
Jeongchul Kim
R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 이해 본문
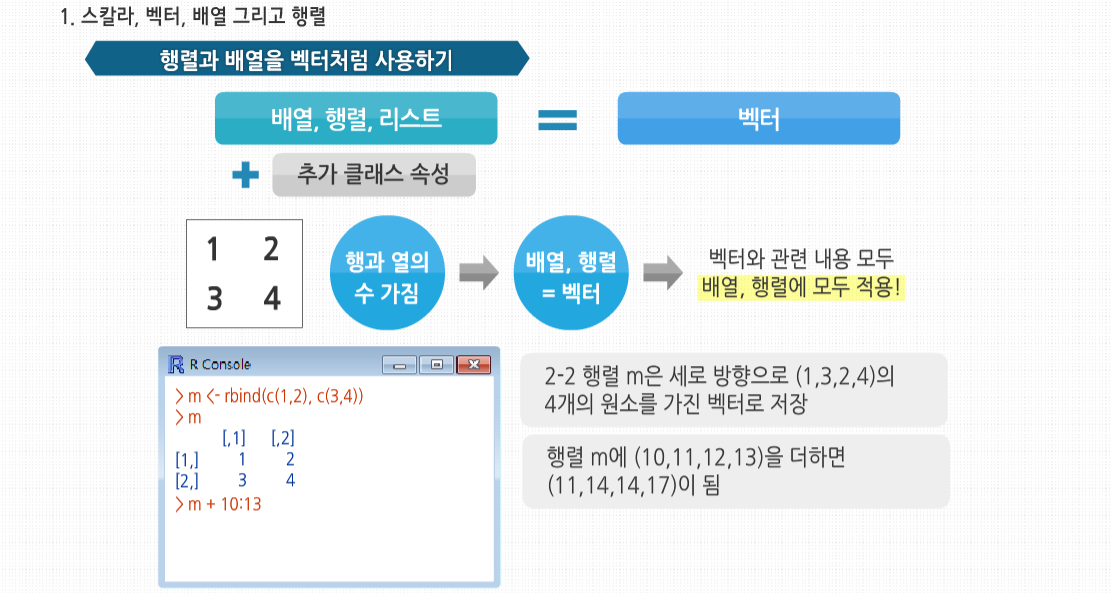
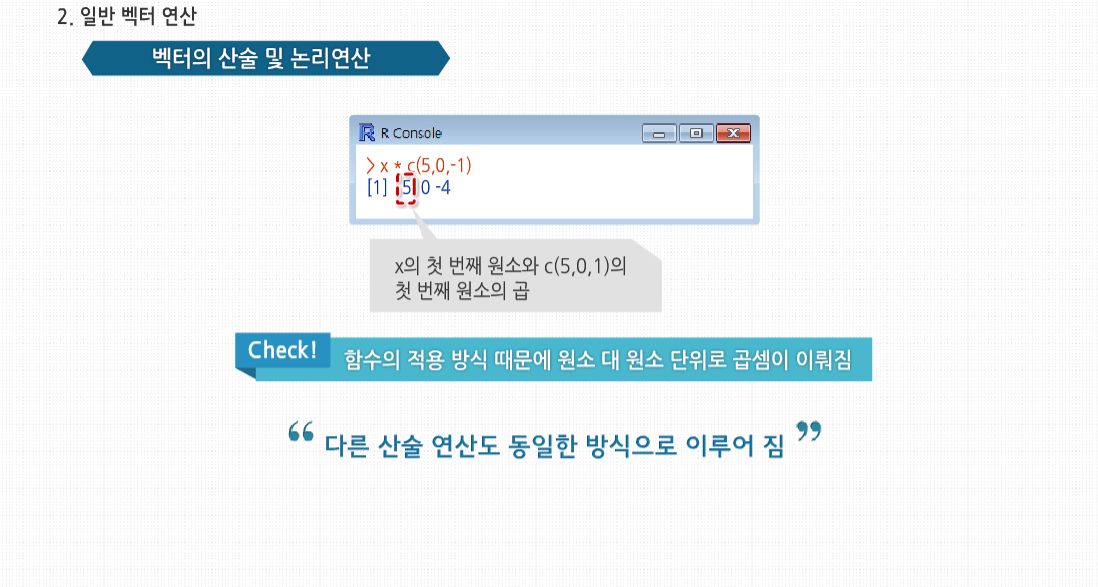
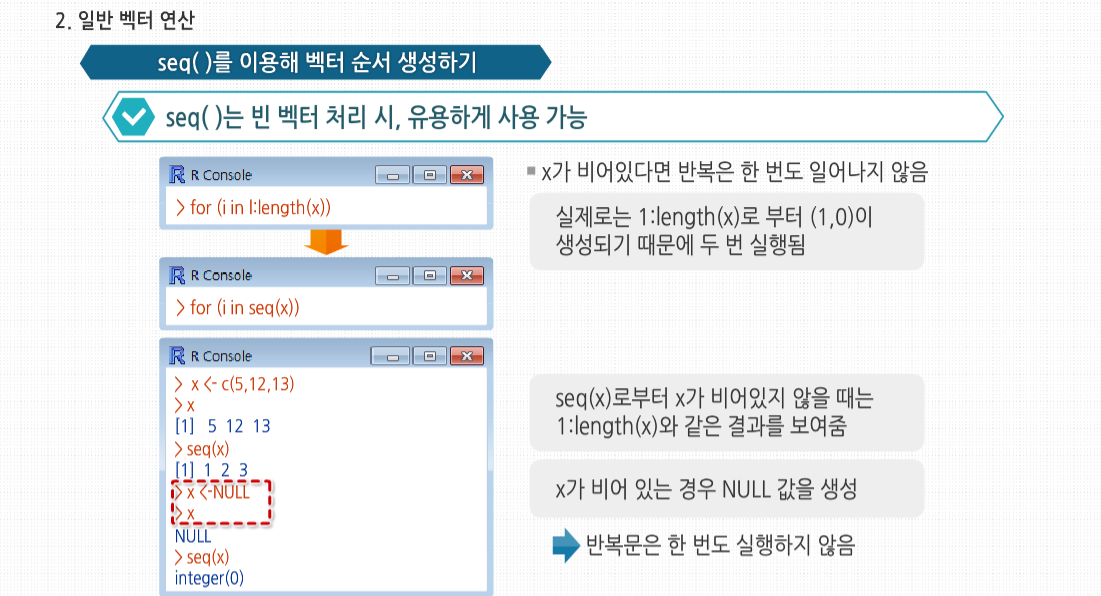
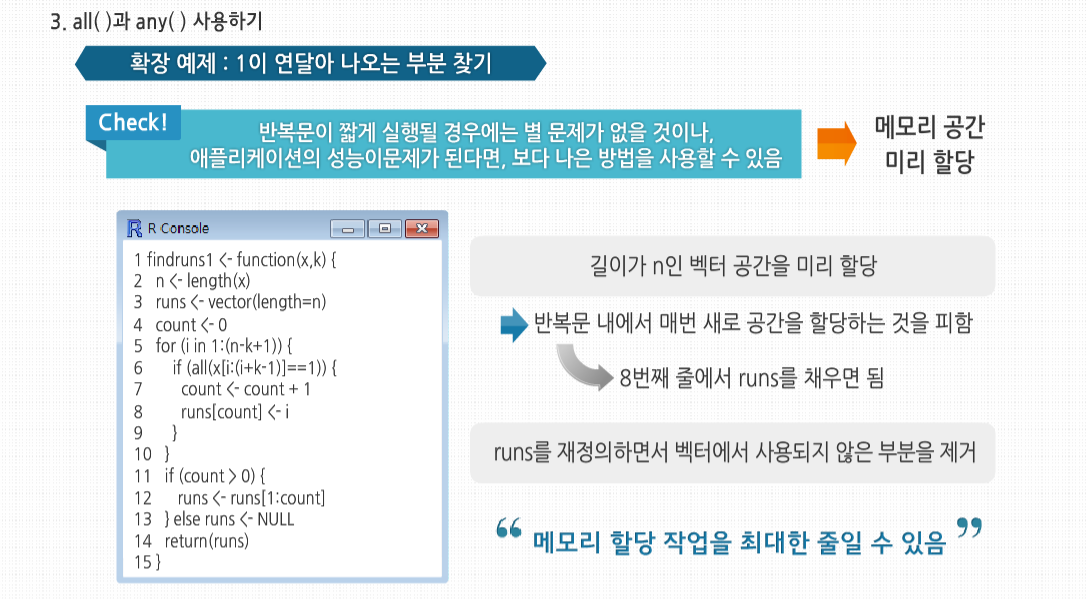
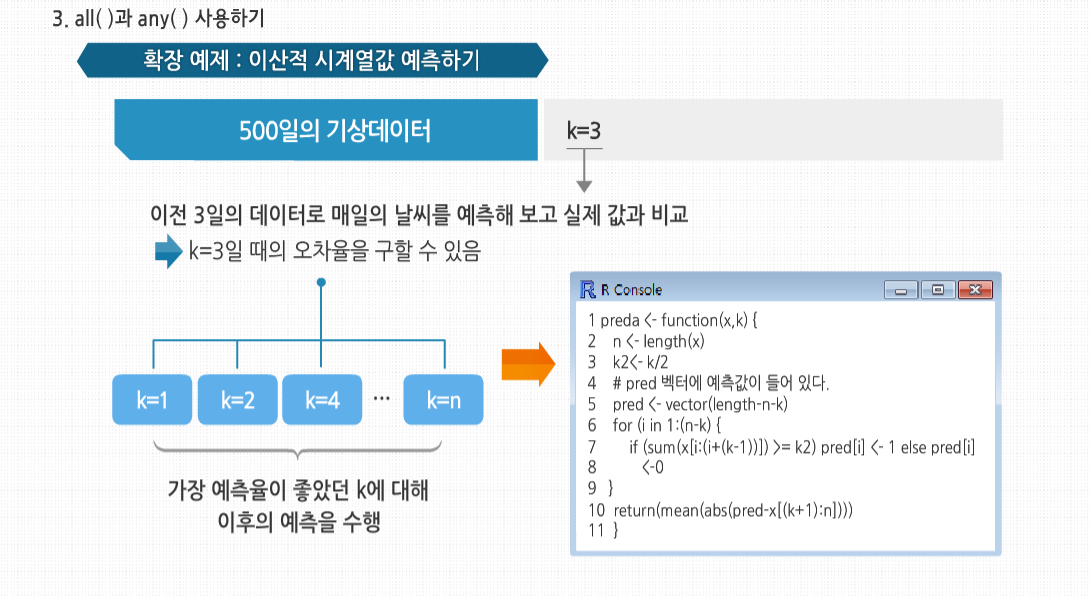
R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 이해 학습을 시작하기에 앞서, 스칼라와 벡터의 개념에 대해 살펴봅시다. 스칼라와 벡터는 물리적 현상을 양적으로 표현하는 방법입니다. 스칼라는 수치값만으로 표시할 수 있는 양을 말하며 넓이, 시간, 온도 등을 이야기합니다. 스칼라가 크기만을 나타내는 물리량이라면, 벡터는 크기와 동시에 방향을 갖는 물리량으로서 변위, 속도, 가속도, 힘 등을 이야기합니다 스칼라, 벡터, 배열 그리고 행렬의 기초 스칼라, 벡터, 배열 그리고 행렬의 기초 많은 프로그래밍 언어에서, 벡터 변수는 한 개의 숫자로 이뤄진 변수인 스칼라와는 다르게 취급됩니다. C코드를 보면, 컴파일러가 x라는 하나의 정수와 y라는 3개의 원소로 이뤄진 정수형 배열을 위한 공간을 할당하도록 요청합니다. 그러나 R에서는 실제로 숫자의 경우 하나의 원소를 가진 벡터형으로 취급되기 때문에 실제로 숫자 값은존재하지 않습니다. R의 변수형은 형식(Mode)으로 불립니다. 벡터의 모든 원소는 정수형, 숫자형, 문자 혹은 문자열, 논리형(불형), 복소수형 같은 형식을 가집니다. 현재 프로그램에서 사용중인 x라는 변수의형식은 typeof(x)를 호출해 확인할 수 있습니다. C나 파이썬 같은 알고리즘 계열의 언어에서 사용하는 벡터의인덱스와 달리, R의 벡터 인덱스는 1부터 시작합니다. 벡터는 C의 배열처럼 저장되므로 파이썬에서 사용하는 것처럼 원소를 추가하거나 삭제할 수 없습니다. 벡터의크기는 처음 만들어질 때 정해지는데, 만약 원소를 추가하거나 삭제하고 싶다면, 벡터를 새로 할당해야 합니다. 예를 들어 4개의 원소로 이뤄진 벡터의 가운데에 새 원소를 추가해 보겠습니다. 이 예제에서 4개의 원소를 가진벡터를 먼저 만든 후 그것을 x에 할당했습니다. 새로운 숫자 168을 세 번째와 네 번째 원소 사이에 넣기 위해 x의 처음 세 원소를 묶고, 168과 x의 네 번째 원소를 연결했습니다. 이렇게 x를 전혀 변경하지 않은 채 새로운 5개의 원소를 가진 벡터를 생성했습니다. 그리고 새롭게 만들어진 벡터를 x에 할당했습니다. 결과적으로 변수 x에 저장된 벡터는 변경된 것처럼 보이지만, 실제로‘새롭게 만든’ 벡터를 x에 저장하는 것입니다. 이 차이는 미미해 보이지만 여러 의미를 갖고 있습니다. 이는 어떠한 경우에 R의 빠른 성능을 제한하는 요인이 될 수 있습니다. length() 함수를 이용하면 벡터의 길이를 파악할 수 있습니다. 예를 들어 보면 이 예제에서는 이미 x의 길이를 알고 있습니다. 그러므로 굳이 찾아 볼 필요는 없습니다. 하지만 일반적인 함수 코드를 작성하다 보면, 벡터 변수의 길이를 알아야 할 때가 종종 있습니다. 예를 들어 값이 들어 있음이 분명한 벡터 변수에서 1이 처음 나오는 위치를 찾아야 하는 함수가 필요하다고 가정해보겠습니다. 이에 대해 이와 같이 코드를 작성할 수 있습니다. 그렇다고 이 방법이 반드시 효율적인 것은 아닙니다. length() 함수를 사용하지 않으면 first1() 함수에서 x의 길이를 정의하는 n이라는 두 번째 변수를 추가로 정의해주어야 합니다. 이 경우 이와 같은 반복문은 동작하지 않음을 기억하도록 합시다. 이렇게 접근할 경우 원하는 원소의 인덱스를 검색하지 못하는 문제가 발생합니다. 그러므로 이와 같은 경우에는 x의 길이를 계산하는 반복문을 사용해야 합니다. 한 가지 더 주의 할 점은 반복문을 사용할 경우 length(x)가 0인 경우가 있을 수 있으므로 주의해서 코딩해야 합니다. 만약 for 반복문에 1:lengh(x)를 사용했을 경우 어떻게 되는지 살펴보겠습니다. 이 반복문은 i는 1의 값을 가졌다가 0의 값을 가지므로, 벡터 x가 비어있는 경우에는 우리가 원하는 대로 동작하지 않습니다. 이를 위한 안전한 방법으로 seg()라는 고급 R함수를 사용하는 방법이 있습니다. 배열과 행렬 및 리스트는 사실 벡터입니다. 추가 클래스 속성을 갖고 있을 뿐입니다. 예를 들어 행렬은 행과 열의 수를 갖고 있습니다. 그리고 배열이나 행렬은 사실 벡터입니다. 벡터에 대해 소개한 내용들이 배열이나 행렬에도 모두 적용된다는 것은 매우 중요한 사실입니다. 예제를 살펴보면 행렬 m은 세로 방향으로 (1,3,2,4)의 4개의 원소를가진 벡터로 저장됩니다. 행렬 m에 (10,11,12,13)을 더하면 (11,14,14,17)이 됩니다. 하지만 R은 현재 행렬 연산 중임을 기억하기 때문에 결과 값은 2-2 행렬로 보여 줍니다. 일반적으로 C언어와 같이 컴파일이 필요한 언어는 인터프리터나 컴파일러에 변수가 있음을 알려주기 위해 변수 사용 전에 이를 ‘선언’해 줄 필요가 있습니다. 다음의 C의 경우를 봅시다. 하지만, 파이썬이나 펄 등 대부분의 스크립트 언어와 마찬가지로, R에서도 변수를 선언할 필요는 없습니다. 이 코드는 이전에 z에 대해 전혀 언급하지 않아도 문법적으로 완벽합니다. 이는 또한 통용되는 방식이기도 합니다. 그러나 벡터의 특정 원소를 언급하고 싶다면, 그 내용을 미리 R에 알려줘야 합니다. 예를 들어 y가 5와 12라는 두 값을 가진 벡터를 만들어 보겠습니다. 다음처럼 만들면 동작하지 않을 것입니다. 그 대신 y를 먼저 생성해 줘야 합니다. 이 방식도 가능합니다. 이는 오른쪽에서 먼저 새 벡터를 생성한 후 y에 연결해 준 것입니다. R에서 y[2]처럼바로 값을 적용하는 표현을 쓸 수 없는 이유는 R의 함수형 언어의 특성에 기인한 것입니다. 개별 벡터 원소를 읽고 값을 연결한다는 면에서 볼 때 변수를 선언하지 않으므로 형식에 제한도 없습니다. 따라서 다음 예제를 순차적으로 실행해도 완벽하게 실행됩니다. 우선 x는 숫자 함수와 연결됐다가 다시 문자열과 연결됩니다. C/C++ 프로그래머를 위해 다시 한번 얘기하자면, x는 데이터형이 고정되어 있지 않으므로 서로 다른 시간대에 서로 다른 객체를 가리킬 수 있습니다. 스칼라, 벡터, 배열, 그리고 행렬의 활용 스칼라, 벡터, 배열 그리고 행렬의 활용 두 벡터를 사용하는 연산을 할 때 각각의 길이가 같아야 한다면, R은 자동으로 더 짧은 쪽을 재사용하거나 혹은 반복 사용해 긴 쪽에 맞추도록 합니다.이 코드를 보면 더 짧은 벡터는 재사용돼 실제로는 이와 같이 실행되었습니다. 좀 더 복잡한 예제를 살펴 봅시다. 행렬이 긴 벡터라는 사실을 다시 한번 기억하세요. x는 3-2 행렬이지만, 이 역시 R에서 열 순서로 저장된 6개의 원소를 이뤄진 벡터입니다. 저장 관점에서 보자면, x는 c(1,2,3,4,5,6)과 같습니다. 이 6개의 원소로 이뤄진 벡터에 원소가 2개인 벡터를 더했으므로, 더해진 벡터는 두 번 더 반복 되 6개의 원소가 됩니다. 이는 곧 이와 같이 했다는 뜻입니다. 더불어 c(1,2,1,2,1,2)는 더해지기 전에 벡터에서 이와 같은 형태의 행렬로 변환됩니다. 결국 결과는 다음을 계산한 것과 같습니다. R은 함수형 언어입니다. 제시된 코드에서 나오는 + 같은 기호도 실제로는 함수입니다. 스칼라는 하나의 원소로 이뤄진 벡터이므로 벡터끼리도 더할 수 있습니다. 이때 + 연산은 원소 단위로 이루어집니다. 선형대수에 익숙한 사람이라면 다음과 같이 두 벡터를 곱했을 때에 어떤 결과가 나타나는지를 확인하면 아마 당황할 것입니다. 하지만* 함수의 적용 방식 때문에 원소 대 원소 단위로 곱셈이 이뤄진다는 것을 기억해야 합니다. 처음 결과값 5는 x의 첫 번째 원소 1과 c(5,0,1)의 첫 번째 원소 5의 곱으로 나온 결과이고, 다른 값도 마찬가지입니다. 다른 산술 연산 역시 마찬가지 방식으로 이뤄집니다. R에서 가장 중요하고 자주 사용되는 연산 중 하나가 벡터 인덱싱입니다. 이 기능은 벡터의 특정 위치에 있는 원소들을뽑아내 다른 벡터를 생성한다든가 할 때 유용합니다. 형식은 vector1[vector2]로, vector1의 vector2의 인덱스에 해당하는 원소들을 뽑아냅니다. 이때, 중복 가능합니다. 인덱스를 음수로 표시하는 것은 해당 위치의 원소만 결과에서 제거하고 싶다는 뜻입니다. 이런 기능을 활용할 때length()함수가 종종 유용하게 사용됩니다. 예를 들어 z라는 벡터에서 마지막 원소를 제외한 모든 원소를 추출하고싶다고 가정하겠습니다. 이 때는 다음과 같이 코드를 작성합니다. 아니면 다음과 같이 더 간단하게 할 수도 있습니다. 이는 z[1:2]같이 쓰는 것보다 보편적인 방법입니다. 프로그램은 길이가 2인 벡터만 다루지 않을 것이므로, 두 번째 접근 방법이 보다 보편적입니다. 벡터를 생성하는 데에 유용하게 사용되는 몇 가지 R 연산자가 있습니다. 이 중 :연산자는 일정 범위의 숫자로 이뤄진 벡터를 만들어 줍니다. 반복문에서 연산자를 여러 개를 사용할 경우 순서에 신경 써야 합니다. 이때, 1:i-1에서 :은 –연산보다 우선합니다. 1:i가 먼저 실행되어 1:2가 됩니다. 그 후 이 식에서 1을 뺍니다. 이 경우 2개의 원소를 가진 벡터에서 1개의 원소를 가진 벡터를 빼는 것으로, 벡터가 반복 사용됩니다. 원소 1개의 벡터(1)은 1:2와 같은 길이인(1,1)로 확장되고, 원소 별 계산이 이뤄지면서 벡터 (0,1)이 도출됩니다. 반면 1:(i-1)의 경우는 괄호가 : 보다 우선합니다. i에서 1을 빼게 되므로 예제 하단의 결과로서 1:1이 나옵니다. :를 일반화한 함수는 seq() 혹은 sequence로, 산술연산을 통해 순서를 만듭니다. 예를 들어 3:8은 각 원소가 1씩 차이 나는 벡터 (3,4,5,6,7,8)를 만들어 내는 것처럼, 다음과 같이 하면 3씩 차이가 나는 것도 만들 수 있습니다. 간격은0.1처럼 꼭 정수가 아니어도 가능합니다. seq()를 유용하게 사용하는 방법 중 하나는 빈 벡터를 처리할 때 쓰는 것입니다. 이 경우 x가 비어있다면 반복은 한 번도 일어나지 않을 것입니다. 하지만 실제로는 1:length(x)로 부터 (1,0)이 생성되기 때문에 두 번 실행됩니다.이 코드는 다음과 같이 수정할 수 있습니다. 이를 간단하게 테스트해 보면 seq(x)로부터 x가 비어있지 않을 때는 1:length(x)와 같은 결과를 보여주고, x가 비어 있는 경우 NULL 값을 생성하므로 반복문은 한 번도 실행하지 않습니다. 1 rep() 혹은 repeat 함수는 긴 벡터를 손쉽게 같은 숫자로 채워줍니다. rep(x,times)로 호출하면, times * length(x)개의 원소로 채워진 벡터가 생성됩니다. 즉, x가 times만큼 복제되는 것입니다. 다음 예제를 봅시다. each라는 인수는 약간 특이한 행동을 하게 됩니다. x를 복사해 사이사이에 끼워 넣는 것입니다. any()와 all() 함수는 편리한 축약식입니다. 이 함수들은 일부 혹은 모든 인수가 TRUE인지 알려줍니다. 예를 들어R이 다음 내용을 수행했다고 합시다. 일단 x 8인지 검사하고 다음과 같은 결과를 낼 것 입니다. any() 함수는각각의 값이 TRUE인지 알려줍니다. all() 함수는 유사하게 동작하나 모든 값에 대해 TRUE가 맞는지를 알려줍니다. 1과 0으로만 이뤄진 벡터에서 1이 연달아 나오는 부분을 찾고 싶다고 가정해 봅시다. 예를 들어 (1,0,0,1,1,1,0,1,1)벡터에는 4번째부터 3의 길이로 연달아 나오고, 1이 2번 나오는 부분을 찾으면 4, 5, 8번째 입니다. 그럼 직접 만든함수인 fineruns(c(1,0,0,1,1,1,0,1,1), 2)를 실행해 (4,5,8)이 나오는지 살펴 봅시다. 다음 코드를 볼까요? 5번째 줄에서 x[1]부터 시작해 k에 따라서 변해가는 x[1:(1+k-1)] x의 값 중 확인해야 하는 범위를 정해 주고, all()은 이 범위 내에서 연속돼 나오는 부분이 있는 지 확인해 줍니다. 그럼 테스트해 봅시다. 이전 코드에서 all()을 제대로 사용했다고 해도, runs라는 벡터를 만드는 것 자체는 그다지 좋은 선택이 아닙니다. 벡터 할당은 소모적인 작업 입니다. 다음 코드는 c(runs, 1)이라는 새 벡터를 매번 할당해 전체 실행 속도를 느리게 만들고 있습니다. 즉, 새 벡터를 runs에 할당하는 것과는 무관합니다. 벡터 메모리 공간 할당은 여전히 실행되고 있습니다. 반복문이 짧게 실행될 경우에는 별 문제가 없을 것입니다. 하지만 애플리케이션의 성능이 문제가 된다면, 보다 나은방법을 사용할 수 있습니다. 한 가지 방법은 다음과 같이 메모리 공간을 미리 할당하는 것 입니다. 코드의 2번째 줄에서 길이가 n인 벡터 공간을 미리 할당했습니다. 이렇게 해서 반복문 내에서 매번 새로 공간을 할당하는 것을 피할 수 있습니다. 단지 8번째 줄에서 runs를 채우면 됩니다. 함수를 끝내기 전에 12번째 줄에서 runs를 재정의하면서벡터에서 사용되지 않은 부분을 제거합니다. 이런 식으로 첫 번째 버전의 코드에 비해, 메모리 할당 작업을 2번으로최대한 크게 줄일 수 있습니다. 정말로 빠른 속도가 필요하다면, 이를 C로 작성하는 방안도 고려해 볼 수 있습니다. 매 시간 단위마다 0 혹은 1값을 갖는 데이터가 있다고 가정해 봅시다. 구체적으로 이것이 기상데이터라 하겠습니다.비가 오면 1값을 갖고, 비가 오지 않으면 0값을 갖습니다. 최근 비가 왔든 오지 않았든 상관없이 내일 비가 올지 여부를 예측한다고 합시다. 정확하게 어떤 수 k에 대해, 지난 k일의 기상 기록을 기반으로 해 내일의 날씨를 예측할수 있을 것입니다. 여기서는 다수결의 원칙을 사용하여, 이전 k 기간 동안 최소 k/2의 값이 1이었다면 1로, 아닌 경우0으로 예측합니다. 예를 들어 k = 3이고 지난 세 기간 동안의 데이터가 1,0,1이라면 다음 기간의 값은 1이라 예측합니다. 하지만 k값은 어떻게 골라야 할까요? 만약 너무 작은 값을 고른다면, 예측할 때 사용하는 값이 너무 작아집니다. 너무 큰 값을 고른다면 너무 먼 과거의 값으로 미래 값을 예측하게 되기 때문에 신뢰성이 떨어질 것 입니다. 이런 문제에 대한 일반적인 대처 방안은 트레이닝 세트로 불리는, 이미 알려진 데이터를 이용해, k 값이 어떤 경우 가장 성능이 좋은지 확인해 보는 것 입니다. 00일의 기상 데이터를 갖고 k=3이라고 가정해 봅시다. k값은 통한 예측 능력을 판단하기 위해, 이전 3일의 데이터로 매일의 날씨를 예측해 보고 실제 값과 비교해 보는 것입니다. 이를 통해 k=3일 때의 오차율을 구할 수 있습니다. k=1, k=2, k=4 등 만족할 수 있는 k의 최대값까지에 대해서도 같은 식으로 반복합니다. 그리고 가장 예측율이 좋았던k에 대해 이후의 예측을 수행합니다. 이 경우 R 코드는 어떻게 작성할까요? 직관적으로는 다음과 같이 접근해 볼 수 있습니다. 이 코드의 핵심은 7번째 줄입니다. 여기서 우리는 1, . . . , i+k-1일의 k개의 데이터로 k+1일의 데이터를 예측합니다. 이때 예측 결과는 pred[1]에 저장 됩니다. 그러므로 이 기간 동안 1이 몇 번 나왔는지 세어야 합니다. 0과 1로만 된 데이터를 사용하므로, 1개의 개수는 이 기간의 x[j]의 데이터를 모두 더하면 되고, 이 값은 다음과 같이 간단하게 얻을 수 있습니다. sum()과 벡터 인덱싱은 반복문을 사용하지 않고 이런 계산을 간단하게 하도록 도와주므로, 코드를 단순하고 빠르게 만들게 해줍니다. 이는 R의 대표적인 장점입니다. 10번째 줄에서도 이런 특성을 볼 수 있습니다. 여기서 pred는 예측 값이 들어 있고, x[ (k+1) :n]은 예측한 날짜에 대한 실제 값이 들어 있습니다. 첫 번째 값에서 두 번째 값을 빼면 0, 1, -1 중 한 값이 나올 것입니다. 여기서 1이나 -1의 실제 값은 1인데 0으로 예측했거나, 반대의 경우에 발생하는 오차입니다. 이 값에 abs() 함수를 사용해절대값을 취하면 0이나 1이 나오는데, 1의 경우는 오류가 발생한 경우입니다. 이런 식으로 어느 날에 오류가 발생하는지 알 수 있습니다. 그럼 이제 오차율을 계산하는 것이 남았습니다. 0과 1로 된 데이터의 평균은 1의 비율과 같다는 수학적 사실을 활용해 mean() 함수를 통해 이를 구할 것입니다. 이 방법은 R에서 보통 사용되는 트릭입니다. 앞에서 pred() 함수를꽤 단단히 구현했고, 그래서 코드가 단순하고 함축적입니다. 단, 이 경우 느려질 가능성이 있습니다. 반복문에서 연속적으로 봤을 때, 두 벡터 값으로 인한 차이를 계산하기 위해 sum()이 매번 호출됩니다. k가 매우 작은 경우가아니라면 이는 속도를 매우 느리게 할 수 있습니다. 그러므로 이전에 계산된 값을 활용할 수 있도록 코드를 다시 작성해 봅시다. 매번 반복문 실행 시, 새로 덧셈을 하는 대신에 이전에 더한 값을 갱신할 것입니다. 이 코드에서 가장 중요한 부분은 9번째 줄입니다. 이 줄에서는 sm이란 변수에 가장 오래된 원소의 값인 x[i-1]을 빼고 새 데이터인 x[i+k-1]을 더해 값을 갱신합니다. 이 문제는벡터의 누적합을 구해 주는 R 함수인 cumsum()을 사용해 접근할 수도 있습니다. 다음 예제를 봅시다. 여기서 y의누적합은 5=5, 5+2=7, 5+2+(-3)=4, 5+2+(-3)+8 =12로, cumsum()에서 반환한 값과 같습니다. preda()의 sum(x[1:(i+k-1)]은 cumsum()의 차를 이용해 다음과 같이 나타낼 수 있습니다. 다음처럼 x에서 연속된k개의 원소만큼 sum()을 합니다. 이 대신에 k개의 원소가 시작하는 부분과 끝나는 부분 누적합의 차이를 통해 같은 값을 구합니다. 이때 누적합의 벡터는 0부터 시작하도록 고정시켜 준다는 점을 기억합시다. 이는 i=1인 경우의처리를 위해 필요합니다. presb()에서 두 개의 연산을 사용한 것에 비해, preds()의 방식에서는 반복문에서 1개의 뺄셈 연산만을 사용한다는 것을 알 수 있습니다.1. 스칼라, 벡터, 배열 그리고 행렬
2. 선언
1. 재사용
2. 일반 벡터 연산
3. all()과 any() 사용하기



























'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
|---|---|
| R 3.2.1 프로그래밍 - 행렬과 배열 만들기 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 시작과 종료 및 도움말 시작하기 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - R의 개요와 데이터 구조 (0) | 2016.05.07 |