
Jeongchul Kim
R 3.2.1 프로그래밍 - 행렬과 배열의 활용 본문
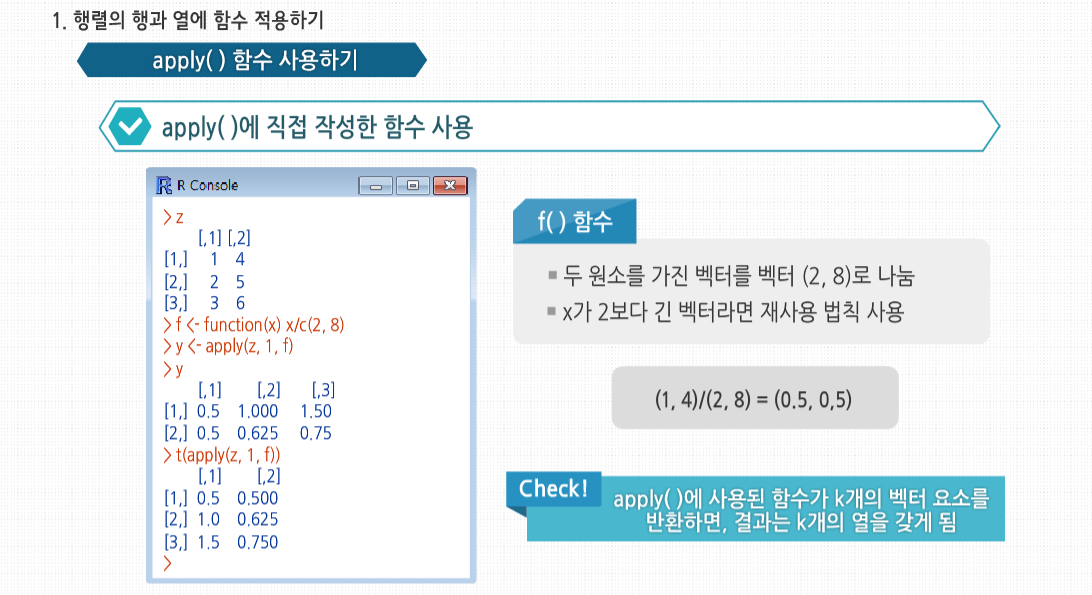
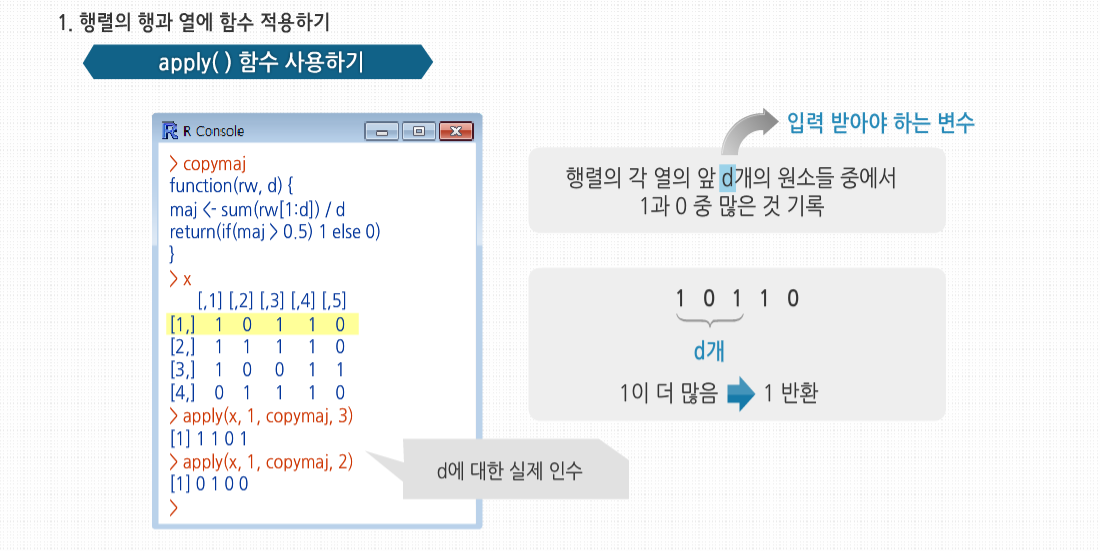
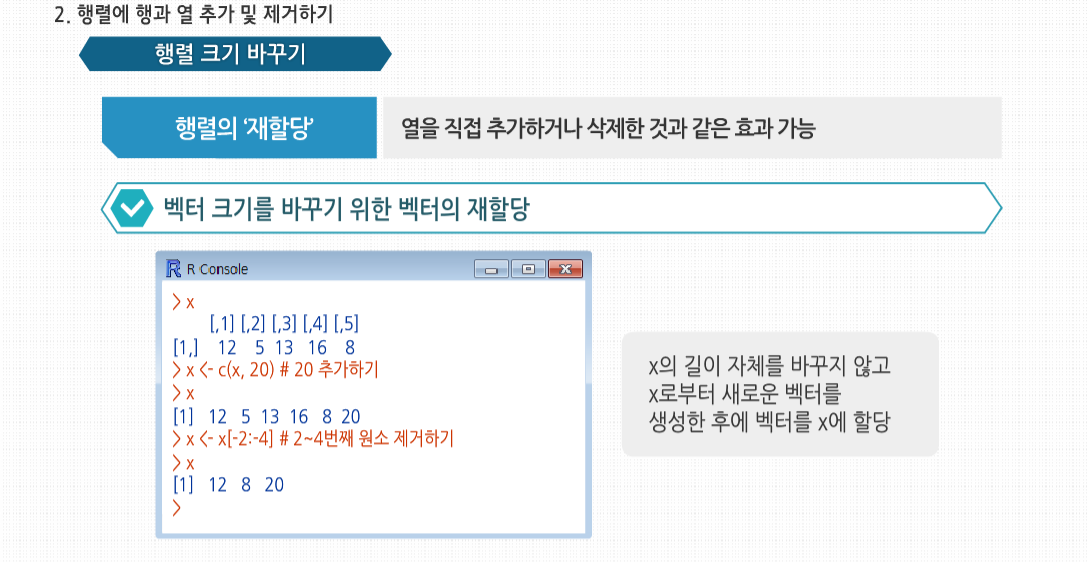
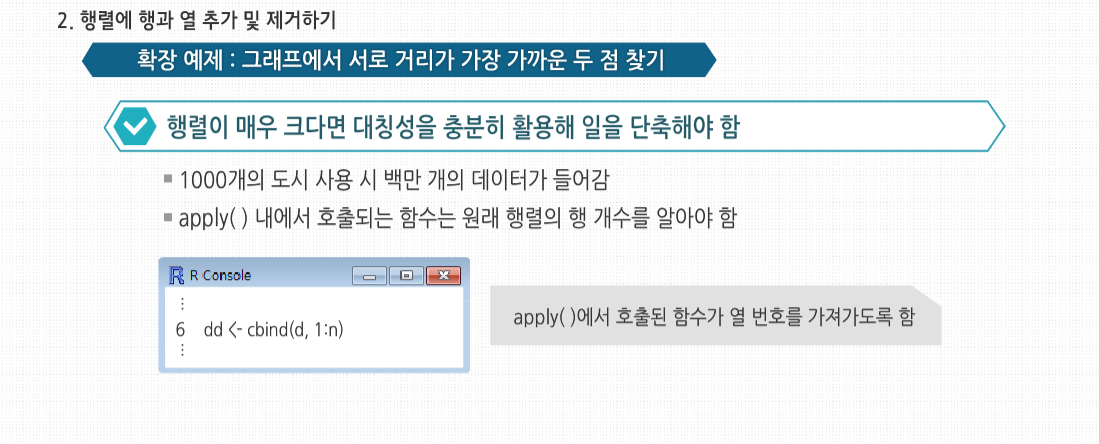
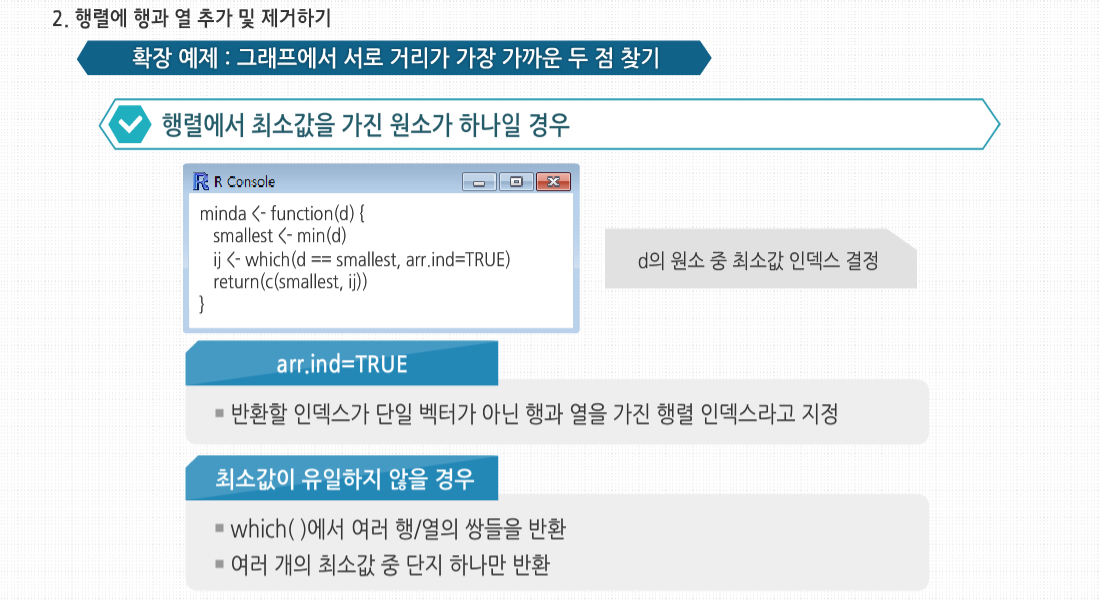
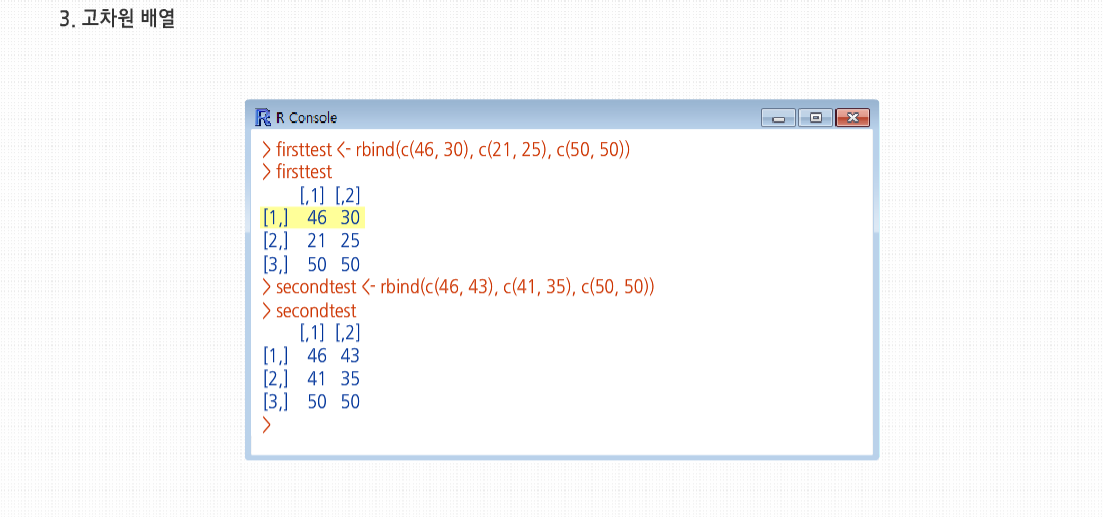
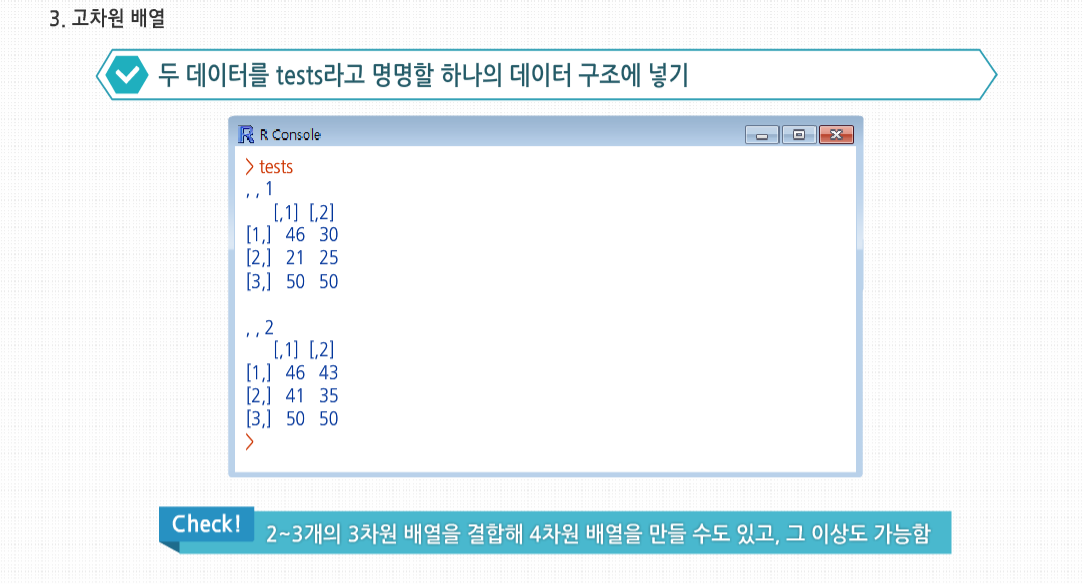
R 3.2.1 프로그래밍 - 행렬과 배열의 활용 행렬에서의 곱셈에 대해 살펴봅시다. 행렬에서는 곱셈의 교환법칙이 성립하지 않습니다. 즉 A*B 와 B*A의 값이 다를 수 있습니다. 이는 우리 실생활과 관련 지어서 생각할 수 있는데요. 어떤 작용을 먼저 하느냐, 그 순서에 따라 그 결과가 달라진다는 것을 의미합니다. 사실 이러한 행렬로 많은 과학 공학 분야에서 혁명적인 이론들이 탄생해 왔습니다. 수학의 식 하나에서 현재의 과학문명이 태동하고 발전해 온 것이지요. 행렬의 응용 행렬의 응용 R에서 가장 유명하고 가장 많이 사용되는 기능 중 하나는 apply(), tapply(), lapply() 같은 *apply()군 함수입니다. R에서 사용자 정의 함수를 행렬의 각 행이나 각 열에 적용할 수 있게 apply() 사용법에 대해 알아봅시다. 이는 행렬에서 apply를 사용하는 일반적인 형태입니다. 인수들을 살펴보면 m은 행렬이고, dimcode는 차원수로, 1인 경우 함수를 행에적용하고 2인 경우 열에 적용합니다. f는 적용할 함수이고, fargs는 f에 필요한 인수의 집합으로 선택 사항입니다. 하나의 예로서 행렬 z의 각 행에 R의 mean() 함수를 적용해 봅시다. 이 예의 경우 이전에는 colMeans() 함수를 사용했지만, 여기서는 apply()를 사용해 간단하게 적용했습니다. apply()에 mean() 함수 같은 R 내장 함수뿐만 아니라 직접 작성한 함수 사용도 가능합니다. 직접 만든 f() 함수는 두 원소를 가진 벡터를 벡터 (2, 8)로 나눕니다. 이때 만약 x가 2보다 긴 벡터라면 재사용 법칙이 사용됩니다. apply()를호출해 f()를 z의 각 행에 적용합니다. 이때 첫 행은 (1, 4)이므로 f()가 호출됐을 때 형식 인수 x에 실제로 대응되는실제 인수는 (1, 4)입니다. 그러므로 R에서는 (1, 4)/(2, 8)을 계산하게 되고, R의 원소 단위 벡터 계산 식에 의해 (0.5, 0,5)가 나오게 됩니다. 다음 두 열에 대한 계산도 비슷합니다. 이 결과값이 3-2 행렬이 아닌 2-3 행렬이라는 것에 놀랐을 수도 있습니다. 처음 계산해 나온 값인 (0.5, 0.5)는 apply() 결과의 첫 번째 행이 아닌, 첫 번째 열이 됩니다. 이는 apply()의 특성입니다. 만약 apply()에 사용된 함수가 k개의 벡터 요소를 반환한다면, 결과는 k개의 열을 갖게 됩니다. 필요 시에는 다음과 같이 행렬 치환 함수를 사용해 변환할 수 있습니다. 만약 함수가 단일 숫자를 반환한다면, 최종 결과는 행렬이 아닌 벡터일 것입니다. 적용된 함수는 최소 1개의 인수를 필요로 합니다. 앞서 보았듯이 형식 인수에는 행렬의 하나의 행 또는 열이라는 실제 인수가 대입될 것입니다. 일부 경우에는 이 함수에 필요한 추가 인수를 apply() 내에서 함수명 뒤에 넣어줘야 합니다. 예를 들어 1과 0으로 이뤄진 행렬로 다음과 같은 벡터를 만들고 싶다고 해봅시다. 행렬의 각 열에 해당하는 벡터의 원소에 그 열의 앞 d개의 원소들 중에서 1과 0 중 많은 것을 기록하는 것입니다. 여기서 d는 입력 받아야 하는 변수입니다. 여기서 3과 2라는 값은 copymaj()의 형식 인수 d에 대한 실제 인수입니다. 이때 x의 1열에서 무슨 일이 일어났는지 봅시다. (1, 0, 1, 1, 0)으로 구성된 행에서 앞에서부터 d개의 원소를 가져오면 (1, 0, 1)이 됩니다. 이 세 원소 중 1이 더 많으므로 copymaj()는 1을 반환합니다. 그러므로 apply()의 결과값의 첫 번째 원소는 1이 됩니다. 보통 생각하는 것과 다르게, apply()를 사용하는 것은 보통 코드의 속도를 높여주지 않습니다. 이것을 사용할 때의 장점은 코드를 매우 짧게 해주기 때문에 읽고 고치기 쉽고, 루프를 사용할 때 발생할 수 있는 오류들을 피할 수 있게해주는 것입니다. 게다가 R이 병렬 처리에 보다 근접할수록, apply() 같은 함수는 점점 더 중요해집니다. 예를 들어 snow 패키지의 clusterApply() 함수는 R에서 다양한 네트워크의 노드에 부분행렬의 데이터를 분배합니다. 이후 각 노드에서 기본적으로 각 부분행렬을 갖고 주어진 함수를 적용할 수 있게 하는 병렬 프로세스로 처리하도록 합니다. 통계에서 ‘아웃라이더’란 다른 대부분의 관측치와 확연하게 다른 개별 데이터들을 말합니다. 예를 들면 워싱턴 주시민들의 소득 중 빌 게이츠의 소득 같은 값을 말합니다. 이런 데이터는 보통 잘못된 데이터로 의심을 하게 되거나 대표값으로는 사용하지 않습니다. 아웃라이더를 찾기 위해 수많은 방법들이 고안됐으며, 여기서는 이 중 매우 단순한 것을 구현해 보겠습니다. 소매점 판매 데이터가 기록된 행렬 rs가 있습니다. 데이터의 각 열은 각각 다른 매장에 대한 데이터로, 기록된 내용은 일별 판매량입니다. 의심할 여지 없이 극도로 단순하게 접근해서, 각 매장별 가장 특이한수치를 정의하는 코드를 작성해 봅시다. 이 수치는 각 매장의 중간값에서 가장 많이 벗어난 수치로 정의할 것입니다. 코드는 이와 같습니다. 다음과 같이 함수를 호출합니다. 우선 apply() 내에서 사용할 함수가 필요합니다. 이 함수는 판매량 행렬의 각 열에 적용될 것이므로 주어진 열에서 가장 특이한 값의 인덱스를 찾아주는 함수를 작성해야 합니다. 3, 4번째 줄에서 사용한 사용자 정의 함수 findol()이 이 역할을 할 것입니다. 여기서는 함수 안에 다른 함수를 정의했는데, 내부에 정의한 함수가 짧은 경우에 종종 사용되는 방식입니다. xrow-mdn 식에서는 보통 1 이상의 길이의 벡터에서 한 개의 원소로 된 벡터인 하나의 숫자를 빼는 연산을 합니다. 이때 뺄셈 연산 이전에 xrow에 대응되도록 mdn은 재사용돼 확장된 형태로 사용됩니다. 그 후 5번째 줄에서 R 함수인 which.max()를 사용합니다. max()는 벡터 내의 최대값을 찾지만, which.max()는 ‘어디에’ 최대값이 있는지를 알려줍니다. 이것이 여기서 필요한 기능입니다. 마지막으로 7번째 줄에서 R이 findol()을 x의 각 열에 적용하게 해, 각 열에서 가장 특이한 값의 인덱스를 찾도록 합니다. 기술적으로 봤을 때 행렬은 고정된 길이와 차원을 가지고 있기 때문에 행이나 열을 추가/삭제할 수 없습니다. 하지만 행렬을 ‘재할당’할 수 있고, 이를 이용해 열을 직접 추가하거나 삭제한 것과 같은 효과를 볼 수 있습니다. 벡터 크기를 바꾸기 위해 벡터를 어떻게 재할당했는지 기억해 봅시다. 첫 번째의 경우 x의 길이는 원래 5였으나, 원소 추가 후 재할당함으로써 6으로 늘렸습니다. x의 길이 자체를 바꾸지 않고 x로부터 새로운 벡터를 생성한 후에 벡터를 x에 할당했습니다. 행렬 크기를 바꾸는 데에도 비슷한 방식이 사용됩니다. 예를 들면 rbind()(행 붙이기)와 cbind()(열 붙이기) 함수를 사용해 행렬에 열과 행을 추가할 수 있습니다. 여기서 cbind()는 x의 행들과 1로 이뤄진 행을 결합한 새 행렬을 생성합니다. 여기서는 이 결과를 바로 출력하도록 했으나, 이와 같이 z 혹은 다른 변수에 할당할 수 있습니다. 이때 재사용 역시 가능합니다. 여기서 1의 값은 재사용돼 네 개의 1이 있는 벡터가 됐습니다. 또한 간단한 행렬을 만드는 데에도 rbind()와 cbind() 함수를 사용할 수 있습니다. 하지만 rbind()와 cbind()를 사용할 때는 조심해야 합니다. 벡터를 새로 만드는 것처럼, 행렬을 새로 만드는 것 역시 시간이 상당히 걸립니다. 어쨌든 행렬도 벡터이기 때문입니다. 다음 코드에서 cbind()를 사용해 새로운 행렬을 생성합니다. 새 행렬은 z에 재할당됩니다. 즉 이 행렬의 이름을 z로 붙여준 것입니다. 같은 이름을 가졌던 원래 행렬은 사라집니다. 하지만 여기서 중요한 점은 새 행렬을 만드는 데 시간 페널티가 발생했다는 것입니다. 만약 이런 작업을 반복문 내에서 계속 수행했다면, 누적 페널티는 매우 커졌을 것입니다. 그러므로 만약 반복문 내에서 행이나 열을 한 번에 하나씩 추가하고 결과적으로 행렬이 커지기를 원한다면, 애초에 큰 행렬을 할당하는 것이 낫습니다. 처음에는 비어있지만, 한 번에 하나씩 행이나 열을 채워넣는 방식이 매번 메모리에 행렬을 재할당하는 것보다 시간 절약 면에서 나을 것입니다. 재할당하는 방식으로 행이나 열을 제거하는 것 역시 가능합니다. 그래프에서 점 간 거리를 찾는 것은 전산과 수업에서 사용되는 가장 일반적인 예제이며 통계 및 데이터 과학에서도 쓰입니다. 예를 들자면 몇몇 클러스터링 알고리즘이나 유전체 응용 프로그램에서도 사용됩니다. 여기서는 도시 간의 거리를 찾는 일반적인 예제를 사용하겠습니다. i열 j행의 원소는 i번 도시와 j번 도시 간의 거리를 갖고 있는 식으로 거리가 기록된 행렬을 입력하면, 도시 간을 한 번에 가는 거리 중 최소값과 이 최소값을 만족하는 도시 쌍을 출력하는 함수가 필요하다고 해봅시다. 이를 위한 코드는 이렇습니다. 새로 정의한 함수를 사용한 예제입니다. 최소값은 3행, 4열의 6입니다. apply()는 여기서도 중요한 역할을 합니다. 행렬에서 0이 아닌 최소값을 찾아야 하는데요.각 열에서 최소값을 찾아 이 중 가장 작은 값을 찾는 것입니다. 하지만 역시 코드상 논리 진행은 보다 복잡해집니다. 중요한 점 하나는 i번 도시에서 j번 도시까지의 거리는 j번에서 i번까지의 거리와 동일하므로, 행렬이 ‘대칭’이라는 것입니다. 그러므로 n이 행렬의 행과 열의 수라면, 첫 번째 행에서최소값을 찾을 때 1+1, 1+2, . . . , n번 원소를 확인해야 합니다. 이것은 곧 코드의 7번 줄에서 apply()를 적용할 때 d의 마지막 열에서는 건너뛰어도 된다는 의미입니다. 행렬이 매우 크다면 대칭성을 충분히 활용해 일을 단축해야 합니다. 하지만 이 경우 문제가 생깁니다. 기본적인 계산을 위해 apply() 내에서 호출되는 함수는 원래 행렬의 행 개수를 알아야 합니다. apply()에서는 이런 정보를 함수에 넘겨주지 않습니다. 그래서 코드의 6번째 줄에서는 행렬에 열 번호로 이뤄진 추가 행을 더해, apply()에서 호출된 함수가 열 번호를 가져갈 수 있도록 했습니다. apply()에서 호출한 함수는 코드의 16번째 줄부터 시작되는 imin() 함수로, 이 함수는 형식 인수 x에 정의된 열에서 최소값을 찾아줍니다. 이 함수는 주어진 열의 최소값뿐 아니라 최소값의 인덱스도 같이 반환합니다. 행렬 q에서 1열에서 imin()이 호출됐을 때, 최소값은 8이고 이에 해당하는 인덱스는 4입니다. 후자의 목적을 위해서는 19번째 줄에 사용된 R 함수 which.min()이 편리합니다. 20번째 줄에 주목할 필요가 있습니다. 행렬이 대칭적이라는 것을 상기합시다. 19번째 줄의 (i+1) : (ix-1)에서 보다시피 각 열의 앞부분은 연산을 건너뜁니다. 하지만 이것을 같은 줄의 which.min()역시 (i+1) : (ix-1) 범위 내에서의 최소값의 인덱스를 반환한다는 말입니다. 예제 행렬 q의 3열에서는 출력 인덱스가 4가 아닌 1이 될 것입니다. 그러므로 코드의 20번째 줄에서처럼 i를 더해주는 단계를 추가해야 합니다.마지막으로 apply()의 결과를 적절히 사용하는 방법은 조금 복잡합니다. 행렬 q에 apply()를 적용하면 행렬 wmins가 반환될 것입니다. 행렬의 두 번째 행은 d의 여러 행의 대각 상위 부분의 최소값들이 들어있습니다. 예를 들어 wmins의 첫째 열에는, q의 첫째 행에서 최소값은 행의 4번 인덱스에 있는 8이라는 정보가 들어 있습니다. 코드의 10번째 줄에서는행별로 나온 최소값 중 가장 작은 값은 i에 지정해 주는데, 예제의 q에서는 6에 해당됩니다. 11번째 줄에서는 j에 최소값이 위치한 행의 위치를 지정해주는데, q의 경우에는 4입니다. 다르게 말하자면 최종적으로 나온 최소값은 i행 j열에 있다는 정보로, 이는 12번째 줄에서 사용됩니다. 한편 apply()의 결과에서 1행은 각 행별 최소값의 인덱스를 나타냅니다. 이를 통해 어떤 다른 도시가 가장 나은 짝인지를 볼 수 있기 때문에 매우 편리합니다. 우리는 3번 도시가 그 중 하나임을 알기 때문에, 1행의 3번 지점으로 가서 이에 대응되는 도시가 4번이라는 것을 알 수 있습니다. 그러므로 서로 가장 가까운 도시의 쌍은 3번 도시와 4번 도시입니다. 만약 행렬에서 최소값을 가진 원소가 하나라면 훨씬 간단한 방법도 있습니다. 이 예제는 작동하지만 몇 개의 가능한 문제점이 있습니다. 이 코드에서 가장 중요한 부분은 이 줄인데요. 이 줄에서는 d의 원소 중 최소값 인덱스를 결정합니다. arr.ind=TRUE라는 인수는 반환할 인덱스가 단일 벡터가 아닌 행과 열을 가진 행렬 인덱스라고 지정해 줍니다. 이 인수가 없다면 d는 벡터로 취급됐을 것입니다. 언급했던 대로 이 새 코드는 최소값이 유일할 때만 작동합니다. 만약 이런 경우가 아니라면 원래 목적과 다르게 which()에서 여러 행/열의 쌍들을 반환할 것입니다. 만약 이전 코드를 사용하고 d가 여러 개의 최소값을 갖고 있다면, 이 중 단지 하나만 반환될 것입니다. 다른 문제는 성능입니다. 이 코드는 사용한 행렬에서 두 개의 보이지 않는 반복문으로 이뤄져 있습니다. 하나는 smallest를 계산하는 부분이고 또 하나는 which() 내에서 사용합니다. 그래서 원래의 코드보다 더 느려질 수 있습니다.두 방법 중 수행 속도가 문제가 된다거나 여러 최소값이 존재한다면 원래의 코드를 선택하겠지만, 그렇지 않다면 다른 대안인 후자를 선택할 것입니다. 후자가 더 단순해서 코드를 읽고 유지하기가 더 쉽기 때문입니다. 이번에는 행렬의 벡터적 속성에 대해 좀더 자세히 살펴보겠습니다. 예제를 보면 Z는 여전히 벡터이므로 다음과 같이 크기를 확인할 수 있습니다. 하지만 행렬이므로 z는 벡터보다 조금 더 추가된 것이 있습니다. 객체지향 프로그래밍 관점에서 보자면 실제로 matrix라는 클래스가 있는 것입니다. R의 대부분은 S3 클래스를 포함하는데, 여기서는 구성 요소가 $로 표기됩니다. matrix 클래스에서는 dim이라는 하나의 속성을 갖는데, 이는 행렬에서 열과 행의 숫자가 되는 벡터입니다. 또한 dim() 함수를 이용해 dim의 값을 얻을 수 있습니다. 행과 열의 숫자는 nrow()와 ncol() 함수를 써서 따로따로 얻을 수도 있습니다. 이 함수들은 코드를 확인해 보면 알겠지만, 그저 dim()에서 파생된 것입니다. 인터렉티브 모드에서 객체를 불러내는 방법은 간단히 이름만 입력해도 됩니다. 이런 함수들은 행렬을 인수로 받는 일반적인 라이브러리 함수를 작성할 때 유용합니다. 코드에서 행과 열의 숫자를 결정할 수 있도록 해, 두 추가 인수에 대한 정보를 따로 제공해야 하는 부담이 없습니다. 이는 객체지향 프로그래밍의 장점 중 하나입니다. 고급 행렬 고급 행렬 통계의 세계에서 차원 축소는 매우 좋은 것이고, 이를 쉽게 하기 위한 많은 통계 기법이 있습니다. 예를 들어 10개의 변수를 다뤄야 하는데, 이를 3개로 줄였는데도 데이터의 핵심은 모두 잘 잡아낼 수 있다면 즐거울 것입니다. 하지만 R에서 ‘차원 축소’라는 이름은 피하는 게 더 좋을 때도 있습니다. 4개의 행을 가진 행렬이 있고 여기서 한 행을 뽑았다고 해봅시다. 이는 별 문제 없어 보이지만, R에서 r을 출력하는 포맷에 주의해야 합니다. 이는 행렬이 아닌 벡터 형식입니다. 다르게 말하자면 1-2 행렬이 아닌 길이 2의 벡터라는 것입니다. 이를 두 가지 방식으로 확인해 봅시다. 여기서 z는 행과 열 수를 갖고 있지만 r은 없다고 알려줍니다. 유사한 방식으로 str()은 행과 열에 대해 1:4와 1:2 범위의 인덱스를 갖고 있지만, r의 인덱스는 단순히 1:2 범위라고 알려줍니다. 의심할 여지없이 r은 행렬이 아닌 벡터입니다. 이는 자연스러워 보이지만 많은 경우에 많은 행렬 연산을 처리해야 하는 프로그램에서 문제를 야기할수 있습니다. 코드가 평소에는 잘 돌아가다가 특수한 케이스에서 실패하는 것을 발견할 수도 있습니다. 예를 들어 코드에 주어진 행렬에서 부분행렬을 뽑아내고 이 부분행렬에 몇몇 행렬 연산을 취한다고 가정해 보면, 부분행렬이 한 개의 행일 경우 R은 이것을 벡터로 취급할 것이고, 이는 코드 실행에 피해를 입힐 수 있습니다.다행히도 R은 이런 차원 축소를 막을 수 있는 방법을 갖고 있습니다. 바로 drop인수입니다. 앞의 z를 활용해 봅시다. 이제 r은 2개의 원소를 가진 벡터가 아니라 1-2 행렬이 됐습니다. 이런 이유로 모든 행렬을 다루는 코드에는 drop=FALSE인수를 습관적으로 집어넣는 것이 편리하다는 걸을 알 수 있습니다. 왜 drop을 인수라고 할까요? 그 이유는 [도 +같은연산자의 경우처럼 실제로는 함수이기 때문입니다. 만약 벡터를 행렬처럼 다루고 싶다면, 다음 예제처럼 as.matrix() 함수를 사용할 수 있습니다. 행렬의 행과 열은 보통 각각의 숫자로 통칭하지만 각각에 이름을 붙여줄 수도 있습니다. 보다시피 이 이름들은 특정 열을 대표해 사용됩니다. rownames() 함수도 유사합니다. 행과 열에 이름을 부여하는 것은 보통 일반적인 R 코드를 작성할 때 그다지 중요하지 않지만 특정 데이터 세트를 분석할 경우 유용하게 사용될 수도 있습니다. 통계적 관점에서 R의 일반적인 행렬의 행은 다양한 사람 같은 관측치에 해당하고, 열은 몸무게나 혈압 같은 변수에 해당합니다. 그래서 행렬은 2차원 구조입니다. 하지만 만약 이 데이터를 시간별로 가져온다면, 하나의 데이터는 한 사람의 한 변수의 하나의 시간 단위에 대한 것이 됩니다. 시간은 열과 행에 이어 세 번째 차원이 되는 것입니다. R에서 이런 데이터 세트를‘ 배열’이라고 합니다. 간단한 예로 학생과 시험 성적을 봅시다. 각 시험은 두 부분으로 구성돼 있기 때문에 한 학생에 대해 매 시험마다 두 개의 성적을 기록하게 됩니다. 그럼 예제를 작게 만들어서, 딱 3명의 학생이 시험을 두 번 봤다고 가정해봅시다. 다음은 첫 번째 시험의 데이터입니다. 1번 학생은 첫 시험에서 46점과 30점을 받았고, 2번 학생은 21점과 25점을 맞았습니다. 다음은 동일한 학생들의 두 번째 시험 점수입니다. 그럼 두 데이터를 tests라고 명명할 하나의 데이터 구조에 넣어 봅시다. 여기서는 한 계층당 하나의 시험으로 두 ‘계층’을 마련할 것입니다. 각 계층에는 3개의 행과 2개의 열을 둘 것입니다. firsttest를 첫째 층에 넣고 secondtest를 두 번째에 넣을 것입니다. 1계층에는 첫 번째 시험에 대한 세 학생의 점수가 들어간 세 개의 행과 행마다 테스트의 두 부분이 기록된 열이 생길 것입니다. 데이터 구조 생성을 위해서는 R의 array 함수를 사용합니다. 인수 dim=c (3,2,2)에서 3개의 행과 2개의 서술자를 갖는 게 아니라, 3개의 서술자를 갖게 됩니다. 첫 번째 서술자는 $dim 벡터의 첫 번째 원소에 대응되며, 두 번째 서술자는 $dim의 두 번째 원소에 대응되는 식입니다. 예를 들어 3번 학생이 1번 시험의 두 번째 부분에서 얻은 점수는 이와 같이 기술됩니다. R에서 배열을 출력해 보면 계층별로 데이터가 표시되는 것을 알 수 있습니다. 지금은 간단히 두 행렬을 결합해 3차원 배열을 만들어 보았지만, 2~3개의 3차원 배열을 결합해 4차원 배열을 만들 수도 있고, 그 이상도 가능합니다.1. 행렬의 행과 열에 함수 적용하기
2. 행렬에 행과 열 추가 및 제거하기
3. 벡터와 행렬을 더 정확히 구분하기
1. 의도하지 않은 차원 축소 피하기
2. 행렬의 행과 열에 이름 붙이기
3. 고차원 배열

























'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 리스트의 적용과 재귀 리스트 (0) | 2016.05.13 |
|---|---|
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 행렬과 배열 만들기 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 이해 (0) | 2016.05.07 |