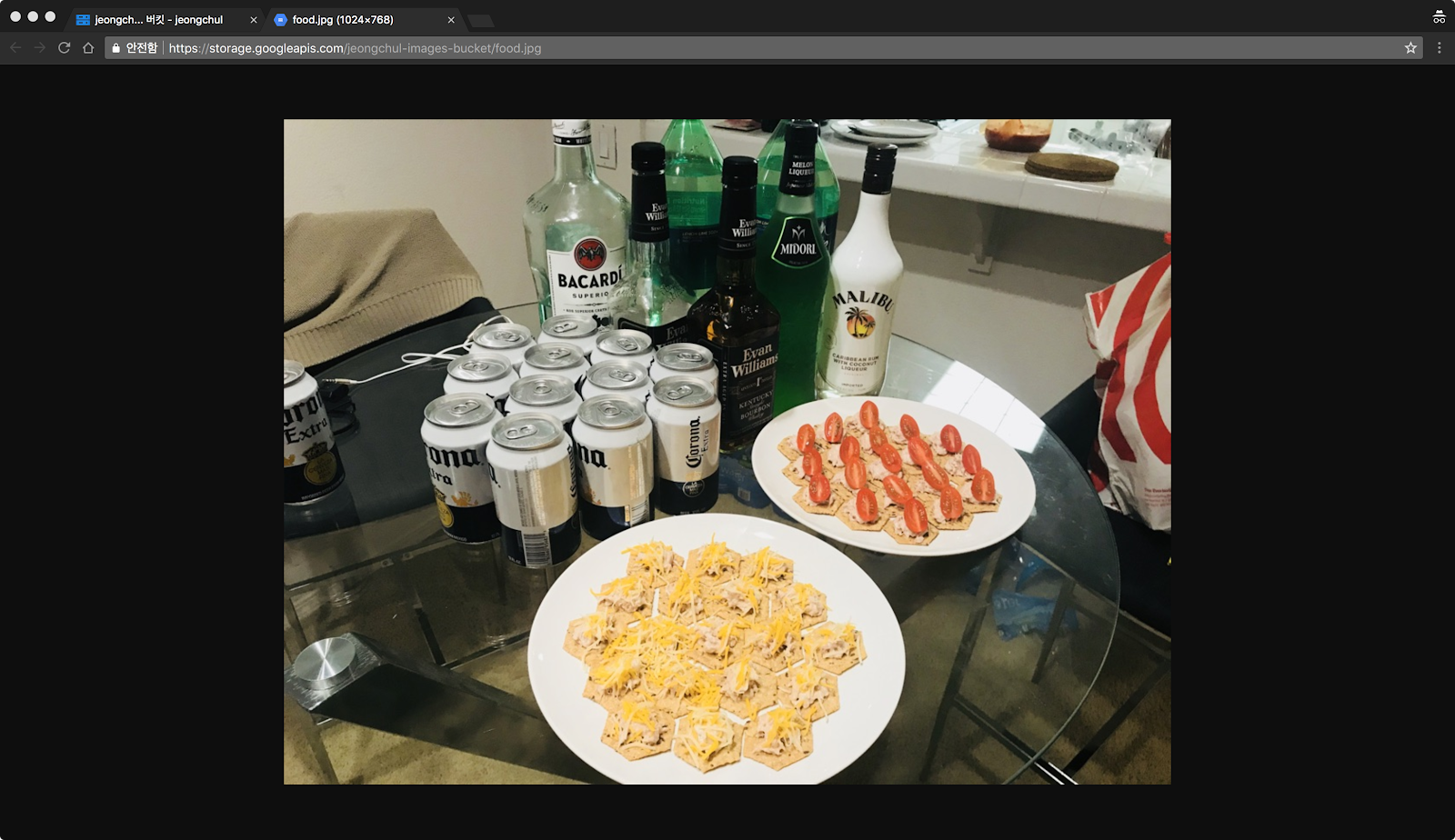
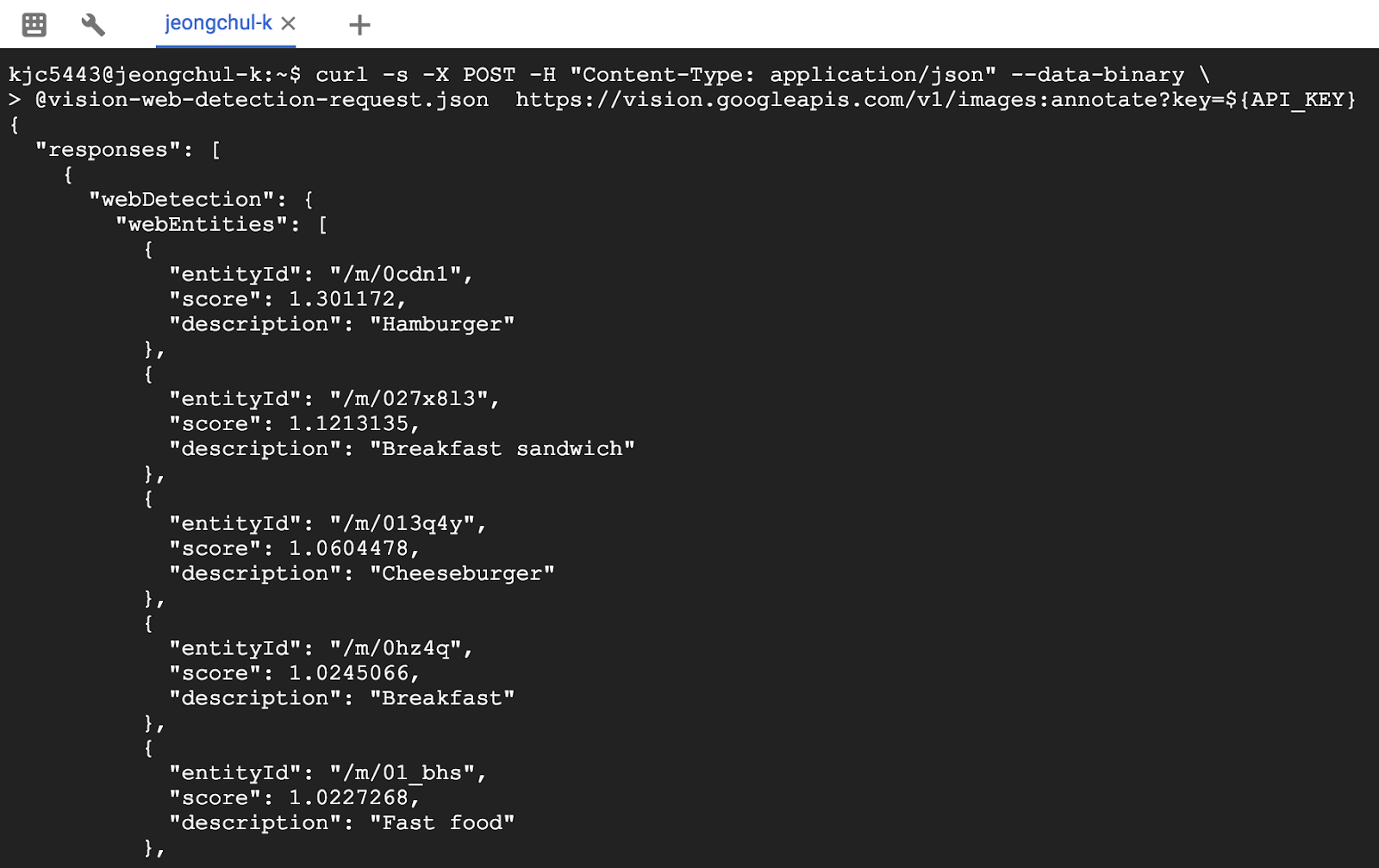
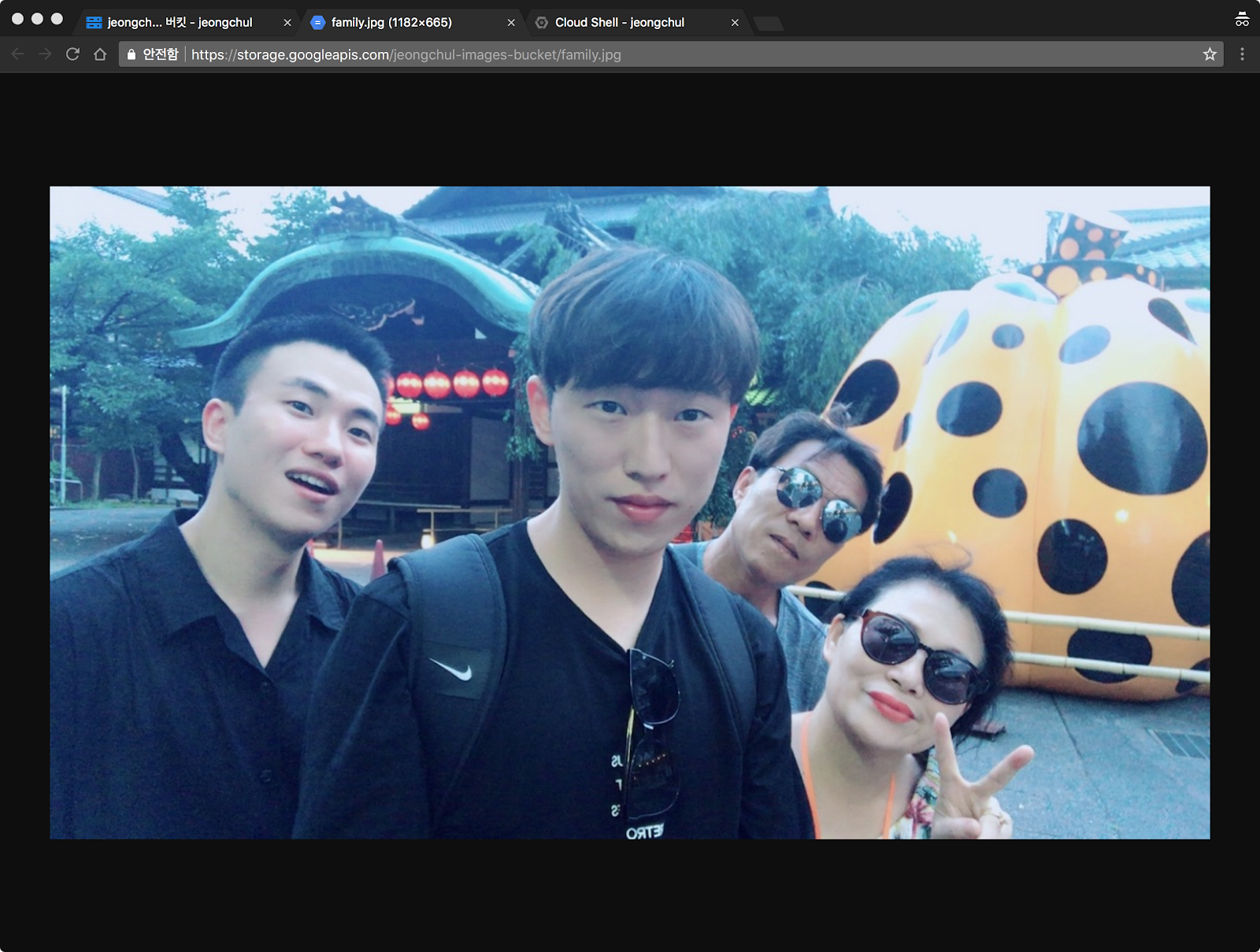
Google Cloud Platform Cloud Vision API를 이용한 이미지, 얼굴 Detection Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API Google Cloud Platform 이용한 텍스트 카테고리 분류 Natural Language API 이미지 분류(classification) 테스트를 위해서 이미지 한 장이 필요합니다. 사진을 준비해주세요! 저는 미국에서 있을 때 홈파티 했을 때 찍은 사진으로 진행해보겠습니다. Google Storage로 이동합니다. 해당 bucket으로 이동합니다. 이미지 파일을 업로드 합니다. 공개 링크를 선택 합니다. 공개 링크로 이동해봅시다. Google Vision API를 테스트할 이미지는 준비가 완료되었습니다. Cloud Shell 환경에서 bucket 이름으로 vision-label-detection-request.json 파일을 생성합니다. 원하는 편집기를 선택하여 만들거나 Cloud Shell의 code editor로 수정합니다. 저는 code editor를 사용하겠습니다. File 메뉴에서 -> New -> File 버튼을 클릭합니다. 이름을 vision-label-detection-request.json으로 입력하고 다음의 코드를 입력합니다. 가운데에 있는 my-bucket-name과 food.jpg를 수정해주세요. { 첫 번째 Cloud Vision API 기능은 Label detection입니다. 이 method는 이미지에있는 labels(word) 목록을 반환합니다. Vision API를 호출하기 위해 curl을 이용합니다. API_KEY에 오류가 있으시다면 $ echo API_KEY 로 설정되어 있는지 확인해주세요!! 첫 링크 글에서 API_KEY Set up을 따라하면서 진행해주세요! 결과는 다음과 같습니다. score가 높은 순으로 정렬(sorting)되어 있습니다. 제일 높은 score의 label은 음식입니다. 2위로는 cuisine(요리) 3위로는 dish(요리), 4위로는 meal(식사) 로 나왔습니다. 사진에 술(맥주와 양주)가 많아서 예상했던 바와는 조금 다르네요ㅎㅎ; Vision API에서 찾은 각 label에 대해 다음을 반환합니다. - description : 아이템의 이름 - score : 0~100의 숫자이며, label에 대한 확신도(confidence) 값입니다. - mid : Google의 Knowledge Graph를 의미하며, Knowledge Graph API 호출 시에 mid를 이용해 자세한 정보를 얻을 수 있습니다. 이번에는 다른 이미지를 사용해보겠습니다. LA에서 그랜드 마켓에서 에그슬럿(eggslut)의 햄버거 사진을 올려보겠습니다. vision-label-detection-request.json 에서 gcsImageUri를 수정해줘야겠죠? 다시 호출해봅시다. 결과로는 1등이 brunch, 2등이 hamburger가 나왔네요 적절한 결과인 것 같습니다ㅎㅎ. Vision API는 이미지의 내용에 label을 지정하는 것 외에도, 인터넷에서 이미지에 대한 추가 세부 정보를 검색 할 수 있습니다. API의 webDetection method를 통해 많은 재미있는 데이터를 얻을 수 있습니다. 여기서는 위에서 사용한 에그슬럿 이미지를 사용해보겠습니다. 위의 vision-label-detection-request.json 파일에서 코드를 복사해서 vision-web-detection-request.json 파일을 새로 생성해 붙여넣기 하고 한 줄을 변경합시다. features 에서 유형을 LABEL_DETECTION에서 WEB_DETECTION (으)로 변경합니다. 자 다시 curl 명령을 실행해봅시다. @ json 파일 이름을 변경해야 합니다. 결과는 다음과 같습니다. 응답(response)으로 webEntities를 살펴봅시다. 이 이미지는 대부분 Hamburger나 Breakfast sandwich, Cheeseburger 에서 많이 사용되었습니다. fullMatchingImages, partialMatchingImages 및 PagesWithMatchingImages 아래에서 URL을 검사하면 대부분 햄버거 사진이 많을 것입니다. 내가 올린 eggslut Hamburger 이미지와 비슷한 사진을 찾고 싶다면 visuallySimilarImages 가 도움이 될 것입니다. url 주소를 따라가봅시다. 첫 번째는 글쎄요.. brunch에서 비슷한 와플 사진을 가져왔네요. 그나마 세 번째 url 사진이 비슷하네요 마지막 주소의 url 사진도 적절합니다. 위의 방법은 Google Image에서 검색하는 방식과 유사합니다. Cloud vision을 사용하면 REST API를 이용해 application에 통합할 수 있습니다. 다음으로 사용할 얼굴을 감지할 사진을 업로드해봅시다. 교토에서 가족과 함께 찍은 사진으로 진행해보겠습니다. bucket에다가 업로드해주세요. request file을 수정해봅시다. 위에서 파일을 복사했던 것 처럼 이번에는 vision-face-detection-request.json 파일을 생성해봅시다. gcsImageUri에 bucket과 image의 이름을 수정합시다. { 이번에도 Vision API를 실행해보겠습니다. 결과는 다음과 같습니다. response에서 faceAnnotations 객체를 살펴봅시다. 이미지에서 발견된 각 얼굴(face) 객체를 반환합니다. - boundingPoly는 이미지에서 얼굴 주위의 x, y 좌표를 제공합니다. 위의 명령에서 | grep boundingPoly 을 이어 붙인다면 Face detection 개수를 알 수 있습니다. 사진에서 보다시피 저희 가족 4명을 모두다 감지했네요. 아쉽게도 여기의 사진에서는 landmarkAnnotations 객체는 반환되지 않았습니다. landmarkAnnotations에서는 랜드마크의 위치를 알려주며 위도와 경도 좌표를 알려줍니다. 이상으로 마치겠습니다.첫 링크 글에서 API_KEY Set up을 따라하면서 진행해주세요!
Google Storage는 첫 링크 글에서 진행했습니다!
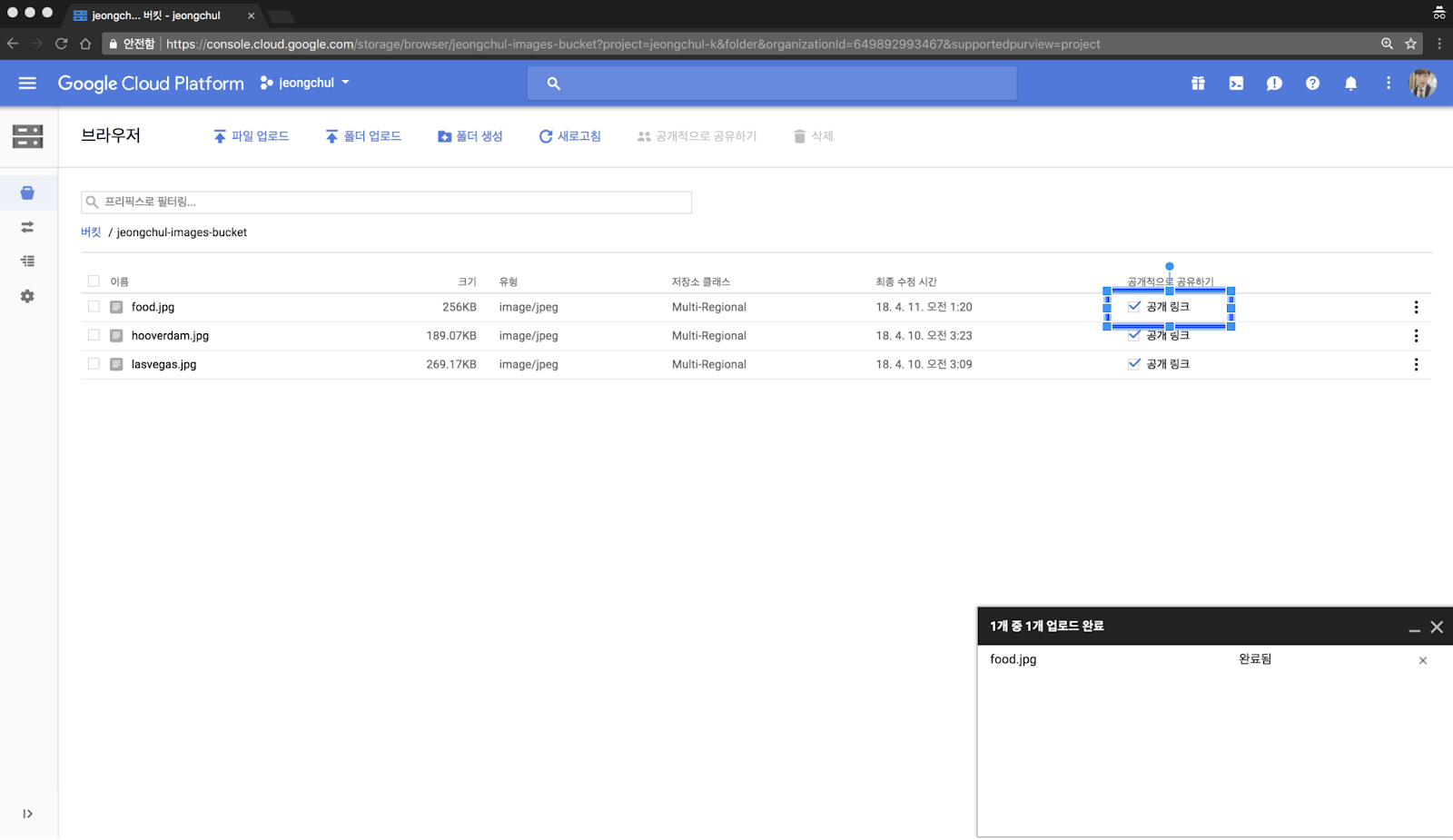
Google Storage Bucket에 이미지 업로드 하기
Vision API 요청(request) 생성하기
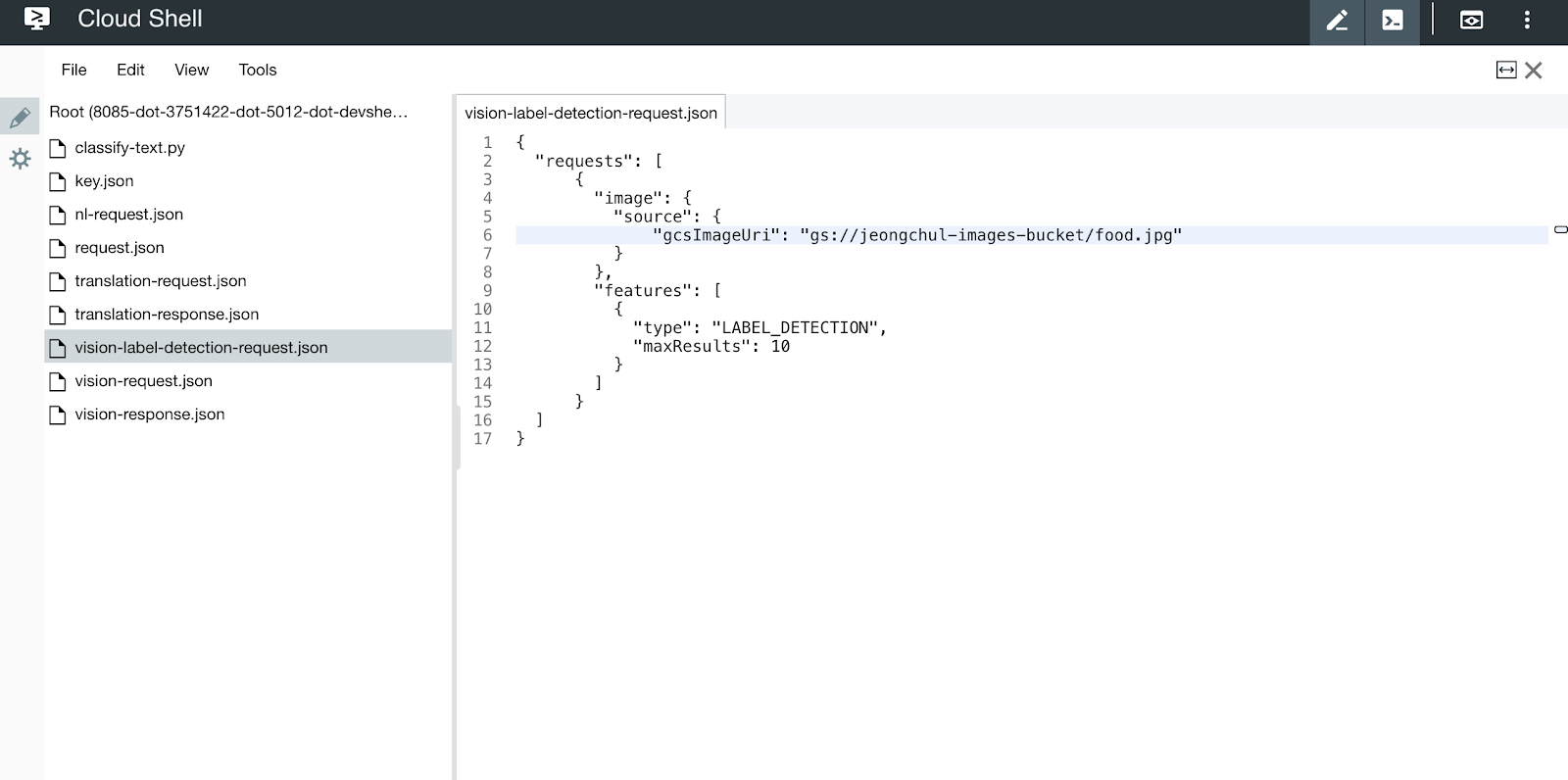
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/food.jpg"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}Label Detection
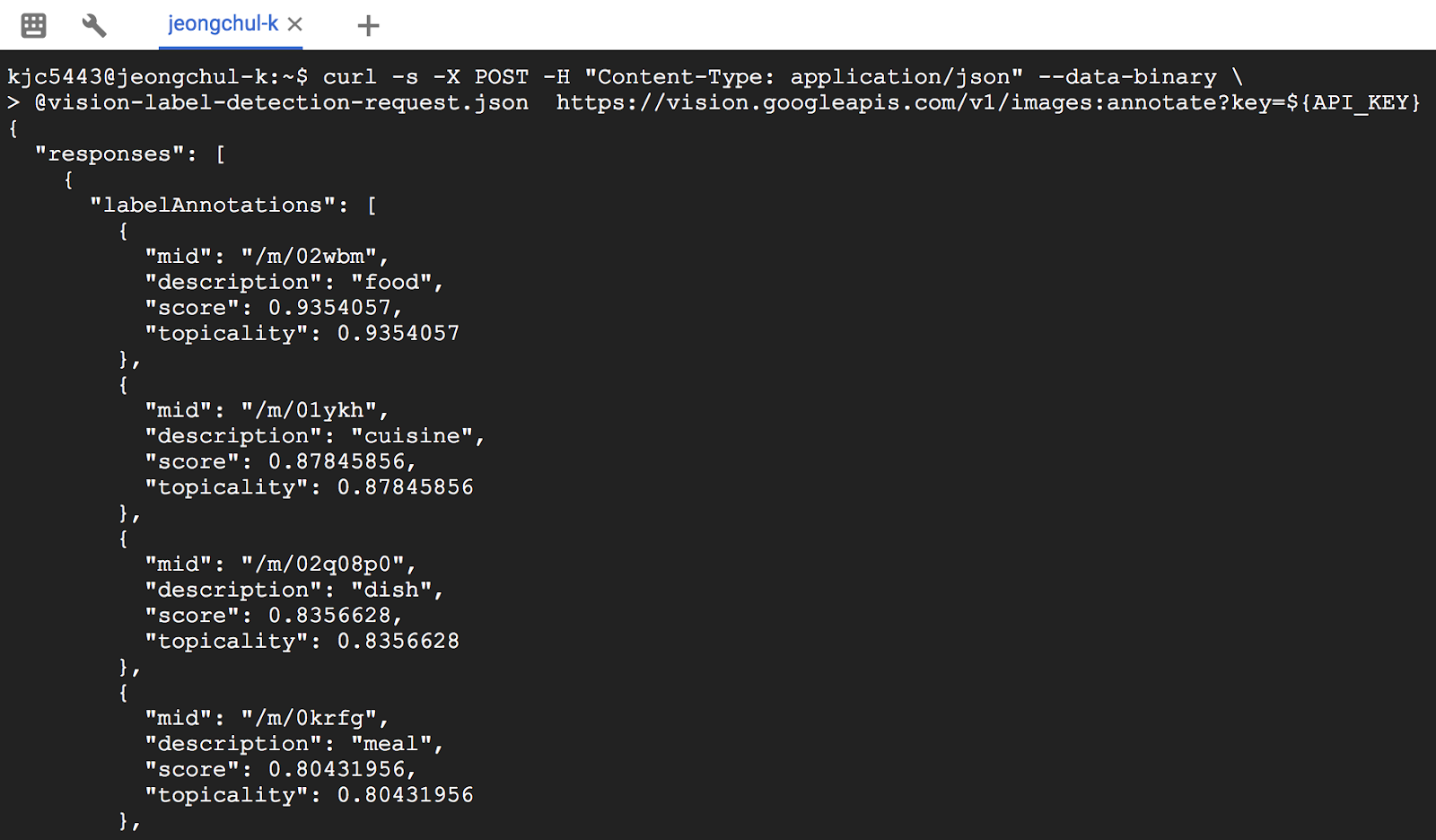
$ curl -s -X POST -H "Content-Type: application/json" --data-binary @vision-label-detection-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
$ curl -s -X POST -H "Content-Type: application/json" --data-binary @vision-label-detection-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
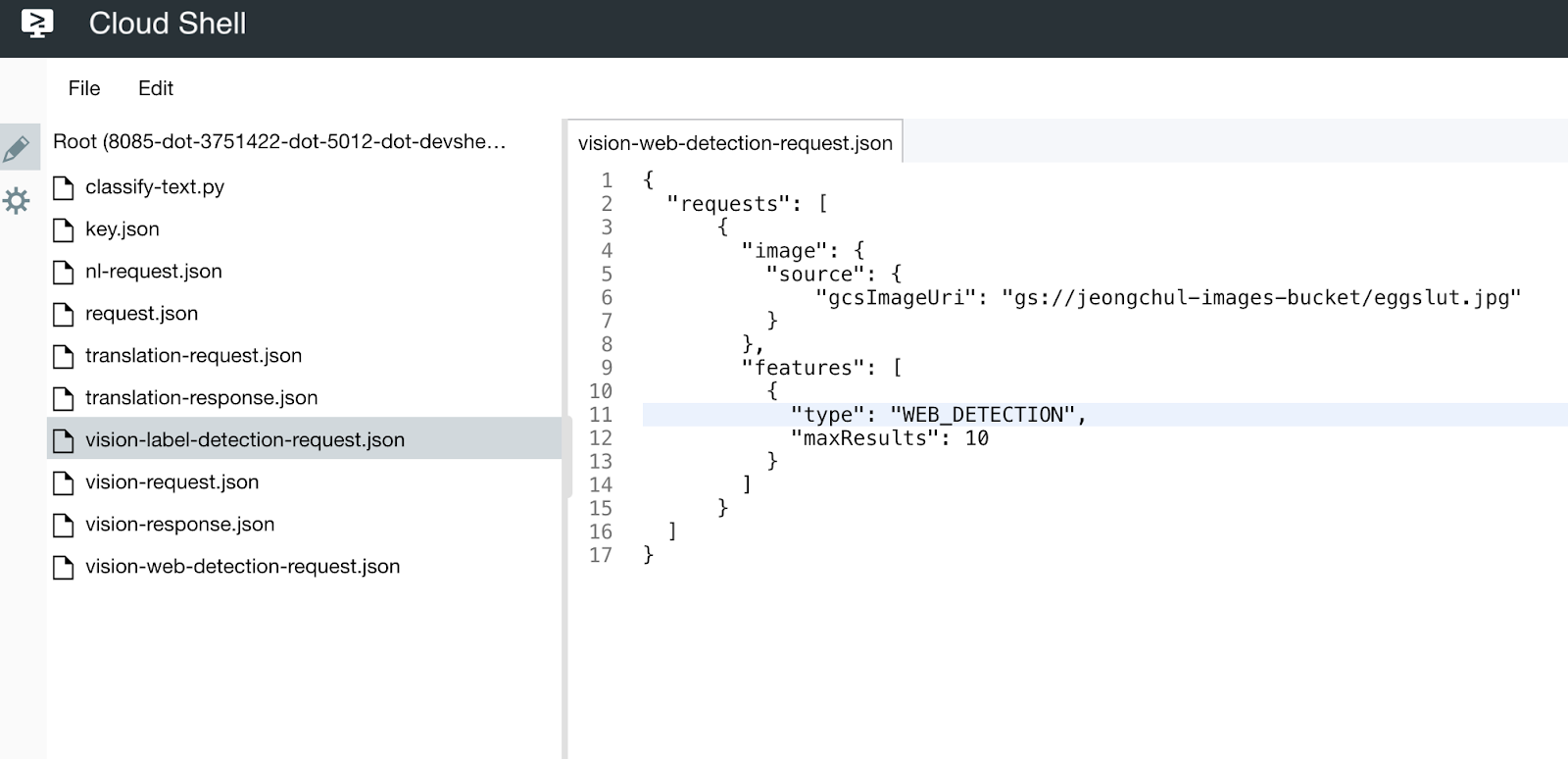
Web Detection
- 비슷한 이미지가있는 페이지의 콘텐츠를 기반으로 Google 이미지에서 발견된 아이템 목록
- 해당 페이지의 URL과 함께 웹에서 발견되는 일치하는 이미지의 URL
- 반전된 이미지 검색과 같은 유사한 이미지의 URL$ curl -s -X POST -H "Content-Type: application/json" --data-binary @vision-web-detection-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
Face(얼굴) Detection
Request file 수정
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://jeongchul-images-bucket/family.jpg"
}
},
"features": [
{
"type": "FACE_DETECTION",
"maxResults": 10
}
]
}
]
}Vision API 실행
$ curl -s -X POST -H "Content-Type: application/json" --data-binary @vision-face-detection-request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}
- fdBoundingPoly는 얼굴의 스킨 부분에 초점을 맞춘 boundingPoly보다 작은 상자입니다.
- landmarks는 각 얼굴 특징에 대한 객체 배열입니다. 이것은 z 좌표가 깊이 인 곳의 특징 (x, y, z 좌표)의 3D 위치와 함께 표식의 유형을 알려줍니다. 나머지 값은 기쁨, 슬픔, 분노 및 놀라움의 가능성을 포함하여 얼굴에 대한 세부 정보를 제공합니다.
!]

















'Google Cloud Platform' 카테고리의 다른 글
| MapReduce 프로그래밍(Hadoop) using GCP DataProc (0) | 2018.06.04 |
|---|---|
| MongoDB using Google Cloud Platform (1) | 2018.06.03 |
| Google Cloud Platform 이용한 텍스트 카테고리 분류 Natural Language API (1) | 2018.04.10 |
| Google Cloud ML Vision API를 이용한 이미지 텍스트 추출 그리고 번역을 위한 Translation API와 Natural Language API (1) | 2018.04.10 |
| Deployments 관리 Kubernetes in Google Cloud Platform (0) | 2018.04.08 |