
Jeongchul Kim
R 3.2.1 프로그래밍 - 리스트의 생성과 연산 본문
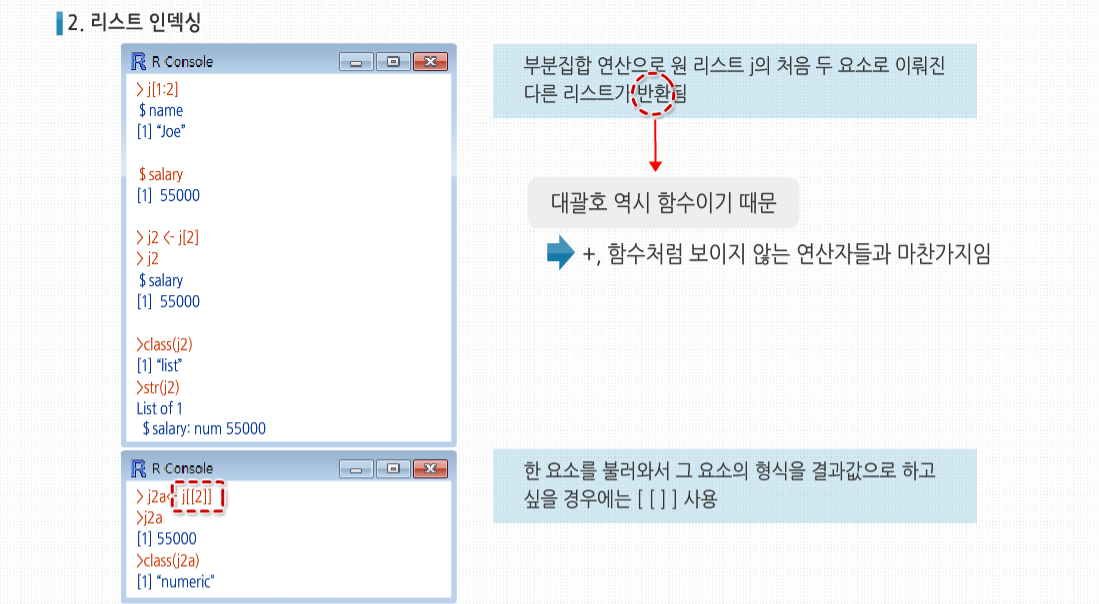
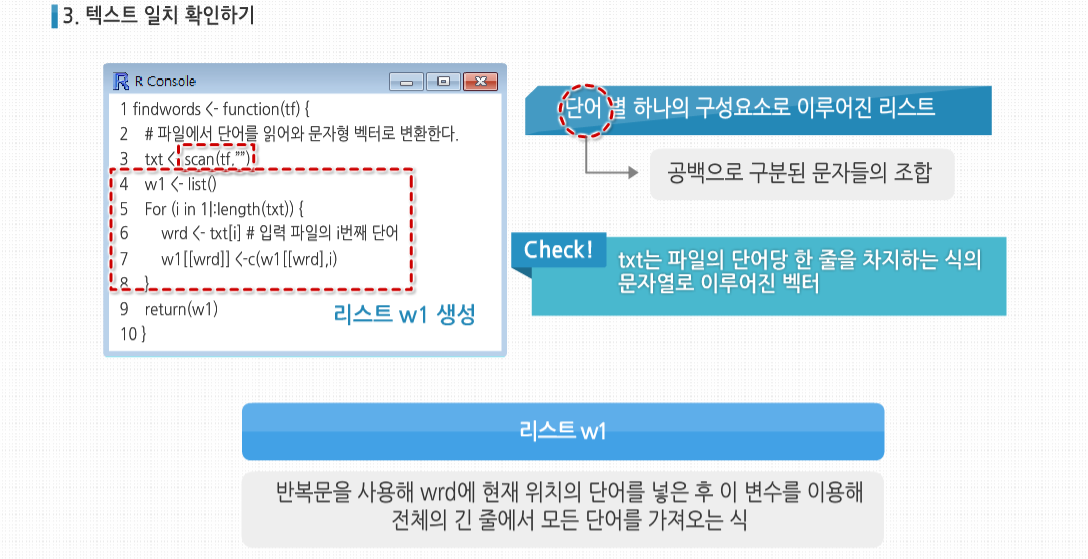
R 3.2.1 프로그래밍 - 리스트의 생성과 연산 리스트는 배열과 같은 다중 자료형 형태이나, 다른 속성을 지닙니다.배열은 이미 정해진 크기의 메모리 공간이 필요하지만, 리스트는 필요 없습니다. 데이터를 하나씩 집어 넣을 때마다 메모리 공간을 생성하기 때문입니다. 배열은 데이터의 위치에 대해서 직접적인 엑세스가 가능하지만, 리스트는 불가능합니다. 가장 처음위치부터 몇 번째인지 하나씩 세어가면서 위치를 찾아나가야 합니다. 또한 배열은데이터의 삽입이나 삭제가 상당히 불편하지만,리스트는 매우 손쉽게 삽입하거나 삭제할 수 있습니다. 리스트의 기초 리스트의 기초 기술적으로 봤을 때 리스트는 벡터의 일종입니다. 일반적인 벡터는 구성 요소가 더 작은 요소로 나뉠 수 없기 때문에 원자 벡터(Atomic Vector)라 합니다. 반면 리스트는 순환 벡터(Recursive Vector)라 합니다. 예를 들어 직원 데이터베이스를 생성해 보겠습니다. 각 직원 별로 이름, 연봉, 노조 가입 여부가 표시된 불리언 값을 저장하고자 합니다. 여기에는 문자형, 숫자형, 논리형의 세 가지 형식이 사용될 것이므로 리스트를 사용하기에 완벽한 조건입니다. 그러면 전체 데이터베이스는 리스트의 리스트가 되거나, 여기서 원하는 바는 아니지만 데이터 프레임 같은 다른 유형의 리스트일 수 있습니다. Joe라는 직원을 나타내는 리스트는 다음과 같은 식으로 생성할 수 있습니다. 또한 j를 전체 혹은 구성 요소 별로 출력할 수 있습니다.실제로 salary 같은 구성 요소의 이름, 즉 R 문법에서 태그(tag)는 선택적 요소입니다. 다른 식으로는 다음과 같이 쓸 수 있습니다. 하지만 숫자 인덱스 대신 이름을 붙이는 편이 보통 더 명확하고 에러를 적게 만드는 경향이 있습니다. 리스트 구성 요소의 이름은 다른 것과 겹치지 않는 선에서 축약해 사용할 수 있습니다. 리스트는 벡터이므로 vector()를 통해 만들 수 있습니다. 리스트를 벡터처럼 사용하면 리스트의 요소를 각 숫자 인덱스를 이용해 호출할 수 있습니다. 다만 이 경우엔 대괄호를 두 개 겹쳐서 사용해야 합니다. 이런 식으로 리스트 1st의 구성요소 c에 접근해서 c의 데이터 형으로 가져오는 방법은 3가지가 있습니다. 이 방법들은 모두 유용할 때가 있지만 c의 데이터 형으로 가져와야 하므로 두 번째와 세 번째 방법에서 대괄호 두 개가 아닌 하나만 사용할 수도 있습니다. 대괄호를 하나만 사용하는 것과 두 개를 사용하는 것 모두 벡터에서 인덱스를 사용하는 방식으로 리스트의 원소에 접근합니다. 하지만 보통 벡터 인덱싱과 확실히 다른 점이 있습니다. 만약 대괄호가 하나만 사용되면 그 결과는 원래 리스트의 부분 리스트가 될 것입니다. 예제를 살펴 봅시다. 부분집합 연산으로 원 리스트 j의 처음 두 요소로 이뤄진 다른 리스트가 반환됩니다. 여기서‘반환’이란 단어를 사용한 이유는 대괄호 역시 함수이기 때문입니다. 이 역시 +, 함수처럼 보이지 않는 연산자들과 마찬가지입니다. 반면 한 요소를 불러와서 그 요소의 형식을 결과값으로 하고 싶다면 대괄호 두 개를 겹쳐서 사용하면 됩니다. 리스트의 활용 리스트의 활용 리스트 원소를 추가하거나 삭제하는 연산은 놀라울 정도로 많이 발생합니다. 특히 리스트가 기초가 된 데이터 구조인 데이터 프레임이나 R 클래스 같은 경우가 그렇습니다. 새 구성 요소는 리스트가 생성된 후에 추가될 수 있고, 구성 요소를 추가할 때 벡터 인덱스를 사용할 수 있습니다. 리스트에서 해당 부분을 NULL로 설정해 구성 요소를 제거할 수 있을 뿐만 아니라, 리스트끼리 합치는 것도 가능합니다. 리스트는 벡터이므로 length()를 사용해 리스트 구성 요소의 개수를 알 수 있습니다. 최근 웹 검색 및 텍스트 데이터 마이닝이 관심을 끌고 있습니다. R 리스트 예제코드로 이 분야의 예제를 사용해 봅시다. 어떤 단어가 텍스트 파일 안에 들어있는지 판단하고 각 단어 위치의 리스트를 만들어주는 findword()라는 함수를 작성할 것입니다. 이 함수는 문맥 분석 등에 유용할 것입니다. 입력 파일인 testconcord.txt에는 다음과 같은 내용이 들어있습니다. 단어 확인을 위해 글자가 아닌 모든 문자를 공백으로 처리하고 대문자를 모두 소문자로 바꿀 것입니다. 그 결과로 새 파일 testconcord.text는 다음과 같이 제시되어야 합니다. 여기서 예를 들어 item이란 단어의 위치는 7, 14, 27입니다. 이는 이 단어가 파일 안에서 7, 14, 27번째에 있다는 뜻입니다. 다음은 함수 findwords()가 파일에 대해 호출됐을 때 나오는 결과 리스트 입니다. 파일은 단어 별 하나의 구성요소로 이뤄진 리스트로, 각 구성요소는 해당 단어 별 파일 내 위치를 보여줍니다. 당연히 item은 7, 14, 27의 위치에 있다고 나옵니다. 여기서 잠깐, 만약 리스트 대신 행렬을 사용한다면 어떻게 될까요?텍스트의 각 단어에 대해 한 열씩 할당한 행렬을 사용할 수도 있습니다. rownames()로 열의 이름에 각 단어를 주고 해당 열에 그 단어의 위치를 보여주는 식을 사용하는 것입니다. 예를 들어 item 열은 7, 14, 27과 빈 부분이 0으로 채워진 형태가 됐을 것입니다. 하지만 행렬을 사용하는 방식에는 두 가지 중요한 약점이 있습니다. 우선, 행렬을 할당할 때 열 부분에 대한 문제가 있습니다. 텍스트 내에서 단어가 가장 많이 나타나는 경우가 10회라면, 10개의 열이 필요합니다. 하지만 그것을 미리 알 수는 없습니다. 따라서 새 단어를 추가하려면 매번 rbind()로 행을 늘려가면서 cbind()로 열을 추가해 줘야 합니다. 두 방법 모두 코드 복잡도나 수행 시간 증가에 따른 비용 문제에 직면할 수 있습니다. 또한, 저장 공간 측면에서 많은 열이 수많은 0으로 채워지는 것은 메모리 낭비입니다. 일반적으로 수치분석 쪽에서는 행렬을 사용하는 경우는 극히 드뭅니다. 그러므로 리스트구조가 적합합니다. 그럼 다시 리스트 코드를 살펴보겠습니다. 파일의 단어는 scan()을 호출해 읽어 들입니다. 여기서‘단어’는 단순히 공백으로 구분된 문자들의 조합을 의미합니다. 여기서 중요한 점은 txt는 파일의 단어당 한 줄을 차지하는 식의 문자열로 이루어진 벡터라는 것입니다. 4~8번째 줄의 리스트 연산에서는 여기서 가장 중요하게 사용되는 변수인 리스트 w1을 생성합니다. 반복문을 사용해 wrd에 현재 위치의 단어를 넣은 후 이 변수를 이용해 전체의 긴 줄에서 모든 단어를 가져오는 식입니다. i = 4일 때 코드의 7번째 줄에서 어떤 일이 일어나는지 살펴봅시다. 예제 파일 testconcorda.txt에서 wrd = “that”이 될 것입니다. 이때까지 w1[ [“that”] ]은 존재하지 않을 것 입니다. R은 이런 경우 w1[ [“that”] ] = NULL로 설정하므로, 7번째 줄에 값을 이어 붙일 수 있는 것 입니다. 그러면 w1[ [“that”] ]은 한 개의 원소를 가진 벡터 (4)가 될 것입니다. 이후 i = 40일 때 w1[ [“that”] ]은 파일 내의 4번째와 40번째 단어가 모두 “that”이라는 내용을 의미하는 (4, 40)이 될 것입니다.w1[ [“that”] ]처럼 문자열에 따옴표를 붙인 형태의 리스트 인덱싱이 매우 편리하다는 것을 기억하세요.1. 리스트 생성하기
2. 리스트 인덱싱
1. 리스트 원소 추가 삭제하기
2. 리스트의 크기 확인하기
3. 텍스트 일치 확인하기


















'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 데이터 프레임의 생성과 연산 (0) | 2016.05.13 |
|---|---|
| R 3.2.1 프로그래밍 - 리스트의 적용과 재귀 리스트 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
| R 3.2.1 프로그래밍 - 행렬과 배열 만들기 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 (0) | 2016.05.07 |