
Jeongchul Kim
R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 본문
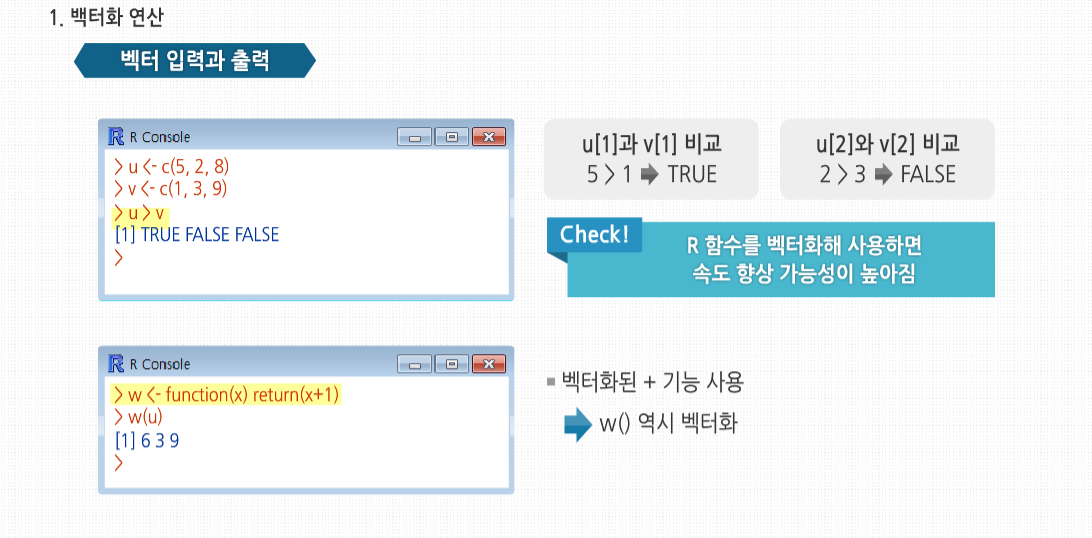
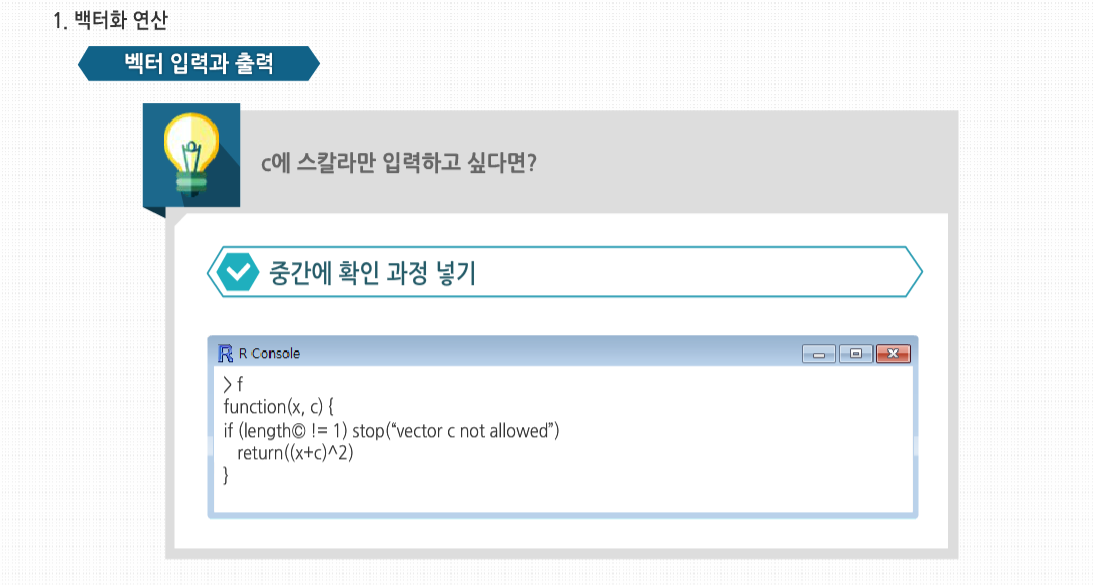
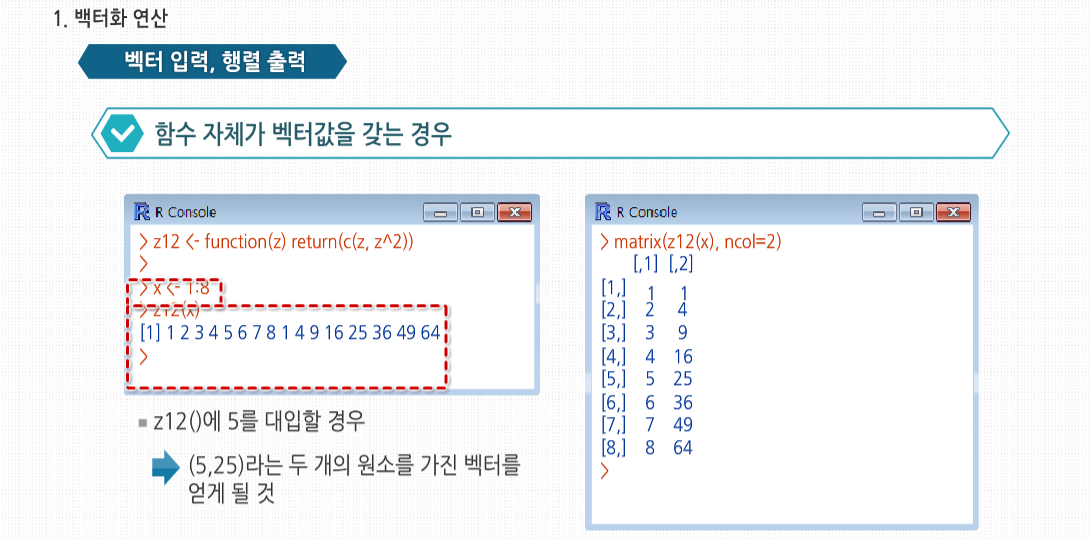
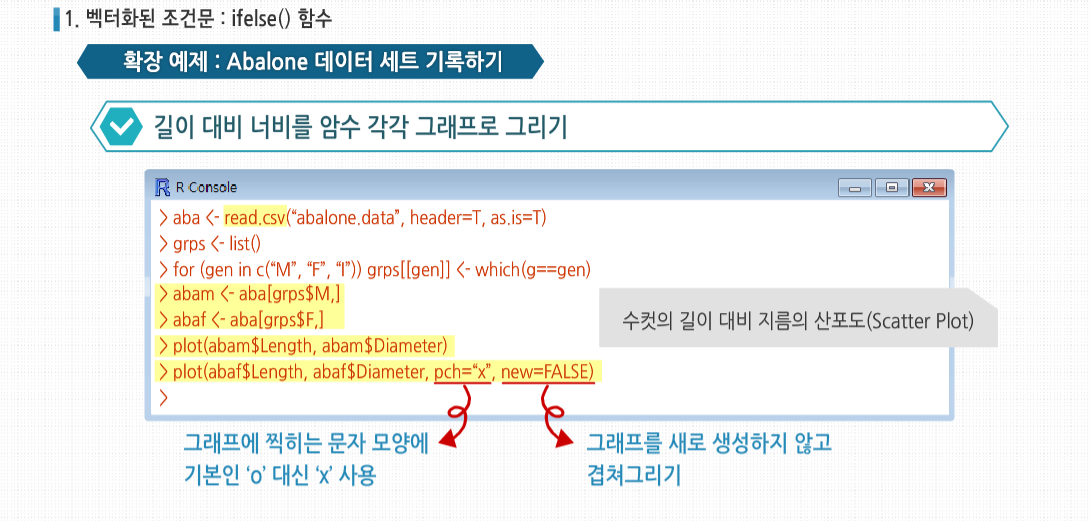
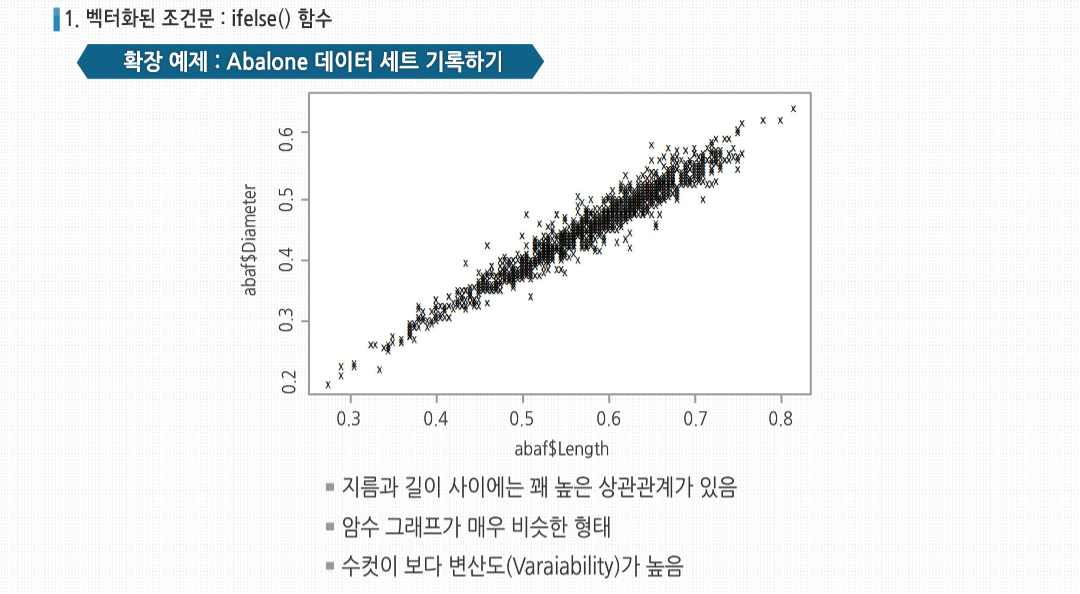
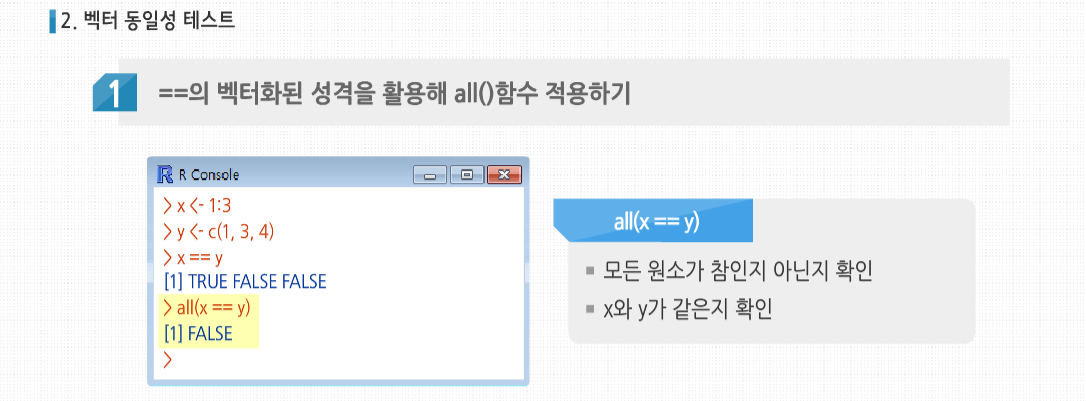
R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 활용 학습을 시작하기에 앞서, NA와 NULL의 개념에 대해 살펴봅시다. NA는 결측치로 데이터가 존재하지 않음을 뜻합니다. 쉽게 말해서 존재는 하지만 무엇인지 모름을 의미합니다. 예를 들어 중간고사 성적을 입력하는데 5번째 학생이 시험을 치지 않은경우 NULL이 아닌 NA를 사용합니다. 이에 반해 NULL은 NULL 객체로서 객체를 정의되지 않은 상태로 만들고자 할 때 사용하며, 존재하지 않는 값을 의미합니다. 결측치는 하나의 요소를 의미하고 NULL은 객체를 의미합니다. NA는 값을 넣은 후 출력이되지만 NULL는 출력이 되지 않습니다. length()를 사용해서 확인해보면 NULL의 경우는 길이에 영향을 미치지 않는다는 것을 알 수 있습니다. 이제 NA와 NULL의 차이에 대해 이해하셨나요? 그럼 본격적으로 학습을 시작해 볼까요? 스칼라, 벡터, 배열 그리고 행렬의 기초 스칼라, 벡터, 배열 그리고 행렬의 기초 벡터 x의 모든 원소에 함수 f()를 적용하고 싶다고 합시다. 대부분의 경우 x 자체에 f()를 적용하는 식으로 간단하게 해결합니다. 이런 방식은 코드를 매우 간단하게 하고, 몇 백 배 이상의 엄청난 성능 향상을 가져다 줍니다. R 코드의 속도를 올리는 가장효과적인 방법 중 하나는, 벡터에 함수를 적용하면 실제로는 내부의 원소에 각각 적용됨을 뜻하는 ‘벡터화’한 연산을 사용하는것입니다. 여기서 >함수는 u[1]과 v[1]을 비교해 TRUE를 반환하고, 이어서 u[2]와 v[2]를 비교하고 FALSE를 반환하는 식으로 사용됐습니다. 핵심은 R 함수를 벡터화해 사용하면 속도 향상 가능성이 높아진다는 것입니다. 다음 예제를 봅시다. 여기서 w()는 벡터화된 + 기능을 사용하므로 w() 역시도 벡터화 됩니다. 보다시피 단순한 함수로부터 여기서 파생된 복잡한 함수들까지 셀 수 없이 많은 벡터화된 함수가 있습니다. 심지어는 제곱근, 로그, 삼각함수 등 초월함수도 벡터화 함수입니다. 이런 방식은 많은 R 내장 함수에 적용할 수 있습니다. 예를 들어 소수를 가장 가까운 정수로 반올림하는 함수를 벡터 y에 적용해 봅시다. 여기서 중요한 점은 round() 함수가 벡터 y의 개개의 원소에 적용됐다는 것입니다. 또한 숫자는 한 개의 원소를 가진 벡터이므로 ‘일반적으로’ round()를 사용하는방식도 그다지 특별한 경우가 아닙니다. 여기서는 내장 함수인 round()를 사용했으나, 함수를 직접 만들어서 이와 유사하게 사용할 수 있습니다. +같은 연산자도 실제로는 함수로 동작합니다. 다음 코드를 봅시다. 원소 단위로 4를 더하는 작업이 일어나는 이유는 +가 실제로 함수이기 때문입니다. 명시적으로 표기하면 이와 같습니다. 여기서도 핵심 기능은 ‘재사용성’입니다. 4가 (4, 4, 4)로재사용됐습니다. R에서는 ‘스칼라 데이터’가 따로 존재하지 않으므로 스칼라 변수로 보이는 것에도 벡터화된 함수를 사용해 봅시다. f()의 정의를 보면 c가 숫자라고 생각하기 쉽지만, 당연히 이는 길이가 1인 벡터입니다. 만약 c에 스칼라를 대입한다고 하더라도,f() 내에서 x+c를 계산하기 위해 재사용돼 확장될 것입니다. 그러므로 f(1:3, 1)을 호출하더라도 실제로는 이와 같이 계산됩니다. 대신 이는 코드 안정성 문제를 야기할 수 있습니다. 이처럼 c에 명시적으로 벡터를 사용하더라도 어떻게 할 방도가 없습니다. (4,16,36)이 예상하던 결과값인지 확인한 후에 이 함수를 계속 사용해야 합니다. 만약 c에 스칼라만 입력하고 싶다면, 이처럼 중간에 확인 과정을 넣어야 합니다. 지금까지 사용한 벡터화된 함수는 스칼라값들을 반환했습니다. sqrt()에 숫자를 넣으면 숫자가 나왔습니다. 만약 이 함수를 8개의 원소를 가진 벡터에 넣으면 다른 8개의 숫자값으로 이뤄진 벡터가 결과값으로 도출됐습니다. 하지만 함수 자체가 예제의 z12()처럼 벡터값을 갖는 것이라면 어떨까요? z12()에 5를 대입하면 (5,25)라는 두 개의 원소를 가진 벡터를 얻게 될 것입니다. 이 함수를 8개의 원소를 가진 벡터에 대입하면 16개의 숫자가 나옵니다. 이 값은 matrix 함수를사용해 8-2 행렬로 나타내는 것이 좀더 자연스럽습니다. 그러나 sapply() 혹은 ‘단순화한 apply 함수(simplify apply)’를 사용해 이를 보다 능률적으로 처리할 수 있습니다. sapply(x, f) 함수를 사용하면 f() 함수를 x의 각 원소에 적용하고 그 결과값을 행렬로 바꿔줍니다. 여기서는 8-2가 아닌 2-8 연산으로 나왔으나 어쨌든 유용한 방식입니다. 다른 스크립트 언어에 대한 지식이 있는 사람이라면 파이썬의 None이나 펄의 Undefined 같은 ‘존재하지 않는 값’을 주의해야 합니다. R에는 이런 값이 두 가지가 있습니다. 바로 NA와 NULL입니다. 통계 데이터 세트에서는 종종 NA로 표기된 누락된 값을 볼 수 있습니다. 반면에 존재하지만 불확실한 값이 아닌 아예 답이 없는 경우에는 NULL 값으로 표기됩니다. 이 둘이 구체적으로 어떤 역할을 하는지 자세히 살펴봅시다. 많은 R의 통계 함수에서 누락된 값이나 NA는 건너뛰고 실행되도록 할 수 있습니다. 예제를 보면, 처음에 mean() 함수는 x의 값 중 하나가 NA이므로 계산을 거부합니다. 그러나 옵션으로 na.rm(NA 제거remove)를 참(T)으로 설정해 나머지 원소들의 평균값을 계산할 수 있습니다. 하지만 R에서 NULL 값은 자동으로 넘어갑니다. NA는 각 형식에 따라서 다양한 형식으로 나타납니다. NULL의 용도 중 하나는 반복문에서 매번 원소를 추가해가며 벡터를 생성할 때 쓰는 것입니다. 이 간단한 예제에서는 짝수로 이뤄진 벡터를 생성합니다. 13을 4로 나누면 나머지가 1이 되므로, 13 %% 4는 1입니다. 그러므로 이 예제는 NULL 벡터로부터 반복문이 시작돼서 거기에 2를 추가하고, 4를 추가하는 식으로 진행됩니다. 물론 이것은 매우 인위적이기 때문에 각각의 작업을 훨씬 나은 방법으로 할 수 있습니다. 이 예제에서는 1:10에서 짝수를 찾는 두어 가지 더 나은 방법을 제시합니다. 그러나 여기서 중요한 점은 NA와 NULL의 차이를 보이는 것입니다. 만약 앞의 예제에서 NULL 대신 NA를 쓰고 싶다면, 나중에 사용되지 않을 NA를 골라내야 합니다. 실제로 NULL은 예제에서 볼 수 있듯이 존재하지 않는 것으로 계산됩니다. NULL은 어떤 형식도 취하지 않는 특별한 객체입니다. R의 함수형 언어적 성격을 반영하는 또 다른 특징은 ‘필터링’입니다. 이는 벡터에서 특정한 어떤 조건을 만족하는 원소들을 골라내는 것입니다. 필터링은 통계 분석에서 관심사에 따라 특정 조건을 만족하는 데이터에 대해서만 보는 일이 잦기 때문에, R에서 가장 일반적으로 사용되는 연산 중 하나입니다. 이 코드를 자세히 살펴보면, z의 모든 원소들 중에서 제곱값이 8보다 더 큰 원소를 찾아 부분 벡터화 w에 넣으라고 R에 명령어를 넣은 것으로 보입니다. R에서 이런 의도를 해소할 수 있는 기술을 갖고 있다면, 그 중 가장 중요한 연산은 필터링일 것입니다. 하나하나 살펴 봅시다. z*z > 8에 대한 결과는 불리언값의 벡터로 나옵니다. 이것이 정확히 어떻게 나온 것인지 이해하는 것은 매우 중요합니다. 우선 z*z > 8에서 ‘모두’ 벡터나 벡터 연산이라는 것을 기억합시다. z가 벡터이므로 z*z 역시 z와 같은 크기의 벡터입니다. 숫자 혹은 길이가 1f인 벡터 8은 재사용돼 여기서는 (8,8,8,8)이 됩니다. >는 +와 마찬가지로 실제로는 함수입니다. 이 마지막 특성에 관련된 예제를 봅시다. 이 예제에 따라 z*z > 8가 되고 실제로는 이와 같습니다. 다른 관점에서 우리는 벡터에 함수를 적용했습니다. 이는 벡터화의 예 가운데 하나로서 앞서 알아본 예제와 다를 게 없습니다. 결과 역시 벡터입니다. 그리고 불리언값은 z에서 원하는 원소만을 가져올 때 사용합니다. 다음 예제는 보다 복잡합니다. 여기서도 z를 이용해 추출 조건을 정의하지만, 그 결과를 z가 아닌 다른 벡터 y에서 데이터를 추출하는 데에 사용할 것입니다. 아니면 좀더 짧게 이와 같이 쓸 수도 있습니다. 이 예제에서 중요한 점은, 벡터 y를 필터링 하기 위해 ‘다른’ 벡터 z를 인덱스처럼 사용하고 있다는 것입니다. 앞선 예제에서는 z가 자신 자신을 필터링했는데 말입니다. 여기 자기 자신을 사용한 다른 예제가 있습니다. 벡터 x중 3보다 큰 모든 원소를 0으로 치환하려 합니다. 이 내용은 매우 짧게,딱 한 줄로 구현할 수 있습니다. 확인해 봅시다. subset() 함수를 사용해 필터링할 수 있습니다. 기존 필터링 방식과 이 함수의 차이는 벡터에 적용했을 때의 NA 처리 여부입니다. 일반적인 필터링 방식은 R에서는 기본적으로 x[5]는 알 수 없는 값이므로 그 값이 5보다 큰지도 알 수 없다고 말합니다. 하지만 아마 결과값에 NA를 포함하고 싶은 사람은 없을 것입니다. NA를 제외할 생각이라면, subset()를 사용하여 직접 NA를 골라내야 하는 귀찮은 일을 피할 수 있습니다. 벡터 z에서 특정 조건을 만족하는 원소들을 골라 재구성하는 작업을 살펴봤습니다. 하지만 어떤 경우에는 z에서 해당 조건을만족하는 원소들의 위치만 찾고 싶을 때가 있습니다. 그 때는 이와 같이 which() 함수를 사용할 수 있습니다. z의 1, 3, 4번째 원소의 제곱값이 8보다 크다는 결과가 나왔습니다. 필터링의 경우처럼 코드가 정확하게 어떤 식으로 실행되는지 이해하는 것이 중요합니다. 이 부분의 결과가 TRUE, FALSE, TRUE, TRUE로 나옵니다. which() 함수는 이중 어떤 원소가 TRUE로 나왔는지를 보여줍니다. 스칼라, 벡터, 배열 그리고 행렬의 활용 스칼라, 벡터, 배열 그리고 행렬의 활용 대부분의 언어는 일반적인 if-then-else 구분을 갖고 있습니다. R은 여기에다 벡터화된 버전의 ifelse() 함수까지 갖고 있습니다. 형식은 이렇습니다. b는 불리언 벡터고, u와 v는 벡터입니다. 반환되는 값은 원소 i에 대해 b[i]가 참이면 u[i], b[i]가 거짓이면 v[i]로 구성된 벡터입니다. 이 예제에서는 x가 짝수면 5를, 짝수가 아니면 12 값을 가진 벡터를 만들려고 합니다. b에 들어가는 실제 인수값은 (F,T,F,T,F,T,F,T,F,T) 입니다. 또한 실제로 두 번째 인수인 u에 들어가는 값은 5로, 재사용 법칙에 따라 10개의 5로 취급됩니다. 세 번째 인수 값인 12 역시 재사용 됩니다. 다른 예제를 봅시다. 여기서는 각 x의 원소가 6보다 크냐에 따라 2를 곱하거나 3을 곱한 값으로 만들어진 벡터를 반환합니다. 여기서 실제로 어떤 일이 일어나는지를 생각해 봅시다. x>6은 불리언 벡터입니다. i번째 원소가 참이라면 결과값의 i번째 원소는 2*x의 i번째 값이 될 것이고, 참이 아니라면 3*x[i]가 될 것입니다. 표준 if-then-else의 구조를 넘어선 ifelse()의 장점은 벡터화돼 훨씬 빠를 수 있다는 것입니다. 두 변수 간의 통계적 관계 측정 방식으로 ifelse()를 사용해보겠습니다. 매 시간별 기온과 기압을 측정해 모은 시계별 벡터 x와 y가 있다고 가정해봅시다. 시간에 따라 x와 y가 증가하고 감소하는 것에 대한 상관관계를 정의할 것입니다. 즉 y[1+1]-y가 x[i+1]-x[i]와 같은 현상을 보이는 i의 비율을 보는 것입니다. 다음과 같은 코드를 만들었습니다. 다음은 그 예입니다. 이 예제에서 x와 y는 10개 중 3번 동일하게 증가하고 감소합니다. 이때 처음의 경우는 x가 12에서 13으로 증가할 때 y가 2에서 3으로 증가합니다. 이를 통해 연관치가 3/10 = 0.3임을 알 수 있습니다. 이 코드가 어떻게 동작하는지 살펴봅시다. 여기서 첫 번째로 해야 할 일은 x와 y를 1과 -1로 기록하는 것입니다. 이때 1은 이전 관찰치보다 현 관찰치가 증가한 경우입니다. 이 작업은 5번과 6번 줄에서 일어납니다. 예를 들어 5번 줄에서 findud()를 16개의 원소를 가진 v에 적용하면 어떤 일이 일어날지 생각해 봅시다. v[-1]은 v의 두 번째 원소부터 시작하는 15개의 원소를 가진 벡터가 될 것입니다. 비슷한 이치로 v[-length(v)] 역시 15개의 원소를 가진 벡터가 될 것입니다. 물론 이때는 v의 첫 번째 원소부터 시작합니다. 그리고 결과값은 원래의 벡터의 각 원소들 값에서 각 값의 오른쪽에 있는 값과의 차이로 나올 것입니다. 이 값은 매 기간별 증가/감소 상태를 보여줄 것으로, 딱 여기서 필요한 값입니다. 그 후 이 차이가 음수인지 양수인지에 따라 1과 -1로 변환합니다. ifelse() 함수를 호출해 반복문을 사용하는 것보다 간단하고 쉽게, 짧은 시간에 이 기능을 수행할 수 있습니다. 그리고 x와 y에 적용하기 위해 findud()을 두 번 호출해야 합니다. 하지만 x와 y를 리스트에 넣고 lapply() 같은 함수는 코드를 짧고 명확하게 작성하는 데에 큰 도움이 될 것이고, 속도 또한 매우 빨라질 수 있습니다. 그리고 이와 같이 결과가 맞을 비율을 구합니다. lapply()가 리스트를 반환한다는 것을 기억합시다. 리스트의 요소는 1과 -1로 구성돼 있습니다. ud[[1]] == ud[[2]]는 TRUE와 FALSE로 구성된 벡터를 반환하는데, 각 값은 mean()에서 1과 0으로 사용됩니다. 그리고 이 결과 원하는 비율값을 얻을 수 있습니다. 보다 발전된 형태로는 벡터 간의 차이를 찾는 기능인 R의 diff() 함수를 들 수 있습니다. 예를 들어 벡터의 각 원소의 3개뒤의 값과 각각 비교한다면, 이는 ‘3구간 차이’라고 합니다. 보통 차이 비교는 예제처럼 하나의 구간 단위로 합니다. 코드의 5번째 줄은 이처럼 될 수 있습니다. 각 인수에 할당된 숫자를 양의 값인지, 0인지, 음의 값인지에 따라 1, 0, -1로 바꿔주는 sign() 이라는 또 다른 고급 R 함수를사용해 코드를 더욱 간결하게 만들 수 있습니다. sign()을 사용하면 이전 예제의 평균을 구해주는 udcorr() 함수를 다음과 같이 한 줄에 작성할 수 있습니다. 이는 원 버전에 비해 정말 많이 짧아졌습니다. 그러나 이게 관연 더 나은 것일까요? 대부분의 사람들이 이렇게 코드를 작성하려면 더 오래 걸릴 것입니다. 그리고 코드가 짧더라도, 이해하기에는 더 어려울 것입니다. 모든 R 프로그래머들은 간결성과 명확성 사이에서 자신만의 ‘적정선’을 찾아야 합니다. 인수가 ‘벡터’라는 성질을 갖고 있기 때문에 ifelse()로 모두 묶어 처리할 수 있습니다. 다음 예제에서 성별이 M, F, I(어린경우)로 표기된 전복abalone 데이터 세트를 사용할 것입니다. 여기서 성별 표기 문자를 1, 2, 3으로 기록하고자 합니다. 실제 데이터 세트는 4000건이 넘지만, 이 예제에서는 g에 저장된 일부만 갖고 있습니다. ifelse() 속에서는 실제로 무슨 일이 일어났을지 살펴보기 위해 ifelse()에서 정식 인수명을 확인합니다. Test의 각 원소가 참값을 갖는다면, 함수에서는 yes에서해당 원소의 값을 찾아준다는 것을 기억합시다. 비슷한 방식으로 test[i]가 거짓이라면, 함수에서는 no[i]의 값을 반환합니다. 그리고 이 값들은 하나의 벡터로 다 같이 반환됩니다. 여기서 R은 test에 g==”M”이, yes에 1이, no에서는 나중에 나올 ifelse(g==”F”, 2, 3)이 실행된 결과값을 대입한 후 바깥의 ifelse()를 먼저 실행합니다. 만약 test[1]이 참이라면, yes[1] 값을 생성하는데, 이 값은 1입니다. 따라서 외부 함수의 결과값 중 첫 번째 원소는 1이 될 것입니다. 다음은 R에서 test[2]를 판단합니다. 이 값은 거짓이므로 R은 no[2]를 찾아야합니다. 이번엔 R에서 내부의 ifelse()를 호출해야 합니다. 이 부분은 아직까지는 쓸 필요가 없으므로 실행된 적이 없습니다. R은 표현식이 필요할 때까지는 실행하지 않는 느슨한 평가 원리를 사용합니다. R은 이제 ifelse(g==”F”, 2, 3)을 실행해 (3,2,2,3,3,3,2)라는 결과값을 냅니다. 이 값은 바깥의 ifelse()에서 no에 해당하는 것이므로, 이전 단계 실행에서는 (3,2,2,3,3,2,2)의 두 번째 원소인 2가 반환됩니다. 바깥쪽 ifelse()가 test(4)에 대해 실행하면, 이 값은 거짓이므로 no(4)를반환합니다. R은 이미 no 값을 계산했으므로, 이것을 실행하는 데에 필요한 값인 3을 갖고 있습니다. 벡터는 일반적으로 행렬의 행이 될 수 있다는 것을 기억합시다. 여기서 사용한 전복 데이터는 성별이 첫 번째 행에 기록된 행렬 ab에 저장돼 있습니다. 만약 성별에 따른 부분집합을 만들고 싶다면 M, F, I에 해당하는 원소들의 번호를 which()를사용해 찾아낼 수 있습니다. 한 발짝 더 나아가, 이 집합을 이와 같이 리스트에 저장할 수 있습니다. R의 for() 반복문은 문자열 벡터에서도 사용 가능함을 기억해 둘 필요가 있습니다. 전복 데이터를 다양한 변수를 탐색하거나 그래프를 그리는 데에 사용할 수도 있습니다. 각 변수의 성격을 요약해 파일에 다음과 같이 헤더를 추가합니다. 다음 코드를 사용해 길이 대비 너비를 암수 각각 그래프로 그릴 수 있습니다. 우선 데이터 세트를 읽어와 전복 관련 데이터가 들어 있는 aba 변수에 할당합니다. 이후 암수를 구분해 aba를 abam과 abaf라는 부분행렬로 나눠 놓습니다. 다음으로 그래프를 만듭니다. 첫 번째 플롯은 수컷의 길이 대비 지름의 산포도입니다. 두 번째는 암컷에 대한 그래프인데요. 수컷 그래프에 겹쳐서 그리고 싶다면, R이 그래프를 새로 생성하지 못하도록 new=FALSE 옵션을 줘야 합니다. pch=”x” 인수는 그래프에 찍히는 문자 모양에 기본인 ‘o’ 대신 ‘x’를 사용하라는 뜻입니다. 전체 데이터 세트를 사용한 그래프 입니다. 점들이 촘촘하게 모여있는 것으로 봤을 때, 지름과 길이 사이에는 꽤 높은 상관관계가 있고 암수 그래프가 매우 비슷한 형태인 것 같습니다. 다만 수컷이 보다 변산도가 높은 것으로 보입니다. 이는 통계 그래프에서 일반적으로 나타나는 문제입니다. 보다 좋은 시각적 분석이 이해하기 좀더 쉽겠지만, 최소한 여기서 변수 간 높은 상관관계가 있다는 것과 그런 관계가 성별에 따라 크게 달라지지 않는다는 것은 알 수 있습니다. ifelse()를 다르게 사용해 예제의 그래프 코드를 간소화할 수 있습니다. 플롯의 인수인 pch를 단일 문자가 아닌 벡터로 사용가능함을 활용하는 것입니다. 이는 R에서 각 그래프의 점마다 다른 문자를 지정해 사용할 수 있다는 말입니다. 여기서 성별을1, 2, 3으로 기록하는 내용은 생략했지만, 여러 이유 측면에서 이 데이터를 그대로 유지하는 것이 좋을 수도 있습니다. 두 벡터가 동일한지 테스트해야 한다고 가정해봅시다. 보통 사용하는 ==는 제대로 동작하지 않습니다. 여기서 중요한 점은 벡터화된 데이터를 다루고 있다는 점입니다. 사실 ==는 벡터화된 함수입니다. x==y라는 식은 ==()함수에 x와 y 원소를 대입한 것과 마찬가지로, 불리언 값을 내놓습니다. 그럼 어떻게 해야 할까요? 한가지 옵션은 ==의 벡터화된 성격을 활용해 all()함수를 적용하는 것입니다. ==의 결과에 all()을 적용하면 모든 원소가참인지 아닌지를 확인하고, 이를 통해 x와 y가 같은지를 확인할 수 있습니다. 아니면 좀더 나은 방법으로 다음과 같이 identical 함수를 사용할 수 있습니다. 이때 조심해야 할 점은, identical(동일함)이 단어의 뜻 그대로 사용된다는 것입니다. 그래서 다음의 짧은 R 세션처럼 해석될 수 있습니다. 벡터의 원소들에 임의로 이름을 지정할 수 있습니다. 예를 들어 미국의 주별 인구를 나타내는 50개의 원소를 가진 벡터가 있다고 합시다. 각 원소에 ‘Montana’라든가 ‘New Jersey’처럼 해당 주의 이름을 붙여줄 수 있고, 이를 그래프의 점에 이름을 지정하는 등으로 활용할 수 있습니다. names()를 이용해 벡터의 원소에 이름을 붙이거나 찾아볼 수 있습니다. 벡터 원소의 이름에 NULL을 지정해 이름을 삭제할 수도 있습니다. 게다가 원소의 이름을 갖고 벡터에서 원소를 찾는 데에도 이용할 수 있습니다.1. 벡터화 연산
2. NA와 NULL 값
3. 필터링
1. 백터화된 조건문 : ifelse() 함수
2. 벡터 동일성 테스트
3. 벡터 원소의 이름






































'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |
|---|---|
| R 3.2.1 프로그래밍 - 행렬과 배열 만들기 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 스칼라, 벡터, 배열, 행렬의 이해 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - 시작과 종료 및 도움말 시작하기 (0) | 2016.05.07 |
| R 3.2.1 프로그래밍 - R의 개요와 데이터 구조 (0) | 2016.05.07 |