
Jeongchul Kim
R 3.2.1 프로그래밍 - 데이터 프레임의 결합과 적용 본문
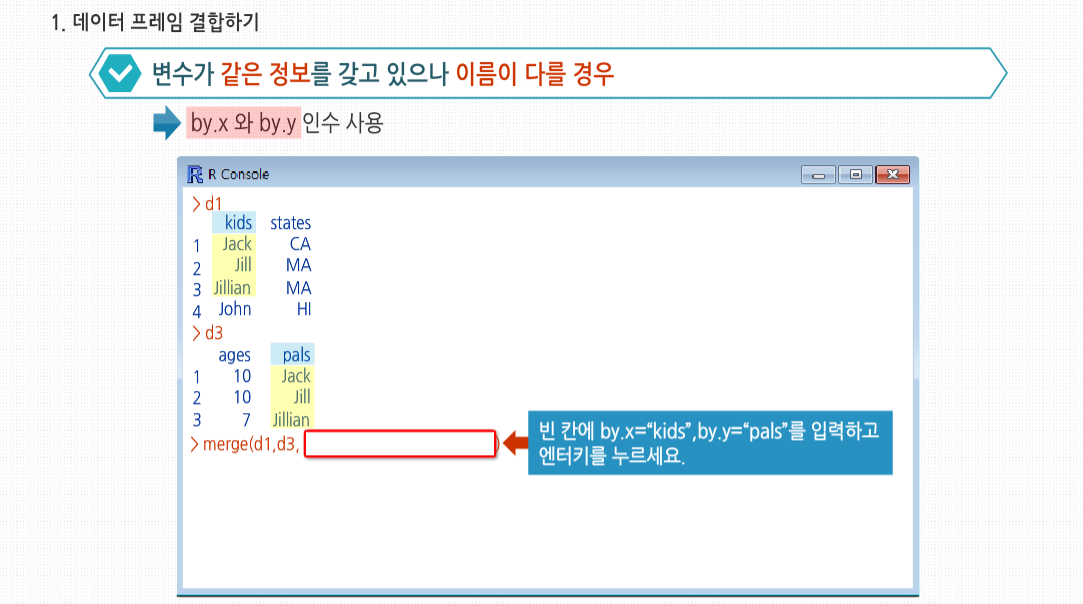
R 3.2.1 프로그래밍 - 데이터 프레임의 결합과 적용 로지스틱 회귀분석은 분석하고자 하는 대상들이 두 집단 혹은 그 이상의 집단으로 나누어진 경우에 개별 관측치들이 어느 집단으로 분류될 수 있는가를 분석하고 이를 예측하는 모형을 개발하는데 사용되는 대표적인 통계 알고리즘입니다. 분석 목적이나 절차에 있어서는 일반 회귀분석과 유사하나 종속 변수가 명목척도로 측정된 범주형 질적 변수인 경우에 사용한다는 점에서 차이가 있습니다. 로지스틱 회귀분석은 판별분석과는 달리 예측변수에 범주형 변수를 투입 할 수 있는 장점이 있는데요, 가장 일반적인 예로 성별을 매우 자연스럽게 예측 변수로 포함할 수 있습니다. 종속변수가 두 가지의 가능한 값만 가질 경우에는 이항 로지스틱 분석이 사용되며 셋 이상인 경우에는 다항 로지스틱 분석을 사용합니다. 성별의 경우는 가능한 값이 두 개이기 때문에 이항 로지스틱 변수를 사용합니다. 로지스틱 회귀분석은 연령에 따른 자동차 소유유무 및 연간 소득, 유권자의 출생 지역에 따른 후보 선택 성향 등과 같은 개인의 특성이 선택과 결과에 어떠한 영향을 미치는가 같은 통계에 적용할 수 있습니다. 데이터 프레임의 활용 데이터 프레임의 활용 관계형 데이터베이스에서 가장 중요한 연산 중 하나는 ‘조인’으로, 두 테이블을 공통 변수의 값을 이용해 합치는 기능입니다. R에서도 merge()를 사용해 비슷하게 두 데이터 프레임을 합칠 수 있습니다. merge()에 각 지정된 데이터 프레임 x,y를 사용하면, x와 y라는 데이터 프레임을 결합 합니다. 이 두 데이터 프레임이 한 개 이상의 공통된 이름의 열을 가진 경우의 예제를 살펴봅시다. 여기서 두 데이터 프레임은 공통으로 kids라는 변수를 갖고 있습니다. R은 두 데이터 프레임의 kids에서 같은 값을 갖고 있는 열을 찾아내는데요. 여기서는 Jack과 Jill, Jillian입니다. merge()를 통해 두 데이터 프레임을 결합해 볼까요? 공통된 이름의 열에 맞춰 d1의 값과, d2의 값이 결합된 데이터 프레임을 생성합니다. 변수가 같은 정보를 갖고 있으나 이름이 다를 경우, merge()에서는 by.x와 by.y 인수를 사용합니다. 다음 예제를 볼까요? Jack, Jill, Jillian이라는 같은 정보를 포함하고 있는 두 개의 데이터 프레임이 있습니다. 한 데이터 프레임에서는 kids라는 이름을 사용하고 다른 데이터 프레임에서는 pals이라는 이름을 사용합니다. 이 경우에는 by.x 인수와 by.y 인수를 사용하면 두 개의 프레임을 결합 할 수 있습니다. 그럼, by.x 인수와 by.y 인수에 각 데이터프레임의 이름을 다음과 같이 지정해 봅시다. 결과를 살펴볼까요? 데이터가 서로 잘 결합되었습니다. 원하지 않을 가능성이 높지만 결과값에서 중복된 값이 나오는 경우도 있습니다. d2a에는 두 개의 Jill이 있습니다. d1에는 매사추세츠의 Jill이 있고, d2a에는 그 Jill과 어디 사는지 모르는 다른 Jill이 있습니다. 앞에서는 양쪽 데이터 프레임에 같은 사람으로 추정되는 한 명의 Jill만 있어서 문제가 없었지만, 여기서는 merge(d1,d2a)를 호출하면 매사추세츠의 Jill이라는 하나의 경우만 나올 것입니다. 짝을 지을 변수를 찾을 때는 매우 조심해야 함을 이 간단한 예제가 확실히 알려줍니다. 컨설팅 프로젝트 예제를 하나 살펴볼까요? 문제는 나이가 많은 사원이 젊은 사원들만큼 임금을 받고 있는지 여부에 대한 것입니다. 나이가 많고 적은 직원을 비교하기 위한 나이와 실적 등급 등의 변수를 가진 데이터를 갖고 있고, 또한 DA와 DB라는 두 데이터 파일을 연결하기 위해 필요한 직원 ID 번호 또한 갖고 있습니다. DA 파일은 직원 ID, 세 개의 실적 등급, 직함 데이터에 대한 이름 즉, 헤더를 갖고 있습니다. DB에는 헤더가 없고, 변수는 역시 ID로 시작하고, 입사일 및 퇴사일이 이어집니다. 두 파일 모두 CSV 형식입니다. 데이터 클렌징 단계에서는 각 데이터가 정확한 필드의 개수로 구성됐는지를 확인합니다. 예를 들어 DA는 각 데이터 별 5개의 필드를 갖고 있어야 합니다. 이를 확인하는 내용을 살펴봅시다. 여기서 우선 DA 파일에는 필드가 ‘,’로 구분돼 있다고 명시했습니다. 파일의 각 줄에 필드가 몇 개씩 있느냐를 세는 함수로부터 다행히 모두 5라는 결과를 얻었습니다. 이를 일일이 눈으로 확인하는 것보다 정확하게 확인하기 위해 이와 같이 all() 함수를 사용해 보았습니다. TRUE 값이 반환되면 모두 괜찮다는 이야기 입니다. 또한 다음과 같은 형식을 사용할 수도 있습니다. 그리고 필드가 5개인 경우, 4개인 경우, 6개인 경우 등의 개수를 확인 합니다. 이렇게 확인이 끝나면 데이터 프레임 형식으로 파일을 읽어 들입니다. 각 필드에서 철자 오류를 확인하고 싶어서 위와 같은 코드를 실행했습니다. 이 코드는 각 열에서 모든 고유값에 대한 리스트를 보여주므로 이를 직접 확인해 잘못된 철자를 잡아낼 수 있습니다. 여기서 두 데이터 프레임을 직원 ID를 갖고 합치는 작업이 필요하므로 이 코드를 실행해 줍니다. 두 데이터 프레임을 합칠 때 양쪽에서 모두 첫 번째 열을 사용한다고 정의했습니다. 숫자 대신 필드명을 사용할 수도 있습니다. 리스트에서처럼 데이터 프레임에도 lapply와 sapply를 사용할 수 있습니다. 데이터 프레임은 리스트의 요소가 데이터 프레임의 열로 구성된 리스트의 특이한 경우라는 것을 기억합시다. 그러므로 데이터 프레임에 lapply()를 사용해 특정 함수 f()를 적용하면, f()는 프레임의 각 열에 호출되고 리스트 형식으로 결과값을 생성할 것입니다. 이 예제에서 사용한 lapply()를 봅시다. d1은 kids와 ages가 정렬된, 두 벡터로 이뤄진 리스트가 됩니다. d1은 데이터 프레임이 아닌 그냥 리스트라는 것을 염두 해 둡시다. d1을 데이터 프레임으로 바꾸고 싶으면, 이와 같이 입력하여 사용할 수 있습니다. 하지만 이렇게 사용할 경우, 이름과 나이의 관계가 사라졌으므로 별로 소용이 없습니다. 예를 들어 Jack의 경우 12살이 아닌 10살로 리스트에 들어갔죠. 만약 관계성을 유지한 채로 한 열을 기준으로 해 데이터 프레임을 정렬하고 싶다면, 다른 방법으로 접근해야 합니다. 고급 데이터 프레임 고급 데이터 프레임 로지스틱 회귀모델 적용에 대해 알아봅시다. 로지스틱 모델은 1개 이상의 관측 변수를 사용해 랜덤 변수 Y에 대해 0 또는 1 값을 예측하는 데에 사용됩니다. 함수값은 주어진 관측 변수에 대해 Y가 1일 확률입니다. 이에 대해 관측 치 중 하나를 X로 두면, 모델은 이와 같이 나타납니다. 선형 회귀모델처럼 𝛽𝑖의 값은 glm()에 family=binomial 인수를 추가해 데이터를 통해 추정합니다. 다음 확장예제를 살펴볼까요? 여기 성별이 M,F,I 로 표기된 전복 데이터 세트가 있습니다. 수컷은 M, 암컷은 F, 어린 전복은 I로 표기합니다. 이 데이터 세트에 길이, 무게, 고리 등 고리 등 8가지 변수를 사용해 로지스틱 회귀모델로 어린 전복의 성별을 예측해 봅시다. 이때, sapply()를 사용해 8개의 각 변수별로 성별을 예측하는 8개의 단일 예측 모델을 코드 한 줄만으로 생성할 수 있습니다. 다음 예시를 통해 좀 더 자세히 살펴볼까요? 1,2번째 줄에서는 데이터 프레임을 읽어서 새끼 전복에 대한 관측치를 제외합니다. 6번째 줄에서 sapply()를 Gender라는 첫 번째 열을 제외한 부분 데이터 프레임에 호출합니다. 다르게 말하자면, 이는 8가지 관측 변수로 이뤄진 8개의 열로 이뤄진 부분 프레임 입니다. 그러므로 lftn()은 부분 프레임의 각 열에 적용됩니다. 형식 인수 clmn을 통해 부분 프레임의 각 열이 입력값으로 들어가면, 코드의 4번째 줄에서 이 열을 이용해 성별을 예측하는 로지스틱 모델을 생성합니다. 일반적인 회귀함수인 lm()이 여러 인수를 가진 “lm” 클래스에 객체를 반환했고, 그 중에 𝛽𝑖의 추정값 벡터인 $coefficients가 있었다는 것을 떠올려 봅시다. 또한 다른 이름과 겹치지 않을 경우리스트의 구성 요소 이름은 요약해 쓸 수 있다는 것도 기억합시다. 그러므로 여기서는 coefficients를 coef로 줄여 사용합니다. 마지막으로 6번 째 줄에서는 𝛽𝑖의 추정값인 8쌍의 값을 반환합니다. 결과를 확인해 볼까요? 당연히 2-8 행렬을 얻게 됩니다. 이 행렬의 J번째 열에는 J번째 관측치를 사용해 로지스틱 회귀분석을 할 때 사용하는 𝛽𝑖의 추정값 쌍이 들어있습니다. 사실 일반적인 행렬 및 데이터 프레임에서는 apply()를 사용해서도 같은 결과를 얻을 수 있지만, 실제로 써보니 이 경우 좀 느려지는 것이 발견됩니다. 행렬을 할당하는 시간에서 차이가 나기 때문입니다. glm()의 반환값에 쓰이는 클래스를 살펴 봅시다. loall은 glm과 lm이라는 클래스를 가진다는 뜻입니다.1. 데이터 프레임 결합하기
2. lapply()와 sapply() 함수 사용하기(데이터 프레임에 함수 적용하기 )
1. 로지스틱 회귀모델 적용하기
















'R프로그래밍' 카테고리의 다른 글
| R 3.2.1 프로그래밍 - 팩터와 테이블의 이해와 활용 (3) | 2016.05.31 |
|---|---|
| R 3.2.1 프로그래밍 - 데이터 프레임의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 적용과 재귀 리스트 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 리스트의 생성과 연산 (0) | 2016.05.13 |
| R 3.2.1 프로그래밍 - 행렬과 배열의 활용 (0) | 2016.05.10 |