Spark Scala Wikipedia dataset Spark와 Scala language를 이용해 Wikipedia의 full-text articles에서 programming language가 출현한 빈도수(occurrences)를 count합니다. wikipedia data를 다운받습니다. $ wget http://alaska.epfl.ch/~dockermoocs/bigdata/wikipedia.dat 다운받은 wikipedia dataset을 hadoop hdfs에 dataset 디렉토리를 생성하여 업로드합니다. $ hdfs dfs -mkdir /dataset/ $ hdfs dfs -put wikipedia.dat /dataset/ 다운 받은 wikipedia dataset 을 살펴봅니다. $ head wikipedia.dat code skeleton을 다운받아 코딩을 진행하면 되겠습니다. $ git clone https://github.com/KimJeongChul/wikipedia $ spark-shell --master spark://MASTER_ADDRESS scala >> 다음을 입력합니다. import org.apache.spark.rdd.RDD $ cd wikipedia $ vi wikipedia/src/main/scala/wikipedia/WikipediaRanking.scala 처음으로 할 작업은 occurrencesOfLang method에서 lang과 RDD[WikipediaArticle]을 parameter로 입력 받아 text 본문에서 lang(language)가 몇 번 출현했는지 count 하여 반환하는 것입니다. def occurrencesOfLang(lang: String, rdd: RDD[WikipediaArticle]): Int = ??? 들어온 RDD의 item에서 text를 space로 split을 합니다. 이후에 RDD.filter와 contains를 이용해 lang이 포함되었는지 확인합니다. 그리고 RDD.count를 이용해 데이터의 개수를 카운트합니다. * RDD.filter : RDD의 item 중 전달받은 function에 만족하는 item을 선택하고 새로운 RDD를 반환합니다. * RDD.count : RDD의 데이터 개수를 카운트한다. * contains : 문자열을 포함하고 있는지 확인한다. def occurrencesOfLang(lang: String, rdd: RDD[WikipediaArticle]): Int = { //rdd.filter(_.text.split(‘ ‘).contains(lang)).count().toInt 위에서 작성한 occurrencesOfLang method를 사용해 Language의 Ranking을 매겨봅니다. ranklangs method는 List로 선언된 langs와 RDD[WikipediaArticle]을 parameter로 입력받아 count 개수를 sorting 해야하며 sorting은 descend(내림 차순)으로 정렬해야 합니다. def rankLangs(langs: List[String], rdd: RDD[WikipediaArticle]): List[(String, Int)] = ??? Language는 다음과 같습니다. val langs = List( 들어온 List에 map함수를 적용해 각 element마다 occurrencesOfLang을 호출하여 count된 결과를 key-value로 만들고, * sortBy : element를 오름차순으로 정렬한다. 내림차순으로 정렬하기 위해서는 reverse - return type은 tuple을 element로 갖는 Seq[(String, Int)]이다. * map RDD의 각 item에 전달받은 function을 적용하여 새로운 RDD를 반환한다. (Transformation) def rankLangs(langs: List[String], rdd: RDD[WikipediaArticle]): List[(String, Int)] = { 중간중간 결과를 확인하기 위해서는 compile 시에 error가 발생하지 않도록 // 또는 /**/ 로 주석 처리를 하고 compile을 진행합니다. $ cd wikipedia $ sbt package $ spark-submit --class wikipedia.WikipediaRunner --master spark://node-1:7077 target/scala-2.11/wikipedia-language-ranking_2.11-0.1-SNAPSHOT.jar hdfs:///dataset/wikipedia.dat 다음 inverted index를 계산합니다. inverted index는 단어 나 숫자와 같은 내용에서 문서 집합 매핑을 저장하는 index data 구조입니다. inverted index의 목적은 빠른 전체 텍스트 검색을 허용합니다. def makeIndex(langs: List[String], rdd: RDD[WikipediaArticle]): RDD[(String, Iterable[WikipediaArticle])] = ??? 여기서는 RDD에 대해서 RDD.flatMap과 RDD.groupByKey method를 사용해야 합니다. RDD.flatMap : flatMap은 map과 flatten을 합성. List에 적용할 수 있는 parameter를 중첩된 List 안의 각 List에 적용해 나온 결과를 하나의 List로 합쳐준다.(Transformation) RDD.groupByKey : RDD의 Key 값으로 Value를 Grouping 하여 RDD를 반환한다. def makeIndex(langs: List[String], rdd: RDD[WikipediaArticle]): RDD[(String, Iterable[WikipediaArticle])] = { 위에서 구현한 makeIndex Method를 이용해 computer language Rank 계산을 더 빠르도록 구현해야 합니다. rankLangs Method 구현과 같이 rankLangsUsingIndex method는 반환을 Language인 String, article의 개수인 Int로 List[(string, Int)] 합니다. 이 목록은 내림차순으로 정렬되어야 합니다. def rankLangsUsingIndex(index: RDD[(String, Iterable[WikipediaArticle])]): List[(String, Int)] = ??? 여기서는 pairRDD의 mapValues를 사용합니다. * pairRDD.mapValues : key-value 쌍의 RDD(pairRDD)를 key 변화 없이 map을 사용해 value에 function을 적용하여 RDD를 반환합니다. pairRDD의 경우 sortBy 이후에 reverse를 사용할 수 없는 parameter에 -를 붙여 내림차순으로 정렬합니다. def rankLangsUsingIndex(index: RDD[(String, Iterable[WikipediaArticle])]): List[(String, Int)] = { inverted index를 계산하지 않고, reduceByKey Method를 이용해 rank를 계산하는 것이 더 효율적이다. rankLangsReduceByKey를 구현합니다. List는 내림차순으로 정렬되어야 합니다. def rankLangsReduceByKey(langs: List[String], rdd: RDD[WikipediaArticle]): List[(String, Int)] = ? * reducBeyKey : key-value로 된 pairRDD에 대해서만 정의되어 있다. def rankLangsReduceByKey(langs: List[String], rdd: RDD[WikipediaArticle]): List[(String, Int)] = { 컴파일 $ sbt package spark-submit으로 실행하면 다음과 같은 시간이 소요됩니다. $ spark-submit --class wikipedia.WikipediaRunner --master spark://node-1:7077 target/scala-2.11/wikipedia-language-ranking_2.11-0.1-SNAPSHOT.jar hdfs:///dataset/wikipedia.dat 1. rankLangs : map 2. rankLangsUsingIndex : groupByKey, mapValue 3. rankLangsReduceByKey : reduceByKey reduceByKey가 제일 적은 시간을 소요하였습니다. 위에서 구현한 3가지의 method는 동일한 output을 가지지만, 소요되는 시간이 다릅니다. map method를 사용하였는데 spark history web ui를 살펴보면 15 jobs가 wikipediaArticle RDD에 대해 각기 실행되었습니다. groupByKey method를 사용하면 모든 key-value 쌍(pair)가 뒤섞입니다. 이것은 네트워크를 통해 전송되는 많은 불필요한 데이터입니다. network overhead가 발생하므로 시간이 소요됩니다. pair를 shuffle하기 위해, Spark는 pair의 key에 partitioning function을 호출합니다. Spark는 Memory에 저장할 수 있는 것보다 더 많은 데이터가 single executor에 있을 시, disk(memory 보다 느림)를 사용합니다. 이 때 disk overhead 발생합니다. reduceByKey가 제일 적은 시간을 소요한 이유는 Spark가 data를 shuffle하기전에 output을 각 partition의 공통 key 결합할 수 있다는 것을 알고 있습니다. 이후에 동일한 machine으로 pair가 shuffle되어 lambda function이 호출되고, 각 partition의 모든 값을 reduce하여 최종 output을 산출합니다.wikipedia data download
code download
case class WikipediaArticle(title: String, text: String) {
def mentionsLanguage(lang: String): Boolean = text.split(' ').contains(lang)
}
def parse(line: String): WikipediaArticle = {
val subs = "</title><text>"
val i = line.indexOf(subs)
val title = line.substring(14, i)
val text = line.substring(i + subs.length, line.length-16)
WikipediaArticle(title, text)
}
val wikiRdd = sc.textFile("hdfs:///dataset/wikipedia.dat").map(parse)
wikiRdd.take(3)Coding
Problem 0 : Occurrences Of Language
rdd.filter(x => x.mentionsLanguage(lang)).count().toInt
}Problem 1 : rank of Language
"JavaScript", "Java", "PHP", "Python", "C#", "C++", "Ruby", "CSS",
"Objective-C", "Perl", "Scala", "Haskell", "MATLAB", "Clojure", "Groovy")
langs.map(lang => (lang, occurrencesOfLang(lang, rdd))).sortBy(_._2).reverse
}compile
Problem 2
여기서는 inverted index를 programming language의 이름에서 적어도 한 번 이상 출현한 WikipediaArticle 매핑하는 inverted index를 계산하는 method를 구현합니다. 이 method는 RDD[(String, Iterable[WikipediaArticle])를 반환하며, RDD는 주어진 language의 대해 한 쌍이 되도록 생성합니다.
val result = rdd.flatMap(wikipedia_article => {
val existLangArticle = langs.filter(lang => wikipedia_article.mentionsLanguage(lang))
existLangArticle.map(lang => (lang, wikipedia_article))
})
result.groupByKey
}Problem 3
index.mapValues(_.size).sortBy(-_._2).collect().toList
}Problem 4
rdd.flatMap(article => {
langs.filter(lang => article.mentionsLanguage(lang)).map((_, 1))
}).reduceByKey(_ + _).sortBy(-_._2).collect().toList
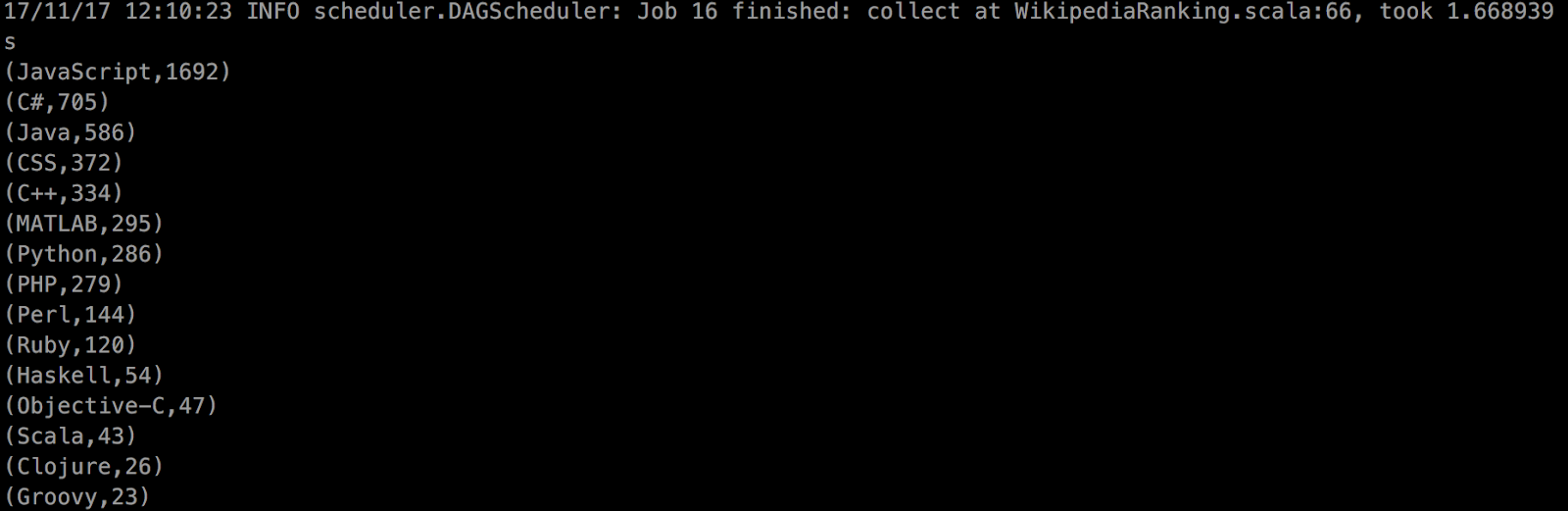
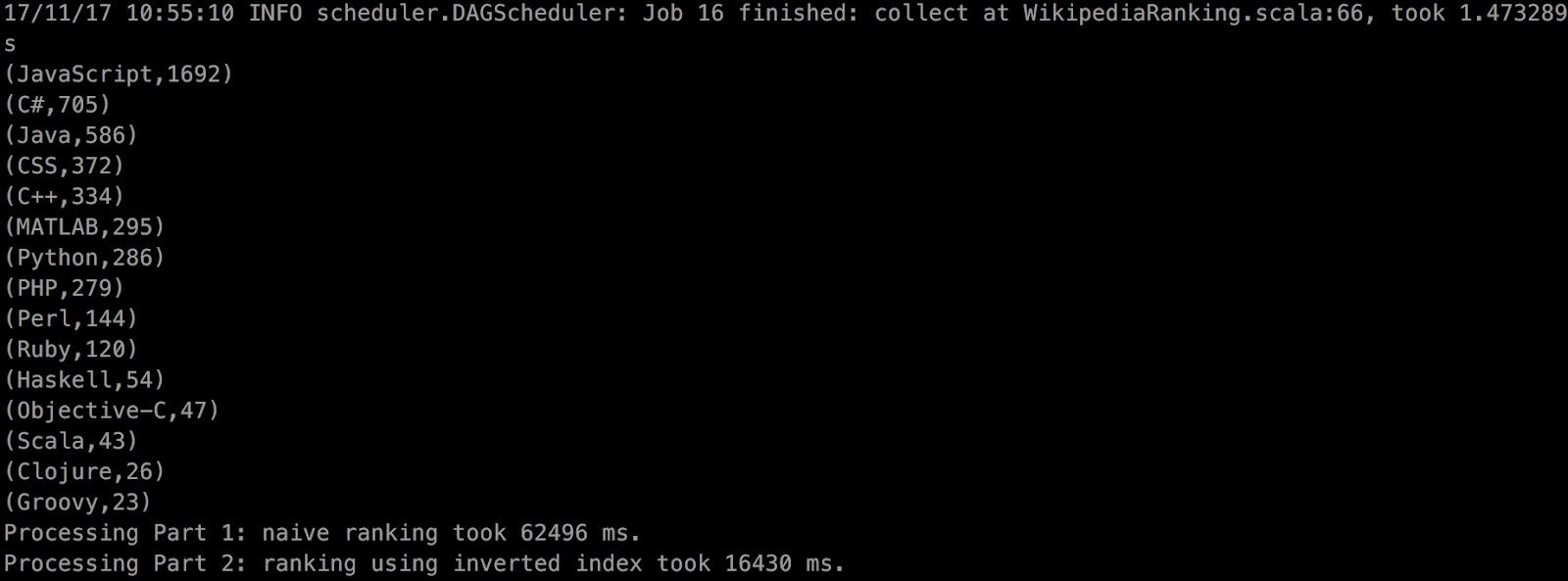
}결과
성능 측정 분석
1. rankLangs - map
2. rankLangsUsingIndex - groupByKey
3. rankLangsReduceByKey - reduceByKey












'MachineLearning' 카테고리의 다른 글
| Matrix Factorization Techniques for Recommender Systems (1) | 2018.01.04 |
|---|---|
| Spark MLlib ALS lastfm dataset (0) | 2017.11.28 |
| DART: Dropouts meet Multiple Additive Regression Trees (0) | 2017.11.14 |
| 01 Scala와 Scala IDE (0) | 2017.11.13 |
| Bayesian Optimization (2) | 2017.10.31 |