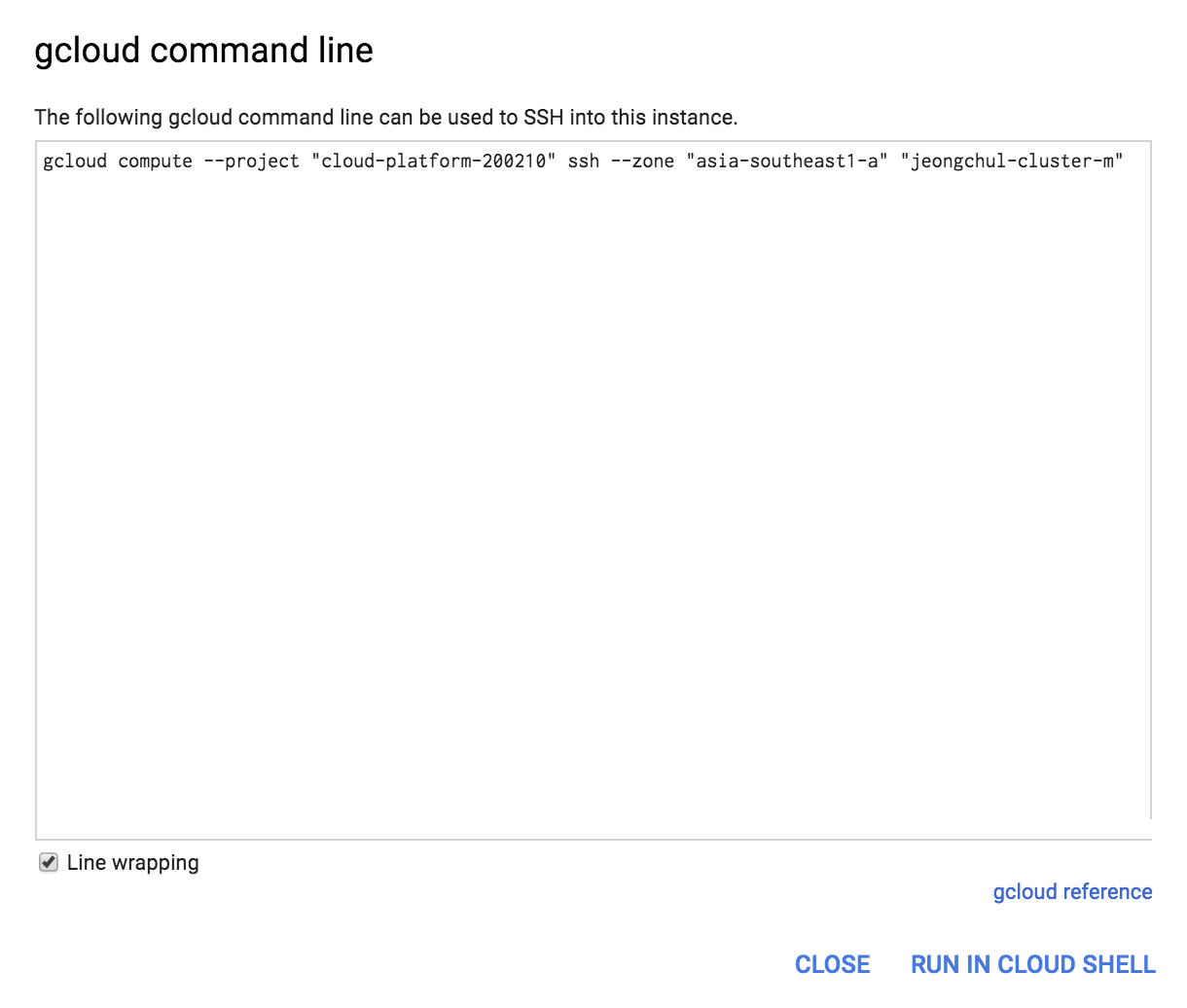
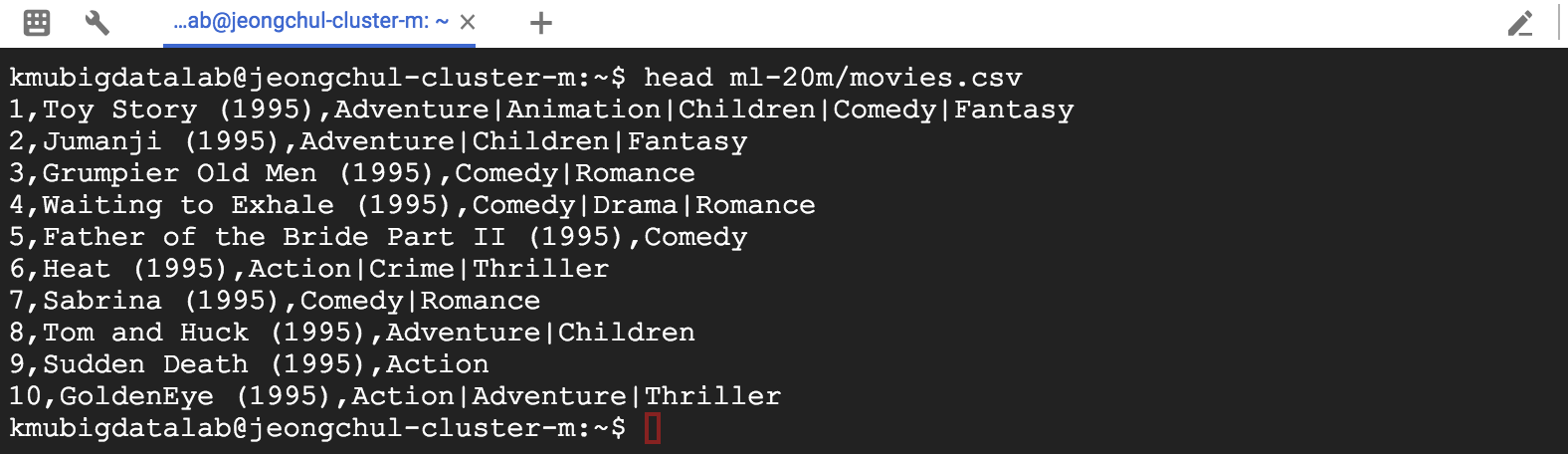
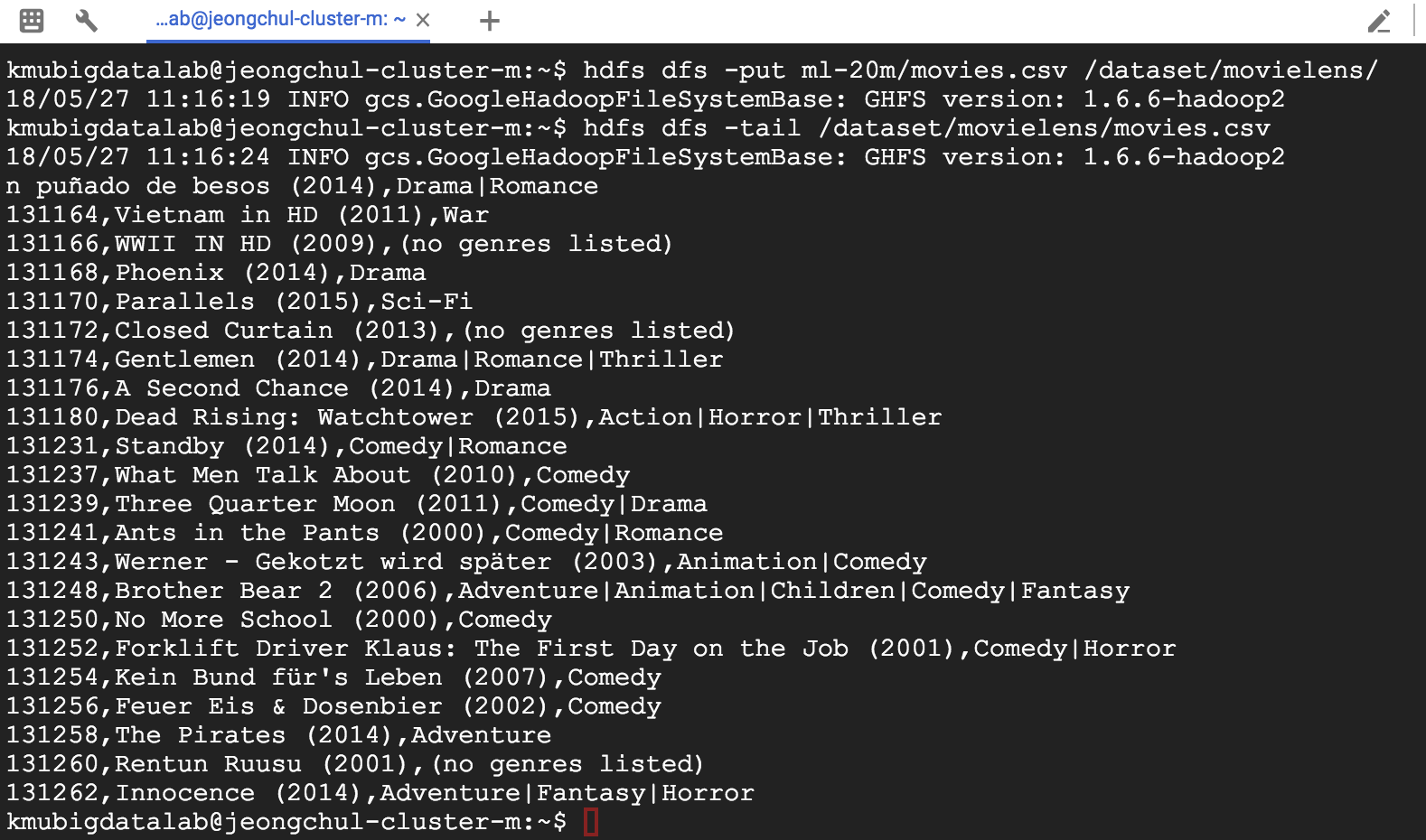
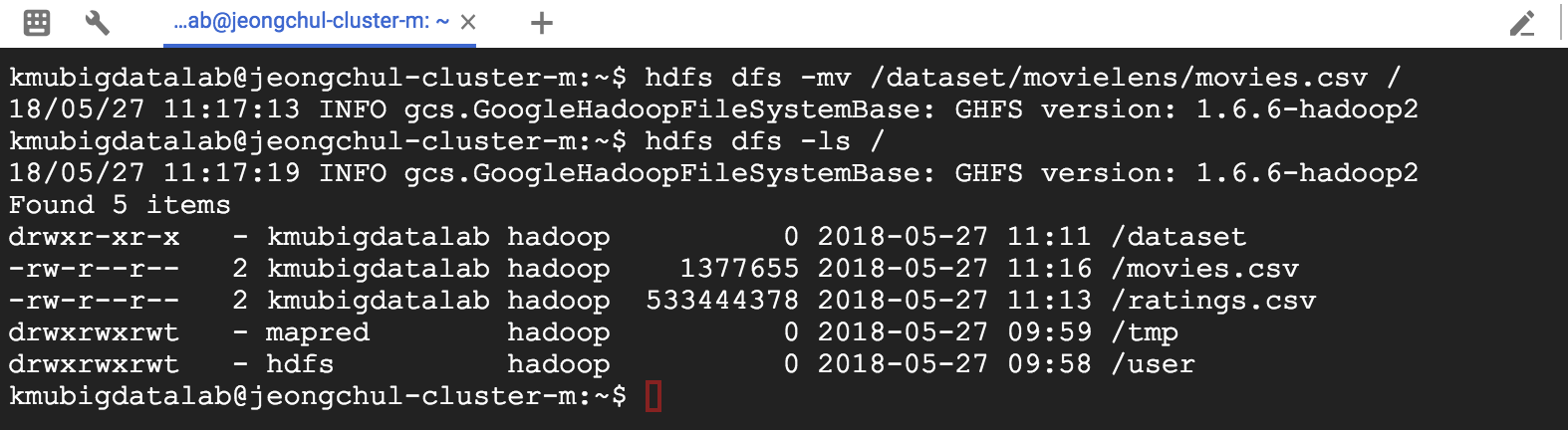
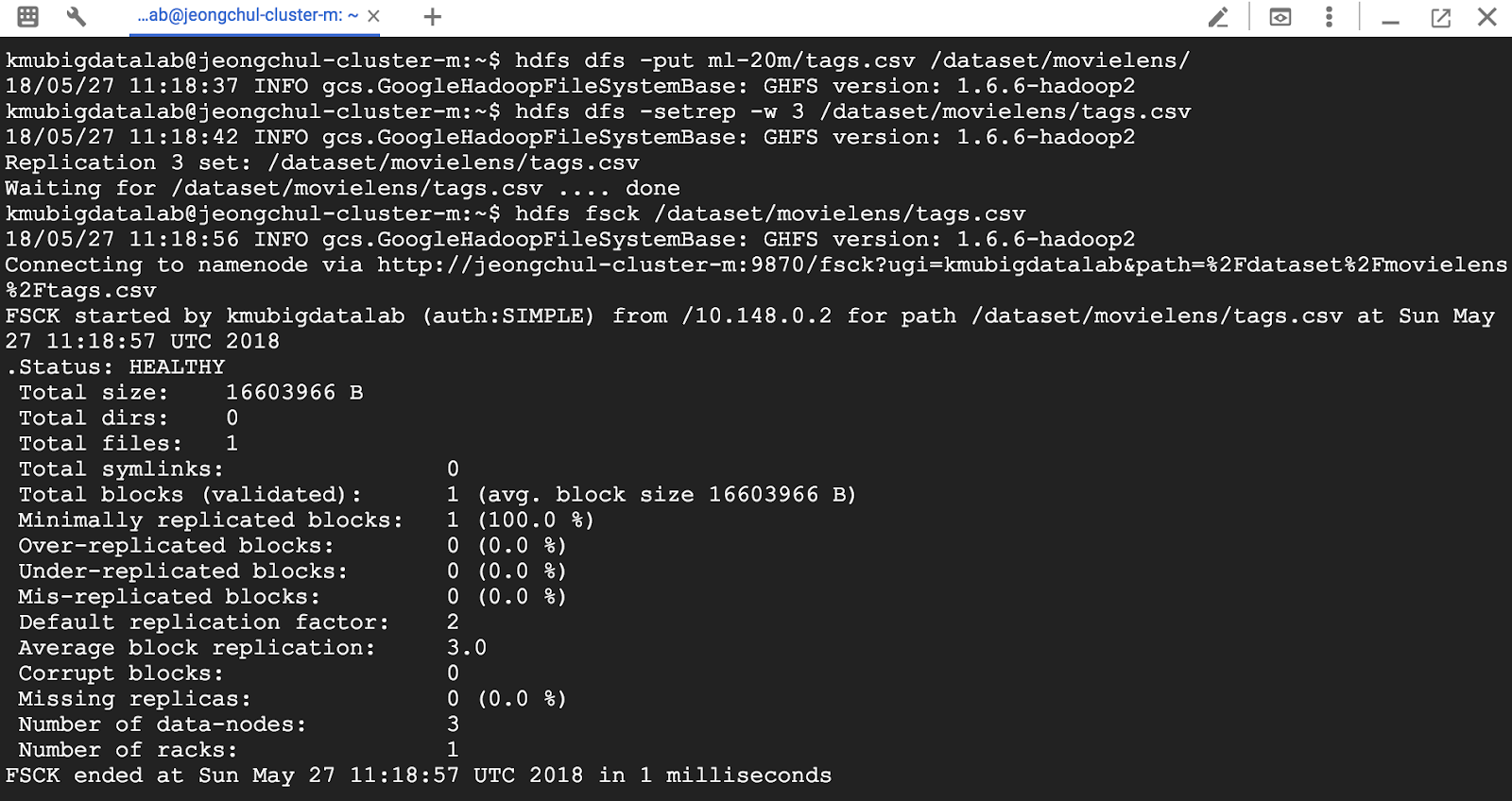
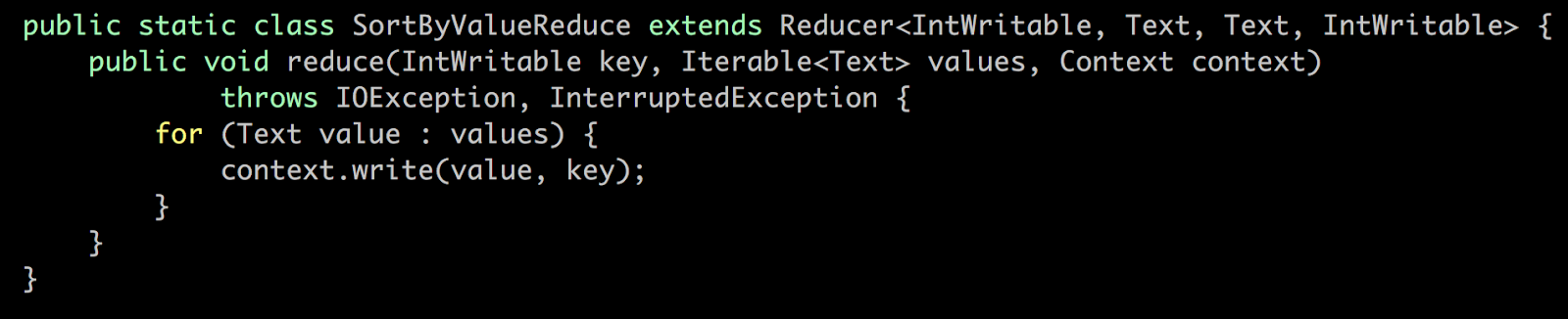
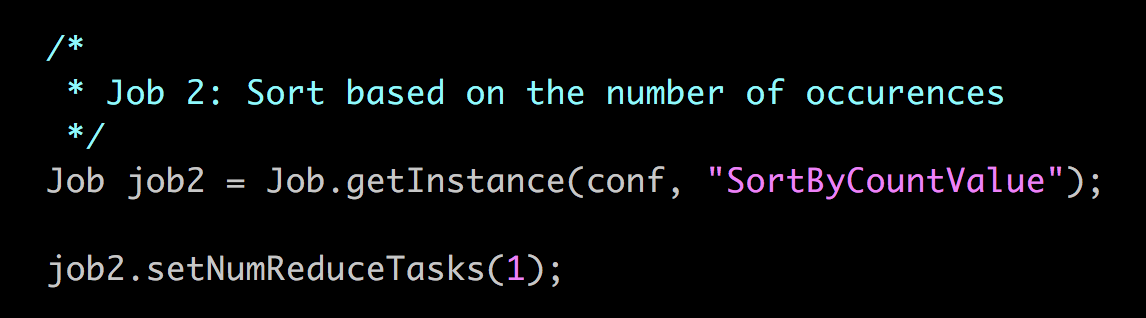
MapReduce 프로그래밍(Hadoop) using GCP DataProc DataProc은 Google Cloud Platform의 서비스로 Apache Spark 및 Apache Hadoop을 실행하는 빠르고 쉽고 비용 효율적인 방법을 제시합니다. - 신속하고 확장 가능한 데이터 처리 Google에 로그인하여 다음의 URL로 이동합니다. 네비게이션 메뉴에서 Dataproc -> Clusters를 클릭합니다. Apache Hadoop 클러스터를 프로비저닝하고 기본 분석 데이터 저장소에 연결하려면 API 사용을 클릭합니다. Enable API 화면이 사라지면 "Create Cluster"를 클릭합니다. DataProc을 설정해봅시다. 클러스터 이름을 입력합니다. 사용 가능한 Zone은 세계 각국에 있습니다. 저는 asia-southeast1-a에 설정하겠습니다. Master node에는 2 vCPUs를 설정하겠습니다. Worker node 또한 같은CPU와 7.5GB메모리를 설정합니다. Nodes에 개수는 최소 2개입니다. 저는 3개를 설정하겠습니다. 설정을 마치면 Create 버튼을 클릭합니다. Dataproc 클러스터를 생성하기 위해서 Provisioning을 시작합니다. ~5 분 정도가 소요됩니다. 클러스터에 있는 Web UI 접근을 허용하기 위해서는 방화벽(firewall) 규칙을 설정해야 합니다. 네비게이션 메뉴에서 VPC Network -> Firewall rules 메뉴를 클릭합니다. CREATE FIREWALL RULE 버튼을 클릭합니다. 새로 생성하는 방화벽(Firewall) 규칙의 이름은 default-allow-dataproc-access로 설정합니다. Targets은 All instances in the network로 설정하며, Source filter -> IP range로 설정합니다. Source IP ranges는 0.0.0.0/0으로 입력합니다. Protocols and ports에서는 Specified protocols and ports를 클릭하고 tcp:8088;tcp:9870;tcp:19888을 입력합니다. - 8088은 Hadoop을 위한 포트 - 9870은 HDFS를 위한 포트 - 19888은 Hadoop 데이터 노드의 Jobhistory를 위한 포트입니다. hdfs와 hadoop의 웹 UI를 확인할 수 있습니다. 왼쪽 상단 탐색 메뉴를 클릭하고 Compute Engine & VM Instances를 선택하십시오. 인스턴스가 나타납니다. w-0, w-1로 끝나는 인스턴스는 작업자 노드입니다. -m으로 끝나는 인스턴스는 마스터 노드입니다. 웹용 마스터 노드의 외부 IP를 사용할 것입니다. 마스터 노드 외부 IP를 복사하고 새 브라우저에서 아래 나열된 포트를 사용하여 IP를 붙여 넣습니다. http://External-IP:8088로 이동하여 Hadoop Cluster 정보를 확인해봅시다. 노드를 클릭하면 슬레이브 노드의 정보도 표시됩니다. http://External-IP:9870로 이동하여 HDFS Cluster 정보를 확인해봅시다. 여기에서 hdfs 및 많은 유용한 메트릭의 사용법을 볼 수 있습니다. http://External-IP:8088로 이동하여 Hadoop JobHistory 를 확인해봅시다. 여기서 hadoop job의 세부사항을 볼 수 있습니다. 이제 모든 구성이 설정되었으므로 Dataproc을 사용하여 WordCount의 연습을 수행합니다. ssh 통신을 통해 마스터 노드로 접속합니다. 방금 설명한 방법으로 마스터 노드에 연결할 수없는 경우 Google Cloud Shell을 사용합니다. “RUN IN CLOUD SHELL” 버튼을 클릭합니다. Cloud Shell을 이용할 VM을 프로비저닝 합니다. Google 클라우드 쉘이 명령과 함께 나타나면이 명령을 추가하고 "Enter"키를 누릅니다. $ gcloud compute --project "cloud-platform-200210" ssh --zone "asia-southeast1-a" "jeongchul-cluster-m" -- -4 -L 8080:jeongchul-cluster-m:8088 "-4"는 IPv4 사용을 의미하며, "-L"은 hadoop의 웹 UI를보기위한 포트 포워딩 8080 -> 8088을 의미합니다. hadoop의 웹 UI를 보려면 포트 8080에서 미리보기를 클릭합니다. 먼저, 마스터 노드에서 Hadoop jar 및 필요한 라이브러리에 액세스하도록 설정을 구성해야합니다 $ echo "export HADOOP_CLASSPATH=$(hadoop classpath)" >> ~/.bashrc $ source ~/.bashrc $ hadoop classpath 입력 데이터의 경우 grouplens의 movie_lens 데이터 데이터 세트를 사용합니다. 이 데이터 세트는 영화 추천 서비스 인 영화 렌즈 (MovieLens)의 5 성급 등급 및 자유 텍스트 태깅 활동을 설명합니다. 이 영화에는 27278 편의 영화에 20000263 개의 평점과 465564 개의 태그 애플리케이션이 포함되어 있습니다. https://grouplens.org/datasets/movielens/ $ wget https://s3.ap-northeast-2.amazonaws.com/kmubigdata-movielensdata/ml-20m.zip 압축을 풉니다. $ unzip ml-20m.zip 데이터셋을 살펴봅시다. $ head -n 3 movies.csv # movieid, title, genres $ head -n 3 ratings.csv # userid, movieid, tag, timestamp $ head -n 3 tags.csv # userid, movieid, rating, timestamp 첫 줄에 있는 header 부분을 제거합니다. $ sed -i 1d ml-20m/*.csv // removing column header per each csv, wait for a while $ rm -f ml-20m.zip $ head ml-20m/movies.csv hdfs 사용법은 다음의 명령어로 확인할 수 있습니다. $ hdfs 자주 사용하는 hdfs dfs 사용법은 다음의 명령어로 확인할 수 있습니다. $ hdfs dfs HDFS에서 루트 디렉토리에 있는 명령어는 다음과 같습니다. $ hdfs dfs -ls <args> $ hdfs dfs -ls / mkdir을 이용해 HDFS에 디렉토리를 생성합니다. $ hdfs dfs -mkdir [-p] <paths> $ hdfs dfs -mkdir -p /dataset/movielens/ $ hdfs dfs -ls /dataset/ put을 이용해 로컬 파일 시스템에서 HDFS로 복사합니다. $ hdfs dfs -put <localsrc> <dst> $ hdfs dfs -put ml-20m/ratings.csv /dataset/movielens/ $ hdfs dfs -ls /dataset/movielens/ fsck를 통해 HDFS의 파일 시스템을 진단합니다. 다음의 명령어로 ratings.csv 전체 크기가 533444378 Byte인 것을 알 수 있고 4개의 파티션으로 나눠져 있는 것을 볼 수 있습니다. Default replication factor는 2로 HDFS안에서 block이 2개로 복제된 것을 알 수 있습니다. $ hdfs fsck /dataset/movielens/ratings.csv hdfs 시스템에서 기본 블록 크기는 128MB입니다. (예 : ratings.csv 크기 = 534MB -> 4 블록 생성) 이 옵션을 사용하여 블록의 크기를 정의 할 수 있습니다. $ hdfs dfs -Dfs.block.size = 1048576 -put ml-20m / ratings.csv / 블록 크기는 1MB가되며 rating.csv (534MB)는 500 개 이상의 블록으로 분할됩니다. 이를 fsck 명령으로 확인할 수 있습니다. $ hdfs dfs -Ddfs.block.size=1048576 -put ml-20m/ratings.csv / $ hdfs fsck /dataset/movielens/ratings.csv get이라는 명령어를 통해 HDFS에 있는 파일을 로컬 파일 시스템으로 복사할 수 있습니다. $ hdfs dfs -get <localsrc> <dst> $ hdfs dfs -get /dataset/movielens/ratings.csv /tmp/ $ ls /tmp/ratings.csv cat을 통해 파일의 내용을 확인할 수 있습니다. $ hdfs dfs -cat /dataset/movielens/ratings.csv | less // type “q” to quit tail을 이용해 파일의 마지막 내용을 확인할 수 있습니다. $ hdfs dfs -put ml-20m/movies.csv /dataset/movielens/ $ hdfs dfs -tail /dataset/movielens/movies.csv df를 이용해 남은 디스크 공간을 확인할 수 있습니다. $ hdfs dfs -df -h / mv라는 명령어로 파일을 이동할 수 있습니다. $ hdfs dfs -mv /dataset/movielens/movies.csv / $ hdfs dfs -ls / 파일과 디렉토리의 Access Control List(ACL)를 확인할 수 있습니다. $ hdfs dfs -put ml-20m/movies.csv /dataset/movielens/ $ hdfs dfs -getfacl /dataset/movielens/movies.csv strep 명령어를 통해 HDFS의 replication의 수를 변경할 수 있습니다. $ hdfs dfs -put ml-20m/tags.csv /dataset/movielens/ $ hdfs dfs -setrep -w 3 /dataset/movielens/tags.csv $ hdfs fsck /dataset/movielens/tags.csv rm을 사용해 파일을 삭제할 수 있습니다. $ hdfs dfs -rm /ratings.csv /movies.csv 함수형 프로그래밍 언어에서 빌린 개념 Map 및 Reduce Map 기본 요소 - 반복 연산에 대한 입력 인수의 연속적인 집합에 적용되는 함수 - 예 : Map ReturnType 기능 : 입력 → 결과 Sequential programming으로 코딩한다면 for문을 이용해 코딩할 수 있습니다. 그러나 이러한 형태라면 단일 머신에서 싱글 프로세스로 실행이 가능합니다. Multi core에서 parallel processing을 위해서 Map과 Reduce 함수를 가능하게 합니다. - 사전 정의 된 함수 (예 : 2 진 연산)를 사용하여 입력 시퀀스의 요소를 결합하는 함수. - 예 : MapReduce 계산은 일련의 키 / 값 쌍을 입력으로 취해 키 / 값 쌍의 집합을 출력으로 생성합니다 키 / 값 쌍으로 많은 정보를 표현할 수 있습니다. - Map 단계 : 입력 레코드에 적용되어 중간 값 결과를 키 - 값 형식으로 계산합니다. - Reduce 단계 : 동일한 키를 사용하여 값 집계(aggregate) 라인별 문장에서 space(공백)으로 나누어 단어를 카운트합니다. Map에서는 <Word, 1>로 리턴하며, Reduce에서는 각 들어온 Key(Word)에 따른 1을 더하여 최종 Word가 몇 번 나왔는지 반환합니다. 비정형화된 텍스트인 로그(log)에서 Error를 포함하는 문장을 찾는데 사용할 수 있습니다. URL 리스트에서 참조하는 URL(source, target)을 이용해 (target, source)로 역으로 바뀐 결과값을 반환합니다. 주어진 문서에서 word, pageID로 뽑아낼 수 있습니다. Web Link Graph와 유사합니다. hadoop은 MapReduce 계산 엔진의 오픈 소스 구현입니다. Java 언어로 개발합니다. - JobTracker : 공유 위치에 jar 및 작업 구성 (XML에 직렬화 됨)을 삽입합니다. JobInProgress를 실행 큐에 게시합니다. - TaskTracker : JobTracker에 주기적으로 쿼리합니다. 작업 별 jar 및 구성 검색, 별도의 Java 인스턴스에서 작업 시작. Block 전달은 네트워크 사용을 통한 network overhead가 발생합니다. 각 블록은 GCP에서는 2개의 replication에 복제됩니다. 주어진 Block을 포함하는 TaskTracker가 사용 중이라면, JobTracker는 복제본이 포함된 다른 TaskTracker를 찾아 할당합니다. 그렇지않다면 replication에 가까운 TaskTracker를 이용합니다. Node(TaskTracker) Job 실패 노드 장애를 감지하기 위해 JobTracker와 TaskTracker 사이에서 heartbeat를 주고받으며 체크합니다. 장애가 발생한 경우 다른 node에 작업을 재할당합니다. Map Job 오류 일반적으로 Map 단계에서 하나라도 실패할 경우 모든 Map Job(성공한 작업도 포함)을 다시 실행해야 합니다. Reduce Job 오류 이미 완료된 것은 다시 실행할 필요 없습니다. Master(JobTracker) 실패 현재 Job의 상태를 FSImage와 HDFS에 있는 트랜잭션 로그(transaction log)를 살펴봅니다. Map tasks의 개수를 M, Reduce task의 개수를 R 그리고 Hadoop Cluster의 노드 개수를 H로 가정한다면 M+R > H인 경우가 로드 밸런싱(Load balancing)이나 노드 장애에 따른 조치가 쉬워집니다. M의 경우 Block의 개수로 결정되며, R의 경우 사용자가 설정할 수 있습니다. R이 적을 수록 하나의 Reducer가 처리해야 할 메모리의 양이 늘어나 out of memory가 발생할 수 있습니다. R이 너무 많다면 Task 스케줄링(scheduling) 오버헤드가 늘어날것이며, Output file 쓰기 오버헤드도 발생할 것입니다. 각 R의 개수가 part-r-xxxxx 파일로 작성됩니다. R의 지정은 -Dmapred.reduce.tasks=개수로 지정가능합니다. $ hadoop jar WordCount.jar kr.ac.kookmin.cs.bigdata.WordCount -Dmapred.reduce.tasks=2 /dataset/movielens/movies.csv /user/kmubigdata/output/ - Driver : 전체 작업 구성을 지정하는 main 프로그램' - Map : 병렬로 적용되는 함수 - Reduce : Map 함수의 결과를 집계하는 함수 적절한 Reduce 작업에 Map 작업의 결과를 배치합니다. 이 때 partitioner를 사용하여 HashPartitioner 기본적으로 사용합니다. key.hashCode()를 사용해 진행하며, skewed된 데이터셋에는 적절하지 않습니다. void setup(Context context) - 작업 시작시 한 번 호출됩니다 (블록 당). - 지도 작업을 수행하기 위해 공유 데이터 세트 준비 (예 : stopwords 불용어 처리) void cleanup(Context context) - 임시 폴더가 Map / Reduce 중에 생성 된 경우 임시 폴더 정리 Hadoop Input format Mapper 함수에 전달된 입력 포멧 - TextInputFormat – Treats each ‘\n’-terminated line of a file as a value (line-based records, logs) - KeyValueTextInputFormat – Maps ‘\n’- terminated text lines of “k SEP v” - SequenceFileInputFormat – User-defined (K,V) format for Hadoop specific high performance format Reducer 함수에 출력 포멧(결과) - TextOutputFormat Default: writes “key val\n” strings to output file Can be read by KeyValueInputFormat Human readable - SequenceFileOutputFormat Uses a binary format to pack (k, v) pairs Usually an input for another MR task (intermediate result) - NullOutputFormat Discards output Only useful if defining own output methods within reduce() Repository를 다운 받아옵니다. $ git clone https://github.com/kmu-bigdata/cloud-data-server $ cd cloud-data-server/wordcount/extractGenreFromMovies $ cat WordCount.java Map 함수는 다음과 같습니다. 입력인자로 4개를 받으며 처음 2개의 parameter는 입력 Key, Value 이며, 뒤의 2개는 출력 Key, Value입니다. 여기서 처음보는 데이터 구조인 LongWritable, IntWritable, Text는 Writable 클래스 Text.class: store string object using UTF-8 encoding 입력으로 들어온 Value는 line by line(문장)으로 \\s+(공백:space)로 분리하여 각 단어마다 (word, 1)로 반환합니다. Mapper는 org.apache.hadoop.mapreduce.Mapper 클래스에서 상속받습니다. Hadoop InputFormat은 입력 파일 (movies.csv)의 각 행을 맵 함수의 입력 키 - 값 쌍으로 제공합니다. map 함수는 각 행을 ","을 사용하여 부분 문자열로 분리하고, 하위 문자열의 마지막 토큰 (장르)에 대해 "|"을 사용하여 토큰을 단어 (장르)로 나눕니다. ". 각 단어 (장르)에 대해지도 함수는 (단어, 1)을 출력으로 내보냅니다. Reduce 함수는 다음과 같습니다. Map에서 나온 Key, Value에서 각각의 Value를 합산하여 반환합니다. 각 reduce 함수는 키와 Iterable 형식의 해당 키의 모든 값을받습니다. reduce 함수는 키와 키의 발생 횟수를 출력으로 출력합니다. 특정 디렉토리(wordcount_classes)에 java 컴파일(javac)을 해봅시다. $ mkdir wordcount_classes $ javac -classpath $HADOOP_CLASSPATH -d wordcount_classes WordCount.java java 컴파일을 통해 나온 결과물(3개의 class 파일)을 jar로 다시 컴파일 합니다. $ jar -cvf WordCount.jar -C wordcount_classes/ . jar 파일이 생겼으므로 문서의 단어를 카운트하는데 이 파일을 사용할 수 있습니다. jar 명령을 실행하는 방법은 다음과 같습니다. $ hadoop jar <jar> [mainClass] args … $ hadoop jar WordCount.jar kr.ac.kookmin.cs.bigdata.WordCount /dataset/movielens/movies.csv /user/kmubigdata/output mapreduce의 상태를 살펴보려면 다음의 명령어로 확인 가능합니다. - mapred job –list : job의 리스트를 가져옵니다. - mapred job –status {job-id}: job의 상태를 가져옵니다. - mapred job –kill {job-id} : 실행 중인 job을 제거합니다. More examples : https://hadoop.apache.org/docs/r2.6.3/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapredCommands.html#job 첫 번째 Job이 실행되고 결과물은 output에 저장됩니다. $ hdfs dfs -ls /user/kmubigdata/output cat을 통해 결과물을 확인할 수 있습니다. 확인하면 정렬이 되어 있지 않은 것을 볼 수 있습니다. $ hdfs dfs -cat /user/kmubigdata/output/* 마스터 IP의 19888로 들어가 완료된 Job을 확인할 수 있습니다. 클릭하면 로그와 결과를 볼 수 있습니다. http://35.186.149.159:19888/jobhistory 정렬된 결과를 확인하기 위해서는 bash의 sort 명령어를 통해 정렬할 수 있습니다. 엄청나게 방대한 양이라면 sort 명령어로 처리할 수 없습니다. 즉 mapreduce에서 처리해야 되는 부분입니다. $ hdfs dfs -cat /user/kmubigdata/output/part* | sort -n -k2 | head -n100 정렬을 위해서 우리는 2개의 Map과 2개의 Reduce 그리고 1개의 Driver를 사용할 것입니다. Multiple MR을 위해 Oozie와 luigi, Crunch, Cascading을 사용합니다. 첫 번째 Mapreduce 작업은 단어를 키 (장르)로 사용하고 단어의 수를 디렉토리 /user/kmubigdata/output2/temp의 값으로 계산한 이전 예와 동일합니다. 두 번째 작업의 Map 기능은 Reduce 작업에서 빈도별로 오름차순으로 단어를 정렬 할 수 있도록 키와 값을 바꿉니다. 이 결과는 /user/kmubigdata/output2/final 디렉토리에 있습니다. $ cd ~/cloud-data-server/wordcount/multipleMR $ cat WordCount.java 두 번째 Mapper를 확인하면 처음 MR Job에서 나온 결과를 <count, word>로 반환합니다. 2번째 Map의 결과를 Value 기준으로 가져와 오름차순으로 sorting하고 <word, count>로 반환합니다. 코드 상에서 Reduce의 개수를 지정하려면 setNumberReduceTasks에 개수를 Parameter로 넘기면 됩니다. $ mkdir wordcount_classes $ javac -classpath $HADOOP_CLASSPATH -d wordcount_classes WordCount.java $ jar -cvf WordCount.jar -C wordcount_classes/ . $ hadoop jar WordCount.jar kr.ac.kookmin.cs.bigdata.WordCount /dataset/movielens/movies.csv /user/kmubigdata/output2 $ hdfs dfs -ls /user/kmubigdata/output2/ $ hdfs dfs -ls /user/kmubigdata/output2/final/ 결과를 살펴보면 오름차순으로 정렬된 것을 확인할 수 있습니다. $ hdfs dfs -cat /user/kmubigdata/output2/final/part-r-00000 여기까지 Google Cloud Platform에서 Dataproc을 활용하여 Hadoop의 MapReduce 프로그래밍을 해보았습니다.
- Cloud Dataproc 클러스터를 신속하게 생성하고 언제든지 크기를 조정할 수 있습니다.
- 오픈 소스 생태계
- Spark, Hadoop, Pig 및 Hive의 버전 제공Dataproc 클러스터 생성하기
https://console.cloud.google.com/
8088-Hadoop, 9870-Hdfs, 19888- 하둡의 JobHistoryDataproc master 접속
마스터 노드에서 "SSH"를 클릭합니다. (-m으로 끝남).
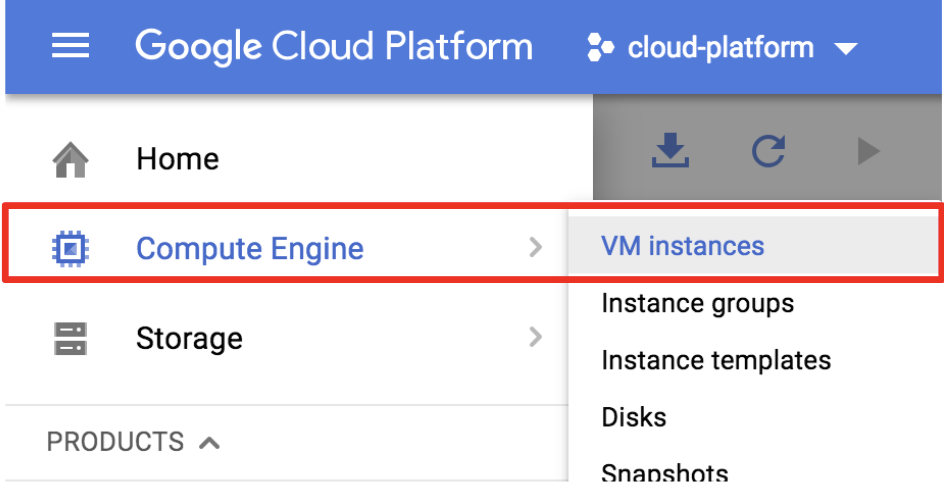
왼쪽 상단의 탐색 메뉴에서 Compute Engine & VM instances를 클릭합니다. 마스터 및 슬레이브 노드가 표시됩니다. 마스터 노드에서 "SSH 옵션 및 gcloud 명령보기"를 클릭하십시오 (-m으로 끝남)movielens 데이터셋
HDFS 사용법
MapReduce
Map
Reduce
WordCount
Distributed Grep
Reverse Web link graph
Inverted index
Hadoop
Job, Task Tracker
Failure
MapReduce granularity
Hadoop 프로그램
- 작업이 끝날 때 한 번 호출됩니다 (블록 당).
네트워크 데이터 전송을 고려한 Hadoop 태스크를위한 직렬화 가능한 형식입니다.
IntWritable.class: serializable Integer
LongWritable.class: serializable Long
TextInputFormat : Treats each ‘\n’-terminated line of a file as a value (line-based records, logs)
TextOutputFormat : Default - writes “key val\n” strings to output fileMultiple MapReduce Job































































'Google Cloud Platform' 카테고리의 다른 글
| Google Cloud ML Engine (2) | 2018.06.12 |
|---|---|
| Google Cloud Platform 이용한 엔티티와 감정 분석 Natural Language API (0) | 2018.06.05 |
| MongoDB using Google Cloud Platform (1) | 2018.06.03 |
| Google Cloud Platform Cloud Vision API를 이용한 이미지, 얼굴 Detection (1) | 2018.04.11 |
| Google Cloud Platform 이용한 텍스트 카테고리 분류 Natural Language API (1) | 2018.04.10 |