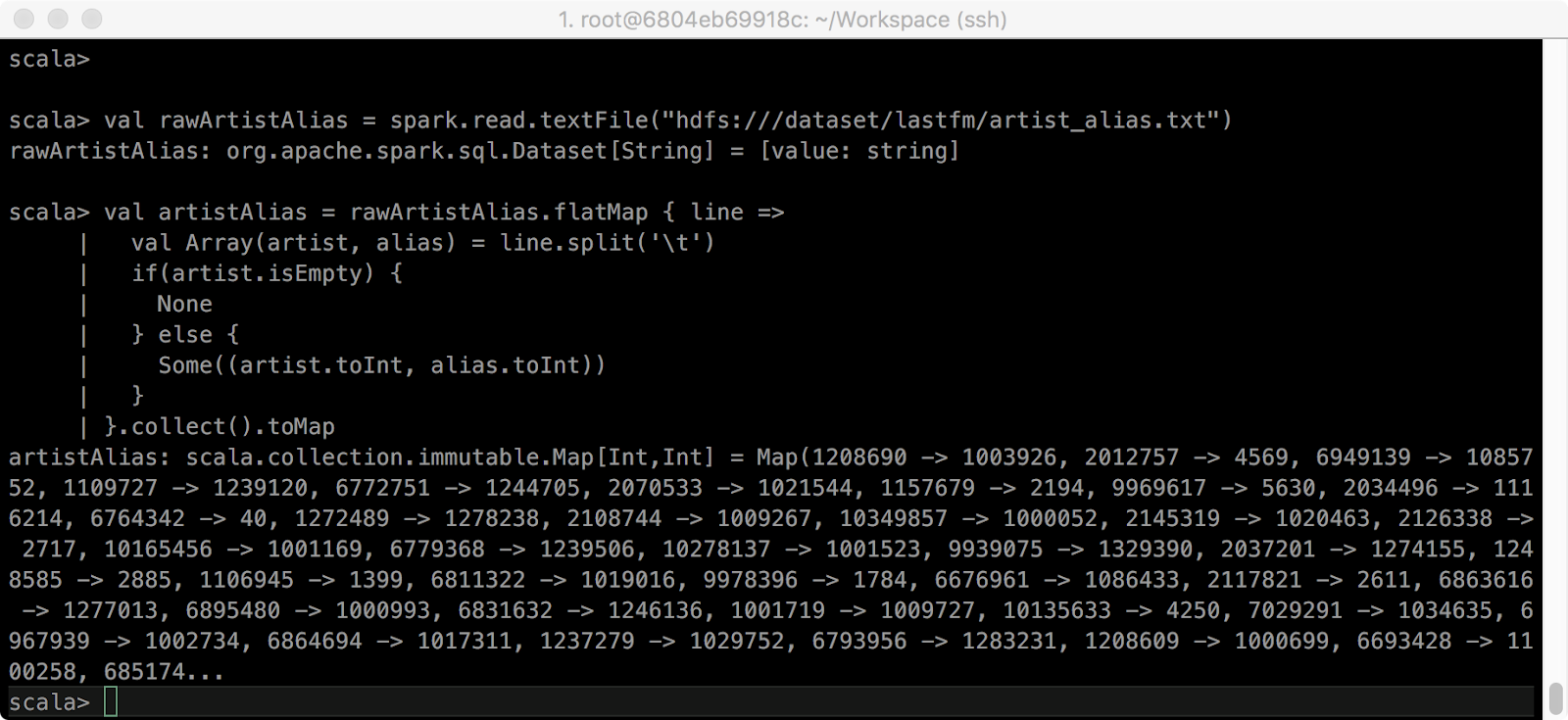
결과를 보면 같은 alias 정보의 artist ID 간에 Map으로 연결된 것을 볼 수 있습니다.
$ symbol을 사용하여 column의 name을 가르킬 수 있습니다.
isin method는 Seq(List)에서 가져옵니다.
위에서 나온 결과의 첫 번째와 두 번째 Map[Int, Int]의 data를 가져와 확인해봅니다.
> artistById.filter($"id" isin(1208690, 1003926)).show
> artistById.filter($"id" isin(2012757, 4569)).show
Alias 정보를 이용해 같은 artist로 처리해야 합니다. 다른 machine인 distributed node에 저장된 분산 RDD data를 전부 처리하기 위해서는 broadcast를 이용합니다. 하나의 JVM에서 여러 task가 실행되므로 Alias 정보를 여러 번 복사하여 보내고 저장하는 것은 비효율적이나, broadcast는 Cluster에 있는 executor 당 하나의 복사본(replication)을 보내고 memory에 유지하도록 합니다. Broadcast[Map[Int, Int]]
Broadcast.value는 간단하게 original data(Map[Int, Int])를 가져옵니다.
> import org.apache.spark.broadcast._
> import org.apache.spark.sql._
> def buildCounts (rawUserArtistData: Dataset[String],
bArtistAlias: Broadcast[Map[Int, Int]]): DataFrame = {
rawUserArtistData.map { line =>
val Array(userID, artistID, count) = line.split(' ').map(_.toInt)
val finalArtistID = bArtistAlias.value.getOrElse(artistID, artistID)
(userID, finalArtistID, count)
}.toDF("user", "artist", "count")
}
위에서 사용된 map.getOrElse(Key, Value)는 map에서 Key가 존재한다면, 일치하는 value를 return하고, Key가 없다면 Value를 return 합니다.
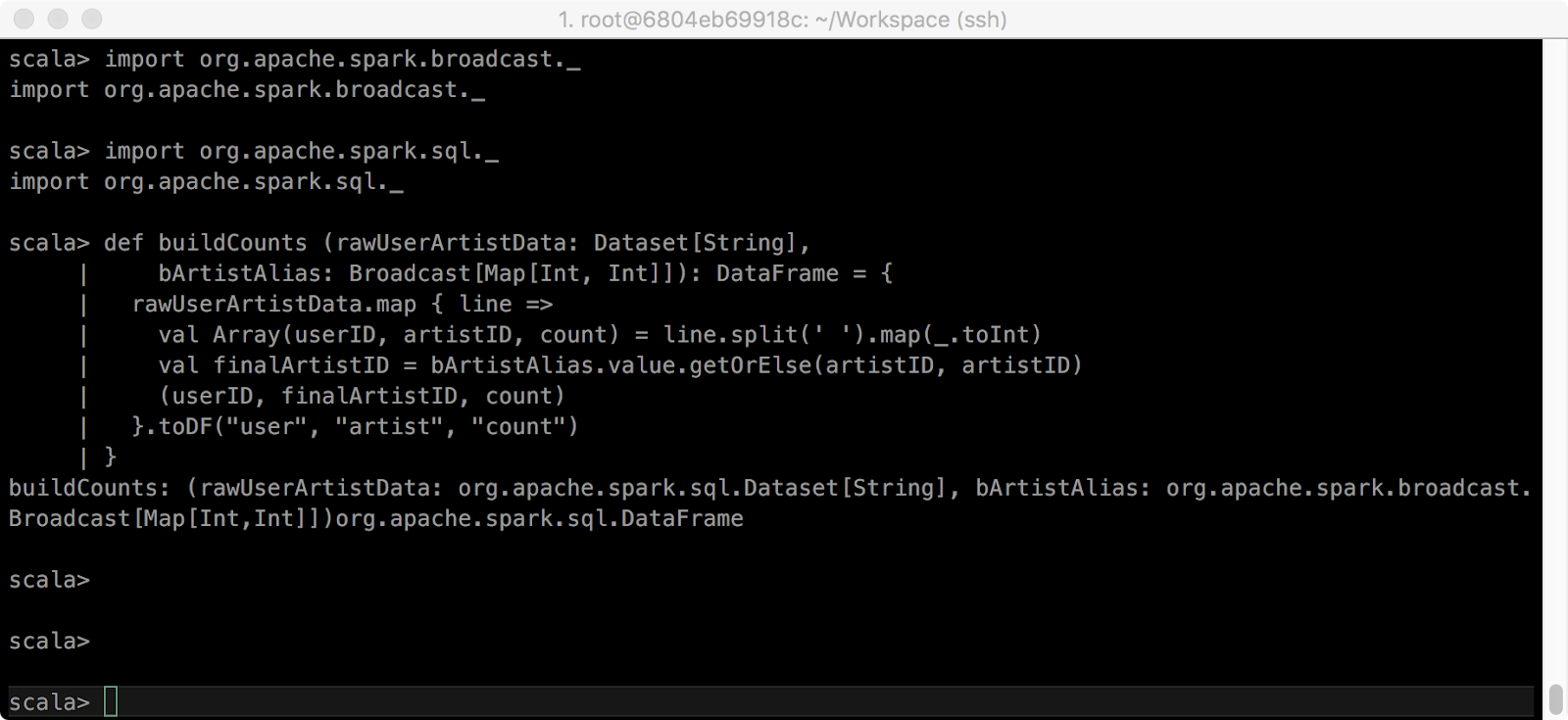
> val bArtistAlias = sc.broadcast(artistAlias)
sc.broadcast를 이용해 broadcast 사용하기 위해서는 변수를 저장해야 합니다.
> val trainData = buildCounts(rawUserArtistData, bArtistAlias)
alias가 적용된 train data-set을 생성하는 buildCounts method를 호출합니다.
> trainData.cache
불필요한 재계산을 위해 cache()를 이용합니다. cache를 호출하면, Spark는 RDD의 연산이 끝나고, 결과를 cluster의 memory에 임시로 저장하여, memory에 유지하도록 합니다. ALS 알고리즘은 이 trainData를 maxIter 만큼 반복하여 수행하기 때문에 cache하는 것이 바람직합니다.
> trainData.show

ALS Model training, predict
> import org.apache.spark.ml.recommendation._
> import scala.util.Random
> val model = new ALS().
setSeed(Random.nextLong()).
setImplicitPrefs(true).
setRank(10).
setRegParam(0.01).
setAlpha(1.0).
setMaxIter(5).
setUserCol("user").
setItemCol("artist").
setRatingCol("count").
setPredictionCol("prediction").
fit(trainData)
ALS Parameter
ALS의 Parameter는 다음과 같습니다.
- setRank : (default : 10) 사용할 feature vector의 size, 더 큰 vector는 더 나은 모델을 만들 수 있지만 계산 비용(cost)이 더 커지며, 오히려 prediction error가 늘어날 수 있기 때문에 최적화(optimization)가 필요합니다.
- setMaxIter : (default : 10)실행할 반복 횟수
- setRegParam : (default : 0.01) Regularization 정규화 parameter
- setImplicitPrefs : (default : false) - Implicit Feedback을 사용할 것인지 false이면 Explicit feedback만 사용합니다.
- setAlpha : (default : 1.0) Implicit ALS에서 신뢰도를 계산하는데 사용되는 상수
- numUserBlocks, numProductBlocks : user와 item을 구분할 block의 개수, 병렬화를 제어한다.
- setSeed() - W와 H의 metrics를 초기화하기 위한 seed를 결정합니다.

training된 model의 weight Factor를 살펴봅시다.
Rank를 10으로 설정했기 때문에 각 user와 item 간의 weight Factor도 10개 입니다.
> model.userFactors.show(truncate=false)
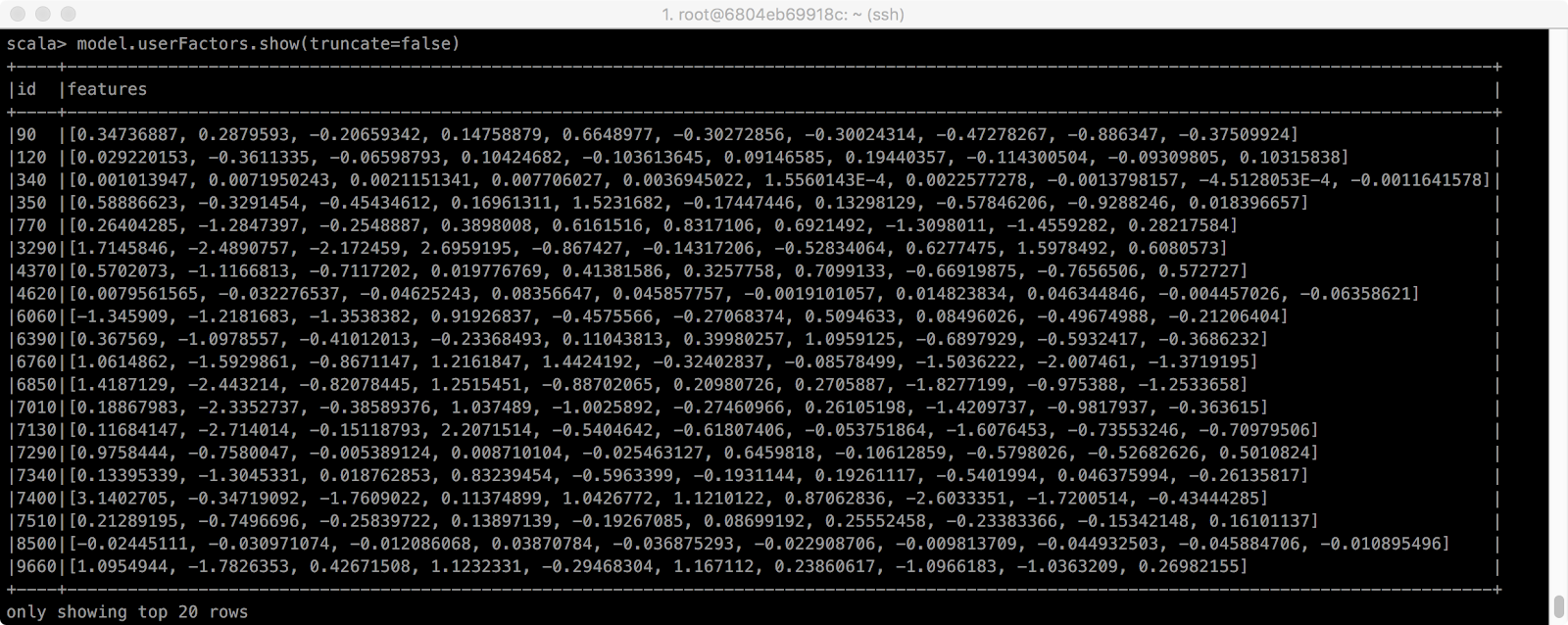
> model.itemFactors.show(truncate=false)

위에서 보여지는 weight Factor와 곱하므로 나머지 모든 missing value를 구할 수 있습니다.

model의 item(artist)이며, itemFactor를 기반으로 user의 artist를 가져옵니다.
lit method는 정해진 row의 특정한 column의 value를 반환합니다.
lit(userID)는 user column의 userID의 value를 반환합니다.
> val userID = 2093760
> val toRecommend = model.itemFactors.select($"id".as("artist")).withColumn("user", lit(userID))
> toRecommend.show
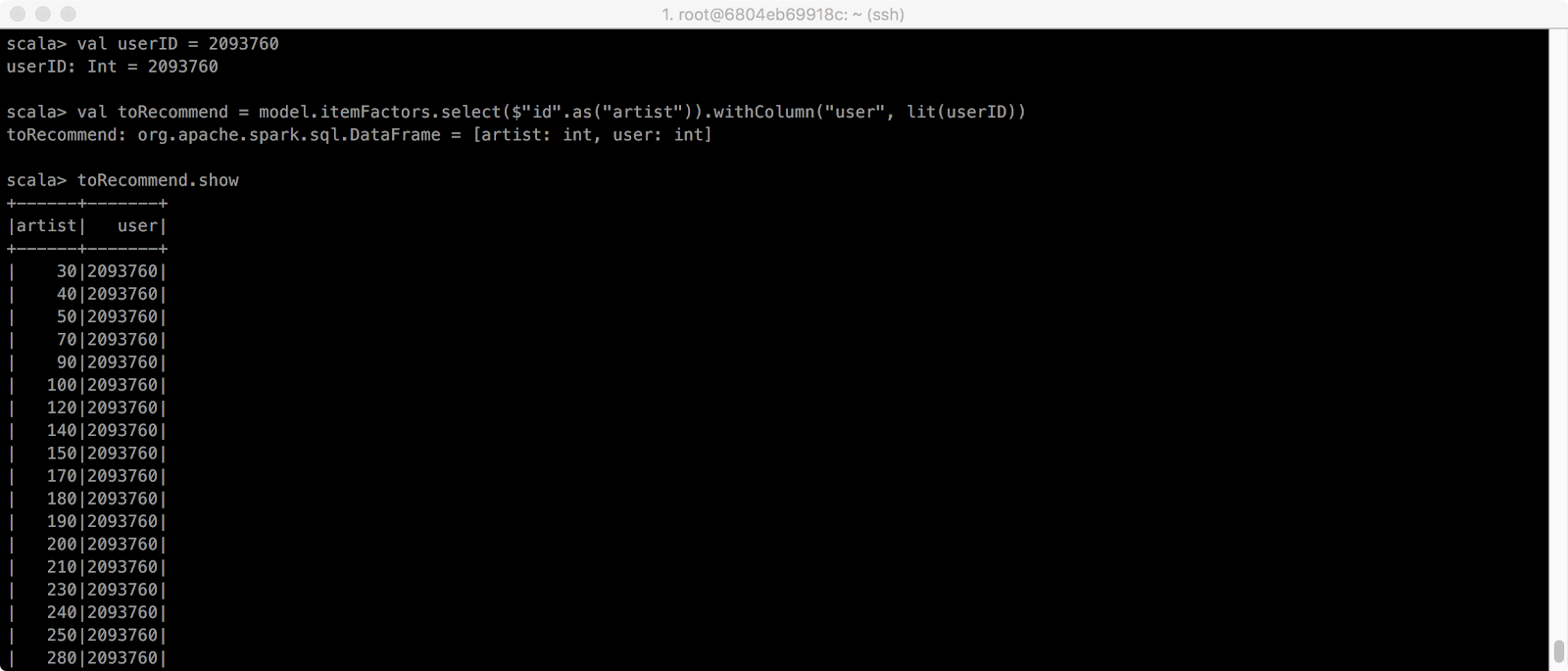
ALS.transform(InputDataset)은 들어온 inputdata로 예측값(predicted value)를 반환합니다.
ALS는 row(행)인 userID(W)와 column(열)인 artistID(H)를 곱셈(multiply)하여 recommendation value를 갖습니다.
> model.transform(toRecommend).show

위에서 나온 값을 내림차순으로 정렬합니다.
> model.transform(toRecommend).orderBy($"prediction".desc).limit(15).show

위에서 구현한 코드로 최종 method를 생성합니다.
> def makeRecommendations(model: ALSModel, userID: Int, howMany: Int): DataFrame = {
val toRecommend = model.itemFactors.select($"id".as("artist")).withColumn("user", lit(userID))
model.transform(toRecommend).select("artist", "prediction").
orderBy($"prediction".desc).
limit(howMany)
}
> val topRecommendations = makeRecommendations(model, userID, 10)
최종적으로 userID가 2093760에게 추천되는 artist의 10명 리스트를 뽑아본 것입니다.

ID를 Artist의 Name으로 변환해봅시다.
> val recommendedArtistIDS = topRecommendations.select("artist").as[Int].collect()
> artistById.filter($"id".isin(recommendedArtistIDS:_*)).show()
userID가 2093760에게는 Hip Hop Artist들이 추천되는 것을 볼 수 있습니다.

'MachineLearning' 카테고리의 다른 글
| Machine Learning - Predicting House Prices : Regression (0) | 2018.01.30 |
|---|---|
| Matrix Factorization Techniques for Recommender Systems (1) | 2018.01.04 |
| Spark Scala Wikipedia dataset (0) | 2017.11.27 |
| DART: Dropouts meet Multiple Additive Regression Trees (0) | 2017.11.14 |
| 01 Scala와 Scala IDE (0) | 2017.11.13 |